【完整源码+数据集+部署教程】矿物分类图像分割系统源码&数据集分享 [yolov8-seg-SPDConv等50+全套改进创新点发刊_一键训练教程_Web前端展示]
【完整源码+数据集+部署教程】矿物分类图像分割系统源码&数据集分享[yolov8-seg-SPDConv等50+全套改进创新点发刊_一键训练教程_Web前端展示]
背景意义
随着全球矿产资源的不断开发与利用,矿物分类与识别在地质学、矿业、环境监测等领域的重要性日益凸显。传统的矿物分类方法多依赖于人工观察与经验判断,然而这种方法不仅耗时耗力,而且容易受到主观因素的影响,导致分类结果的不准确性。近年来,随着计算机视觉技术的快速发展,基于深度学习的图像处理方法逐渐成为矿物分类领域的新兴研究方向。特别是YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。
YOLOv8作为YOLO系列的最新版本,具备了更强的特征提取能力和更高的分类精度,能够在复杂背景下快速准确地识别多种物体。通过对YOLOv8模型的改进,结合实例分割技术,可以实现对矿物图像的精细化处理。这种方法不仅能够识别矿物的种类,还能对矿物的形状和边界进行精确分割,为后续的矿物分析提供了丰富的信息。
本研究所使用的数据集“MineralVision”包含1200幅图像,涵盖了47种不同类别的矿物,如辉石、石英、长石等,涵盖了从常见矿物到一些特殊矿物的广泛范围。这些数据的多样性为模型的训练提供了良好的基础,能够有效提高模型的泛化能力和分类精度。此外,数据集中还包含了一些未知类别的矿物,这为模型的自适应学习提供了挑战与机遇,进一步推动了智能矿物分类系统的发展。
基于改进YOLOv8的矿物分类图像分割系统,不仅能够提升矿物识别的准确性,还能在实际应用中实现自动化与智能化,减少人工干预的需求。这对于矿业公司在资源勘探、开采及环境保护等方面具有重要的现实意义。通过实现高效的矿物分类与分割,可以帮助地质学家和矿业工程师更好地理解矿物的分布特征,从而优化资源利用和环境管理。
此外,本研究还具有重要的学术价值。通过对YOLOv8模型的改进与应用,可以为计算机视觉领域的研究提供新的思路和方法,推动深度学习技术在矿物分类中的应用。研究成果不仅能够丰富矿物学和地质学的理论体系,还能够为相关领域的研究者提供有价值的参考,促进跨学科的合作与交流。
综上所述,基于改进YOLOv8的矿物分类图像分割系统的研究,不仅在技术上具有创新性和实用性,同时也为矿业及相关领域的可持续发展提供了新的解决方案,具有重要的研究背景与深远的社会意义。
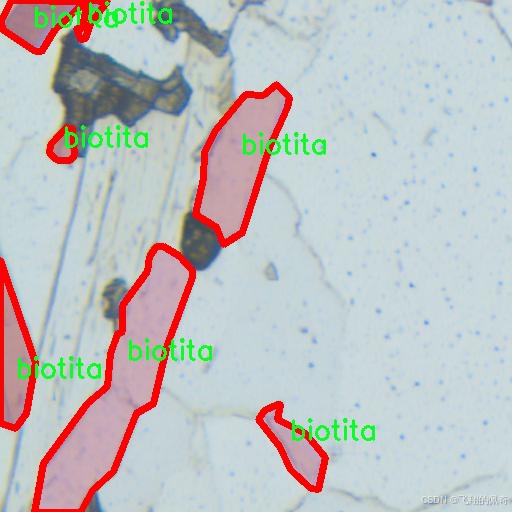
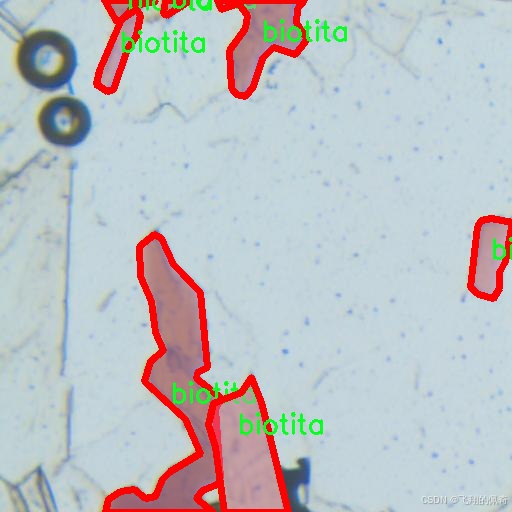
图片效果
