训练任何人!无需动手制作数据集,一键微调大语言模型。
你需要准备音频数据,这个音频数据可以是主播的闲聊内容,或者你的电话录音。实际上LLM模型就是学习你给的数据,以达到你给定的要求的一个神经网络模型。点开后,可以发现里面已经有了一个音频了,这个是我的一个音频示例,如果你手上没有合适的音频,可以用这个测试。那么,回到我们这里,实际上我想要介绍的项目就是这样的一个功能,它可以训练任何你感兴趣的人物,包括名人、历史人物、动漫角色或电影小说中的虚拟人物。模型
在训练LLM大语言模型的时候,你是不是苦于懊恼数据集的收集?或者在面对一大堆杂乱资料的时候,无从下手?模型训练最累的不是真正的微调,搞参数这些。反而最累的就是制作数据。就好比烧菜的时候,最累的不是炒菜,而且准备食材那部分。没人喜欢这种枯燥的数据制作。但是,这种苦逼的工作又不得不做。
所以,在我从刚开始接触模型训练的时候,就一直在想有没有什么方法可以可以让我逃离这个数据收集的牢笼。后来在和业内工作者聊天的时候发现,不止我一个,大家都很不喜欢自己手动制作数据集。如果是学院内,就直接扔给学生搞,如果在企业里,就让实习生或者给外包去搞。反正自己是一点都不想去做这种工作。
