机器学习周报六
本周学习的是集成学习部分的内容,关于bagging和boosting有了认识,对梯度、方向导数进行学习,解开了理解不充分的地方。本周对集成学习的概念和AdaBoost、GBDT算法和空间代数进行了学习,由于时间问题,还没有通过梯度去解释GBDT算法,下周将会解开GBDT的疑惑。
文章目录
摘要
本周学习的是集成学习部分的内容,关于bagging和boosting有了认识,对梯度、方向导数进行学习,解开了理解不充分的地方。
Abstract
This week I learned the content of the integrated learning part, about bagging and boosting, learned gradients and direction derivatives, and solved the insufficient understanding.
1 集成学习
1.1 基本概念
构建并组合多个学习器来完成学习任务。先产生一组“个体学习器”,再用某种策略将它们结合起来。个体学习器一般就是我们常见的机器学习算法,比如:决策树,神经网络等。
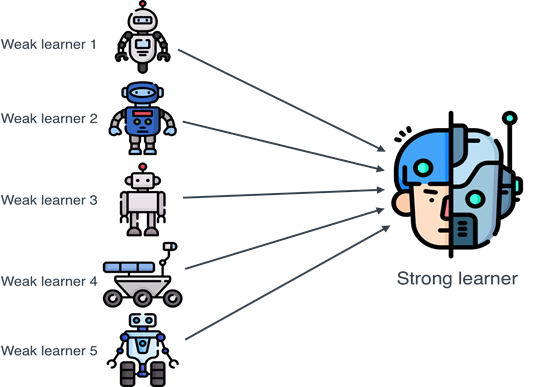
图1.1 集成学习
有两种集成:同质和异质
-
同质是指个体学习器都是同一种类型,同质集成中的个体学习器又称基学习器。
-
异质是指个体学习器包含不同类型的学习算法,比如包含决策树和神经网络。
一般使用的都是同质的
按照个体学习器之间是否存在依赖关系可以分为两类:
- 个体学习器之间存在强依赖关系,一系列个体学习器基本必须串行生成,代表是boosting系列算法。
- 个体学习器之间不存在强依赖关系 ,一系列个体学习器可以并行生成,代表是bagging系列算法。
1.2 Boosting
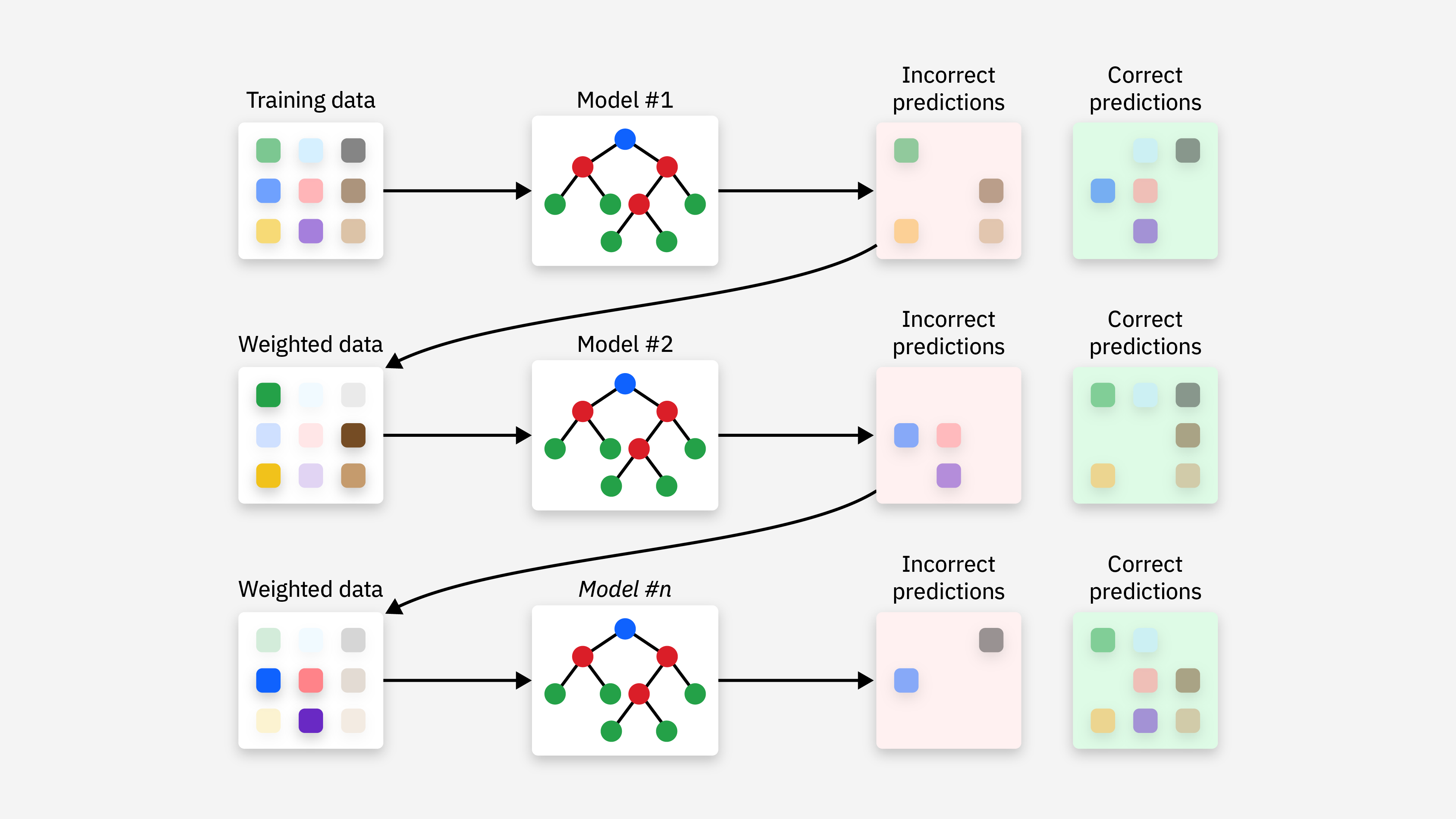
图1.2 Boosting
上图看出,Boosting的流程是从初始训练集先训练一个基学习器;根据基学习器的预测结果对样本权重进行调整,增加基学习器分类错误的样本的权重(重采样);基于调整后的样本分布重新训练下一个学习器。如此重复进行到T个学习器的训练,将这T个学习器进行整合,得到最后的强学习器。
Boosting算法的典型有:
-
AdaBoost(Adaptive Boosting):AdaBoost 通过改变样本的权重,使得每个后续分类器更加关注前一轮错误分类的样本。
-
梯度提升树(Gradient Boosting Decision Trees, GBDT):GBTD 通过迭代优化目标函数,逐步减少偏差。
-
XGBoost(Extreme Gradient Boosting):XGBoost 是一种高效的梯度提升算法,广泛应用于数据科学竞赛中,具有较强的性能和优化。
-
LightGBM(Light Gradient Boosting Machine):LightGBM 是一种基于梯度提升树的框架,相较于 XGBoost,具有更快的训练速度和更低的内存使用。
优势:
- 适用于偏差较大的模型,能有效提高预测准确性。
- 强大的性能,在许多实际应用中表现优异。
缺点:
-
对噪声数据比较敏感,容易导致过拟合。
-
训练过程较慢,特别是在数据量较大的情况下。
1.3 Bagging
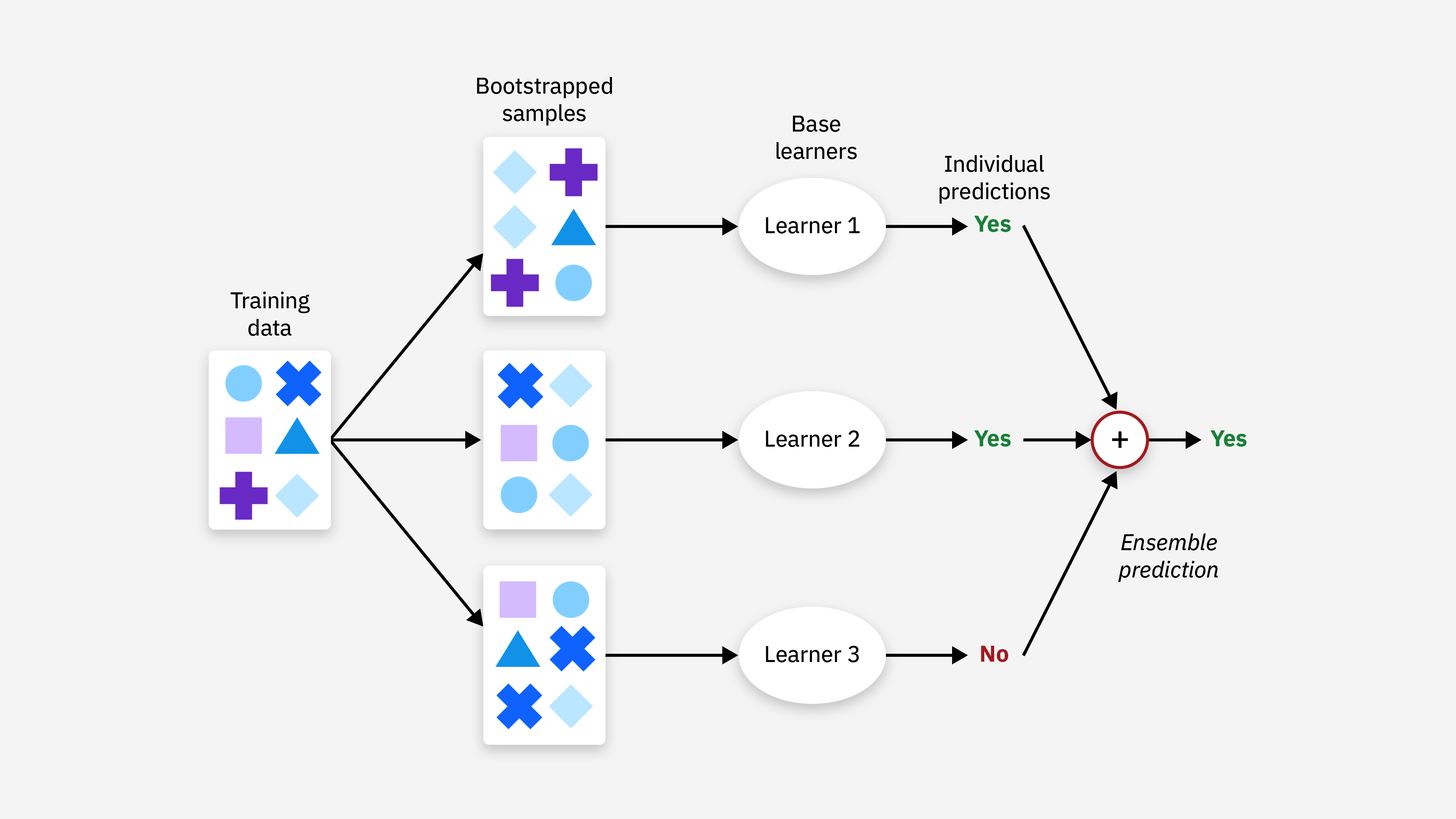
图 1.3 Bagging
Bagging 的目标是通过减少模型的方差来提高性能,适用于高方差、易过拟合的模型。它通过以下步骤实现:
- 数据集重采样:对训练数据集进行多次有放回的随机采样(bootstrap),每次采样得到一个子数据集。
- 训练多个模型:在每个子数据集上训练一个基学习器(通常是相同类型的模型)。
- 结果合并:将多个基学习器的结果进行合并,通常是通过投票(分类问题)或平均(回归问题)。
