【完整源码+数据集+部署教程】眼病图像分割系统: yolov8-seg-C2f-ODConv
【完整源码+数据集+部署教程】眼病图像分割系统: yolov8-seg-C2f-ODConv
背景意义
研究背景与意义
随着全球人口老龄化的加剧,眼病的发病率逐年上升,成为了影响人们生活质量的重要健康问题。根据世界卫生组织的统计,眼病已成为导致视觉障碍和失明的主要原因之一,尤其是白内障、糖尿病视网膜病变和青光眼等疾病,给患者及其家庭带来了沉重的经济和心理负担。因此,及时、准确地诊断和治疗眼病显得尤为重要。近年来,随着计算机视觉和深度学习技术的快速发展,基于图像处理的眼病检测和诊断方法逐渐成为研究热点。
在这一背景下,眼病图像分割技术的研究显得尤为重要。图像分割是计算机视觉中的一项基本任务,其目标是将图像划分为若干个有意义的区域,以便于后续的分析和处理。在眼病的诊断中,图像分割可以帮助医生准确识别病变区域,从而提高诊断的准确性和效率。传统的图像分割方法往往依赖于手工特征提取,难以适应复杂的眼部图像特征。而基于深度学习的图像分割方法,尤其是YOLO(You Only Look Once)系列模型,因其高效性和准确性,逐渐成为眼病图像分割的主流选择。
本研究旨在基于改进的YOLOv8模型,构建一个高效的眼病图像分割系统。YOLOv8作为YOLO系列的最新版本,具备更强的特征提取能力和更快的推理速度,能够在实时性和准确性之间取得良好的平衡。通过对YOLOv8模型的改进,我们将其应用于眼病图像分割任务,以实现对不同类型眼病的准确识别和分割。具体而言,本研究将利用包含2600幅图像的眼病数据集,该数据集涵盖了四种类别:白内障、糖尿病视网膜病变、青光眼和正常眼部图像。这些类别的选择不仅反映了当前眼病的主要类型,也为模型的训练和评估提供了丰富的样本。