不过,实际上数据制作并不是洪水猛兽。只不过没有找到一个好方法罢了。在我不断的偷懒的思维的思考下。我制作了一个全自动的数据集制作项目。它可以完全不需要你来一点一点的敲字、清洗数据。而且全部交给代码系统。麻烦的事情全都会为你解决。
不知道大家有没有过训练自己的想法?实际上LLM模型就是学习你给的数据,以达到你给定的要求的一个神经网络模型。所以说,只要给定合适的数据,是完全可以训练出一个你自己出来的。我利用自己平时的聊天内容真的训练出了我自己,这种感觉很神奇,发现一个说话和我很像但又有区别的东西。确实很有趣。就像是流浪地球2里面的数字生命一样,一个克隆后的你自己。
国外博主Athene的频道就是在互联网上面收集大量的数据,利用LLM模型来训练各类名人、主播、甚至总统。然后将弹幕的问题来让这些AI来回答,直播采访AI“角色”
链接:
https://www.bilibili.com/video/BV1wg4y1p7AJ?spm_id_from=333.788.recommend_more_video.4&vd_source=dc0e5f82ef841663cb2763adcb8f5ba9
https://www.bilibili.com/video/BV11b411Q7p5?spm_id_from=333.788.recommend_more_video.-1&vd_source=dc0e5f82ef841663cb2763adcb8f5ba9