值得注意的是这里的随机采样采用的是自助采样法(Bootstrap sampling),自助采样法是一种有放回的采样。即对于 m m m个样本的原始训练集,每次先随机采集一个样本放入采样集,接着把该样本放回,这样采集 m m m次,最终可以得到 m m m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的。
对于一个样本,它每次被采集到的概率是 1 m \frac{1}{m} m1。不被采集到的概率为 1 − 1 m 1-\frac{1}{m} 1−m1 。如果 m m m次采样都没有被采集中的概率是 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m。则 lim m → ∞ ( 1 − 1 m ) m → 1 e ≈ 0.368 \lim_{m\rightarrow \infty}(1-\frac{1}{m})^m\rightarrow \frac{1}{e}\approx0.368 limm→∞(1−m1)m→e1≈0.368,即当抽样的样本量足够大时,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采集中。对于这部分大约36.8%的没有被采样到的数据,常常称之为袋外数据(Out Of Bag, 简称OOB)。这些数据未参与训练集模型的拟合,可以用来检测模型的泛化能力。
bagging对于弱学习器最常用的一般也是决策树和神经网络。bagging的集合策略也比较简单,对于分类问题,通常使用相对多数投票法。对于回归问题,通常使用算术平均法。
典型算法:
- 随机森林(Random Forest):随机森林是 Bagging 的经典实现,它通过构建多个决策树,每棵树在训练时随机选择特征,从而减少过拟合的风险。
优势:
- 可以有效减少方差,提高模型稳定性。
- 适用于高方差的模型,如决策树。
缺点:
- 训练过程时间较长,因为需要训练多个模型。
- 结果难以解释,因为没有单一的模型。
1.4 合成策略
假定得到的 T T T个弱学习器 h 1 , h 2 , . . . , h T h_1,h_2,...,h_T h1,h2,...,hT
- 平均法
对于回归问题通常使用平均法
最简单的平均法是算术平均,即:
H ( x ) = 1 T Σ i = 1 T h i ( x ) H(x)=\frac{1}{T}\Sigma_{i=1}^{T}h_i(x) H(x)=T1Σi=1Thi(x)
也可以是每个学习器的加权平均,即:
H ( x ) = Σ i = 1 T w i h i ( x ) H(x)=\Sigma_{i=1}^T w_i h_i(x) H(x)=Σi=1Twihi(x)
其中 w i w_i wi是个体学习器 h i h_i hi的权重
- 投票法
对于分类问题通常使用投票法。
假设预测类别是 c 1 , c 2 , . . . , c K c_1,c_2,...,c_K c1,c2,...,cK,对于任意一个预测样本 x x x, T T T个弱学习器的预测结果分别是 ( h 1 ( x ) , h 2 ( x ) , . . . , h T ( x ) ) (h_1(x),h_2(x),...,h_T(x)) (h1(x),h2(x),...,hT(x))。主要有以下三种:
-
相对多数投票法:也就是少数服从多数,即预测结果中票数最高的分类类别。如果不止一个类别获得最高票,则随机选择一个作为最终类别。
-
绝对多数投票法:即不光要求获得最高票,还要求票过半数。
-
加权投票法:每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,最大的值对应的类别为最终类别。
1.5 Stacking
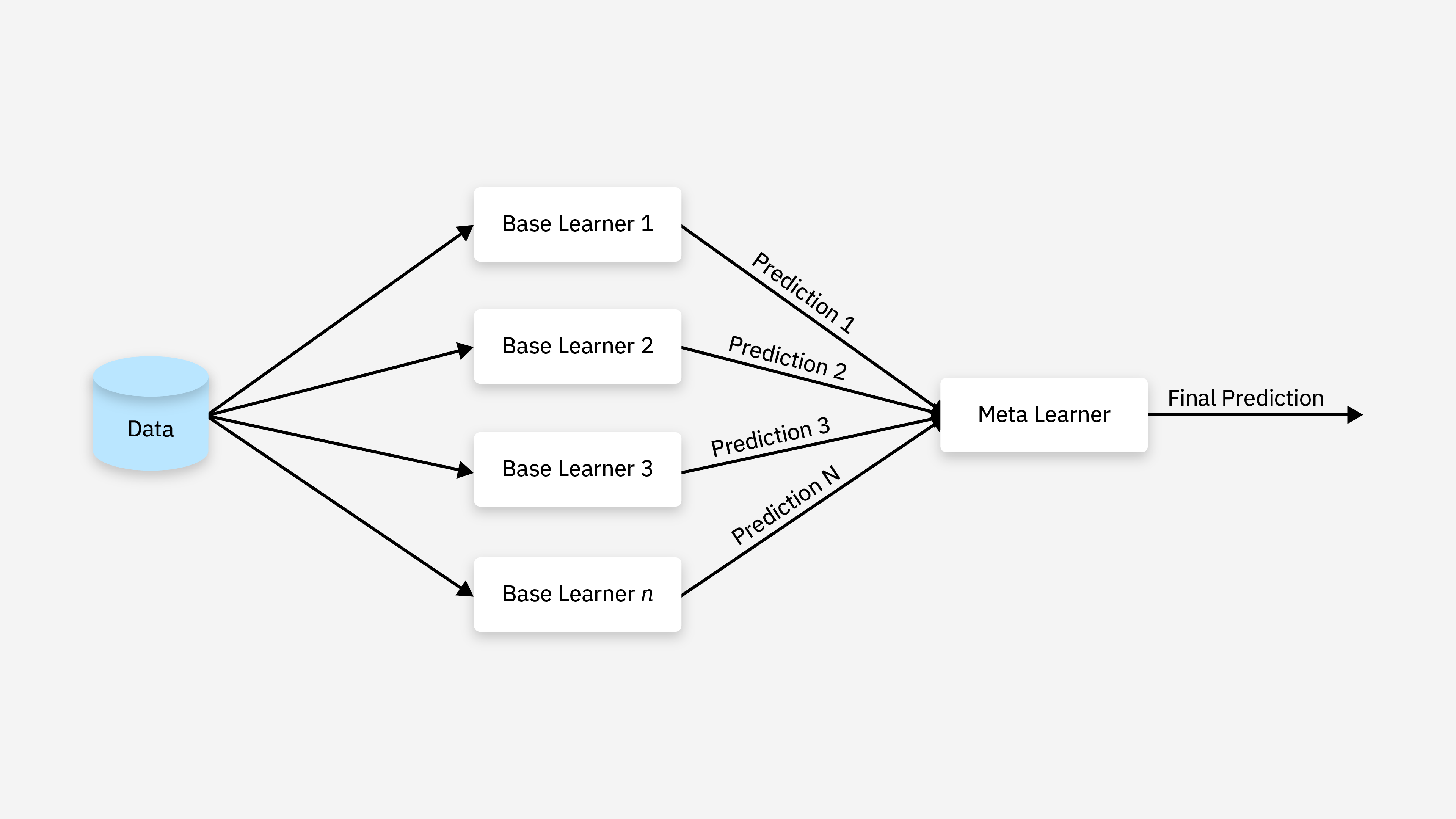
图1.4 Stacking
Stacking 是一种通过训练不同种类的模型并组合它们的预测来提高整体预测准确度的方法。其核心思想是:
- 第一层(基学习器):训练多个不同类型的基学习器(例如,决策树、SVM、KNN 等)来对数据进行预测。
- 第二层(元学习器):将第一层学习器的预测结果作为输入,训练一个元学习器(通常是逻辑回归、线性回归等),来做最终的预测。
