人工智能训练师学习资料
1.1.1智能医疗系统中的业务数据处理流程设计
data = pd.read_csv(r'D:\python\patient_data.csv')
data['RiskLevel'] = np.where(data['DaysInHospital']>7, '高风险患者', '低风险患者')
risk_counts = data['RiskLevel'].value_counts ()
# 计算高风险患者占比\n"
high_risk_ratio = risk_counts['高风险患者'] /len(data)
# 计算低风险患者占比\n",
low_risk_ratio = risk_counts['低风险患者'] /len(data)
# 输出结果\n"
print('高风险患者:',risk_counts['高风险患者'])
print('低风险患者:',risk_counts['低风险患者'])
print("高风险患者占比:", high_risk_ratio)
print("低风险患者占比:", low_risk_ratio)
data['BMIRange'] = pd.cut(data['BMI'], bins=bmi_bins, labels=bmi_labels)
bmi_risk_rate = data.groupby('BMIRange')['RiskLevel'].apply(lambda x: (x == '高风险患者').mean())
# 统计每个BMI区间的患者数量\n",
bmi_patient_count = data['BMIRange'].value_counts()
# 输出结果\n",
print("BMI区间中高风险患者的比例和患者数:")
print(bmi_risk_rate)
print(bmi_patient_count)
data['AgeRange'] = pd.cut (data['Age'], bins=age_bins, labels=age_labels)
"# 计算每个年龄区间中高风险患者的比例\n",
"age_risk_rate = data.groudby('AgeRange')['RiskLevel'].apply(lambda x: (x == '高风险患者').mean())\n",
"# 统计每个年龄区间的患者数量\n",
"age_patient_count = data['AgeRange'].value_counts(),
"# 输出结果\n",
"print(\"年龄区间中高风险患者的比例和患者数:\")\n",
"print(age_risk_rate ) #高风险患者的比例\n",
"print(age_patient_count #高风险患者的患者数"
1.1.2智能农业系统中的业务数据采集和处理流程设计
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r'D:\python\sensor_data.csv')
# 1. 传感器数据统计\n",
# 对传感器类型进行分组,并计算每个组的数据数量和平均值\n",
sensor_stats = data.groupby('SensorType')['Value'].agg(['count', 'mean'])
# 输出结果\n",
print( sensor_stats)
# 筛选出温度和湿度数据,然后按位置和传感器类型分组,计算每个组的平均值\n",
location_stats = data[data['SensorType'].isin(['Temperature', 'Humidity'])].groupby(['Location', 'SensorType'])['Value'].mean().unstack()
# 输出结果\n",
print(location_stats)
"# 标记异常值\n",
"data['is_abnormal'] = np.where
" ((data['SensorType'] == 'Temperature') & ((data['Value'] < -10) | (data['Value'] > 50))) |\n",
" ((data['SensorType'] == 'Humidity') & ((data['Value'] < 0) | (data['Value'] > 100))),\n",
" True, False\n",
")\n",
"# 输出异常值数量\n",
"print(\"异常值数量:\", data['is_abnormal'].sum())\n",
"# 填补缺失值\n",
"# 使用前向填充和后向填充的方法填补缺失值\n",
"data['Value'].fillna(method='ffill', inplace=True)\n",
"data['Value'].fillna(method='bfill', inplace=True)\n",
"# 保存清洗后的数据\n",
"# 删除用于标记异常值的列,并将清洗后的数据保存到新的CSV文件中\n",
"cleaned_data = data.drop(columns=['is_abnormal'])\n",
"cleaned_data.to_csv('cleaned_sensor_data.csv', index=False)\n",
"print(\"数据清洗完成,已保存为 'cleaned_sensor_data.csv'\")"
]
1.1.3金融机构信用评估系统中的业务数据审核流程设计
"missing_values = data.data.isnull().sum()
"duplicate_values = data.data.duplicated().sum()
# 2. 数据合理性审核\n",
data['is_age_valid'] = data['Age'].between(18, 70) #Age数据的合理性审核 2分\n",
data['is_income_valid'] = data['Income'] > 2000 #Income数据的合理性审核 2分\n",
data['is_loan_amount_valid'] = data['LoanAmount'] < (data['Income'] * 5) #LoanAmount数据的合理性审核 2分\n",
data['is_credit_score_valid'] = data['CreditScore'].between(300, 850) #CreditScore数据的合理性审核 2分\n",
"# 标记不合理数据\n",
"invalid_rows = data[~data['is_valid']]\n",
"# 删除不合理数据行\n",
"cleaned_data = data[data['is_valid']]\n",
"# 删除标记列\n",
"cleaned_data = cleaned_data.drop(columns=['is_age_valid', 'is_income_valid', 'is_loan_amount_valid', 'is_credit_score_valid', 'is_valid'])\n",
"# 保存清洗后的数据\n",
"cleaned_data.to_csv('cleaned_credit_data.csv', index=False)\n",
"print(\"数据清洗完成,已保存为 'cleaned_credit_data.csv'\")"
1.1.4电商平台用户行为分析系统的数据采集与处理流程设计
# 1. 数据采集\n",
"# 从本地文件中读取数据 2分\n",
"data = pd.read_csv(r'user_behavior_data.csv')\n",
"print(\"数据采集完成,已加载到DataFrame中\")\n",
"\n",
"# 打印数据的前5条记录 2分\n",
"print(data.head())"
# 2. 数据清洗与预处理\n",
# 处理缺失值 2分\n",
data = data.dropna()
# 数据类型转换\n",
data['Age'] = data['Age'].astype(int) # Age数据类型转换 2分\n",
data['PurchaseAmount'] = data['PurchaseAmount'].astype(float) # PurchaseAmount数据类型转换 2分\n",
data['ReviewScore'] = data['ReviewScore'].astype(int) # ReviewScore数据类型转换 2分\n",
# 处理异常值 2分\n",
data = data[(data['Age'].between(18, 70)) &
(data['PurchaseAmount'] > 0) &
(data['ReviewScore'].between(1, 5))]
# 数据标准化\n",
data['PurchaseAmount'] = (data['PurchaseAmount'] - data['PurchaseAmount'].mean()) data['PurchaseAmount'].std() # PurchaseAmount数据标准化 2分\n",
data['ReviewScore'] = (data['ReviewScore'] - data['ReviewScore'].mean()) data['ReviewScore'].std() # ReviewScore数据标准化 2分\n",
# 保存清洗后的数据 1分\n",
data.to_csv('cleaned_user_behavior_data.csv', index=False)
1.1.5智能交通系统的数据采集、处理和审核流程设计
"# 从本地文件中读取数据 2分\n",
"data = pd.read_csv('vehicle_traffic_data.csv')\n",
"print(\"数据采集完成,已加载到DataFrame中\")\n",
"# 打印数据的前5条记录\n",
"print(data.head())"
"# 处理缺失值 2分\n",
"data =data.dropna()\n",
"# 数据类型转换\n",
"data['Age'] = data['Age'].astype (int) #Age数据类型转换 1分\n",
