Maskformer图像分割微调/Maskformer微调
本文详细介绍了如何基于MMDetection框架对MaskFormer全景分割模型进行微调的完整流程。首先说明了使用MaskFormer-R50模型进行全景图分割的需求,然后从环境配置、数据集准备、模型微调到推理测试的各个环节进行了细致讲解
最近在做一个项目需要实现对全景图进行分割的功能,最终选用了maskformer架构和对应的分割模型maskformer_r50_ms-16xb1-75e_coco。查了很多资料,发现网上很少有对maskformer进行微调的帖子,所以写一篇整个微调和推理历程给大家看看有没有帮助,也有一些踩过的坑,一起贴出来共享讨论。
前期准备
整个工程使用的maskformer架构都是mmdetection框架下的,包括推理和微调。官方网站一些介绍和官方文档还是有价值的,比如“训练 & 测试”中的“学习配置文件”、“数据集准备”等,有时间的话可以看一下:
mmdetection官方网站:mmdetection/README_zh-CN.md at main · open-mmlab/mmdetection · GitHub
对应官方文档:
概述 — MMDetection 3.3.0 文档
maskformer_r50_ms-16xb1-75e_coco模型是Panoptic Segmentation下的MaskFormer,点进去可以下载pth模型和config配置文件(不单独下也没事,mmdetection源码中都有)。
这里先介绍一下,使用mmdetection框架进行推理和微调,除了模型本身pth权重文件,还需要模型对应的配置文件maskformer_r50_ms-16xb1-75e_coco.py和数据集配置文件coco_panoptic.py,还有一个default_runtime.py
实现过程
1. 首先下载mmdetection官方源码GitHub - open-mmlab/mmdetection: OpenMMLab Detection Toolbox and Benchmark
2. 环境创建和依赖安装:
①先创建conda环境
②安装cuda版本的torch,才能在微调的时候使用显卡,否则速度很慢:
I. 首先看一下是不是cpu版本的torch,
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.version.cuda)"如果出现 “2.7.1+cpu ”则是cpu,卸载cpu版本 (刚建起来环境可能啥也没有,直接跳卸载这一步)
pip uninstall mmcv -y
II. 在conda里安装对应版本的torch、cuda、mmcv,注意三者要保持版本号对应,因为后续需要与mmcv版本对其,否则会报各种奇怪的错;这里建议使用“torch1.13.1 + cu11.6 + mmcv2.1.0",具体可以去https://mmcv.readthedocs.io/en/latest/get_started/installation.html网站查找mmcv对应的cuda和torch版本(滑动滚动条在网页界面中间部分)的安装命令,安装mmcv能用的版本(具体可以参考https://blog.csdn.net/Xiao_Ya__/article/details/143200728安装)
torch1.13.1 + cu11.6 + mmcv2.1.0安装命令如下:
卸载旧版本cuda和torch:
pip uninstall torch torchvision torchaudio -y
安装torch11.3.1和cu11.6:
torchaudio==0.13.1 -f https://download.pytorch.org/whl/torch_stable.html
安装mmcv2.1.0:
pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cu116/torch1.13/index.html
再次使用 python -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.version.cuda)"验证,即可看到已有cuda版本号,
使用 python -c "import mmcv; print(mmcv.__version__)" --查看mmcv版本
注:如果后续推理或微调出现报numpy的错误,是因为新numpy版本和老模块不兼容,直接降级numpy即可:pip install numpy==1.26.4(可能会出现一些警告,忽略即可)
补充:
python -c "import mmcv; print(mmcv.__version__)" --查看mmcv版本
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.version.cuda)" --查看torch和cuda的版本号
python -c "import numpy; print(numpy.__version__)" --查看numpy版本号
3. 构建自己的数据集:
使用labelme进行自定义图像的标注,使用自己写的转换代码将label生成的JSON文件转为coco_panoptic数据集格式(适用于133类微调)
①先了解COCO Panoptic 数据集:http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip 下载完后解压,并解压内部的所有zip文件,最后文件夹目录结构为:

②使用labelme标注自己的图片:
conda中打开labelme,设置好“更改输出路径”;
拖动需要标注的照片到labelme中,或者直接打开文件夹;
使用AI多边形或者创建多边形进行标注,注意label类别名称要与coco_panoptic数据集中"name"一致,比如天空要写“sky-other-merged”,具体133类如下:
{"supercategory": "person", "isthing": 1, "id": 1, "name": "person"},
{"supercategory": "vehicle", "isthing": 1, "id": 2, "name": "bicycle"},
{"supercategory": "vehicle", "isthing": 1, "id": 3, "name": "car"},
{"supercategory": "vehicle", "isthing": 1, "id": 4, "name": "motorcycle"},
{"supercategory": "vehicle", "isthing": 1, "id": 5, "name": "airplane"},
{"supercategory": "vehicle", "isthing": 1, "id": 6, "name": "bus"},
{"supercategory": "vehicle", "isthing": 1, "id": 7, "name": "train"},
{"supercategory": "vehicle", "isthing": 1, "id": 8, "name": "truck"},
{"supercategory": "vehicle", "isthing": 1, "id": 9, "name": "boat"},
{"supercategory": "outdoor", "isthing": 1, "id": 10, "name": "traffic light"},
{"supercategory": "outdoor", "isthing": 1, "id": 11, "name": "fire hydrant"},
{"supercategory": "outdoor", "isthing": 1, "id": 13, "name": "stop sign"},
{"supercategory": "outdoor", "isthing": 1, "id": 14, "name": "parking meter"},
{"supercategory": "outdoor", "isthing": 1, "id": 15, "name": "bench"},
{"supercategory": "animal", "isthing": 1, "id": 16, "name": "bird"},
{"supercategory": "animal", "isthing": 1, "id": 17, "name": "cat"},
{"supercategory": "animal", "isthing": 1, "id": 18, "name": "dog"},
{"supercategory": "animal", "isthing": 1, "id": 19, "name": "horse"},
{"supercategory": "animal", "isthing": 1, "id": 20, "name": "sheep"},
{"supercategory": "animal", "isthing": 1, "id": 21, "name": "cow"},
{"supercategory": "animal", "isthing": 1, "id": 22, "name": "elephant"},
{"supercategory": "animal", "isthing": 1, "id": 23, "name": "bear"},
{"supercategory": "animal", "isthing": 1, "id": 24, "name": "zebra"},
{"supercategory": "animal", "isthing": 1, "id": 25, "name": "giraffe"},
{"supercategory": "accessory", "isthing": 1, "id": 27, "name": "backpack"},
{"supercategory": "accessory", "isthing": 1, "id": 28, "name": "umbrella"},
{"supercategory": "accessory", "isthing": 1, "id": 31, "name": "handbag"},
{"supercategory": "accessory", "isthing": 1, "id": 32, "name": "tie"},
{"supercategory": "accessory", "isthing": 1, "id": 33, "name": "suitcase"},
{"supercategory": "sports", "isthing": 1, "id": 34, "name": "frisbee"},
{"supercategory": "sports", "isthing": 1, "id": 35, "name": "skis"},
{"supercategory": "sports", "isthing": 1, "id": 36, "name": "snowboard"},
{"supercategory": "sports", "isthing": 1, "id": 37, "name": "sports ball"},
{"supercategory": "sports", "isthing": 1, "id": 38, "name": "kite"},
{"supercategory": "sports", "isthing": 1, "id": 39, "name": "baseball bat"},
{"supercategory": "sports", "isthing": 1, "id": 40, "name": "baseball glove"},
{"supercategory": "sports", "isthing": 1, "id": 41, "name": "skateboard"},
{"supercategory": "sports", "isthing": 1, "id": 42, "name": "surfboard"},
{"supercategory": "sports", "isthing": 1, "id": 43, "name": "tennis racket"},
{"supercategory": "kitchen", "isthing": 1, "id": 44, "name": "bottle"},
{"supercategory": "kitchen", "isthing": 1, "id": 46, "name": "wine glass"},
{"supercategory": "kitchen", "isthing": 1, "id": 47, "name": "cup"},
