从头理解大语言模型
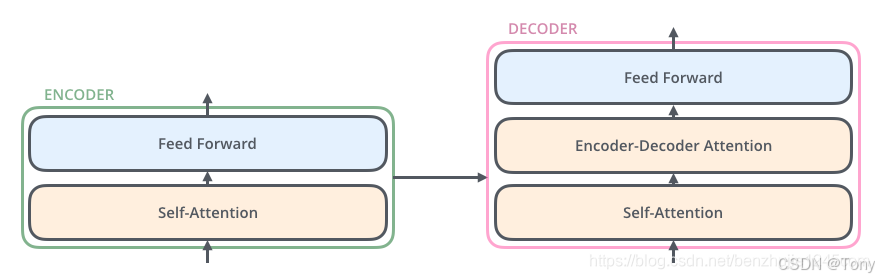
Transformer本质上是一个Encoder到Decoder的框架,也就是将某一种语言的句子的作为输入经过Transformer将其翻译成另一种语言的句子作为输出。主要包含的两个组件就是编码组件和解码组件:编码组件由多层Encoder组成,解码组件也是由相同层数的Decoder组成。每个Encoder由两个子层组成:自注意力层和前馈神经网络,每个Encoder组成部件都一样,只不过使用的参数各
1.Transformer模型
Transformer本质上是一个Encoder到Decoder的框架,也就是将某一种语言的句子的作为输入经过Transformer将其翻译成另一种语言的句子作为输出。
主要包含的两个组件就是编码组件和解码组件:编码组件由多层Encoder组成,解码组件也是由相同层数的Decoder组成。每个Encoder由两个子层组成:自注意力层和前馈神经网络,每个Encoder组成部件都一样,只不过使用的参数各不相同。Encoder首先流入自注意力层,他的作用是当翻译句子中的某一个词的时候,不仅仅关注当前的词,还会关注其他词的信息,然后输出到前馈网络中。Decoder中也有这两层,但是会多出一个Encoder-Decoder注意力层,其作用是来帮助Decoder关注输入句子的相关部分。
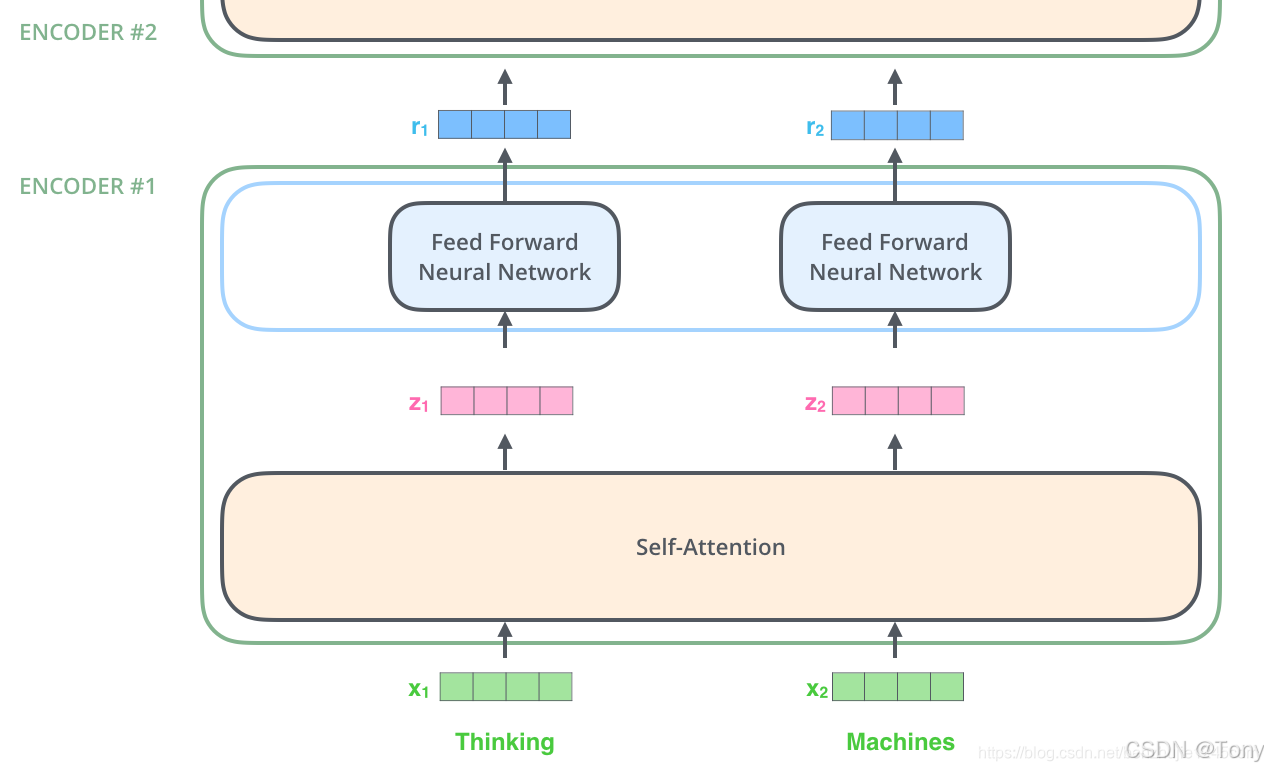
数据流动:使用词嵌入向量(Embedding)将每个词转换为一个词向量,维度是512,传入到自注意力层,然后传递到前馈神经网络,最后将输出传递到下一个Encoder:
1.1什么是自注意力机制?
