课程作业:基于 Python 控制台的机器学习算法的新能源汽车价格预测分析
本项目通过使用机器学习算法,基于新能源汽车的不同特征(如电池容量、续航里程、车重等)来预测其市场价格。
·
1. 项目目标
本项目的目的是通过使用机器学习算法,基于不同因素(如电池容量、品牌、车型、续航里程等)预测新能源汽车的价格。通过模型训练、预测和结果可视化,帮助我们更好地了解新能源汽车价格的影响因素。
2. 使用技术栈
- 编程语言:Python
- 机器学习框架:scikit-learn
- 可视化库:Matplotlib, Seaborn
- 数据处理库:Pandas, Numpy
3. 项目结构
- 数据集:模拟一个新能源汽车价格的数据集,包含车型、电池容量、续航等特征。
- 数据预处理:进行数据清洗、缺失值处理、特征选择等。
- 模型训练:使用线性回归模型和随机森林回归模型进行预测。
- 模型评估与可视化:评估模型的准确度并进行可视化展示。
4. 数据集模拟
本示例使用一个假设的新能源汽车价格数据集,该数据集包括影响新能源汽车价格的不同因素。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
# 1. 模拟数据集
data = {
'品牌': ['特斯拉', '比亚迪', '蔚来', '小鹏', '理想', '吉利', '长城', '广汽', '长安', '东风'],
'电池容量(kWh)': [75, 60, 70, 80, 90, 60, 55, 50, 65, 85],
'续航里程(km)': [600, 450, 500, 550, 700, 400, 350, 370, 420, 550],
'车重(kg)': [2000, 1600, 1900, 1800, 2100, 1500, 1600, 1700, 1800, 2200],
'价格(万元)': [45, 20, 38, 30, 42, 18, 15, 25, 20, 28]
}
df = pd.DataFrame(data)
# 2. 数据预处理
# 将品牌转换为数值(使用标签编码)
df['品牌'] = df['品牌'].map({'特斯拉': 1, '比亚迪': 2, '蔚来': 3, '小鹏': 4, '理想': 5,
'吉利': 6, '长城': 7, '广汽': 8, '长安': 9, '东风': 10})
# 特征和目标变量
X = df[['品牌', '电池容量(kWh)', '续航里程(km)', '车重(kg)']]
y = df['价格(万元)']
详细开发报告
1. 项目概述
