计算机体系结构之单周期MIPS处理器的设计
本文介绍了MIPS指令在单周期处理器中的执行过程,分为五个阶段:取指令(IF)、译码与读寄存器(ID)、运算(EX)、访存与分支(MEM)和写回(WB)。每条指令在单周期内完成,CPI为1,但时钟周期受限于最长执行时间的指令(如lw)。文章详细解析了各阶段的数据通路部件,包括组合逻辑(加法器、ALU等)和存储部件(寄存器堆、存储器等),并阐述了控制单元如何通过ALUOp信号协调ALU完成不同运算。
文章目录
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
提示:这里可以添加本文要记录的大概内容:
参考:
川大:
一、引言
在电路中时钟规定了什么时候可以从存储单元中读数据和什么时候可以将数据写入存储单元。一般包括电平触发和边沿触发:
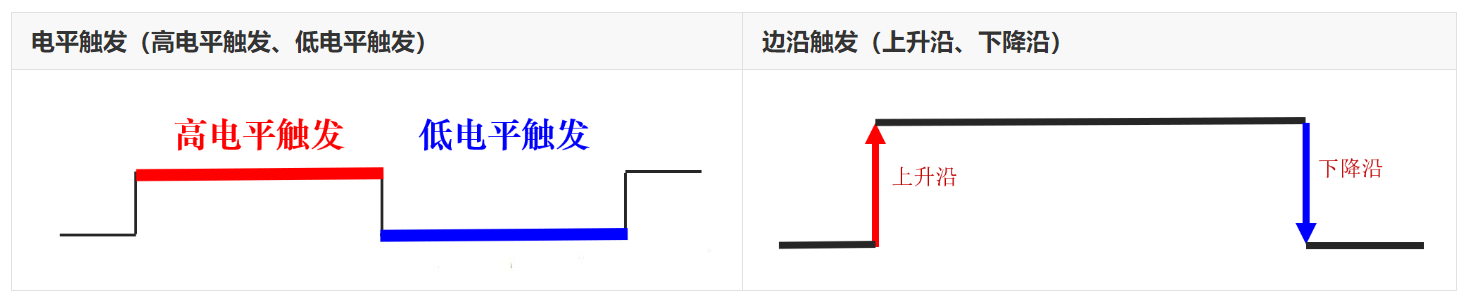
因此时序的安排对硬件逻辑设计很关键,如下图所示。
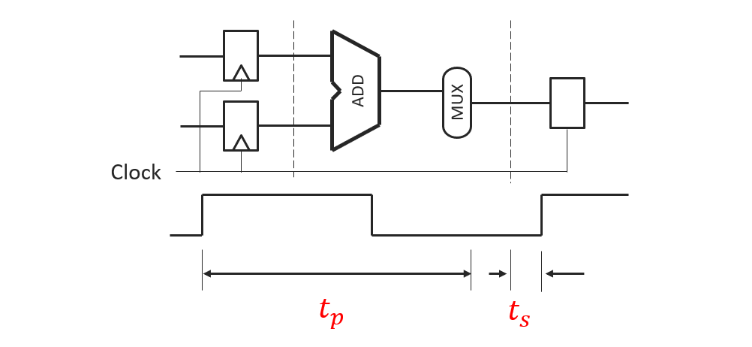
时钟周期应该满足如下关系:
t C l o c k = t p + t s l a c k + t s t_{Clock}=t_p+t_slack+t_s tClock=tp+tslack+ts
- t Clock t_{\text{Clock}} tClock 是时钟周期
- t p t_p tp 是传播延迟(Propagation Delay),即信号在电路中传播所需的时间
- t slack t_{\text{slack}} tslack是松弛时间,通常用于描述电路的时间裕量
- t s t_s ts 是建立时间(Setup Time),指在时钟上升沿前,输入信号必须稳定的时间
约束条件:
t Clock ≥ t p + t s t_{\text{Clock}} \geq t_p + t_s tClock≥tp+ts
这个条件表明,为了确保电路能够正确工作,时钟周期必须大于等于传播延迟加上建立时间。在设计时,必须选择合适的时钟频率,保证 t Clock t_{\text{Clock}} tClock满足上述约束条件。如果时钟频率过高,则可能会导致传播延迟和建立时间不满足要求,进而引发信号错误。
指令的执行步骤:
- 取指令:根据PC寄存器的值取出要执行的指令,然后PC 内容加4
- 取操作数:根据指令中操作数字段,选择读取1或2寄存器、或立即数送ALU(运算器)
- 分析指令:将指令中的操作码送控制器,分析指令的功能,产生相应的控制信号
- 执行指令:ALU根据控制器产生的控制信号完成指令规定的操作
MIPS指令非常规整,分3类:存储访问(sw、lw)、算术逻辑(add、sub等:操作均为寄存器;addi等:有一个操作数为立即数)、分支(beq、j)。
数据路径部件
1.组合逻辑部件:加法器、ALU、多路选择器MUX、符号扩展器。
2.存储部件:寄存器、寄存器堆、存储器。
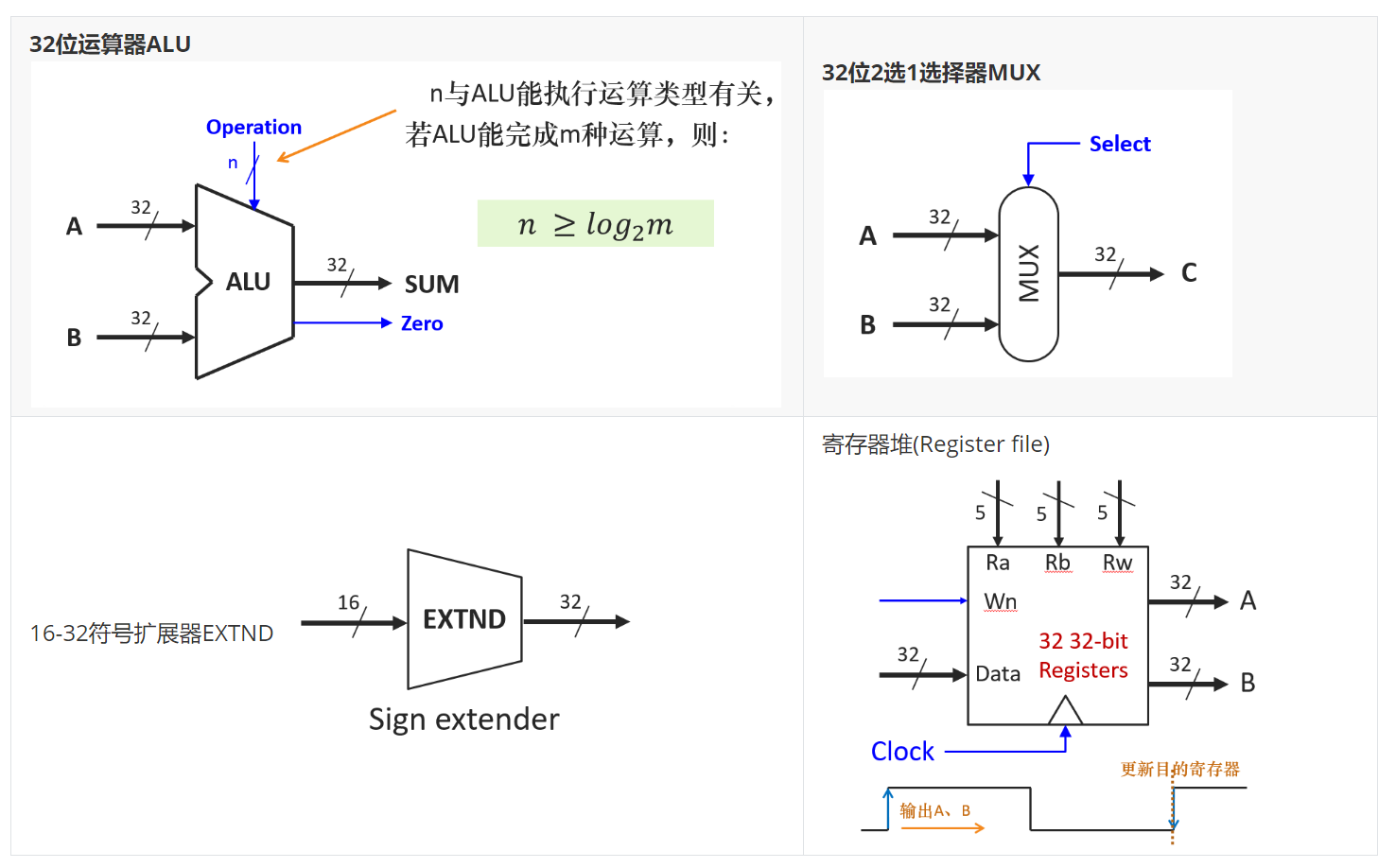
对于符号扩展器,其方法是设符号位为S,S∈{0,1},在原数前加16个S,构成32位数。
-
正数 0110010100001100 —> 0000000000000000 0110010100001100
-
负数 1110010100001100 —> 1111111111111111 1110010100001100
对于数据通路中的存储部件—寄存器堆(Register file),其有2个输出A、B和做最多2个读入Ra、Rb(R指令2个,访存指令1个,分支指令2个),A输出由Ra给出地址,B输出由Rb给出地址。RW或者Rb作为写入目的寄存器。