首先举个例子,假设我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired
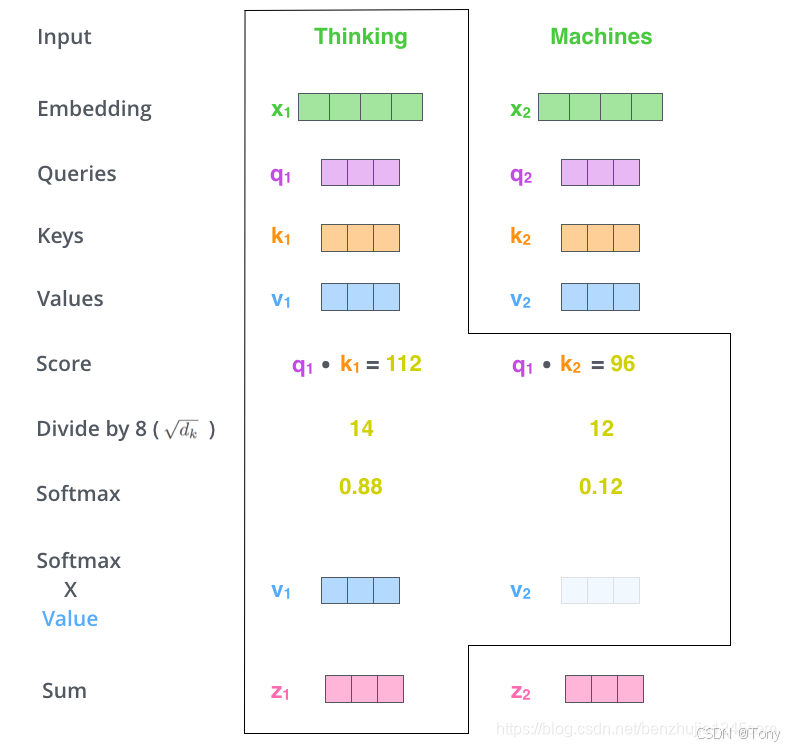
对于人类来说,句子中的it很容易就被理解成前面的主语animal,但是对于算法来说,可能就无法理解,自注意力机制的作用就是让模型再处理it这个词的时候能够关注到句子中的其他词,将it和animal关联起来,其具体结构如下图所示:
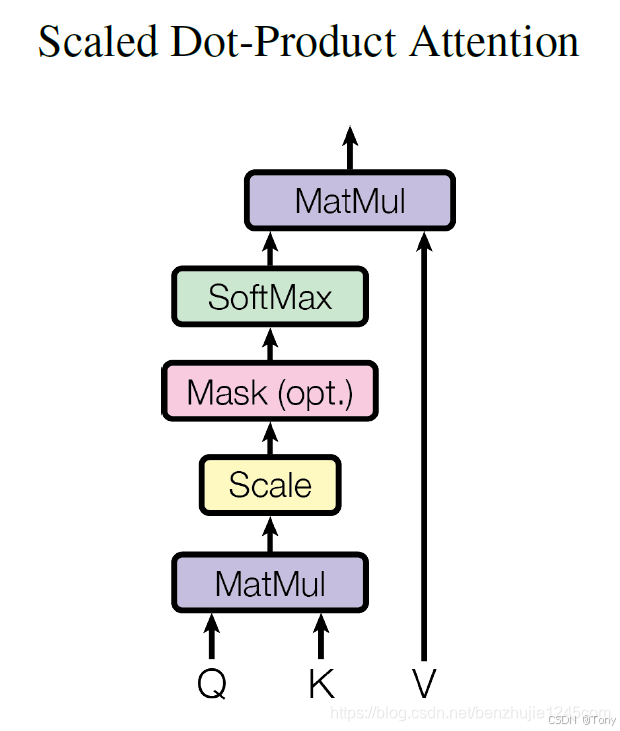
对于自注意力来说,Q(Query),K(Key)和 V(Value)三个矩阵均来自同一个输入,计算过程是首先计算Q和K的点积,为了防止其过大所以会除以根号下dk,dk是Key的向量维度,然后利用Softmax作归一化,再乘以矩阵V就得到权重求和:
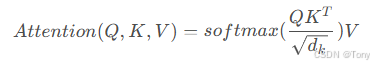
那么QKV又是如何得到的呢,其实就是通过矩阵变换得到的,将嵌入的词向量与我们训练好的三个权重矩阵相乘即可:
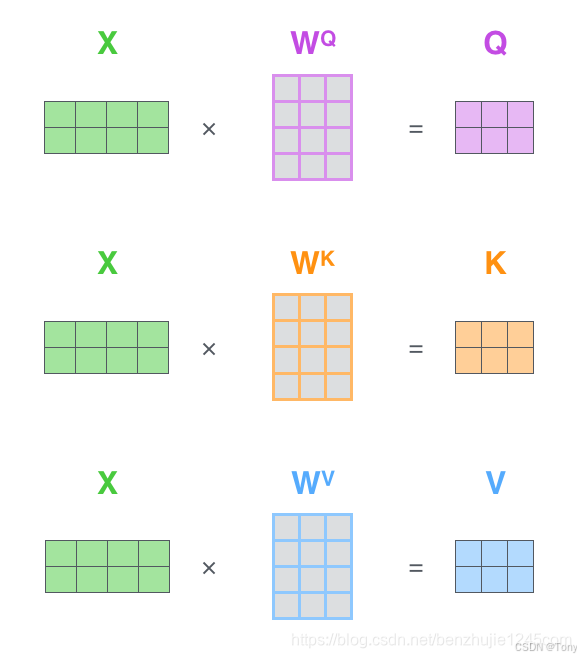
比如我们正在计算第一个词“Thinking” 的自注意力。我们需要根据 “Thinking” 这个词,对句子中的每个词都计算一个分数。这些分数决定了我们在编码 “Thinking” 这个词时,需要对句子中其他位置的每个词放置多少的注意力,分数是由Q点积K得到的,之后除以根号下向量维度,再通过Softmax层,Softmax分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力,之后将每个Softmax分数分别与每个Value向量相乘,对于分数高的位置,相乘后的值就越大,我们把更多的注意力放在它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大,我们就可以忽略这些位置的词,将加权Value向量(即上一步求得的向量)求和。