https://www.bilibili.com/video/BV1p24y1q7A8/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=dc0e5f82ef841663cb2763adcb8f5ba9
被训练的AI都和被训练人十分相似。经常会说出各种语不惊人死不休的内容。非常的有趣。
那么,回到我们这里,实际上我想要介绍的项目就是这样的一个功能,它可以训练任何你感兴趣的人物,包括名人、历史人物、动漫角色或电影小说中的虚拟人物。甚至你自己。而你需要准备的就是——音频
你需要准备音频数据,这个音频数据可以是主播的闲聊内容,或者你的电话录音。或者电台对话音频。总之,只要有人在讲话就行了。举个例子,假设你想要训练一个主播,就下载这个主播的直播音频。你想要训练你自己,就去录制你和别人的通话记录等等。这些音频会被拿去转换,也就是语音转文字。这是第一步。转换后的文字又会被拿去给模型二次加工成有着对话格式的数据。这是第二步。成型的数据被处理好了以后,继续更仔细的转换成可训练数据集。这是第三步。
经过这三步的处理后,你的数据就已经可以用于训练了。而我们要做的就只是收集音频数据,然后上传就行了。理论上来说,只要你上传的音频数据够多。模型就会无限接近于你训练的那一个人。
这就是我今天要着重介绍的开源项目:Chatbot-Trainer
github链接:https://github.com/morettt/Chatbot-Trainer
为了让更多的人可以省去项目配置的繁琐流程。环境依赖模型下载的问题。我制作了一个镜像,大家可以一步一步的跟着我的介绍来使用此项目。
首先前往此链接:https://www.autodl.com/console/instance/list?_random_=1721007118217
这是一个云端服务器,里面有很多便宜的机子可以用于模型训练。所以即使你本地的电脑不支持模型训练也完全没有关系。
链接打开后就是这样,新用户需要注册。
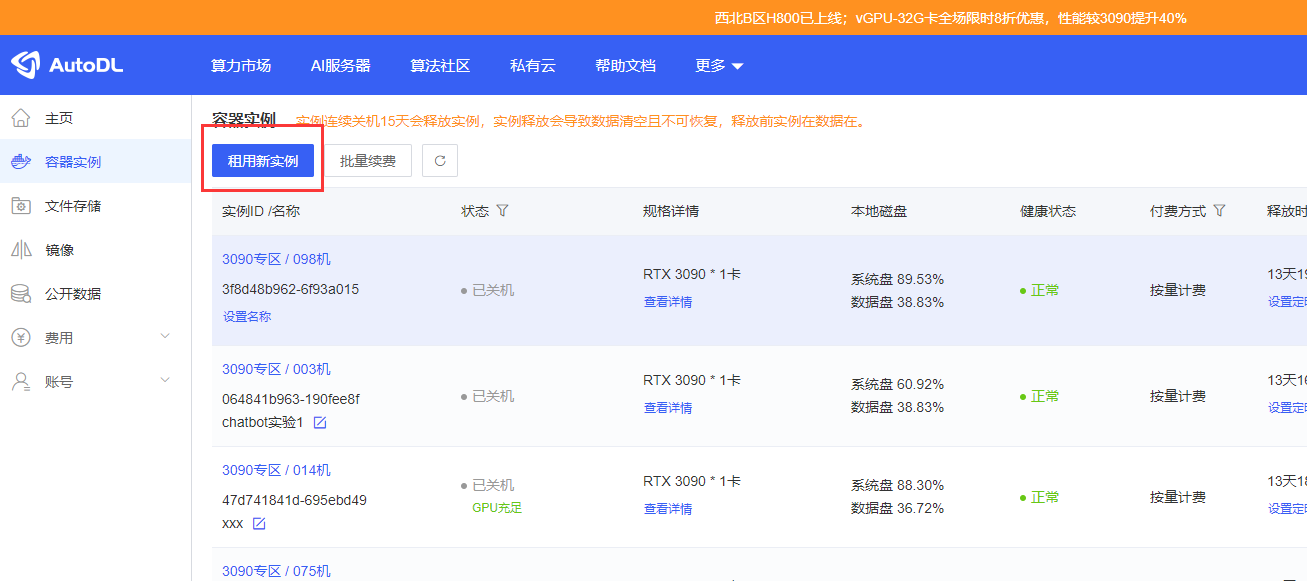
登录或者注册后,你会进入这个界面,不用管别的。我们点击这个租用新实例
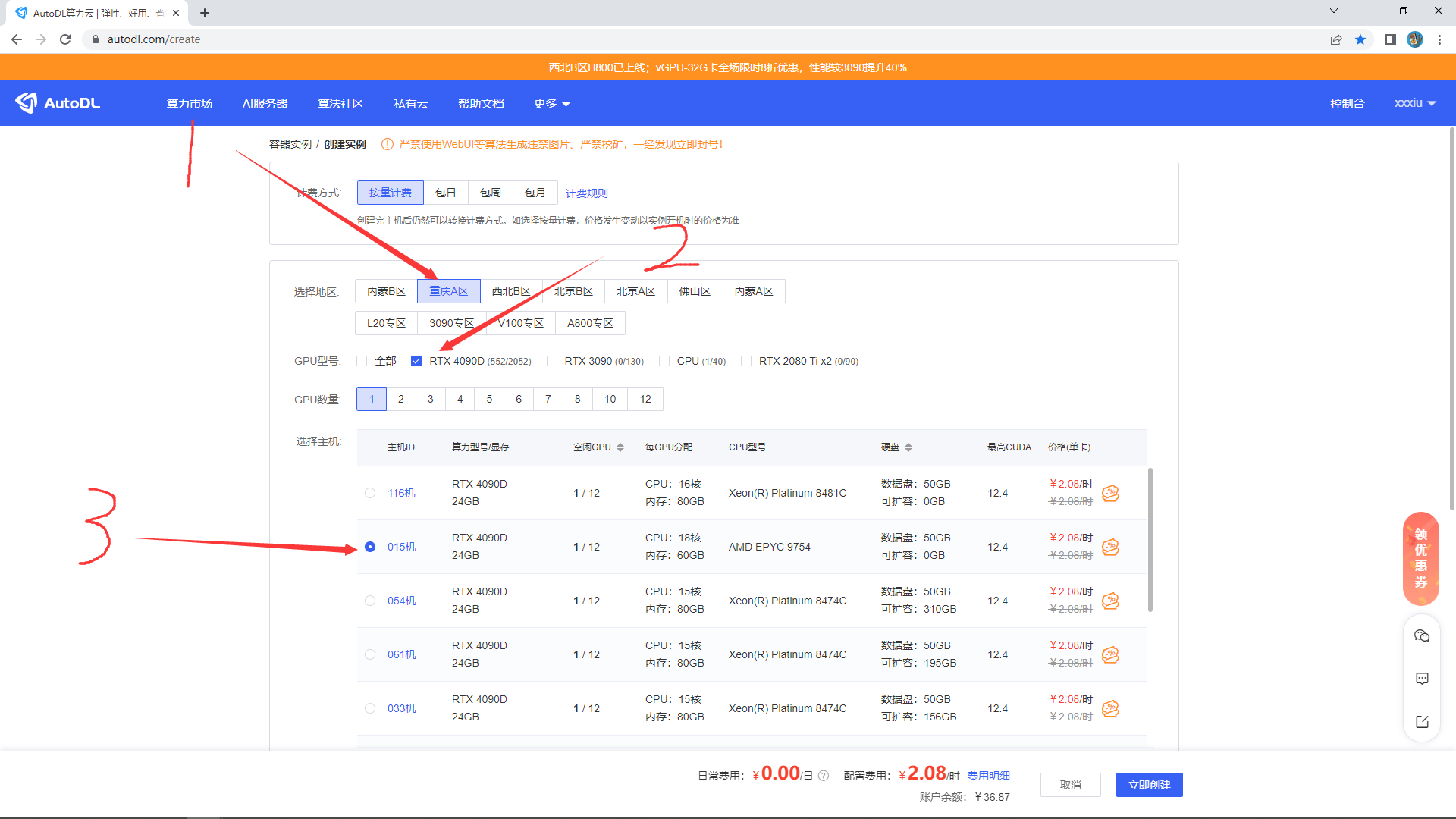
你会进入这样的界面,我推荐选择重庆A区,当然别的地区也可以。显卡可以选择4090D 也可以选择例如L40或者更大显存的显卡。在别的专区里面也有不同的显卡可以选择。