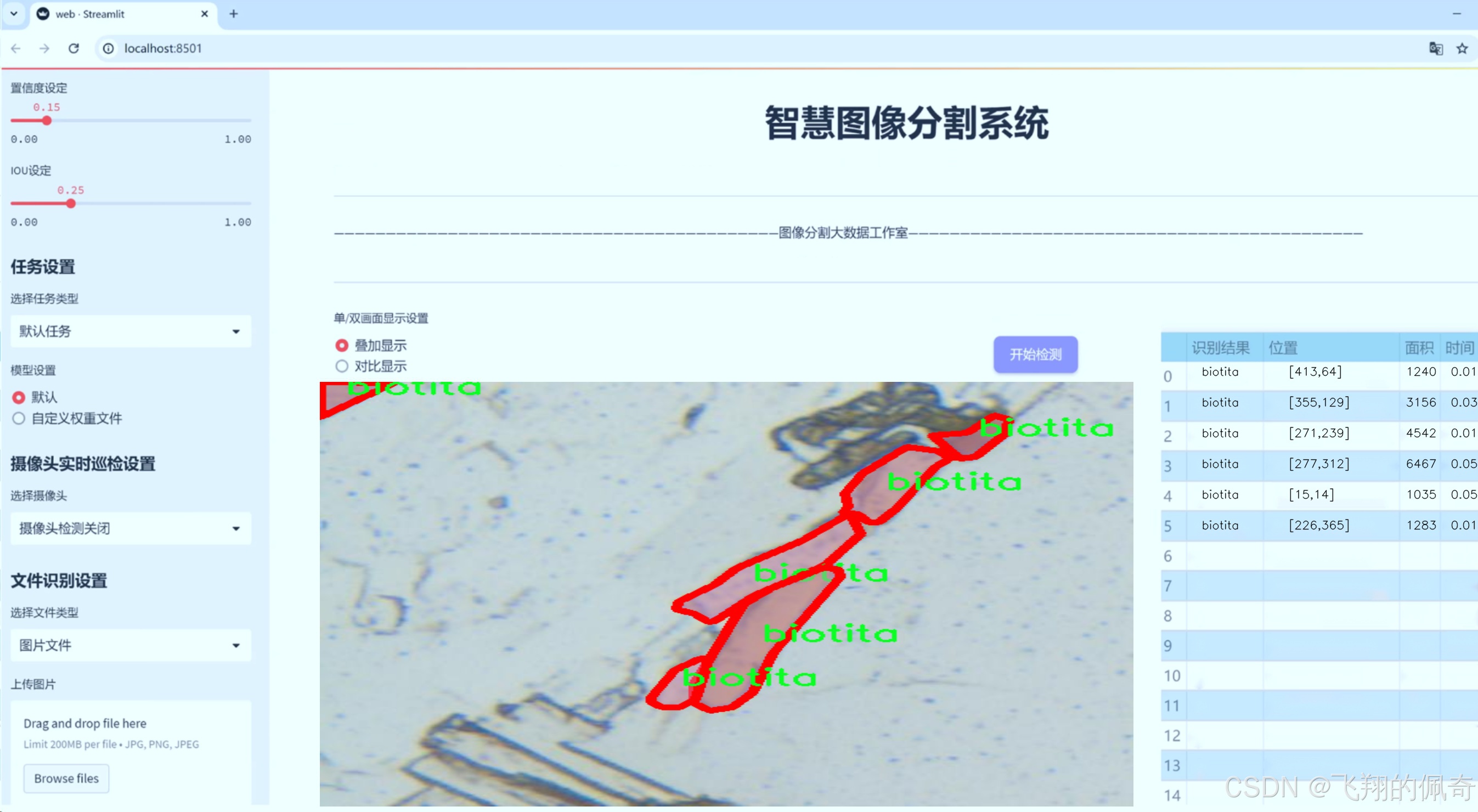
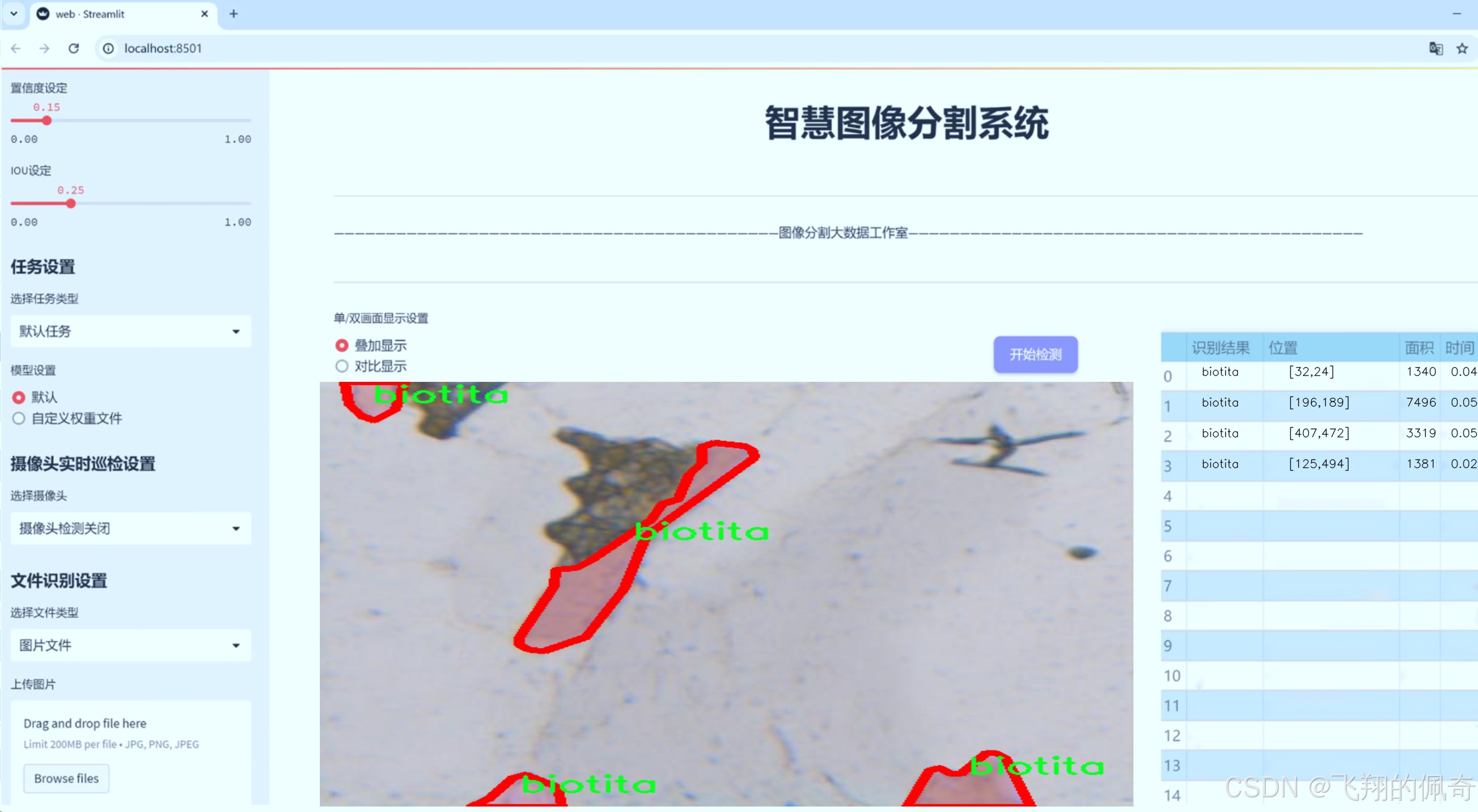
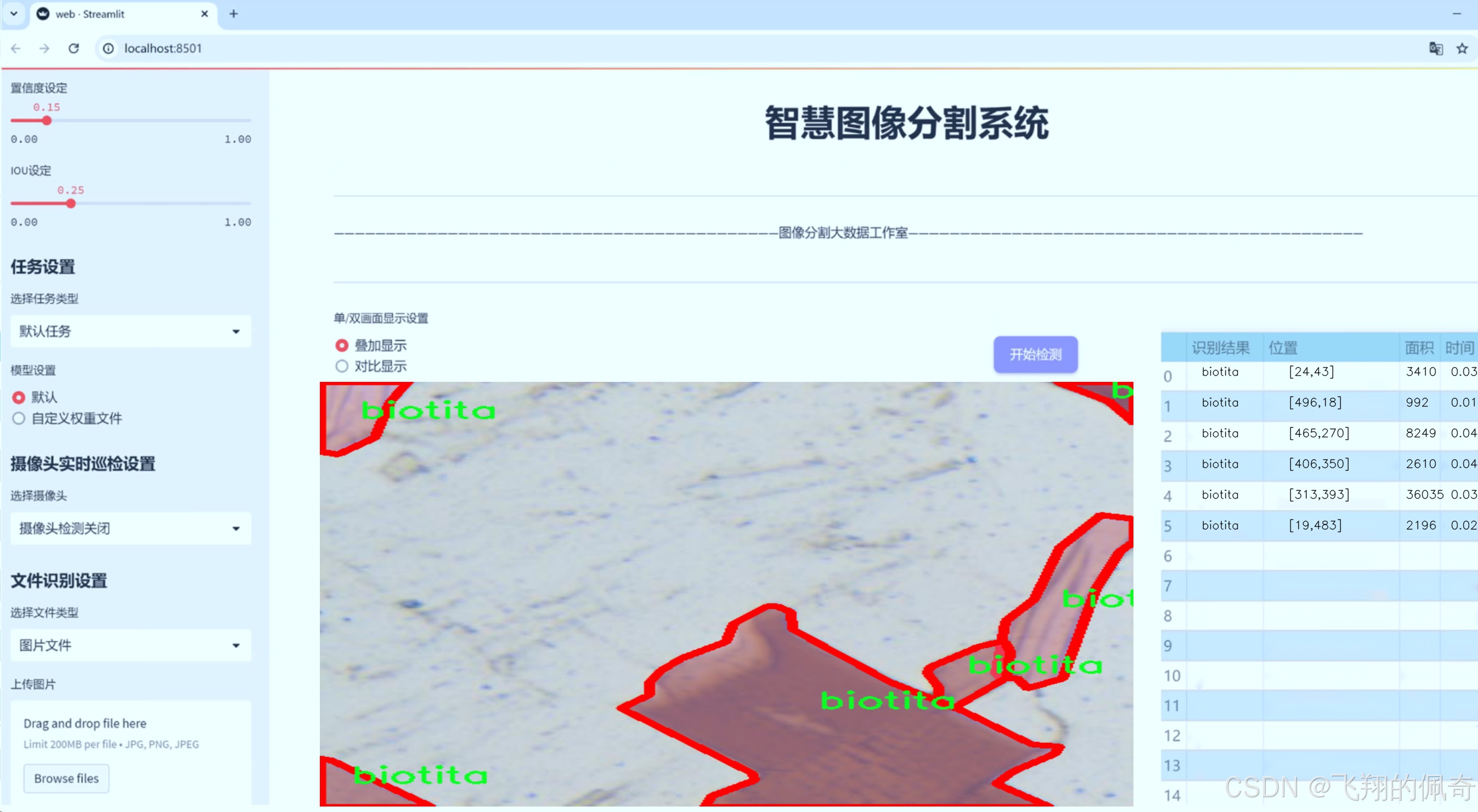
数据集信息
在本研究中,我们采用了名为“MineralVision”的数据集,以训练和改进YOLOv8-seg的矿物分类图像分割系统。该数据集专注于生物矿物的识别与分割,尤其是针对“biotita”这一特定类别的图像数据。MineralVision数据集的设计旨在为矿物学研究提供高质量的图像数据支持,助力深度学习模型在矿物分类和分割任务中的表现。
MineralVision数据集的核心特点在于其独特的单类别设计。该数据集仅包含一个类别,即“biotita”,这使得其在训练过程中能够专注于这一特定矿物的特征提取与分割。生物云母(biotite)是一种常见的黑色或深褐色的矿物,广泛分布于多种岩石中,尤其是在花岗岩和片麻岩中。其独特的层状结构和光泽特性使得生物云母在矿物学研究中具有重要的地位。因此,MineralVision数据集的选择为研究者提供了一个专注于生物云母特征的理想平台。
在数据集的构建过程中,MineralVision团队致力于收集多样化的生物云母图像,确保其在不同光照、角度和背景下的表现。通过精心的图像采集和处理,数据集涵盖了生物云母的各种形态特征,包括其层状结构、颜色变化以及在不同矿物组合中的表现。这种多样性不仅增强了模型的泛化能力,也提高了其在实际应用中的有效性。
此外,MineralVision数据集还经过严格的标注过程,确保每张图像中的生物云母区域被准确地分割和标识。这一过程采用了专业的图像标注工具,结合矿物学专家的知识,确保了数据集的高质量和高准确性。这样的标注策略使得YOLOv8-seg模型在训练时能够获得清晰的目标区域信息,从而提升了其分割精度和分类能力。
在数据集的使用过程中,研究者可以通过对MineralVision数据集的深入分析,探索生物云母在不同环境下的特征表现,进而为矿物分类与分割算法的改进提供数据支持。通过结合YOLOv8-seg的强大特性,研究者能够实现对生物云母的高效检测与分割,为矿物学研究和相关应用提供新的思路和方法。
总之,MineralVision数据集不仅为矿物分类图像分割系统的训练提供了坚实的基础,也为后续的研究和应用奠定了良好的数据支持。随着深度学习技术的不断发展,利用这一数据集进行的研究将为矿物学领域带来新的突破和进展。通过不断优化和改进模型,研究者有望在生物云母的识别与分割方面取得更为显著的成果,为矿物学的研究和应用开辟新的方向。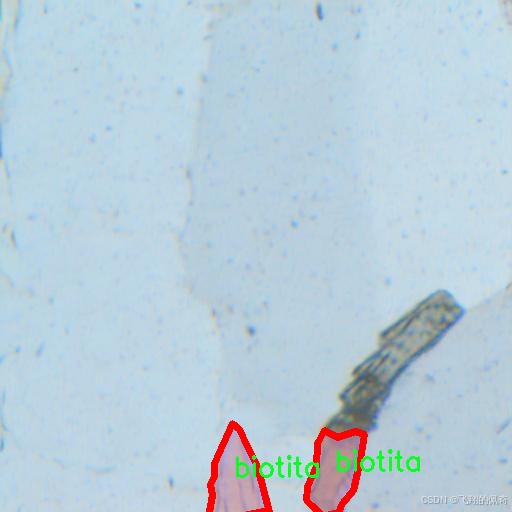


核心代码
以下是经过简化和注释的核心代码部分,保留了主要功能和逻辑:
# 导入所需的库
import requests