这样就得到了自注意力层在这个位置的输出:
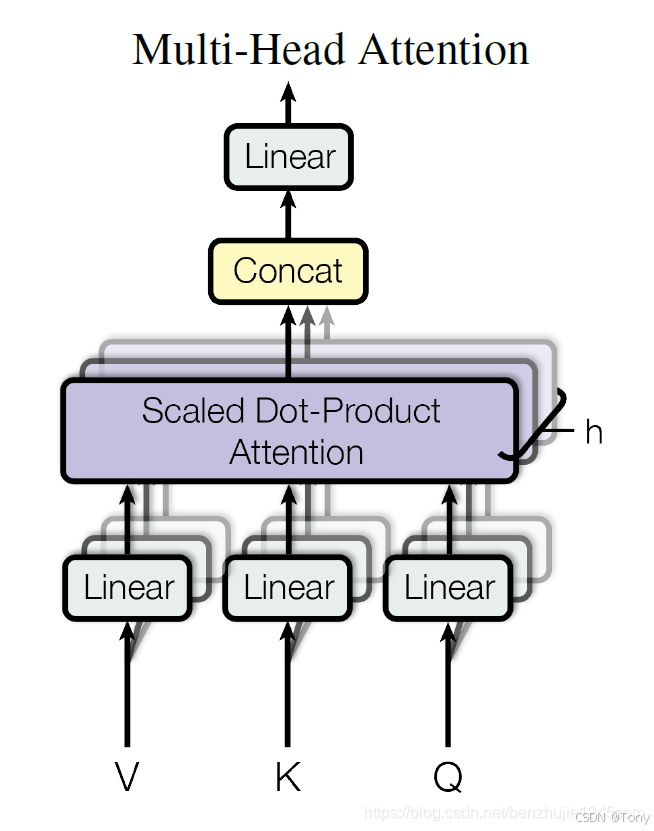
在Transformer论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。通过h个个不同的线性变换对Query、Key和 Value进行映射;然后,将不同的Attention拼接起来;最后,再进行一次线性变换:
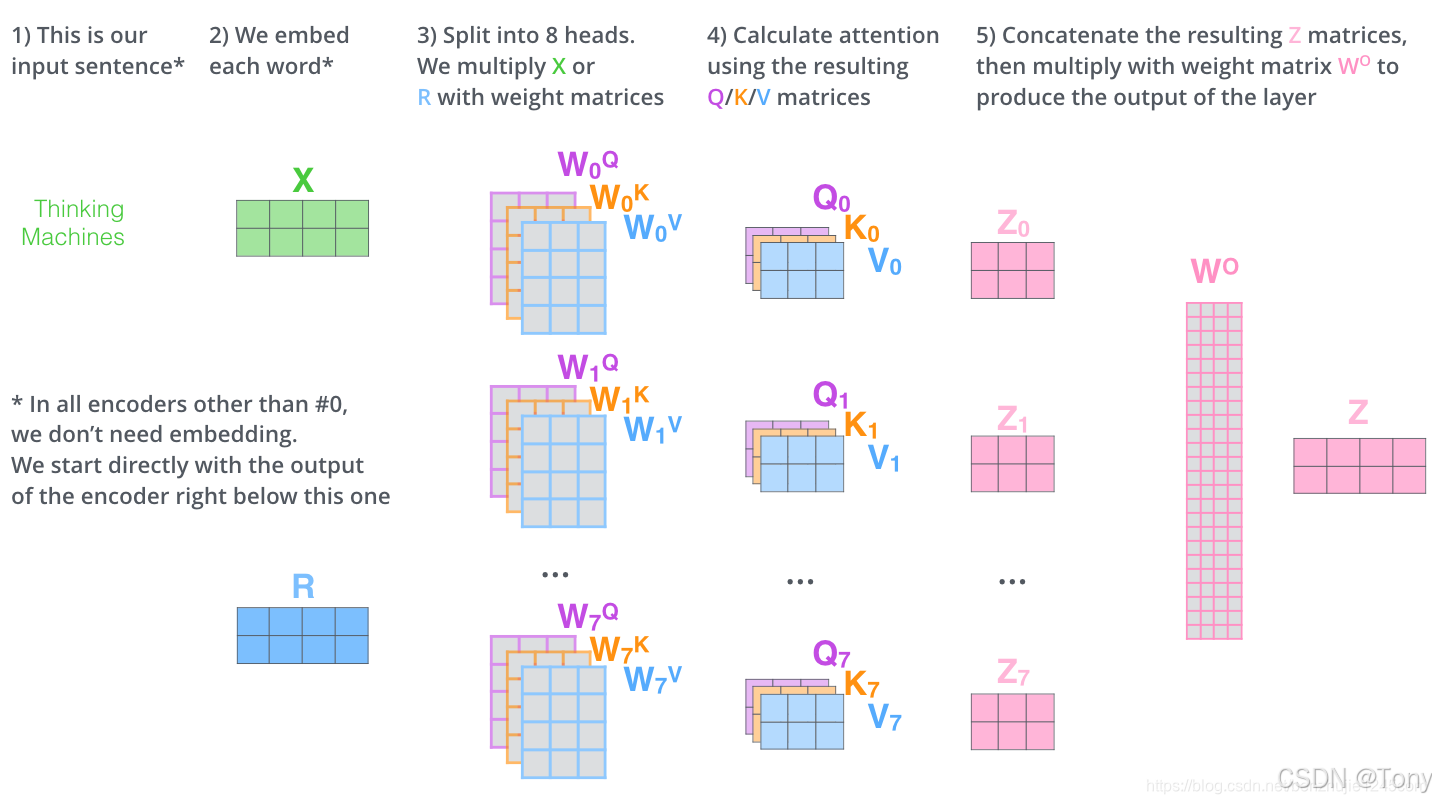
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。在多头注意力下,我们为每组注意力单独使用不同的Query、Key和Value权重矩阵,从而得到不同的Query、Key和Value矩阵,使用不同的权重矩阵进行8次自注意力计算,就可以得到8个不同的Z矩阵,因为前馈神经网络层接收的是1个矩阵(每个词的词向量),而不是上面的8个矩阵。因此,我们需要一种方法将这8个矩阵整合为一个矩阵,同样也是进行矩阵变换,乘以一个矩阵就OK了,总体过程如下图所示:
1.2前馈神经网络
前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成,先线性变换,然后ReLU非线性,再线性变换。第一个全连接层的激活函数为ReLU激活函数,在每个Encoder和Decoder中,虽然这个全连接前馈网络结构相同,但是不共享参数。