{"supercategory": "kitchen", "isthing": 1, "id": 48, "name": "fork"},
{"supercategory": "kitchen", "isthing": 1, "id": 49, "name": "knife"},
{"supercategory": "kitchen", "isthing": 1, "id": 50, "name": "spoon"},
{"supercategory": "kitchen", "isthing": 1, "id": 51, "name": "bowl"},
{"supercategory": "food", "isthing": 1, "id": 52, "name": "banana"},
{"supercategory": "food", "isthing": 1, "id": 53, "name": "apple"},
{"supercategory": "food", "isthing": 1, "id": 54, "name": "sandwich"},
{"supercategory": "food", "isthing": 1, "id": 55, "name": "orange"},
{"supercategory": "food", "isthing": 1, "id": 56, "name": "broccoli"},
{"supercategory": "food", "isthing": 1, "id": 57, "name": "carrot"},
{"supercategory": "food", "isthing": 1, "id": 58, "name": "hot dog"},
{"supercategory": "food", "isthing": 1, "id": 59, "name": "pizza"},
{"supercategory": "food", "isthing": 1, "id": 60, "name": "donut"},
{"supercategory": "food", "isthing": 1, "id": 61, "name": "cake"},
{"supercategory": "furniture", "isthing": 1, "id": 62, "name": "chair"},
{"supercategory": "furniture", "isthing": 1, "id": 63, "name": "couch"},
{"supercategory": "furniture", "isthing": 1, "id": 64, "name": "potted plant"},
{"supercategory": "furniture", "isthing": 1, "id": 65, "name": "bed"},
{"supercategory": "furniture", "isthing": 1, "id": 67, "name": "dining table"},
{"supercategory": "furniture", "isthing": 1, "id": 70, "name": "toilet"},
{"supercategory": "electronic", "isthing": 1, "id": 72, "name": "tv"},
{"supercategory": "electronic", "isthing": 1, "id": 73, "name": "laptop"},
{"supercategory": "electronic", "isthing": 1, "id": 74, "name": "mouse"},
{"supercategory": "electronic", "isthing": 1, "id": 75, "name": "remote"},
{"supercategory": "electronic", "isthing": 1, "id": 76, "name": "keyboard"},
{"supercategory": "electronic", "isthing": 1, "id": 77, "name": "cell phone"},
{"supercategory": "appliance", "isthing": 1, "id": 78, "name": "microwave"},
{"supercategory": "appliance", "isthing": 1, "id": 79, "name": "oven"},
{"supercategory": "appliance", "isthing": 1, "id": 80, "name": "toaster"},
{"supercategory": "appliance", "isthing": 1, "id": 81, "name": "sink"},
{"supercategory": "appliance", "isthing": 1, "id": 82, "name": "refrigerator"},
{"supercategory": "indoor", "isthing": 1, "id": 84, "name": "book"},
{"supercategory": "indoor", "isthing": 1, "id": 85, "name": "clock"},
{"supercategory": "indoor", "isthing": 1, "id": 86, "name": "vase"},
{"supercategory": "indoor", "isthing": 1, "id": 87, "name": "scissors"},
{"supercategory": "indoor", "isthing": 1, "id": 88, "name": "teddy bear"},
{"supercategory": "indoor", "isthing": 1, "id": 89, "name": "hair drier"},
{"supercategory": "indoor", "isthing": 1, "id": 90, "name": "toothbrush"},
{"supercategory": "textile", "isthing": 0, "id": 92, "name": "banner"},
{"supercategory": "textile", "isthing": 0, "id": 93, "name": "blanket"},
{"supercategory": "building", "isthing": 0, "id": 95, "name": "bridge"},
{"supercategory": "raw-material", "isthing": 0, "id": 100, "name": "cardboard"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 107, "name": "counter"},
{"supercategory": "textile", "isthing": 0, "id": 109, "name": "curtain"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 112, "name": "door-stuff"},
{"supercategory": "floor", "isthing": 0, "id": 118, "name": "floor-wood"},
{"supercategory": "plant", "isthing": 0, "id": 119, "name": "flower"},
{"supercategory": "food-stuff", "isthing": 0, "id": 122, "name": "fruit"},
{"supercategory": "ground", "isthing": 0, "id": 125, "name": "gravel"},
{"supercategory": "building", "isthing": 0, "id": 128, "name": "house"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 130, "name": "light"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 133, "name": "mirror-stuff"},
{"supercategory": "structural", "isthing": 0, "id": 138, "name": "net"},
{"supercategory": "textile", "isthing": 0, "id": 141, "name": "pillow"},
{"supercategory": "ground", "isthing": 0, "id": 144, "name": "platform"},
{"supercategory": "ground", "isthing": 0, "id": 145, "name": "playingfield"},
{"supercategory": "ground", "isthing": 0, "id": 147, "name": "railroad"},
{"supercategory": "water", "isthing": 0, "id": 148, "name": "river"},
{"supercategory": "ground", "isthing": 0, "id": 149, "name": "road"},
{"supercategory": "building", "isthing": 0, "id": 151, "name": "roof"},
{"supercategory": "ground", "isthing": 0, "id": 154, "name": "sand"},
{"supercategory": "water", "isthing": 0, "id": 155, "name": "sea"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 156, "name": "shelf"},
{"supercategory": "ground", "isthing": 0, "id": 159, "name": "snow"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 161, "name": "stairs"},
{"supercategory": "building", "isthing": 0, "id": 166, "name": "tent"},
{"supercategory": "textile", "isthing": 0, "id": 168, "name": "towel"},
{"supercategory": "wall", "isthing": 0, "id": 171, "name": "wall-brick"},
{"supercategory": "wall", "isthing": 0, "id": 175, "name": "wall-stone"},
{"supercategory": "wall", "isthing": 0, "id": 176, "name": "wall-tile"},
{"supercategory": "wall", "isthing": 0, "id": 177, "name": "wall-wood"},
{"supercategory": "water", "isthing": 0, "id": 178, "name": "water-other"},
{"supercategory": "window", "isthing": 0, "id": 180, "name": "window-blind"},
{"supercategory": "window", "isthing": 0, "id": 181, "name": "window-other"},
{"supercategory": "plant", "isthing": 0, "id": 184, "name": "tree-merged"},
{"supercategory": "structural", "isthing": 0, "id": 185, "name": "fence-merged"},
{"supercategory": "ceiling", "isthing": 0, "id": 186, "name": "ceiling-merged"},