from ultralytics.data.utils import HUBDatasetStats
from ultralytics.hub.auth import Auth
from ultralytics.hub.utils import HUB_API_ROOT, PREFIX
from ultralytics.utils import LOGGER, SETTINGS
def login(api_key=''):
"""
使用提供的API密钥登录Ultralytics HUB API。
参数:
api_key (str, optional): API密钥或组合API密钥和模型ID。
示例:
hub.login('API_KEY')
"""
Auth(api_key, verbose=True) # 进行身份验证
def logout():
"""
从Ultralytics HUB注销,移除设置文件中的API密钥。
再次登录请使用 'yolo hub login'。
示例:
hub.logout()
"""
SETTINGS['api_key'] = '' # 清空API密钥
SETTINGS.save() # 保存设置
LOGGER.info(f"{PREFIX}logged out ✅. To log in again, use 'yolo hub login'.") # 日志记录
def reset_model(model_id=''):
"""将训练过的模型重置为未训练状态。"""
# 发送POST请求重置模型
r = requests.post(f'{HUB_API_ROOT}/model-reset', json={'apiKey': Auth().api_key, 'modelId': model_id})
if r.status_code == 200:
LOGGER.info(f'{PREFIX}Model reset successfully') # 日志记录成功信息
else:
LOGGER.warning(f'{PREFIX}Model reset failure {r.status_code} {r.reason}') # 日志记录失败信息
def export_fmts_hub():
"""返回HUB支持的导出格式列表。"""
from ultralytics.engine.exporter import export_formats
return list(export_formats()['Argument'][1:]) + ['ultralytics_tflite', 'ultralytics_coreml'] # 返回支持的格式
def export_model(model_id='', format='torchscript'):