优势:
- 可以使用不同类型的基学习器,捕捉数据中不同的模式。
- 理论上可以结合多种模型的优势,达到更强的预测能力。
缺点:
- 训练过程复杂,需要对多个模型进行训练,且模型之间的结合方式也需要精心设计。
- 比其他集成方法如 Bagging 和 Boosting 更复杂,且容易过拟合。
2 AdaBoost算法
(1)设置初始样本权重
在算法开始时,为训练集样本设置一个相同的权重,例如样本 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) D={(x_1,y_1),(x_2,y_2),...,(x_n,y_n)} D=(x1,y1),(x2,y2),...,(xn,yn),初始权重为 w ( 1 ) = ( w 1 ( 1 ) , w 2 ( 1 ) , . . . , w n ( 1 ) ) w^{(1)}=(w_1^{(1)},w_2^{(1)},...,w_n^{(1)}) w(1)=(w1(1),w2(1),...,wn(1)),其中 w i ( 1 ) = 1 n w_i^{(1)}=\frac{1}{n} wi(1)=n1,即在第一轮训练时,每个样本在训练中的重要度相同。
(2)训练弱学习器
基于当前的权重分布,训练一个弱学习器。弱学习器是指一个性能仅略优于随机猜测的学习算法,例如决策树桩(一种简单的决策树,通常只有一层)。在训练过程中,弱学习器会根据样本的权重来调整学习的重点,更关注那些权重较高的样本。
(3)计算弱学习器的权重
根据弱学习器在训练集上的分类错误率,计算该弱学习器的权重。错误率越低,说明该弱学习器的性能越好,其权重也就越大;反之,错误率越高的弱学习器权重越小。通常使用的计算公式为 α = 1 2 ln ( 1 − ε ε ) \alpha=\frac{1}{2}\ln(\frac{1-\varepsilon}{\varepsilon}) α=21ln(ε1−ε),其中 ε \varepsilon ε为弱学习器的错误率。
(4)更新训练数据的权重分布
根据当前数据的权重和弱学习器的权重,更新训练集的权重分布。具体的规则是对于被正确分类的样本,降低其权重;对于被错误分类的样本,提高其权重。这样,在下一轮训练中,弱学习器会更加关注那些之前被错误分类的样本,从而有针对性地进行学习。公式为
KaTeX parse error: {equation} can be used only in display mode.
其中, w i ( t ) w_i^{(t)} wi(t)是第 t t t 轮中第 i i i个样本的权重, Z t Z_t Zt是归一化因子,确保更新后的样本权重之和为 1, h t ( x i ) h_t(xi) ht(xi)是第 t t t个弱学习器对第 i i i个样本的预测结果。
(5)重复以上步骤
不断重复训练弱学习器、计算弱学习器权重、更新数据权重分布的过程,直到达到预设的停止条件,如训练的弱学习器数量达到指定的上限,或者集成模型在验证集上的性能不再提升等。
(6)构建集成模型
将训练好的所有弱学习器按照其权重进行组合,得到最终的集成模型。如训练得到一系列弱学习器 h 1 , h 2 , . . . , h T h_1,h_2,...,h_T h1,h2,...,hT及对应的权重 α 1 , α 2 , . . . , α n \alpha_1,\alpha_2,...,\alpha_n α1,α2,...,αn,最终的强学习器 H ( X ) H(X) H(X)通过这些弱学习器进行加权组合得到。对于分类问题,通常采用符号函数 H ( X ) = s i g n ( ∑ t = 1 T α t h t ( X ) ) H\left( X \right)=sign\left( \sum_{t=1}^{T}{\alpha_th_t(X)} \right) H(X)=sign(∑t=1Tαtht(X))输出;对于回归问题,则可以采用加权平均的方式输出。
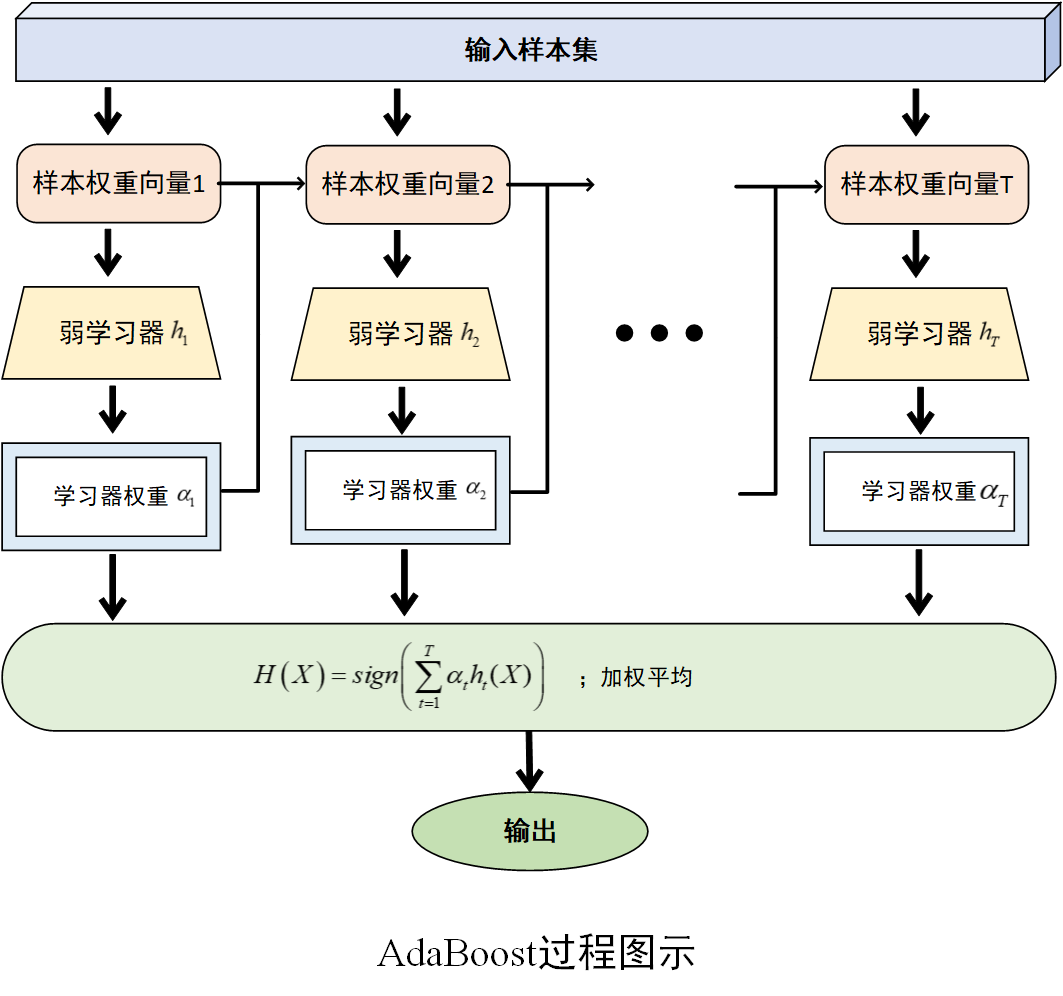
图 2.1 AdaBoost