Encoder结构中有一个需要注意的细节:每个Encoder的每个子层都有一个残差连接,再执行一个层标准化操作。这两层网络就是为了将输入的Z映射到更加高维的空间中然后通过非线性函数ReLU进行筛选,筛选完后再变回原来的维度。经过6个Encoder后输入到Decoder中。
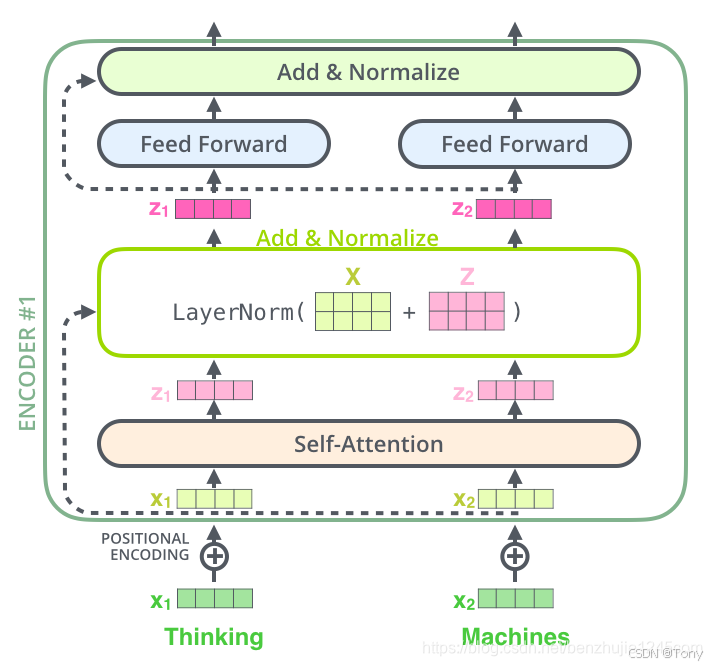
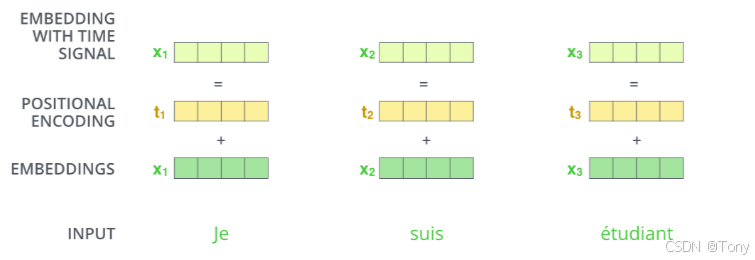
1.3位置编码
到目前为止,我们所描述的模型中缺少一个东西:表示序列中词顺序的方法。为了解决这个问题,Transformer 模型为每个输入的词嵌入向量添加一个向量。这些向量遵循模型学习的特定模式,有助于模型确定每个词的位置,或序列中不同词之间的距离:
1.4解码器
在Transformer结构中,Encoder输出的是一系列上下文的隐藏关系,这些状态捕捉了输入序列的全局信息。在完成了编码阶段后,开始解码阶段。解码阶段的每个时间步都输出一个元素。接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。在整个过程的开始,会使用Mask掩码:它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种mask,分别是Padding Mask和Sequence Mask。
Padding Mask:什么是Padding mask呢?因为每个批次输入序列的长度是不一样的,所以我们要对输入序列进行对齐。具体来说,就是在较短的序列后面填充0(但是如果输入的序列太长,则是截断,把多余的直接舍弃)。因为这些填充的位置,其实是没有什么意义的,所以我们的 Attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。