《人工智能联合大作业》课程报告--论文精读--ProtoGCN:面向细粒度骨架动作识别的结构建模与其优化探索
针对现有GCN在相似动作识别中的不足,ProtoGCN创新性地提出MTE动态拓扑增强、PRN原型重构和CSCL类特异性对比学习三个核心模块,从结构、表示和监督三个层面提升细粒度识别能力。通过理论分析和代码复现,验证了模型在各常见数据集上的有效性。同时指出原型选择机制、结构正则化等潜在改进方向,并与BlockGCN、DeGCN等模型进行对比,总结GCN在骨架动作识别中的演进趋势。研究成果为细粒度动作
本文是本人的实践短学期《人工智能联合大作业》的论文报告,protogcn的论文(原文链接点此---谷歌学术),protogcn的github仓库(代码链接点此--github)。本报告中用到的参考文献都以谷歌学术链接整理在文末。
摘要
随着基于骨架的动作识别在智能监控、运动分析等领域的应用需求不断上升,图卷积网络(GCN)因其天然契合骨骼图结构而成为主流方案。然而,现有GCN在相似动作(如“写字”与“打字”)的识别上仍面临显著挑战,主要源于对局部细节的建模不足、结构刚性及监督机制单一。为此,ProtoGCN引入了三个关键模块:MTE动态拓扑增强模块、PRN原型重构模块和CSCL类特异性对比学习模块,从结构、表示、监督三个层面协同提升细粒度识别能力。本文在理解原理和复现代码的基础上,深入剖析了ProtoGCN的机制设计与性能表现,并对其核心假设提出质疑,尝试从动态原型选择、结构正则化等方面提出潜在改进思路。同时对比分析了BlockGCN与DeGCN的异同,总结三者在空间拓扑、时间建模与关键细节建模方面的共性与差异,形成对骨架动作识别中GCN演进路径的系统认知。
引言
随着人工智能技术发展,人体基于骨架的运动识别是目前计算机视觉领域的热点课题,在智能监控、人体运动分析、人机交互、健康监测等领域有很高的应用价值。传统人体运动识别主要通过RGB图像或视频帧序列提取运动和外观信息建模识别,在实际应用中容易受到光照、遮挡、背景等干扰的影响使得识别率下降。
随着人体姿态估计的进一步发展,最近几年的研究主要是以人体骨骼数据为基础的人体动作的研究。“基于骨架的动作识别” [1]是指利用人体在视频序列中各个关键点(如头、手、肘、膝等)随时间的运动轨迹来判断人物所执行的动作(如“跳跃”“挥手”“坐下”等)。输入数据通常为一系列帧,每帧为一个人体骨架的2D/3D关键点坐标。而“人体的骨架”[1]可以被建模成一个图:节点表示关节;边表示关节之间的自然连接(如肩-肘-手为一条链)。该图结构反映了人体的解剖结构,是先验知识,常被编码为邻接矩阵。骨骼数据是由人体关节点构成的对人体动作的轻量级表示,不仅计算量小,而且对人的运动更加敏感。
骨骼序列数据包含的图结构特征决定了GNNs可以很好的拟合骨骼数据之间的空间关系。ST-GCN[2]、2s-AGCN[3]、CTR-GCN[4]等人,都以骨骼关节之间的空间关系与时间序列的信息对人体运动进行建模。在主流方法ST-GCN[2]中:空间维度上基于同一帧的人体骨架图进行图卷积,提取各个关节之间的结构关系;时间维度上则将相同关节在不同帧之间连接成“时间边”,做1D卷积或序列建模;通常以序列帧为输入,输出每帧或整个序列的动作类别。
在3D骨架动作识别中,相比于RNN、CNN、Transformer这三类主流深度架构,GCN能更自然地表达骨骼结构,即节点=关节,边=连接,捕捉姿态空间关系;且GCN可以实现端到端时空特征融合、不依赖背景或外观信息,对噪声或遮挡更稳定。
尽管现有的GCN方法在常用数据集(如NTURGB+D[5]、Kinetics[6]等)上都取得了满意的效果,但是相似度极高的动作识别对于他们来说仍然是一个大问题。相似度极高的动作即骨骼的整体动作轮廓相似但是局部动作(例如手部的手指和手腕动作)略有不同的动作,如“写”和“打字键键”类似,“鼓掌”和“擦手”类似,这些动作的本质差异在于局部动作的细节或运动平衡,对于动作识别模型来说需要很高的细化程度。但现有GCN更加关注动作的整体轮廓,缺乏对于动作的细化处理机制,因而很容易将它们混淆。
为了更加直观地表明这个问题,本文将两个相似的任务“书写”和“键盘打字”的骨架图结构学习效果如图1所示。从图1的(a)和(c)中可以发现现有基线模型PSYSKL[7]对两个动作的注意力热力图基本都关注到两个动作的手部相关关节点,对于两个动作的运动特征模型之间没有区分,两个热力图基本一致,无法区分开两个动作;(a)现有的基线模型PSYSKL对两个注意力热力图,热力图基本一致,无法区分关节点,(b)和(c)是加了图原型机制后的ProtoGCN,从图1中可以看出来两个键打的手部活动比较平衡,热力图的分布也相对比较平均,书写偏向左手,经常活动在左手,热力图偏重左手。图1表明:现有的结构无法从局部动作建模角度加以区分,在相似分类任务上准确率不高。
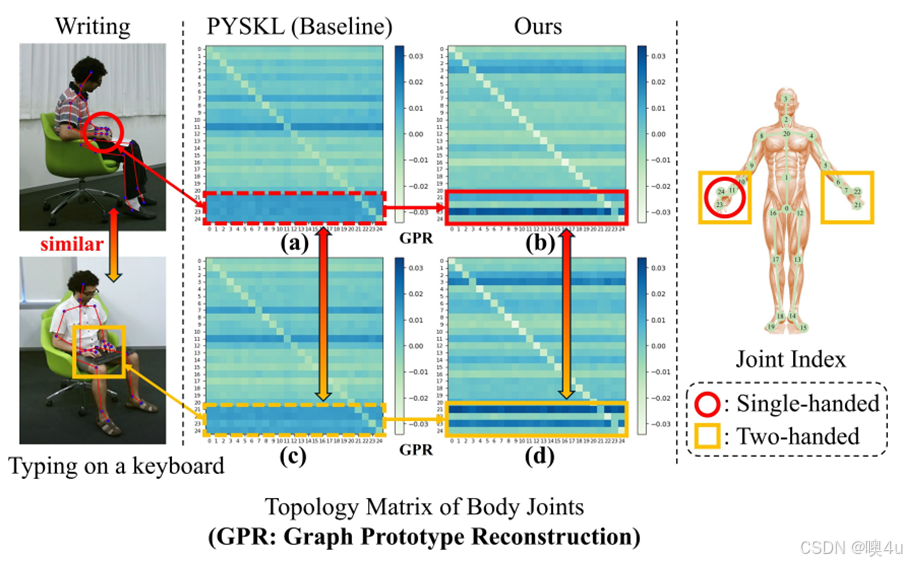
图1 类似动作“书写”和“键盘打字”的骨架及学习到的拓扑结构示意图
之所以存在上述问题,一方面是由于原有的骨架图结构建模过于刚性、不适合结构建模、无法处理动作间的不同局部模式;另一方面是由于训练目标仅考虑交叉熵分类损失,忽略样本间的分布规律,即同一类别的样本应聚集在一起、不同类别应区分开来的特性,缺少判别性学习规则;同时也体现出时序建模与长期依赖不足的问题。因此,ProtoGCN设计了三个协同创新的模块,提出了一个具有细粒度判别能力的新型骨架动作识别模型,如下所示:
- Motion Topology Enhancement(MTE):结合样本内的-样本的骨骼图,动态构建动作拓扑模型,增强样本内的局部运动建模能力,替换原有的骨骼图。
- Prototyping Network(PRN):将原型记忆库学习能学习的记忆库,将骨架模型描述成多个原型的组合,将动作模型结构化,突出重要差异性,区分相似动作。
- CSCL(Class-Specific contrast learning):生成类中心对比损失,实现类内聚集、类间分离,提升特征在类间可判性、类内一致性,适用于细粒度识别。
综合这些模块,ProtoGCN是一个完整的端到端的可训练体系结构,从结构建模到特征重建再到损失函数,完整的实现了模型对相似动作的识别,在NTURGB+D、NTU120、Kinetics-Skeleton、FineGYM多个数据集上都取得了很好的成效,大幅度超越已有的方法,尤其是在细粒度分类上。
本文的目标是了解并实现论文[8]提出的原型化的GCN,在理论层面对其模块设计的动机和数学基础进行阐述,在代码层面对其训练过程和模型架构进行解释,并在实际数据集上观察其效果,而不仅是关注最终的准确率,还观察其在参数变化下的鲁棒性,尽可能对其方法的可解释性和实用性有一个完整的认知;同时发现原论文中的问题和自身的改进方法思路。
本报告的内容安排如下:第2章是对GCN动作识别算法、原型学习和对比学习等方法的综述;第3章是关于ProtoGCN的总体结构及其三个关键部分的介绍;第4章包括实验设置、数据集、超参数的选取及实验结果;第5章是对该课题的一些问题分析和后续工作展望;第6、7章是分别是对该实训项目的总结和对本门课程学习的总结。
文献总结
骨架动作识别技术进展与关键挑战
近年来,基于骨架的数据建模方法迅速成为人体动作识别研究的主流方向之一。相比传统使用 RGB 图像或光流特征的视觉建模方法,骨架数据具有更强的抗光照干扰性、对背景依赖性弱、表达紧凑、计算高效等优点,特别适用于实时、低算力场景下的动作识别[1]。得益于 OpenPose、Kinect 等人体姿态估计方法的成熟发展,研究者可以稳定地获取 2D/3D 骨架序列,为动作识别模型提供结构化、序列化的输入。人体骨骼结构信息作为识别人体动作的常用信息输入,具有结构简单、体积小、对光照、背景信息不敏感等优点[9]。骨骼由关节点构成,天然具有图形结构,容易进行联合建模。
早期的骨架动作识别方法以循环神经网络(RNN)为主,典型代表如 BiLSTM 等模型,擅长从时间维度建模骨架点的动态演化轨迹,但在捕捉空间结构信息方面能力有限[1]。随后,一些研究者尝试将骨架序列转化为伪图像形式,通过卷积神经网络(CNN)提取空间特征,但此类方式往往依赖复杂的预处理,且对骨架结构的建模能力较弱。
在2018年,ST-GCN(Spatial-Temporal Graph Convolutional Network)[2] 首次将骨架数据建模为图结构,其中节点表示人体关节,边表示自然连接的骨骼链接,从而使用图卷积网络(GCN)联合建模空间结构与时间序列,开创了骨架动作识别的“图建模”范式。ST-GCN 的成功为后续基于图神经网络的动作识别研究奠定了基础,这个创新的方式可以充分利用关节点的时空信息,并在NTURGB + DandKinetics数据集取得了不错的成绩。
在 ST-GCN 的基础上,研究者围绕图结构设计、邻接矩阵表达能力、特征传播机制等方面不断改进。例如,2s-AGCN(Two-stream Adaptive GCN)[3] 引入了自适应邻接机制,通过对关节关系的动态调整增强模型的语义表达能力;CTR-GCN(Channel-wise Topology Refinement GCN)[4] 在通道维度引入拓扑优化,进一步提升了空间语义建模的精度与灵活性;PYSKL[7] 则在数据预处理和训练策略上进行实践优化,提出了多个增强和精简策略,使得GCN在实际部署中更为高效鲁棒。这些研究成果充分体现了 GCN 模型在时空融合建模方面的强大潜力,也推动了骨架动作识别从粗分类向高精度识别的进步。
然而,随着任务难度的提升,尤其是在细粒度识别(fine-grained recognition)和高相似度动作分类等复杂场景下,现有 GCN 架构仍面临显著挑战,主要体现在以下三个方面:
1、局部细节建模能力弱:多数GCN结构关注全局图形轮廓,缺乏对关节局部动态的高分辨建模能力,导致在如“写字”与“打字”、“鼓掌”与“擦手”等动作类别中容易混淆。
2、图结构适应性有限:多数方法采用静态或统一的图结构(如固定邻接矩阵或共享自适应图),无法灵活应对不同样本间在骨架连接模式上的细微差异,缺乏对个体化结构变化的感知能力。
3、监督信号过于单一:当前主流方法大多依赖交叉熵损失进行训练,忽视了样本之间的类内/类间关系分布,难以引导模型学习具有判别力的特征空间。
为解决上述问题,近年研究逐渐向更复杂、更结构化的设计发展,如引入动态图建模、原型表达机制和对比监督机制等,从结构表达、表示学习与优化目标多个角度出发,系统性提升模型在细粒度动作识别中的能力。例如 BlockGCN[16] 通过静态与动态拓扑编码增强图结构保留能力,DeGCN[17] 则采用可变形图结构与多流感知提升对动作差异的敏感度。
本文所着重研究的ProtoGCN也需要通过结合三大模块MTE、PRN、CSCL解决以上问题,从结构、表示与监督三方面共同增强模型细粒度动作识别的性能。
综上,骨架动作识别的发展趋势正在从静态、统一建模逐渐演进到结构自适应、关系多样化与监督增强的方向,GCN架构也从传统图卷积走向结构感知更强、判别能力更优的深度图模型体系。
