[统计学笔记] (一) 统计学的基本概念
[统计学笔记一] 统计学的基本概念
[统计学笔记] (一) 统计学的基本概念
统计是处理数据的一门科学。统计学是收集、分析、表述和解释数据的科学;统计是一组方法,用来设计实验、获得数据,然后在这些数据的基础上组织、概括、演示、分析、解释和得出结论。
统计学是有效收集、处理、分析和解释数据,发现规律,以便更好决策的一门方法论学科。人们用数据发现规律从而做出更好的决策。要发现规律,对统计数据通常有要求:客观性、适用性、准确性和及时性。
统计学是收集、分析、表述和解释数据的科学。
分析数据的方法有描述统计、推断统计。
- 描述统计(Descriptive Statistics)
① 描述统计是将所收集的数据处理后,用数值、表格或图形形式表现 的有用信息。
② 描述统计是基础,它为推断统计、统计咨询、统计决策提供必要的信息。
- 推断统计(Inferential Statistics)
根据样本数据特征去估计或检验总体的数据特征。
数据分析的真正目的是从数据中找出规律,从数据中寻找启发,而不是寻找支持。真正的数据分析事先是没有结论的,通过数据的分析才能得出结论。
统计学是如何解决实际问题的?
统计学解决实际问题的基本思路是:
① 提出与统计有关的实际问题;
② 建立有效的指标体系;
③ 收集数据;
④ 选用或创造有效的统计方法处理、显示所收集数据的特征;
⑤ 根据所收集数据的特征、结合定性、定量知识作出总体特征的合理推断;
⑥ 根据推断给出更好决策的建议;
在解决问题时,重复第②-⑥步。
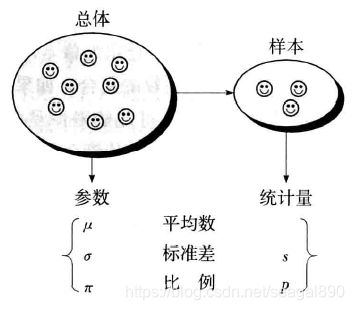
统计学中几个基本概念
总体、单位和样本
总体(Population)是包含所研究的全部个体(数据)的集合,它通常由所研究的一些个体组成。总体根据其所包含的单位数据是否可数分为有限总体和无限总体。有限总体是指总体的范围能够明确确定,而且元素是有限可数的。例如:由若干个企业构成的总体就是有限总体,一批待检测的电池也是有限总体。无限总体是指总体所包含的元素是无限的、不可数的。例如:在科学实验中,每个实验数据可以看做总体的一个元素,而实验则可以无限地进行下去,因此由实验数据构成的总体就是一个无限总体。
样本(sample)是从总体中抽取的一部分元素的集合,构成样本的元素的数组称为样本量(sample size)。抽样的目的是根据样本提供的信息推断总体的特征。
- 总体:统计总体是根据一定目的确定的,由客观存在的、具有某种同质性的许多个别事物构成的整体。
(1)同质性是确定统计总体的基本标准,它是根据统计的研究目的而定的。研究目的不同,所确定的总体也不同,其同质性的意义也随之变化。
(2)统计总体还应具备大量性,即统计总体应应该由足够数量的同质性单位构成。
- 总体单位(简称单位)是组成总体的各个个体。
- 样本:由总体的部分单位组成的集合称为样本(又称子样)。构成样本的单位称为样品,样本中样品的数目称为样本容量。
统计学解决问题的目的是认识总体的数据特征。但是,当调查是破坏性的,或者出于成本、时间等因素考虑时,不必要或不可能对构成总体的所有单位都进行调查。
标志、指标(参数)和统计量
- 标志:总体单位普遍具有的属性或特征称为标志。标志按其表现分为品质标志和数量标志两种。
① 品质标志表明单位属性方面的特征,品质标志的表现只能用非数值来描述。 例如商品的类别;居民的性别等。
② 数量标志表明单位数量方面的特征,其表现用数值来描述。例如:商品的价格,销量;居民的收入等。
- 参数(标志):统计总体具有的数量特征的概念和数值称为统计指标,也称为参数。统计指标由两项基本要素构成,即指标的概念和指标的取值。指标的概念是对所研究现象本质的抽象概括,也是对总体数量特征的质的规定性。例如:居民人口数1000万人,总收入600亿元。
统计指标按表示形式可以分为数量指标和质量指标。