具体的做法:把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过Softmax后,这些位置的概率就会接近 0。
Sequence mask:sequence mask是为了使得decoder不能看见未来的信息。对于一个序列,在time_step为t的时刻,我们的解码输出应该只能依赖于t时刻之前的输出,而不能依赖t之后的输出。因此我们需要想一个办法,把t之后的信息给隐藏起来。这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
简单来说就是在掩码过程中只能看到当前的token和之前的token,防止看到未来的信息,保证自回归生成,之后通过交叉注意力机制,来正确生成目标序列。保证消息的正确性需要QKV来确定,QKV不是简单的Encoder直接生成的,而是通过Encoder输出的隐藏状态,在Decoder计算交叉注意力的时候得到。这里的Q则是Decode自己生成的。decoder的任务是根据目标序列的部分信息,逐步生成完整的翻译或文本。
用个最简单的例子来说明:输入的句子是:
I love NLP
Encoder输出:对I love NLP进行编码,得到每个token的隐藏状态。
Decoder逐步生成:
第一步:Decoder只看到起始符,预测“我”
第二步:Decoder看到起始符跟我,预测喜欢
第三步:Decoder看到起始符,我跟喜欢,预测NLP
第四步:Decoder看到起始符,我,喜欢跟NLP,预测结束
总结一下完整流程:
Encoder:
输入:源语言序列的词向量
计算:经过多层自注意力和前馈神经网络
输出:每个词向量的隐藏状态