GCN结构优化方法
由于相比传统基于图像或光流的方法,骨架数据本质上具有图结构特性,因此图卷积网络(Graph Convolutional Networks, GCN)被广泛应用于该领域,成为主流建模框架之一。
早期工作如 ST-GCN 首次将 GCN 引入骨架动作识别任务中,利用预定义的骨架连接关系构建时空图,对关节间的空间结构和动作序列中的时间变化进行联合建模。该方法奠定了基于图的动作识别基本范式,但其在图构建方式上相对固定,难以适应不同动作中多样化的语义关系。
伴随着GCN网络在骨架动作识别领域上的成功,在后续的研究中,主要是对拓扑结构和模型效率上的改进。
为解决这一问题,后续研究逐渐引入自适应图结构学习机制,比如通过引入可学习的邻接矩阵,使模型能够根据不同输入动态调整图结构,从而增强对动作语义的建模能力。然而,这类方法也暴露出一些局限,例如训练过程中易产生“灾难性遗忘”现象(如图2所示),使得模型逐渐偏离人体原始骨架结构,削弱对先验拓扑的建模能力。同时,使用单一图结构进行全局建模也限制了模型对多层次语义关系的表达。
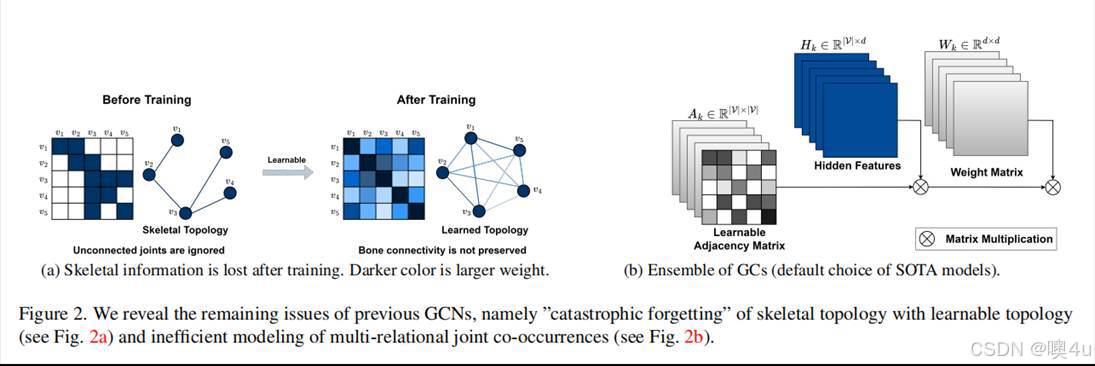
图2 “灾难性遗忘”:GCN训练过程中拓扑信息丢失
为进一步提升模型结构感知能力与多语义建模能力,最新研究如 BlockGCN 引入了“拓扑编码”与“语义分组”的思想,通过显式引入静态与动态的拓扑信息,并采用分组图卷积机制以提升结构保留性与表达多样性,实现了在准确率与计算效率上的双重提升。这一系列优化表明,GCN 在骨架动作识别中的研究正逐步从静态图建模向结构自适应、语义可解释、效率可控的方向演进。
不仅如此,自适应拓扑作为常用改进方式,如图所示,自适应拓扑通过学习每一层的邻接矩阵,根据输入动作的实际情况,不断调整自身连通性,使得自适应拓扑能够跟随其局部结构的变化,使图结构更加敏感于样本差异。
与此同时,GCN的发展还局限于计算复杂度和参数量。为了解决这个问题,BlockGCN提出了一种将骨架图划分为不同块的设计方案:每个块包含一个局部图卷积后经过投影层整合成一图。这种设计方案显著降低了参数量和计算复杂度,而不会改变原始拓扑结构。BlockGCN在NTURGB + D120上取得了最高的精度并保持了轻量级模型。说明了结构层次设计的重要性。
尽管上述结构改进方式对模型效率、表达能力增强等有很好的效果,然而上述方式只考虑如何更好的描述图式结构,对如何更好的区分类别、细粒度动作等依然缺乏足够的关注,特别是样本级结构变化、类别比较监督等。因此,上述两方面动态化图增强、可解释原型重构、类中心对比损失在ProtoGCN的基础上被引入,以在结构和优化两方面进行完整改进。
原型与对比学习在骨架动作识别中的整合趋势
近年来,为了进一步提升模型对细粒度骨架动作的建模能力,越来越多研究开始将原型学习(Prototypical Learning)与对比学习(Contrastive Learning)机制引入图神经网络模型中,以增强模型对高相似度类别间微小差异的感知能力。这两类机制分别从结构表示表达与类别判别优化两个维度,有效补足了传统GCN对局部细节敏感性弱的问题。
原型学习最初在图像识别与元学习任务中提出,其核心思想是为每个类别学习一个或多个“类别原型”,使模型在训练过程中能够学习到具有代表性的中心表达[11]。该机制在骨架动作识别中的应用主要集中于通过维护可学习的原型库,将复杂动作表征解构为若干典型子结构的组合,从而更好地抽象和强调动作中的关键部位。例如 ProtoGCN 中的原型重构网络(PRN)[8],即通过原型加权方式表达骨架图的判别性局部结构,尤其适用于书写、打字等“宏观形态接近、微观行为差异显著”的动作对。
对比学习最初作为一种无监督的预训练手段被广泛应用于表征学习,其核心目标是通过“拉近正样本对,拉远负样本对”来增强模型的判别能力。近年来发展出的有监督类特异性对比学习(Class-Specific Contrastive Learning)更进一步地引入了类别信息,将其与中心聚类思想结合,在骨架动作识别中取得良好成效[10]。例如,StructureGCL通过在图层级别构造跨样本对比任务,有效增强了骨架结构的判别性;而ProtoGCN的CSCL模块[8]则通过引入类中心对比损失,在样本与类原型之间构造聚散监督,从而进一步提升类内一致性与类间可分性。
然而,现有大多数研究往往仅从结构建模、原型表达或对比监督三者中选取其一进行优化,缺乏三者融合协同的系统性设计。ProtoGCN 则首次将三者整合为一个统一架构:基于 PRN 模块学习原型空间中的结构组合,利用 MTE 模块进行动态图构建以适配个体差异,进而借助 CSCL 模块通过类中心引导对比学习,实现了从结构建模到监督优化的闭环协同。这种“原型+对比+动态图结构”三维融合机制,不仅在理论上具备更强的结构表达能力,也在实践中于 NTU-120、FineGYM 等细粒度数据集上取得了显著的性能提升[8][9]。
本报告的复现实验进一步验证了该机制的有效性,通过调整原型数量和对比损失权重,我们观察到模型在相似类别判别任务中的准确率和收敛速度均有明显提升。这也表明,在骨架动作识别从粗分类向细粒度识别转向的趋势下,原型表达与判别监督的融合机制将成为未来骨架图模型设计的重要方向。
研究内容 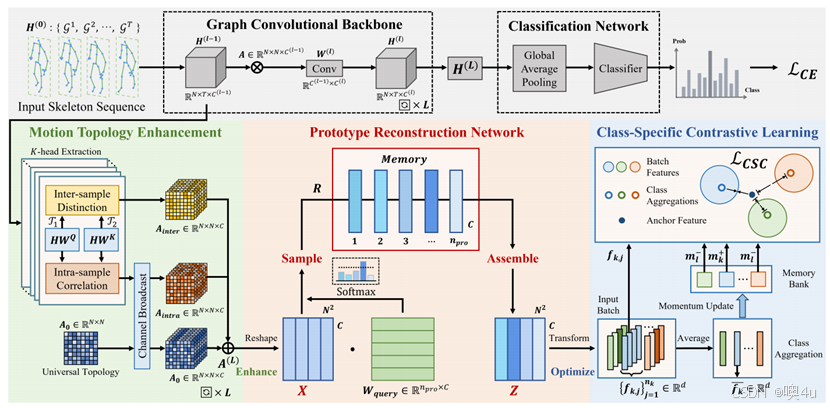
图3 ProtoGCN的整体架构图
由图3可知,网络主干部分(灰色)的输入是一段时间序列的骨架数据,包含N个关节点、T帧、C维特征。在图卷积网络主干部分,通过每一层的卷积操作,最后一层输出H(L),通过全局平均池化和MLP分类器得到最终分类概率,使用交叉熵损失Lce。原文的工作主要在于通过下方绿、红、蓝三部分形成的重构图特征强化细粒度动作关系的表达以及提高类间区分能力,最终实现对“写字vs打字”这类微差动作的判别能力提升。
绿色部分则是Motion Topology Enhancement,即MTE,运动拓扑增强。该机制的核心目的是在原始骨架图结构A的基础上,动态生成inter(差异)图和intra(相似)图,并通过可学习的标量权重进行融合,构成一个每个样本、每一层、每一时刻都不同的动态图邻接矩阵,用于更好地区分相似动作。分别用两个不同的1×1卷积对输入做特征投影,变成不同空间表达形式。将时间维度做平均池化后,每个关节只保留一个时序平均特征表示,用于构图。这两个表示之间的关系就是后续要学习的“图连接结构”。inter_graph(跨关节差异图)通过关节对之间的差计算获得,表示相对运动变化;而intra_graph(相似度图)通过关节间余弦相似性计算获得,表示内部结构一致性。将A_inter和A_intra与静态拓扑A相加,形成增强版拓扑,每个样本、每个通道、每层网络的A都是如此动态计算出来的。以上在代码中被定义为“unit_gcn”类,这部分设计使得GCN能动态调节邻接关系,关注关键细节区域。
class unit_gcn(nn.Module):
def __init__(self,in_channels,out_channels,A,ratio=0.125,intra_act='softmax',inter_act='tanh',norm='BN',act='ReLU'):
super().__init__()
self.A = nn.Parameter(A.clone())
self.pre = nn.Sequential(
nn.Conv2d(in_channels, mid_channels * num_subsets, 1),
build_norm_layer(self.norm_cfg, mid_channels * num_subsets)[1], self.act)
self.post = nn.Conv2d(mid_channels * num_subsets, out_channels, 1)
。。。
def forward(self, x, A=None):
n, c, t, v = x.shape
res = self.down(x)
A = self.A[None, :, None, None]
pre_x = self.pre(x).reshape(n, self.num_subsets, self.mid_channels, t, v)
tmp_x = x
x1 = self.conv1(tmp_x).reshape(n, self.num_subsets, self.mid_channels, -1, v)
x2 = self.conv2(tmp_x).reshape(n, self.num_subsets, self.mid_channels, -1, v)
x1 = x1.mean(dim=-2, keepdim=True) # mean over T (time) [N, K, C', 1, V]
x2 = x2.mean(dim=-2, keepdim=True)
graph_list = []
diff = x1.unsqueeze(-1) - x2.unsqueeze(-2) # 计算 V×V 的差异矩阵 [N, K, C', 1, V, V]
inter_graph = getattr(self, self.inter_act)(diff) * self.alpha[0] # 可学习标量 α(权重)训练中调节 inter 图的重要性
A = inter_graph + A
graph_list.append(inter_graph)
intra_graph = torch.einsum('nkctv,nkctw->nktvw', x1, x2)[:, :, None] #每对关节的内积(即相似度)
intra_graph = getattr(self, self.intra_act)(intra_graph) * self.beta[0] #另一可学习因子,控制 intra 图的强度
A = intra_graph + A
graph_list.append(intra_graph)
A = A.squeeze(3)
x = torch.einsum('nkctv,nkcvw->nkctw', pre_x, A).contiguous()
x = x.reshape(n, -1, t, v)
x = self.post(x)
get_gcl_graph = graph_list[0] + graph_list[1]
get_gcl_graph = get_gcl_graph.squeeze(3)
get_gcl_graph = get_gcl_graph.reshape(n, -1, v, v)
return self.act(self.bn(x) + res), get_gcl_graph
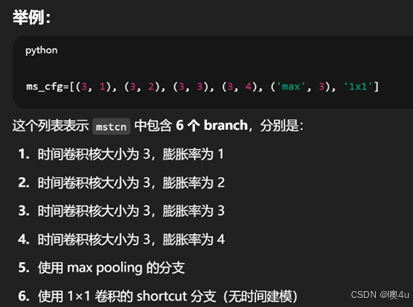
