员工考勤管理系统(SSM框架+MySQL数据库)
SSM框架,即Spring、SpringMVC和MyBatis的组合,是在企业级Java应用开发中广泛应用的三大框架。Spring负责业务对象的管理和业务逻辑的处理,SpringMVC则负责前端控制器的职责,处理前端发来的请求并返回响应,而MyBatis作为持久层框架,提供了数据库交互的抽象层。SSM框架之所以得到广泛应用,主要因为以下优势:1.解耦合:Spring通过依赖注入(DI)和面向切面编

简介:考勤打卡系统是企业管理员工上下班时间的工具,包含签到签退、请假和异常记录管理。本系统利用MySQL数据库存储考勤数据,结合SSM技术栈(Spring、SpringMVC和MyBatis)实现基本的CRUD操作和关键词搜索功能。系统版本3.3.2优化了与MySQL的交互,提升了数据存取的效率和准确性。 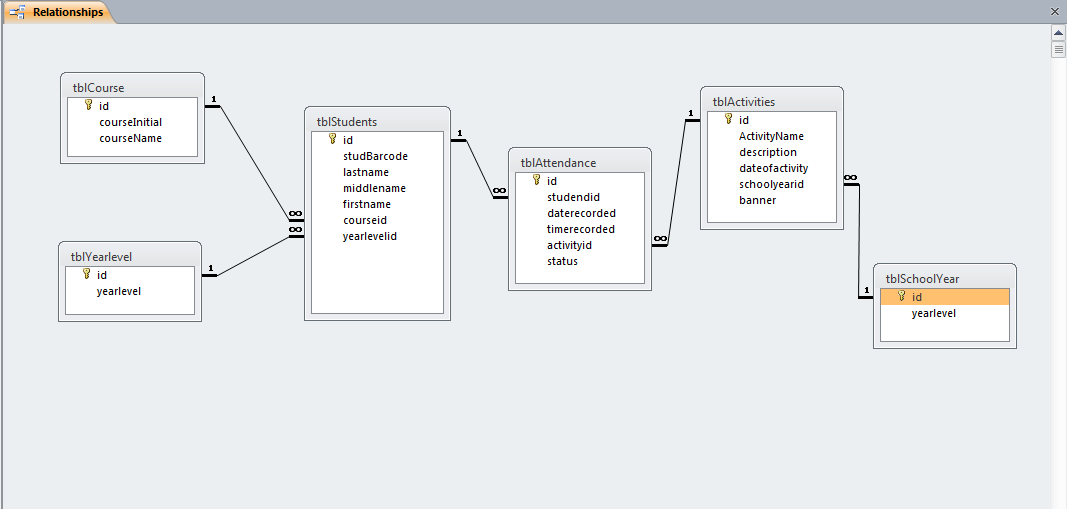
1. 员工考勤打卡系统概念
1.1 系统的基本概念
员工考勤打卡系统是现代企业日常管理中不可或缺的一部分,旨在记录员工上下班时间和出勤情况。它不仅确保了企业人力资源数据的准确性,也帮助管理层制定更合理的工作计划和评估员工绩效。
1.2 系统的重要性
良好的考勤制度不仅关系到企业的日常运营,还能提升员工的工作效率和企业的文化氛围。它通过自动化的记录和分析,减少了人力资源的管理成本,并且促进了企业内部的公平性。
1.3 系统的发展历程
从最初的纸质考勤卡到如今的数字化考勤系统,考勤打卡系统已经历了多次技术革新。随着技术的发展,系统也逐渐引入了面部识别、指纹识别等生物识别技术,提高了考勤的准确性和便捷性。在未来,考勤系统可能会与人工智能、大数据等前沿技术融合,进一步提升其智能化水平。
2. MySQL数据库在考勤系统中的应用
2.1 数据库基础知识
2.1.1 数据库的作用和特点
数据库是现代信息系统的核心组件之一,它为应用程序提供数据的持久化存储、高效的数据检索以及灵活的数据管理功能。与传统的文件系统相比,数据库具有以下特点:
- 持久化存储: 数据库将数据存储在磁盘或其他非易失性存储设备上,即使在系统故障或断电后,数据也不会丢失。
- 数据结构化: 数据库存储的数据是结构化的,通常是表格形式,便于维护和查询。
- 数据一致性: 数据库系统提供了事务管理机制,确保数据的完整性不受并发操作的影响。
- 数据安全性: 数据库提供了多层次的安全机制,如用户权限管理、数据加密等,以保护数据安全。
- 高效的数据检索: 通过索引、查询优化等技术,数据库能够高效地检索出所需数据。
- 数据共享: 多个应用程序或多个用户可以共享同一数据库,实现数据的集中管理和访问。
2.1.2 MySQL的安装和配置
MySQL是一种流行的开源关系型数据库管理系统,以其高性能、高可靠性和易用性受到广泛欢迎。安装MySQL的步骤通常包括以下几方面:
- 下载与安装: 访问MySQL官网下载适合当前操作系统版本的安装包,然后按照安装向导完成安装过程。
- 配置文件修改: 根据需求修改MySQL的配置文件(如
my.cnf或my.ini),调整数据库的性能参数,如连接数、缓存大小等。 - 启动数据库服务: 安装完成后,需要启动MySQL服务,确保数据库系统随时待命。
- 安全配置: 对MySQL进行安全配置,包括设置root用户密码、删除匿名账户和测试数据库等。
- 远程访问设置: 根据需要配置允许远程访问的IP地址,并确保网络连接的安全性。
# 示例:MySQL安装和配置的bash命令片段
sudo apt-get update
sudo apt-get install mysql-server
sudo mysql_secure_installation
sudo mysql -u root -p
2.2 数据库的设计原理
2.2.1 数据库设计的三大范式
数据库设计的目的是为了减少数据冗余,提高数据的一致性和完整性。设计数据库时通常遵循三大范式:
- 第一范式(1NF): 要求数据表的每一列都是不可分割的基本数据项,即列的原子性。
- 第二范式(2NF): 在第一范式的基础上,要求数据表中的所有非主属性完全依赖于主键。即不存在部分依赖。