{"supercategory": "sky", "isthing": 0, "id": 187, "name": "sky-other-merged"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 188, "name": "cabinet-merged"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 189, "name": "table-merged"},
{"supercategory": "floor", "isthing": 0, "id": 190, "name": "floor-other-merged"},
{"supercategory": "ground", "isthing": 0, "id": 191, "name": "pavement-merged"},
{"supercategory": "solid", "isthing": 0, "id": 192, "name": "mountain-merged"},
{"supercategory": "plant", "isthing": 0, "id": 193, "name": "grass-merged"},
{"supercategory": "ground", "isthing": 0, "id": 194, "name": "dirt-merged"},
{"supercategory": "raw-material", "isthing": 0, "id": 195, "name": "paper-merged"},
{"supercategory": "food-stuff", "isthing": 0, "id": 196, "name": "food-other-merged"},
{"supercategory": "building", "isthing": 0, "id": 197, "name": "building-other-merged"},
{"supercategory": "solid", "isthing": 0, "id": 198, "name": "rock-merged"},
{"supercategory": "wall", "isthing": 0, "id": 199, "name": "wall-other-merged"},
{"supercategory": "textile", "isthing": 0, "id": 200, "name": "rug-merged"}这里我需要标注天空和树木、建筑物,对应:sky-other-merged 和 tree-merged、building-other-merged
★但是注意这些都是stuff类,我们要尽量把图中的thing也标出来!原因是mmdetection框架使用coco_panoptic数据集训练时需要thing类和stuff类不能为空,否则极有可能会报错ValueError: need at least one array to concatenate
这个错误是因为模型训练或者推理时,没有预测到有效的类别,导致算法索引时数据为空报错,在训练和微调时都可能会出现。
微调时出现是因为所有的标注图片中都没有同时存在thing和stuff,一般只会出现在数据集比较少的情况,此时需要增加数据集,或者把图片中thing和stuff尽量标注出来,如果遇到没有同时标注出来的图片算法会自动跳过该图片,即该图片不参与微调训练,所以标注时需要在每个图片中都尽量确保有thing和stuff;
如果出现在推理时报这个错,一个可能是你标注的数据集有问题,第二个是微调的参数设置的不正确,可以尝试减小学习率,或冻结一部分参数(比如'optimizer'中的lr参数减小、'backbone'、'query_embed'设置的小一点,frozen_stages设置为1~4等,表示冻结层数量)
③标注完成后,在输出目录中会有每张图对应的标注JSON文件,查看是否有原图,一个JSON文件对应一张图,如果没有直接复制一份所有的原图到输出目录。
④运行my_labelme2coco_panoptic.py文件,这个是我用大模型写的将labelme标注集转为coco_panoptic数据集代码,可以使用:
import os
import json
import cv2
import numpy as np
from PIL import Image
import random
import shutil
from datetime import datetime
import argparse
from pathlib import Path
class LabelMeToCOCOPanoptic:
def __init__(self, labelme_dir, output_dir, train_ratio=0.8):
self.labelme_dir = Path(labelme_dir)
self.output_dir = Path(output_dir)
self.train_ratio = train_ratio
# 全局segment_id计数器,确保整个数据集中的segment_id唯一
self.global_segment_id = 1
# COCO Panoptic categories - 保持与示例一致
self.categories = [
{"supercategory": "person", "isthing": 1, "id": 1, "name": "person"},
{"supercategory": "vehicle", "isthing": 1, "id": 2, "name": "bicycle"},
{"supercategory": "vehicle", "isthing": 1, "id": 3, "name": "car"},
{"supercategory": "vehicle", "isthing": 1, "id": 4, "name": "motorcycle"},
{"supercategory": "vehicle", "isthing": 1, "id": 5, "name": "airplane"},
{"supercategory": "vehicle", "isthing": 1, "id": 6, "name": "bus"},
{"supercategory": "vehicle", "isthing": 1, "id": 7, "name": "train"},
{"supercategory": "vehicle", "isthing": 1, "id": 8, "name": "truck"},
{"supercategory": "vehicle", "isthing": 1, "id": 9, "name": "boat"},
{"supercategory": "outdoor", "isthing": 1, "id": 10, "name": "traffic light"},
{"supercategory": "outdoor", "isthing": 1, "id": 11, "name": "fire hydrant"},
{"supercategory": "outdoor", "isthing": 1, "id": 13, "name": "stop sign"},
{"supercategory": "outdoor", "isthing": 1, "id": 14, "name": "parking meter"},
{"supercategory": "outdoor", "isthing": 1, "id": 15, "name": "bench"},
{"supercategory": "animal", "isthing": 1, "id": 16, "name": "bird"},
{"supercategory": "animal", "isthing": 1, "id": 17, "name": "cat"},
{"supercategory": "animal", "isthing": 1, "id": 18, "name": "dog"},
{"supercategory": "animal", "isthing": 1, "id": 19, "name": "horse"},
{"supercategory": "animal", "isthing": 1, "id": 20, "name": "sheep"},
{"supercategory": "animal", "isthing": 1, "id": 21, "name": "cow"},
{"supercategory": "animal", "isthing": 1, "id": 22, "name": "elephant"},
{"supercategory": "animal", "isthing": 1, "id": 23, "name": "bear"},
{"supercategory": "animal", "isthing": 1, "id": 24, "name": "zebra"},
{"supercategory": "animal", "isthing": 1, "id": 25, "name": "giraffe"},
{"supercategory": "accessory", "isthing": 1, "id": 27, "name": "backpack"},
{"supercategory": "accessory", "isthing": 1, "id": 28, "name": "umbrella"},
{"supercategory": "accessory", "isthing": 1, "id": 31, "name": "handbag"},
{"supercategory": "accessory", "isthing": 1, "id": 32, "name": "tie"},
{"supercategory": "accessory", "isthing": 1, "id": 33, "name": "suitcase"},
{"supercategory": "sports", "isthing": 1, "id": 34, "name": "frisbee"},
{"supercategory": "sports", "isthing": 1, "id": 35, "name": "skis"},
{"supercategory": "sports", "isthing": 1, "id": 36, "name": "snowboard"},
{"supercategory": "sports", "isthing": 1, "id": 37, "name": "sports ball"},
{"supercategory": "sports", "isthing": 1, "id": 38, "name": "kite"},
{"supercategory": "sports", "isthing": 1, "id": 39, "name": "baseball bat"},
{"supercategory": "sports", "isthing": 1, "id": 40, "name": "baseball glove"},
{"supercategory": "sports", "isthing": 1, "id": 41, "name": "skateboard"},
{"supercategory": "sports", "isthing": 1, "id": 42, "name": "surfboard"},
{"supercategory": "sports", "isthing": 1, "id": 43, "name": "tennis racket"},
{"supercategory": "kitchen", "isthing": 1, "id": 44, "name": "bottle"},
{"supercategory": "kitchen", "isthing": 1, "id": 46, "name": "wine glass"},
{"supercategory": "kitchen", "isthing": 1, "id": 47, "name": "cup"},
{"supercategory": "kitchen", "isthing": 1, "id": 48, "name": "fork"},
{"supercategory": "kitchen", "isthing": 1, "id": 49, "name": "knife"},
{"supercategory": "kitchen", "isthing": 1, "id": 50, "name": "spoon"},