在每一个整体GCN模块中,总是先执行unit_gcn做空间卷积,再执行mstcn做时间建模,并返回卷积后的特征与图结构(gcl_graph)。Mstcn是“多尺度时间卷积网络”,用于捕捉不同时间尺度上的动作变化特征。一个分支就是一个不同的时序建模路径,对应一个不同配置(核大小/膨胀率)的时间卷积子网络。这些分支会并行作用于同一个输入,每个负责建模不同尺度的时间动态信息。这一结构让模型能适应动作的不同节奏与持续时间。它增加了感受野,使得卷积可以“看到”更长时间范围的上下文信息,而不增加参数量。在动作识别中,不同动作可能节奏快慢不同,因此引入多种 dilation(即不同时间感知尺度)是非常必要的。
import torch
import torch.nn as nn
from mmcv.cnn import build_norm_layer
from .init_func import bn_init, conv_init
import sys
class unit_tcn(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=9, stride=1, dilation=1, norm='BN', dropout=0):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.norm_cfg = norm if isinstance(norm, dict) else dict(type=norm)
pad = (kernel_size + (kernel_size - 1) * (dilation - 1) - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=(kernel_size, 1),
padding=(pad, 0),
stride=(stride, 1),
dilation=(dilation, 1))
self.bn = build_norm_layer(self.norm_cfg, out_channels)[1] if norm is not None else nn.Identity()
self.drop = nn.Dropout(dropout, inplace=True)
self.stride = stride
def forward(self, x):
return self.drop(self.bn(self.conv(x)))
def init_weights(self):
conv_init(self.conv)
bn_init(self.bn, 1)
class mstcn(nn.Module):
def __init__(self,
in_channels,
out_channels,
mid_channels=None,
num_joints=25,
dropout=0.,
ms_cfg=[(3, 1), (3, 2), (3, 3), (3, 4), ('max', 3), '1x1'],
stride=1):
super().__init__()
self.ms_cfg = ms_cfg
num_branches = len(ms_cfg)
self.num_branches = num_branches
self.in_channels = in_channels
self.out_channels = out_channels
self.act = nn.ReLU()
self.num_joints = num_joints
self.add_coeff = nn.Parameter(torch.zeros(self.num_joints))
if mid_channels is None:
mid_channels = out_channels // num_branches
rem_mid_channels = out_channels - mid_channels * (num_branches - 1)
else:
assert isinstance(mid_channels, float) and mid_channels > 0
mid_channels = int(out_channels * mid_channels)
rem_mid_channels = mid_channels
self.mid_channels = mid_channels
self.rem_mid_channels = rem_mid_channels
branches = []
for i, cfg in enumerate(ms_cfg):
branch_c = rem_mid_channels if i == 0 else mid_channels
if cfg == '1x1':
branches.append(nn.Conv2d(in_channels, branch_c, kernel_size=1, stride=(stride, 1)))
continue
assert isinstance(cfg, tuple)
if cfg[0] == 'max':
branches.append(
nn.Sequential(
nn.Conv2d(in_channels, branch_c, kernel_size=1), nn.BatchNorm2d(branch_c), self.act,
nn.MaxPool2d(kernel_size=(cfg[1], 1), stride=(stride, 1), padding=(1, 0))))
continue
assert isinstance(cfg[0], int) and isinstance(cfg[1], int)
branch = nn.Sequential(
nn.Conv2d(in_channels, branch_c, kernel_size=1), nn.BatchNorm2d(branch_c), self.act,
unit_tcn(branch_c, branch_c, kernel_size=cfg[0], stride=stride, dilation=cfg[1], norm=None))
branches.append(branch)
self.branches = nn.ModuleList(branches)
tin_channels = mid_channels * (num_branches - 1) + rem_mid_channels
self.transform = nn.Sequential(
nn.BatchNorm2d(tin_channels), self.act, nn.Conv2d(tin_channels, out_channels, kernel_size=1))
self.bn = nn.BatchNorm2d(out_channels)
self.drop = nn.Dropout(dropout, inplace=True)
def inner_forward(self, x):
N, C, T, V = x.shape
x = torch.cat([x, x.mean(-1, keepdim=True)], -1)
branch_outs = []
for tempconv in self.branches:
out = tempconv(x)
branch_outs.append(out)
out = torch.cat(branch_outs, dim=1)
local_feat = out[..., :V]
global_feat = out[..., V]
global_feat = torch.einsum('nct,v->nctv', global_feat, self.add_coeff[:V])
feat = local_feat + global_feat
feat = self.transform(feat)
return feat
def forward(self, x):
out = self.inner_forward(x)
out = self.bn(out)
return self.drop(out)import copy as cp
import torch
import torch.nn as nn
from mmcv.cnn import build_norm_layer
from mmcv.runner import load_checkpoint
from ...utils import Graph, cache_checkpoint
from ..builder import BACKBONES
from .utils import unit_gcn, mstcn, unit_tcn
EPS = 1e-4
class GCN_Block(nn.Module):
def __init__(self, in_channels, out_channels, A, stride=1, residual=True, **kwargs):
super().__init__()
common_args = ['act', 'norm', 'g1x1']
for arg in common_args:
if arg in kwargs:
value = kwargs.pop(arg)
kwargs['tcn_' + arg] = value
kwargs['gcn_' + arg] = value
gcn_kwargs = {k[4:]: v for k, v in kwargs.items() if k[:4] == 'gcn_'}
tcn_kwargs = {k[4:]: v for k, v in kwargs.items() if k[:4] == 'tcn_'}
kwargs = {k: v for k, v in kwargs.items() if k[1:4] != 'cn_'}
assert len(kwargs) == 0
self.gcn = unit_gcn(in_channels, out_channels, A, **gcn_kwargs)
self.tcn = mstcn(out_channels, out_channels, stride=stride, **tcn_kwargs)
self.relu = nn.ReLU()
if not residual:
self.residual = lambda x: 0
elif (in_channels == out_channels) and (stride == 1):
self.residual = lambda x: x
else:
self.residual = unit_tcn(in_channels, out_channels, kernel_size=1, stride=stride)
def forward(self, x, A=None):
"""Defines the computation performed at every call."""