本研究的意义在于,通过构建基于改进YOLOv8的眼病图像分割系统,能够为眼科医生提供一种高效、准确的辅助诊断工具。这一系统不仅可以提高眼病的早期筛查和诊断效率,还能够为后续的治疗方案制定提供重要依据。此外,随着数据集的不断扩展和模型的进一步优化,该系统有望在未来的临床应用中发挥更大的作用,推动眼病诊疗的智能化和精准化进程。
综上所述,基于改进YOLOv8的眼病图像分割系统的研究,不仅具有重要的理论价值,也具有广泛的应用前景。通过深入探索深度学习在眼病图像处理中的应用,我们期望能够为眼科医学的发展贡献一份力量,同时为患者提供更为优质的医疗服务。
图片效果
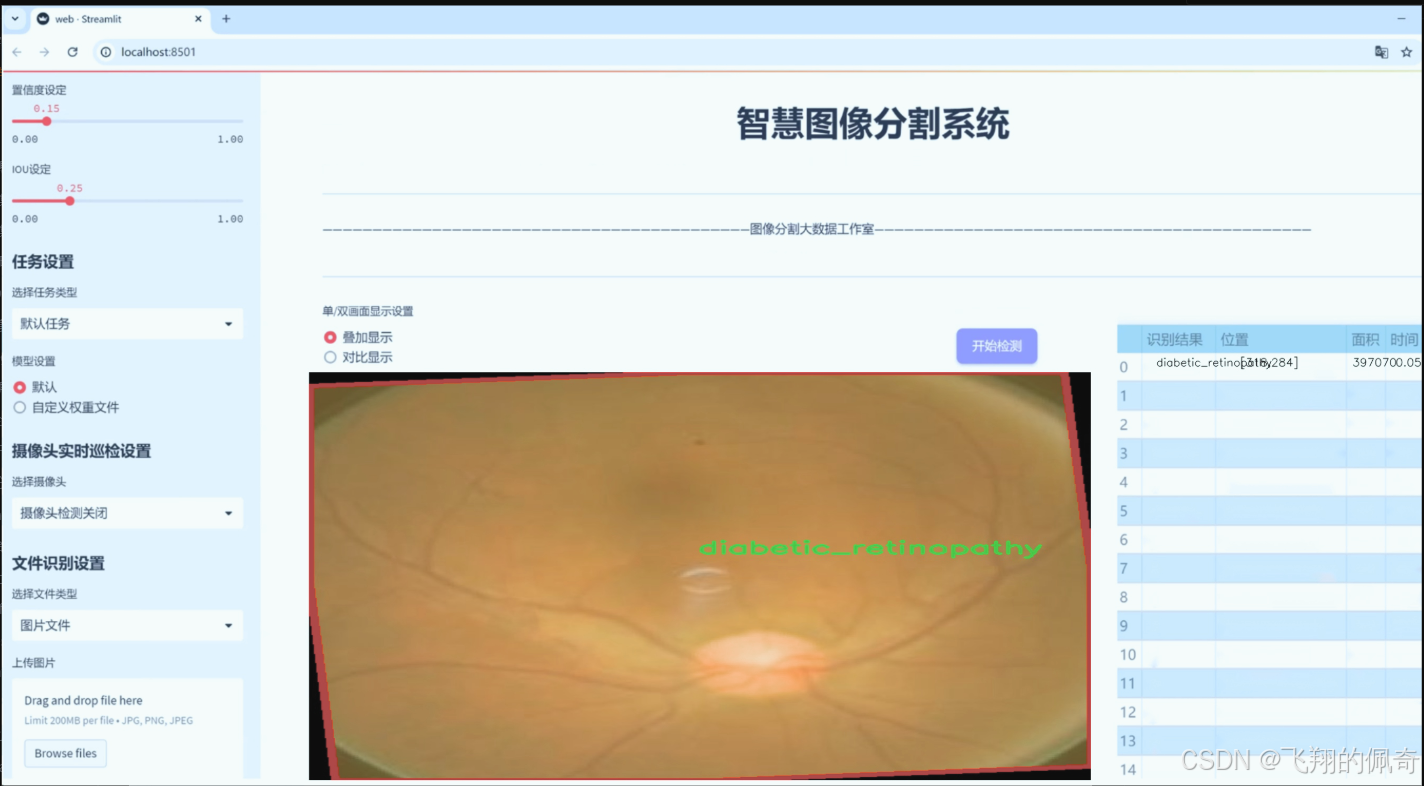
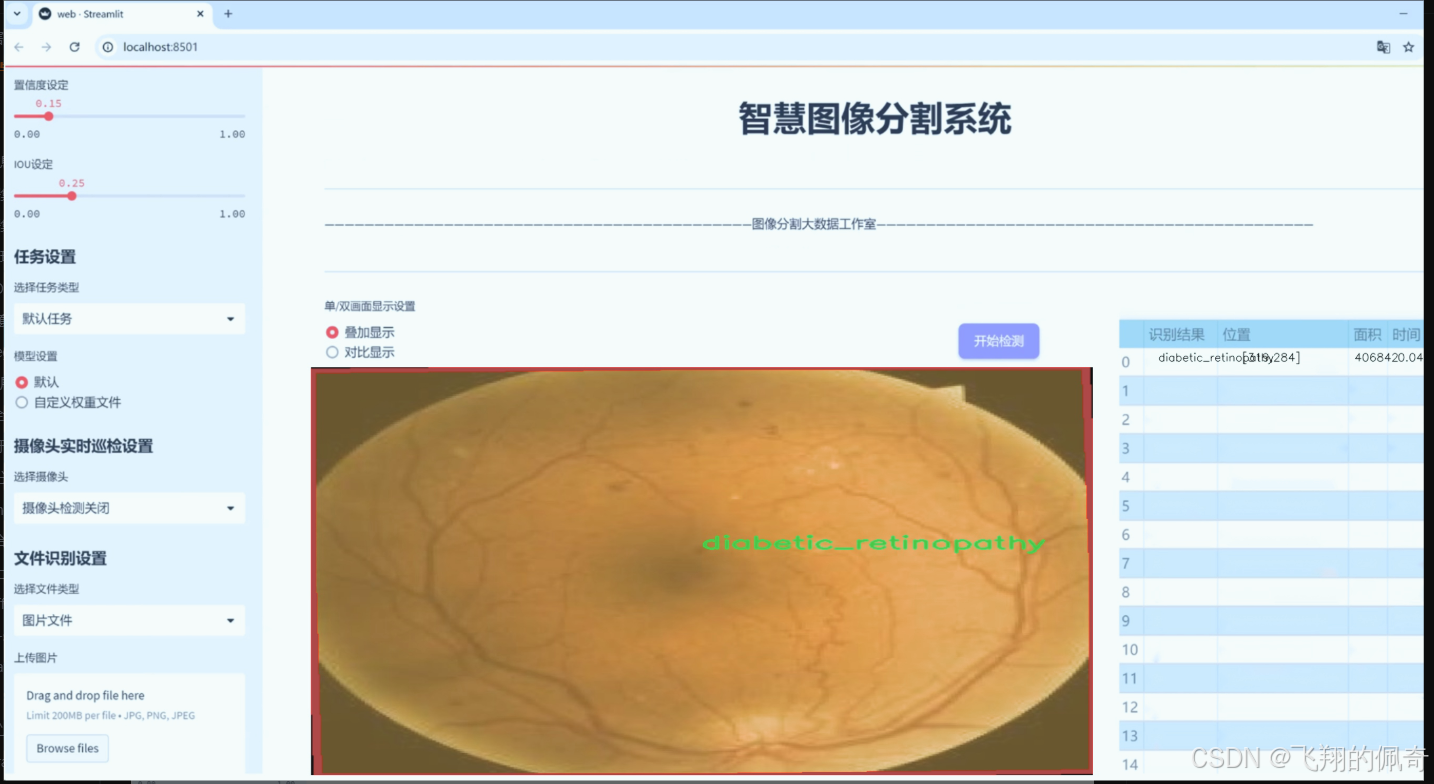
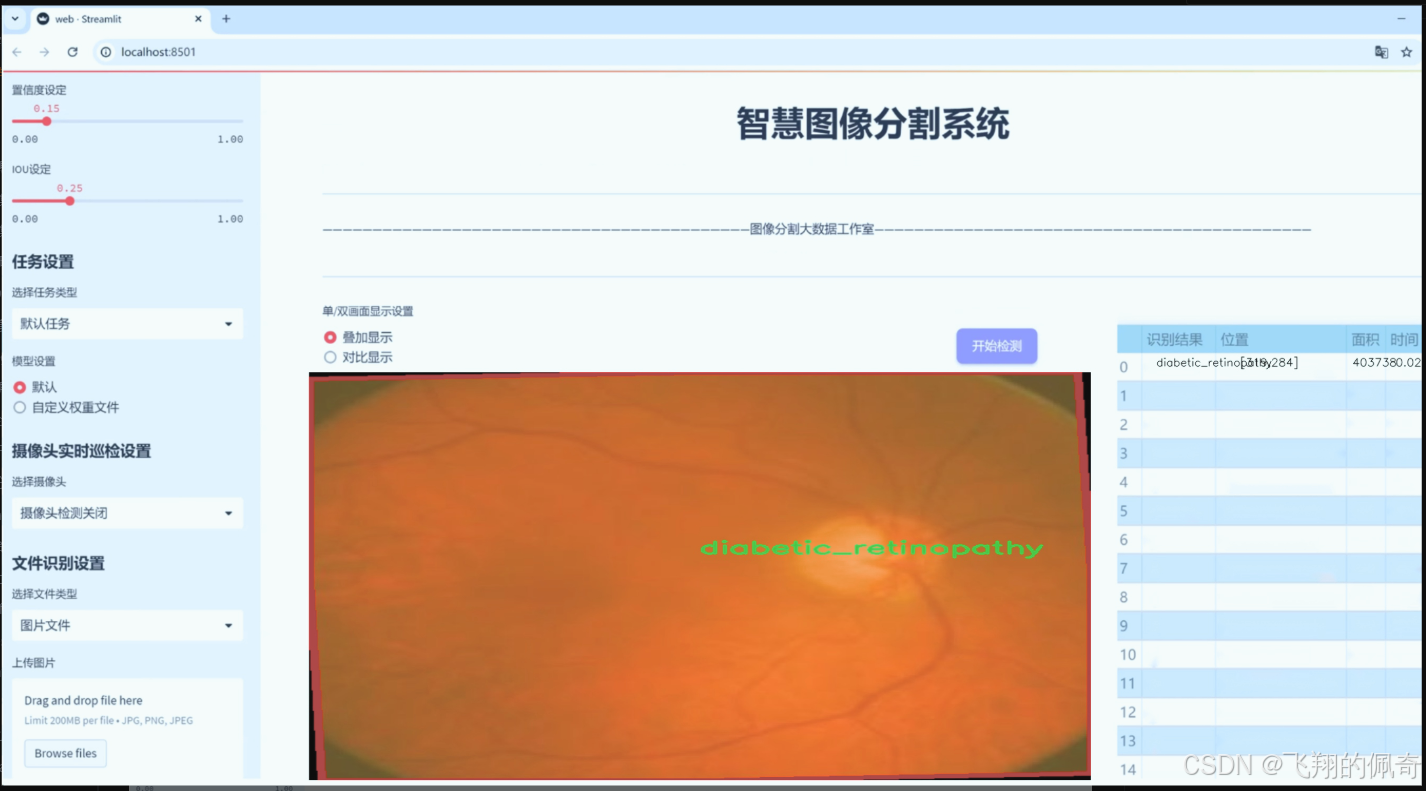
数据集信息
数据集信息展示
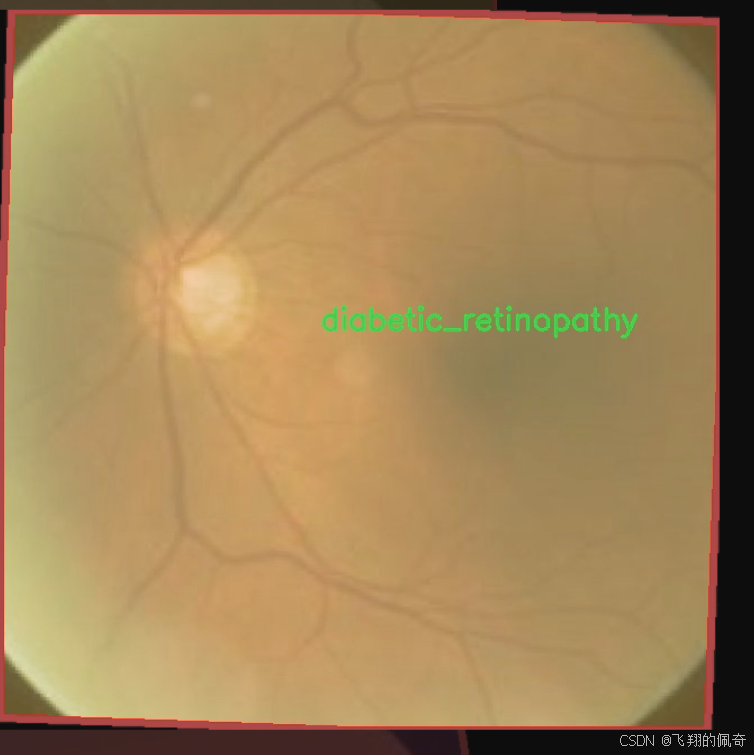
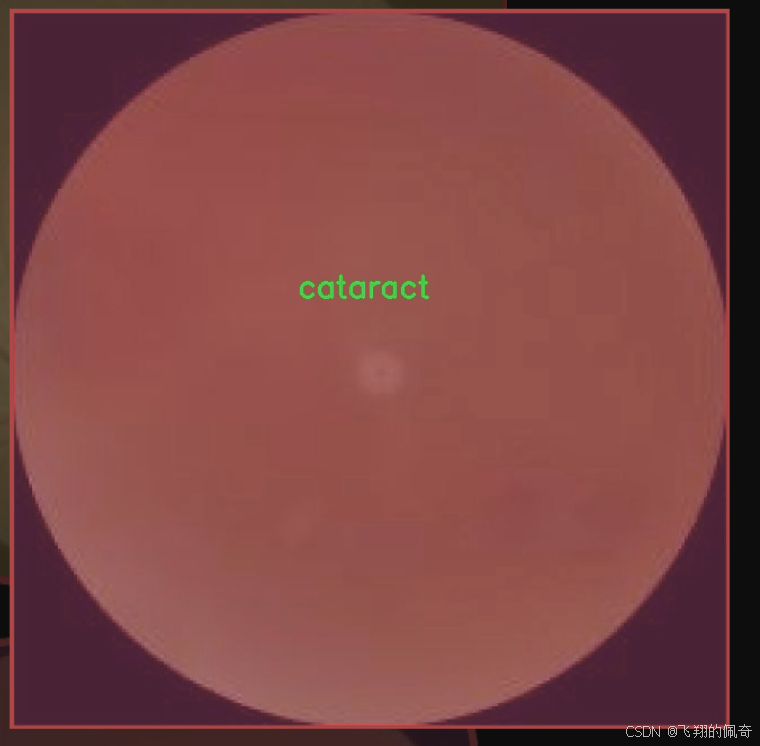