还有1个写端口(时序逻辑),写使能Wn=1时,当时钟边沿到来时,将Data端口送来的数据写入Rw指定的寄存器。在时钟的上升沿AB输出Ra和Rb,然后再下降沿时将Data的数据写入Rw中的寄存器,Data可能是由AB地址中的数据进行ALU得到的。
二、MIPS指令单周期五阶段
一条MIPS指令的执行分为五个阶段,统称为一个指令周期(instruction cycle)
①IF取指令:根据PC所给地址,从存储器中取出指令
②ID译码与读寄存器:分析指令字段,同时读取一个或两个寄存器
③EX运算:ALU运算:R型指令的结果 / 访存指令的地址 / beq两源操作数是否相等
④MEM访存与分支:访存指令向存储器进行读写,同时分支指令完成分支
⑤WB写回:将结果送回某寄存器
3.1取指令周期IF
IF取指令:根据PC所给地址,从存储器中取出指令。将存储器中的指令和数据分别看待,由此形成指令存储器和数据存储器。
-
指令存储器存放程序的指令,输入一个地址时输出其指向的指令 -
程序计数器(PC)保存当前指令的地址
将一个ALU完全用作加法器(Add),用来计算PC+4,即下一条指令的地址。
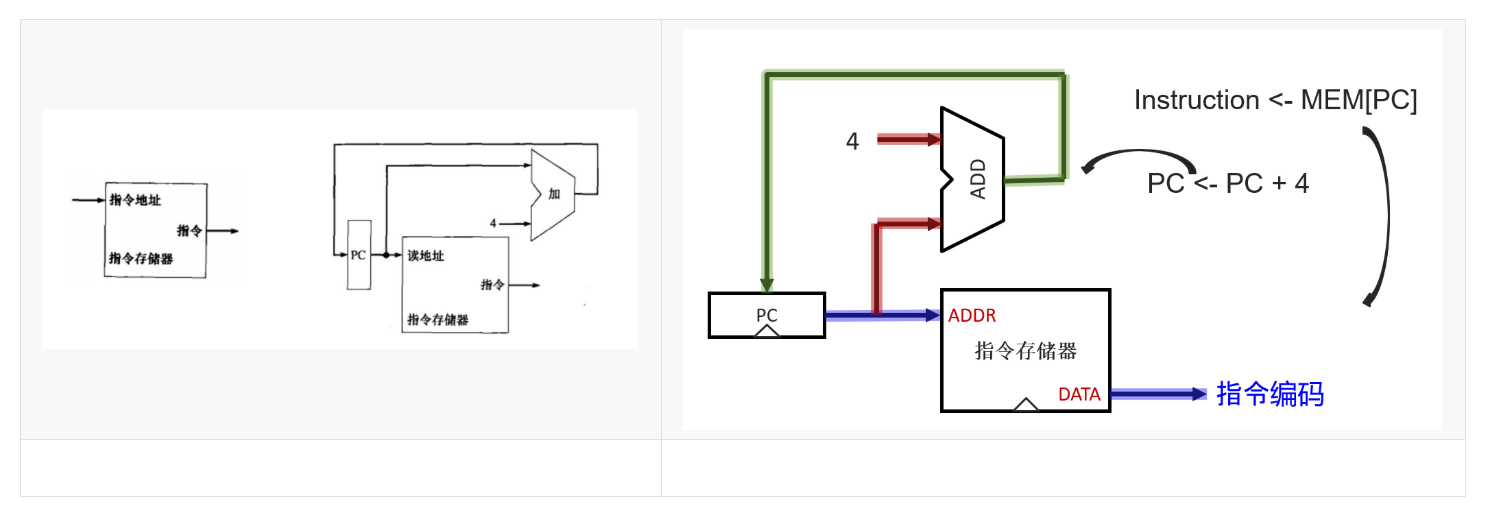