- 第三范式(3NF): 在第二范式的基础上,要求数据表中的所有非主属性不依赖于其他非主属性,即不存在传递依赖。
遵循这些范式,有助于构建一个结构良好、扩展性和维护性更强的数据库系统。
2.2.2 实体关系图(ER图)的绘制和应用
实体关系图(ER图)是用来描述现实世界中实体之间关系的图形化工具。它由实体、属性和关系构成,是数据库设计的重要环节。
- 实体(Entity): 代表现实世界中的一个对象,如员工、考勤记录等。
- 属性(Attribute): 描述实体的特征,如员工的姓名、工号等。
- 关系(Relationship): 描述实体之间的联系,如员工和考勤记录之间的关联。
绘制ER图有助于理清业务逻辑,为创建数据库表提供基础架构。使用ER图工具可以直观地展示实体之间的关系,并有助于团队成员之间的沟通。
2.3 MySQL在考勤系统中的角色
2.3.1 数据表结构设计
考勤系统中涉及的数据表结构设计应考虑考勤记录、员工信息、部门信息等多种因素。一个基本的数据表结构设计可能包括以下表:
- 员工表(Employees): 存储员工的基本信息,如员工ID、姓名、部门ID等。
- 考勤记录表(Attendance): 存储考勤的具体信息,如日期、时间、出勤状态等。
- 部门表(Departments): 存储部门的相关信息,如部门ID、部门名称、部门领导等。
CREATE TABLE Employees (
employee_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100),
department_id INT
);
CREATE TABLE Departments (
department_id INT PRIMARY KEY AUTO_INCREMENT,
department_name VARCHAR(100),
manager_id INT
);
CREATE TABLE Attendance (
attendance_id INT PRIMARY KEY AUTO_INCREMENT,
employee_id INT,
date DATE,
status VARCHAR(20),
FOREIGN KEY (employee_id) REFERENCES Employees(employee_id)
);
2.3.2 数据库操作的需求分析
在设计考勤系统时,需要对数据库操作进行详细的需求分析。这包括:
- 录入考勤数据: 考勤记录的创建和插入。
- 查询考勤记录: 员工、部门或日期范围的考勤查询。
- 修改考勤信息: 修改或删除已存在的考勤记录。
- 统计和报告: 生成考勤统计报告和分析数据。
需求分析是考勤系统数据库设计的关键步骤,直接影响到数据表结构的构建和数据库操作的具体实现。通过需求分析,可以确定系统的主要功能以及对数据的访问模式。
graph LR
A[考勤系统用户] -->|录入| B[录入考勤数据]
A -->|查询| C[查询考勤记录]
A -->|修改| D[修改考勤信息]
A -->|统计| E[生成考勤统计报告]
通过本章节的介绍,我们了解了数据库的基础知识,包括其作用、特点以及安装配置方法。同时,我们探讨了数据库设计原理中的三大范式和ER图的应用,为考勤系统的数据表结构设计和需求分析打下了基础。接下来的章节,我们将进一步深入到CRUD操作实现的细节,并探讨如何使用MySQL来满足考勤系统中的数据处理需求。
3. CRU(Create、Read、Update)操作实现
3.1 创建(C)操作:录入考勤数据
在任何考勤系统中,能够准确地录入员工的考勤信息至关重要。创建操作是这一流程的开始,它确保数据的及时性和准确性。我们通过编写SQL语句来实现考勤数据的录入。
3.1.1 SQL插入语句的编写
首先,我们需要了解如何使用SQL的INSERT语句来插入数据。基本的INSERT语句非常简单,但要注意确保数据类型和插入的数据匹配,并且不会违反任何数据完整性约束。
INSERT INTO attendance (employee_id, date, time_in, time_out, status)
VALUES (1234, '2023-04-01', '08:30:00', '17:30:00', 'present');