res = self.residual(x)
x, gcl_graph = self.gcn(x, A)
x = self.tcn(x) + res
return self.relu(x), gcl_graph
"""
****************************************
*** Prototype Reconstruction Network ***
****************************************
"""
class Prototype_Reconstruction_Network(nn.Module):
def __init__(self, dim, n_prototype=100, dropout=0.1):
super().__init__()
self.query_matrix = nn.Linear(dim, n_prototype, bias = False)
self.memory_matrix = nn.Linear(n_prototype, dim, bias = False)
self.softmax = torch.softmax
self.dropout = nn.Dropout(dropout)
def forward(self, x):
query = self.softmax(self.query_matrix(x), dim=-1)
z = self.memory_matrix(query)
return self.dropout(z)
@BACKBONES.register_module()
class ProtoGCN(nn.Module):
def __init__(self,
graph_cfg,
in_channels=3,
base_channels=96,
ch_ratio=2,
num_stages=10,
inflate_stages=[5, 8],
down_stages=[5, 8],
data_bn_type='VC',
num_person=2,
pretrained=None,
**kwargs):
super().__init__()
self.graph = Graph(**graph_cfg)
A = torch.tensor(self.graph.A, dtype=torch.float32, requires_grad=False)
self.data_bn_type = data_bn_type
self.kwargs = kwargs
if data_bn_type == 'MVC':
self.data_bn = nn.BatchNorm1d(num_person * in_channels * A.size(1))
elif data_bn_type == 'VC':
self.data_bn = nn.BatchNorm1d(in_channels * A.size(1))
else:
self.data_bn = nn.Identity()
num_prototype = kwargs.pop('num_prototype', 100)
lw_kwargs = [cp.deepcopy(kwargs) for i in range(num_stages)]
for k, v in kwargs.items():
if isinstance(v, tuple) and len(v) == num_stages:
for i in range(num_stages):
lw_kwargs[i][k] = v[i]
lw_kwargs[0].pop('tcn_dropout', None)
lw_kwargs[0].pop('g1x1', None)
lw_kwargs[0].pop('gcn_g1x1', None)
self.in_channels = in_channels
self.base_channels = base_channels
self.ch_ratio = ch_ratio
self.inflate_stages = inflate_stages
self.down_stages = down_stages
modules = []
if self.in_channels != self.base_channels:
modules = [GCN_Block(in_channels, base_channels, A.clone(), 1, residual=False, **lw_kwargs[0])]
inflate_times = 0
down_times = 0
for i in range(2, num_stages + 1):
stride = 1 + (i in down_stages)
in_channels = base_channels
if i in inflate_stages:
inflate_times += 1
out_channels = int(self.base_channels * self.ch_ratio ** inflate_times + EPS)
base_channels = out_channels
modules.append(GCN_Block(in_channels, out_channels, A.clone(), stride, **lw_kwargs[i - 1]))
down_times += (i in down_stages)
if self.in_channels == self.base_channels:
num_stages -= 1
self.num_stages = num_stages
self.gcn = nn.ModuleList(modules)
self.pretrained = pretrained
out_channels = base_channels
norm = 'BN'
norm_cfg = norm if isinstance(norm, dict) else dict(type=norm)
self.post = nn.Conv2d(out_channels, out_channels, 1)
self.bn = build_norm_layer(norm_cfg, out_channels)[1]
self.relu = nn.ReLU()
dim = 384 # base_channels * 4
self.prn = Prototype_Reconstruction_Network(dim, num_prototype)
def init_weights(self):
if isinstance(self.pretrained, str):
self.pretrained = cache_checkpoint(self.pretrained)
load_checkpoint(self, self.pretrained, strict=False)
def forward(self, x):
N, M, T, V, C = x.size()
x = x.permute(0, 1, 3, 4, 2).contiguous()
if self.data_bn_type == 'MVC':
x = self.data_bn(x.view(N, M * V * C, T))
else:
x = self.data_bn(x.view(N * M, V * C, T))
x = x.view(N, M, V, C, T).permute(0, 1, 3, 4, 2).contiguous().view(N * M, C, T, V)
get_graph = []
for i in range(self.num_stages):
x, gcl_graph = self.gcn[i](x)
# N*M C V V
get_graph.append(gcl_graph)
x = x.reshape((N, M) + x.shape[1:])
c_graph = x.size(2)
graph = get_graph[-1]
# N C V V -> N C V*V
graph = graph.view(N, M, c_graph, V, V).mean(1).view(N, c_graph, V * V)
the_graph_list = []
for i in range(N):
# V*V C
the_graph = graph[i].permute(1, 0)
# V*V C
the_graph = self.prn(the_graph)
# C V V
the_graph = the_graph.permute(1, 0).view(c_graph, V, V)
the_graph_list.append(the_graph)
# N C V V
re_graph = torch.stack(the_graph_list, dim=0)
re_graph = self.post(re_graph)
reconstructed_graph = self.relu(self.bn(re_graph))
# N V*V
reconstructed_graph = reconstructed_graph.mean(1).view(N, -1)
return x, reconstructed_graph红色部分则是Prototype Reconstruction Network,即PRN,原型学习模块。这是ProtoGCN的核心,该模块的核心目标是:将骨架图的拓扑表达解构为若干可学习原型(prototype)的加权组合,从而突出动作中具有判别性的局部运动结构,尤其用于区分在整体轨迹上相似的动作(如“写字”与“打字”)。其整体结构可以理解为一个encoder-decoder式瓶颈结构,但编码器部分不直接压缩,而是引导输入去“在prototype空间中寻址和重构”。从上一层得到增强后的骨架图拓扑后,首先将其重构为二维矩阵,每一行表示某一对关节点之间的通道特征,形成一种“关节关系空间”的表示基础。记忆模块维护一个可学习的记忆矩阵,其中每一行mi表示一种“动作基元”或“关节间关系模式”。这些原型在训练中自动学习得到,代表不同的动作关系类型(如“单手快速移动”“双手对称静止”等),并会被用于构建输入的组合式表示。使用另一个可学习的询问矩阵将输入投影到原型空间,通过softmax激活计算每个输入样本对每个原型的响应权重,即可理解为输入骨架特征作为query,在prototype空间中对各个原型打分。最后利用上述响应权重对memory中的原型加权求和,得到重构后的特征表示,其中较高权重的原型往往对应输入中的关键判别结构。
由于原型是跨样本共享的,它们具备了一定的抽象能力,能够帮助模型排除非判别性的个体差异(如幅度、方向、速度等非结构性变化),聚焦于局部运动的本质结构。这一机制与后续的对比学习机制天然协同:后者对原型组合结果进行聚类与拉远操作,使得每类动作倾向于激活一组独特原型,从而进一步强化原型的判别性。
蓝色模块Class-Specific Contrastive Learning,即CSCL,类特异性对比学习模块。该模块的目标是进一步提升原型重构后的特征表示的判别性,特别是在区分相似类别时增强类间边界。通过在特征压缩和采用momentum更新策略构建类中心后引入对比损失Lcsc以鼓励样本“靠近同类中心,远离其他类中心”,ProtoGCN被引导去学习“更集中”的类内表示,同时让不同类别在prototype空间中激活不同的组合,进一步强化类间可分性。CSCL是整个架构中的监督性正则模块,与PRN搭配使用,提升了模型对细粒度相似动作的判别能力。

图4 ProtoGCN的仓库项目结构
configs中定义了数据路径、模型结构、训练超参数、对比学习设置、分布式训练选项等。以下是nut120_xset/b.py为例:
modality = 'b'
graph = 'nturgb+d'
work_dir = f'./work_dirs/ntu120_xset/b'
model = dict(
type='RecognizerGCN',
backbone=dict(
type='ProtoGCN',
num_prototype=100,
tcn_ms_cfg=[(3, 1), (3, 2), (3, 3), (3, 4), ('max', 3), '1x1'],
graph_cfg=dict(layout=graph, mode='random', num_filter=8, init_off=.04, init_std=.02)),
cls_head=dict(type='SimpleHead', joint_cfg='nturgb+d', num_classes=120, in_channels=384, weight=0.3))
dataset_type = 'PoseDataset'
ann_file = '/data/nturgbd/ntu120_3danno.pkl'
train_pipeline = [
dict(type='PreNormalize3D', align_spine=False),
dict(type='RandomRot', theta=0.2),
# Effective Augmentation
dict(type='Spatial_Flip', dataset='nturgb+d', p=0.5),
dict(type='GenSkeFeat', feats=[modality]),
dict(type='UniformSampleDecode', clip_len=100),
dict(type='FormatGCNInput'),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
val_pipeline = [
dict(type='PreNormalize3D', align_spine=False),
dict(type='GenSkeFeat', feats=[modality]),
dict(type='UniformSampleDecode', clip_len=100, num_clips=1),
dict(type='FormatGCNInput'),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
test_pipeline = [
dict(type='PreNormalize3D', align_spine=False),
dict(type='GenSkeFeat', feats=[modality]),
dict(type='UniformSampleDecode', clip_len=100, num_clips=10),
dict(type='FormatGCNInput'),
dict(type='Collect', keys=['keypoint', 'label'], meta_keys=[]),
dict(type='ToTensor', keys=['keypoint'])
]
data = dict(
videos_per_gpu=16,
workers_per_gpu=4,
test_dataloader=dict(videos_per_gpu=1),
train=dict(type=dataset_type, ann_file=ann_file, pipeline=train_pipeline, split='xset_train'),
val=dict(type=dataset_type, ann_file=ann_file, pipeline=val_pipeline, split='xset_val'),
test=dict(type=dataset_type, ann_file=ann_file, pipeline=test_pipeline, split='xset_val'))
# setting: 4 GPU 64 0.1 -> 1 GPU 64/4=16 0.1/4=0.025
optimizer = dict(type='SGD', lr=0.025, momentum=0.9, weight_decay=0.0005, nesterov=True)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='CosineAnnealing', min_lr=0, by_epoch=False)
total_epochs = 150
checkpoint_config = dict(interval=1)
evaluation = dict(interval=1, metrics=['top_k_accuracy'])
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])实验结果与分析
评估指标方面,模块提供了包括混淆矩阵、平均类别准确率、Top-K准确率和多标签场景下的mAP等函数,适配多种评价需求。通过seg_interval参数配置不同训练阶段采用不同的评估间隔,以提高训练效率与监控粒度。
import numpy as np
from mmcv.runner import DistEvalHook as BasicDistEvalHook
class DistEvalHook(BasicDistEvalHook):
greater_keys = [
'acc', 'top', 'AR@', 'auc', 'precision', 'mAP@', 'Recall@'
]
less_keys = ['loss']
def __init__(self, *args, save_best='auto', seg_interval=None, **kwargs):
super().__init__(*args, save_best=save_best, **kwargs)
self.seg_interval = seg_interval
if seg_interval is not None:
assert isinstance(seg_interval, list)
for i, tup in enumerate(seg_interval):
assert isinstance(tup, tuple) and len(tup) == 3 and tup[0] < tup[1]
if i < len(seg_interval) - 1:
assert tup[1] == seg_interval[i + 1][0]
assert self.by_epoch
assert self.start is None
def _find_n(self, runner):
current = runner.epoch
for seg in self.seg_interval:
if current >= seg[0] and current < seg[1]:
return seg[2]
return None
def _should_evaluate(self, runner):
if self.seg_interval is None:
return super()._should_evaluate(runner)
n = self._find_n(runner)
assert n is not None
return self.every_n_epochs(runner, n)
def confusion_matrix(y_pred, y_real, normalize=None):
"""Compute confusion matrix.