在眼科医学领域,图像分割技术的应用日益广泛,尤其是在眼病的早期诊断和治疗中。为此,我们构建了一个名为“Eye-Disease”的数据集,旨在为改进YOLOv8-seg的眼病图像分割系统提供强有力的支持。该数据集包含四个主要类别,分别是白内障(cataract)、糖尿病视网膜病变(diabetic_retinopathy)、青光眼(glaucoma)和正常眼底(normal)。这些类别的选择基于眼科临床实践中常见的眼病,具有重要的临床意义和应用价值。
“Eye-Disease”数据集的构建过程经过精心设计,确保了数据的多样性和代表性。每个类别的图像均来源于真实的临床病例,涵盖了不同年龄、性别和种族的患者,确保了数据集的广泛适用性。通过与多家医院和眼科诊所的合作,我们收集了大量的眼底图像,并对其进行了严格的标注和分类。每幅图像都经过专业眼科医生的审核,确保标注的准确性和可靠性。
在数据集的设计中,我们特别注重图像的质量和分辨率,以便为YOLOv8-seg模型的训练提供高质量的输入。所有图像均为高分辨率,能够清晰地展示眼底的细微结构和病变特征。这对于模型的学习和特征提取至关重要,能够帮助其更好地识别和分割不同类型的眼病。
此外,数据集还考虑到了样本的不平衡问题。为了提高模型在不同类别上的表现,我们在数据集中对每个类别的样本数量进行了合理的配置,确保每个类别都有足够的样本进行训练。这种设计使得模型在训练过程中能够更好地学习到各个类别的特征,从而提高分割的准确性和鲁棒性。
在数据集的使用过程中,我们建议研究人员在进行模型训练时,采用数据增强技术,以进一步提升模型的泛化能力。通过旋转、缩放、翻转等操作,可以有效增加训练样本的多样性,从而使模型在面对未见过的图像时,依然能够保持良好的性能。
