入门机器学习之——BP神经网络
本实验通过多层感知器(MLP)和反向传播算法实现半月形数据分类。实验使用MATLAB生成半月形数据集,并进行归一化预处理。构建包含2个输入神经元、20个隐藏层神经元和1个输出神经元的MLP网络,采用反向传播算法训练模型,并应用学习率退火策略优化训练过程。结果显示,在50次迭代后,模型在测试集上达到0%错误率。实验验证了MLP处理非线性分类问题的有效性,同时展示了数据预处理和学习率调整对模型性能的重
实 验 目 的:
通过实践来理解和掌握多层感知器(MLP)和反向传播算法的工作原理,以及如何使用它们进行分类任务。同时,还将学习到数据预处理和学习率退火策略的重要性
实 验 原 理:
1.多层感知器(MLP):MLP 是一种前馈神经网络,它包括一个输入层、一个或多个隐藏层和一个输出层。每一层都包含一定数量的神经元。MLP 可以用于解决各种复杂的非线性问题。
2.反向传播算法:反向传播是一种在神经网络中用于训练模型的主要算法。它通过计算损失函数对模型参数的梯度,然后使用这些梯度来更新参数,从而最小化损失。
3.数据预处理:在机器学习任务中,数据预处理是非常重要的一步。这个实验中,使用了归一化来处理数据,使得数据的均值为0,且所有特征的取值范围都在 [-1, 1] 之间。
4.学习率退火策略:在神经网络的训练过程中,适当地调整学习率可以提高训练效果和稳定性。这个实验中,使用了一种名为 “annealing” 的学习率退火策略
实 验 设 备 与 器 件:
PC机、 MATLAB软件。
实 验 内 容 与 参 数 分 析
第一步
使用halfmoon 函数来生成半月形数据。这个函数可能是用来生成具有特定半径、宽度和距离的两个半月形数据集。这些数据集可能会被用于训练和测试一个多层感知器分类器。
半月半径 (rad): 10
半月宽度 (width): 6
两个半月之间的距离 (dist): -2
训练集样本数量 (num_tr): 300
测试集样本数量 (num_te): 2000
总样本数量 (num_samp): 2300
 第二步
第二步
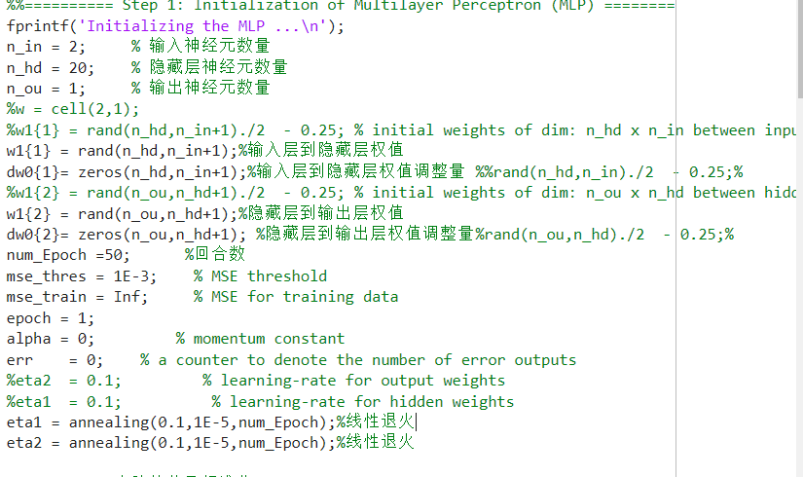
1.神经元数量:输入层 (n_in)、隐藏层 (n_hd) 和输出层 (n_ou) 的神经元数量。
2.权重和权重调整量:输入层到隐藏层的权重 (w1{1}) 和权重调整量 (dw0{1}),以及隐藏层到输出层的权重 (w1{2}) 和权重调整量 (dw0{2})。
3.训练参数:最大迭代次数 (num_Epoch)、均方误差阈值 (mse_thres)、动量常数 (alpha),以及输入层到隐藏层的学习率 (eta1) 和隐藏层到输出层的学习率 (eta2)。
这些参数的设置可能会影响到 MLP 的训练效果和稳定性
第三步

1.计算均值:首先,计算 data 的前两行(即所有样本的特征)的均值 mean1,并在其后添加一个0,形成一个新的向量 mean1。
2.中心化数据:然后,对于每一个样本,从其特征值中减去 mean1,得到新的数据集 nor_data。这一步是为了将数据集中心化,即使得数据的均值为0。
3.计算最大值:接着,计算 nor_data 的前两行(即所有样本的特征)的绝对值的最大值 max1,并在其后添加一个1,形成一个新的向量 max1。
4.归一化数据:最后,对于每一个样本,将其特征值除以 max1,得到新的数据集 nor_data。这一步是为了将数据的范围缩放到 [-1, 1]。
这样处理后,数据的均值为0,且所有特征的取值范围都在 [-1, 1] 之间,有助于提高神经网络的训练效果和稳定性。