3 GBDT算法
所有弱分类器的结果相加等于预测值。每次都以当前预测为基准,下一个弱分类器去拟合残差(预测值与真实值之间的误差)。GBDT的弱分类器使用的是决策树。实际上每个决策树拟合的都是负梯度,只是当损失函数是均方损失时,负梯度刚好是残差,所以其实残差只是负梯度的一种特例而已。
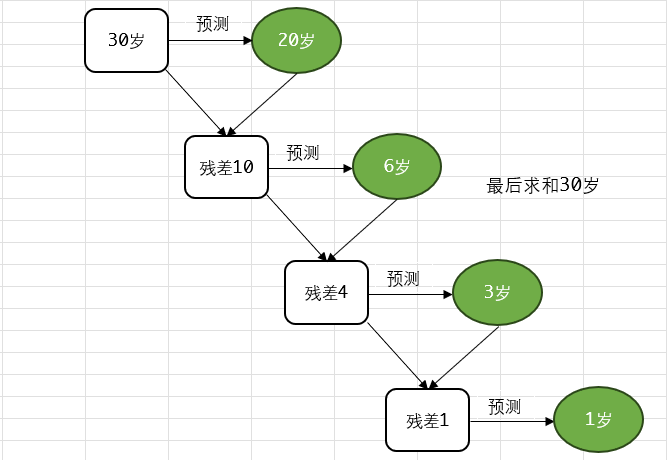
图3.1 GBDT算法
上图是GBDT算法的例子
第一个弱分类器(第一棵树)预测一个年龄(如20岁),计算发现误差有10岁;
第二棵树预测拟合残差,预测值6,计算发现差距还有4岁;
第三棵树继续预测拟合残差,预测值3,发现差距只有1岁了;
第四课树用1岁拟合剩下的残差,完成。
最终,四棵树的结论加起来,得到30岁这个标注答案。
4 向量代数与空间几何
4.1 基础公式
数量积: a ⋅ b = ∣ a ∣ ∣ b ∣ cos θ a\cdot b=|a||b|\cos \theta a⋅b=∣a∣∣b∣cosθ
性质: a ⋅ a = ∣ a ∣ 2 ; a ⋅ b = 0 , a ⊥ b a\cdot a=|a|^2;a \cdot b=0,a \perp b a⋅a=∣a∣2;a⋅b=0,a⊥b
交换律: a ⋅ b = b ⋅ a a \cdot b= b \cdot a a⋅b=b⋅a
分配律: ( a + b ) ⋅ c = a ⋅ c + b ⋅ c (a+b)\cdot c=a\cdot c+ b\cdot c (a+b)⋅c=a⋅c+b⋅c
结合律: ( λ a ) ⋅ b = λ ( a ⋅ b ) (\lambda a)\cdot b=\lambda(a \cdot b) (λa)⋅b=λ(a⋅b)
坐标表示: a = a x i + a y j + a z k ; b = b x i + b y j + b z k a=a_x i+a_y j+a_z k \space ;b=b_x i+b_y j+b_z k a=axi+ayj+azk ;b=bxi+byj+bzk,则 a ⋅ b = a x b x + a y b y + a z b z , cos θ = a x b x + a y b y + a z b z a x 2 + a y 2 + a z 2 b x 2 + b y 2 + b z 2 a \cdot b=a_xb_x+a_yb_y+a_zb_z,\cos \theta=\frac{a_xb_x+a_yb_y+a_zb_z}{\sqrt{a_x^2+a_y^2+a_z^2}\sqrt{b_x^2+b_y^2+b_z^2}} a⋅b=axbx+ayby+azbz,cosθ=ax2+ay2+az2bx2+by2+bz2axbx+ayby+azbz
向量积: c = a × b c=a\times b c=a×b,其中 ∣ c ∣ = ∣ a ∣ ∣ b ∣ sin θ |c|=|a||b|\sin \theta ∣c∣=∣a∣∣b∣sinθ
方向确定:右手规则
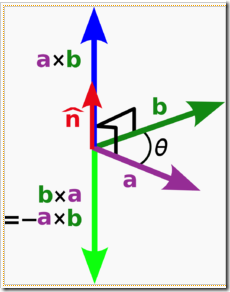
图4.1 向量积
四指握拳,大拇指竖直,类似点赞的手势;掌心朝外的方向是b的方向,手指相反的指向是a的方向,大拇指的方向为c的方向。
性质: a × a = 0 ; a × b = 0 , a / / b ; a\times a =0;a \times b=0,a//b; a×a=0;a×b=0,a//b;
基本运算规律: a × b = − b × a a \times b=-b \times a a×b=−b×a
分配律: ( a + b ) × c = a × c + b × c (a+b)\times c=a\times c+b \times c (a+b)×c=a×c+b×c
结合律: ( λ a ) × b = a × ( λ b ) = λ ( a × b ) (\lambda a)\times b=a\times (\lambda b)=\lambda(a\times b) (λa)×b=a×(λb)=λ(a×b)
坐标表示