"""将模型导出为指定格式。"""
assert format in export_fmts_hub(), f"Unsupported export format '{format}', valid formats are {export_fmts_hub()}"
# 发送POST请求导出模型
r = requests.post(f'{HUB_API_ROOT}/v1/models/{model_id}/export',
json={'format': format},
headers={'x-api-key': Auth().api_key})
assert r.status_code == 200, f'{PREFIX}{format} export failure {r.status_code} {r.reason}' # 检查导出是否成功
LOGGER.info(f'{PREFIX}{format} export started ✅') # 日志记录导出开始信息
def check_dataset(path='', task='detect'):
"""
在上传之前检查HUB数据集Zip文件的错误。
参数:
path (str, optional): 数据集Zip文件路径,默认是''。
task (str, optional): 数据集任务类型,默认为'detect'。
示例:
check_dataset('path/to/coco8.zip', task='detect') # 检查检测数据集
"""
HUBDatasetStats(path=path, task=task).get_json() # 获取数据集统计信息
LOGGER.info(f'Checks completed correctly ✅. Upload this dataset to {HUB_WEB_ROOT}/datasets/.') # 日志记录检查完成信息
代码说明:
- 登录与注销功能:
login和logout函数用于用户身份验证,分别处理登录和注销操作。 - 模型重置:
reset_model函数用于将已训练的模型重置为未训练状态,确保可以重新训练。 - 导出格式:
export_fmts_hub函数返回支持的模型导出格式,方便用户选择。 - 模型导出:
export_model函数根据指定格式导出模型,并进行状态检查。 - 数据集检查:
check_dataset函数在上传数据集之前检查其有效性,确保数据集符合要求。```
这个文件是Ultralytics YOLO项目的一部分,主要负责与Ultralytics HUB API进行交互。文件中包含了一些函数,用于用户登录、登出、模型重置、模型导出、数据集检查等功能。
