DenoDet:SAR 图像目标检测
一、什么是 SAR 图像
SAR 图像是一种独特的遥感成像技术,能够穿透云、雨、雪和雾等大气障碍物,因此在多个领域都有广泛应用,如地质勘探、环境监测、军事侦察等
二、SAR 图像上目标检测的挑战
-
散斑噪声干扰(speckle noise):SAR 是一个相干成像系统,其图像本质上包含不可避免的散斑噪声,会叠加在目标上
针对散斑噪声的传统解决办法:多尺度特征表示、合并上下文信息、软阈值 -
小目标的挑战(small targets):空间范围通常有限,并且目标物体很容易与杂波混淆
解决办法:浅层特征增强网络、多内核大小的特征融合
以上两个问题的现有的解决方法(在目标检测的过程中同时去噪)在几个关键领域存在局限性:
- 抑制噪声不足:CNN 本身会在检测目标特征的同时尝试空间去噪,但是 SAR 图像中的散斑噪声和目标混在一起,难以在原始光谱中分离
- 深度学习中的光谱偏差:深度网络对低频分量表现出频谱偏向,这些分量主要代表背景或更大的物体。不利于检测小目标。
即:深度网络更容易学习到图像的整体结构和背景信息,而忽略一些细节特征 - 静态网络权重:训练后网络权重是静态的,无法自适应地适应 SAR 图像中不断变化的地形或噪点条件。
那么,我们能否在目标检测之前对图像去噪呢?
不可以,因为在图像域中,将相干散斑噪声与目标特征完全分离本质上是一个病态问题。噪声的去除不可避免地会导致关键目标细节的丢失
与其试图在图像层面抑制散斑噪声,不如将去噪的重点转移到目标检测框架内的特征层面
即:设计一个可以无缝集成到目标检测框架中的即插即用特征降噪模块
因此,本文提出了:DenoDet,一种从频域多子空间特征去噪的角度提高 SAR 目标检测性能,DenoDet 将注意力机制解释为动态软阈值收缩操作,即转到频域去噪
三、DenoDet 网络的动机
源于希望通过 显式频域转换 使网络能够优先保留与小目标特征相关的高频信息,同时校准卷积网络对低频分量的固有偏见。
因为:不同的频率会对应于不同尺度的结构,自然而然地形成多尺度的子空间表示
大的思想就是:引入频域之后,目标和噪声就可以分布在不同的频域内,就可以很好的分离,所以也就比较方便抑制噪声
四、整体架构
(1)TransDeno
动态软阈值去噪过程,选择性地保留有效的目标信号,同时过滤掉多余的噪声成分。
使用 2D DCT 将特征表示映射到频域中,并将其分解为多个子空间,每个子空间代表特定频率范围内的信息。
(2)Deformable Group Fully Connected (DeGroFC) layer
自适应地确定每个图像的最佳子空间数量。
五、具体模块
A. Revisiting Attention as Dynamic Soft Thresholding
软阈值是用于降噪的一项基本技术,常规的软阈值函数为:
![]()
为了更有效地抑制噪声,信号通常被转换为特定的变换域,如小波或傅里叶域,这样可以更清楚地区分信号特征和噪声。
创新点是为软阈值加入注意力机制,注意力机制会为数据组件分配不同的权重,会强调与预测任务最相关的权重。
其中函数 g 会聚合相关的特征上下文,生成注意力权重(所以现在的阈值是一个取决于输入的动态值)
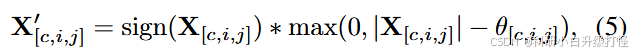
![]()
B. DenoDet Architecture
(一)公式梳理:
(1)DCT 变换
为了将空间域变到频域

DCT 沿 x 轴计算:
class DCT2DSpatialTransformLayer_x(nn.Module):
def __init__(self, width):
super(DCT2DSpatialTransformLayer_x, self).__init__()
self.register_buffer('weight', self.get_dct_filter(width))
def get_dct_filter(self, width): # 根据公式计算 DCT 系数
# dct_filter = torch.zeros(width, width, dtype=torch.float64)
dct_filter = torch.zeros(width, width)
for v in range(width):
for j in range(width):
DCT_base_x = math.cos(math.pi * (0.5 + j) * v / width) / math.sqrt(width)
if v != 0:
DCT_base_x = DCT_base_x * math.sqrt(2)
dct_filter[v, j] = DCT_base_x
return dct_filter
def forward(self, x):
dct_components = []