a = a x i + a y j + a z k ; b = b x i + b y j + b z k a=a_x i+a_y j+a_z k \space;b=b_x i+b_y j +b_z k a=axi+ayj+azk ;b=bxi+byj+bzk
a × b = ( a y b z − b z a y ) i + ( a z b x − a x b z ) j + ( a x b y − a y b x ) k a\times b=(a_yb_z-b_za_y)i+(a_zb_x-a_xb_z)j+(a_xb_y-a_yb_x)k a×b=(aybz−bzay)i+(azbx−axbz)j+(axby−aybx)k
a × b = ∣ i j k a x a y a z b x b y b z ∣ a\times b=\begin{vmatrix}i && j && k \\ a_x && a_y && a_z \\ b_x && b_y && b_z\end{vmatrix} a×b= iaxbxjaybykazbz
混合积
[ a b c ] = ( a × b ) ⋅ c [abc]=(a\times b)\cdot c [abc]=(a×b)⋅c
坐标表示
a = a x i + a y j + a z k ; b = b x i + b y j + b z k ; c = c x i + c y j + c z k a=a_x i+a_y j+a_z k \space;b=b_x i+b_y j +b_z k;c=c_x i+c_y j+c_z k a=axi+ayj+azk ;b=bxi+byj+bzk;c=cxi+cyj+czk
[ a b c ] = ∣ a x a y a z b x b y b z c x c y c z ∣ [abc]=\begin{vmatrix}a_x && a_y && a_z \\ b_x && b_y && b_z\\ c_x && c_y && c_z\end{vmatrix} [abc]= axbxcxaybycyazbzcz
性质 ( a × b ) ⋅ c = a ⋅ ( b × c ) = b ⋅ ( c × a ) (a\times b)\cdot c=a \cdot (b\times c)=b\cdot (c\times a) (a×b)⋅c=a⋅(b×c)=b⋅(c×a)
( a × b ) ⋅ c = − ( b × a ) ⋅ c (a\times b)\cdot c=-(b\times a)\cdot c (a×b)⋅c=−(b×a)⋅c
( a × b ) ⋅ c = − ( c × b ) ⋅ a (a\times b)\cdot c=-(c\times b)\cdot a (a×b)⋅c=−(c×b)⋅a
( a × b ) ⋅ c = − ( a × c ) ⋅ b (a\times b)\cdot c=-(a\times c)\cdot b (a×b)⋅c=−(a×c)⋅b
a 、 b 、 c 共面 ⇔ [ a b c ] = 0 a、b、c\text{共面}\Leftrightarrow [abc]=0 a、b、c共面⇔[abc]=0
几何意义
向量的混合积 [ a b c ] = ( a × b ) ⋅ c [abc]=(a\times b)\cdot c [abc]=(a×b)⋅c的绝对值在数值上等于向量a、b、c为棱的平行六面体的体积。
4.2 平面、曲面
曲面S方程: F ( x , y , z ) = 0 F(x,y,z)=0 F(x,y,z)=0满足下列条件:
1.曲线S上的任一点坐标都满足方程
2.不在曲面S上的点的坐标都不满足方程
平面
法线向量:垂直于给定平面的非零向量
平面方程
点法式方程:
A ( x − x 0 ) + B ( y − y 0 ) + C ( z − z 0 ) = 0 A(x-x_0)+B(y-y_0)+C(z-z_0)=0 A(x−x0)+B(y−y0)+C(z−z0)=0
