【机器学习-16】-NumPy数组、张量tensor、神经网络计算公式
以下内容的整合解释,涵盖NumPy数组、激活向量、神经网络模型和前向传播的核心概念和公式
【机器学习-16】-NumPy数组、张量tensor、神经网络计算公式
以下内容的整合解释,涵盖NumPy数组、激活向量、神经网络模型和前向传播的核心概念和公式:
1. NumPy数组的维度与创建
• 内容:展示不同维度的NumPy数组及其代码实现。
• 2D数组:python x = np.array([[1, 2, 3], [4, 5, 6]]) # 2x3矩阵(2行3列)
• 1D数组:python x = np.array([0.1, 0.2, -3.0, -4.0, -0.5, -0.6, 7.0, 8.0]) # 可重塑为4x2矩阵
• 关键点:
• 数组形状(如2x3)决定其维度,np.array是创建数组的基础方法。
• 手写图示直观对比了矩阵结构和代码的对应关系。
2. 激活向量的生成
• 内容:演示神经网络中激活向量的计算过程。
• 代码示例:python x = np.array([[200.0, 17.0]]) # 输入向量 layer_1 = Dense(units=3, activation='sigmoid') # 3个神经元的密集层 a1 = layer_1(x) # 输出激活向量:[0.2, 0.7, 0.3]
• 输出:1x3矩阵,通过sigmoid函数将值压缩到0-1之间。
• 关键点:
• 激活函数(如sigmoid)引入非线性,输出向量表示神经元的激活状态。
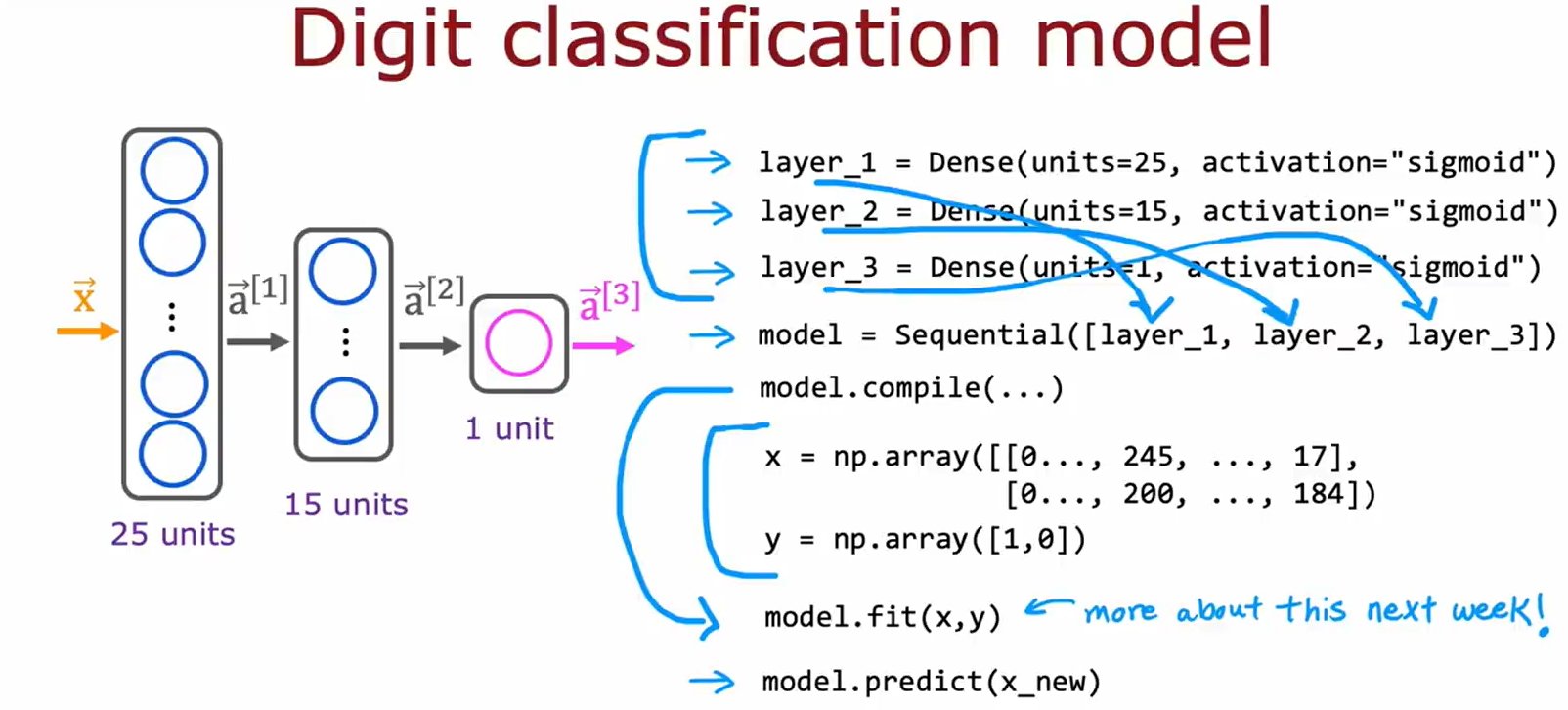
3. 数字分类神经网络
• 内容:展示一个Sequential模型的结构和训练流程。
• 模型结构:python model = Sequential([ Dense(units=25, activation='sigmoid'), # 输入层→隐藏层1(25单元) Dense(units=15, activation='sigmoid'), # 隐藏层2(15单元) Dense(units=1, activation='sigmoid') # 输出层(二分类) ])
• 训练与预测:python model.fit(x, y) # 训练数据(x为特征,y为标签) model.predict(x_new) # 对新数据预测
• 关键点:
• 逐层传递数据,每层通过激活函数转换特征。
• 适用于图像分类等任务(如手写数字识别)。
4. 咖啡烘焙模型的前向传播
• 内容:详细拆解单层神经网络的前向计算步骤。
• 输入与参数:python x = np.array([200, 17]) # 输入特征(如温度、时间) w1 = np.array([1, 2]), w2 = np.array([-3, 4]), w3 = np.array([5, -6]) # 权重 b1, b2, b3 = -1, 1, 2 # 偏置
• 计算过程:
1. 计算加权和:z1_1 = np.dot(w1, x) + b1
2. 激活输出:a1_1 = sigmoid(z1_1)
3. 合并激活值:a1 = np.array([a1_1, a1_2, a1_3])
• 关键点:
◦ 展示如何从输入到输出逐步计算,体现神经网络的“前向”传递。
◦ 适用于回归或分类问题(如咖啡烘焙质量预测)。
总结
四张图片共同覆盖了机器学习的核心流程:
- 数据准备(NumPy数组操作)→
- 单神经元计算(激活向量)→
- 完整模型构建(Sequential网络)→
- 底层数学实现(前向传播)。
如需进一步探讨某一部分,可提供具体问题!



根据图片的核心内容,以下是关于NumPy实现神经网络前向传播的详细解析,包括代码功能、数学原理和实现步骤:
1. 核心概念:前向传播的数学原理
• 输入与参数:
• 输入向量 a_in(或 x)通过权重矩阵 W 和偏置 b 进行线性变换:
z=W⋅a_in+bz = W \cdot a\_in + bz=W⋅a_in+b
• 激活函数 g(z)(如 sigmoid、ReLU)引入非线性,输出激活值 a_out。
• 多层级联:
每一层的输出作为下一层的输入,形成链式计算(如 x → a1 → a2 → ... → f_x)。
2. 代码解析与实现
(1) 单层计算:dense 函数
def dense(a_in, W, b):
units = W.shape[1] # 获取当前层的神经元数量(权重矩阵列数)
a_out = np.zeros(units) # 初始化输出向量
for j in range(units):
w = W[:, j] # 提取第j个神经元的权重向量
z = np.dot(w, a_in) + b[j] # 计算加权和 + 偏置
a_out[j] = g(z) # 应用激活函数
return a_out
• 关键点:
• 权重矩阵 W 的每一列对应一个神经元的权重。
• 循环计算每个神经元的输出,支持任意激活函数 g()(需提前定义)。
• 示例参数:python W = np.array([[1, -3, 5], [2, 4, -6]]) # 2x3矩阵(输入维度2,输出维度3) b = np.array([-1, 1, 2]) # 偏置向量 a_in = np.array([200, 17]) # 输入向量
(2) 多层串联:sequential 函数
def sequential(x):
a1 = dense(x, W1, b1) # 第一层计算
a2 = dense(a1, W2, b2) # 第二层计算
a3 = dense(a2, W3, b3) # 第三层计算
f_x = dense(a3, W4, b4) # 输出层计算
return f_x
• 关键点:
• 通过多次调用 dense 实现多层前向传播。
• 需提前定义每层的参数 W1, b1, W2, b2, ...。
3. 示例计算流程(结合图中参数)
假设输入 x = [200, 17],参数如下:
• 第一层(W1, b1):
W1 = np.array([[1, -3, 5], [2, 4, -6]]) # 2x3矩阵
b1 = np.array([-1, 1, 2]) # 偏置
• 计算步骤:
1. 第一个神经元:z1 = 1*200 + 2*17 + (-1) = 233 → a1_1 = g(233)
2. 第二个神经元:z2 = -3*200 + 4*17 + 1 = -531 → a1_2 = g(-531)
3. 第三个神经元:z3 = 5*200 + (-6)*17 + 2 = 900 → a1_3 = g(900)
• 输出 a1 = [g(233), g(-531), g(900)](具体值取决于 g 函数)。
4. 关键注意事项
- 权重矩阵形状:
• 第 (i) 层的W形状为(输入维度, 输出维度)。例如,从2维输入到3维输出需2x3矩阵。 - 激活函数
g():
• 需提前定义(如sigmoid、ReLU),未在图中显示具体实现。 - 向量化优化:
• 实际应用中应避免循环,直接用矩阵运算(如Z = np.dot(a_in, W.T) + b)。
5. 总结与扩展
• 图片核心:展示了前向传播的底层实现逻辑,适合理解神经网络的基础数学原理。
• 扩展建议:
• 使用 NumPy 的广播机制优化 dense 函数。
• 结合反向传播实现完整训练流程(如梯度下降)。
如需进一步解释某部分代码或数学细节,请具体说明!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)