Args:
y_pred (list[int] | np.ndarray[int]): Prediction labels.
y_real (list[int] | np.ndarray[int]): Ground truth labels.
normalize (str | None): Normalizes confusion matrix over the true
(rows), predicted (columns) conditions or all the population.
If None, confusion matrix will not be normalized. Options are
"true", "pred", "all", None. Default: None.
Returns:
np.ndarray: Confusion matrix.
"""
if normalize not in ['true', 'pred', 'all', None]:
raise ValueError("normalize must be one of {'true', 'pred', "
"'all', None}")
if isinstance(y_pred, list):
y_pred = np.array(y_pred)
if not isinstance(y_pred, np.ndarray):
raise TypeError(
f'y_pred must be list or np.ndarray, but got {type(y_pred)}')
if not y_pred.dtype == np.int64:
raise TypeError(
f'y_pred dtype must be np.int64, but got {y_pred.dtype}')
if isinstance(y_real, list):
y_real = np.array(y_real)
if not isinstance(y_real, np.ndarray):
raise TypeError(
f'y_real must be list or np.ndarray, but got {type(y_real)}')
if not y_real.dtype == np.int64:
raise TypeError(
f'y_real dtype must be np.int64, but got {y_real.dtype}')
label_set = np.unique(np.concatenate((y_pred, y_real)))
num_labels = len(label_set)
max_label = label_set[-1]
label_map = np.zeros(max_label + 1, dtype=np.int64)
for i, label in enumerate(label_set):
label_map[label] = i
y_pred_mapped = label_map[y_pred]
y_real_mapped = label_map[y_real]
confusion_mat = np.bincount(
num_labels * y_real_mapped + y_pred_mapped,
minlength=num_labels**2).reshape(num_labels, num_labels)
with np.errstate(all='ignore'):
if normalize == 'true':
confusion_mat = (
confusion_mat / confusion_mat.sum(axis=1, keepdims=True))
elif normalize == 'pred':
confusion_mat = (
confusion_mat / confusion_mat.sum(axis=0, keepdims=True))
elif normalize == 'all':
confusion_mat = (confusion_mat / confusion_mat.sum())
confusion_mat = np.nan_to_num(confusion_mat)
return confusion_mat
def mean_class_accuracy(scores, labels):
"""Calculate mean class accuracy.
Args:
scores (list[np.ndarray]): Prediction scores for each class.
labels (list[int]): Ground truth labels.
Returns:
np.ndarray: Mean class accuracy.
"""
pred = np.argmax(scores, axis=1)
cf_mat = confusion_matrix(pred, labels).astype(float)
cls_cnt = cf_mat.sum(axis=1)
cls_hit = np.diag(cf_mat)
mean_class_acc = np.mean(
[hit / cnt if cnt else 0.0 for cnt, hit in zip(cls_cnt, cls_hit)])
return mean_class_acc
def top_k_accuracy(scores, labels, topk=(1, )):
"""Calculate top k accuracy score.
Args:
scores (list[np.ndarray]): Prediction scores for each class.
labels (list[int]): Ground truth labels.
topk (tuple[int]): K value for top_k_accuracy. Default: (1, ).
Returns:
list[float]: Top k accuracy score for each k.
"""
res = []
labels = np.array(labels)[:, np.newaxis]
for k in topk:
max_k_preds = np.argsort(scores, axis=1)[:, -k:][:, ::-1]
match_array = np.logical_or.reduce(max_k_preds == labels, axis=1)
topk_acc_score = match_array.sum() / match_array.shape[0]
res.append(topk_acc_score)
return res
def mean_average_precision(scores, labels):
"""Mean average precision for multi-label recognition.
Args:
scores (list[np.ndarray]): Prediction scores of different classes for
each sample.
labels (list[np.ndarray]): Ground truth many-hot vector for each
sample.
Returns:
np.float: The mean average precision.
"""
results = []
scores = np.stack(scores).T
labels = np.stack(labels).T
for score, label in zip(scores, labels):
precision, recall, _ = binary_precision_recall_curve(score, label)
ap = -np.sum(np.diff(recall) * np.array(precision)[:-1])
results.append(ap)
results = [x for x in results if not np.isnan(x)]
if results == []:
return np.nan
return np.mean(results)
def binary_precision_recall_curve(y_score, y_true):
"""Calculate the binary precision recall curve at step thresholds.
Args:
y_score (np.ndarray): Prediction scores for each class.
Shape should be (num_classes, ).