第四步
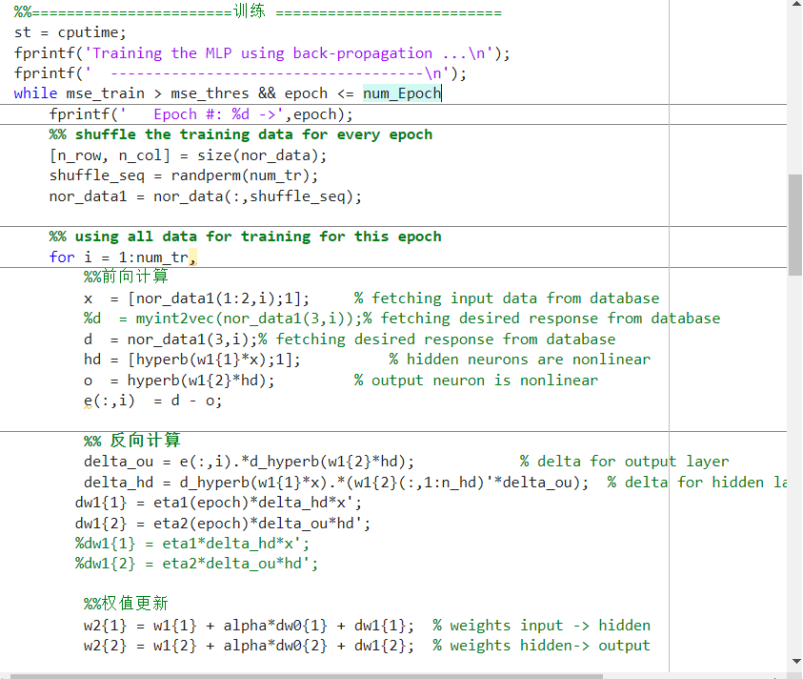
这段代码的主要目的是使用反向传播算法训练多层感知器(MLP)。以下是代码的主要步骤和原理:
1.开始训练:首先,记录开始训练的时间,并打印出一些信息。
2.训练循环:然后,进入一个循环,直到训练数据的均方误差小于预设阈值或达到最大迭代次数为止。
3.数据洗牌:在每个迭代开始时,对训练数据进行洗牌,以避免模型过拟合。
4.前向传播:对于每个训练样本,首先进行前向传播,计算隐藏层和输出层的神经元的输出。
5.计算误差:然后,计算模型的输出与期望输出之间的误差。
6.反向传播:接着,利用误差进行反向传播,计算输出层和隐藏层的 delta 值。
7.权重更新:然后,根据 delta 值和学习率,更新权重。
8.计算 MSE:在每个迭代结束时,计算训练数据的均方误差,并打印出来。
9.结束训练:最后,当满足停止条件时,打印出训练的样本数、进行的迭代次数和训练的时间消耗。
这个过程是神经网络训练的基本步骤,通过这个过程,MLP 能够学习到从输入到输出的映射关系
参数调试和运行截图
1.回合数: 50, 测试点数 : 2000, 错误点数 : 0 ( 0.00%)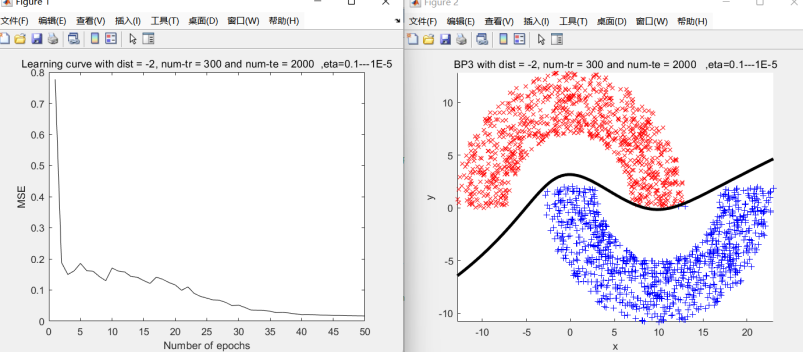
2.回合数: 25, 测试点数 : 3000, 输入神经元数量:2,隐藏层神经元数量:20,
输出神经元数量:1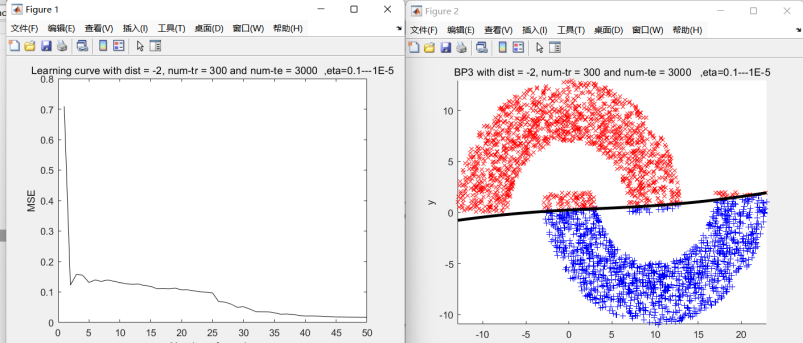 3.回合数: 50, 测试点数 : 6000 误码点数:0 ( 0.00%)
3.回合数: 50, 测试点数 : 6000 误码点数:0 ( 0.00%)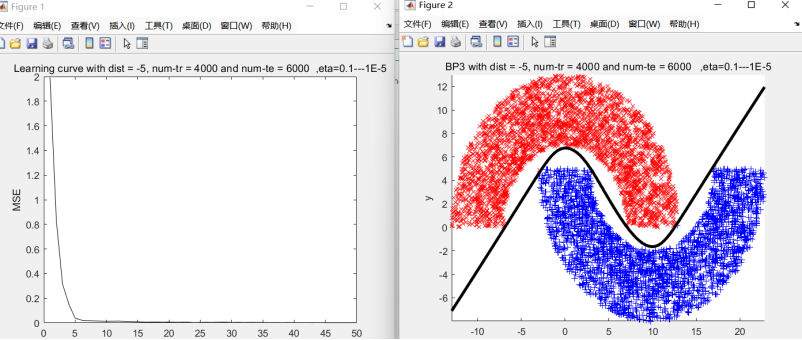
实验总结
这个实验成功地使用了多层感知器(MLP)进行了分类任务。我们生成了半月形数据,对其进行了归一化处理,然后使用反向传播算法训练了 MLP。我们还采用了学习率退火策略来优化训练过程。这个实验帮助我们深入理解了 MLP、反向传播算法以及数据预处理和学习率调整的重要性
实验代码
close all;
%%=========== Step 0: Generating halfmoon data ============================
rad = 10; % central radius of the half moon
width = 6; % width of the half moon
dist = -2; % distance between two half moons
num_tr = 300; % 训练集
num_te = 2000; % 测试集
num_samp = num_tr+num_te; % 样本数量
fprintf('Multiple Layer Perceptron for Classification\n');
fprintf('_________________________________________\n');
fprintf('Generating halfmoon data ...\n');
fprintf(' ------------------------------------\n');
fprintf(' Points generated: %d\n',num_samp);
fprintf(' Halfmoon radius : %2.1f\n',rad);
fprintf(' Halfmoon width : %2.1f\n',width);