在上述例子中,我们假设已经有一个名为 attendance 的表,该表具有五个字段: employee_id 、 date 、 time_in 、 time_out 和 status 。其中, employee_id 对应员工的ID, date 是考勤的日期, time_in 和 time_out 是员工上下班的时间, status 表示考勤状态。
3.1.2 数据校验和异常处理机制
为了确保数据的准确性,我们需要对输入数据进行校验。这包括检查员工ID是否有效、时间格式是否正确以及考勤状态是否合适。例如,考勤时间不应早于工作开始时间或晚于工作结束时间,考勤状态必须是预定义的值之一,如"present"、"absent"或"late"。
对于异常处理,我们可以利用SQL的事务特性来确保数据的一致性和完整性。如果在插入过程中出现任何错误,如违反了唯一性约束或数据类型错误,事务将回滚,保证不会留下无效数据。
BEGIN TRANSACTION;
INSERT INTO attendance ...
IF 插入成功 THEN
COMMIT TRANSACTION;
ELSE
ROLLBACK TRANSACTION;
END IF;
通过事务管理,我们可以确保数据的一致性,即使在多用户环境中也不会出现数据覆盖或者冲突的问题。
3.2 读取(R)操作:查询考勤记录
读取操作涉及到从数据库中检索考勤记录。这通常是系统中最频繁的操作,因此,执行效率至关重要。
3.2.1 SQL查询语句的优化技巧
为了优化查询性能,我们可以采取多种策略。首先,确保正确使用索引。索引能够加快查询速度,尤其是在大表中查找特定记录时。例如,如果经常按员工ID查询考勤记录,应在 employee_id 列上创建索引。
CREATE INDEX idx_employee_id ON attendance(employee_id);
其次,可以优化查询语句本身,避免使用SELECT *,只选择需要的列。同时,合理使用WHERE子句来缩小查询结果范围。
SELECT employee_id, date, time_in, time_out, status
FROM attendance
WHERE employee_id = 1234 AND date BETWEEN '2023-04-01' AND '2023-04-30';
3.2.2 复杂查询案例解析
在某些情况下,可能需要进行更复杂的查询,比如查询某个时间段内所有员工的考勤记录。此时,我们可能需要使用GROUP BY和ORDER BY子句来对结果进行分组和排序。
SELECT employee_id, date, COUNT(*) AS total_days
FROM attendance
WHERE date BETWEEN '2023-04-01' AND '2023-04-30'
GROUP BY employee_id, date
ORDER BY employee_id, date;
这个查询结果将显示每个员工在指定月份内的考勤天数。通过使用聚合函数COUNT()和GROUP BY子句,我们可以轻松地汇总和分析数据。
3.3 更新(U)操作:修改考勤信息
更新操作允许我们更改已存在的考勤记录。在考勤系统中,这种操作通常用于修改员工的状态,比如将缺勤改为出勤或迟到。
3.3.1 SQL更新语句的使用场景
最常用的更新操作是更改考勤记录的状态字段。例如,如果员工当天迟到了,我们可能需要更新其考勤记录以反映这一变化。
UPDATE attendance
SET status = 'late'
WHERE employee_id = 1234 AND date = '2023-04-01' AND time_in > '09:00:00';
在这个例子中,只有当记录匹配所有指定的条件时, status 字段才会更新为 late 。使用适当的WHERE子句非常重要,以防止不正确的记录被更新。
3.3.2 更新操作中的事务管理
更新操作涉及修改数据,因此事务管理变得尤其重要。所有更新操作都应该在事务的上下文中执行,以便在出现错误时能够回滚更改。
START TRANSACTION;
UPDATE attendance ...