先从PC寄存器中开始执行,从指令存储器中取指,并且PC=PC+4,在下一个时钟上升沿写入PC对PC进行更新。
3.2译码与读寄存器周期ID
ID译码与读寄存器:分析指令字段,并同时读取一个或两个寄存器。
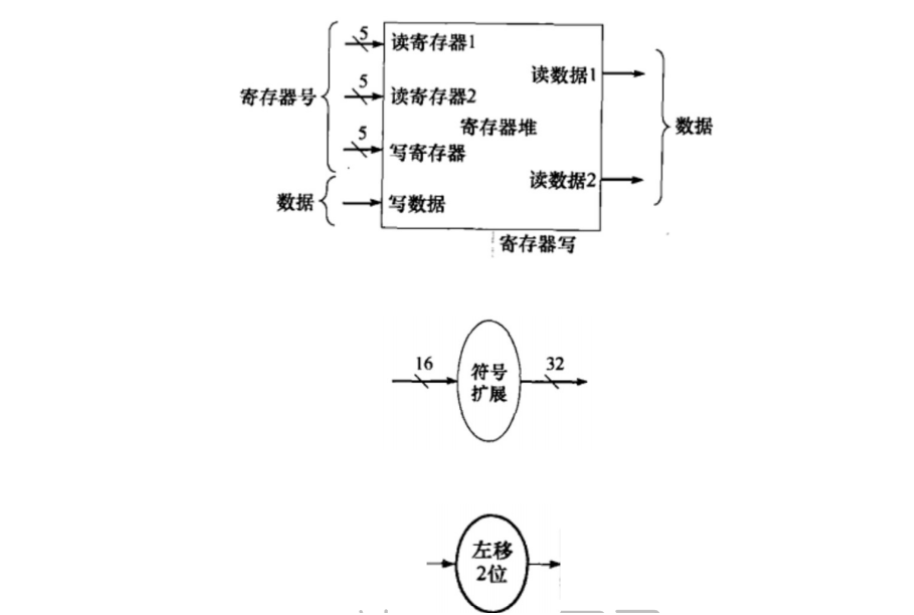
寄存器堆(reg file)含有32个通用寄存器,对应R型指令的三操作数格式,寄存器堆接收3个寄存器编号,其中至多两个寄存器用于读(R型和beq读两个,sw读一个),至多一个寄存器用于写(R型写回rd、lw写回rt)。读取时输出rs和rt寄存器中的数据。为了支持写入数据,需要一个32位的写数据端口作为输入。
访存指令中的16位偏移量(立即数)和beq中的相对地址,需要经符号扩展(sign-extend)逻辑扩充到32位。
-
对访存指令,立即数和rs中的基地址相加
-
对beq指令,需要一个移位逻辑(左移2位)将字地址转换为字节地址
3.3 运算周期EX
ALU运算:R型指令的结果/访存指令的地址/beq两源操作数是否相等。
①对于R型指令,ALU执行相应的算数/逻辑运算,并输出结果
②对于访存指令,ALU计算基地址和偏移量的和,得到数据的真正地址