说明:已知平面上一点 M ( x 0 , y 0 , z 0 ) M(x_0,y_0,z_0) M(x0,y0,z0)和法线向量 n = ( A , B , C ) n=(A,B,C) n=(A,B,C),设 M ( x , y , z ) M(x,y,z) M(x,y,z)为平面上任意一点,由 n ⋅ M 0 M ⃗ = 0 n\cdot \vec{M_0M}=0 n⋅M0M=0可得
一般方程:
A x + B y + C z + D = 0 Ax+By+Cz+D=0 Ax+By+Cz+D=0其中 n ⃗ = ( A , B , C ) \vec{n}=(A,B,C) n=(A,B,C)为法线向量
截距式方程:
x a + y b + z c = 1 \frac{x}{a}+\frac{y}{b}+\frac{z}{c}=1 ax+by+cz=1,其中a,b,c为平面在三个坐标轴上的截距。
平面夹角
定义:两平面的法线向量夹角称为两平面的夹角
计算: cos θ = A 1 A 2 + B 1 B 2 + C 1 C 2 A 1 2 + B 1 2 + C 1 2 A 2 2 + B 2 2 + C 2 2 \cos \theta=\frac{A_1A_2+B_1B_2+C_1C_2}{\sqrt{A_1^2+B_1^2+C_1^2}\sqrt{A_2^2+B_2^2+C_2^2}} cosθ=A12+B12+C12A22+B22+C22A1A2+B1B2+C1C2
空间直线
直线的方向向量:平行于已知直线的向量
直线方程:
一般方程:空间直线可以看作两平面的交线,所以 { A 1 x + B 1 y + C 1 z + D 1 = 0 A 2 x + B 2 y + C 2 z + D 2 = 0 \begin{cases}A_1x+B_1y+C_1z+D_1=0 \\ A_2x+B_2y+C_2z+D_2=0\end{cases} {A1x+B1y+C1z+D1=0A2x+B2y+C2z+D2=0
对称式方程: x − x 0 m = y − y 0 n = z − z 0 p \frac{x-x_0}{m}=\frac{y-y_0}{n}=\frac{z-z_0}{p} mx−x0=ny−y0=pz−z0其中 ( x 0 , y 0 , z 0 ) (x_0,y_0,z_0) (x0,y0,z0)为直线上任意点, s = ( m , n , p ) s=(m,n,p) s=(m,n,p)为直线方向向量
参数方程: { x = x 0 + m t y = y 0 + n t z = z 0 + p t \begin{cases}x=x_0+mt \\ y=y_0+nt \\ z=z_0+pt\end{cases} ⎩ ⎨ ⎧x=x0+mty=y0+ntz=z0+pt
夹角
线线夹角:两直线的方向向量夹角
设 s 1 = ( m 1 , n 1 , p 1 ) ; s 2 = ( m 2 , n 2 , p 2 ) s_1=(m_1,n_1,p_1);s_2=(m_2,n_2,p_2) s1=(m1,n1,p1);s2=(m2,n2,p2)
则 c o s φ = m 1 m 2 + n 1 n 2 + p 1 p 2 m 1 2 + n 1 2 + p 1 2 m 2 2 + n 2 2 + p 2 2 cos \varphi =\frac{m_1m_2+n_1n_2+p_1p_2}{\sqrt{m_1^2+n_1^2+p_1^2}\sqrt{m_2^2+n_2^2+p_2^2}} cosφ=m12+n12+p12m22+n22+p22m1m2+n1n2+p1p2
线面夹角:直线和它在平面上的投影的夹角
设直线向量 s = ( m , n , p ) s=(m,n,p) s=(m,n,p),平面法向量 n = ( A , B , C ) n=(A,B,C) n=(A,B,C)
则 sin φ = ∣ A m + B n + C p ∣ A 2 + B 2 + C 2 m 2 + n 2 + p 2 \sin \varphi =\frac{|Am+Bn+Cp|}{\sqrt{A^2+B^2+C^2}\sqrt{m^2+n^2+p^2}} sinφ=A2+B2+C2m2+n2+p2∣Am+Bn+Cp∣