首先,login函数允许用户通过提供API密钥来登录Ultralytics HUB。用户可以通过调用这个函数并传入API密钥来完成登录。函数内部会创建一个Auth对象,并显示登录信息。
接下来,logout函数用于登出操作。它会清空设置文件中的API密钥,并记录登出信息。用户在登出后,可以通过yolo hub login命令重新登录。
reset_model函数用于将训练过的模型重置为未训练状态。它通过向HUB API发送POST请求来实现这一功能,并根据返回的状态码记录重置结果。
export_fmts_hub函数返回HUB支持的导出格式列表。这些格式可以用于将模型导出为不同的文件类型,以便在不同的平台上使用。
export_model函数则是将指定的模型导出为用户指定的格式。用户需要确保所选格式是支持的,函数会向HUB API发送请求以开始导出过程,并记录导出状态。
get_export函数用于获取已导出的模型的下载链接。用户同样需要指定导出格式,函数会向HUB API请求相应的导出信息,并返回包含下载链接的字典。
最后,check_dataset函数用于在上传数据集到HUB之前进行错误检查。它会检查指定路径下的ZIP文件,确保其中包含正确的数据格式和文件结构。用户可以通过传入数据集的路径和任务类型来使用这个函数,检查完成后会记录成功信息,提示用户可以上传数据集。
整体来看,这个文件提供了一系列与Ultralytics HUB交互的功能,旨在简化用户的操作流程,确保模型和数据集的管理更加高效。
```python
from typing import List
import torch
from torch import nn
from .decoders import MaskDecoder
from .encoders import ImageEncoderViT, PromptEncoder
class Sam(nn.Module):
"""
Sam (Segment Anything Model) 是一个用于对象分割任务的模型。它使用图像编码器生成图像嵌入,并使用提示编码器对各种类型的输入提示进行编码。这些嵌入随后被掩码解码器用于预测对象掩码。
属性:
mask_threshold (float): 掩码预测的阈值。
image_format (str): 输入图像的格式,默认为 'RGB'。
image_encoder (ImageEncoderViT): 用于将图像编码为嵌入的主干网络。
prompt_encoder (PromptEncoder): 编码各种类型的输入提示。
mask_decoder (MaskDecoder): 根据图像和提示嵌入预测对象掩码。
pixel_mean (List[float]): 用于图像归一化的均值像素值。
pixel_std (List[float]): 用于图像归一化的标准差值。
