第1关:机器学习类型
神经网络学习之机器学习基础
任务描述
本关任务:掌握机器学习的基础知识,完成相应的选择题。
相关知识
为了完成本关任务,你需要掌握:
- 监督学习;
- 非监督学习;
- 强化学习。
监督学习
监督学习是根据己有的训练集提供的样本(xi,yi),通过不断计算从样本中学习选择特征参数,对分类器建立判别函数以对被识别的样本进行分类。 监督学习需要一定量级的训练数据,通过对训练数据进行特征提取形成符合特征的分类模型, 最后将分类模型形成分类器并实现对数据的分类。 根据有监督学习的输出类型,可以分为回归( Regression )和分类( Classification )两种 :
- 回归问题。如果监督学习中,输出的y是一个连续值,且 f(x) 的输出也是连续的值,则此类问题可以划分为回归问题,以距离计算为主,常见的有线性回归和逻辑回归等。
- 分类问题。如果 y 是离散的类别标记或者数值,则可以视为分类问题,以概率计算为主,常见的分类模型有朴素贝叶斯、支持向量机等 。
图1为监督学习的一般过程,使用训练数据( training data)来对模型算法进行训练。其中训练数据中的x作为输入,通过模型计算得到预测结果f(x),真实结果y作为监督,判断预测结果f(x)是否正确,最终使f(x)无限趋近于y。
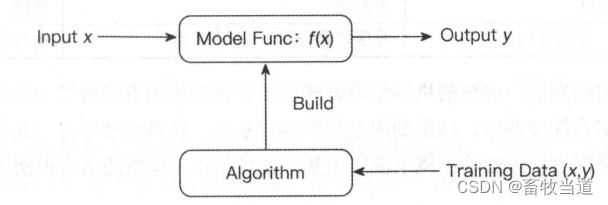
图1 监督学习过程示例
非监督学习
无监督学习是模型本身不进行先验知识学习,不会对模型进行参数训练,而是使用被预测的样本数据直接进行预测的过程,此类预测过程只是对不同类型的数据进行了预测,预测后的结果具有不确定性 。 由于非监督学习的人为干预较少,结果具备一定的客观性,但是一般非监督学习的方式计算过程较为复杂,需要大量的分析之后,才有可能获得较好的预测结果。典型的非监督学习是聚类(Clustering)。 考虑到监督学习需要训练集,而训练集往往是人工参与标注,非监督学习的优势在于它不需要人工标记的数据集,因此出现了类似于弱监督学习和半监督学习的新机制。 半监督学习(Semi-Supervised Leaming),它是建立在己有模型的基础上,通过从少量训练样本中获得先验数据的机器学习方式,结合了有监督学习和无监督学习的各自优势 。
强化学习
强化学习主要强调的是基于当前环境下的动作行为控制,以取得最优效果 ,它是由一系列累计的动作行为得到的最优效果。强化学习不同于监督学习的地方在于它不需要显式地输入一些样本数据,属于一种在线的学习方式 。 下图2为强化学习的一般过程。Agent 先作出动作a,然后环境会对动作a作出反映,表现为状态s。Agent 获取到环境的状态s,对自己的动作a进行奖赏,即值为r,然后再作出下一个动作,循环往复。
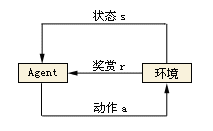
图2 强化学习过程示例
三种机器学习类型的比较
下表为三种机器学习方法的比较:
| |监督学习 |非监督学习 |强化学习 |
| ------------ | ------------ | ------------ | ------------ |
| 输入 | 已标记数据 | 无标记数据 | 决策过程 |
| 反馈 |直接反馈 | 无反馈 | 奖励 |
| 用途 | 分类预测问题 | 发现隐藏结构 | 动作行为控制 |
随着深度学习的发展,传统的机器学习方式己经开始演进为监督学习的深度网络、无监督的生成网络、混合深度网络。这里的混合是指混合系统,是将深度学习与其他机器学习组合的方式。例如,将深度学习的输出概率应用于基于隐马尔科夫模型的语音识别系统中。
作答要求
根据相关知识,按照要求完成右侧选择题任务。作答完毕,通过点击“测评”,可以验证答案的正确性。
参考资料
【1】监督学习
【2】非监督学习
【3】强化学习
开始你的任务吧,祝你成功
1、下列说法错误的的是 AC
A、监督学习不需要一定量级的数据作为训练数据。
B、监督学习可以根据输出类型分为回归和分类两种类型。
C、强化学习不需要训练数据。
D、非监督学习的结果具有不确定性。
2、下列关于回归和分类问题的说法错误的是: AC
A、回归问题的输出y为离散的类别标记或者数值。
B、分类问题的主要手段为概率计算。
C、支持向量机解决的是回归问题。
D、回归问题以距离计算为主。
DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)