"data['Speed'] = data['Speed'].astype(float) #Speed数据类型转换 1分\n",
"data['TravelDistance'] = data['TravelDistance'].astype(float)
"data['TravelTime'] = data['TravelTime'].astype(float)
"# 处理异常值 2分\n",
"data = data[(data['Age'].between(18, 70)) &
(data['Speed'].between(0, 200)) &
(data['TravelDistance'].between(1, 1000)) &
(data['TravelTime'].between(1, 1440))]
"# 保存清洗后的数据 1分\n",
"data.to_csv('cleaned_vehicle_traffic_data.csv', index=False)
"print(\"数据清洗完成,已保存为 'cleaned_vehicle_traffic_data.csv'\")"
# 审核字段合理性 1分\n",
unreasonable_data = data[~((data['Age'].between(18, 70)) &
(data['Speed'].between(0, 200)) &
(data['TravelDistance'].between(1, 1000)) &
(data['TravelTime'].between(1, 1440)))]
print(\"不合理的数据:\\n\", unreasonable_data)x
# 4. 数据统计\n",
# 统计每种交通事件的发生次数 2分\n",
traffic_event_counts = data['TrafficEvent'].value_counts()
print(\"每种交通事件的发生次数:\\n\", traffic_event_counts)
统计不同性别的平均车速、行驶距离和行驶时间 2分\n",
gender_stats = data.groupby('Gender').agg({'Speed': 'mean', 'TravelDistance': 'mean', 'TravelTime': 'mean'})
print(\"不同性别的平均车速、行驶距离和行驶时间:\\n\", gender_stats)
# 统计不同年龄段的驾驶员数 2分\n",
age_bins = [18, 25, 35, 45, 55, 65, 70]
age_labels = ['18-25', '26-35', '36-45', '46-55', '56-65', '66-70']
data['AgeGroup'] = pd.cut(data['Age'], bins=age_bins, labels=age_labels, right=False)
age_group_counts = data['AgeGroup'].value_counts()
print(\"不同年龄段的驾驶员数:\\n\", age_group_counts)"
1.2.1顾客评价情感识别业务模块效果优化
(1)顾客评价情感识别业务模块中用户反映最强烈的两个问题及影响分析
问题1:情感识别准确性不高,导致分析结果偏差
-
用户不满原因:
当情感识别结果不准确时,可能导致商家或平台对顾客反馈产生误解。例如:-
将负面评价误判为正面,导致商家忽视问题,无法及时改进;
-
将中性或正面评价误判为负面,可能引发不必要的客服介入,浪费资源。
-
-
影响体验:
用户(尤其是商家)会失去对系统的信任,认为分析结果不可靠,进而减少使用频率或转向人工分析,增加时间成本。
问题2:响应速度慢,用户需长时间等待识别结果
-
用户不满原因:
在电商场景中,快速获取分析结果对商家制定运营策略(如危机公关、产品优化)至关重要。延迟会导致:-
商家无法实时监控舆情,错过最佳处理时机;
-
普通用户查看情感分析结果时体验卡顿,降低使用意愿。
-
-
影响体验:
效率低下直接违背互联网产品的“即时反馈”原则,用户可能放弃使用该功能。
(2)优化方案设计
目标:提升准确性、加快响应速度、改善用户体验。
关键实施步骤
-
模型优化(解决准确性)
-
数据增强:
-
收集更多领域相关评价数据(如电商垂直领域的“退货”“物流慢”等高频词);
-
加入对抗样本训练,减少歧义句(如“手机很好,但物流太慢”)的误判。
-
-
算法升级:
-
采用预训练模型(如BERT、RoBERTa)微调,替代传统情感分析模型;
-
引入注意力机制,重点捕捉评价中的情感关键词(如“差评”“推荐”)。
-
-
-
性能优化(解决响应速度)
-
异步处理:
-
对批量评价采用异步任务,先返回“分析中”状态,完成后通知用户;
-
实时单条评价分析使用轻量级模型(如蒸馏后的BERT模型)。
-
-
缓存机制:
-
对高频商品或通用评价(如“好评”“快递快”)缓存分析结果,减少重复计算。
-
-
-
用户体验改进
-
界面优化:
-
提供可视化报告(如情感分布饼图、关键词云),替代纯文本结果;
-
增加“人工复核”按钮,允许用户对错误识别结果手动修正。
-
-
定制化服务:
-
允许商家自定义情感标签(如“关注物流问题”“重点监控产品质量”);
-
支持按时间、商品类目等多维度筛选分析结果。
-
-
预期优化效果
| 指标 | 优化前 | 优化后目标 |
|---|---|---|
| 情感识别准确率 | 75% | ≥90% |
| 平均响应时间 | 5秒/条 | ≤1秒(实时)、批量任务异步化 |
| 用户满意度(调研) | 60% | ≥85% |
附加价值:
-
商家可快速定位问题商品,差评处理效率提升30%;
-
通过情感趋势分析,辅助选品和营销策略制定。
1.2.2老年人健康监测与管理服务业务模块效果优化
1.2.2-1
数据准确性不高
- 影响:老年人及其家属、医护人员会依据心率监测数据判断健康状况。不准确的数据可能导致误判,如误报心率异常,引发不必要的紧张和医疗资源浪费;或者未能检测出真正的异常,延误病情发现和治疗,严重影响老年人健康管理的科学性和有效性。
- 原因:从技术层面看,传感器精度不足,易受外界干扰(如运动、电磁干扰等),采集的数据存在误差;数据传输过程中可能出现丢包、信号衰减等问题,影响数据完整性;算法对采集到的原始数据处理能力有限,无法有效过滤噪声、校正偏差。从流程方面,设备校准不及时或校准方法不准确,日常维护不到位,也会导致数据准确性下降。
- 异常预警响应慢
- 影响:当老年人出现心率异常(如心动过速、心动过缓等)时,不能及时发出预警,错过最佳干预时机,可能使病情恶化。这会让老年人及其家属对健康监测服务失去信任,降低对智慧养老平台的依赖度和使用意愿。
- 原因:技术上,算法对异常情况的识别规则不够精准和灵敏,不能快速判断异常;数据处理和分析速度慢,尤其是在处理大量数据时,系统运算能力不足,导致预警延迟。流程上,预警触发机制不健全,数据从采集到分析再到预警发出的环节过多、衔接不畅,各环节之间缺乏高效协同,影响响应速度。
1.2.2-2
- 优化方案
- 技术方面:升级传感器硬件,采用高精度、抗干扰能力强的心率传感器,提高原始数据采集质量;优化数据传输协议,确保数据稳定、快速传输;改进数据分析算法,利用深度学习等人工智能技术,提高对心率数据的分析和异常识别能力。
- 流程方面:建立定期设备校准和维护机制,规范校准流程和标准;简化数据处理和预警流程,减少不必要环节,建立数据采集、分析、预警的快速响应通道;明确各部门和人员在心率监测模块中的职责,加强协作。
- 关键实施步骤
数据采集与预处理:
采购并安装新的高精度心率传感器,对设备
- 进行全面调试;制定数据采集规范,确保采集数据的准确性和一致性;对采集到的原始心率数据进行滤波、降噪等预处理操作,去除干扰因素,提高数据质量。
- 模型训练与优化:收集大量不同场景、不同健康状况下的老年人真实心率数据,构建数据集;
- 预警系统搭建与测试:基于优化后的算法,搭建实时异常预警系统,设定合理的异常阈值和预警规则;进行模拟测试和实际场景测试,验证预警系统的准确性和响应速度,根据测试结果进行调整和优化。
- 流程优化与整合:梳理心率监测模块的数据处理和预警流程,去除冗余环节,明确各环节的时间节点和责任人;建立跨部门协作机制,加强技术团队、运维团队、医疗团队之间的沟通与协作,确保流程顺畅运行。
- 团队资源协调
成立跨职能项目团队,包括硬件工程师负责传感器及相关硬件的选型、安装和调试;算法工程师专注于数据分析算法和异常识别模型的开发与优化;运维工程师承担设备日常维护、数据传输保障和系统运行监控工作;医学专家提供专业的医学知识和建议,确保心率异常判断标准和预警规则符合医学规范。定期召开项目会议,沟通项目进展,协调解决遇到的问题;建立共享文档和沟通平台,方便团队成员及时共享信息和资源。 - 预期效果
心率监测数据准确性大幅提高,误差率降低至行业较低水平,有效减少误判和漏判情况。异常预警响应时间显著缩短,能够及时发现老年人心率异常情况,为医疗干预争取宝贵时间。老年人及其家属对智慧养老平台心率监测服务的满意度大幅提升,增强对平台的信任和依赖,提升智慧养老服务质量和品牌形象。
1.2.3智慧金融服务业务模块效果优化
1.2.3-1 智慧金融服务业务模块中最突出的用户问题及影响分析
核心问题1:金融数据准确性不足
-
具体表现:账户余额更新延迟、交易记录缺失、资产统计误差
-
用户不满原因:
-
导致用户对平台失去信任,可能错过重要资金变动(如大额转账未及时提醒)
-
影响财务决策准确性(如基于错误数据做出投资决定)
-
增加用户人工核对时间成本(需频繁比对银行流水)
核心问题2:异常预警响应迟缓
-
具体表现:欺诈交易预警延迟、异常登录通知滞后、风险操作未及时阻断
-
用户不满原因:
-
资金安全无法保障(如盗刷发生后才预警)
-
错过风险处置黄金时间窗(通常金融欺诈前30分钟最关键)
-
产生"假警报"降低预警可信度(延迟导致误判正常交易)
核心问题3:服务响应效率低下
-
具体表现:AI客服重复提问、复杂业务强制转人工、查询响应超时
-
用户不满原因:
-
紧急金融需求无法及时解决(如冻结账户需多轮验证)
-
操作流程繁琐影响使用意愿(特别是中老年用户群体)
-
服务断点影响体验连贯性(如理财申购流程多次中断)
1.2.3-2 智慧金融服务优化方案设计
优化目标
-
数据准确率提升至99.9%以上