曲面
旋转曲面
一条平面曲线绕其平面上的一条直线旋转一周所成的曲线
母线:旋转曲线
轴:定直线
常见曲面
圆锥面
直线L绕另一条与L相交的直线旋转一周所得的旋转曲面
顶点:两直线交点
半顶角:两直线的夹角 α ( 0 < α < π 2 ) \alpha(0<\alpha<\frac{\pi}{2}) α(0<α<2π)
方程: z 2 = a 2 ( x 2 + y 2 ) z^2=a^2(x^2+y^2) z2=a2(x2+y2)其中 a = c o t α a=cot \alpha a=cotα
4.3 曲线
曲线方程:看作两个曲面的交线
所有在曲线上的点都满足方程 { F ( x , y , z ) = 0 G ( x , y , z ) = 0 \begin{cases} F(x,y,z)=0 \\ G(x,y,z)=0\end{cases} {F(x,y,z)=0G(x,y,z)=0
参数方程,只要将曲线C上的动点坐标x,y,z用带有参数t的函数表示即可,即方程组 { x = x ( t ) y = y ( t ) z = z ( t ) \begin{cases}x=x(t) \\ y=y(t) \\ z=z(t)\end{cases} ⎩ ⎨ ⎧x=x(t)y=y(t)z=z(t)
5 梯度
第四节的内容是因为看到了梯度提升树,梯度提升在对曲线上的点求偏导,所以学习了空间几何的部分,对梯度的理解也不到位,于是对这两个方向进行学习。
5.1 导数
在一元函数情况下,梯度就是斜率。
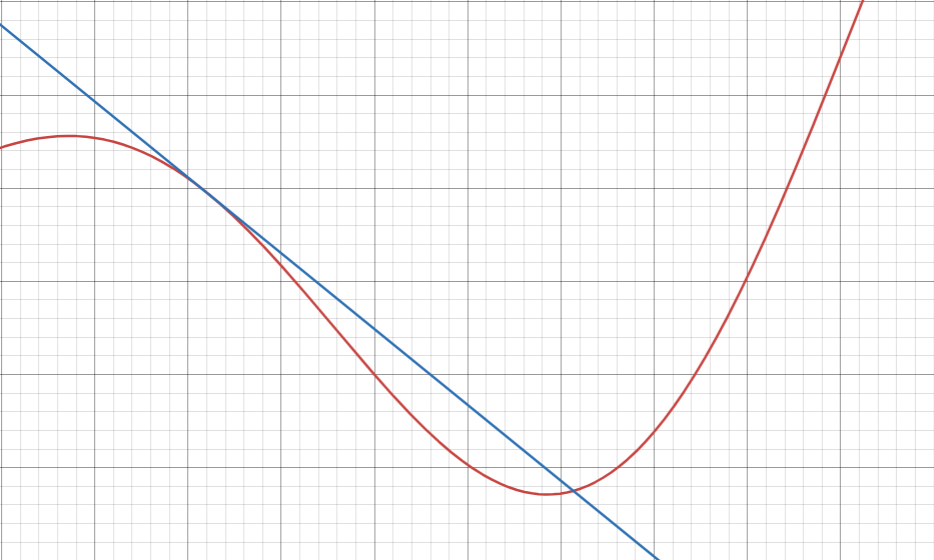
图 5.1 一元函数
梯度的方向
变化率:函数上 处发生一个增量 Δ x \Delta x Δx,则 y y y也将发生一个增量 Δ y \Delta y Δy ,记 lim Δ x → 0 Δ y Δ x \lim_{\Delta x \rightarrow 0}\frac{\Delta y}{\Delta x} limΔx→0ΔxΔy为该点的瞬时变化率(导数)。
是直线的时候,由于各点的导数相同,因此导数的含义很好理解,设 k = Δ y Δ x k=\frac{\Delta y}{\Delta x} k=ΔxΔy,则表示在该点处x增加1时,y将增加k。
曲线时,将某点很小的范围内的线段视为直线,则变化率 d y d x = lim Δ x → 0 f ( x + Δ x ) − f ( x ) Δ x \frac{dy}{dx}=\lim_{\Delta x \rightarrow 0}\frac{f(x+\Delta x)-f(x)}{\Delta x} dxdy=limΔx→0Δxf(x+Δx)−f(x)
5.2 方向导数
函数定义域内的某点对某一方向求导得到的导数。
方向就是 x x x点处发生一个增量 Δ x \Delta x Δx,显然这个增量可正可负,向左移动( Δ x < 0 \Delta x<0 Δx<0)或者向右移动( Δ x > 0 \Delta x>0 Δx>0)
方向导数就是,给定方向的变化率,若曲线在该点可导,那么左右方向的变化率相等。
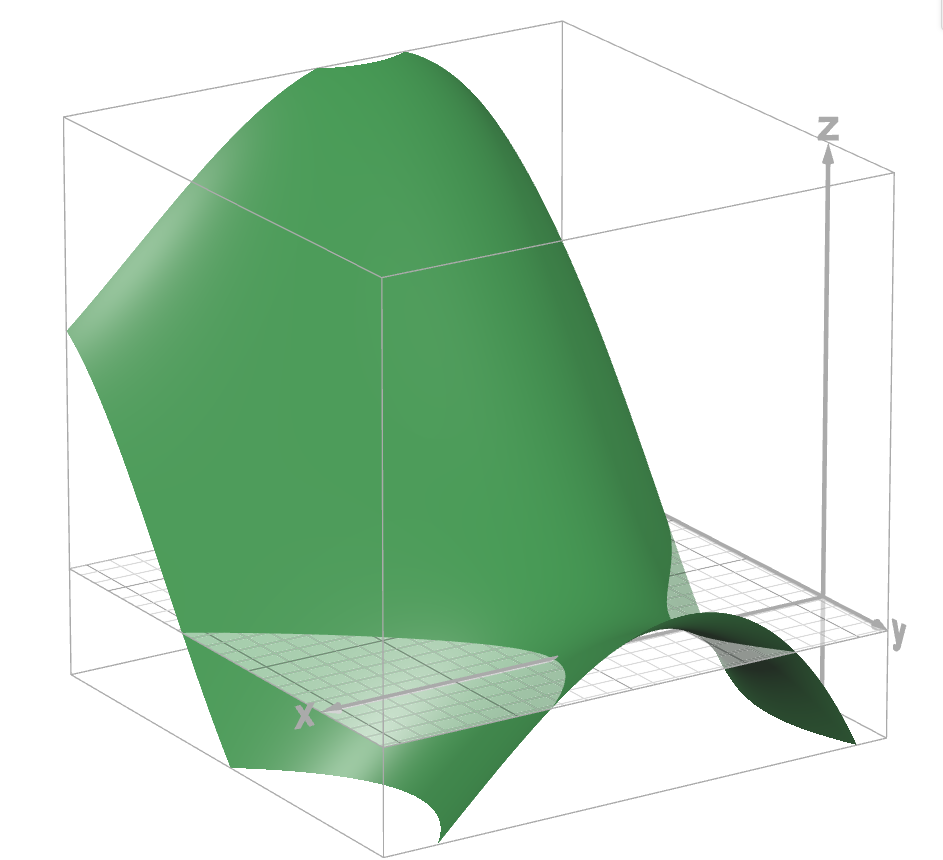
图5.2 z = f ( x , y ) z=f(x,y) z=f(x,y)
在曲面上的一个点向另一个点移动,方向导数表示一个方向下的变化率。对于某一个方向的变化率,设方向为 l ⃗ = ( c o s α , c o s β ) \vec{l}=(cos \alpha,cos \beta) l=(cosα,cosβ), f ( cos α , cos β ) ′ ( x , y ) = lim t → 0 f ( x 0 + t c o s α , y 0 + t c o s β ) − f ( x 0 , y 0 ) t = f ′ ( x , y ) cos α + f ′ ( x , y ) cos β , t = ( Δ x ) 2 + ( Δ y ) 2 f^{'}_{(\cos \alpha,\cos \beta)}(x,y)=\lim_{t\rightarrow 0}\frac{f(x_0+tcos \alpha,y_0+tcos\beta)-f(x_0,y_0)}{t}=f^{'}(x,y)\cos \alpha+f^{'}(x,y)\cos \beta,t=\sqrt{(\Delta x)^2+(\Delta y)^2} f(cosα,cosβ)′(x,y)=limt→0tf(x0+tcosα,y0+tcosβ)−f(x0,y0)=f′(x,y)cosα+f′(x,y)cosβ,t=(Δx)2+(Δy)2是 f ( x , y ) f(x,y) f(x,y)在 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)的方向导数,记作 δ f δ l ⃗ ∣ ( x 0 , y 0 ) \frac{\delta f}{\delta \vec{l}}|_{(x_0,y_0)} δlδf∣(x0,y0)
函数在该点有定义,极限值存在。
对于坐标轴x轴或y轴方向的变化率,为对应的偏导数 δ z δ x 、 δ z δ y \frac{\delta z}{\delta x}、\frac{\delta z}{\delta y} δxδz、δyδz
5.3 梯度
f ( cos α , cos β ) ′ ( x , y ) = ( δ f δ x , δ f δ y ) ( cos α , cos β ) = ∣ δ f δ x , δ f δ y ∣ ⋅ ∣ e ∣ ⋅ cos < ( δ f δ x , δ f δ y ) , e > f^{'}_{(\cos \alpha,\cos \beta)}(x,y)=(\frac{\delta f}{\delta x},\frac{\delta f}{\delta y})(\cos \alpha,\cos \beta)=|\frac{\delta f}{\delta x},\frac{\delta f}{\delta y}|\cdot |e|\cdot \cos<(\frac{\delta f}{\delta x},\frac{\delta f}{\delta y}),e> f(cosα,cosβ)′(x,y)=(δxδf,δyδf)(cosα,cosβ)=∣δxδf,δyδf∣⋅∣e∣⋅cos<(δxδf,δyδf),e>
当 e e e和 ( δ f δ x , δ f δ y ) (\frac{\delta f}{\delta x},\frac{\delta f}{\delta y}) (δxδf,δyδf)方向相同时, f ( cos α , cos β ) ′ ( x , y ) f^{'}_{(\cos \alpha,\cos \beta)}(x,y) f(cosα,cosβ)′(x,y)取得最大值,也就是该方向的变化率达到最大值。
对于某一点而言,其各个方向的导数(变化率)可能是不同的,而对于变化率最大方向,在同等增量的情况下(同等付出),能使得函数值增长达到最大化(收益最大)。
因此,变化率最大的方向对我们是有意义的,向量 ( δ f δ x , δ f δ y ) (\frac{\delta f}{\delta x},\frac{\delta f}{\delta y}) (δxδf,δyδf)的方变化率最大的方向是同向的,所以将 ( δ f δ x , δ f δ y ) (\frac{\delta f}{\delta x},\frac{\delta f}{\delta y}) (δxδf,δyδf)称为梯度,用来记录变化率最大的方向。
梯度是指函数值增长最快的方向。
机器学习/深度学习中,目标是最小化损失函数,因此要找到最低点,所以每次迭代都应该朝梯度的反方向前进(函数值掉得最快),故而叫梯度下降法。
总结
本周对集成学习的概念和AdaBoost、GBDT算法和空间代数进行了学习,由于时间问题,还没有通过梯度去解释GBDT算法,下周将会解开GBDT的疑惑。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)