{"supercategory": "kitchen", "isthing": 1, "id": 51, "name": "bowl"},
{"supercategory": "food", "isthing": 1, "id": 52, "name": "banana"},
{"supercategory": "food", "isthing": 1, "id": 53, "name": "apple"},
{"supercategory": "food", "isthing": 1, "id": 54, "name": "sandwich"},
{"supercategory": "food", "isthing": 1, "id": 55, "name": "orange"},
{"supercategory": "food", "isthing": 1, "id": 56, "name": "broccoli"},
{"supercategory": "food", "isthing": 1, "id": 57, "name": "carrot"},
{"supercategory": "food", "isthing": 1, "id": 58, "name": "hot dog"},
{"supercategory": "food", "isthing": 1, "id": 59, "name": "pizza"},
{"supercategory": "food", "isthing": 1, "id": 60, "name": "donut"},
{"supercategory": "food", "isthing": 1, "id": 61, "name": "cake"},
{"supercategory": "furniture", "isthing": 1, "id": 62, "name": "chair"},
{"supercategory": "furniture", "isthing": 1, "id": 63, "name": "couch"},
{"supercategory": "furniture", "isthing": 1, "id": 64, "name": "potted plant"},
{"supercategory": "furniture", "isthing": 1, "id": 65, "name": "bed"},
{"supercategory": "furniture", "isthing": 1, "id": 67, "name": "dining table"},
{"supercategory": "furniture", "isthing": 1, "id": 70, "name": "toilet"},
{"supercategory": "electronic", "isthing": 1, "id": 72, "name": "tv"},
{"supercategory": "electronic", "isthing": 1, "id": 73, "name": "laptop"},
{"supercategory": "electronic", "isthing": 1, "id": 74, "name": "mouse"},
{"supercategory": "electronic", "isthing": 1, "id": 75, "name": "remote"},
{"supercategory": "electronic", "isthing": 1, "id": 76, "name": "keyboard"},
{"supercategory": "electronic", "isthing": 1, "id": 77, "name": "cell phone"},
{"supercategory": "appliance", "isthing": 1, "id": 78, "name": "microwave"},
{"supercategory": "appliance", "isthing": 1, "id": 79, "name": "oven"},
{"supercategory": "appliance", "isthing": 1, "id": 80, "name": "toaster"},
{"supercategory": "appliance", "isthing": 1, "id": 81, "name": "sink"},
{"supercategory": "appliance", "isthing": 1, "id": 82, "name": "refrigerator"},
{"supercategory": "indoor", "isthing": 1, "id": 84, "name": "book"},
{"supercategory": "indoor", "isthing": 1, "id": 85, "name": "clock"},
{"supercategory": "indoor", "isthing": 1, "id": 86, "name": "vase"},
{"supercategory": "indoor", "isthing": 1, "id": 87, "name": "scissors"},
{"supercategory": "indoor", "isthing": 1, "id": 88, "name": "teddy bear"},
{"supercategory": "indoor", "isthing": 1, "id": 89, "name": "hair drier"},
{"supercategory": "indoor", "isthing": 1, "id": 90, "name": "toothbrush"},
{"supercategory": "textile", "isthing": 0, "id": 92, "name": "banner"},
{"supercategory": "textile", "isthing": 0, "id": 93, "name": "blanket"},
{"supercategory": "building", "isthing": 0, "id": 95, "name": "bridge"},
{"supercategory": "raw-material", "isthing": 0, "id": 100, "name": "cardboard"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 107, "name": "counter"},
{"supercategory": "textile", "isthing": 0, "id": 109, "name": "curtain"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 112, "name": "door-stuff"},
{"supercategory": "floor", "isthing": 0, "id": 118, "name": "floor-wood"},
{"supercategory": "plant", "isthing": 0, "id": 119, "name": "flower"},
{"supercategory": "food-stuff", "isthing": 0, "id": 122, "name": "fruit"},
{"supercategory": "ground", "isthing": 0, "id": 125, "name": "gravel"},
{"supercategory": "building", "isthing": 0, "id": 128, "name": "house"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 130, "name": "light"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 133, "name": "mirror-stuff"},
{"supercategory": "structural", "isthing": 0, "id": 138, "name": "net"},
{"supercategory": "textile", "isthing": 0, "id": 141, "name": "pillow"},
{"supercategory": "ground", "isthing": 0, "id": 144, "name": "platform"},
{"supercategory": "ground", "isthing": 0, "id": 145, "name": "playingfield"},
{"supercategory": "ground", "isthing": 0, "id": 147, "name": "railroad"},
{"supercategory": "water", "isthing": 0, "id": 148, "name": "river"},
{"supercategory": "ground", "isthing": 0, "id": 149, "name": "road"},
{"supercategory": "building", "isthing": 0, "id": 151, "name": "roof"},
{"supercategory": "ground", "isthing": 0, "id": 154, "name": "sand"},
{"supercategory": "water", "isthing": 0, "id": 155, "name": "sea"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 156, "name": "shelf"},
{"supercategory": "ground", "isthing": 0, "id": 159, "name": "snow"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 161, "name": "stairs"},
{"supercategory": "building", "isthing": 0, "id": 166, "name": "tent"},
{"supercategory": "textile", "isthing": 0, "id": 168, "name": "towel"},
{"supercategory": "wall", "isthing": 0, "id": 171, "name": "wall-brick"},
{"supercategory": "wall", "isthing": 0, "id": 175, "name": "wall-stone"},
{"supercategory": "wall", "isthing": 0, "id": 176, "name": "wall-tile"},
{"supercategory": "wall", "isthing": 0, "id": 177, "name": "wall-wood"},
{"supercategory": "water", "isthing": 0, "id": 178, "name": "water-other"},
{"supercategory": "window", "isthing": 0, "id": 180, "name": "window-blind"},
{"supercategory": "window", "isthing": 0, "id": 181, "name": "window-other"},
{"supercategory": "plant", "isthing": 0, "id": 184, "name": "tree-merged"},
{"supercategory": "structural", "isthing": 0, "id": 185, "name": "fence-merged"},
{"supercategory": "ceiling", "isthing": 0, "id": 186, "name": "ceiling-merged"},
{"supercategory": "sky", "isthing": 0, "id": 187, "name": "sky-other-merged"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 188, "name": "cabinet-merged"},
{"supercategory": "furniture-stuff", "isthing": 0, "id": 189, "name": "table-merged"},