继续往下滑,按照图片的顺序提示选择,最后点击立即创建,如果点击立即创建后提示:该主机已租满,请更换主机重新创建实例。那么就是你当前选择的显卡被别人抢先选择了,可以换个机子,或者刷新一下,重新选一个机子。
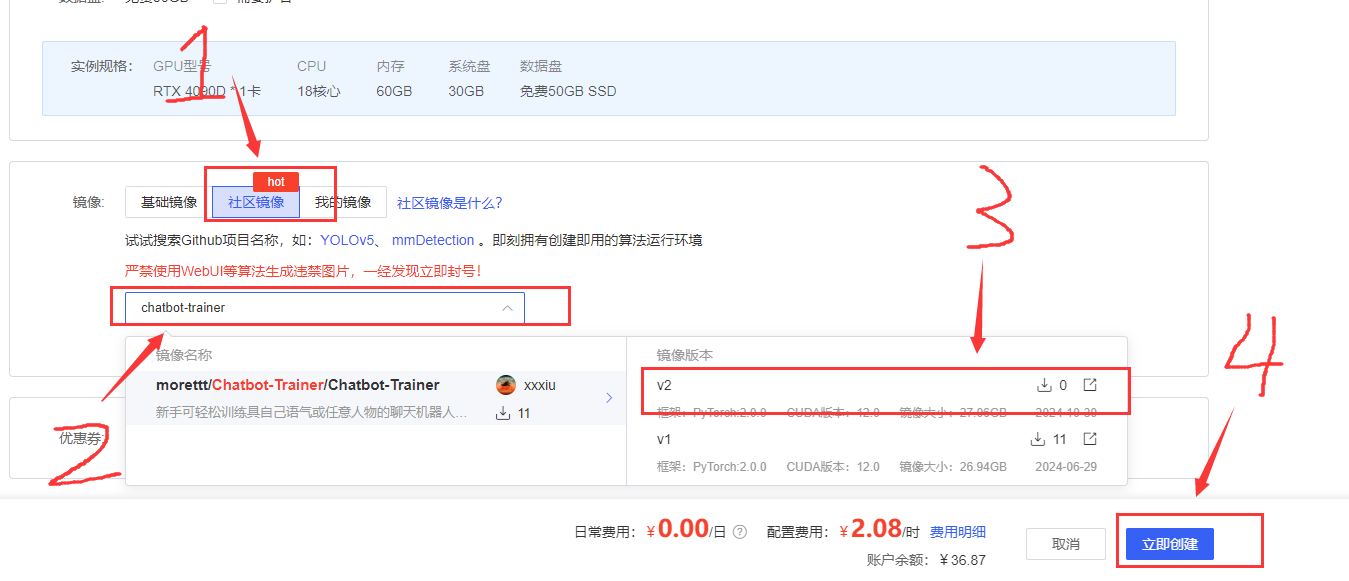
当你点击立即创建后,会直接跳转到这个界面,我们直接点击这个JupyterLab
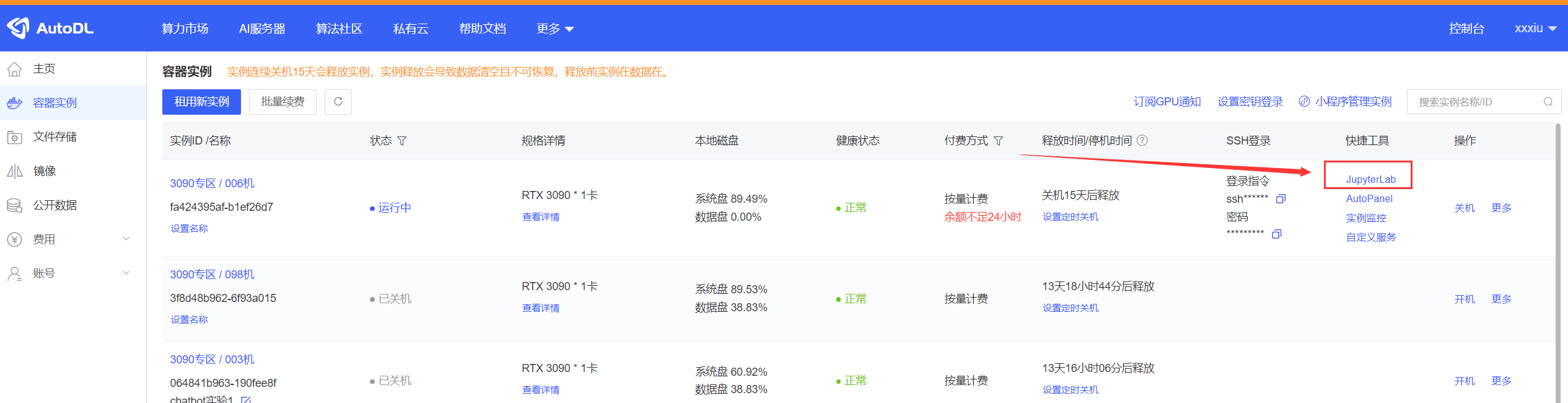
稍等片刻,即可看见如下操作界面:
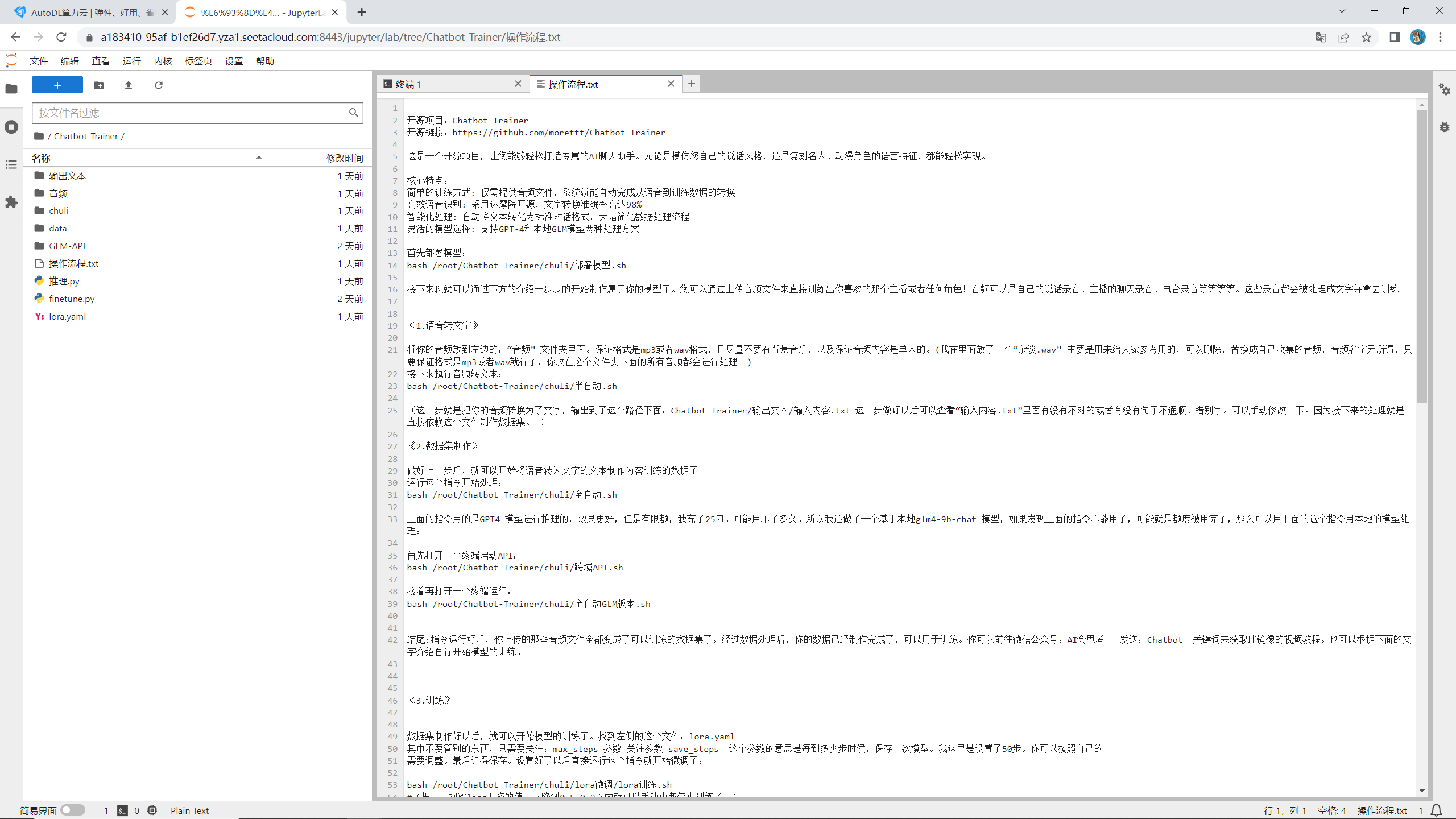
(我已经把所有的具体操作流程都写在了里面。但是如果你不想看那么多多文字讲解,那也可以直接在这里一步一步和我操作,都是一样的。)
第一步,我们复制这个指令:
bash /root/Chatbot-Trainer/chuli/部署模型.sh
然后点击那个终端图标,然后将其输入到终端

这个指令是安装必要的模型。耐心等模型下载,不过不用很久,基本上1分钟以内就可以全部下载好。
模型下载好后,我们开始做第二步。可以看见,左边有一个文件夹,叫做“音频” 这里面就是处理你的音频文件的地方。双击打开这个文件夹。
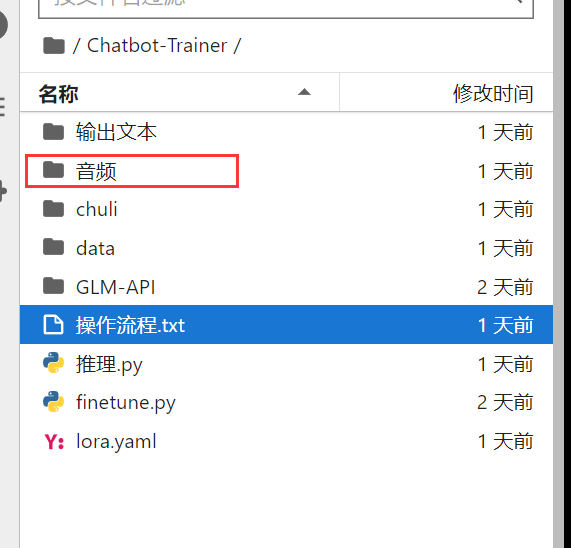