IF 更新成功 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
通过这种方式,我们可以确保在并发环境下对数据的修改不会导致数据损坏,同时也维护了数据的一致性。
在下一章节中,我们将探讨如何通过关键词查询功能来实现更为高级的搜索需求,从而提升系统的数据检索能力。
4. 关键词查询功能
在考勤系统中,关键词查询功能是至关重要的,它能够帮助管理人员快速定位特定员工的考勤记录。本章节将深入探讨查询功能的设计与实现,查询性能的优化,以及在特定场景下的高级查询技术。
4.1 查询功能的设计与实现
4.1.1 关键词搜索需求分析
关键词搜索是指用户通过输入一个或多个关键词,系统会根据这些关键词返回相关的数据结果。在考勤系统中,一个典型的关键词搜索可能涉及员工的姓名、工号、部门等信息。需求分析的首要步骤是确定搜索功能的范围和限制,例如,搜索是否区分大小写,是否支持通配符和模糊搜索,以及搜索结果是否需要排序等。
4.1.2 SQL模糊查询的使用
在实现关键词查询时,我们主要使用SQL中的 LIKE 语句进行模糊匹配。例如,如果我们想要搜索所有姓“张”的员工,我们可以编写如下SQL语句:
SELECT * FROM employees WHERE name LIKE '张%';
在 LIKE 语句中, % 代表任意数量的字符,而 _ 代表单个字符。这样我们就可以构造各种模糊匹配的查询。
-- 查询名字中包含"华"的所有员工
SELECT * FROM employees WHERE name LIKE '%华%';
4.2 查询性能的优化
4.2.1 索引的创建和优化
为了提高关键词查询的效率,合理地使用数据库索引是非常关键的。索引能够加快数据检索的速度,尤其是在大数据集上进行查询时。在创建索引之前,需要考虑以下几点:
- 索引的列应该是经常用于查询条件的列。
- 多列索引的顺序应该根据查询条件中列的出现频率来决定。
- 索引不应该过度,因为索引会增加写操作的负担并占用额外的存储空间。
索引创建的示例:
CREATE INDEX idx_name ON employees(name);
4.2.2 查询缓存的应用
查询缓存是另一种提高查询效率的方法,它能够在不改变数据的情况下缓存查询结果,以便于后续相同查询的快速响应。在MySQL中,可以通过设置query_cache_size来启用查询缓存,并通过query_cache_type来控制缓存的行为。
SET GLOBAL query_cache_type = 1;
SET GLOBAL query_cache_size = 16M;
缓存策略通常需要根据实际的查询模式和数据变化频率来定制。需要注意的是,当数据库的数据发生更新时,相关缓存会被自动清除。
4.3 高级查询技术
4.3.1 组合查询与联合查询
在复杂的查询场景中,我们可能需要结合多个条件进行搜索,这可以通过使用 AND 、 OR 和 NOT 等逻辑运算符来实现组合查询。
SELECT * FROM employees WHERE department = '财务部' AND (name LIKE '%华%' OR name LIKE '%明%');
联合查询(JOIN)通常用于将多个表中的数据合并在一起,以便于执行更为复杂的查询。
4.3.2 分布式数据库中的关键词查询
在分布式数据库系统中,关键词查询可能会跨越多个节点进行,此时查询优化变得更加复杂。分布式查询通常需要考虑数据分片策略、跨节点通信成本以及分布式事务的处理。
一种策略是使用分布式数据库自带的查询优化器,它们能够自动选择最优的查询计划。如果系统允许,还可以采用中间件或者搜索引擎,如Elasticsearch,来处理复杂的分布式查询。
在本章节中,我们从关键词查询的设计与实现,到查询性能的优化,再到在分布式数据库场景下的高级查询技术进行了深入探讨。通过这些方法和策略的实施,可以大大提高考勤系统的数据检索效率,从而为管理人员提供更为准确和快速的数据服务。在下一章节,我们将继续探索考勤系统的其他关键技术组件和实施细节。
5. SSM框架(Spring、SpringMVC、MyBatis)介绍
5.1 SSM框架的概述
5.1.1 框架的组成和优势
SSM框架,即Spring、SpringMVC和MyBatis的组合,是在企业级Java应用开发中广泛应用的三大框架。Spring负责业务对象的管理和业务逻辑的处理,SpringMVC则负责前端控制器的职责,处理前端发来的请求并返回响应,而MyBatis作为持久层框架,提供了数据库交互的抽象层。
SSM框架之所以得到广泛应用,主要因为以下优势: 1. 解耦合 :Spring通过依赖注入(DI)和面向切面编程(AOP)显著降低了业务组件之间的耦合度。 2. 声明式事务管理 :Spring的声明式事务支持使得事务管理与业务代码分离,简化了事务处理。 3. 灵活的MVC设计 :SpringMVC允许开发者自定义视图解析器和各种处理器,提供了灵活的请求处理机制。 4. ORM框架的集成 :MyBatis与传统的JDBC相比,简化了代码并且提供了XML和注解两种方式配置SQL,使得数据库交互更高效、更直观。