y_true (np.ndarray): Ground truth many-hot vector.
Shape should be (num_classes, ).
Returns:
precision (np.ndarray): The precision of different thresholds.
recall (np.ndarray): The recall of different thresholds.
thresholds (np.ndarray): Different thresholds at which precision and
recall are tested.
"""
assert isinstance(y_score, np.ndarray)
assert isinstance(y_true, np.ndarray)
assert y_score.shape == y_true.shape
# make y_true a boolean vector
y_true = (y_true == 1)
# sort scores and corresponding truth values
desc_score_indices = np.argsort(y_score, kind='mergesort')[::-1]
y_score = y_score[desc_score_indices]
y_true = y_true[desc_score_indices]
# There may be ties in values, therefore find the `distinct_value_inds`
distinct_value_inds = np.where(np.diff(y_score))[0]
threshold_inds = np.r_[distinct_value_inds, y_true.size - 1]
# accumulate the true positives with decreasing threshold
tps = np.cumsum(y_true)[threshold_inds]
fps = 1 + threshold_inds - tps
thresholds = y_score[threshold_inds]
precision = tps / (tps + fps)
precision[np.isnan(precision)] = 0
recall = tps / tps[-1]
# stop when full recall attained
# and reverse the outputs so recall is decreasing
last_ind = tps.searchsorted(tps[-1])
sl = slice(last_ind, None, -1)
return np.r_[precision[sl], 1], np.r_[recall[sl], 0], thresholds[sl]数据集介绍
原文中,作者在NTU-120[5],NTU-60[5],Kinetics[6]和FineGYM[9]四个数据集上进行了实验。其中NTU-120是动作识别任务中较为经典且具有一定挑战性的数据集,而FineGYM则是目前最全面的结构化细粒度动作数据集。
作者在实验过程中,引入了InfoGCN中的六流集成策略以提高准确率,即将关节点位置,骨骼朝向,及其位移等6种模态的数据集成。由于训练资源限制,我们在接下来的实验中仅使用关节点位置数据,并基于NTU-60进行初步复现,且基于FineGYM进行相关对比实验。
NTU-60又称NTU-RGB+D数据集,由南洋理工大学发布。其包含60类日常动作,共56880个样本。其从3个不同角度使用Kinect采集25关节骨架,采集的数据形式包括深度信息、3D骨骼信息、RGB帧以及红外序列。
其在划分训练集和测试集时使用了两种不同的标准,一种根据受试者的ID来进行划分,而另一种根据收集数据时的相机来划分。数据在同一竖直高度从-45°、0°和45°三个不同的水平角度进行采集,受试者对左和右两个相机风别做出一次相同的动作,相机的高度和距离在不同组间会存在差异。
图5 NTU-60数据集示例
NTU-120是NTU-60数据集的扩展,其共有120类日常动作,114480个样本。其数据格式和采集方式与NTU-120一致,但演员更多,视角更多,场景更复杂,适合评估模型在大规模、多样性场景下的泛化能力,是基于骨架的动作识别任务中最为主要的数据集之一。
Kinetics数据集由DeepMind团队发布,根据种类数和样本数分为Kinetics-400和Kinetics-700等数据集,是行为识别中的重要Benchmark数据集。数据主要来自于Youtube,每个数据在10秒左右,包含人与物之间的互动以及人与人之间的互动。
FineGYM数据集由香港大学发布,其填补了先前动作识别领域缺少细粒度数据集的问题。FineGYM收集了体操领域10种不同的事件类别(男子六种+女子四种)共三百多场专业比赛,其对一个动作之中的子动作进行了标注,并通过结构树的方式组织数据元素。数据的长度通常只有几秒,但其蕴含的信息量很大。ProtoGCN针对的是基于骨架的动作识别领域中相似动作难以识别的问题,与该数据集有较好的契合度。
图6 FineGYM数据集示例
实验软硬件配置
在后续的实验中,我们使用如下的软硬件配置进行实验。
CPU:AMD EPYC 7542 32-Core Processor 756G 128 核
GPU:NVIDIA RTX A6000 48G
内存:94G
Cuda:11.3.1
pytorch:1.11.0
在论文中,作者使用单张RTX 3090进行实验。为了缩短训练时间,我们使用算力更强的RTX A6000进行实验,并保持其他环境不变。
不同数据集结果复现
在本实验中,为了确保代码能够正确运行、能够达到论文中所展示的效果,我们首先尝试对作者提到的4个数据集进行结果复现,以便后续进一步的研究与验证。由于Kinetics数据集的骨架注释文件较大,需要使用额外的组件辅助进行下载和解码,考虑到源代码中并没有给出其对应的使用代码,因此我们使用其余的三个数据集进行初步复现。
在论文中,作者给出了6种训练方式:仅使用节点、仅使用骨架、使用K个骨架,以及2、4、6流集成训练方式。官方github仓库给出了前三种训练方式的调用接口,以及每种方式与动作相结合的训练方式。虽然6流集成训练方式在论文中的表现最优,但是缺少相应的训练代码与具体实现方法,因此我们采用仅节点的训练方式,通过调用对应的代码进行训练。 在不同数据集的结果复现种,训练所使用的超参数均为默认值,与论文中所使用的参数一致,因此可以通过将复现结果与论文结果进行对比,确认训练过程有效。训练结果如下:
|
Top-1 准确率 |
NTU 60 X-Sub |
NTU-120 X-Sub |
FineGYM |
|
论文结果 |
91.54 |
85.52 |
93.28 |
|
复现结果 |
90.45 |
84.43 |
93.51 |
表1 不同数据集复现结果
从Top-1准确率的对比中可以看出,我们的复现结果与论文中给出的结果的差别较小,甚至在FineGYM数据集上的表现优于论文中的数据。因此我们判断官方给出的github仓库代码有效,并且可以作为后续复现和改进实验的基础代码。
不同原型数结果复现
在本论文中,作者使用原型学习强化模型的近似动作的分辨能力,通过引入可维护的原型库,将复杂动作表征解构为若干典型子结构的组合,从而更好地抽象和强调动作中的关键部位。
在原型学习中,原型数是其重要超参数之一。原型数是指用于表示数据集中所有类别的原型的总数量。它的选择直接影响模型的复杂度、分类性能和计算效率。其中,原型学习又可分为每类仅使用1个原型的简单情况,以及每类使用多个原型的复杂情况。过少的原型数会提升计算效率,但可能会导致欠拟合,无法捕捉类内多样性;而过多的原型数可能会导致过拟合,且会增加计算成本。因此,需要选择合适的原型数进行训练,有助于缩短训练时间并尽可能提高模型的准确率和泛化性。
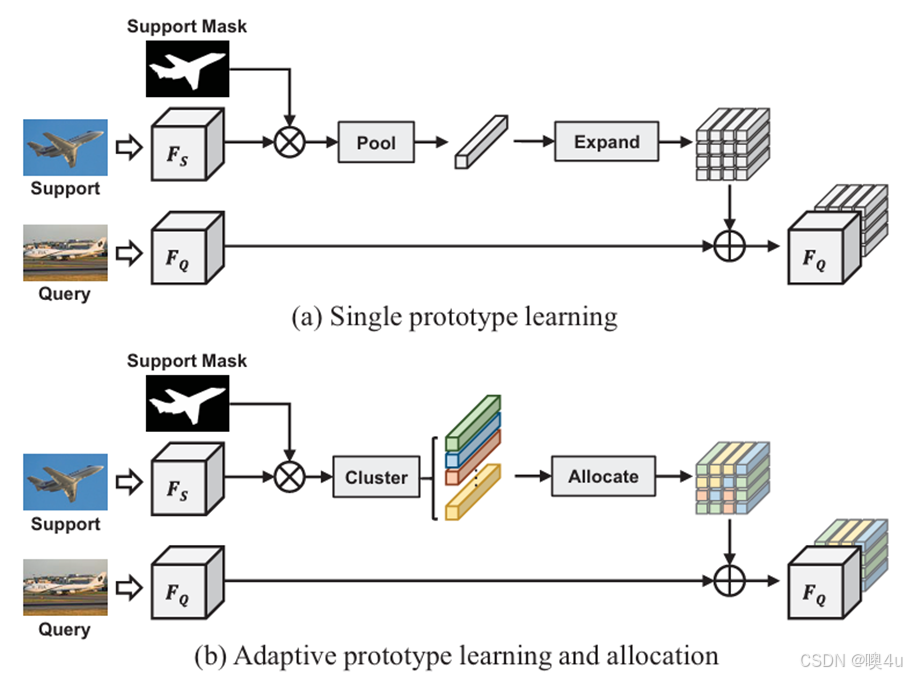
图7 单原型与适应性多原型学习原理
在论文中,作者给出了针对原型数的对比实验结果,我们选择同样的超参数,在训练时间较短的FineGYM上进行复现。实验结果如下:
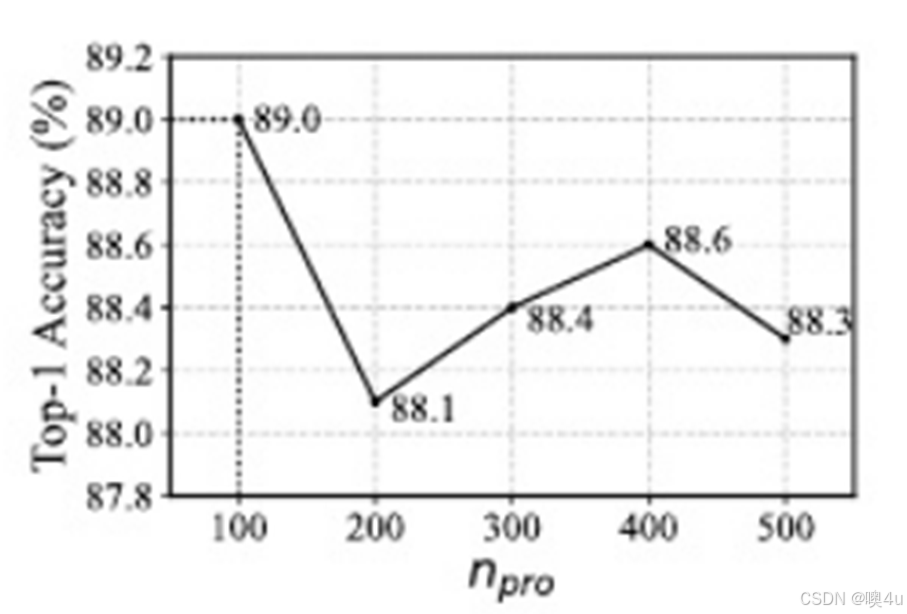
图8 原论文不同原型数实验结果
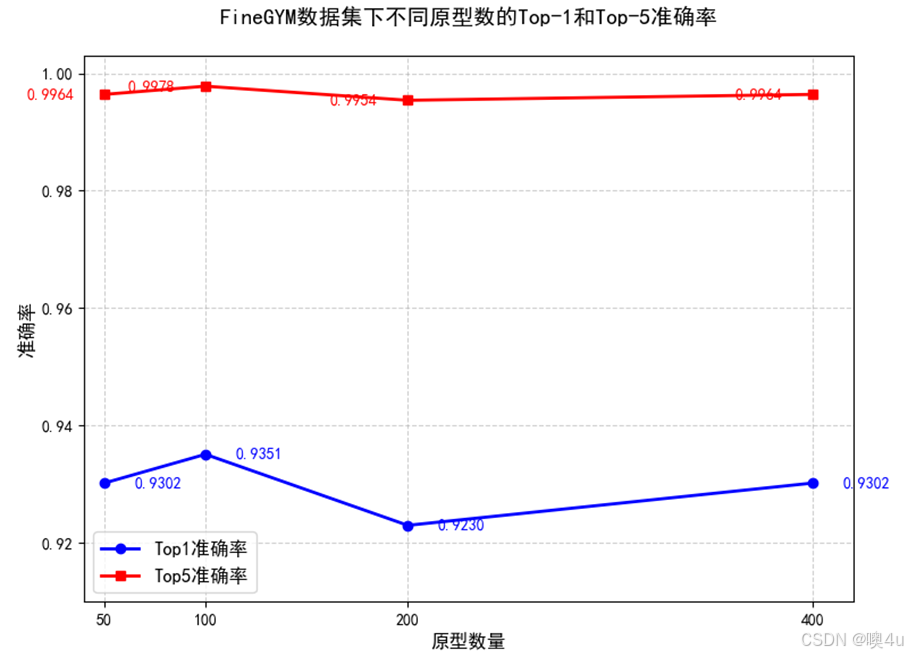
图9 FineGYM数据集下不同原型数的复现结果
从上述结果中可以看出,在原型数为100时,模型准确率最高,Top1准确率达到93.51%(原文为93.28%),与原文中的结论一致。因此,可以判断成功复现了对原型数的对比试验,并在后续的改进实验中,使用原型数100作为基线,以最优化模型效果。
不同损失函数比重结果复现