点开后,可以发现里面已经有了一个音频了,这个是我的一个音频示例,如果你手上没有合适的音频,可以用这个测试。如果有的话,你就可以直接删除。用你自己的音频来处理了。音频格式支持wav和mp3格式。音频名字可以不用关心,都能被识别到。
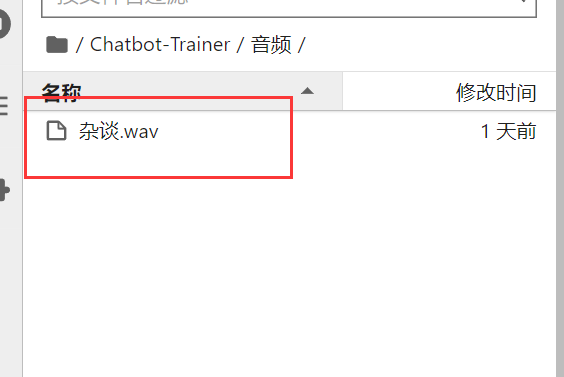
音频的上传也很简单,直接把音频拖到这个文件夹里面就行了。
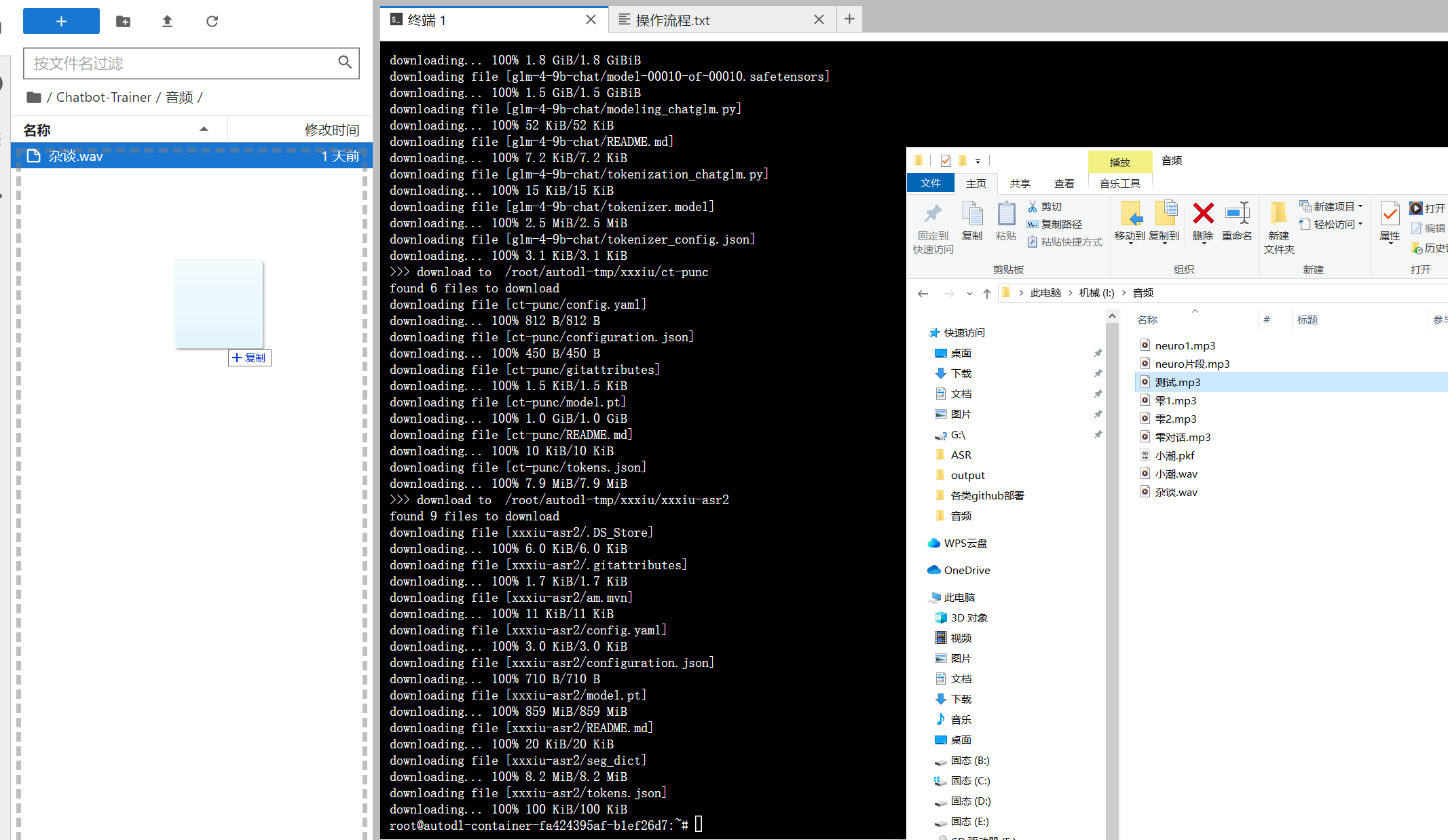
需要注意的是要等待下面的这个进度条加载完了才是音频上传成功了
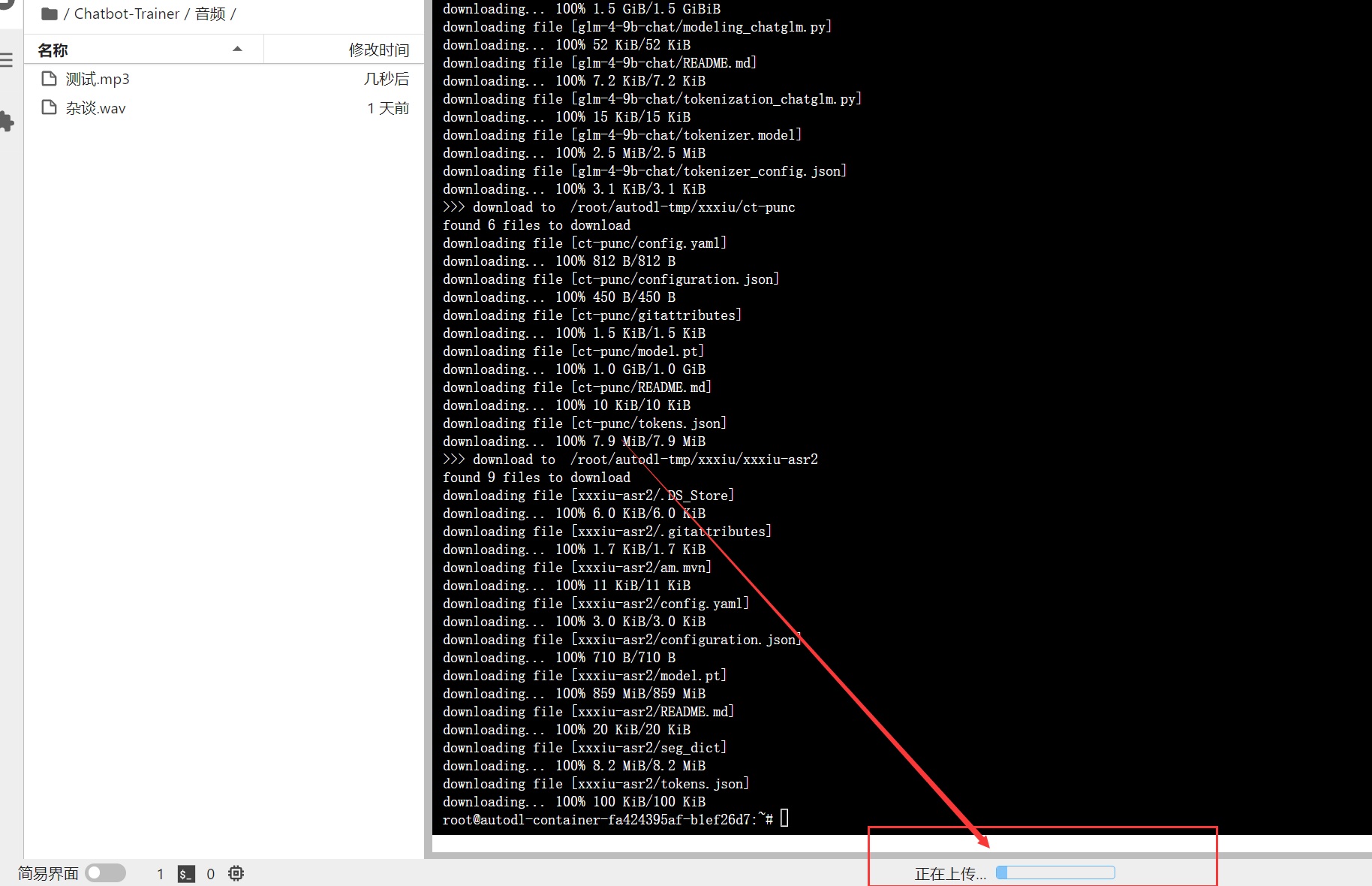
音频上传好了之后,我们在终端运行这个指令开始处理数据:
bash /root/Chatbot-Trainer/chuli/半自动.sh
运行后,系统就会开始为你处理数据了,就像这样:
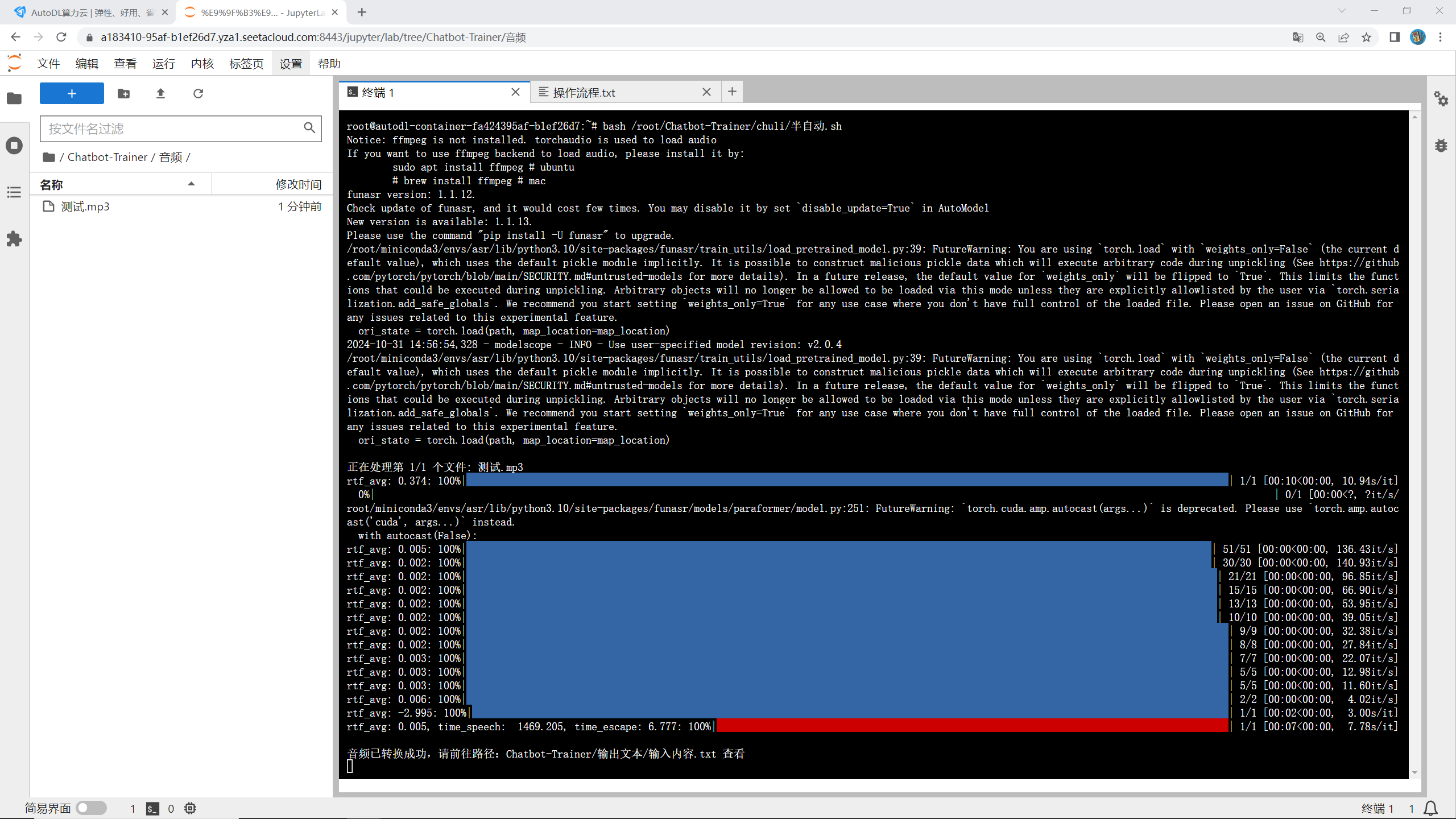
处理好的数据会被保存到这个路径下面:
Chatbot-Trainer/输出文本/输入内容.txt
可以简单的看一下有没有什么错别字或者人名识别不对的,简单的改一改。
这一步做好以后,我们继续运行这个指令:
bash /root/Chatbot-Trainer/chuli/全自动.sh
模型会将你音频转换为文字的内容进一步处理成这种对话的数据,我们需要的就是,耐心等待模型将你的数据全部制作完成。
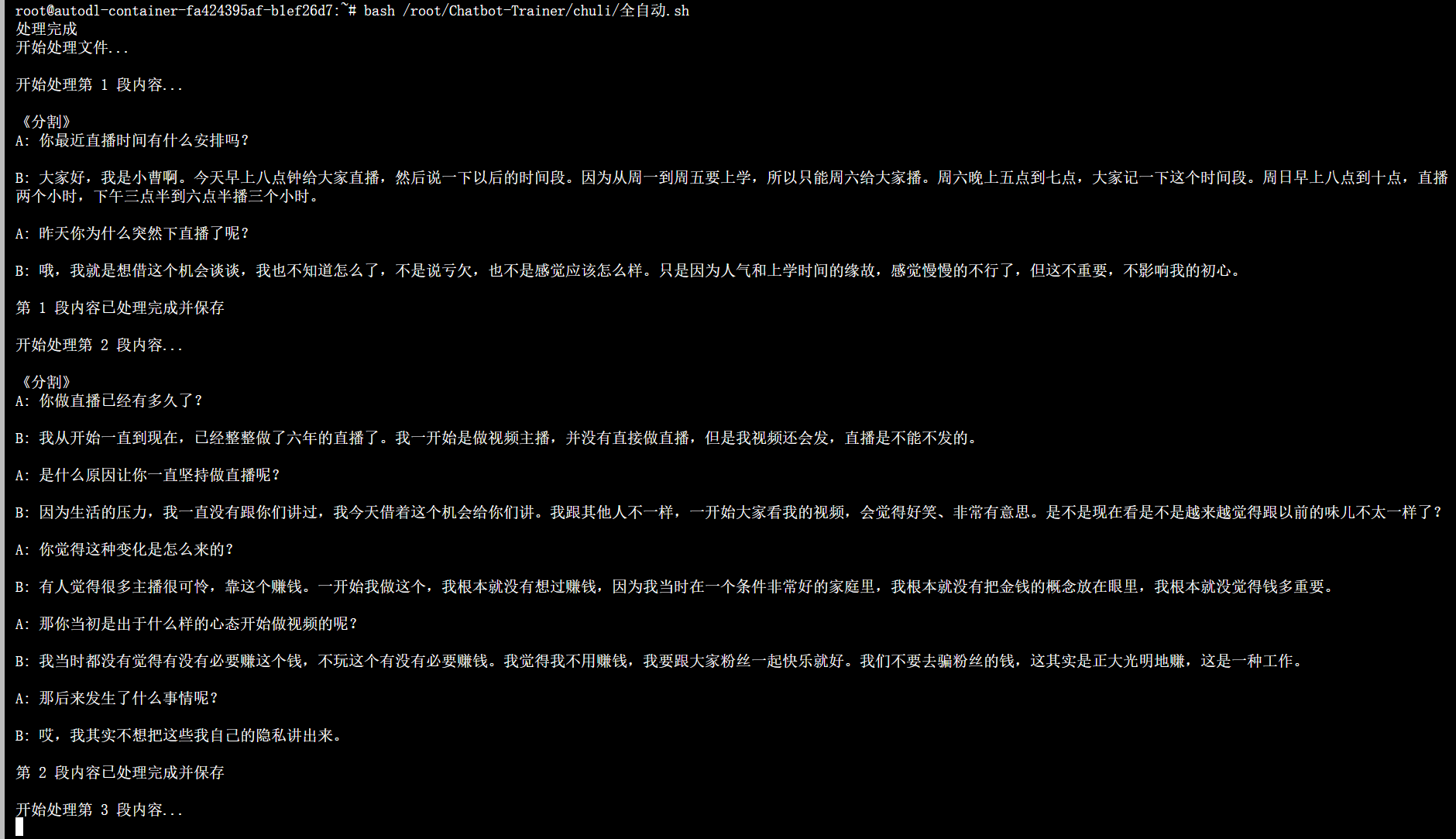
全部处理好以后,会输出这样的内容就代表全部处理完了:

到了这一步,我们的数据就全部处理好了,你现在可以直接开始模型的训练了!我们运行这个指令:
bash /root/Chatbot-Trainer/chuli/lora微调/lora训练.sh
你可以看见模型现在就开始训练了:
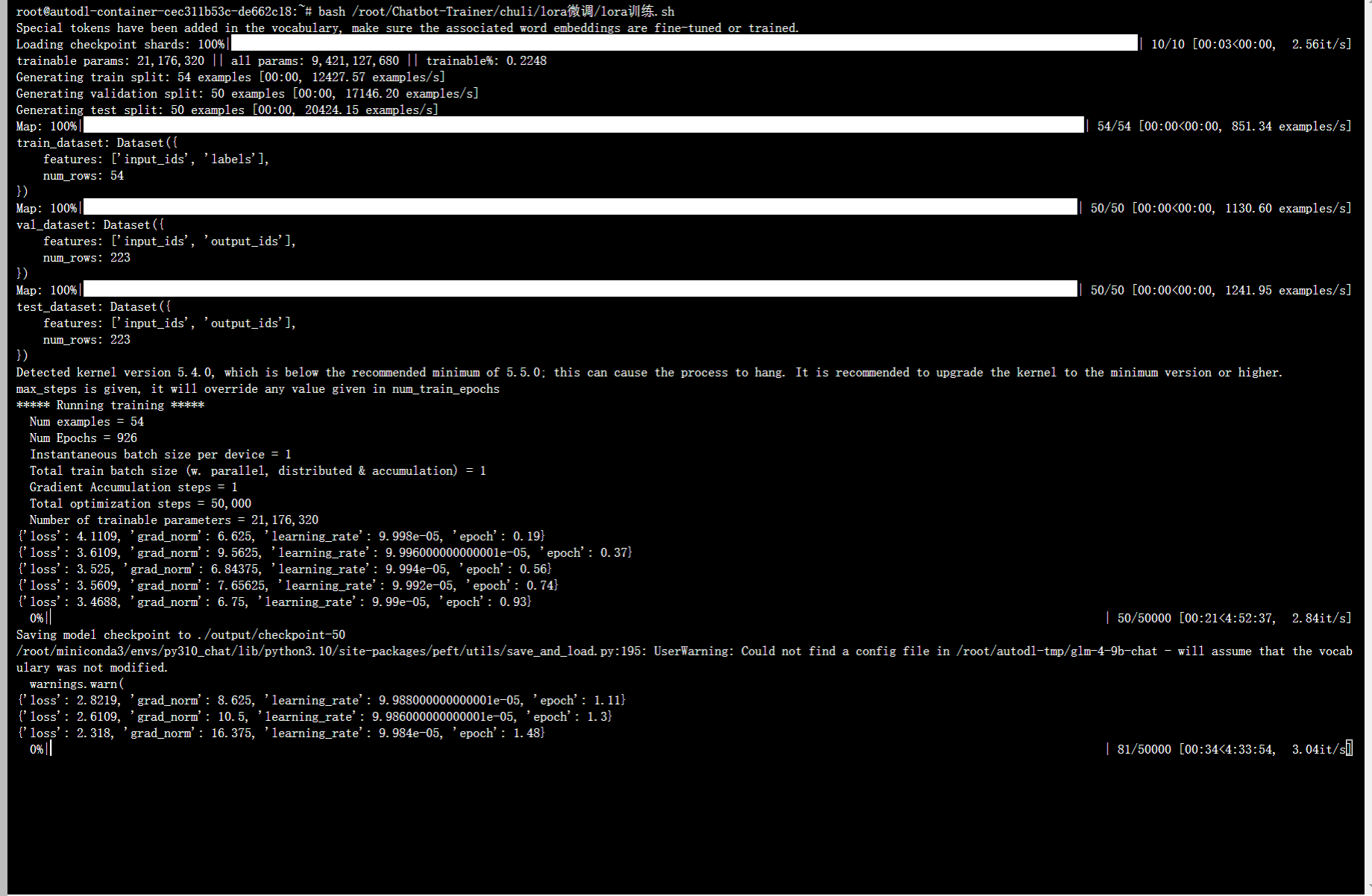
我给的默认设置是每50步保存一次模型。其中你可以观察左边的这个loss
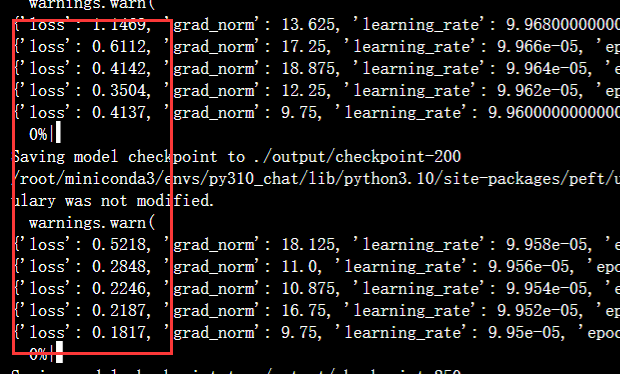
loss会一直下降。我们不用等进度条跑完,只要看见loss已经下降到了0.5~0.9这个范围,就可以手动按住键盘的ctrl+c 键直接停止训练。
保存好的模型会生成到这个路径下面
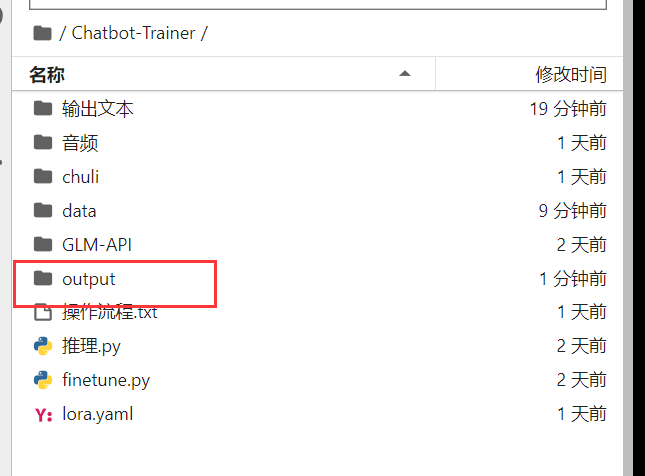
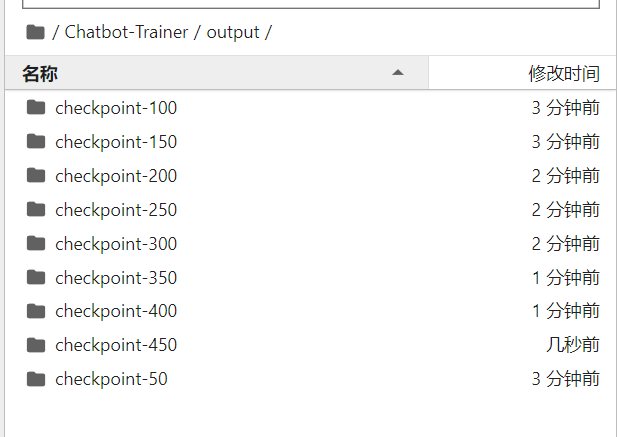