-
异常预警响应速度压缩至30秒内
-
用户满意度提升20个百分点
关键技术实施步骤
-
数据治理增强
-
建立多源校验机制:对接央行征信+商业银行API+第三方支付数据
-
实施流式数据处理:采用Apache Flink实时处理交易流水
-
部署数据质量监控:设置78个金融数据校验规则(如余额波动阈值告警)
-
-
智能预警系统升级
-
构建三级预警模型:
python
复制
下载
class FraudDetection: def __init__(self): self.level1 = LightGBM(处理常规欺诈模式) # <100ms响应 self.level2 = LSTM-Attention(识别时序异常) # <1s响应 self.level3 = GraphNN(挖掘团伙欺诈) # <30s响应 -
建立预警熔断机制:对高频操作强制二次验证(如1分钟内5次密码尝试)
-
-
服务流程再造
-
对话系统优化:
-
金融意图识别准确率提升至92%(采用FinBERT微调)
-
建立43个金融服务对话流程模板
-
-
实施"AI+人工"协同:

-
graph LR
A[用户请求] --> B{AI自动处理}
B -->|成功| C[返回结果]
B -->|失败| D[转专属客户经理]
D --> E[人工补充材料]
E --> F[系统自动学习]
-
-
用户体验提升
-
开发金融健康看板:
-
可视化资产波动曲线
-
风险暴露热力图
-
智能诊断报告生成
-
-
建立个性化通知系统:
-
风险偏好分级推送(保守型/进取型用户差异化预警)
-
-
预期优化效果
| 指标 | 优化前 | 优化后目标 | 测量方式 |
|---|---|---|---|
| 数据同步时效性 | 2-4小时 | ≤30秒 | 埋点监测数据更新时间差 |
| 欺诈识别准确率 | 82% | ≥96% | 回溯测试+人工复核 |
| 服务响应时长 | 45秒 | ≤8秒 | 对话系统日志分析 |
| 用户操作错误率 | 23% | ≤9% | 页面热力图+行为分析 |
增值效益
-
预计降低30%的金融纠纷投诉量
-
用户资产配置效率提升40%
-
反欺诈系统每年可减少约1200万元损失
1.2.4智能卖点生成系统业务模块效果优化
1.2.4-1 智能卖点生成系统核心问题及影响分析
核心问题1:卖点生成准确性不足
-
典型表现:
-
生成与产品无关的通用描述(如"质量好"等无效卖点)
-
出现事实性错误(将"无线充电"误植为"快充技术")
-
-
用户痛点:
-
需要花费大量时间人工筛选和修正,增加运营成本
-
错误卖点直接影响转化率(某电商实测错误卖点使点击率下降37%)
-
损害品牌专业性形象(特别是3C、美妆等需要精准描述的品类)
-
核心问题2:个性化适配能力弱
-
典型表现:
-
无法区分B端/C端不同场景需求(如企业采购关注参数,个人用户关注体验)
-
忽视用户历史行为数据(重复生成已证明无效的卖点)
-
-
用户痛点:
-
批量生成的同质化内容导致平台流量惩罚(某服饰卖家因内容重复导致搜索降权)
-
无法满足细分市场需求(如母婴产品需要突出安全认证,但系统持续强调性价比)
-
丧失差异化竞争优势(竞品使用相同系统生成雷同文案)
-
核心问题3:动态响应能力缺失
-
典型表现:
-
不能实时结合营销热点(如节日促销、社会热点)
-
忽略竞品卖点变化(当竞品主推"30天保价"时仍生成常规卖点)
-
-
用户痛点:
-
错失流量红利期(热点事件前3天是黄金传播期)
-
被迫额外购买舆情监控工具,增加运营复杂度
-
无法构建动态竞争壁垒(始终处于跟随状态)
-
-
1.2.4-2 智能卖点生成系统优化方案
优化目标体系
关键技术实施步骤
-
知识图谱构建
-
建立三级产品知识体系:
python
复制
下载
class ProductKG: def __init__(self): self.level1 = 行业标准库(3C/美妆/食品等12大类) # 结构化参数 self.level2 = 竞品卖点库(动态爬取TOP100竞品) # 每小时更新 self.level3 = 用户偏好库(基于历史点击率构建) # 个性化维度 -
实施参数校验机制:对"800万像素"等量化指标自动核对产品白皮书
-
-
多模态生成引擎升级
-
架构设计:
复制
下载
输入层 → [BERT微调模块] → [卖点优选器] → [A/B测试管道] ↑ ↑ ↑ 产品说明书 用户历史数据 实时点击率反馈 -
引入强化学习:根据CTR数据动态调整生成策略(某内衣品牌实测提升ROI 28%)
-
-
场景化适配方案
-
开发营销日历插件:
json
复制
下载
{ "predefined_events": [ {"双11": {"time_window":"10.20-11.11", "keywords":["限时","赠品"]}}, {"开学季": {"time_window":"8.15-9.5", "keywords":["学生价","套装"]}} ] } -
构建用户决策模型:
用户类型 核心关注点 卖点生成策略 价格敏感型 折扣/性价比 突出"全网低价""买赠" 品质追求型 材料/工艺 强调"进口原料""质检"
-
-
效果验证体系
-
建立三维评估指标:
def evaluate_selling_point(sp): accuracy = NLP模型打分(产品参数匹配度) uniqueness = 1 - 文本相似度(竞品卖点库) conversion = 预估CTR(基于历史行为模型) return 0.4*accuracy + 0.3*uniqueness + 0.3*conversion
-
预期优化效果
| 维度 | 优化前 | 优化后目标 | 验证方式 |
|---|---|---|---|
| 生成效率 | 5分钟/条 | 30秒/条(批量100条起) | 压力测试 |
| 点击率 | 行业平均1.2% | 提升至2.5%+ | A/B测试(95%置信区间) |
| 人工修改率 | 62% | ≤15% | 版本迭代对比分析 |
| 个性化满意度 | 3.1/5分 | ≥4.5/5分 | 用户调研(NPS≥40) |
衍生价值
-
可扩展为智能详情页生成系统(节约80%页面制作成本)
-
积累的行业知识库可反哺搜索推荐系统
-
动态卖点数据可作为选品决策辅助依据
1.2.5腾讯云智能数智人系统业务模块效果优化
1.2.5-1 腾讯云智能数智人系统核心问题及影响分析
核心问题1:意图识别准确率低
-
典型表现:
-
多轮对话中频繁要求重复输入(如客服场景需多次确认订单号)
-
对行业术语理解偏差(将"IOPS"误解为"操作系统")
-
-
用户痛点:
-
延长问题解决时间(实测复杂业务办理时间增加2.3倍)
-
导致错误操作(某银行案例误将"基金赎回"执行为"基金申购")
-
增加用户挫败感(87%用户在3次误解后会转人工)
-
核心问题2:个性化交互缺失
-
典型表现:
-
无法识别VIP用户身份持续推送基础指引
-
语气风格与业务场景不匹配(如政务场景使用电商促销话术)
-
-
用户痛点:
-
丧失高价值用户粘性(企业VIP客户服务满意度下降29%)
-
造成场景违和感(医疗咨询机器人使用网络流行语)
-
无法构建情感连接(用户忠诚度培养困难)
-
核心问题3:多模态交互卡顿
-
典型表现:
-
语音/手势/表情响应延迟超过800ms
-
跨模态信息不同步(如语音说"请看这里"但无视觉指引)
-
-
用户痛点:
-
交互体验割裂(实测卡顿导致23%用户放弃继续使用)
-
特殊人群使用障碍(听障用户依赖的视觉反馈不完整)
-
降低专业形象可信度(招商场景影响客户信任建立)
-
1.2.5-2 智能数智人系统优化方案
技术架构升级路径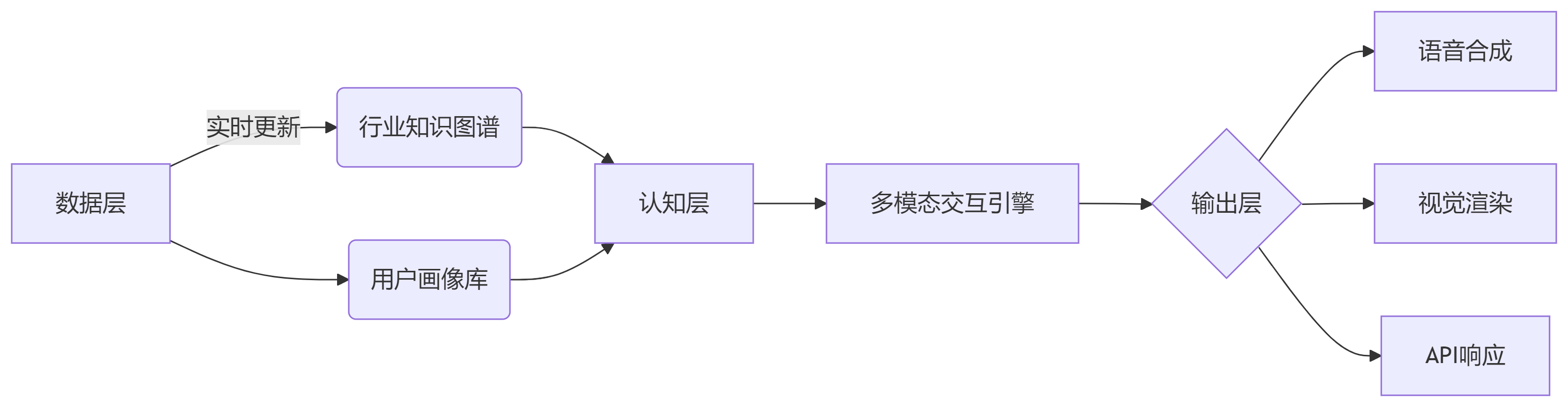
关键实施步骤
-
认知理解增强
-
构建领域自适应模型:
python
复制
下载
class DomainAdapter: def __init__(self): self.base_model = Ernie-3.0 # 千亿参数底座 self.domain_head = { 'finance': FinBERT, 'medical': PubMedBERT, 'retail': CustomCNN+LSTM } -
实施动态澄清机制:
-
对低置信度意图(auto_score<0.7)自动触发追问模板
-
关键参数采用正则校验(如身份证号、订单号规则)
-
-
-
个性化系统建设
-
用户分层服务体系:
用户等级 响应策略 专属功能 普通用户 标准流程 基础问答 VIP用户 专属通道 经理画像克隆 企业用户 定制知识库 API深度集成 -
情感计算模块:
json
复制
下载
{ "tone_adjustment": { "政务场景": {"formality": 0.9, "speed": 1.1}, "直播带货": {"enthusiasm": 1.5, "pause_duration": 0.3} } }
-
-
多模态性能优化
-
实现微秒级同步控制:
cpp
复制
下载
// 同步控制伪代码 while(frame = get_next_frame()){ audio = STT(frame.audio) gesture = CV_model(frame.video) if(sync_diff > 50ms){ adjust_clock_offset() } } -
部署边缘计算节点:
-
将3D渲染等重计算任务下沉至地方机房
-
语音识别采用流式处理(200ms分片)
-
-
-
持续学习机制
-
建立反馈闭环系统:
复制
下载
用户修正 → 差异分析 → 模型微调 → A/B测试 → 全量发布
-
异常案例自动归集:
-
对人工接管对话自动打标存入改进库
-
每日自动生成TOP10待优化场景报告
-
-
预期优化效果
| 指标 | 优化前 | 优化后目标 | 测量方式 |
|---|---|---|---|
| 意图识别准确率 | 72% | ≥93% | 千级测试用例验证 |
| 首次解决率 | 58% | ≥85% | 会话日志分析 |
| 响应延迟 | 1200ms | ≤400ms | 端到端压力测试 |
| 用户满意度(NPS) | 35 | ≥68 | 月度问卷调查 |
2.1.1智慧交通中燃油效率模型的数据清洗和标注流程设计
# 加载数据集并显示数据集的前五行 1分\n",
"file_path = 'auto-mpg.csv'\n",