③对于分支指令,ALU将两源操作数相减,根据结果是否为0,判断两数是否相等
与此同时,加法器得到符号扩展并左移两位的PC相对地址,将其与PC+4相加得到分支目标地址。
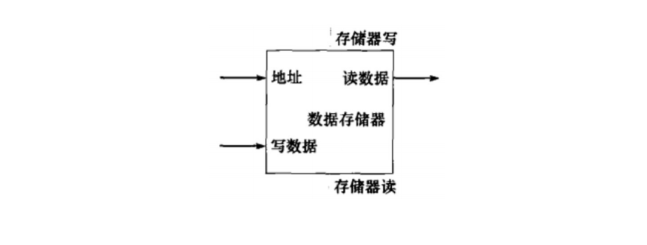
3.4 访存与分支周期MEM
MEM访存分支:访存指令向存储器进行读写,同时分支指令完成分支。
访存指令在第四阶段才真正读/写数据存储器,ALU计算基址和偏移量的和,得到真正地址并输入数据存储器。lw从数据存储器读取数据并输出,sw向数据存储器写入数据。
beq分支指令在这个周期不访存,但会将PC+4/分支目标地址写回PC,决定分支是否发生。因此,将第四阶段统称为访存分支周期。
3.5 写回周期WB
WB写回:将结果送回某寄存器。R型指令将运算结果写回rd寄存器。lw指令将存储器数据写回rt寄存器。
小结:
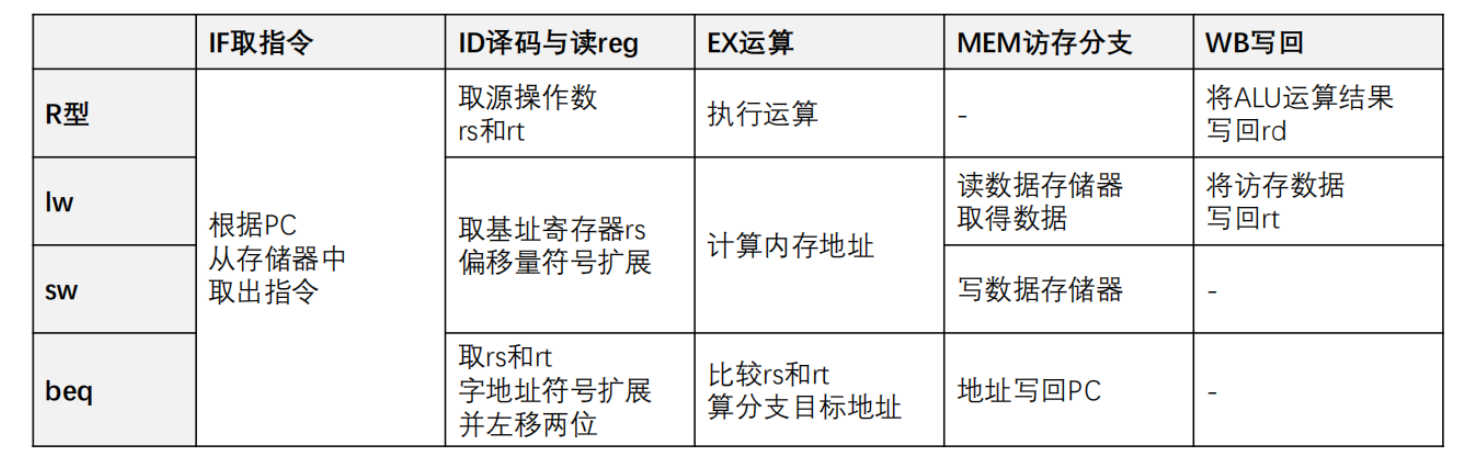
在单周期实现中,每条指令都在一个时钟周期内完成,CPI为1。注意到只有lw使用全部5个阶段,因此基本可以肯定,时钟周期取决于lw的执行时长。其他指令只用4个阶段,但仍然要花费5个阶段的时间。