Decoder:
输入:目标序列的前半部分(训练时)或者过去已生成的token(推理时)
计算:先Mask自注意力,然后再查询Encoder的信息,最后通过前馈神经网络
输出:经过Softmax变成下一个token的概率分布
Encoder处理输入,生成隐藏状态(类似于一个数据库,存储源语言的信息)。
Decoder通过自己当前的状态计算Q查询 Encoder 提供的信息)。
Decoder的K/V是由Encoder的输出计算得到的(存储的信息被查询)。
这种设计让 Decoder 能够根据自己的解码进度,动态查询 Encoder 的信息,生成合理的输出。
2.GPT3理解
GPT是一种基于Transformer的预训练语言模型,本质上是一个纯Decoder结构的Transformer,采用了多层的Decoder堆叠而成,通过自回归的方式进行文本生成,GPT3最大版本有96层Transformer Decoder,每层包括掩码自注意力,前馈神经网络和残差连接+层归一化。
具体每一层包括:
1.输入Enbedding:输入token通过一个可学习嵌入层转换为向量并使用可学习的位置编码,表示token的位置
2.采用掩码自注意力,确保模型只能看到当前token及其之前的token
3.前馈神经网络:使用激活函数引入非线性特征
4.残差连接与归一化:进一步提高梯度稳定性,防止梯度消失
5.输出层:通过线性变换+Softmax,得到词表上每个token的概率分布,选取概率最大的token作为下一个输出
2.1GPT3如何生成文本
GPT3采用自回归生成方式,一次预测下一个token
1.输入一个prompt(如“Hello,how are you”)
2.模型计算输出分布,选择下一个token(如“?”)