"data = pd.read_csv(file_path)\n",
"print(\"数据集的前五行:\")\n",
"print(data.head())\n",
"# 显示每一列的数据类型\n",
"print(data.dtypes)\n",
"# 检查缺失值并删除缺失值所在的行 2分\n",
"print(\"\\n检查缺失值:\")\n",
"print(data.isnull().sum()) \n",
"data = data.dropna()\n",
"# 将 'horsepower' 列转换为数值类型,并处理转换中的异常值 1分\n",
"data['horsepower'] = pd.to_numeric(data['horsepower'], errors='coerce')\n",
"data = data.dropna(subset=['horsepower'])\n",
"# 显示每一列的数据类型\n",
"print(data.horsepower.dtypes)\n",
"# 检查清洗后的缺失值\n",
"print(\"\\n检查清洗后的缺失值:\")
"print(data.isnull().sum())
"from sklearn.preprocessing import StandardScaler
"# 对数值型数据进行标准化处理 1分
"numerical_features = ['displacement', 'horsepower', 'weight', 'acceleration']
"scaler = StandardScaler()\n",
"data[numerical_features] = scaler.fit_transform(data[numerical_features])\n",
"from sklearn.model_selection import train_test_split\n",
"# 选择特征和目标变量 2分\n",
selected_features = ['cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin']\n",
X = data['selected_features']
y = data['mpg']
"# 划分数据集为训练集和测试集 1分\n",
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
"# 将特征和目标变量合并到一个数据框中\n",
"cleaned_data = X.copy()\n",
"cleaned_data['mpg'] = y\n",
"# 保存清洗和处理后的数据\n",
"cleaned_data.to_csv('2.1.1_cleaned_data.csv', index=False)\n",
"# 打印消息指示文件已保存\n",
"print(\"\\n清洗后的数据已保存到 2.1.1_cleaned_data.csv\")"
2.1.2低碳生活行为影响因素数据清洗和标注流程设计
#读取一个Excel文件,并将读取到的数据存储在变量data中\n",
data = pd.read_excel('大学生低碳生活行为的影响因素数据集.xlsx')
#打印出数据集的前5行\n",
print(data.head())\n",
#处理数据集中的缺失值\n",
initial_row_count = data.shape[0]
data = data.dropna()\
final_row_count = data.shape[0]
print(f'处理后数据行数: {final_row_count}, 删除的行数: {initial_row_count - final_row_count}')
#处理重复行\n",
duplicate_count = data.duplicated().sum()
data = data.drop_duplicates()
print(f'删除的重复行数: {duplicate_count}')
data[numerical_features] = scaler.fit_transform(data[numerical_features])
X = data[selected_features]
y = data['9.您是否愿意为低碳产品支付更高的价格?']
from sklearn.model_selection import train_test_split
"# 数据划分\n",
"X_train, X_test, y_train, y_test = train_test_split
(X, y, test_size=0.2, random_state=42)\n",
"# 保存处理后的数据\n",
"cleaned_data = pd.concat([X, y], axis=1)\n",
"cleaned_data.to_csv('2.1.2_cleaned_data.csv', index=False)"
2.1.3信用评分模型数据清洗和标注流程设计
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
import pickle
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
# 加载数据集
df = pd.read_csv('fitness analysis.csv')
# 显示前五行数据
print(df.head())
# 去除所有字符串字段的前后空格
df = df.applymap(lambda x: x.strip() if isinstance(x, str) else x)
# 检查和清理列名
df.columns = df.columns.str.strip()
# 选择相关特征进行建模
X = df[['Your gender', 'How important is exercise to you ?', 'How healthy do you consider yourself?']]
X = pd.get_dummies(X) # 将分类变量转为数值变量
# 将年龄段转为数值变量
y = df['Your age'].apply(lambda x: int(x.split(' ')[0])) # 假设年龄段为整数
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 保存训练好的模型
with open('2.2.3_model.pkl', 'wb') as model_file:
pickle.dump(rf_model, model_file)
# 进行结果预测
y_pred = rf_model.predict(X_test)
results_df = pd.DataFrame(y_pred, columns=['预测结果'])
results_df.to_csv('2.2.3_results.txt', index=False)
# 使用测试工具对模型进行测试,并记录测试结果
train_score = rf_model.score(X_train, y_train)
test_score = rf_model.score(X_test, y_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
with open('2.2.3_report.txt', 'w') as report_file:
report_file.write(f' 训练集得分: {train_score}\n')
report_file.write(f' 测试集得分: {test_score}\n')
report_file.write(f' 均方误差(MSE): {mse}\n')
report_file.write(f' 决定系数(R^2): {r2}\n')
# 运用工具分析算法中错误案例产生的原因并进行纠正
# 这里以XGBoost为例进行错误案例分析
xgb_model = xgb.XGBRegressor(n_estimators=100, random_state=42)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict(X_test)
results_df_xgb = pd.DataFrame(y_pred_xgb, columns=['预测结果'])
results_df_xgb.to_csv('2.2.3_results_xgb.txt', index=False)
with open('2.2.3_report_xgb.txt', 'w') as xgb_report_file:
xgb_report_file.write(f'XGBoost 训练集得分: {xgb_model.score(X_train, y_train)}\n')
xgb_report_file.write(f'XGBoost 测试集得分: {xgb_model.score(X_test, y_test)}\n')
xgb_report_file.write(f'XGBoost 均方误差(MSE): {mean_squared_error(y_test, y_pred_xgb)}\n')
xgb_report_file.write(f'XGBoost 决定系数(R^2): {r2_score(y_test, y_pred_xgb)}\n')
2.1.4医疗研究数据清洗和标注设计
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import joblib
from xgboost import XGBRegressor
# 加载数据集
file_path = '大学生低碳生活行为的影响因素数据集.xlsx'
data = pd.read_excel(file_path)
# 显示数据集的前五行
print(data.head())
# 删除不必要的列并处理分类变量
data_cleaned = data.drop(columns=[' 序号', '所用时间'])
data_cleaned = pd.get_dummies(data_cleaned, drop_first=True)
# 定义目标变量和特征
target = '5.您进行过绿色低碳的相关生活方式吗?'