for weight in self.weight.split(1, dim=0):
dct_component = x * weight.view(1, 1, 1, x.shape[3]).expand_as(x) # 先卷积
dct_components.append(dct_component.sum(3).unsqueeze(3)) # 再求和
result = torch.concat(dct_components, dim=3)
return resultDCT 沿 y 轴计算:
class DCT2DSpatialTransformLayer_y(nn.Module):
def __init__(self, height):
super(DCT2DSpatialTransformLayer_y, self).__init__()
self.register_buffer('weight', self.get_dct_filter(height))
def get_dct_filter(self, height): # 计算 DCT 系数
# dct_filter = torch.zeros(height, height, dtype=torch.float64)
dct_filter = torch.zeros(height, height)
for k in range(height):
for i in range(height):
DCT_base_y = math.cos(math.pi * (0.5 + i) * k / height) / math.sqrt(height)
if k != 0:
DCT_base_y = DCT_base_y * math.sqrt(2)
dct_filter[k, i] = DCT_base_y
return dct_filter
def forward(self, x):
dct_components = []
for weight in self.weight.split(1, dim=0):
dct_component = x * weight.view(1, 1, x.shape[2], 1).expand_as(x) # 先卷积
dct_components.append(dct_component.sum(2).unsqueeze(2)) # 再求和
result = torch.concat(dct_components, dim=2)
return result而频域中变换后的特征图:左上角低频,右下角高频
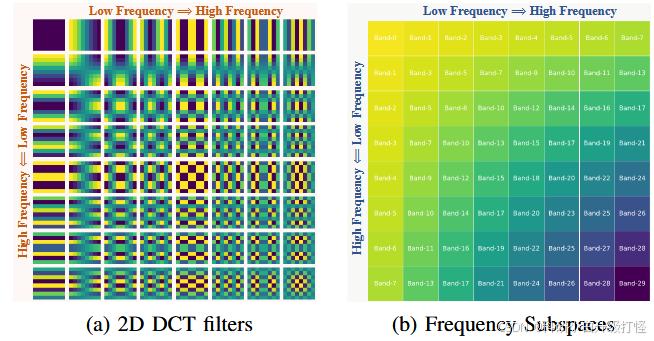
(2)2D 特征图 ----> 1D 特征图
为了针对性的分析
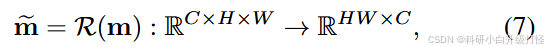
(3)在频域中引入注意力机制
吸收全局语义信息,以调制频谱中的信号,即对二维特征图,沿信道维度执行平均和最大池化来得到频谱图

(4)计算动态阈值
将频域特征图送到注意力块中
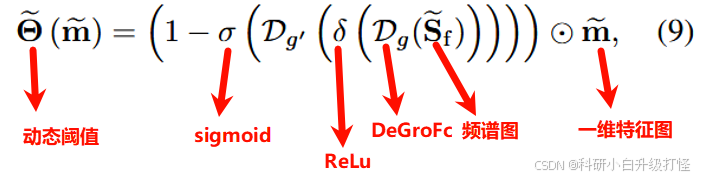
这个其实和 A 模块中提到的动态阈值的计算公式是同一个公式
其中的 一维特征图 、 频谱图,都需要先有 DCT 变换得到的 m 特征图
(5)TransDeno 模块封装为:

y = y.mean(2, keepdim=True) + y.max(2, keepdim=True)[0]注: A 模块只是在给 B 模块铺垫,(4)(5)是 B 模块中的主要公式
其中 IDCT(DCT 逆)的计算公式为:
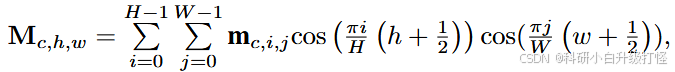
IDCT 沿 x 轴计算:
class IDCT2DSpatialTransformLayer_x(nn.Module):
def __init__(self, width):
super(IDCT2DSpatialTransformLayer_x, self).__init__()
self.register_buffer('weight', self.get_dct_filter(width))
def get_dct_filter(self, width):
# dct_filter = torch.zeros(width, width, dtype=torch.float64)
dct_filter = torch.zeros(width, width)
for v in range(width):
for j in range(width):
DCT_base_x = math.cos(math.pi * (0.5 + v) * j / width) / math.sqrt(width)
if j != 0:
DCT_base_x = DCT_base_x * math.sqrt(2)
dct_filter[v, j] = DCT_base_x
return dct_filter
def forward(self, x):
dct_components = []
for weight in self.weight.split(1, dim=0):
dct_component = x * weight.view(1, 1, 1, x.shape[3]).expand_as(x)
dct_components.append(dct_component.sum(3).unsqueeze(3))
result = torch.concat(dct_components, dim=3)
return resultIDCT 沿 y 轴计算:
class IDCT2DSpatialTransformLayer_y(nn.Module):
def __init__(self, height):
super(IDCT2DSpatialTransformLayer_y, self).__init__()
self.register_buffer('weight', self.get_dct_filter(height))
def get_dct_filter(self, height):
# dct_filter = torch.zeros(height, height, dtype=torch.float64)
dct_filter = torch.zeros(height, height)
for k in range(height):
for i in range(height):
DCT_base_y = math.cos(math.pi * (0.5 + k) * i / height) / math.sqrt(height)
if i != 0:
DCT_base_y = DCT_base_y * math.sqrt(2)
dct_filter[k, i] = DCT_base_y
return dct_filter
def forward(self, x):
dct_components = []
for weight in self.weight.split(1, dim=0):
dct_component = x * weight.view(1, 1, x.shape[2], 1).expand_as(x)
dct_components.append(dct_component.sum(2).unsqueeze(2))
result = torch.concat(dct_components, dim=2)
return result(二)DenoDet 整体框架如图所示:
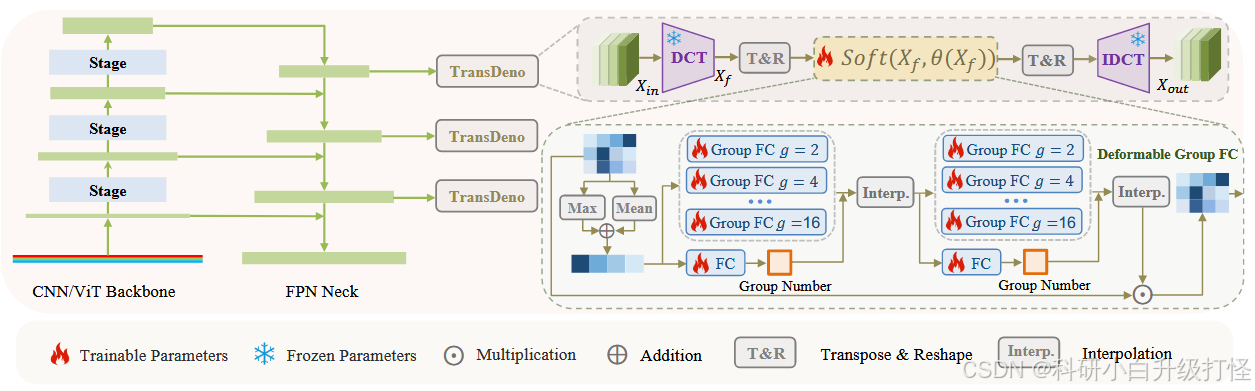
框架图的右上角一行(尤其是是 soft --> T&R --> IDCT)是和公式(10)是对应的
(三)DenoDet 、TransDeno 、 DeGroFC 三者直接的关系:
DeGroFC 是 TransDeno 的一部分,而 TransDeno 又是 DenoDet 框架
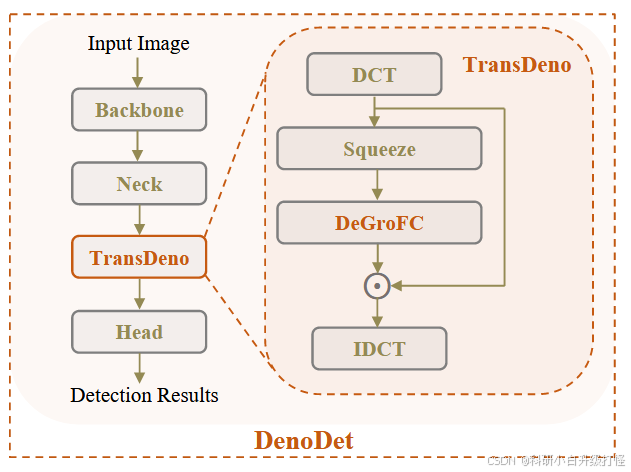
C. Deformable Group FC Layer
DeGroFC:
self.fc1 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=2),
nn.ReLU(),
)
self.fc2 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=4),
nn.ReLU(),
)
self.fc3 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=8),
nn.ReLU(),
)
self.fc4 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=16),
nn.ReLU(),
)
self.select1 = SelectBlock(channel,4)y1 = self.fc1(y).unsqueeze(1)
y2 = self.fc2(y).unsqueeze(1)
y3 = self.fc3(y).unsqueeze(1)
y4 = self.fc4(y).unsqueeze(1)
temp = self.select1(y, torch.cat([y1,y2,y3,y4],dim=1)) DeGroFC 逆:
self.fc5 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=2),