5.1.2 企业级应用的适用场景
SSM框架特别适用于对业务逻辑和数据交互要求较高的企业级应用开发。例如,在员工考勤打卡系统中,需要处理大量复杂的业务逻辑,同时频繁与数据库交互,使用SSM框架可以有效地组织和管理代码。
SSM框架在以下场景中尤为合适: - 大型企业应用 :需要管理复杂业务流程的应用,可以借助Spring强大的事务管理功能。 - Web应用开发 :通过SpringMVC,可以快速构建MVC架构的Web应用。 - 数据库操作频繁 :MyBatis对数据库操作进行了封装,使得开发人员可以更专注于业务逻辑的实现,同时提高代码的可读性和维护性。
5.2 框架中的关键组件解析
5.2.1 Spring的核心原理
Spring框架的核心是依赖注入(DI)和面向切面编程(AOP)。依赖注入是通过容器管理对象之间的依赖关系,实现对象创建和依赖关系的管理;而AOP允许将横切关注点(如日志记录、事务管理等)与业务逻辑分离。
5.2.2 SpringMVC的工作流程
SpringMVC的工作流程主要包含以下步骤: 1. 前端请求 :用户通过浏览器发起请求。 2. DispatcherServlet拦截 :SpringMVC的核心控制器DispatcherServlet接收到请求后,根据HandlerMapping找到相应的Controller。 3. Controller处理请求 :Controller执行具体的业务逻辑,并返回ModelAndResult对象。 4. 视图解析 :视图解析器根据ModelAndResult中的信息,找到对应的视图。 5. 响应返回 :DispatcherServlet将数据填充到视图,并将最终结果返回给用户。
5.2.3 MyBatis的ORM机制
MyBatis是一个半自动化的ORM框架,提供了对象关系映射功能。它允许开发者通过XML或注解的方式,将数据库表映射为Java对象。MyBatis的核心是SqlSessionFactory和SqlSession,分别用于管理数据库连接和执行SQL语句。
5.3 SSM集成实践
5.3.1 SSM框架整合步骤
SSM框架的整合步骤如下: 1. 配置Spring :通过applicationContext.xml配置数据源、事务管理器和业务对象。 2. 配置SpringMVC :通过springmvc-servlet.xml配置视图解析器、静态资源处理等。 3. 配置MyBatis :在mybatis-config.xml中配置别名、类型处理器等,并在mapper.xml中配置SQL语句。 4. 整合配置文件 :确保所有的配置文件相互协调,完成整合。
5.3.2 实例:考勤系统中的SSM应用
在考勤系统中,SSM框架的集成使用可简化开发流程。例如,使用Spring管理业务逻辑和事务,SpringMVC处理请求和响应,MyBatis进行数据库操作。下面是一个简单的代码示例:
// Controller层
@Controller
public class AttendanceController {
@Autowired
private AttendanceService attendanceService;
@RequestMapping(value = "/logAttendance", method = RequestMethod.POST)
public String logAttendance(@ModelAttribute("attendanceForm") AttendanceForm form, Model model) {
boolean result = attendanceService.recordAttendance(form);
if(result) {
model.addAttribute("message", "Attendance recorded successfully!");
} else {
model.addAttribute("message", "Failed to record attendance!");
}
return "attendanceResult";
}
}
// Service层
@Service
public class AttendanceServiceImpl implements AttendanceService {
@Autowired
private AttendanceMapper attendanceMapper;
@Override
public boolean recordAttendance(AttendanceForm form) {
Attendance attendance = new Attendance();
// 将表单数据映射到Attendance对象...
