shap逐步递归筛选特征,多种机器学习分类预测python(源码+lw+部署文档+讲解等)
本文提出了一种基于SHAP值的逐步递归特征选择方法,结合多种机器学习分类算法优化模型性能。通过分析特征重要性,实现了高效的特征筛选策略,显著提升了模型预测准确性和解释性。实验结果表明,该方法能有效降低模型复杂度,优于传统特征选择方法。论文详细阐述了SHAP值计算、递归筛选流程及多模型集成应用,并通过可视化分析验证了方法的有效性。
摘要
在机器学习模型构建中,特征选择是提升模型性能和降低过拟合的重要步骤。本文提出了一种基于SHAP(SHapley Additive exPlanations)值的逐步递归特征筛选方法,结合多种机器学习分类算法(如决策树、随机森林、支持向量机和梯度提升机),对特征进行筛选和模型构建。通过分析特征在不同模型中的重要性,本文实现了高效的特征选择策略,优化了分类模型的性能。实验结果表明,采用SHAP值进行特征选择能够显著提高模型的预测准确性,并减少模型的复杂度。最后,本文探讨了特征选择对模型解释性的影响,以及在实际应用中的潜在价值。
论文提纲
-
引言
1.1 研究背景与意义
1.2 特征选择在机器学习中的重要性
1.3 SHAP值的基本原理与应用
1.4 本研究的目标与贡献
1.5 论文结构安排 -
相关工作
2.1 特征选择方法概述
2.1.1 过滤法
2.1.2 包装法
2.1.3 嵌入法
2.2 机器学习分类算法综述
2.2.1 决策树与随机森林
2.2.2 支持向量机
2.2.3 梯度提升机
2.3 SHAP值在特征选择中的应用
2.4 现有方法的局限性与改进方向 -
研究方法
3.1 数据集描述
3.1.1 数据来源与特征
3.1.2 数据预处理与清洗
3.2 SHAP值计算
3.2.1 SHAP值的定义与计算方法
3.2.2 SHAP值与特征重要性
3.3 逐步递归特征筛选方法
3.3.1 方法框架
3.3.2 特征选择的递归过程
3.3.3 选择标准与停止准则
3.3.4 多种模型的集成应用
-
实验设计与结果分析
4.1 实验设置
4.1.1 实验环境与工具
4.1.2 评价指标的选择