fprintf(' Distance : %2.1f\n',dist);
fprintf(' ------------------------------------\n');
[data, data_shuffled] = halfmoon(rad,width,dist,num_samp);
%%========== Step 1: Initialization of Multilayer Perceptron (MLP) ========
fprintf('Initializing the MLP ...\n');
n_in = 2; % 输入神经元数量
n_hd = 20; % 隐藏层神经元数量
n_ou = 1; % 输出神经元数量
%w = cell(2,1);
%w1{1} = rand(n_hd,n_in+1)./2 - 0.25; % initial weights of dim: n_hd x n_in between input layer to hidden layer
w1{1} = rand(n_hd,n_in+1);%输入层到隐藏层权值
dw0{1}= zeros(n_hd,n_in+1);%输入层到隐藏层权值调整量 %%rand(n_hd,n_in)./2 - 0.25;%
%w1{2} = rand(n_ou,n_hd+1)./2 - 0.25; % initial weights of dim: n_ou x n_hd between hidden layer to output layer
w1{2} = rand(n_ou,n_hd+1);%隐藏层到输出层权值
dw0{2}= zeros(n_ou,n_hd+1); %隐藏层到输出层权值调整量%rand(n_ou,n_hd)./2 - 0.25;%
num_Epoch =50; %回合数
mse_thres = 1E-3; % MSE threshold
mse_train = Inf; % MSE for training data
epoch = 1;
alpha = 0; % momentum constant
err = 0; % a counter to denote the number of error outputs
%eta2 = 0.1; % learning-rate for output weights
%eta1 = 0.1; % learning-rate for hidden weights
eta1 = annealing(0.1,1E-5,num_Epoch);%线性退火
eta2 = annealing(0.1,1E-5,num_Epoch);%线性退火
%%========= 去除均值及标准化=========
mean1 = [mean(data(1:2,:)')';0];
for i = 1:num_samp,
nor_data(:,i) = data_shuffled(:,i) - mean1;
end
max1 = [max(abs(nor_data(1:2,:)'))';1];
for i = 1:num_samp,
nor_data(:,i) = nor_data(:,i)./max1;
end
%%=======================训练 ==========================
st = cputime;
fprintf('Training the MLP using back-propagation ...\n');
fprintf(' ------------------------------------\n');