“Eye-Disease”数据集的发布,不仅为眼病图像分割研究提供了重要的基础数据,也为相关领域的研究者提供了一个良好的实验平台。通过对该数据集的深入研究和分析,研究人员可以探索更多的深度学习算法和技术,以期在眼病的早期诊断和治疗中取得更好的成果。
总之,“Eye-Disease”数据集的构建和应用,标志着眼科图像处理研究的一次重要进展。我们期待着该数据集能够推动眼病图像分割技术的发展,为眼科临床实践提供更为精准和高效的辅助工具。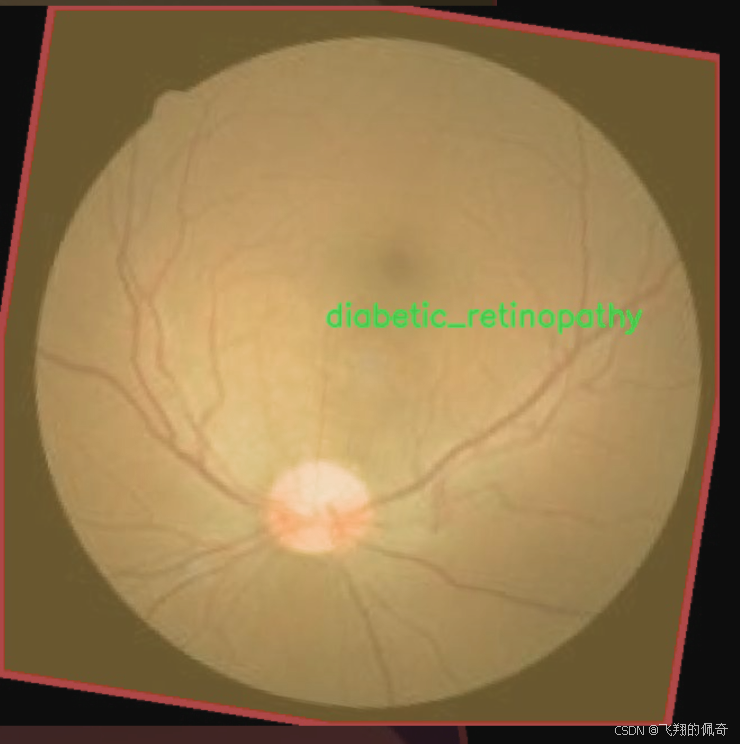


核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
def cfg2dict(cfg):
“”"
将配置对象转换为字典,无论它是文件路径、字符串还是SimpleNamespace对象。
参数:
cfg (str | Path | dict | SimpleNamespace): 要转换为字典的配置对象。
返回:
cfg (dict): 以字典格式表示的配置对象。
"""
if isinstance(cfg, (str, Path)):
cfg = yaml_load(cfg) # 从文件加载字典
elif isinstance(cfg, SimpleNamespace):
cfg = vars(cfg) # 转换为字典
return cfg
def get_cfg(cfg: Union[str, Path, Dict, SimpleNamespace] = DEFAULT_CFG_DICT, overrides: Dict = None):
“”"
从文件或字典加载并合并配置数据。
参数:
cfg (str | Path | Dict | SimpleNamespace): 配置数据。
overrides (str | Dict | optional): 以文件名或字典形式的覆盖项。默认为None。
返回:
(SimpleNamespace): 训练参数命名空间。
"""
cfg = cfg2dict(cfg)
# 合并覆盖项
if overrides:
overrides = cfg2dict(overrides)
if 'save_dir' not in cfg:
overrides.pop('save_dir', None) # 忽略特殊覆盖键
check_dict_alignment(cfg, overrides)
cfg = {**cfg, **overrides} # 合并cfg和覆盖字典(优先使用覆盖项)
# 特殊处理数字项目/名称
for k in 'project', 'name':
if k in cfg and isinstance(cfg[k], (int, float)):
cfg[k] = str(cfg[k])
if cfg.get('name') == 'model': # 将模型赋值给'name'参数
cfg['name'] = cfg.get('model', '').split('.')[0]
LOGGER.warning(f"WARNING ⚠️ 'name=model' 自动更新为 'name={cfg['name']}'.")