① 凡是反映现象总规模、总水平的统计指标称为数量指标,用绝对数来表示。例如居民总数1000万人、总收入600亿元等。
② 凡是反映现象相对水平和工作质量的统计指标称为质量指标,用相对数或平均数来表示.例如企业职工平均工资5000元、工人出勤率93%等。质量指标是总量指标的派生指标,以反映现象之间的内在联系和对比关系。
单个指标不能反映总体的全貌,这便需要设立指标体系。统计指标体系是由一系列相互联系的统计指标组成的有机整体,用以反映所研究现象各方面相互依存相互制约的关系。
- 统计量(statistics)
统计量是样本观测量的一个已知函数,用来说明样本的特征。是样本观测量的一个已知函数,用来说明样本的特征。
统计量是用来描述样本特征的概括性数字度量。
抽取的样本不同,统计量的观测值也就不同。如样本平均数、样本方差、样本比例是统计量,抽取样本后,人们通常用与总体参数对应的统计量观测值, 作为总体参数的估计。(如某汽车制造企业从生产的一批轿车中抽取了16辆轿车,用这些轿车的平均行驶里程值、合格率值分别作为该批轿车平均行驶里程、合格率的估计。)
数据
变量与变量值
1. 即说明现象的某一事实或数量的特征称为变量,将上述标志、指标和统计量的名称进行归纳就是变量。
2. 变量的具体表现是变量值,数据就是变量及其表现,也可称为反映客观事物的事实或数量依据。
例如:收入是一个变量,收入的表现是变量值。
3. 将在特定研究过程中收集的所有数据集合在一起,称为数据集。
4. 根据变量值的确定与否,变量分为确定性变量(受确定性因素影响,因素是明确的,可解释,可控制的)与随机变量(受许多不确定因素影响,如员工的起床时间)。
变量类型
分类变量、顺序变量、数值型变量
数值型变量根据其取值的不同,又可以分为离散型变量和连续型变量。离散型变量是只能取可数值的变量,它只能取有限个值,而且其取值都以整数位断开,可以一一列举。连续型变量是可以在一个或多个区间中取任何值的变量,它的取值是连续不断的,不能一一列举。
数据的计量尺度
收集数据时需要用到以下四种由低到高的计量尺度:定类尺度、定序尺度、定距尺度和定比尺度,计量尺度的不同决定了不同的数据分析与处理方法。
1. 定类尺度是说明客观现象无序类别的计量。定类尺度的主要数学特征是“=”或“≠”.如居民的性别是男、女计量,战机的类型是战斗机、轰炸机、侦察机等计量,这一场合的所使用的数值只作为无序分类的代码。
2. 定序尺度是说明客观现象有序类别的非数值计量。定序尺度的主要数学特征是“<”或“>”.例如,对居民的满意度计量可以分为非常满意、满意、一般、不满意、非常不满意五类。这一场合的所使用的数值只作为有序分类的代码。
3. 定距尺度是说明客观现象数值间距有意义的计量。其用确切的数值反映现象之间在量方面的差异,定距尺度的主要数学特征是“+”“–” 。如总量指标是定距尺度计量的。
(0不代表不存在)
4. 定比尺度是说明客观现象两个数值比有意义的计量。定比尺度的主要数学特征是“x”“/”
如质量指标中的相对数、平均数是定比尺度计量的(0代表不存在)
5 数据分类
(1)定类尺度,定序尺度的数据统称为定性数据。定性变量是指带有定性数据的变量。
(2)定距尺度,定比尺度的数据统称为为定量数据。定量变量是指带有定量数据的变量。
根据定量变量值连续出现与否,定量变量分为连续性变量与离散型变量。
①连续型变量是指变量在某一区域内的取值是连续不断的,无法一一列举。如:军机的弹孔位置,产品的寿命等。
②离散型变量是指变量的取值是间断的,可以一一列举。例如,产品数等。
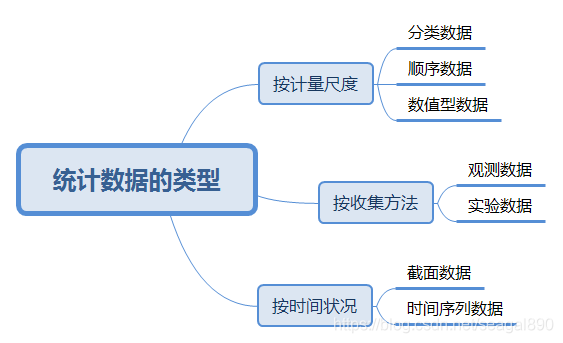
统计数据的类型
按照所采取的计量尺度的不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
| 统计数据的类型 | 说明 | 举例 |