3.将这个token作为新输入,继续预测
4.重复以上步骤,直到达到最大长度或遇到终止符
2.2GPT3的训练方式
GPT3在大规模无监督数据集上进行自回归语言建模
训练目标:最大化下一个token发生的概率进行训练,目的是在给定上下文的情况下预测合理的下一个token
训练方式:采用自监督学习
输入:一个文本的片段,例如:
“The capital of France is”
模型学习:预测下一个token“Paris”
P(Paris | The capital of France is)
正确答案的概率增加,错误答案的概率减少:
P(Paris) ↑, P(London) ↓, P(Tokyo) ↓
GPT3采用的是交叉熵损失函数来衡量模型预测的token和真实token之间的误差
总结一下完整的流程:
GPT3的输入是大量文本组成的语料库,这些文本被转换成token序列,然后输入GPT3,简单而言就是大量的句子或者是文本片段。每个token被转换成向量并加入位置编码,传入多层的Transformer Decoder处理。计算输出token的概率,之后在进行损失计算和梯度下降,可以将其理解成一个深度学习和transform结合的系统,通过深度学习loss调整概率根据输入文本Decoder生成最后结果
3.T5语言模型理解
T5是Google研发的一个Encoder-Decoder结构的Transformer语言模型,专用于各种NLP任务,其核心思想是:将所有NLP任务统一转换成“文本到文本”的格式,这样同一个模型架构就可以处理不同的任务。
3.1T5的架构
Encoder:负责读取输入文本,提取语义信息,注意这里采用的是双向注意力机制,所有token可以相互关注,没有方向限制,能够更好的获取全局信息
Decoder:负责生成输出文本,类似GPT,使用自回归方式,并且确保只关注过去的token,但注意,在T5中使用了交叉注意力机制用来获取Encoder中的隐藏信息,但是GPT3没有用,GPT3只用了掩码注意力
举一个具体的例子:
Encoder:
1.输入:"translate English to German: Hello"
2.经过嵌入(Embedding)+ 位置编码(Positional Encoding)
3.经过多层 Encoder(Self-Attention + FFN)
4.得到最终的隐藏表示 Hencoder
Decoder:
1.以特殊 token作为起始输入。
2.逐步生成“hallo”
3.通过交叉注意力机制,Decoder 查询 Encoder 的信息,确保正确的文本生成。
3.2T5的训练方式
预训练:
1.给定一段文本,随机隐藏部分句子:
"The cat sat on the mat and the dog played outside."
2.训练输入
"The cat <extra_id_0> the dog played outside."