# 类型和值检查
for k, v in cfg.items():
if v is not None: # None值可能来自可选参数
if k in CFG_FLOAT_KEYS and not isinstance(v, (int, float)):
raise TypeError(f"'{k}={v}' 的类型 {type(v).__name__} 无效. "
f"有效的 '{k}' 类型是 int(例如 '{k}=0')或 float(例如 '{k}=0.5')")
elif k in CFG_FRACTION_KEYS:
if not isinstance(v, (int, float)):
raise TypeError(f"'{k}={v}' 的类型 {type(v).__name__} 无效. "
f"有效的 '{k}' 类型是 int(例如 '{k}=0')或 float(例如 '{k}=0.5')")
if not (0.0 <= v <= 1.0):
raise ValueError(f"'{k}={v}' 的值无效. "
f"有效的 '{k}' 值在 0.0 和 1.0 之间。")
elif k in CFG_INT_KEYS and not isinstance(v, int):
raise TypeError(f"'{k}={v}' 的类型 {type(v).__name__} 无效. "
f"'{k}' 必须是 int(例如 '{k}=8')")
elif k in CFG_BOOL_KEYS and not isinstance(v, bool):
raise TypeError(f"'{k}={v}' 的类型 {type(v).__name__} 无效. "
f"'{k}' 必须是 bool(例如 '{k}=True' 或 '{k}=False')")
# 返回实例
return IterableSimpleNamespace(**cfg)
def entrypoint(debug=‘’):
“”"
该函数是ultralytics包的入口点,负责解析传递给包的命令行参数。
该函数允许:
- 以字符串列表的形式传递必需的YOLO参数
- 指定要执行的任务,'detect'、'segment'或'classify'
- 指定模式,'train'、'val'、'test'或'predict'
- 运行特殊模式,如'checks'
- 向包的配置传递覆盖项
它使用包的默认配置并使用传递的覆盖项初始化它。
然后调用具有组合配置的CLI函数。
"""
args = (debug.split(' ') if debug else sys.argv)[1:]
if not args: # 没有传递参数
LOGGER.info(CLI_HELP_MSG)
return
# 处理特殊命令
special = {
'help': lambda: LOGGER.info(CLI_HELP_MSG),
'checks': checks.collect_system_info,
'version': lambda: LOGGER.info(__version__),
'settings': lambda: handle_yolo_settings(args[1:]),
'cfg': lambda: yaml_print(DEFAULT_CFG_PATH),
'hub': lambda: handle_yolo_hub(args[1:]),
'login': lambda: handle_yolo_hub(args),
'copy-cfg': copy_default_cfg}
# 合并参数并处理覆盖项
overrides = {}
for a in merge_equals_args(args): # 合并'='周围的空格
if '=' in a:
try:
k, v = parse_key_value_pair(a)
overrides[k] = v
except (NameError, SyntaxError, ValueError, AssertionError) as e:
check_dict_alignment(full_args_dict, {a: ''}, e)
# 检查键
check_dict_alignment(full_args_dict, overrides)
# 运行命令
getattr(model, mode)(**overrides) # 使用模型的默认参数运行命令
# 显示帮助信息
LOGGER.info(f'💡 了解更多信息请访问 https://docs.ultralytics.com/modes/{mode}')
if name == ‘main’:
# 示例: entrypoint(debug=‘yolo predict model=yolov8n.pt’)
entrypoint(debug=‘’)
代码核心部分解释:
cfg2dict: 将不同类型的配置对象(如字符串、路径或命名空间)转换为字典格式,以便后续处理。
get_cfg: 加载并合并配置,检查参数类型和有效性,确保配置的正确性。
entrypoint: 作为程序的入口,解析命令行参数,处理特殊命令,并根据用户输入执行相应的YOLO操作。
这个程序文件是Ultralytics YOLO(You Only Look Once)模型的配置和命令行接口(CLI)实现部分。文件的主要功能是处理用户输入的命令行参数,加载和合并配置,进行参数验证,并根据用户的请求执行相应的任务,如训练、验证、预测等。
首先,文件导入了一些必要的库和模块,包括路径处理、类型检查和Ultralytics库中的工具函数。接着,定义了一些有效的任务和模式,例如任务包括检测、分割、分类和姿态估计,而模式则包括训练、验证、预测、导出等。
文件中定义了一些映射关系,例如任务与数据集、模型和评估指标之间的对应关系。这些映射关系便于在执行特定任务时自动选择合适的配置。
接下来,文件提供了一个帮助信息字符串,详细说明了如何使用命令行接口,包括可用的任务、模式和参数示例。这对于用户理解如何使用该工具非常重要。
在配置处理方面,文件提供了多个函数来处理配置的加载和验证。例如,cfg2dict函数可以将配置对象转换为字典格式,get_cfg函数则负责加载和合并配置数据,并进行类型和值的检查,以确保用户输入的参数符合预期的格式。
