Go-Zero(Gin+GORM)实现聚合推特数据进行情感分析 技术设计-将持续更新并且开源
搭建开发环境,完成账号注册和基础工具准备,确保后续功能能正常开发。
Twitter 圈内行情信息-情感分析系统
设计说明文章地址:Gin+GORM实现聚合推特数据进行情感分析 技术设计-将持续更新并且开源
开源地址:github开源地址
以下是基于上述技术方案的分阶段实现计划,从环境搭建到核心功能落地,逐步推进项目开发,确保每一步可验证、可迭代:
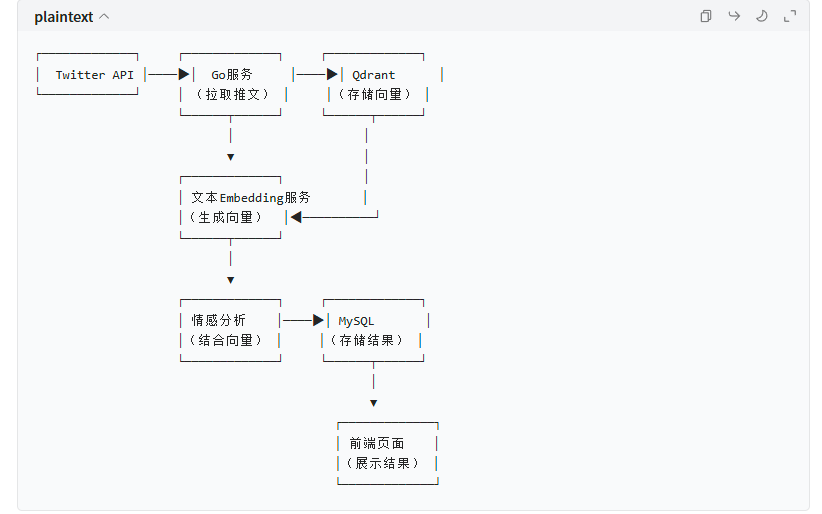
阶段1:环境与基础配置(1-2天)
目标:搭建开发环境,完成账号注册和基础工具准备,确保后续功能能正常开发。
步骤1:注册必要账号与获取权限
-
注册Twitter开发者账号:访问 https://developer.x.com/,创建项目,获取
API Key、API Secret、Access Token、Access Token Secret(用于调用Twitter API)。 -
记录关键信息:整理上述Token到本地配置文件(如
config.yaml),注意保密(后续用环境变量或加密存储)。
步骤2:搭建本地开发环境
-
安装Go:确保Go 1.21+版本(
go version验证),配置GOPATH。 -
安装数据库:
-
MySQL:本地部署或用Docker(
docker run -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:8.0),创建数据库(如twitter_sentiment)。 -
Qdrant:用Docker部署(
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant),访问http://localhost:6333/dashboard确认启动成功。
-
-
安装必要工具:
- Git(版本控制)、Postman(API调试)、Docker(容器化工具)。
步骤3:初始化Go项目结构
-
创建项目目录:
twitter-sentiment/
├── cmd/ # 程序入口
│ └── api/ # 主服务入口
├── internal/ # 内部模块
│ ├── config/ # 配置解析
│ ├── twitter/ # 推特数据拉取
│ ├── embedding/ # 文本向量生成
│ ├── sentiment/ # 情感分析
│ ├── storage/ # 存储(MySQL+Qdrant)
│ └── server/ # HTTP服务(Gin)
├── pkg/ # 公共工具
│ ├── logger/ # 日志
│ └── retry/ # 重试逻辑
├── configs/ # 配置文件(config.yaml)
└── go.mod # 依赖管理
- 初始化`go.mod`:
```Bash
go mod init github.com/你的用户名/twitter-sentiment
-
引入核心依赖:
go get github.com/gin-gonic/gin go get gorm.io/gorm go get gorm.io/driver/mysql go get github.com/robfig/cron/v3 go get github.com/qdrant/go-client go get github.com/dghubble/go-twitter/twitter go get github.com/dghubble/oauth1
阶段2:核心存储与基础模型设计(1-2天)
目标:完成MySQL表结构设计、Qdrant向量集合定义,确保数据能正常存储。
步骤1:设计MySQL表结构并初始化
-
用GORM定义模型(
internal/storage/mysql/models.go):实现Influencer(大V信息)和TweetSentiment(情感分析结果)模型(参考前文结构)。 -
编写数据库初始化逻辑(
internal/storage/mysql/init.go):连接MySQL,自动迁移表结构(db.AutoMigrate(&Influencer{}, &TweetSentiment{}))。 -
测试:运行初始化代码,检查MySQL中是否生成对应表。
步骤2:设计Qdrant向量集合
-
编写Qdrant客户端初始化逻辑(
internal/storage/qdrant/client.go):连接本地Qdrant服务,创建tweets_embeddings集合(定义向量维度384,相似度计算方式为余弦距离)。 -
测试:调用创建集合接口,通过Qdrant Dashboard确认集合创建成功。
步骤3:编写基础配置解析
-
编写配置文件(
configs/config.yaml):包含MySQL连接信息、Qdrant地址、Twitter API Token、定时任务频率等。 -
实现配置解析逻辑(
internal/config/config.go):用github.com/spf13/viper读取yaml配置,解析为Go结构体。
阶段3:推特数据拉取功能(2-3天)
目标:实现从Twitter拉取指定大V的推文,并处理为后续可用的格式。
步骤1:实现Twitter API客户端
-
在
internal/twitter/client.go中封装客户端:用go-twitter和oauth1初始化客户端,支持通过用户名获取用户ID(需调用users/by/username接口)。 -