nn.Sigmoid(),
)
self.fc6 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=4),
nn.Sigmoid(),
)
self.fc7 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=8),
nn.Sigmoid(),
)
self.fc8 = nn.Sequential(
nn.Conv1d(channel, channel, 1, groups=16),
nn.Sigmoid(),
)
self.select2 = SelectBlock(channel,4)y5 = self.fc5(temp).unsqueeze(1)
y6 = self.fc6(temp).unsqueeze(1)
y7 = self.fc7(temp).unsqueeze(1)
y8 = self.fc8(temp).unsqueeze(1)
att = self.select2(temp, torch.cat([y5,y6,y7,y8],dim=1)) 其中 SelectBlock:
class SelectBlock(nn.Conv1d):
def __init__(self, channels, branches):
super(SelectBlock, self).__init__(channels,branches,1, bias=False)
self.eps = 1e-15
self.branches = branches
self.softmax = nn.Softmax(1)
def forward(self, origin_tensor, branch_tensors):
branch_offsets = super().forward(origin_tensor)
branch_offsets = branch_offsets - branch_offsets.min(1,keepdim=True)[0] + self.eps
branch_offsets = branch_offsets / branch_offsets.max(1,keepdim=True)[0] * (branch_tensors.size(1) - 1)
b,c,h,w = branch_tensors.size()
y = branch_tensors.clone()
branch_min = (branch_offsets.floor().long()).view(b, self.branches, 1, 1).expand(b, self.branches, h, w)
branch_max = branch_offsets.ceil().long().view(b, self.branches, 1, 1).expand(b, self.branches, h, w)
min_offset = (branch_offsets - branch_offsets.floor()).view(b, self.branches, 1, 1).expand(b,self.branches, h, w)
max_offset = (branch_offsets.ceil() - branch_offsets).view(b, self.branches, 1, 1).expand(b,self.branches, h, w)
offset = self.softmax(torch.cat([min_offset,max_offset],dim=1)).split(self.branches,dim=1)
min_offset = offset[0] # 对应公式 13 中的 Op
max_offset = offset[1] # 对应公式 13 中的 Oq
for i in range(self.branches):
y[:,i,...] = (torch.gather(branch_tensors, 1, branch_min[:,i,...].unsqueeze(1)).squeeze(1) * min_offset[:,i,...] # 对应公式 14
+ torch.gather(branch_tensors, 1, branch_max[:,i,...].unsqueeze(1)).squeeze(1) * max_offset[:,i,...])
return y.sum(1)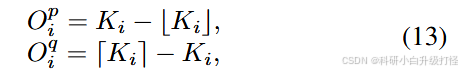
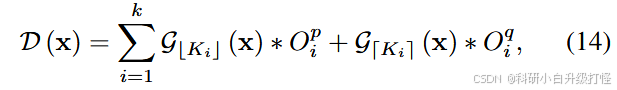

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)