文件还定义了一些处理保存目录、处理过时配置键、检查字典对齐等功能的辅助函数。这些函数确保用户提供的自定义配置与基础配置之间的一致性,并处理一些常见的错误。
在命令行参数解析方面,entrypoint函数是程序的入口点。它负责解析用户输入的命令行参数,并根据参数的类型和内容执行相应的操作。该函数支持多种命令,包括帮助信息、版本查询、设置管理等。
此外,文件还提供了一些特殊模式的处理函数,例如处理Ultralytics HUB的命令和YOLO设置的命令。这些功能增强了程序的灵活性和可用性。
最后,文件在主程序块中调用entrypoint函数,以便在直接运行该脚本时执行相应的命令。这种设计使得用户可以通过命令行直接与YOLO模型进行交互,方便进行各种任务的执行。
11.5 ultralytics\models\sam\modules\transformer.py
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
from torch import Tensor, nn
class Attention(nn.Module):
“”“一个注意力层,允许在投影到查询、键和值后缩小嵌入的大小。”“”
def __init__(self, embedding_dim: int, num_heads: int, downsample_rate: int = 1) -> None:
"""
初始化注意力模型,设置嵌入维度和头数。
Args:
embedding_dim (int): 输入嵌入的维度。
num_heads (int): 注意力头的数量。
downsample_rate (int, optional): 内部维度缩小的因子,默认为1。
"""
super().__init__()
self.embedding_dim = embedding_dim
self.internal_dim = embedding_dim // downsample_rate # 计算内部维度
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, 'num_heads必须能整除embedding_dim.'
# 定义线性投影层
self.q_proj = nn.Linear(embedding_dim, self.internal_dim) # 查询的线性投影
self.k_proj = nn.Linear(embedding_dim, self.internal_dim) # 键的线性投影
self.v_proj = nn.Linear(embedding_dim, self.internal_dim) # 值的线性投影
self.out_proj = nn.Linear(self.internal_dim, embedding_dim) # 输出的线性投影
@staticmethod
def _separate_heads(x: Tensor, num_heads: int) -> Tensor:
"""将输入张量分离为指定数量的注意力头。"""
b, n, c = x.shape # b: 批量大小, n: 序列长度, c: 通道数
x = x.reshape(b, n, num_heads, c // num_heads) # 重塑为 B x N x N_heads x C_per_head
return x.transpose(1, 2) # 转置为 B x N_heads x N_tokens x C_per_head
@staticmethod
def _recombine_heads(x: Tensor) -> Tensor:
"""将分离的注意力头重新组合为单个张量。"""
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2) # 转置为 B x N_tokens x N_heads x C_per_head
return x.reshape(b, n_tokens, n_heads * c_per_head) # 重塑为 B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
"""计算给定输入查询、键和值张量的注意力输出。"""
# 输入投影
q = self.q_proj(q) # 对查询进行线性投影
k = self.k_proj(k) # 对键进行线性投影
v = self.v_proj(v) # 对值进行线性投影
# 分离为多个头
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# 计算注意力
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # 计算注意力得分
attn = attn / math.sqrt(c_per_head) # 归一化
attn = torch.softmax(attn, dim=-1) # 应用softmax
# 获取输出
out = attn @ v # 计算输出
out = self._recombine_heads(out) # 重新组合头
return self.out_proj(out) # 通过输出投影层返回结果
代码核心部分说明:
Attention类:实现了一个注意力机制,允许输入嵌入的大小在经过查询、键和值的投影后进行缩小。
初始化方法:设置嵌入维度、注意力头数和缩小率,并定义了用于查询、键和值的线性投影层。
_separate_heads方法:将输入张量分离为多个注意力头,以便进行并行计算。
_recombine_heads方法:将分离的注意力头重新组合为一个张量,以便进行后续处理。
forward方法:实现了注意力机制的前向传播,包括输入的线性投影、注意力得分的计算、输出的组合等。
这些部分构成了注意力机制的基础,能够在多种任务中有效地处理信息。
这个程序文件定义了一个名为 TwoWayTransformer 的类,它是一个双向变换器模块,能够同时关注图像和查询点。该类是一个专门的变换器解码器,使用提供的查询的位置信息来关注输入图像。这种设计特别适用于目标检测、图像分割和点云处理等任务。
