【机器学习】聚类方法
1. 聚类和分类的区别数据分类是分析已有的数据,寻找其共同的属性,并根据分类模型将这些数据划分成不同的类别,这些数据赋予类标号。这些类别是事先定义好的,并且类别数是已知的。相反,数据聚类则是将本没有类别参考的数据进行分析并划分为不同的组,即从这些数据导出类标号。聚类分析本身则是根据数据来发掘数据对象及其关系信息,并将这些数据分组。每个组内的对象之间是相似的,而各个组间的对象是不相关的。不难理解..
1. 聚类和分类的区别
数据分类是分析已有的数据,寻找其共同的属性,并根据分类模型将这些数据划分成不同的类别,这些数据赋予类标号。这些类别是事先定义好的,并且类别数是已知的。相反,数据聚类则是将本没有类别参考的数据进行分析并划分为不同的组,即从这些数据导出类标号。聚类分析本身则是根据数据来发掘数据对象及其关系信息,并将这些数据分组。每个组内的对象之间是相似的,而各个组间的对象是不相关的。不难理解,组内相似性越高,组间相异性越高,则聚类越好
2. k-means算法
K 均值算法流程
K 均值算法,应该是聚类算法中最为基础但也最为重要的算法。其算法流程如下:
- 随机的取 k 个点作为 k 个初始质心;
- 计算其他点到这个 k 个质心的距离;
- 如果某个点 p 离第 n 个质心的距离更近,则该点属于 cluster n,并对其打标签,标注 point p.label=n,其中 n<=k;
- 计算同一 cluster 中,也就是相同 label 的点向量的平均值,作为新的质心;
- 迭代至所有质心都不变化为止,即算法结束
当然算法实现的方法有很多,比如在选择初始质心时,可以随机选择 k 个,也可以随机选择 k 个离得最远的点等等,方法不尽相同。
K 值估计
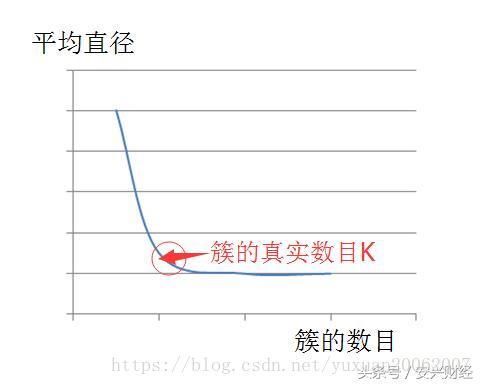
对于 k 值,必须提前知道,这也是 kmeans 算法的一个缺点。当然对于 k 值,我们可以有很多种方法进行估计。本文中,我们采用平均直径法来进行 k 的估计。
也就是说,首先视所有的点为一个大的整体 cluster,计算所有点之间距离的平均值作为该 cluster 的平均直径。选择初始质心的时候,先选择最远的两个点,接下来从这最两个点开始,与这最两个点距离都很远的点(远的程度为,该点到之前选择的最远的两个点的距离都大于整体 cluster 的平均直径)可视为新发现的质心,否则不视之为质心。设想一下,如果利用平均半径或平均直径这一个指标,若我们猜想的 K 值大于或等于真实的 K 值,也就是簇的真实数目,那么该指标的上升趋势会很缓慢,但是如果我们给出的 K 值小于真实的簇的数目时,这个指标一定会急剧上升。
根据这样的估算思想,我们就能估计出正确的 k 值,并且得到 k 个初始质心,接着,我们便根据上述算法流程继续进行迭代,直到所有质心都不变化,从而成功实现算法。如下图所示:
我们知道 k 均值总是收敛的,也就是说,k 均值算法一定会达到一种稳定状态,在此状态下,所有的点都不会从一个簇转移到另一个簇,因此质心不在发生改变。在此,我们引出一个剪枝优化,即:k 均值最明显的收敛过程会发生在算法运行的前期阶段,故在某些情况下为了增加算法的执行效率,我们可以替换上述算法的第五步,采用“迭代至仅有 1%~3%的点在影响质心”或“迭代至仅有 1%~3%的点在改变簇”。
k 均值适用于绝大多数的数据类型,并且简单有效。但其缺点就是需要知道准确的 k 值,并且不能处理异形簇,比如球形簇,不同尺寸及密度的簇,环形簇等等。
3. 层次聚类算法
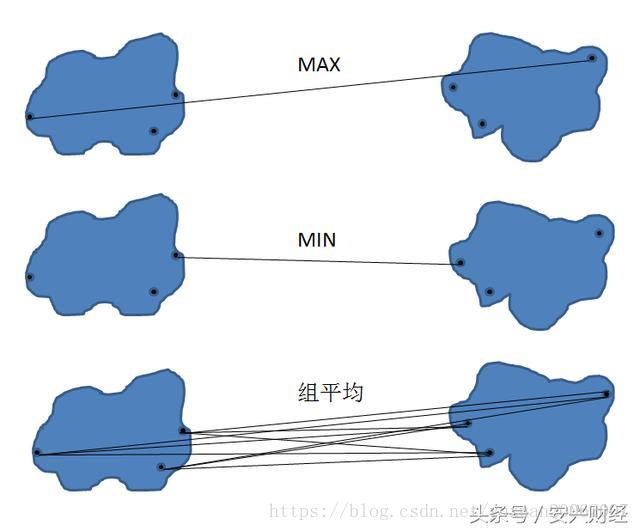
对于凝聚式层次聚类,指定簇的邻近准则是非常重要的一个环节,在此我们介绍三种最常用的准则,分别是 MAX, MIN, 组平均。如下图所示:
算法流程
凝聚式层次聚类算法也是一个迭代的过程,算法流程如下:
- 每次选最近的两个簇合并,我们将这两个合并后的簇称之为合并簇。
- 若采用 MAX 准则,选择其他簇与合并簇中离得最远的两个点之间的距离作为簇之间的邻近度。若采用 MIN 准则,取其他簇与合并簇中离得最近的两个点之间的距离作为簇之间的邻近度。若组平均准则,取其他簇与合并簇所有点之间距离的平均值作为簇之间的邻近度。
- 重复步骤 1 和步骤 2,合并至只剩下一个簇。
4. DBSCAN 算法
考虑一种情况,点的分布不均匀,形状不规则时,Kmeans 算法及层次聚类算法将面临失效的风险,,这时我们考虑采用基于密度的聚类算法:DBSCAN。
算法流程
- 设定扫描半径 Eps, 并规定扫描半径内的密度值。若当前点的半径范围内密度大于等于设定密度值,则设置当前点为核心点;若某点刚好在某核心点的半径边缘上,则设定此点为边界点;若某点既不是核心点又不是边界点,则此点为噪声点。
- 删除噪声点。
- 将距离在扫描半径内的所有核心点赋予边进行连通。
- 每组连通的核心点标记为一个簇。
- 将所有边界点指定到与之对应的核心点的簇总。
聚类的应用与评估是一个非常定性的过程,通常在数据分析的探索阶段很有帮助。我们学习了三种聚类算法:k 均值、DBSCAN 和凝聚聚类。这三种算法都可以控制聚类的粒度(granularity)。k 均值和凝聚聚类允许你指定想要的簇的数量,而DBSCAN 允许你用eps 参数定义接近程度,从而间接影响簇的大小。三种方法都可以用于大型的现实世界数据集,都相对容易理解,也都可以聚类成多个簇。
每种算法的优点稍有不同。k 均值可以用簇的平均值来表示簇,每个数据点都由其簇中心表示。DBSCAN 可以检测到没有分配任何簇的“噪声点”,还可以帮助自动判断簇的数量。与其他两种方法不同,它允许簇具有复杂的形状,正如我们在two_moons 的例子中所看到的那样。DBSCAN 有时会生成大小差别很大的簇,这可能是它的优点,也可能是缺点。凝聚聚类可以提供数据的可能划分的整个层次结构,可以通过树状图轻松查看。
参考资料:
K均值聚类算法(K-Means)《Python机器学习》之十一
DBSCAN 具有噪声的基于密度的空间聚类《Python机器学习》之十三

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)