计算机系统结构课程总结(合成)
数据表示能由硬件直接辨认,可以被指令系统直接调用的数据类型。缩短程序运行时间减少CPU与主存的通信通用性和利用率发展趋势:数据表示在不断上移,即更多的数据类型用硬件实现。理论最短平均码长理论最短平均码长l=−∑i=1N(Pi⋅log2Pi)理论最短平均码长l=−∑i=1N(Pi⋅log2Pi)理论最短平均码长l=\begin{equation*}-\sum_{i=...
※20%与80%规律
最常适用的是较简单的指令,仅占指令总数的20%,但在程序中出现的频率却80%。
较少使用的是较复杂的指令,占指令总数20%,为了实现其功能而设计的微程序代码却占总代码的80%。
数据表示
能由硬件直接辨认,可以被指令系统直接调用的数据类型。
- 缩短程序运行时间
- 减少CPU与主存的通信
- 通用性和利用率
发展趋势:数据表示在不断上移,即更多的数据类型用硬件实现。
理论最短平均码长
这里的PiPi<script type="math/tex" id="MathJax-Element-27">P_i</script>是概率,不过计算时用频率pipi<script type="math/tex" id="MathJax-Element-28">p_i</script>代替了。
编码冗余量
下面的定长编码冗余量一般在35%,Huffman编码冗余量一般在1%,Huffman扩展编码冗余量可控制约11.4%。
[1]定长编码
译码简单并且规整,但浪费信息量。如有N种指令,操作码位数为:
[2]Huffman编码
出现概率大的用短编码,概率小的用长编码。每次选两个概率最小的结点,按一定规则(一般小的在左边)合成一个新的概率结点,投入原集合继续选择。最终root结点概率应为1.00。
为Huffman树设定编码时,一般左0右1。
[3]Huffman扩展编码
如1-2-3-5扩展编码: 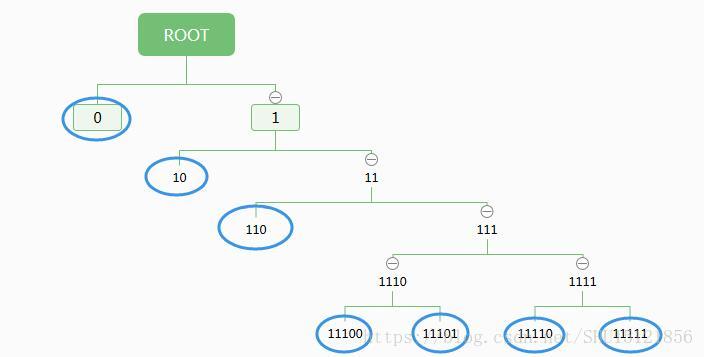
如2-4扩展编码: 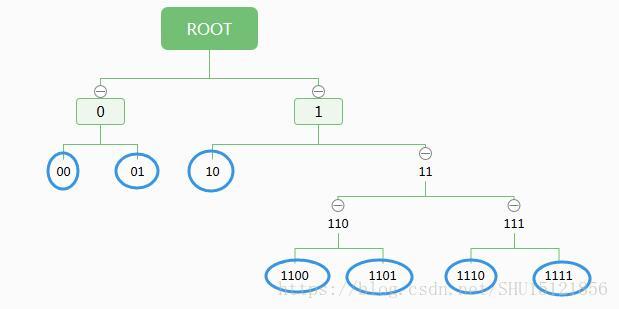
Huffman扩展编码的实用性较高。为了便于实现分级译码,一般采用等长扩展法,即展开结点的层级数之间是等差数列。
地址码优化设计
定长编码、Huffman编码、Huffman扩展编码都是指操作码的设计。
地址码一般有0/1/2/3地址这四种形式。应从程序存储容量和程序执行速度这两个方面去考虑用多少个地址。PPT上的图: 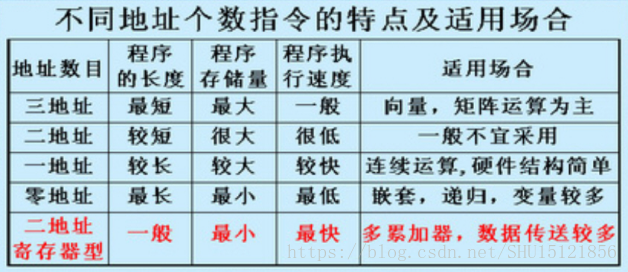
缩短地址码的方法:间接寻址、变址寻址、寄存器间接寻址。
RISC
CISC是复杂指令集计算机,功能强大,但指令繁多;RISC是精简指令计算机,只保留常见指令,采用32位固定长度的指令。
而RISC的思想精髓就在于减少CPI。
总线
总线:计算机中各模块间各种信号线的集合。
总线分类:
- 片总线:即元件级总线,包括DBUS、ABUS、CBUS。
- 内总线:即系统总线,是系统内插件间的并行通信总线,如。
- 外总线:即通信总线,系统与系统之间,接口与外设之间通信。
总线工作阶段:
- 申请分配阶段
- 寻址阶段
- 数据交换阶段
- 撤销阶段
同步和异步通信
同步通信:使用系统时钟,模块之间的通信传输周期固定。
异步通信:不使用系统时钟,增设请求线和响应线来通信。
半同步通信:介于上面两者之间,在同步通信方式里增加一条控制信号线。
分离式通信:把一个读周期一分为二,把寻址阶段作为前一个传输子周期,数据交换阶段作为后一个传输子周期。
总线仲裁
当多个模块同时申请使用总线以成为主模块,就会发生各模块对总线的争用问题,总线仲裁就是判断把总线使用权给谁。
总线仲裁与中断很类似,但是中断可以高优先级立即打断低优先级,但是总线使用时这种打断会出现问题,必须等待总线操作完成才能重新分配总线使用权,所以需要添加控制信号。
串行总线仲裁
优先权排列按链接的位置决定,每个模块在它前面的(高优先级的)模块没有使用总线时才能申请使用。
- 固定式优先权
- 转换式优先权
并行总线仲裁
利用外部逻辑的硬件编码来进行模块的判优。
优点:要改变优先权只要改变接入外部逻辑的申请信号次序。
存储器指标计算
(1)
(2)
(3)
很多时候数据总线宽度ww<script type="math/tex" id="MathJax-Element-36">w</script>和存储器字长 <script type="math/tex" id="MathJax-Element-37">W</script>是一样的。