在原论文中,为了强化模型的相似动作分辨能力,作者还引入了对比学习及其相应的损失函数。对比学习的核心思想是最小化正样本对的相似度,最大化负样本对的相似度。
class BaseWeightedLoss(nn.Module, metaclass=ABCMeta):
def __init__(self, loss_weight=1.0):
super().__init__()
self.loss_weight = loss_weight
@abstractmethod
def _forward(self, *args, **kwargs):
pass
def forward(self, *args, **kwargs):
ret = self._forward(*args, **kwargs)
if isinstance(ret, dict):
for k in ret:
if 'loss' in k:
ret[k] *= self.loss_weight
else:
ret *= self.loss_weight
return ret
在通常的训练中,常采用交叉熵损失函数。交叉熵损失用于衡量模型预测概率分布与真实标签分布之间的差异,其核心思想是事件发生的概率越低,包含的信息越多。使用熵(概率分布p的期望)度量信息的多少,并通过最小化熵使得模型和实际情况尽可能一致。交叉熵损失函数的计算公式为:
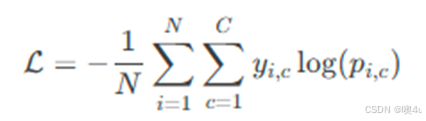
lsm = F.log_softmax(cls_score, 1)
if self.class_weight is not None:
self.class_weight = self.class_weight.to(cls_score.device)
lsm = lsm * self.class_weight.unsqueeze(0)
# -(label * lsm).sum(1) 对应 -∑ y_i * log(p_i)
loss_cls = -(label * lsm).sum(1)
# 平均处理
if self.class_weight is not None:
# 加权平均: ∑(w*y*log(p)) / ∑(w*y)
loss_cls = loss_cls.sum() / torch.sum(self.class_weight.unsqueeze(0) * label)
else:
# 普通平均: mean(-∑ y_i * log(p_i))
loss_cls = loss_cls.mean()
交叉熵损失的优点在于梯度计算高效,适合梯度下降优化,并且对错误预测的惩罚力度大;但它假设类别互斥,难以直接处理类内多样性,难以做到细粒度的分类。
为了提高相似动作的区分,即提高细粒度的分类,作者引入对比学习的损失函数,并对其进行一定的修改,使其符合原型学习的输出与更新,做到类别特定的对比学习。对比学习的核心思想是最小化正样本对的相似度,最大化负样本对的相似度,在计算公式中分别将两者放在分子与分母,从而让同类样本能在特征空间中更紧密、异类样本更远离,从而做到细粒度的区分。对比学习损失函数的计算公式为:
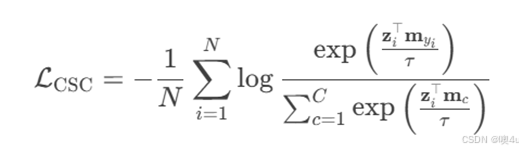
为了让训练过程兼具两种损失函数的优点,作者使用如下的公式替换原本的损失函数计算方法:
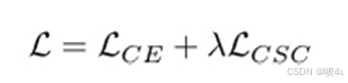
其中,LCE为交叉熵损失,LCSC为对比损失。作者通过控制比例超参λ,决定模型对两种更新方式的倾向程度。
为了确定λ的最优取值,作者对其进行了对比试验。我们选择同样的超参数,在FineGYM数据集上进行结果复现,实验结果如下:
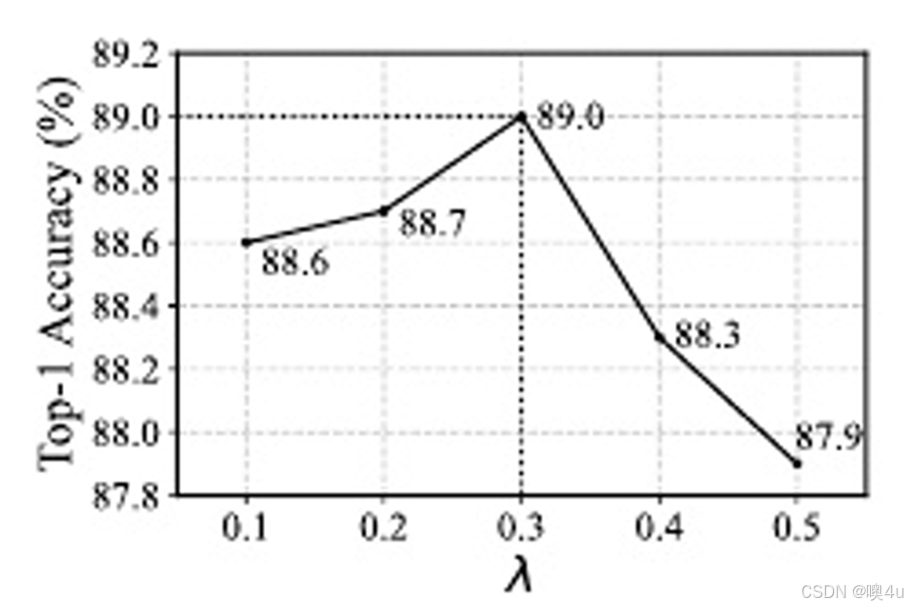
图10 原论文不同损失函数权重比实验结果
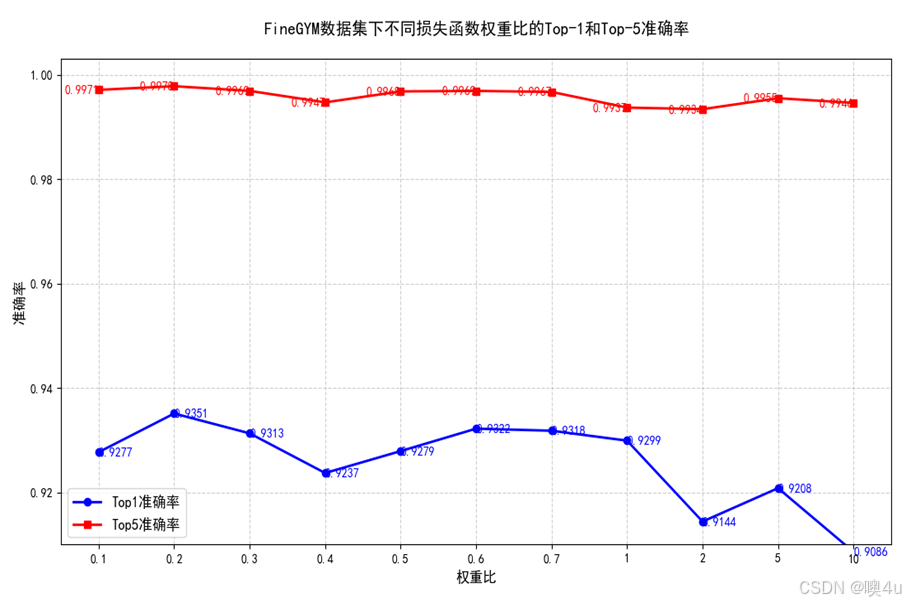
图11 FineGYM数据集下不同损失函数权重比的复现结果
从上述结果中可以观察到,权重比λ在0.2时,模型取得最高准确率,这与FineGYM数据集的结果(λ=0.3)有区别。同时在100原型数下,权重比在0.2时,复现得到的结果(93.51%)略高于作者给出的结果(93.28%)。在其余的改进实验中,我们采用λ=0.2作为基线。
# 类别特定对比学习损失函数
def forward(self, feature, lbl, logit):
feature = self.cl_fc(feature) # 特征投影
pred_one = self.onehot(logit.max(1)[1]) # 预测类别one-hot
lbl_one = self.onehot(lbl) # 真实类别one-hot
logit = torch.softmax(logit, 1) # 预测概率
mask = self.get_mask(lbl_one, pred_one, logit) # 获取有效样本掩码
f_mem = self.local_average(feature, mask) # 更新类别原型
score_cl = self.get_score(feature, lbl_one, f_mem) # 计算对比分数
return self.loss(score_cl.permute(1, 0), lbl).mean() # 计算对比损失
## 原型更新
def local_average(self, f, mask):
f_mask = torch.matmul(f, mask) / (mask.sum(0, keepdim=True) + 1e-12)
has_object = (mask.sum(0) > 1e-8).float()
has_object = has_object * self.mom + (1 - has_object) # 动态更新系数
f_mem = avg_f * has_object + (1 - has_object) * f_mask
self.avg_f = f_mem # 更新记忆库
## 对比分数计算
def get_score(self, feature, lbl_one, f_mem):
feature = F.normalize(feature, p=2, dim=1) # 特征L2归一化
f_mem = F.normalize(f_mem, p=2, dim=0) # 原型L2归一化
return torch.matmul(f_mem.t(), feature.t()) / self.tmp # 相似度/温度
原型更新:
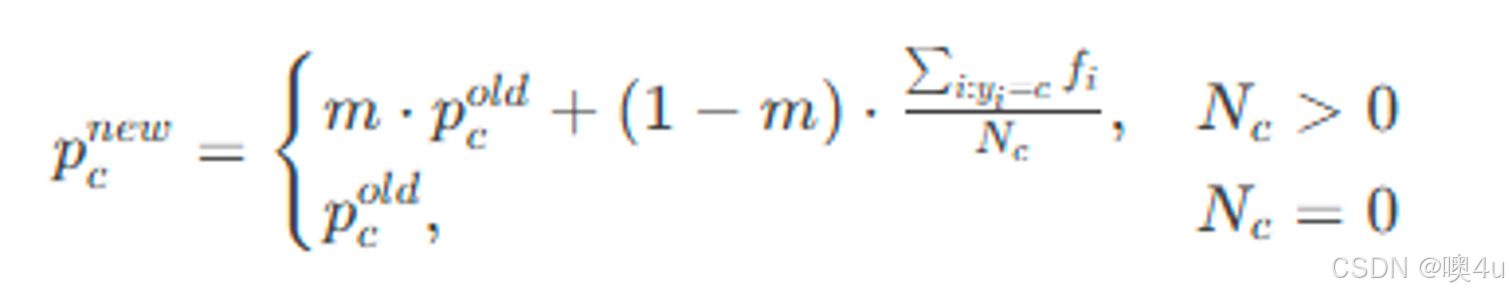
对比分数计算:
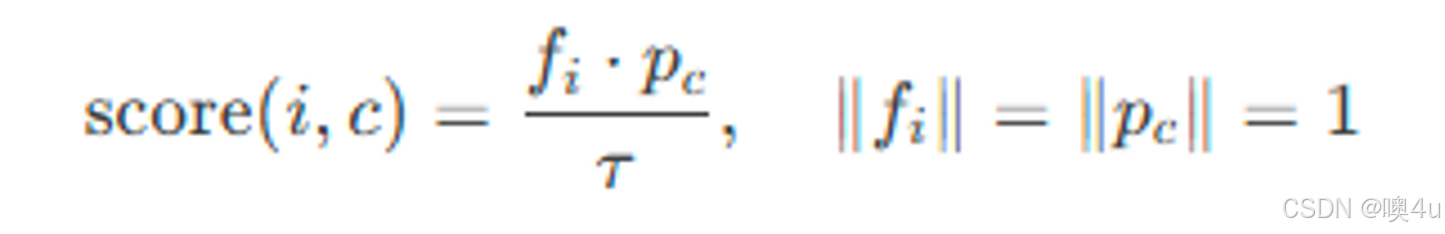
实验结果分析
从上述复现实验中可以发现,原作者给出的代码具有一定的可复现性。其中,在不同数据集上的实验结果与论文中的结果基本一致,并在原型数的对比实验中结果一致。这表明该训练过程并非随机结果,并且可以使用相应的超参数作为最优化模型效果的基线使用。
但在损失函数权重比的实验中,我们观察到实验结果与论文结果不同。经过进一步研究,我们发现作者在不同的训练方式(使用节点、仅使用骨架、使用K个骨架)的训练参数文件中使用了不同的权重比。在仅使用节点的训练中,均使用λ=0.2,与我们的实验结论一致;在仅使用骨架的训练中,均使用λ=0.3。并且在不同训练集中,相同的训练方法使用的λ一致。在原文中,作者仅给出了使用6流集成训练时,λ的最优取值为0.3,但并没有给出其他训练方式的最优λ取值。因此可以判断,不同的训练方式使用的数据不同,适合的学习方法不同,需要重新确认损失函数权重比的最优值;但该权重比应与数据集无关,不需要对不同的数据集进行重复确认。
在实验中,我们还发现在FineGYM上的复现结果比论文中给出的结果高。由于时间原因,没有对该组实验进行重复实验。可能的原因是论文中给出的数据为多次训练后的平均值,而我们的复现实验恰好取得较高的模型表现。另一种原因可能是使用的显卡不同,导致部分环境不同。论文中使用RTX 3090进行试验,我们使用算力更高的A6000进行实验。在之后的学习与实践中,可以针对该现象进行进一步的验证,如使用相同的硬件配置重复实验。
综上,我们使用论文给出的代码,成功对其结果进行复现,验证了论文给出的训练方法的有效性与可复现性。同时,为我们后续对原论文中的部分设计的思考与改进提供了可运行的实验环境。
质疑和思考
在分析和实验的过程中,我们对原论文中的内容产生了一些质疑,具体如下:
- 论文中使用固定的原型数是否能完全适应不同类别规模或细粒度复杂度的数据集(尽管原文中使用了多个数据集进行结果验证)?或许可以引入动态原型选择机制[11],使用注意力机制在推理时选择前K个原型进行组合,减少冗余,提高泛化。
- 原型学习部分PRN仍然是一个线性映射 + softmax attention的浅层结构,若采取更复杂交互机制[12]是否会更有效?原型重构是否只是通过增加非线性表达能力而非确实在语义上形成“典型动作单位”?