return attendanceMapper.insertSelective(attendance) > 0;
}
}
// Mapper层
public interface AttendanceMapper {
int insertSelective(Attendance record);
}
// Mapper.xml
<mapper namespace="com.example.mapper.AttendanceMapper">
<insert id="insertSelective" parameterType="com.example.model.Attendance">
INSERT INTO attendance (employee_id, date, in_time, out_time)
VALUES (#{employeeId}, #{date}, #{inTime}, #{outTime})
</insert>
</mapper>
此示例展示了通过SSM框架组织代码的方式:Controller处理用户请求,Service层负责业务逻辑,而Mapper层则通过MyBatis与数据库进行交云。
以上章节内容,我们已经由浅入深地探讨了SSM框架的概念、关键组件以及集成实践,并通过实例代码展示了框架在实际应用中的运用。在了解了SSM框架之后,开发者可以更有效地利用这些工具进行企业级应用的开发和优化。
6. 数据库交互优化与系统版本3.3.2
在前几章节中,我们详细探讨了考勤打卡系统的核心功能以及相关技术实现。在本章节中,我们将集中讨论数据库交互优化的方法,以及系统版本3.3.2带来的变化和升级策略。
6.1 数据库性能调优策略
随着系统使用频率的增加,数据库性能优化变得至关重要。以下是进行数据库性能调优的一些关键点。
6.1.1 SQL语句的优化
在进行SQL语句优化时,首先应确保查询语句尽可能高效。使用 EXPLAIN 关键字来分析SQL执行计划可以帮助我们理解数据库是如何执行查询的,并找出潜在的性能瓶颈。例如:
EXPLAIN SELECT * FROM attendance WHERE date >= '2023-01-01' AND date <= '2023-01-31';
优化技巧包括但不限于:
- 尽量避免在WHERE子句中使用函数或表达式,因为它会阻止索引的使用。
- 使用连接(JOIN)代替子查询,可以减少查询的复杂度和执行时间。
- 合理使用索引,确保常用作查询条件的列上有索引。
6.1.2 数据库结构和索引优化
在数据库结构层面,可以优化数据表的设计,例如:
- 规范化数据表以减少数据冗余。
- 使用合适的字段类型以减少存储空间和提高查询效率。
对于索引的优化,需要定期评估和调整索引,以适应数据的变化和查询模式。此外,可以使用多列索引(复合索引),针对多个列进行优化,例如:
CREATE INDEX idx_employee_date ON attendance(employee_id, date);
这为 employee_id 和 date 的查询提供了性能优化。
6.2 系统升级与维护
系统升级和维护是确保考勤打卡系统长期稳定运行的关键。在升级过程中,需要细致规划,遵循最佳实践。
6.2.1 从旧版本到3.3.2的升级路径
在升级到新版本时,需要考虑以下步骤:
- 备份旧版本数据,防止升级过程中数据丢失。
- 检查新版本的依赖项是否与旧版本兼容。
- 按照官方发布的升级指南逐步进行升级操作。
- 升级后进行详尽的测试,确保所有功能正常运行。
6.2.2 版本维护的最佳实践
维护一个系统不仅限于更新软件版本,还包括日常的监控和优化。以下是一些最佳实践:
- 定期检查系统日志,分析错误和异常。
- 定期进行数据库的备份和清理工作。
- 根据用户反馈和系统性能指标进行必要的调整。
6.3 未来展望与技术趋势
随着技术的不断发展,考勤系统也需要不断适应新的技术趋势。
6.3.1 考勤系统的技术发展趋势
随着人工智能(AI)、机器学习(ML)和大数据技术的进步,未来的考勤系统可能会包含如下功能:
- 利用AI进行人脸识别和行为分析,提高考勤的准确性。
- 通过大数据分析员工的工作模式,优化人力资源管理。
6.3.2 云服务与大数据在考勤系统中的应用预览
云服务和大数据技术为考勤系统带来的优势包括:
- 灵活性:无需大量硬件投资,可通过云服务轻松扩展。
- 数据洞察:大数据技术可以分析考勤数据,帮助企业做出更好的决策。
小结
数据库交互优化是考勤打卡系统中一个至关重要的环节。合理的优化策略能够提升系统性能,并确保数据的准确性和稳定性。随着技术的发展,考勤系统的未来将更加智能化,大数据和云计算将为考勤系统带来更多的可能性。
简介:考勤打卡系统是企业管理员工上下班时间的工具,包含签到签退、请假和异常记录管理。本系统利用MySQL数据库存储考勤数据,结合SSM技术栈(Spring、SpringMVC和MyBatis)实现基本的CRUD操作和关键词搜索功能。系统版本3.3.2优化了与MySQL的交互,提升了数据存取的效率和准确性。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)