3.目标输出
"<extra_id_0> sat on the mat and"
T5不像bert一样Mask掉单个token,而是Mask掉一整个短语或者句子,这样可以让T5学会更长距离的依赖关系,提高对文本结构的理解能力。
计算损失:
T5使用交叉熵损失来衡量模型的预测结果与真实文本之间的误差 ,首先预测概率分布,然后再使用多token计算损失
总结一下完整的流程:
T5 采用Encoder-Decoder结构,先通过Encoder的双向自注意力理解输入文本,再通过Decoder 的自回归生成+交叉注意力逐步生成目标文本,并使用交叉熵损失进行优化,实现通用的文本到文本(Text-to-Text)任务处理。
4.PaLM语言模型理解
PaLM是PaLM(Pathways Language Model)是Google于2022年发布的超大规模语言模型,基于Transformer架构,但结合了Pathways训练方法,使其在多任务学习、推理能力和代码生成方面达到了前所未有的水平。
Pathways是Google研发的高效分布式训练系统,它能够:并行训练多个任务,提高计算效率;减少计算资源浪费;让一个模型同时适应不同的任务,而不是单独训练多个模型
4.1PaLM的架构
PaLM采用仅Decoder结构,并行化训练,减少计算资源消耗,采用更高效的自注意力机制运算,计算更稳定且用SwiGLU取代了传统的ReLU,提高模型的表达能力
4.2PaLM的训练方式
PaLM的训练数据包括:互联网文本,新闻,书籍,代码数据,多语言数据,数字推理数据等
训练方法:使用自回归语言建模,也是基于前面token预测下一个token
总结一下:
看到这儿也许会疑惑,大体上PaLM跟GPT3没有什么区别啊,也就是细节上添加了一点分布式然后更加精确,其实确实如此,两者都是采用自回归语言建模并且只有Decoder,都是逐步预测下一个token,但是PaLM比GPT3有更大规模的数据训练,并且使用Google Pathways训练,能够更高效的并行训练多个任务,节省计算资源few-shot跟zero-shot上的能力更强。
5.LLaMA模型理解
LLaMA也是属于自回归Transformer模型,采用纯Decoder-only Transformer结构,类似于GPT3但是在一些方面做出了改进
5.1LLaMA模型结构
与GPT3类似:
1.输入 Prompt
2.模型通过多层 Transformer 计算隐藏状态
3.Masked Self-Attention 确保每个 token 只能看见之前的 token
4.逐步生成文本
关键优化点:
1.使用SwiGLU激活函数
2.使用Rotary Positional Embeddings:RoPE 改进了传统位置编码,使模型能够更好地处理长文本,在长文本推理(>2048 tokens)时,比传统位置编码更稳定。
3.更大的训练数据:LLaMA 使用 1.4 万亿 token 训练,比 GPT-3 更高质量、更大规模,这样可以在更小的模型规模下,达到更好的效果。
5.2LLaMA优势
计算效率更高,训练数据更优质,适用于长文本处理,主要是部分版本开源,可以用于学术研究
总结一下:
LLaMA 和 GPT-3 都是 Decoder-only 语言模型,但 LLaMA 在更少的参数(最高 65B)下,通过更高质量的训练数据(1.4T token)和优化计算架构(RoPE、SwiGLU),实现了接近甚至超越 GPT-3(175B)级别的性能,同时计算效率更高、对低算力设备更友好。
6.GLM模型理解
GLM(General Language Model,通用语言模型)是 清华大学 KEG 实验室(THU-KEG) 研发的一种 双向自回归(Bidirectional Autoregressive)语言模型。GLM 不同于传统的 GPT(仅 Decoder)或 BERT(仅 Encoder)模型,而是结合了 Encoder 和 Decoder 的优点,从而在 文本理解(如摘要、问答)和文本生成(如翻译、对话) 任务上都能表现良好。
6.1GLM特点
1.采用双向自回归架构,也就是可以向前预测也可以向后预测,能理解上下文还可以生成高质量文本
2.兼容NLP多种任务
3.采用块填充式预训练,训练时随机Mask一部分文本,让模型同时向前和向后填充缺失内容
6.2GLM架构与训练方式
GLM不是单纯的Encoder或者Decoder,而是将两者结合的一种架构
1.块填充式预训练:
原文本:"The Eiffel Tower is located in Paris, France."
GLM 训练输入:"The Eiffel Tower is <MASK>."
目标输出:"located in Paris, France."
2.自回归学习:结合BERT的MaskedLM和GPT的自回归生成
6.3GLM的推理
1.输入 Prompt
2.模型计算隐藏状态
3.Softmax 计算 token 概率
4.逐步生成完整文本
总结一下:
也就是说GLM跟T5和GPT3的主要区别是什么呢,也就是说最主要的区别在与T5和GPT3的Decoder都是自回归并且只能看到前一个token,但是GLM是双向自回归的,不止可以看到前面,而且可以看到后面的token,同时也可以做一个块填充
以上就是所有的目前主流语言模型的粗浅见解,具体的区别分析在后续文章

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)