机器人运动规划(motion planning)发展到了什么阶段?
如今发展到能够同时处理复杂环境和动态任务的阶段。
先从传统算法开始,再者应用较多的算法,最后是开源库。
传统算法的优化与改进
快速搜索随机树(RRT)及其升级版
属于高维空间规划的经典算法 ,通过引入启发式引导和并行计算,效率大幅提升。像RRT*通过渐进优化路径,能找到更短的可行解。
而FCIT*(完全连接知情树)则利用 SIMD 并行技术,去掉了传统 RRT 的最近邻搜索步骤,在保证最优性的同时,初始解生成速度比现有算法快。
Nearest-Neighbourless Asymptotically Optimal Motion Planning with Fully Connected Informed Trees (FCIT*)

A* 算法与混合规划
全局路径规划器 (A*) + 局部实时控制器 (DWA),属于移动机器人混合规划中最经典、最实用的范式之一。
The dynamic window approach to collision avoidance
基于学习的智能规划
深度强化学习(DRL)与博弈论结合
针对多机器人协作和动态对抗场景,IGT-MPC(隐式博弈论模型预测控制)通过学习博弈论交互结果,指导机器人在竞争或合作中优化策略。
Learning Two-agent Motion Planning Strategies from Generalized Nash Equilibrium for Model Predictive Control

运动基元与安全强化学习
一种混合方法,在不需要复杂系统精确解析模型的前提下,实现复杂任务中的安全、灵巧运动规划。对于动力学约束复杂的任务,例如机器人空气曲棍球,学习规划与运动基元结合的方法,通过黑盒优化生成安全且灵巧的动作。
Bridging the gap between Learning-to-plan, Motion Primitives and Safe Reinforcement Learning
神经 RRT(NRRT)
思路是运动规划Transformer,应用于需要实时性能的场景,用一个统一的神经网络模型直接输出路径,不完全是引导RRT,属于端到端思路:用神经网络完全替代传统规划器。
Motion Planning Transformers: One Model to Plan Them All
多机器人协作与动态环境处理
非对称自博弈强化学习
在多机器人集群导航中,深度强化学习框架,通过模拟机器人与干扰者的对抗,提升系统鲁棒性。
A Deep Reinforcement Learning Approach Using Asymmetric Self-Play for Robust Multi-Robot Flocking

协作定位下的多机器人规划
使用图神经网络来构建多机器人系统,在复杂、大规模的环境中具有可扩展性和良好性能。
Graph Neural Networks for Multi-Robot Active Information Acquisition
开源库和平台
MoveIt! 2:支持混合规划和插件化扩展,已应用在 NASA Robonaut 2 和亚马逊分拣机器人。
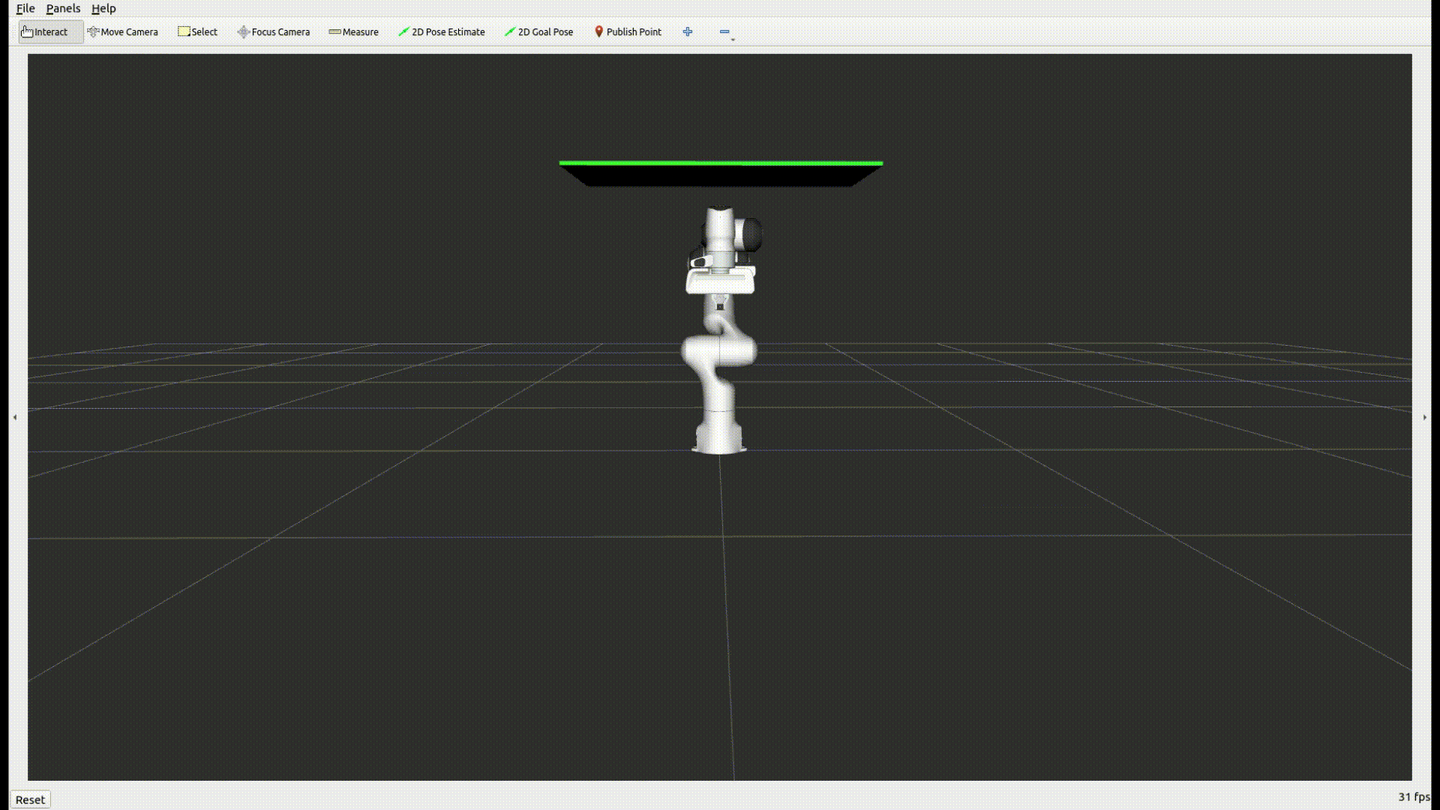
OMPL:运动规划算法的集合库,包含多种采样算法,如 RRT*、PRM,可快速集成到工业系统中。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 38
38 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)