|---|---|---|
| 分类数据 | 只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的。 | 例如:人口按照性别分类为男人、女人。 |
| 顺序数据 | 只能归于某一有序类别的非数字型数据。顺序数据虽然也是类别,但是这些类别是有序的。 | 例如:将产品分为一等品、二等品、三等品等、次品等。 |
| 数值型数据 | 按数字尺度侧脸的观察值,其结果表现为具体的数值。 |
数据统计的尺度有四种:
- 分类尺度
- 顺序尺度
- 间隔尺度
- 比率尺度
观测数据和试验数据
观测数据是通过调查或观测收集到的数据。
实验数据是在实验中控制实验对象而收集到的数据。
截面数据和时间序列数据
截面数据是在相同或近似相同的时间点上收集的数据,这类数据通常是在不同的空间获得的,用于描述现象在某一时刻的变化情况。
时间序列数据是在不同时间收集到的数据,这类数据是按时间顺序收集到的,用户描述现象随时间变化的情况。
为什么需要区分数据类型?
因为对于不同类型的数据需要采用不同的统计方法来处理。
例如:对于分类数据,我们通常计算出各组的频数或频率,计算其众数和异众比率,进行列联表分析和
检验等;对于顺序数据,可以计算其中位数和四分位差,计算等级相关系数等;对于数值型数据,可以用更多的统计方法进行分析,如计算各种统计量,进行参数估计和检验等。
根据对客观现象观察的角度不同,统计数据可分为:横截面数据、时间序列数据和面板数据。
1、 横截面数据又称为静态数据,它是指在同一时间对同一总体内不同单位进行观察而获得的数据。例如,2014年全国各省、市、自治区的居民收入总值就属于横截面数据。
2、 时间序列数据又称为动态数据,它是指在某一段时期内按时间顺序对同一总体进行观察而获得的数据。例如,“十二五”期间我国按年份顺序的居民收入总值就属于时间序列数据。
3、 面板数据则是同时在时间和截面空间上取得的二维数据。例如2005-2014年30个企业的总产值数据。面板数据则由30个企业10年的数据组成,共有300个观测值。从某一年份看,它是由30个企业总产值数。
思考题
1. 什么是统计学?
统计学是搜集 、处理、分析、解释数据并从中得出结论的科学。
2. 解释描述统计与推断统计。
描述统计研究的是数据搜集 、处理、汇总、图表描述、概括与分析等统计方法。推断统计研究的是如何利用样本数据来推断总体特征的统计方法。
3. 统计数据可分为哪几种类型?不同类型的数据各有什么特点?
按照计量尺度可分为分类数据、顺序数据和数值型数据;按照数据的搜集 方法,可以分为观测数据和试验数据;按照被描述的现象与实践的关系,可以分为截面数据和时间序列数据。
4. 解释分类数据、顺序数据和数值型数据的含义。
分类数据是只能归于某一类别的非数字型数据;顺序数据是只能归于某一有序类别的非数字型数据;数值型数据是按照数字尺度测量的观测值,其结果表现为具体的数值。
5. 举例说明总体、样本、参数、统计量、变量这几个概念。
总体是包含所研究的全部个体的集合,样本是从总体中抽取的一部分元素的集合,参数是用来描述总体特征的概括性数字度量,统计量是用来描述样本特征的概括性数字度量,变量是用来说明现象某种特征的概念。
6. 变量可分为哪几类?
变量可分为分类变量、顺序变量和数值型变量。分类变量是说明数据类别的一个名称,其取值为分类数据;顺序变量是说明有序类别的一个名称,其取值是顺序数据;数值型变量是说明事物数字特征的一个名称,其取值是数值型数据。
7. 举例说明离散型变量和连续型变量。
离散型变量是只能去可数值的变量,它只能取有限个值,而且其取值都以整位数断开,如“产品数量”;连续性变量是可以在一个或多个区间中取任何值的变量,它的取值是连续不断的,不能一一列举,如“温度”等。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)