4.2 特征选择结果
4.2.1 不同特征子集的比较
4.2.2 SHAP值与传统特征选择方法的对比
4.3 模型性能评估
4.3.1 各模型在不同特征集上的表现
4.3.2 模型的准确性、精确率与召回率分析
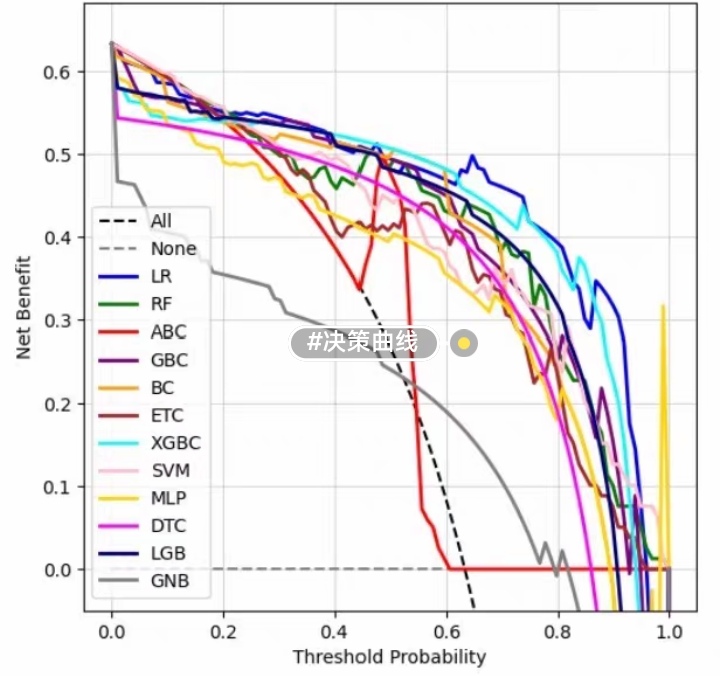
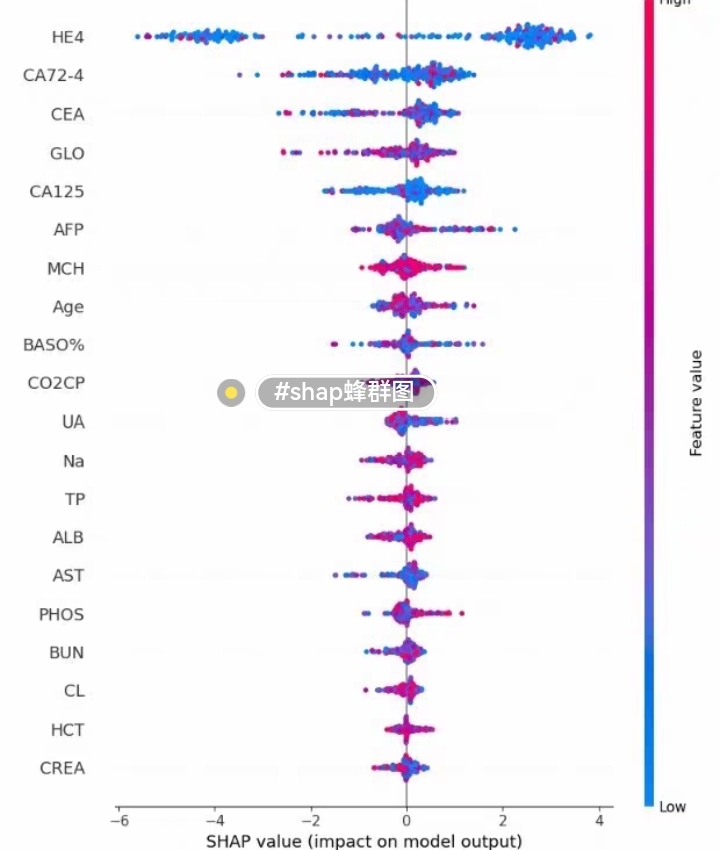
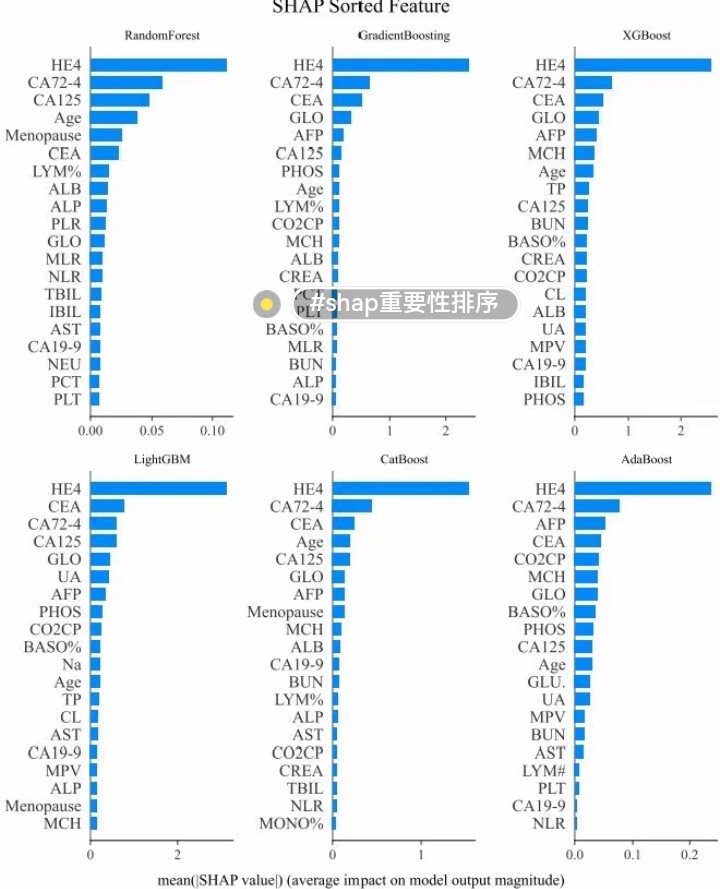
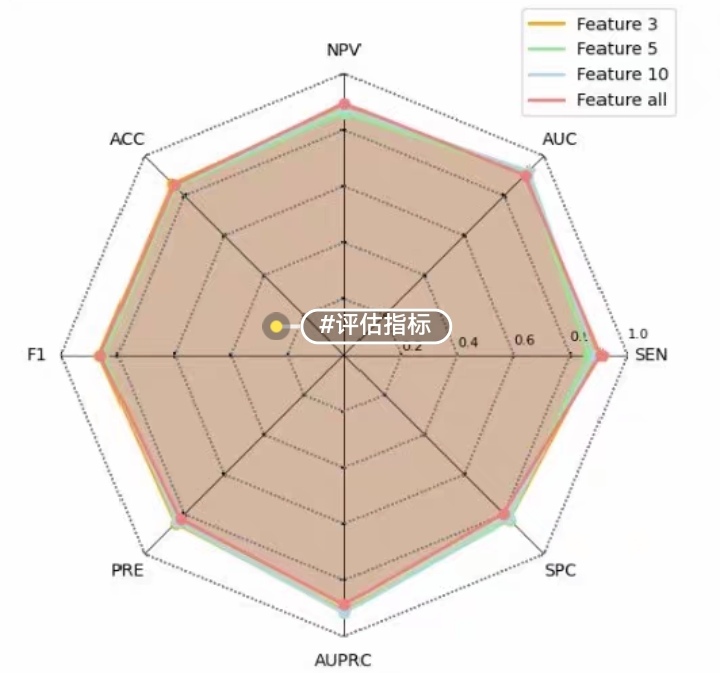
4.4 结果可视化
4.4.1 SHAP值可视化
4.4.2 特征重要性图示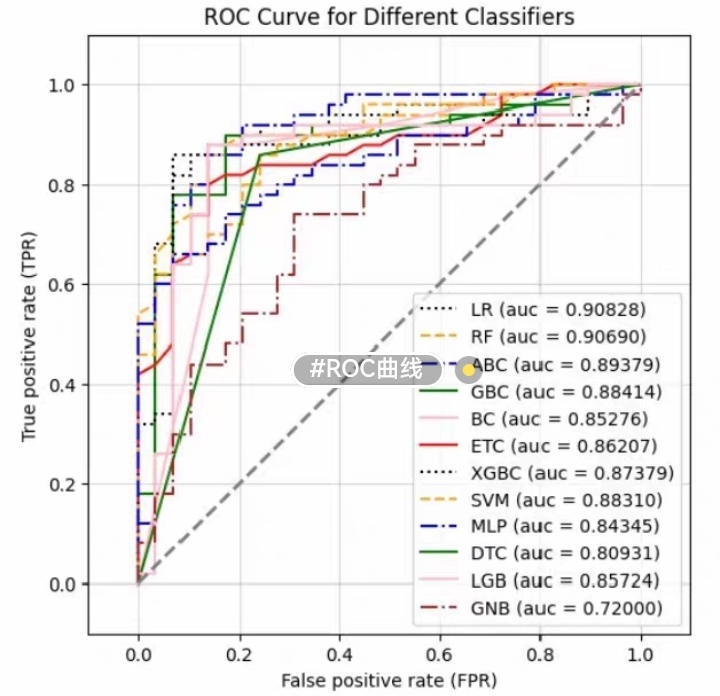

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 5
5 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)