测试:写一个简单函数,传入大V用户名(如“elonmusk”),验证能否获取用户ID。
步骤2:实现推文增量拉取逻辑
-
核心函数(
internal/twitter/fetcher.go):-
输入:大V的Twitter ID、上次拉取的最后一条推文ID(避免重复拉取)。
-
逻辑:调用
userTimeline接口,排除转发和回复,获取原创推文。 -
输出:推文列表(包含ID、文本、发布时间、点赞数等)。
-
-
测试:拉取某个大V的最新10条推文,打印结果确认数据正确。
步骤3:集成定时任务框架
-
在
internal/server/cron.go中初始化cron:添加定时任务(如每30分钟执行一次),任务逻辑为“获取所有订阅大V→并发拉取推文”。 -
测试:手动触发任务,检查是否能正常拉取并打印推文。
阶段4:文本向量生成与存储(2-3天)
目标:将拉取的推文文本转换为向量,存储到Qdrant并关联元数据。
步骤1:部署文本Embedding服务(Python辅助)
-
用Python+FastAPI封装
sentence-transformers模型 -
启动服务:
uvicorn main:app --host 0.0.0.0 --port 8000,测试接口(POST http://localhost:8000/embed,传入文本返回向量)。
步骤2:Go调用Embedding服务
-
在
internal/embedding/client.go中实现调用逻辑:发送HTTP请求到Python服务,解析响应获取向量([]float32)。 -
测试:传入一条推文文本,验证能否获取384维向量。
步骤3:向量存储到Qdrant
-
编写存储逻辑(
internal/storage/qdrant/store.go):对每条推文,生成向量后,调用Qdrant的UpsertPoints接口,存储向量及元数据(推文ID、内容、发布时间、大V ID)。 -
测试:拉取一条推文,生成向量并存储,通过Qdrant Dashboard查询确认存储成功。
阶段5:情感分析功能(2-3天)
目标:结合向量相似性检索和基础模型,计算推文情感得分并存储到MySQL。
步骤1:实现基础情感得分计算
-
用
prose库(github.com/jdkato/prose)分析文本情感:在internal/sentiment/basic.go中,对推文文本进行分词,计算基础情感得分(-1~1)。 -
测试:输入正面/负面文本(如“Bitcoin will surge!”“Bitcoin will crash!”),验证得分是否符合预期。
步骤2:结合Qdrant相似性检索优化得分
-
编写相似推文查询逻辑(
internal/sentiment/similar.go):对新推文向量,在Qdrant中查询Top5相似历史推文,获取其情感标签(若有),加权调整基础得分。 -
规则示例:若3条相似推文为正面,则基础得分+0.2;若2条为负面,则-0.1。
步骤3:存储情感分析结果到MySQL
-
编写存储逻辑(
internal/storage/mysql/store.go):将推文ID、大V ID、内容、发布时间、情感得分、标签(positive/negative/neutral)存入TweetSentiment表。 -
测试:对一条推文完成“拉取→向量生成→情感分析→存储”全流程,检查MySQL中是否有记录。
阶段6:API服务与前端对接准备(1-2天)
目标:提供HTTP API供前端查询数据,完成核心功能闭环。
步骤1:实现Gin API接口
-
在
internal/server/handler.go中定义接口:-
GET /api/influencers:获取所有订阅大V列表。 -
GET /api/influencers/{id}/tweets:获取指定大V的推文及情感分析结果(支持分页、按时间筛选)。 -
POST /api/influencers:添加新的订阅大V(需传入Twitter用户名)。
-
-
测试:用Postman调用接口,验证返回数据格式正确。
步骤2:集成所有模块,启动完整服务
-
在
cmd/api/main.go中整合各模块:初始化配置→连接数据库→启动cron定时任务→启动Gin服务。 -
测试:运行服务,观察日志确认定时任务正常执行,API能返回最新分析结果。
阶段7:测试与优化(2-3天)
目标:修复bug,优化性能和分析精度,确保系统稳定运行。
步骤1:功能测试
-
测试场景:
-
添加大V后,是否能自动拉取其推文?
-
情感分析结果是否合理(人工抽检100条推文)?
-
API是否能正确返回数据,无重复或缺失?
-
步骤2:性能优化
-
优化拉取频率:对活跃大V(每日推文>5条)每15分钟拉取一次,低频大V每2小时一次。
-
缓存热门数据:用Redis缓存大V列表和最新推文(10分钟过期),减少数据库压力。
步骤3:精度优化
- 扩充领域词典:收集比特币相关情感词(如“bullish”“bearish”“FOMO”),手动标注500条推文,微调情感分析规则。
最终交付物
-
可运行的Go服务(包含定时任务、API、数据处理逻辑)。
-
初始化脚本(数据库表、Qdrant集合创建)。
-
接口文档(供前端对接)。
按此计划,总开发周期约12-18天,可根据实际进度调整各阶段时间,优先保证“拉取→分析→存储→API”核心流程跑通。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)