"""
mask_threshold: float = 0.0 # 掩码预测的阈值,初始化为0.0
image_format: str = 'RGB' # 输入图像的格式,默认为RGB
def __init__(
self,
image_encoder: ImageEncoderViT, # 图像编码器,用于将图像转换为嵌入
prompt_encoder: PromptEncoder, # 提示编码器,用于编码输入提示
mask_decoder: MaskDecoder, # 掩码解码器,用于从嵌入中预测掩码
pixel_mean: List[float] = (123.675, 116.28, 103.53), # 像素归一化的均值
pixel_std: List[float] = (58.395, 57.12, 57.375) # 像素归一化的标准差
) -> None:
"""
初始化 Sam 类,以便从图像和输入提示中预测对象掩码。
参数:
image_encoder (ImageEncoderViT): 用于将图像编码为图像嵌入的主干网络。
prompt_encoder (PromptEncoder): 编码各种类型的输入提示。
mask_decoder (MaskDecoder): 从图像嵌入和编码的提示中预测掩码。
pixel_mean (List[float], optional): 输入图像中像素的均值,用于归一化。默认为 (123.675, 116.28, 103.53)。
pixel_std (List[float], optional): 输入图像中像素的标准差,用于归一化。默认为 (58.395, 57.12, 57.375)。
"""
super().__init__() # 调用父类 nn.Module 的初始化方法
self.image_encoder = image_encoder # 设置图像编码器
self.prompt_encoder = prompt_encoder # 设置提示编码器
self.mask_decoder = mask_decoder # 设置掩码解码器
# 注册均值和标准差,用于图像归一化
self.register_buffer('pixel_mean', torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer('pixel_std', torch.Tensor(pixel_std).view(-1, 1, 1), False)
代码核心部分说明:
- 类定义:
Sam类继承自nn.Module,是一个用于对象分割的模型。 - 属性:定义了模型的基本属性,包括掩码阈值、图像格式、编码器和解码器等。