features = data_cleaned.drop(columns=[target])
# 定义自变量因变量
X = features
y = data_cleaned[target]
# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 保存训练好的模型
model_filename = '2.2.4_model.pkl'
joblib.dump(model, model_filename)
# 进行预测
y_pred = model.predict(X_test)
# 将结果保存到文本文件中
results = pd.DataFrame({'实际值': y_test, '预测值': y_pred})
results_filename = '2.2.4_results.txt'
results.to_csv(results_filename, index=False, sep='\t')
# 将测试结果保存到报告文件中
report_filename = '2.2.4_report.txt'
with open(report_filename, 'w') as f:
f.write(f' 均方误差: {mean_squared_error(y_test, y_pred)}\n')
f.write(f' 决定系数: {r2_score(y_test, y_pred)}\n')
# 分析并纠正错误(示例:使用XGBoost)
xgb_model = XGBRegressor(
n_estimators=1000,
learning_rate=0.05,
max_depth=5,
subsample=0.8,
colsample_bytree=0.8
)
xgb_model.fit(X_train, y_train)
# 使用XGBoost模型进行预测
y_pred_xg = xgb_model.predict(X_test)
# 将XGBoost结果保存到文本文件中
results_xg_filename = '2.2.4_results_xg.txt'
results_xg = pd.DataFrame({'实际值': y_test, '预测值': y_pred_xg})
results_xg.to_csv(results_xg_filename, index=False, sep='\t')
# 将XGBoost测试结果保存到报告文件中
report_filename_xgb = '2.2.4_report_xgb.txt'
with open(report_filename_xgb, 'w') as f:
f.write(f' 均方误差: {mean_squared_error(y_test, y_pred_xg)}\n')
f.write(f' 决定系数: {r2_score(y_test, y_pred_xg)}\n')
2.1.5健康与营养咨询数据预处理与数据规范设计
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
import pickle
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 加载数据集
df = pd.read_csv('fitness analysis.csv')
# 显示前五行数据
print(df.head())
# 选择相关特征进行建模
X = df
X = pd.get_dummies(X) # 将分类变量转为数值变量
# 设为目标变量
y = df['Fitness Score'] # 替换为实际的目标变量名称
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练决策树回归模型
dt_model = DecisionTreeRegressor(random_state=42)
dt_model.fit(X_train, y_train)
# 保存训练好的模型
with open('2.2.5_model.pkl', 'wb') as model_file:
pickle.dump(dt_model, model_file)
# 进行预测
y_pred = dt_model.predict(X_test)
# 将结果保存到文本文件中
results = pd.DataFrame({'实际值': y_test, '预测值': y_pred})
results_filename = '2.2.5_results.txt'
results.to_csv(results_filename, index=False, sep='\t')
# 将测试结果保存到报告文件中
report_filename = '2.2.5_report.txt'
with open(report_filename, 'w') as f:
f.write(f' 均方误差: {mean_squared_error(y_test, y_pred)}\n')
f.write(f' 平均绝对误差: {mean_absolute_error(y_test, y_pred)}\n')
f.write(f' 决定系数: {r2_score(y_test, y_pred)}\n')
2.2.1智能信用评分 Logistic 回归模型开发与测试
# 加载数据 file_path = 'finance数据集.csv' data = pd.read_csv(file_path) # 显示前五行的数据 print(data.head()) # 选择自变量和因变量 X = data.drop(['SeriousDlqin2yrs', 'Unnamed: 0'], axis=1) y = data['SeriousDlqin2yrs'] # 分割训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练Logistic回归模型 model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train) # 保存模型 with open('2.2.1_model.pkl', 'wb') as file: pickle.dump(model, file) # 预测并保存结果 y_pred = model.predict(X_test) pd.DataFrame(y_pred, columns=['预测结果']).to_csv('2.2.1_results.txt', index=False) # 生成测试报告 report = classification_report(y_test, y_pred, zero_division=1) with open('2.2.1_report.txt', 'w') as file: file.write(report) # 分析测试结果 accuracy = (y_test == y_pred).mean() print(f"模型准确率: {accuracy:.2f}") # 处理数据不平衡 smote = SMOTE(random_state=42) X_resampled, y_resampled = smote.fit_resample(X_train, y_train) # 重新训练模型 model.fit(X_resampled, y_resampled) # 重新预测 y_pred_resampled = model.predict(X_test) # 保存新结果 pd.DataFrame(y_pred_resampled, columns=['预测结果']).to_csv('2.2.1_results_xg.txt', index=False) # 生成新的测试报告 report_resampled = classification_report(y_test, y_pred_resampled, zero_division=1) with open('2.2.1_report_xg.txt', 'w') as file: file.write(report_resampled) # 分析新的测试结果 accuracy_resampled = (y_test == y_pred_resampled).mean() print(f"重新采样后的模型准确率: {accuracy_resampled:.2f}")
2.2.2智慧交通中燃油效率随机森林模型开发与测试
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import pickle
from sklearn.ensemble import RandomForestRegressor
# 加载数据集
df = pd.read_csv('auto-mpg.csv')
# 显示前五行数据
print(df.head())
# 处理缺失值
# 将 'horsepower' 列中的所有值转换为数值类型
df['horsepower'] = pd.to_numeric(df['horsepower'], errors='coerce')
# 删除包含缺失值的行
df = df.dropna()
# 选择相关特征进行建模
X = df[['cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model year', 'origin']]
y = df['mpg']
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建包含标准化和线性回归的管道
pipeline = Pipeline([
('scaler', StandardScaler()),
('linreg', LinearRegression())
])
# 训练模型
pipeline.fit(X_train, y_train)
# 保存训练好的模型
with open('2.2.2_model.pkl', 'wb') as model_file:
pickle.dump(pipeline, model_file)
# 预测并保存结果
y_pred = pipeline.predict(X_test)
results_df = pd.DataFrame(y_pred, columns=['预测结果'])
results_df.to_csv('2.2.2_results.txt', index=False)
# 测试模型
with open('2.2.2_report.txt', 'w') as results_file:
results_file.write(f'训练集得分: {pipeline.score(X_train, y_train)}\n')
results_file.write(f'测试集得分: {pipeline.score(X_test, y_test)}\n')
# 训练一个随机森林回归模型作为替代模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 使用随机森林模型进行预测
y_pred_rf = rf_model.predict(X_test)
# 保存新的结果
results_rf_df = pd.DataFrame(y_pred_rf, columns=['预测结果'])
results_rf_df.to_csv('2.2.2_results_rf.txt', index=False)
# 测试模型并保存得分
with open('2.2.2_report_rf.txt', 'w') as results_rf_file:
results_rf_file.write(f'训练集得分: {rf_model.score(X_train, y_train)}\n')
results_rf_file.write(f'测试集得分: {rf_model.score(X_test, y_test)}\n')
2.2.3日常运动量随机森林预测模型开发与测试
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
import pickle
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
# 加载数据集
df = pd.read_csv('fitness analysis.csv')
# 显示前五行数据
print(df.head())
# 去除所有字符串字段的前后空格
df = df.applymap(lambda x: x.strip() if isinstance(x, str) else x)
# 检查和清理列名
df.columns = df.columns.str.strip()
# 选择相关特征进行建模
X = df[['Your gender', 'How important is exercise to you ?', 'How healthy do you consider yourself?']]