while mse_train > mse_thres && epoch <= num_Epoch
fprintf(' Epoch #: %d ->',epoch);
%% shuffle the training data for every epoch
[n_row, n_col] = size(nor_data);
shuffle_seq = randperm(num_tr);
nor_data1 = nor_data(:,shuffle_seq);
%% using all data for training for this epoch
for i = 1:num_tr,
%%前向计算
x = [nor_data1(1:2,i);1]; % fetching input data from database
%d = myint2vec(nor_data1(3,i));% fetching desired response from database
d = nor_data1(3,i);% fetching desired response from database
hd = [hyperb(w1{1}*x);1]; % hidden neurons are nonlinear
o = hyperb(w1{2}*hd); % output neuron is nonlinear
e(:,i) = d - o;
%% 反向计算
delta_ou = e(:,i).*d_hyperb(w1{2}*hd); % delta for output layer
delta_hd = d_hyperb(w1{1}*x).*(w1{2}(:,1:n_hd)'*delta_ou); % delta for hidden layer
dw1{1} = eta1(epoch)*delta_hd*x';
dw1{2} = eta2(epoch)*delta_ou*hd';
%dw1{1} = eta1*delta_hd*x';
%dw1{2} = eta2*delta_ou*hd';
%%权值更新
w2{1} = w1{1} + alpha*dw0{1} + dw1{1}; % weights input -> hidden
w2{2} = w1{2} + alpha*dw0{2} + dw1{2}; % weights hidden-> output
%% 权值单步移动
dw0 = dw1;
w1 = w2;
end
mse(epoch) =sum(mean(e'.^2));
mse_train = mse(epoch);
fprintf('MSE = %f\n',mse_train);
epoch = epoch + 1;
end
fprintf(' Points trained : %d\n',num_tr);
fprintf(' Epochs conducted: %d\n',epoch-1);
fprintf(' Time cost : %4.2f seconds\n',cputime - st);
fprintf(' ------------------------------------\n');
%%=============== 绘学习曲线 =================================
figure;
plot(mse,'k');
title(['Learning curve with dist = ',num2str(dist), ', num-tr = ',...