- 初始化方法:在初始化时接收编码器和解码器的实例,并注册用于图像归一化的均值和标准差。```
这个程序文件定义了一个名为Sam的类,属于 Ultralytics YOLO 项目的一部分,主要用于对象分割任务。该类继承自 PyTorch 的nn.Module,并通过不同的编码器和解码器来处理图像和输入提示,以生成对象的掩码。
在类的文档字符串中,首先说明了 Sam 的主要功能,即通过图像编码器生成图像嵌入,并使用提示编码器对各种类型的输入提示进行编码。随后,这些嵌入会被掩码解码器用来预测对象的掩码。
类中定义了一些属性,包括:
mask_threshold:用于掩码预测的阈值。image_format:输入图像的格式,默认为 ‘RGB’。image_encoder:用于将图像编码为嵌入的主干网络,类型为ImageEncoderViT。prompt_encoder:用于编码各种输入提示的编码器,类型为PromptEncoder。mask_decoder:根据图像和提示嵌入预测对象掩码的解码器,类型为MaskDecoder。pixel_mean和pixel_std:用于图像归一化的均值和标准差。
在 __init__ 方法中,类的初始化过程接受三个主要参数:image_encoder、prompt_encoder 和 mask_decoder,这些参数分别用于图像编码、提示编码和掩码预测。此外,还可以传入用于归一化的均值和标准差,默认值已经给出。
在初始化过程中,调用了父类的构造函数,并将传入的编码器和解码器赋值给相应的属性。同时,使用 register_buffer 方法注册了均值和标准差,以便在模型训练和推理时保持一致性。
总的来说,这个类的设计旨在将图像和提示信息结合起来,以实现高效的对象分割功能。
```python
import random
import shutil
import subprocess
import time
import numpy as np
import torch
from ultralytics.cfg import get_cfg, get_save_dir
from ultralytics.utils import LOGGER, callbacks, yaml_save, yaml_print
from ultralytics.utils.plotting import plot_tune_results
class Tuner:
"""
负责YOLO模型的超参数调优的类。
该类通过在给定的迭代次数内变异超参数,并重新训练模型来评估其性能。
"""
def __init__(self, args=None, _callbacks=None):
"""
初始化Tuner类。
参数:
args (dict, optional): 超参数进化的配置。
"""