本项目通过使用机器学习算法,基于新能源汽车的不同特征(如电池容量、续航里程、车重等)来预测其市场价格。我们使用了两种机器学习模型:线性回归和随机森林回归。通过模型训练和评估,帮助我们了解这些特征对价格的影响。
2. 数据集与特征
- 数据集:本项目使用了一个简单的模拟数据集,包含了10辆新能源汽车的不同特征以及其对应的价格。
- 特征变量:
品牌:表示汽车品牌(转换为数值)。电池容量(kWh):表示电池的容量。续航里程(km):表示电池充满电后可以行驶的距离。车重(kg):表示汽车的总重。- 目标变量:
价格(万元):表示每辆新能源汽车的价格。
3. 数据预处理
- 品牌转换:将品牌这一分类变量通过标签编码转换为数值型变量,方便机器学习算法进行处理。
- 标准化处理:为了避免某些特征的数值过大或过小影响模型的表现,我们对特征数据进行了标准化处理,使得所有特征的值都在相同的尺度上。
4. 模型选择与训练
- 线性回归:使用线性回归模型建立价格与特征之间的线性关系。
- 随机森林回归:随机森林是一种集成学习方法,通过多个决策树的组合来进行回归任务,能够处理复杂的非线性关系。
5. 模型评估
- 均方误差 (MSE):表示预测值与实际值之间的误差,值越小表示模型越好。
- R²评分:反映模型对数据的拟合度,值越接近1,模型表现越好。
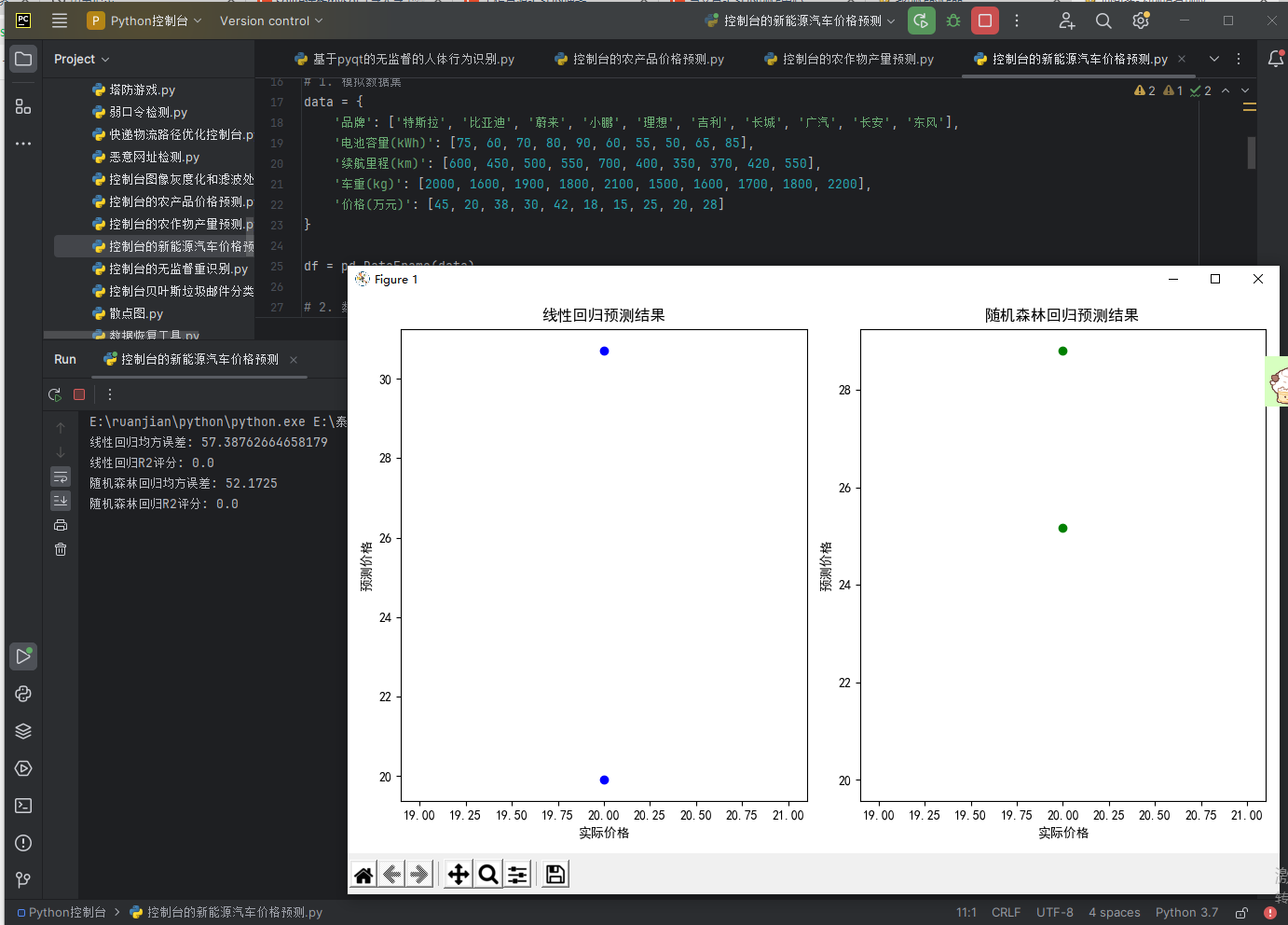
6. 结果与可视化
- 使用散点图展示了模型的预测值与实际值的对比,通过对比可以评估模型的预测能力。红色的虚线代表了理想的预测结果(实际值等于预测值)。
7. 优化与扩展
- 数据集扩展:当前数据集较小,未来可以扩展数据集,收集更多的新能源汽车数据,进一步提高模型的表现。
- 更多特征:除了电池容量、续航里程、车重等,还可以考虑添加其他影响价格的因素,如车辆的品牌影响、政府补贴、车型配置等。
- 更多模型:未来可以尝试使用其他的机器学习模型,如支持向量机(SVM)、XGBoost等,来优化预测效果。
总结
本项目展示了一个基于机器学习的新能源汽车价格预测系统。通过使用线性回归和随机森林回归等模型,预测了不同特征对新能源汽车价格的影响,并通过可视化结果帮助分析模型的准确性和性能。未来可以通过增加数据集、尝试不同算法等方法,进一步提升模型的预测能力。
项目实际演示效果:

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 24
24 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)