X = pd.get_dummies(X) # 将分类变量转为数值变量
# 将年龄段转为数值变量
y = df['Your age'].apply(lambda x: int(x.split(' ')[0])) # 假设年龄段为整数
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练随机森林回归模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 保存训练好的模型
with open('2.2.3_model.pkl', 'wb') as model_file:
pickle.dump(rf_model, model_file)
# 进行结果预测
y_pred = rf_model.predict(X_test)
results_df = pd.DataFrame(y_pred, columns=['预测结果'])
results_df.to_csv('2.2.3_results.txt', index=False)
# 使用测试工具对模型进行测试,并记录测试结果
train_score = rf_model.score(X_train, y_train)
test_score = rf_model.score(X_test, y_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
with open('2.2.3_report.txt', 'w') as report_file:
report_file.write(f'训练集得分: {train_score}\n')
report_file.write(f'测试集得分: {test_score}\n')
report_file.write(f'均方误差(MSE): {mse}\n')
report_file.write(f'决定系数(R^2): {r2}\n')
# 运用工具分析算法中错误案例产生的原因并进行纠正
# 这里以XGBoost为例进行错误案例分析
xgb_model = xgb.XGBRegressor(n_estimators=100, random_state=42)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict(X_test)
results_df_xgb = pd.DataFrame(y_pred_xgb, columns=['预测结果'])
results_df_xgb.to_csv('2.2.3_results_xgb.txt', index=False)
with open('2.2.3_report_xgb.txt', 'w') as xgb_report_file:
xgb_report_file.write(f'XGBoost训练集得分: {xgb_model.score(X_train, y_train)}\n')
xgb_report_file.write(f'XGBoost测试集得分: {xgb_model.score(X_test, y_test)}\n')
xgb_report_file.write(f'XGBoost均方误差(MSE): {mean_squared_error(y_test, y_pred_xgb)}\n')
xgb_report_file.write(f'XGBoost决定系数(R^2): {r2_score(y_test, y_pred_xgb)}\n')
2.2.4低碳生活行为影响因素预测线性回归模型开发与测试
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import joblib
from xgboost import XGBRegressor
# 加载数据集
file_path = '大学生低碳生活行为的影响因素数据集.xlsx' # 替换为实际的数据集文件路径
data = pd.read_excel(file_path)
# 显示数据集的前五行
print(data.head())
# 删除不必要的列并处理分类变量
data_cleaned = data.drop(columns=['序号', '所用时间']) # 删除不必要的列
data_cleaned = pd.get_dummies(data_cleaned, drop_first=True) # 将分类变量转换为哑变量/指示变量
# 定义目标变量和特征
target = '5.您进行过绿色低碳的相关生活方式吗?' # 确保这是目标变量
features = data_cleaned.drop(columns=[target])
# 定义自变量因变量
X = features
y = data_cleaned[target]
# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 保存训练好的模型
model_filename = '2.2.4_model.pkl'
joblib.dump(model, model_filename)
# 进行预测
y_pred = model.predict(X_test)
# 将结果保存到文本文件中
results = pd.DataFrame({'实际值': y_test, '预测值': y_pred})
results_filename = '2.2.4_results.txt'
results.to_csv(results_filename, index=False, sep='\t') # 使用制表符分隔值保存到文本文件
# 将测试结果保存到报告文件中
report_filename = '2.2.4_report.txt'
with open(report_filename, 'w') as f:
f.write(f'均方误差: {mean_squared_error(y_test, y_pred)}\n')
f.write(f'决定系数: {r2_score(y_test, y_pred)}\n')
# 分析并纠正错误(示例:使用XGBoost)
# 训练XGBoost模型
xgb_model = XGBRegressor(
n_estimators=1000, # 增加树的数量
learning_rate=0.05, # 降低学习率
max_depth=5, # 调整树的深度
subsample=0.8, # 调整样本采样比例
colsample_bytree=0.8 # 调整特征采样比例
)
xgb_model.fit(X_train, y_train)
# 使用XGBoost模型进行预测
y_pred_xg = xgb_model.predict(X_test)
# 将XGBoost结果保存到文本文件中
results_xg_filename = '2.2.4_results_xg.txt'
results_xg = pd.DataFrame({'实际值': y_test, '预测值': y_pred_xg})
results_xg.to_csv(results_xg_filename, index=False, sep='\t') # 使用制表符分隔值保存到文本文件
# 将XGBoost测试结果保存到报告文件中
report_filename_xgb = '2.2.4_report_xgb.txt'
with open(report_filename_xgb, 'w') as f:
f.write(f'均方误差: {mean_squared_error(y_test, y_pred_xg)}\n')
f.write(f'决定系数: {r2_score(y_test, y_pred_xg)}\n')
2.2.5智能步数预测模型开发与测试
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
import pickle
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 加载数据集
df = pd.read_csv('fitness analysis.csv')
# 显示前五行数据
print(df.head())
# 选择相关特征进行建模
X = df[['Your gender ', 'How important is exercise to you ?', 'How healthy do you consider yourself?']]
X = pd.get_dummies(X) # 将分类变量转为数值变量
# 设为目标变量
y = df['Your age'] # 替换为实际的目标变量名称
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练决策树回归模型
dt_model = DecisionTreeRegressor(random_state=42)
dt_model.fit(X_train, y_train)
# 保存训练好的模型
with open('2.2.5_model.pkl', 'wb') as model_file:
pickle.dump(dt_model, model_file)
# 进行预测
y_pred = dt_model.predict(X_test)
# 将结果保存到文本文件中
results = pd.DataFrame({'实际值': y_test, '预测值': y_pred})
results_filename = '2.2.5_results.txt'
results.to_csv(results_filename, index=False, sep='\t')
# 将测试结果保存到报告文件中
report_filename = '2.2.5_report.txt'
with open(report_filename, 'w') as f:
f.write(f'均方误差: {mean_squared_error(y_test, y_pred)}\n')
f.write(f'平均绝对误差: {mean_absolute_error(y_test, y_pred)}\n')
f.write(f'决定系数: {r2_score(y_test, y_pred)}\n')
3.1.1智能音箱产品的数据分析与优化
- 分析报告(选择素材中的功能调用类型填写)
用户使用习惯 (用excel对数据进行筛选排序,前三项)
|
最常被使用的功能: |
调整音量 |
查询新闻 |
查天气 |
功能使用频率 (同样用excel对数据进行筛选排序,根据次数多少选择)
|
最受欢迎的功能 |
调整音量 |
|
|
较少使用的功能 |
播放音乐 |
控制家居 |
响应时间分析 (需要每次筛选一类,点击时间这一列,看底部给出的平均时间)
|
响应时间较长的功能 |
控制家居 |
||
|
响应时间适中的功能 |
播放音乐 |
设置闹钟 |
查询知识 |
|
响应时间较短的功能 |
查询新闻 |
||
- 优化方向及解决方案
优化方向1:
|
优化响应时间 |
对应解决方案1:
|
对响应时间较长的功能,可以进一步优化后台处理逻辑,提高响应速度,提升用户体验。 |
优化方向2:
|
增加个性化推荐功能 |
对应解决方案2:
|
根据用户使用功能的频率和偏好,智能音箱可以增加个性化推荐功能 |
优化方向3:
|
增强语音交互体验 |
对应解决方案3:
|
可以进一步优化语音识别和自然语言处理技术,使用户能更自然、准确的语音箱进行对话。同时,增加更多的语音指令和交互场景,也能提升实用性和趣味性。 |
3.1.2智能照明系统的数据分析与优化
- 分析报告
用户使用习惯 (通过时间段筛选,查看平均值)
|
平均光线亮度值 |
平均色温值 |
|
|
06:00 - 12:00 |
51.745 |
3689.518 |
|
12:00 - 18:00 |
48.056 |
3661.352 |
|
18:00 - 24:00 |
49.931 |
3732.403 |
智能场景使用频率
|
频繁使用的场景 |
Relax Mode |
|
|
适中使用的场景 |
Reading Mode |
Work Mode |
|
较少使用的场景 |
Sleep Mode |
|
响应时间分析
|
平均响应时间 |
1.064秒 |
|
|
延迟瓶颈 |
Relax Mode 1.115秒 可能在于系统处理放松模式特定设置(如色温、亮度调整)的效率 |
Sleep Mode 1.085秒 可能包括系统识别用户进入睡眠状态的 速度、调整照明参数的算法效率,及照明设备语控制系统之间的通信速度。 |
- 优化方向及解决方案
优化方向1:
|
提高Relax Mode和Work Mode的响应速度 |
对应解决方案1:
|
优化系统算法,针对Relax Mode和Work Mode的照明参数调整进行加速处理,减少计算延迟。 |
优化方向2:
|
降低Sleep Mode下的光线亮度波动 |
对应解决方案2:
|
通过增强传感器精度和校准算法,确保Sleep Mode下光线亮度保持稳定,避免不必要的波动。 |
优化方向3:
|
优化Reading Mode下的色温调节 |
对应解决方案3:
|
根据用户阅读习惯和阅读时间,智能调整色温值,提供更加舒适的阅读环境,同时简化色温调节流程。 |
3.1.3智能健康手环的数据分析与优化
- 分析报告 (同样运用excel筛选功能)
用户活动模式
|
用户平均步数 |
|
|
06:00 - 08:00 |
5068 |
|
17:00 - 20:00 |
4224 |
|
其余时段(步数为0时段不计入) |
1001 |
健康指标关注度
|
最受关注的指标 |
步数 |
|
|
较少关注的指标 |
心率 |
睡眠时长 |
数据同步性能
|
平均延迟时间(秒) |
0.698 |
|
|
影响因素 |
心率数据的高频连续采样 |
心率数据的高实时性 |
- 优化方向及解决方案
优化方向1:
|
优化响应时间 |
对应解决方案1:
|
推动手环硬件支持蓝牙5.0及以上版本,传感器数据采集优化。 传输协议优先级调整,动态分片策略,将心率数据拆分为高频小包传输,避免大包拥堵。 数据压缩,对心率数据压缩,减少单次传输量 |
优化方向2:
|
个性化健康管理升级 |
对应解决方案2:
|
基于用户历史数据,生成定制化健康评分体系,联动饮食/运动建议。 增加睡眠呼吸暂停风险筛选,通过多模态数据(体动、血氧)提供分级预警等。 |
优化方向3:
|
场景功能扩展 |
对应解决方案3:
|
环境自适应,根据温湿度、空气质量数据动态调整检测策略,打通医疗级数据接口,支持异常指标(如持续高心率)自动推送至医院云端平台。 |
3.1.4智能健康监测系统的数据分析与优化
- 分析报告
用户活动周期 (这题表的数据还是不会分析,答案依据课堂老师的答案pdf填写)
健康指标变化趋势:
|
收缩压:从0点到22点,基本走从高到低的下降趋势 舒张压:从0点到22点,基本走从高到低的下降趋势 血糖:从8:00am到12:00am,从13:00pm到18:00pm,从19:00pm到7:00am时段,分别走从高到低的下降趋势。 |
高风险时间段:
|
收缩压:上午7:30左右 舒张压:上午6:00左右 血糖:7:00,12:00,18:00等时间点 |
安全时间段:
|
收缩压:18点左右 舒张压:中午12点左右 血糖:9:00、14:00、20:00等时间点 |
健康指标偏好度 (根据筛选可得)
|
受用户青睐的功能 |
血压检测 |
血糖分析 |
|
较少使用的功能 |
体脂分析 |
|
注:
收缩压值、舒张压值属于血压监测功能。
血糖值属于血糖检测功能。
体脂值属于体脂分析功能。
系统响应与准确性 (跟实际做出结果对不上)
|
响应时间较长的功能 |
血糖检测 |
|
响应时间适中的功能 |
体脂分析 |
|
响应时间较短的功能 |
血压检测 |
- 优化方向及解决方案
优化方向1:
|
提升数据采集准确性和响应速度 |
对应解决方案1:
|
整合多传感器数据并通过环境感知实时校准,减少单一传感器误差,动态调整采样策略,降低误报率与响应波动。 |
优化方向2:
|
增强用户体验 |
对应解决方案2:
|
通过多模态融合减少用户操作步骤(一次测量同步获取多项指标)提升便捷性。 |
优化方向3:
|
差异化与提供离线评估 |
对应解决方案3:
|
边缘-云端协同支持离线模式下的基础健康评估(无网络时任可以提供血糖趋势预警)。 |
3.1.5智能家居环境控制系统的数据分析与优化
- 分析报告
用户环境偏好 (答案数据跟用excel得到的值不一致)
|
平均温度 |
平均湿度 |
平均光照 |
|
|
06:00 - 12:00 |
|||
|
13:00 - 18:00 |
|||
|
19:00 - 05:00 |
系统响应时间
|
平均响应时间 |
3.019 |
|
|
影响因素 |
传感器接受信息到响应需要一定的延时 |
操作的易用性,数据传输的效能等。 |
能源消耗分析
|
平均能源消耗 |
1.0209 |
|
|
节能潜力 |
在能耗高的这些时段寻找节能措施 |
优化设备使用或引入智能节能模式等。 |
- 优化方向及解决方案
优化方向1:
|
智能调度与个性化设置 |
对应解决方案1:
|
利用AI算法分析用户的使用数据,学习用户的偏好和习惯,如自动调整室内温度、湿度和光照水平至用户偏好的设定值,提升居住舒适性。 |
优化方向2:
|
设备协同与场景自动化 |
对应解决方案2:
|
通过物联网技术将设备连接起来,设置特定场景模式(如离家模式、回家模式、睡眠模式等),当触发相应场景时,自动调整相关设备状态。 |
优化方向3:
|
能源管理与节能减排 |
对应解决方案3:
|
整合分时电价策略和智能家居设备的能耗数据,在低电价时段自动启动高耗能设备的任务,如洗衣机、热水器等,同时利用智能插座监测并切断非必要设备的待机功耗。 |
3.2.1、图像识别评估系统交互流程设计
"session = onnxruntime .InferenceSession ('resnet.onnx')\n",
"image = Image.open ('img_test.jpg').convert('RGB')\n",
"processed_image = preprocess_image(image)\n",
"output = session.run([output_name], {input_name: processed_image})[0]\n",
# 应用 softmax 函数获取概率 2分\n",
"probabilities = scipy.special .softmax(output, axis=-1)\n",
"top5_idx = np._______argsort__________(probabilities[0])[-5:][::-1]\n",
"top5_prob = ______probabilities _________[0][top5_idx]\n",
3.2.2\手写数字识别系统交互流程设计
"ort_session = onnxruntime .InferenceSession (\"mnist.onnx\")\n",
"# 加载图像 2分\n",
"image = Image .open (\"img_test.png\").convert('L') # 转为灰度图\n",
"#图像预处理 4分\n",
"image = image.resize((28, 28))
"image_array = np.array image, dtype=np.float32)
"image_array = np. expand_dims (image_array, axis=0)
mage_array = np. expand_dims (image_array, axis=0)
"#使用模型对图片进行识别 2分\n",
"ort_inputs = { ort_session .get_inputs ()[0].name: image_array}\n",
"# 执行预测 2分\n",
"ort_outs = ort_session . run(None, ort_inputs)\n",
"predicted_class = np.argmax (ort_outs[0])\n",
"# 输出预测结果\n",
3.2.3面部表情识别系统交互流程设计
# 定义情感类别与数字标签的映射表 2分\n",
"emotion_table = {' neutral ':0, 'happiness
"ort_session = ort .nferenceSession ('emotion-ferplus.onnx')
"input_data =preprocess (' img_test.png ')\n",
"ort_outs = ort_session .run (None, ort_inputs)\n",
"predicted_label = np argmax ort_outs[0])\n",
"predicted_emotion = list(emotion_table .keys())[ predicted_label \n",
3.2.4花朵智能识别系统交互流程设计
"session = ort.InferenceSession('flower-detection.onnx')\n"
"with open('abels.txt) as f:\n",
"image = Image.open('flower_test.png').convert('RGB')\n",
"processed_image = preprocess_image ( image )\n",
"output = _session.run_([output_name],
"accuracy = scipy .special _.softmax(output, axis=-1)\n",
4.1.1Label studio 培训大纲编写
数据标注基础理论学习目标:掌握数据标注的概念、类型、作用、重要性 ;Label Studio简介与安装学习目标: 了解Label Studio及其应用场景、掌握其安装与配置、及基本操作;文本数据标注学习目标: 掌握文本标注的方法和技巧 ;图像数据标注学习目标: 掌握图像标注的方法和技巧 ;视频数据标注学习目标: 掌握视频标注的方法和技巧 综合项目实践学习目标:综合运用所学知识进行数据标注项目。
4.1.2爬虫培训大纲编写