{"supercategory": "floor", "isthing": 0, "id": 190, "name": "floor-other-merged"},
{"supercategory": "ground", "isthing": 0, "id": 191, "name": "pavement-merged"},
{"supercategory": "solid", "isthing": 0, "id": 192, "name": "mountain-merged"},
{"supercategory": "plant", "isthing": 0, "id": 193, "name": "grass-merged"},
{"supercategory": "ground", "isthing": 0, "id": 194, "name": "dirt-merged"},
{"supercategory": "raw-material", "isthing": 0, "id": 195, "name": "paper-merged"},
{"supercategory": "food-stuff", "isthing": 0, "id": 196, "name": "food-other-merged"},
{"supercategory": "building", "isthing": 0, "id": 197, "name": "building-other-merged"},
{"supercategory": "solid", "isthing": 0, "id": 198, "name": "rock-merged"},
{"supercategory": "wall", "isthing": 0, "id": 199, "name": "wall-other-merged"},
{"supercategory": "textile", "isthing": 0, "id": 200, "name": "rug-merged"}
]
# 创建类别名称到ID的映射和isthing的映射
self.category_name_to_id = {cat['name']: cat['id'] for cat in self.categories}
self.category_id_to_isthing = {cat['id']: cat['isthing'] for cat in self.categories}
# 初始化目录结构
self.setup_directories()
def setup_directories(self):
"""创建输出目录结构"""
dirs_to_create = [
self.output_dir / 'train2017',
self.output_dir / 'val2017',
self.output_dir / 'annotations' / 'panoptic_train2017',
self.output_dir / 'annotations' / 'panoptic_val2017'
]
for dir_path in dirs_to_create:
dir_path.mkdir(parents=True, exist_ok=True)
def polygon_to_mask(self, polygon_points, img_shape):
"""将多边形转换为掩码"""
mask = np.zeros(img_shape[:2], dtype=np.uint8)
points = np.array(polygon_points, dtype=np.int32)
cv2.fillPoly(mask, [points], 1)
return mask
def calculate_bbox_area(self, mask):
"""计算边界框和面积"""
rows = np.any(mask, axis=1)
cols = np.any(mask, axis=0)
if not np.any(rows) or not np.any(cols):
return [0, 0, 0, 0], 0
rmin, rmax = np.where(rows)[0][[0, -1]]
cmin, cmax = np.where(cols)[0][[0, -1]]
bbox = [int(cmin), int(rmin), int(cmax - cmin + 1), int(rmax - rmin + 1)]
area = int(np.sum(mask))
return bbox, area
def process_labelme_json(self, json_path, img_shape):
"""处理单个labelme JSON文件"""
with open(json_path, 'r', encoding='utf-8') as f:
labelme_data = json.load(f)
segments_info = []
panoptic_mask = np.zeros(img_shape[:2], dtype=np.uint32)
# 用于追踪stuff类别的segment_id,确保同一类别在同一张图片中只有一个ID
stuff_category_to_segment_id = {}
for shape in labelme_data.get('shapes', []):
label = shape['label']
points = shape['points']
# 查找对应的category_id
category_id = self.category_name_to_id.get(label)
if category_id is None:
print(f"Warning: Label '{label}' not found in categories, skipping...")
continue
# 创建掩码
mask = self.polygon_to_mask(points, img_shape)
if np.sum(mask) == 0:
continue
# 获取类别的isthing属性
isthing = self.category_id_to_isthing[category_id]
# 根据isthing决定segment_id的分配策略
if isthing == 1: # Thing类:每个实例独立ID
current_segment_id = self.global_segment_id
self.global_segment_id += 1
else: # Stuff类:同一类别在同一张图片中共享ID
if category_id in stuff_category_to_segment_id:
# 如果这个stuff类别已经在当前图片中出现过,使用相同的segment_id
current_segment_id = stuff_category_to_segment_id[category_id]
else:
# 第一次出现这个stuff类别,分配新的segment_id
current_segment_id = self.global_segment_id
stuff_category_to_segment_id[category_id] = current_segment_id
self.global_segment_id += 1
# 添加到全景掩码(对于stuff类,可能会合并多个不相邻的区域)
panoptic_mask[mask == 1] = current_segment_id
# 检查这个segment是否已经在segments_info中
existing_segment = None
for segment in segments_info:
if segment['id'] == current_segment_id:
existing_segment = segment
break
if existing_segment is None:
# 计算边界框和面积
bbox, area = self.calculate_bbox_area(mask)
if area == 0:
continue
# 创建新的segment信息
segments_info.append({
"id": current_segment_id,
"category_id": category_id,
"iscrowd": 0,
"bbox": bbox,
"area": area
})
else:
# 更新现有segment的bbox和area(对于stuff类的多个区域)
# 获取当前segment的所有像素
segment_mask = (panoptic_mask == current_segment_id).astype(np.uint8)
bbox, area = self.calculate_bbox_area(segment_mask)
existing_segment['bbox'] = bbox
existing_segment['area'] = area
return segments_info, panoptic_mask
def segment_id_to_rgb(self, segment_id):
"""将segment_id转换为RGB颜色 - COCO Panoptic标准编码"""
# COCO Panoptic格式的RGB编码公式
r = segment_id % 256
g = (segment_id // 256) % 256
b = (segment_id // 65536) % 256
return (r, g, b)
def rgb_to_segment_id(self, r, g, b):
"""将RGB颜色转换为segment_id - COCO Panoptic标准解码"""
return r + g * 256 + b * 65536
def encode_panoptic_mask(self, panoptic_mask, segments_info):
"""将panoptic掩码编码为RGB图像,使用COCO Panoptic标准编码"""
rgb_mask = np.zeros((*panoptic_mask.shape, 3), dtype=np.uint8)
# 为每个segment使用标准的segment_id到RGB的数学转换
for segment in segments_info:
segment_id = segment['id']
# 使用COCO Panoptic标准的RGB编码
color = self.segment_id_to_rgb(segment_id)
mask_indices = panoptic_mask == segment_id
rgb_mask[mask_indices] = color
return rgb_mask
def convert_dataset(self):
"""转换整个数据集"""
# 收集所有图片和JSON文件
json_files = list(self.labelme_dir.glob('*.json'))
print(f"Found {len(json_files)} JSON files in {self.labelme_dir}")
# 为每个JSON文件找对应的图片文件
valid_pairs = []
for json_path in json_files:
# 尝试不同的图片扩展名
base_name = json_path.stem
image_extensions = ['.jpg', '.jpeg', '.png', '.JPG', '.JPEG', '.PNG']
img_path = None
for ext in image_extensions:
potential_img_path = json_path.parent / (base_name + ext)
if potential_img_path.exists():
img_path = potential_img_path
break
if img_path is not None:
valid_pairs.append((img_path, json_path))
print(f"Found pair: {img_path.name} <-> {json_path.name}")
else:
print(f"Warning: No corresponding image found for {json_path}")
print(f"Found {len(valid_pairs)} valid image-json pairs")
if len(valid_pairs) == 0:
print("Error: No valid image-json pairs found!")