- PRN的输出即重构图未参与loss,是否训练稳定?PRN的训练不存在独立损失,因此存在训练初期退化的风险,未引入结构正则项或辅助约束。
- 图的重构是否只是噪声(动态图结构的波动性--有可能源自训练早期的特征不稳定,也有可能源自不同样本之间拓扑差异过大,过拟合局部结构)放大?原文中没有结构正则对其进行控制,重构图有潜在噪声风险[13,14]。
- inter/intra图是否有更加合理的合成方式?骨架图链接的数据与inter-graph和intra-graph(通过两个投影映射得来)的物理意义、尺度不同,却直接线性叠加,是否应该先做归一化[15]、残差门控等?
除了ProtoGCN外,我们还阅读和理论分析了BlockGCN[16]和DeGCN[17]两种改进模型。其中,BlockGCN的核心模型设计紧扣两个关键问题:“骨架拓扑结构遗忘”以及“多关系建模低效”。为解决第一个问题,BlockGCN引入拓扑编码机制:一方面通过“静态拓扑编码”使用关节对在骨骼图中的最短路径距离,稳定保留原始骨架连接关系;另一方面结合“动态拓扑编码”,利用持久同调方法,提取动作序列在不同尺度下的拓扑变化特征,增强模型对动作动态的敏感性。这两个模块分别从结构约束和动作动态两个视角补全GCN在拓扑建模中的缺失。为解决第二个问题,BlockGCN设计了新型卷积模块BlockGC,将特征维度划分为多个子块,每个子块采用独立的稀疏图卷积和投影权重,通过块对角矩阵结构显著减少冗余参数,提高效率同时保持表达力。最终模型由拓扑编码、BlockGC、以及多尺度时序卷积模块交替堆叠构成,融合静态结构与动态拓扑、低耗多关系建模,在多个动作识别数据集上超越现有SOTA,且参数量和计算开销更低。
DeGCN则核心针对“建模刚性”、“冗余连接”、“时序建模不足”的问题:采用关节、骨骼、速度模态作为输入,在各自特征提取的基础上加入关节骨骼融合流形成“三输入-四流”结构。在每个特征提取流中,initial block将原始输入变换为特征空间;basic block中SM模块做空间建模,即对“哪个关节与哪个关节有关系”建模、TM模块做时间建模,即关注“某一关节在不同时刻的动态演化”;具体来说,空间维度SM采用DeSGC,自适应挑选关键邻居,也就是最相似的关节--反映了两个关节在语义特征空间中的相似性,不仅限于结构连接-原始骨架图的邻接矩阵元素,还包括动态和上下文的共同性-协同出现;时间维度TM引入DeTGC,完成刚刚介绍过的支持连续域感知,也就是使用可学习的连续采样点+插值,以更精准捕捉连续动作变化,自动采到有效关键帧。同时结构模块TSM(SM+TM)保证模型轻量化,对S个时间尺度独立建模,在图中就是SM和TM模块的初始的四种颜色的小方格,每个子段单独进入一个DeSGC空间建模分支,对不同时间尺度切分出的子通道并行处理、后续再融合,由于DeSGC本身是多头机制+大量点卷积,所以参数不是线性增加的,因此重复使用S个轻量DeSGC分支比原始的DeSGC更轻量,论文中给出的数据是参数是近似减小到原来的1/s。
BlockGCN、ProtoGCN和DeGCN尽管在实现方式上各有差异,但它们在整体设计理念上体现出诸多共性。三者都以图卷积网络为基础,致力于解决传统静态骨架图无法充分表达复杂动作结构的问题,尤其是在面对细粒度或相似动作识别场景下的挑战。它们共同意识到,仅依赖固定骨架连接难以覆盖人体关节间的高阶、非直接关联,因此都在空间建模层面引入了更具表达能力的拓扑结构:BlockGCN通过静态图的相对位置编码结合persistent homology构建动态拓扑,ProtoGCN借助intra/inter图与prototype重构机制增强对动作细节的表达,而DeGCN则引入可变形图卷积模块,动态选择每个样本中最相关的邻接点用于卷积操作。此外,三者都强化了时间建模能力:BlockGCN和DeGCN明确使用多尺度时域卷积或可变形时间采样来建模动作的时序动态,ProtoGCN虽未将时间维度显式分离,但其intra/inter关系图和prototype表征同样体现了时间上的差异性。此外,它们均以“动作的本质结构依赖于关键关节之间的细微差别”为出发点,强调了样本自适应建图的必要性:BlockGCN从每个样本中提取拓扑条码,ProtoGCN对每个样本构建个性化的prototype表达,而DeGCN在每一帧内动态选择top-k关键关节进行信息聚合。这些机制体现了它们对“相似动作应依赖不同关节交互细节区分”的一致认知,进而实现对结构变化强烈、细节差异显著的动作类别的更好区分。综上,三者虽在模型架构和技术路径上各有创新,但在整体思路上都从“骨架图的不完备性”出发,试图在空间拓扑、时间动态与动作细节三方面实现更精准、更泛化的动作建模。
结论
在本次实践中,我们小组通过学习BlockGCN和DeGCN的网络结构与创新方法,围绕ProtoGCN模型,在细粒度骨架动作识别中的结构建模与优化展开研究,通过论文学习、理论分析、代码复现和实验验证,系统性地探讨了其在相似动作识别任务中的性能表现与改进f方法。实验复现结果表明,ProtoGCN通过MTE动态拓扑增强模块、PRN原型重构模块和CSCL类别特定对比学习模块的协同设计,有效解决了传统GCN在局部细节建模、结构适应性和监督信号单一等方面的局限性。在NTU-60、NTU-120和FineGYM等数据集上的复现实验验证了其优越性,尤其在细粒度动作分类任务中表现突出。
然而,本文也发现了部分难以解释与解决的问题,例如原型数的固定选择可能限制模型对不同数据集的适应性,PRN模块的浅层结构可能影响原型语义的表达能力,以及动态图结构的噪声风险等。针对这些问题,本文提出了动态原型选择机制、结构正则化等改进思路,为后续研究提供了方向。此外,通过与BlockGCN和DeGCN的对比分析,本文总结了当前GCN在骨架动作识别中的演进趋势,即从静态建模向动态自适应、多模态融合和判别性监督的方向发展。
未来研究可进一步探索以下方向:
- 动态原型机制:引入注意力机制或聚类算法,动态调整原型数量与组合方式,提升模型对不同数据分布的适应性。
- 结构优化:在PRN模块中增加非线性交互或辅助损失函数,增强原型的语义表达能力与训练稳定性。
- 噪声抑制:通过图正则化或门控机制优化动态图的生成过程,减少噪声干扰。
- 模型迁移:或许可以用于各种图结构的分类,如“金融欺诈检测”等等课题。
综上所述,ProtoGCN为细粒度骨架动作识别提供了创新性的解决方案,其“动态结构-原型表示-对比监督”的三维协同机制具有重要的理论价值与应用潜力。本研究不仅验证了其有效性,也为后续优化与拓展奠定了坚实基础。
参考文献
[6]Kay, W., et al. (2017). The Kinetics Human Action Video Dataset. arXiv:1705.06950.
[8]Liu, Hongda, et al. Revealing key details to see differences: A novel prototypical perspective for skeleton-based action recognition. CVPR 2025.

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 55
55 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)