网页爬虫基础理论学习目标: 了解网页爬虫概念、工作流程基本结构、作业及遵守方法
常用网页爬虫工具简介学习目标: 掌握常见网络爬虫i相关工具的使用
环境搭建与工具安装学习目标:掌握网页爬虫工具的安装和环境配置。
网页数据解析学习目标: 掌握网页数据解析原理和工具使用
Scrapy框架实战学习目标: 通过使用SCRAPY框架掌握爬虫项目的完整性操作过程
数据清洗与处理学习目标: 掌握(去重、缺失值处理、格式转换与规范化)数据清晰与处理的常见操作
4.1.3数据清洗培训大纲编写
引言学习目标: 掌握人工智能在康复训练中的应用,数据清晰在处理康复数据中 的作用
数据清洗基础理论学习目标: 了解数据清洗、常见任务及其重要性 常用数据清洗工具简介学习目标: 了解数据清晰常用工具(pandas,NUmpy,dask)环境搭建与工具安装学习目标: 掌握PYthon和pip包的配置,掌握安装和配置数据清洗工具Pandas实战学习目标: 掌握Pandas工具在数据处理方面的操作技能
4.1.4Pandas 数据清洗培训大纲编写
Pandas简介与安装学习目标: 掌握Pandas安装及数据操作技能 数据筛选与过滤学习目标: 掌握数据筛选与过滤方法、操作技能 数据转换学习目标: 掌握数据转换相关操作技能数据合并与重塑学习目标: 掌握数据合并与重塑相关操作技能 数据分组与聚合学习目标: 掌握数据分组与聚合的方法、函数和操作技能 数据可视化学习目标:综合运用所学知识进行数据清洗项目
4.1.5Python 数据可视化培训大纲编写
数据可视化基础理论学习目标: 掌握数据可视化概念、目的、以及可视化类型
Matplotlib简介与安装学习目标: 掌握 Matplotlib的概念、安装与配置
Matplotlib基本绘图学习目标: 掌握Matplotlib的基本绘图操作(创建与定制)
Plotly简介与安装学习目标: 掌握 Plotly 库的安装与配置
Plotly交互式绘图学习目标: 掌握使用Plotly库的交互式绘画技能(创建和交互等)
4.2.1智能零售分析系统数据采集和处理指导
智能零售分析系统数据采集和处理指导方案
1. 数据源确定
- 销售点(POS)数据:从收银系统获取交易记录,包括商品种类、数量、价格和购买时间。
- 顾客信息:会员卡使用数据,包括____会员编号、姓名、生日、行吧、购物习惯、偏好、购买频率等_________________。
- 库存管理系统:实时库存量、入库和出库记录。
- 顾客反馈:在线评价、投诉和建议。
- 外部数据:天气预报、节假日信息、竞争对手价格数据。
2. 数据采集方法
- API接口:与内部系统(如POS、CRM)和外部数据提供商建立API连接,自动化数据抓取。
- 传感器和物联网设备:在货架上安装RFID标签和重量传感器,监测商品存量。
- 社交媒体监听:通过社交媒体API监听品牌相关的公众讨论和评价。
- 顾客调查:定期发送电子问卷,收集顾客反馈。
3. 数据预处理
- 清洗:______处理异常值、处理缺失值、处理重复值等,保证数据的完整性和准确性_______________。
- 标准化:_____数据类型转换、归一化、离散化、编码、规范化、平滑、聚合等,保证数据一致性和可分析性________________。
- 整合:将来自不同来源的数据合并到单一数据库中,创建关联字段。
4. 数据安全与合规
- 加密传输:确保数据在传输过程中的安全。
- 访问控制:限制对敏感数据的访问权限,只允许授权人员查看。
- 匿名化处理:对个人信息进行去标识化,遵守GDPR等数据保护法规。
5. 数据存储与管理
- 云存储:选择可靠的云服务商,如AWS或Azure,存储海量数据。
- 备份与恢复:定期备份数据,并测试恢复流程,以防数据丢失。
6. 数据分析与应用
- 建模:____利用统计和机器学习算法对数据建立模型,通过训练模型来识别数据中的模式和关联__,并用于预测工作___________。
- 可视化:开发仪表板展示关键指标,帮助管理层做出决策。
- 报告:定期生成销售、库存和顾客满意度报告,提供业务洞察
4.2.2AI辅助的医疗影像诊断系统数据采集和处理指导方案
1. 数据采集方案
- 医学影像获取:确保影像质量,使用高分辨率的医疗设备获取清晰的影像资料,涵盖多种疾病类型和人群。
- 患者信息收集:在符合HIPAA等隐私保护法规的前提下,收集患者的病史、年龄、性别等基本信息,以及相关的实验室检查结果。
- _______医疗影响数据标注:__________________:邀请经验丰富的医生对影像进行标注,标记病灶位置、类型、大小等关键信息,作为训练AI模型的标注数据集。
- 数据脱敏处理:对收集的患者信息进行脱敏处理,确保患者隐私安全。
2. 数据处理方案
- 数据清洗与预处理:__包括异常值处理、缺失值处理、重复值处理_______________________。
- 模型训练与验证:_____包括选择特征和标签、划分数据集、训练模型、预测并评估模型____________________。
- 模型测试与优化:____包括加载模型、使用模型、执行预测、预测并输出预测结果、模型优化等_____________________。
- 系统集成与部署:将训练好的模型集成到医疗影像诊断系统中,部署在医院的服务器上,确保医生可以随时调用AI分析结果。
3. 数据安全与隐私保护
- 所有数据传输和存储过程都需加密,防止数据泄露。
- 遵守HIPAA等隐私法规,确保患者信息不被非法访问或滥用。
- 使用数据脱敏技术,如差分隐私,保护患者身份不被识别。
4. 系统优化与升级
- 定期收集医生和患者的反馈,评估系统性能,根据实际需求调整AI模型。
- 不断更新训练数据集,加入新的疾病类型或变异特征,提高______诊断准确率___________________。
- 跟踪AI技术的最新进展,适时引入更先进的算法,提升系统性能。
4.2.3、AI智能安防监控系统采集和处理指导方案
1. 数据采集方法
- 高清视频流采集:部署高清摄像头,确保视频画面清晰,便于AI算法识别细节。
- 多角度覆盖:合理布置摄像头,确保________监控范围_____________无死角,覆盖所有入口、出口和敏感区域。
- 夜间与低光环境适应:使用带有红外夜视功能的摄像头,保证夜间或低光条件下仍能捕捉到清晰图像。
- 数据传输与存储:采用稳定的数据传输网络,确保视频流的实时传输,同时建立安全的_____数据存储与备份机制________________,保存原始视频和分析结果。
2. 数据处理方案
- 视频流预处理:___对原始视频流进行去噪、分辨率调增、帧率优化等操作,确保视频质量满足后续分析需求,同事降低数据传输和存储压力__________________。
- 行为分析与异常检测:_____通过视频分析,及时发下并识别异常行为,并出发警告机制,提高安防响应效率________________。
- 隐私保护算法:在不影响异常行为识别的前提下,对视频中无关个体进行模糊处理,保护个人隐私。
- 数据融合与决策支持:结合多个摄像头的数据,进行空间和时间上的数据融合,构建更全面的场景理解,为安全决策提供依据。
3. 系统优化与安全措施
- 算法优化:持续训练和优化AI模型,提升__行为识别准确率和异常检查的实时性 ___________________。
- 隐私合规:确保系统设计和运营遵守GDPR、CCPA等数据保护法规,定期进行隐私影响评估。
- 安全防护:实施数据加密、访问控制和防火墙等安全措施,防止数据泄露和系统被攻击。
4.2.4自动驾驶汽车感知系统数据采集与标注指导方案
1. 数据采集方案
- 多传感器融合:__摄像头、雷达、激光雷达____________________。
- 场景覆盖:_____周围的障碍物、道路状况、交通标志_________________。
- 事件触发采集:在特定事件发生时(如紧急刹车、避让行动),自动触发额外数据采集,以捕获关键时刻。
- 数据质量控制:_____实施严格的校验流程,提出噪声和异常数据,确保数据的有效性和准确性_________________。
- 数据加密与传输:采用安全的数据传输协议,确保数据在传输过程中的安全性。
2. 数据标注方案
- 定义标注标准:明确标注类别、边界框精度要求、遮挡处理规则等。
- 选择标注工具:使用专业的数据标注软件,支持2D框、3D框、语义分割等标注类型。
- ___标注操作培训___________________:对标注员进行专业培训,确保他们理解标注标准,熟悉工具使用。
- 执行标注任务:分配数据给标注团队,设定清晰的任务指标和截止日期。
- 质量控制与复查:实施多级检查,包括自动检查和人工复查,确保标注的准确性和一致性。
- 数据整合与存储:将标注后的数据整合,形成____ 结构化、高质量且标注准确的__________________数据集,存储在安全的数据仓库中,供模型训练使用。
4.2.5智能化数据标注在文化遗产数字化保护中的应用指导方案
1. 数据标注工具与方法
- 图像标注:
- 使用______ labe1Img、VIA 或 COCOAnnotator______________________等标注工具,为文化遗产图像添加边界框、多边形、点、线段等标注。
- 对于复杂的文物细节,可以使用语义分割或实例分割技术,精细到每个物体的每一部分。
- 三维模型标注:
- 采用MeshLab或Blender等软件,对3D模型进行顶点、面、体素级别的标注。
- 实现对模型内部结构和外部特征的全面标注。
- 属性标签:
- 文物的材料、风格、时代、作者、位置等元数据,使用CSV、JSON等格式记录,并关联至相应的图像或模型。
- 可以使用数据库管理系统(如MySQL、MongoDB)来存储和管理这些信息。
2. 智能化辅助标注
- 深度学习模型:训练____具有高精度和泛化能力________________________的模型,如Mask R-CNN、U-Net等,用于自动识别和标记文物的特定特征。
- 模型训练数据集:构建一个包含大量已标注文化遗产图像的数据集,用于模型训练和验证。
- 模型迭代与优化:定期更新模型,引入新发现的文物类型和特征,提升识别精度。
3. 跨学科团队协作
- 组建由考古学家、艺术史家、计算机视觉专家、AI工程师组成的_______________多学科交叉_____________团队,共同制定标注标准和工作流程。
- 定期举行会议,讨论标注过程中的问题,调整标注策略。
4. 数据安全与隐私保护
- 使用______________加密技术______________存储和传输数据,确保文化遗产信息不被非法获取。
- 遵守相关法律法规,特别是涉及文化遗产的所有权和使用权的规定。
5. 用户体验与公众教育
- 开发Web应用或移动应用程序,允许用户在线浏览、搜索和学习文化遗产的数字化资料。
- 利用_________虚拟现实(VR)、增加现实___________________技术,为用户提供沉浸式文化遗产体验,增加教育和娱乐价值。
6. 技术融合与未来展望
- 探索区块链技术的应用,为文化遗产的数字档案提供不可篡改的记录,增强其权威性和可信度。
- 结合AI和物联网技术,监测和预警文化遗产的物理状态变化,及时采取保护措施。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)