我们选择结尾最大的数字复制它的文件名。例如这里就是 checkpoint-450
然后我们回到这里,打开这个推理.py文件
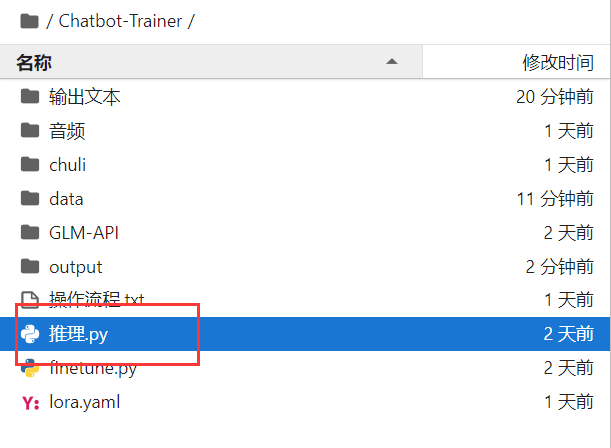
这个代码其余的都不用管,直接看红框标注的地方
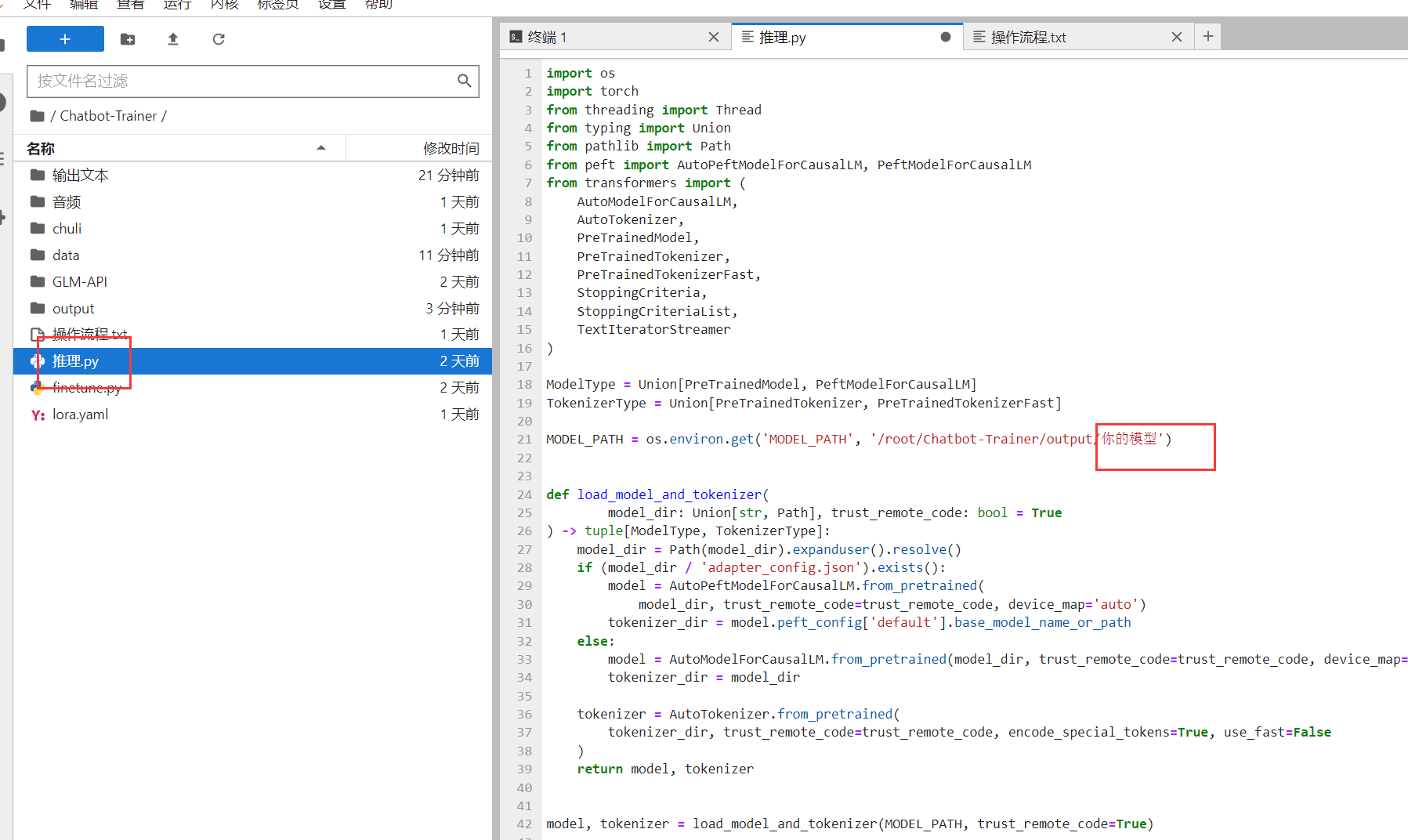
我们把刚刚复制的模型名字粘贴,记得保存。
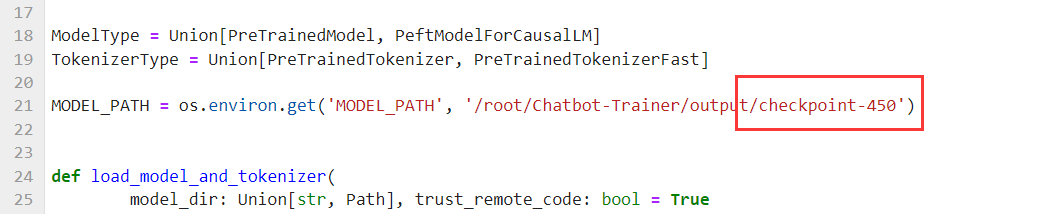
最后,我们就可以推理你训练好的模型了:
bash /root/Chatbot-Trainer/chuli/lora微调/推理.sh
将上面的指令输入到终端,代码会加载你训练好的模型,你可以直接和训练好的模型对话测试,就像这样。
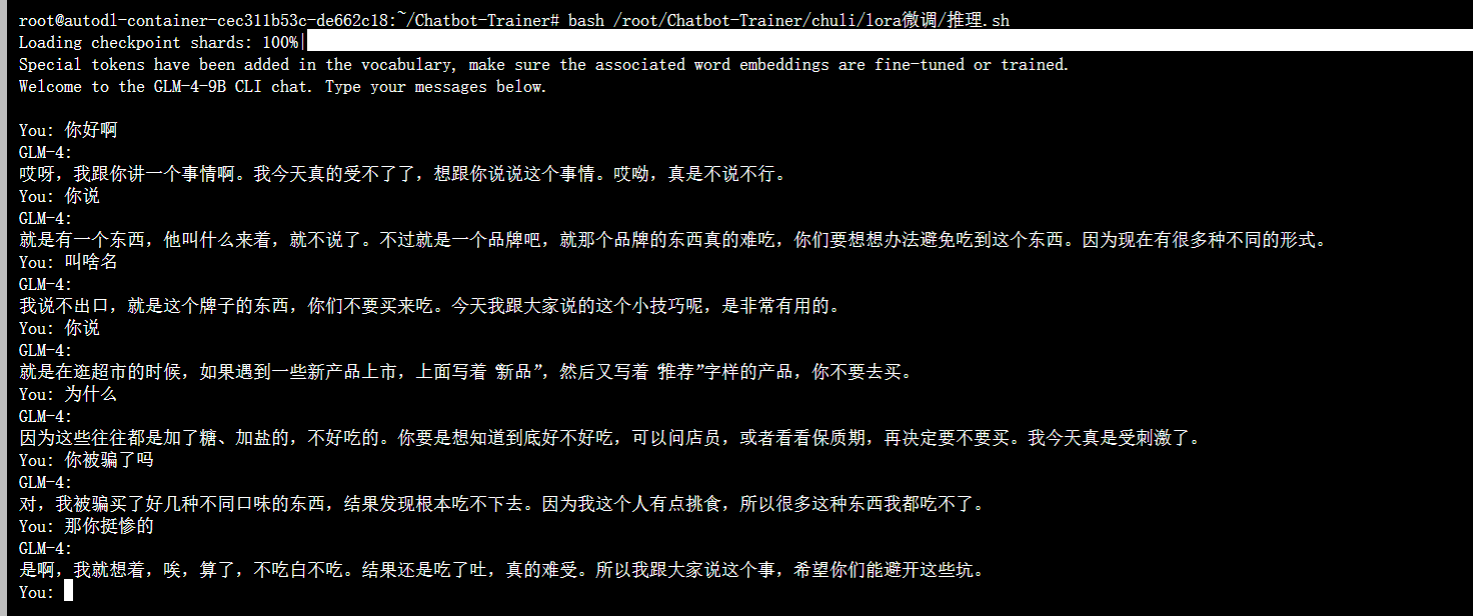
模型已经把音频里面的角色性格给学会了,你和它交流。会发现它说出来的语言风格和音频数据里面的人性格十分的相似。我这里的音频时长只有1小时。但大家可以收集很多的音频进行训练。需要做的就只是上传音频。你也可以训练出属于自己的专属模型。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)