return
# 随机划分训练集和验证集
random.shuffle(valid_pairs)
train_count = int(len(valid_pairs) * self.train_ratio)
train_pairs = valid_pairs[:train_count]
val_pairs = valid_pairs[train_count:]
print(f"Training set: {len(train_pairs)} images")
print(f"Validation set: {len(val_pairs)} images")
# 重置全局segment_id计数器
self.global_segment_id = 1
# 处理训练集
train_coco = self.process_split(train_pairs, 'train')
# 处理验证集
val_coco = self.process_split(val_pairs, 'val')
# 保存JSON文件
with open(self.output_dir / 'annotations' / 'panoptic_train2017.json', 'w') as f:
json.dump(train_coco, f, indent=2)
with open(self.output_dir / 'annotations' / 'panoptic_val2017.json', 'w') as f:
json.dump(val_coco, f, indent=2)
print("Conversion completed successfully!")
print(f"Total segments processed: {self.global_segment_id - 1}")
def process_split(self, pairs, split_name):
"""处理训练集或验证集"""
images = []
annotations = []
for idx, (img_path, json_path) in enumerate(pairs, 1):
print(f"Processing {split_name} {idx}/{len(pairs)}: {img_path.name}")
# 读取图片
img = cv2.imread(str(img_path))
if img is None:
print(f"Warning: Cannot read image {img_path}")
continue
height, width = img.shape[:2]
# 处理JSON标注
segments_info, panoptic_mask = self.process_labelme_json(json_path, img.shape)
if not segments_info:
print(f"Warning: No valid annotations found in {json_path}")
continue
# 生成新的文件名
new_img_name = f"{idx:012d}.jpg"
new_mask_name = f"{idx:012d}.png"
# 保存图片(转换为JPG格式)
img_output_dir = self.output_dir / f'{split_name}2017'
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
pil_img = Image.fromarray(img_rgb)
pil_img.save(img_output_dir / new_img_name, 'JPEG', quality=100)
# 保存panoptic掩码
mask_output_dir = self.output_dir / 'annotations' / f'panoptic_{split_name}2017'
rgb_mask = self.encode_panoptic_mask(panoptic_mask, segments_info)
pil_mask = Image.fromarray(rgb_mask)
pil_mask.save(mask_output_dir / new_mask_name, 'PNG')
# 添加图片信息
images.append({
"file_name": new_img_name,
"height": height,
"width": width,
"id": idx
})
# 添加标注信息
annotations.append({
"segments_info": segments_info,
"file_name": new_mask_name,
"image_id": idx
})
# 构建COCO格式数据
coco_data = {
"info": {
"description": "",
"url": "",
"version": "",
"year": 2025,
"contributor": "",
"date_created": datetime.now().strftime("%Y-%m-%d %H:%M:%S")
},
"licenses": [],
"images": images,
"annotations": annotations,
"categories": self.categories
}
return coco_data
def main():
parser = argparse.ArgumentParser(description='Convert LabelMe format to COCO Panoptic format')
parser.add_argument('--labelme_dir', type=str, required=True,
help='Directory containing LabelMe images and JSON files')
parser.add_argument('--output_dir', type=str, default='my_coco',
help='Output directory for COCO format dataset')
parser.add_argument('--train_ratio', type=float, default=0.8,
help='Ratio of training set (0.0-1.0)')
args = parser.parse_args()
# 检查输入目录
if not os.path.exists(args.labelme_dir):
print(f"Error: Input directory '{args.labelme_dir}' does not exist")
return
# 创建转换器并执行转换
converter = LabelMeToCOCOPanoptic(
labelme_dir=args.labelme_dir,
output_dir=args.output_dir,
train_ratio=args.train_ratio
)
converter.convert_dataset()
if __name__ == "__main__":
# 示例用法
if len(os.sys.argv) == 1:
# 如果没有提供命令行参数,使用默认值进行演示
print("Demo mode: Converting 'labelme' folder to 'my_coco' folder")
print("Use --help for command line options")
converter = LabelMeToCOCOPanoptic(
labelme_dir="labelme",
output_dir="my_coco",
train_ratio=0.8
)
converter.convert_dataset()
else:
main()运行命令示例:
python my_labelme2coco_panoptic.py --labelme_dir labelme --output_dir data\my_coco --train_ratio 0.8--labelme_dir是labelme的标注文件路径;
--output_dir是我们自己的coco_panoptic数据集输出路径;
--train_ratio是训练集和验证集的比例;默认为0.8,比如10张标注照片,那么8张会分到训练集中,2张分到验证集中;1.0就是全都是训练集;
代码主要就是将labelme的JSON和原图生成coco_panoptic数据集格式,在该过程中需要注意两点:
第一是panoptic_train2017.json和panoptic_val2017.json文件中“annotations”的"segments_info"中的id,这个id是与每个mask掩码图中对应区域的RGB颜色对应,具体公式为:
r = id % 256
g = (id // 256) % 256
b = (id // 256 // 256) % 256
第二个是"categories"最好是写上所有类,以方便算法进行类别对应
4. 开始运行微调:
当自定义的数据集准备完成后,可以运行mmdetection中的train进行微调
①首先确保train.py文件同级目录下有数据集文件夹、maskformer_r50_ms-16xb1-75e_coco.pth模型文件、maskformer_r50_ms-16xb1-75e_coco.py模型配置文件、coco_panoptic.py数据集配置文件、default_runtime.py文件,他们都放在同一目录文件夹下。
②修改maskformer_r50_ms-16xb1-75e_coco.py模型配置文件
开头 _base_ 中要改为数据集配置文件和default_runtime文件所在目录,第一步中因为我都放在同级目录了,所以示例如下:
_base_ = ['coco_panoptic.py', 'default_runtime.py']在“# optimizer”前(或其他合适位置)加上load_from = 'maskformer_r50_ms-16xb1-75e_coco.pth',用来加载预训练的模型权重。(如果运行代码时下载resnet50模型,可以把init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'))这个代码注释掉)
设置好适当的微调参数,微调的学习率和训练回合max_epochs可以小一些
我的maskformer_r50_ms-16xb1-75e_coco.py模型配置文件代码如下,可以参考,有些地方如果注释不对感谢帮忙指出
_base_ = [
'coco_panoptic.py', 'default_runtime.py'
]
data_preprocessor = dict(
type='DetDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_size_divisor=1,
pad_mask=True,
mask_pad_value=0,
pad_seg=True,
seg_pad_value=255)
num_things_classes = 80
num_stuff_classes = 53
num_classes = num_things_classes + num_stuff_classes
model = dict(
type='MaskFormer',