(4)
(5)
其中RiRi<script type="math/tex" id="MathJax-Element-40">R_i</script>是命中MiMi<script type="math/tex" id="MathJax-Element-41">M_i</script>的次数。
(6)
存储层次的特性
- 包含性:所具备的信息项满足Mi⊂Mi+1Mi⊂Mi+1<script type="math/tex" id="MathJax-Element-43">M_i \subset M_{i+1}</script>。
- 一致性:同一个信息项与最底层(后援存储器)上的副本一致。
- 写直达:MiMi<script type="math/tex" id="MathJax-Element-44">M_i</script>中的修改在Mi+1Mi+1<script type="math/tex" id="MathJax-Element-45">M_{i+1}</script>中立即修改。
- 写回:MiMi<script type="math/tex" id="MathJax-Element-46">M_i</script>中的修改,等到该信息项被换掉时,再在Mi+1Mi+1<script type="math/tex" id="MathJax-Element-47">M_{i+1}</script>中将其修改。
- 局部性
- 时间局部性:因为程序中存在循环。
- 空间局部性:某个操作总在某一区域集中访问,因为数据时常连续存放。
- 顺序局部性:因为程序大多顺序执行。
中断
定义:CPU中止正在执行的任务,转而处理随机提出的请求,处理完毕再返回原程序继续执行。
- 中断源:引起中断的各种事件。
- 可屏蔽中断:可以通过CPU关中断来不响应该中断。
- 非屏蔽中断:必须响应。
- 中断优先级
- 软硬件分配
- 中断响应事件:从中断源发出请求到CPU响应并转向该中断服务程序入口地址所用的时间。
- 灵活性:硬件实现的中断速度快、灵活性差;软件实现的中断与之相反。
通道处理机
定义:能够执行有限个I/O指令并能与多台外设共享的专用处理机。
- 字节多路通道:分时、串行,为多台中低速外设服务。
- 选择通道:独占直至传输完成,为高速外设服务。
- 数组多路通道:结合以上两种通道,使用较普遍。
通道指标计算
(0)指标
TS:选择设备用时。TS:选择设备用时。<script type="math/tex" id="MathJax-Element-48">T_S:选择设备用时。</script>
TD:传送1字节用时。TD:传送1字节用时。<script type="math/tex" id="MathJax-Element-49">T_D:传送1字节用时。</script>
P:通道上连接外设数。P:通道上连接外设数。<script type="math/tex" id="MathJax-Element-50">P:通道上连接外设数。</script>
n:每台外设都传输n字节。n:每台外设都传输n字节。<script type="math/tex" id="MathJax-Element-51">n:每台外设都传输n字节。</script>
T∗:∗型通道连接P台外设,每台外设传送n字节用时。T∗:∗型通道连接P台外设,每台外设传送n字节用时。<script type="math/tex" id="MathJax-Element-52">T_*:*型通道连接P台外设,每台外设传送n字节用时。</script>
fmax⋅∗:∗型通道的最大流量。fmax⋅∗:∗型通道的最大流量。<script type="math/tex" id="MathJax-Element-53">f_{max\cdot *}:*型通道的最大流量。</script>
(1)字节多路通道
(2)选择通道
(3)数组多路通道
假设数组多路通道一次工作传送k字节的数据块。
I/O处理机
通道不能看成独立的处理机,也不能实现完全的并行操作,故引入IOP全权负责I/O和管理外设。IOP具有自己的专用存储器(局部MEM),不必通过主存(System MEM)就能完成与外设的数据交换。
- 共享主存的IOP
- 不共享主存的IOP

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)