在 TwoWayTransformer 类的构造函数中,定义了一些属性,包括变换器的层数、输入嵌入的通道维度、多头注意力的头数、MLP块的内部通道维度等。它还初始化了一个包含多个 TwoWayAttentionBlock 层的模块列表。每个 TwoWayAttentionBlock 负责执行自注意力和交叉注意力操作,确保查询和键之间的双向交互。
forward 方法接收图像嵌入、图像的位置信息和查询点的嵌入,并对这些输入进行处理。首先,它将图像嵌入和位置信息展平并重新排列,以便于后续处理。然后,它准备查询和键,并通过每个变换器层进行处理。最后,应用最终的注意力层,从查询点到图像的注意力,并进行层归一化处理,返回处理后的查询和键。
TwoWayAttentionBlock 类实现了一个注意力块,执行自注意力和交叉注意力操作。它包含四个主要层:对稀疏输入的自注意力、稀疏输入到密集输入的交叉注意力、对稀疏输入的MLP块以及密集输入到稀疏输入的交叉注意力。每个步骤后都应用层归一化,以提高模型的稳定性和收敛速度。
Attention 类实现了一个注意力层,允许在投影到查询、键和值之后对嵌入的大小进行下采样。它定义了输入嵌入的维度、注意力头的数量以及下采样率,并在前向传播中实现了查询、键和值的线性投影。注意力计算通过将查询和键进行点积,并应用softmax来获得注意力权重,最后将注意力权重应用于值,得到最终的输出。
整体而言,这个程序文件实现了一个复杂的双向变换器架构,能够在图像和查询点之间进行高效的注意力机制,适用于多种计算机视觉任务。
12.系统整体结构(节选)
程序整体功能和构架概括
该程序是Ultralytics YOLO(You Only Look Once)系列模型的实现,主要用于计算机视觉任务,如目标检测、图像分割和分类等。整个项目的架构由多个模块组成,每个模块负责特定的功能,从模型的构建、训练会话管理到配置处理和注意力机制的实现。
模型构建:包括不同类型的神经网络架构,如CSWin Transformer,支持高效的特征提取和处理。
会话管理:通过session.py管理训练会话,处理与Ultralytics HUB的通信和数据上传。
配置管理:通过cfg/init.py处理用户输入的命令行参数,加载和验证配置。
注意力机制:在transformer.py中实现了双向变换器,能够有效地在图像和查询点之间进行信息交互。
文件功能整理表
文件路径 功能描述
ultralytics/hub/session.py 管理训练会话,处理模型初始化、心跳信号和检查点上传,确保与Ultralytics HUB的通信。
ultralytics/nn/backbone/CSwomTramsformer.py 实现CSWin Transformer模型,包括多层感知机、自定义注意力机制和模型的不同变体。
ultralytics/models/sam/modules/init.py 初始化模块,处理模块导入和公共接口,确保该目录可以作为一个包使用。
ultralytics/cfg/init.py 处理命令行参数,加载和验证配置,提供帮助信息,支持多种任务和模式的执行。
ultralytics/models/sam/modules/transformer.py 实现双向变换器,包含自注意力和交叉注意力机制,处理图像和查询点之间的信息交互。
这个表格清晰地展示了每个文件的功能,便于理解整个程序的结构和模块之间的关系。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:
x1, y1, x2, y2 = bbox
aim_frame_area = (x2 - x1) * (y2 - y1)
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))
image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:
mask_points = np.concatenate(mask)
aim_frame_area = calculate_polygon_area(mask_points)
mask_color = generate_color_based_on_name(name)
try:
overlay = image.copy()
cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)
image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)
cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))
# 计算面积、周长、圆度
area = cv2.contourArea(mask_points.astype(np.int32))
perimeter = cv2.arcLength(mask_points.astype(np.int32), True)
......
# 计算色彩
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)
color_points = cv2.findNonZero(mask)
......
# 绘制类别名称
x, y = np.min(mask_points, axis=0).astype(int)
image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param)
# 绘制面积、周长、圆度和色彩值
metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]
for idx, (metric_name, metric_value) in enumerate(metrics):
......
return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
......
# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:
processed_image = process_frame(model, image)
......
# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 31
31 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)