data_preprocessor=data_preprocessor,
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
#####################################################
frozen_stages=-1, # frozen_stages 主要用来控制骨干网络(backbone)里哪些 stage 的参数被冻结,默认-1。 -1 表示不冻结任何参数,所有层都会训练(full fine-tune);0 表示冻结 stem(也就是卷积+BN 的最前面那几层),后面所有 stage 依然训练;1 表示冻结 stem 和第一个 stage,只训练 stage2、stage3、stage4,后面以此类推。
#####################################################
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
# init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
style='pytorch'
),
panoptic_head=dict(
type='MaskFormerHead',
in_channels=[256, 512, 1024, 2048], # pass to pixel_decoder inside
feat_channels=256,
out_channels=256,
num_things_classes=num_things_classes,
num_stuff_classes=num_stuff_classes,
num_queries=100,
pixel_decoder=dict(
type='TransformerEncoderPixelDecoder',
norm_cfg=dict(type='GN', num_groups=32),
act_cfg=dict(type='ReLU'),
encoder=dict( # DetrTransformerEncoder
num_layers=6,
layer_cfg=dict( # DetrTransformerEncoderLayer
self_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.1,
act_cfg=dict(type='ReLU', inplace=True)))),
positional_encoding=dict(num_feats=128, normalize=True)),
enforce_decoder_input_project=False,
positional_encoding=dict(num_feats=128, normalize=True),
transformer_decoder=dict( # DetrTransformerDecoder
num_layers=6,
layer_cfg=dict( # DetrTransformerDecoderLayer
self_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
cross_attn_cfg=dict( # MultiheadAttention
embed_dims=256,
num_heads=8,
dropout=0.1,
batch_first=True),
ffn_cfg=dict(
embed_dims=256,
feedforward_channels=2048,
num_fcs=2,
ffn_drop=0.1,
act_cfg=dict(type='ReLU', inplace=True))),
return_intermediate=True),
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=1.0,
reduction='mean',
class_weight=[1.0] * num_classes + [0.1]),
loss_mask=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
reduction='mean',
loss_weight=20.0),
loss_dice=dict(
type='DiceLoss',
use_sigmoid=True,
activate=True,
reduction='mean',
naive_dice=True,
eps=1.0,
loss_weight=1.0)),
panoptic_fusion_head=dict(
type='MaskFormerFusionHead',
num_things_classes=num_things_classes,
num_stuff_classes=num_stuff_classes,
loss_panoptic=None,
init_cfg=None),
train_cfg=dict(
assigner=dict(
type='HungarianAssigner',
match_costs=[
dict(type='ClassificationCost', weight=1.0),
dict(type='FocalLossCost', weight=20.0, binary_input=True),
dict(type='DiceCost', weight=1.0, pred_act=True, eps=1.0)
]),
sampler=dict(type='MaskPseudoSampler')),
test_cfg=dict(
panoptic_on=True,
# For now, the dataset does not support
# evaluating semantic segmentation metric.
semantic_on=False,
instance_on=False,
# max_per_image is for instance segmentation.
max_per_image=100,
object_mask_thr=0.8,
iou_thr=0.8,
# In MaskFormer's panoptic postprocessing,
# it will not filter masks whose score is smaller than 0.5 .
filter_low_score=False),
init_cfg=None
)
# dataset settings
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='LoadPanopticAnnotations',
with_bbox=True,
with_mask=True,
with_seg=True),
dict(type='RandomFlip', prob=0.5),
dict(
type='RandomChoice',
transforms=[[
dict(
type='RandomChoiceResize',
scales=[(480, 1333), (512, 1333), (544, 1333), (576, 1333),
(608, 1333), (640, 1333), (672, 1333), (704, 1333),
(736, 1333), (768, 1333), (800, 1333)],
keep_ratio=True)
],
[
dict(
type='RandomChoiceResize',
scales=[(400, 1333), (500, 1333), (600, 1333)],
keep_ratio=True),
dict(
type='RandomCrop',
crop_type='absolute_range',
crop_size=(384, 600),
allow_negative_crop=True),
dict(
type='RandomChoiceResize',
scales=[(480, 1333), (512, 1333), (544, 1333),
(576, 1333), (608, 1333), (640, 1333),
(672, 1333), (704, 1333), (736, 1333),
(768, 1333), (800, 1333)],
keep_ratio=True)
]]),
dict(type='PackDetInputs')
]
train_dataloader = dict(
batch_size=1, num_workers=1, dataset=dict(pipeline=train_pipeline))
val_dataloader = dict(batch_size=1, num_workers=1)
test_dataloader = val_dataloader
# 使用预训练的 Mask R-CNN 模型权重来做初始化,可以提高模型性能
load_from = 'maskformer_r50_ms-16xb1-75e_coco.pth'
# optimizer
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(
type='AdamW',
lr=0.0001, # 原始为0.0001
weight_decay=0.0001,
eps=1e-8,
betas=(0.9, 0.999)
),
#####################################################################
# 冻结部分参数以便微调时防止模型失忆,与frozen_stages参数配合使用
paramwise_cfg=dict(
custom_keys={
'backbone': dict(lr_mult=0.1, decay_mult=1.0), # 原始:lr_mult=0.1, decay_mult=1.0 冻结时 lr_mult=0.0, decay_mult=1.0
# 'transformer': dict(lr_mult=0.0), # transformer 不更新(原始没有这一参数) 冻结时取消注释即可
'query_embed': dict(lr_mult=1.0, decay_mult=0.0) # 原始:lr_mult=1.0, decay_mult=0.0 冻结时 lr_mult=0.0, decay_mult=0.0
},
norm_decay_mult=0.0),
#####################################################################
clip_grad=dict(max_norm=0.01, norm_type=2)
)
max_epochs = 5 # 75
# learning rate学习率
param_scheduler = dict(
type='MultiStepLR',
begin=0,
end=max_epochs,
by_epoch=True,
milestones=[50],
gamma=0.1)
train_cfg = dict(
type='EpochBasedTrainLoop',
max_epochs=max_epochs,
val_interval=10) # 训练多少轮后验证一次
val_cfg = dict(type='ValLoop')
test_cfg = dict(type='TestLoop')