self.args = get_cfg(overrides=args) # 获取配置
self.space = { # 定义超参数搜索空间及其范围
'lr0': (1e-5, 1e-1), # 初始学习率
'lrf': (0.0001, 0.1), # 最终学习率
'momentum': (0.7, 0.98, 0.3), # 动量
'weight_decay': (0.0, 0.001), # 权重衰减
# 其他超参数...
}
self.tune_dir = get_save_dir(self.args, name='tune') # 获取保存目录
self.tune_csv = self.tune_dir / 'tune_results.csv' # CSV文件路径
self.callbacks = _callbacks or callbacks.get_default_callbacks() # 回调函数
callbacks.add_integration_callbacks(self) # 添加集成回调
LOGGER.info(f"Initialized Tuner instance with 'tune_dir={self.tune_dir}'")
def _mutate(self):
"""
根据超参数空间的范围和缩放因子变异超参数。
返回:
dict: 包含变异后的超参数的字典。
"""
# 从CSV文件中加载现有超参数
if self.tune_csv.exists():
x = np.loadtxt(self.tune_csv, ndmin=2, delimiter=',', skiprows=1)
fitness = x[:, 0] # 获取适应度
n = min(5, len(x)) # 考虑的结果数量
x = x[np.argsort(-fitness)][:n] # 选择适应度最高的n个超参数
# 选择父代并变异
# ...(变异逻辑)
else:
hyp = {k: getattr(self.args, k) for k in self.space.keys()} # 初始化超参数
# 限制超参数在指定范围内
for k, v in self.space.items():
hyp[k] = max(hyp[k], v[0]) # 下限
hyp[k] = min(hyp[k], v[1]) # 上限
hyp[k] = round(hyp[k], 5) # 保留五位小数
return hyp
def __call__(self, model=None, iterations=10, cleanup=True):
"""
执行超参数进化过程。
参数:
model (Model): 预初始化的YOLO模型。
iterations (int): 进化的代数。
cleanup (bool): 是否清理迭代权重以减少存储空间。
"""
for i in range(iterations):
mutated_hyp = self._mutate() # 变异超参数
LOGGER.info(f'Starting iteration {i + 1}/{iterations} with hyperparameters: {mutated_hyp}')
# 训练YOLO模型
# ...(训练逻辑)
# 保存结果到CSV
# ...(保存逻辑)
# 绘制调优结果
plot_tune_results(self.tune_csv)
# 打印调优结果
# ...(打印逻辑)
代码注释说明:
- 类的定义:
Tuner类负责YOLO模型的超参数调优,主要通过变异和评估超参数来寻找最佳配置。 - 初始化方法:
__init__方法设置超参数的搜索空间、保存目录和回调函数,并记录初始化信息。 - 变异方法:
_mutate方法根据现有超参数进行变异,确保变异后的超参数在预设范围内。 - 调用方法:
__call__方法执行超参数的进化过程,包括变异、训练模型、记录结果等。
以上是代码的核心部分和详细注释,帮助理解超参数调优的过程。```
这个程序文件 ultralytics\engine\tuner.py 是用于超参数调优的模块,专门针对 Ultralytics YOLO 模型进行对象检测、实例分割、图像分类、姿态估计和多目标跟踪等任务。超参数调优是一个系统化搜索最佳超参数集合的过程,这对于深度学习模型(如 YOLO)尤其重要,因为超参数的微小变化可能会导致模型性能的显著差异。
文件中定义了一个 Tuner 类,负责 YOLO 模型的超参数调优。该类通过在给定的迭代次数内进化超参数,利用突变的方法来评估模型性能。类的属性包括超参数搜索空间、调优结果保存目录和 CSV 文件路径等。方法 _mutate 用于在指定的搜索空间内突变给定的超参数,而 __call__ 方法则执行超参数进化过程。
在初始化 Tuner 类时,会设置超参数的搜索空间,包括学习率、动量、权重衰减等多个参数的最小值和最大值。调优目录和 CSV 文件路径也会在初始化时确定,并记录相关信息。
_mutate 方法的作用是根据超参数的边界和缩放因子进行突变。它会从已有的调优结果中选择最优的超参数进行突变,并确保突变后的超参数在指定的范围内。该方法还使用随机数生成器来实现高斯突变,确保突变的多样性。
__call__ 方法是执行超参数进化的核心。它会在指定的迭代次数内进行以下步骤:加载现有的超参数或初始化新的超参数,使用 _mutate 方法进行突变,训练 YOLO 模型并记录性能指标,最后将结果和突变后的超参数保存到 CSV 文件中。每次迭代后,程序会检查当前的最佳结果,并在必要时清理不再需要的文件,以节省存储空间。
在每次迭代结束时,程序还会绘制调优结果,并记录和打印当前的最佳超参数和性能指标。这些信息会被保存为 YAML 格式,方便后续使用。
总的来说,这个文件实现了一个完整的超参数调优流程,能够有效地帮助用户找到最佳的超参数组合,从而提升 YOLO 模型的性能。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)