num2str(num_tr), ' and num-te = ',num2str(num_te),' ,eta=0.1---1E-5']);
xlabel('Number of epochs');ylabel('MSE');
%%================= Colormaping the figure here ===========================
%%=== In order to avoid the display problem of eps file in LaTeX. =========
figure;
hold on;
xmin = min(data_shuffled(1,:));
xmax = max(data_shuffled(1,:));
ymin = min(data_shuffled(2,:));
ymax = max(data_shuffled(2,:));
[x_b,y_b]= meshgrid(xmin:(xmax-xmin)/100:xmax,ymin:(ymax-ymin)/100:ymax);
z_b = 0*ones(size(x_b));
%wh = waitbar(0,'Plotting testing result...');
for x1 = 1 : size(x_b,1)
for y1 = 1 : size(x_b,2)
input = [(x_b(x1,y1)-mean1(1))/max1(1);(y_b(x1,y1)-mean1(2))/max1(2);1];
hd= [hyperb(w1{1}*input);1];
z_b(x1,y1) = hyperb(w1{2}*hd);
end
%waitbar((x1)/size(x,1),wh)
%set(wh,'name',['Progress = ' sprintf('%2.1f',(x1)/size(x,1)*100) '%']);
end
%% Adding colormap to the final figure
%figure;
%sp = pcolor(x_b,y_b,z_b);
%load red_black_colmap;
%colormap(red_black);
shading flat;
set(gca,'XLim',[xmin xmax],'YLim',[ymin ymax]);
%%==========================测试======================================
fprintf('Testing the MLP ...\n');
for i = num_tr+1:num_samp,
x = [nor_data(1:2,i);1];
hd = [hyperb(w1{1}*x);1];
o(:,i)= hyperb(w1{2}*hd);
xx = max1(1:2,:).*x(1:2,:) + mean1(1:2,:);
if o(:,i)>0%myvec2int(o(:,i)) == 1,
plot(xx(1),xx(2),'rx');
end
if o(:,i)<0%myvec2int(o(:,i)) == -1,
plot(xx(1),xx(2),'b+');
end
end
xlabel('x');ylabel('y');
title(['BP3 with dist = ',num2str(dist), ', num-tr = ',...
num2str(num_tr), ' and num-te = ',num2str(num_te),' ,eta=0.1---1E-5']);
% Calculate testing error rate
for i = num_tr+1:num_samp,
if abs(mysign(o(i)) - nor_data(3,i)) > 1E-6,
err = err + 1;
end
end
fprintf(' ------------------------------------\n');
fprintf(' Points tested : %d\n',num_te);
fprintf(' Error points : %d (%5.2f%%)\n',err,(err/num_te)*100);
fprintf(' ------------------------------------\n');
fprintf('Mission accomplished!\n');
fprintf('_________________________________________\n');
%%======================= 绘决策边界 ==========================
%% Adding contour to show the boundary
contour(x_b,y_b,z_b,[0 0],'k','Linewidth',3);
%contour(x_b,y_b,z_b,[-1 -1],'k:','Linewidth',2);
%contour(x_b,y_b,z_b,[1 1],'k:','Linewidth',2);
set(gca,'XLim',[xmin xmax],'YLim',[ymin ymax]);
%% That's all, folks

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)