# 学习率自动缩放
# Default setting for scaling LR automatically
# - `enable` means enable scaling LR automatically
# or not by default.
# - `base_batch_size` = (16 GPUs) x (1 samples per GPU).
# auto_scale_lr = dict(enable=False, base_batch_size=16)③修改coco_panoptic.py数据集配置文件,主要也是最开头的数据集路径修改,直接贴我的:
# dataset settings
dataset_type = 'CocoPanopticDataset'
data_root = 'data/my_coco/'
# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically infer from prefix (not support LMDB and Memcache yet)
# data_root = 's3://openmmlab/datasets/detection/coco/'
# Method 2: Use `backend_args`, `file_client_args` in versions before 3.0.0rc6
# backend_args = dict(
# backend='petrel',
# path_mapping=dict({
# './data/': 's3://openmmlab/datasets/detection/',
# 'data/': 's3://openmmlab/datasets/detection/'
# }))
backend_args = None
train_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='LoadPanopticAnnotations', backend_args=backend_args),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', prob=0.5),
dict(type='PackDetInputs')
]
test_pipeline = [
dict(type='LoadImageFromFile', backend_args=backend_args),
dict(type='Resize', scale=(1333, 800), keep_ratio=True),
dict(type='LoadPanopticAnnotations', backend_args=backend_args),
dict(
type='PackDetInputs',
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
'scale_factor'))
]
train_dataloader = dict(
batch_size=2,
num_workers=2,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=dict(type='AspectRatioBatchSampler'),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/panoptic_train2017.json',
data_prefix=dict(
img='train2017/',
seg='annotations/panoptic_train2017/'),
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=train_pipeline,
backend_args=backend_args))
val_dataloader = dict(
batch_size=1,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/panoptic_val2017.json',
data_prefix=dict(
img='val2017/',
seg='annotations/panoptic_val2017/'),
test_mode=True,
pipeline=test_pipeline,
backend_args=backend_args))
test_dataloader = val_dataloader
val_evaluator = dict(
type='CocoPanopticMetric',
ann_file=data_root + 'annotations/panoptic_val2017.json',
seg_prefix=data_root + 'annotations/panoptic_val2017/',
backend_args=backend_args)
test_evaluator = val_evaluator
# inference on test dataset and
# format the output results for submission.
# test_dataloader = dict(
# batch_size=1,
# num_workers=1,
# persistent_workers=True,
# drop_last=False,
# sampler=dict(type='DefaultSampler', shuffle=False),
# dataset=dict(
# type=dataset_type,
# data_root=data_root,
# ann_file='annotations/panoptic_image_info_test-dev2017.json',
# data_prefix=dict(img='test2017/'),
# test_mode=True,
# pipeline=test_pipeline))
# test_evaluator = dict(
# type='CocoPanopticMetric',
# format_only=True,
# ann_file=data_root + 'annotations/panoptic_image_info_test-dev2017.json',
# outfile_prefix='./work_dirs/coco_panoptic/test')
④开始微调:
(在train.py所在文件夹下开的cmd并进入conda环境)
python train.py maskformer_r50_ms-16xb1-75e_coco.py正常情况log中会出现加载的预训练模型、训练中的各种loss值和参数值、验证时的PQ、RQ值等,训练完成后,会在train.py所在文件夹下出现一个work_dirs文件夹,其中的epoch_X,X最大的那个就是最后的模型文件,还会同时生成很多检查点,每训练一回合就会自动保存一个epoch_N
如果报错ValueError: need at least one array to concatenate、return {'pq': pq / n, 'sq': sq / n, 'rq': rq / n, 'n': n}, per_class_results ZeroDivisionError: division by zero的错误,注意看前面数据集构建说的,return {'pq': pq / n, 'sq': sq / n, 'rq': rq / n, 'n': n}这个错误本质也是没有检测到有效类别,有可能是数据集没标好,有可能是参数设置的不好导致过拟合或者模型推理能力退化。
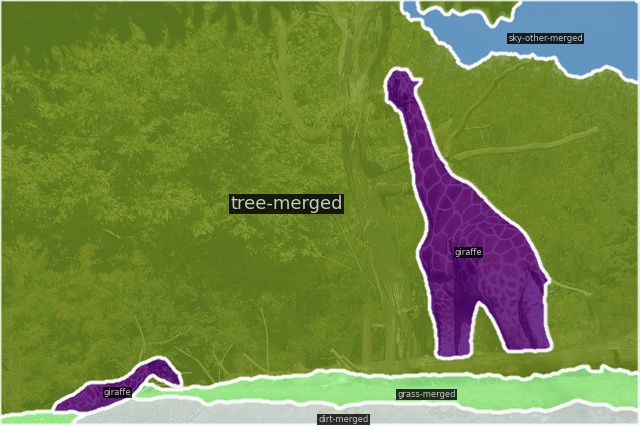
5. 测试推理:
将微调后的模型进行推理测试,验证模型对我们标注的感兴趣区域的推理能力是否变强,并且保留了通用检测能力:
将推理代码、微调后模型文件、模型配置文件、coco_panoptic.py配置文件和default_runtime.py配置文件、需要推理图像都放在同一目录中(这里模型配置文件、coco_panoptic.py配置文件和default_runtime.py配置文件我都用的mmdetection中原始的),然后运行推理代码test_my.py,即可进行推理,我的test_my.py如下:
from mmdet.apis import DetInferencer
def simple_infer(image_path, config_path, weights_path, out_path, device='cpu'):
"""
简单推理:
- image_path: 输入图片
- config_path: 模型配置文件
- weights_path: 权重pth文件
- out_path: 输出目录
- device: 推理设备
"""
inferencer = DetInferencer(model=config_path, weights=weights_path, device=device)
inferencer(image_path, out_dir=out_path, show=False)
if __name__ == '__main__':
simple_infer(
'000000000001.jpg',
'maskformer_r50_ms-16xb1-75e_coco.py',
'epoch_10.pth',
'outputs',
device='cpu' # 或 'cuda'
)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)