C P U 时间 = I C × C P I × 时钟周期 CPU时间 = IC \times CPI \times 时钟周期 CPU时间=IC×CPI×时钟周期
多周期实现可以缩减时钟周期到1个阶段的长度,一条指令占用几个阶段,就执行几个周期。虽然CPI变成了4或5,但时钟周期缩短到1/5,运行速度反而更快,后面两种相乘肯定比原来变小。
MIPS子集的基本实现
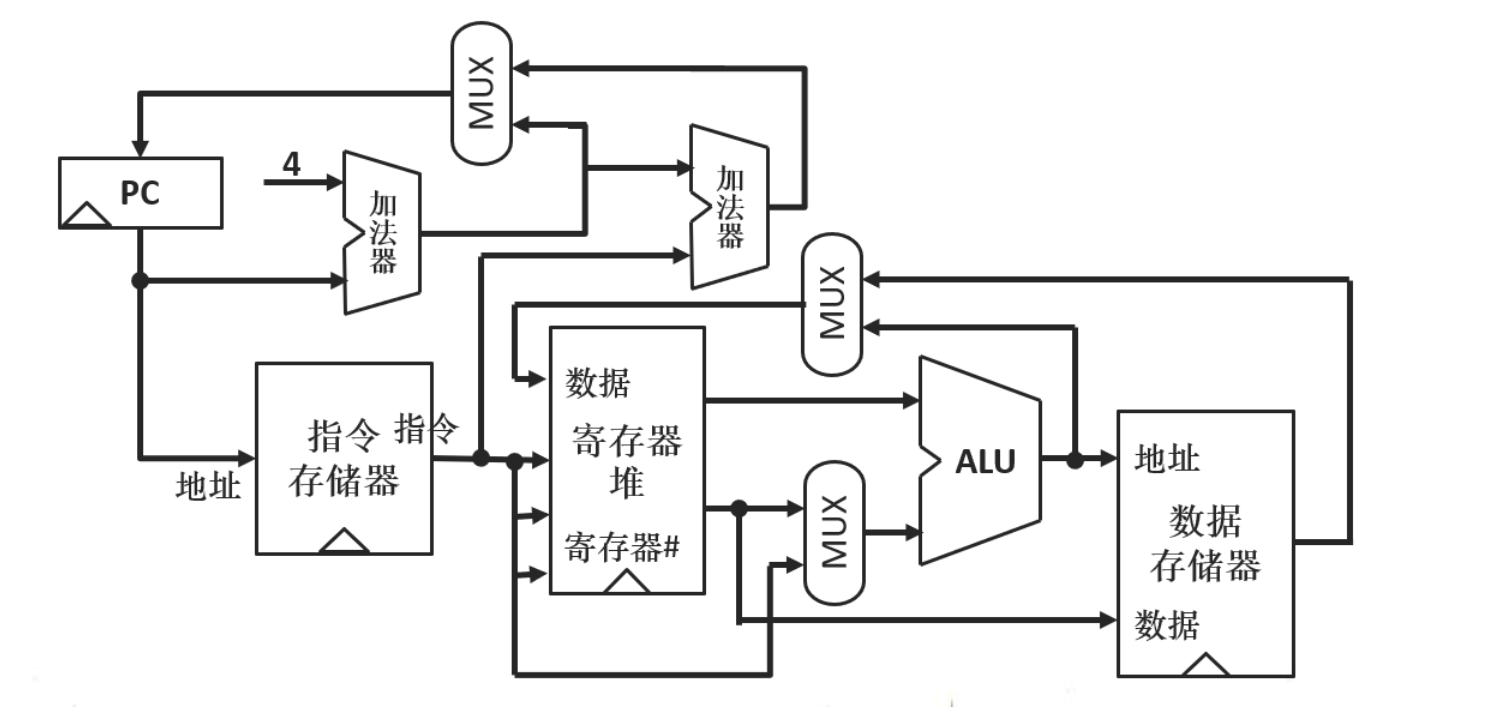
电路中带有三角形的电路表示这是一个时序逻辑电路,其余的为组合逻辑电路。
三、MIPS单周期控制单元
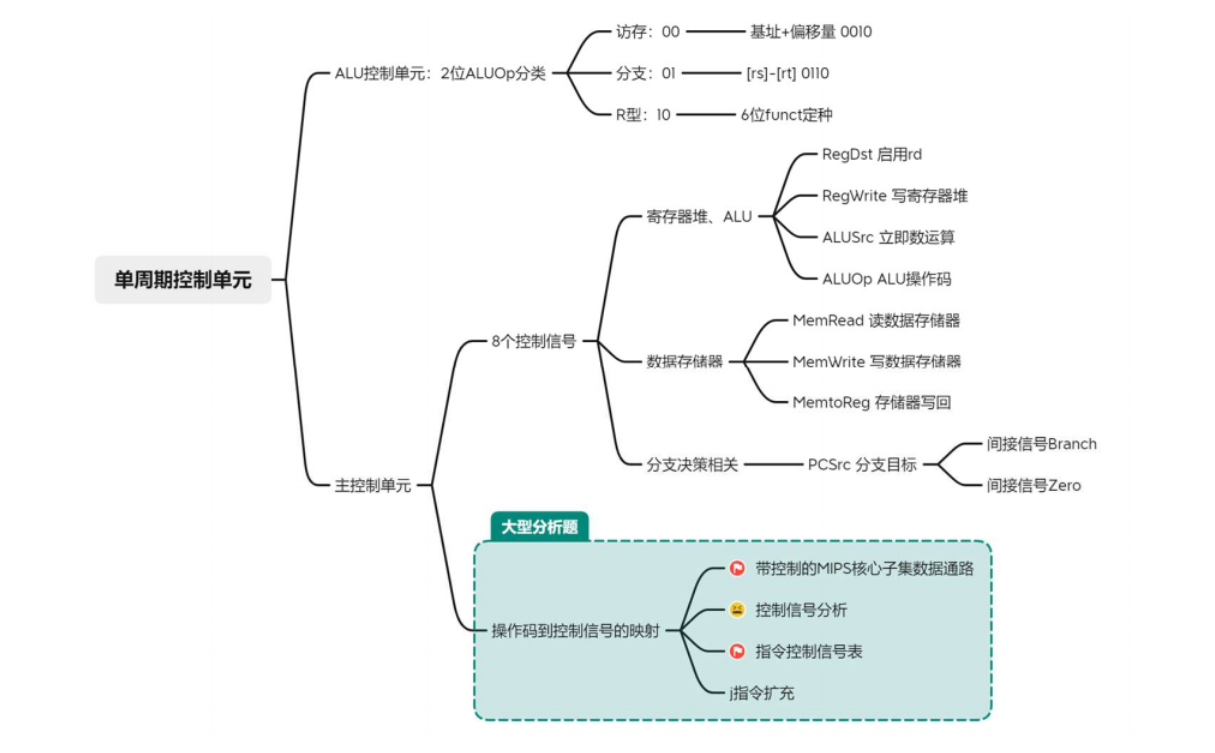
3.1 控制器单元结构
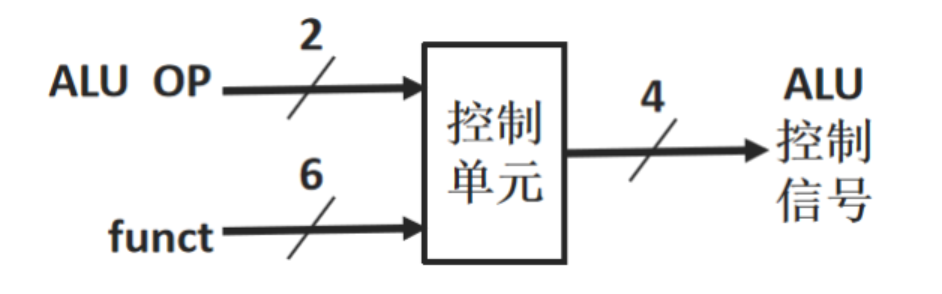
ALU控制线:ALU可以执行加add、减sub、与AND、或OR、小于则置位slt五种运算(或非NOR不讨论),具体执行什么运算,由4位ALU控制线决定。
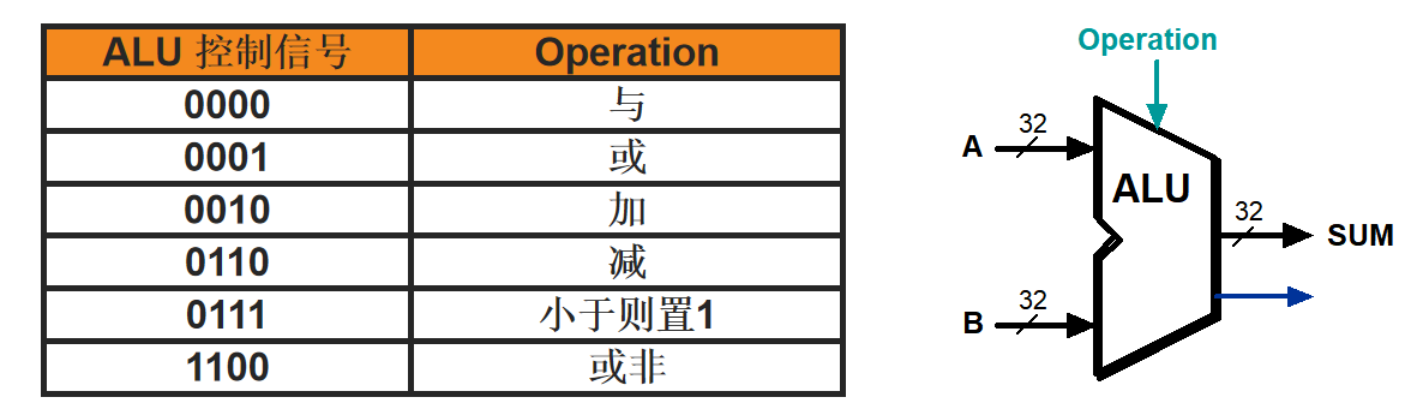
主控制单元根据指令操作码,向ALU控制单元输出一个2位控制信号ALUOp(ALU操作码):
-
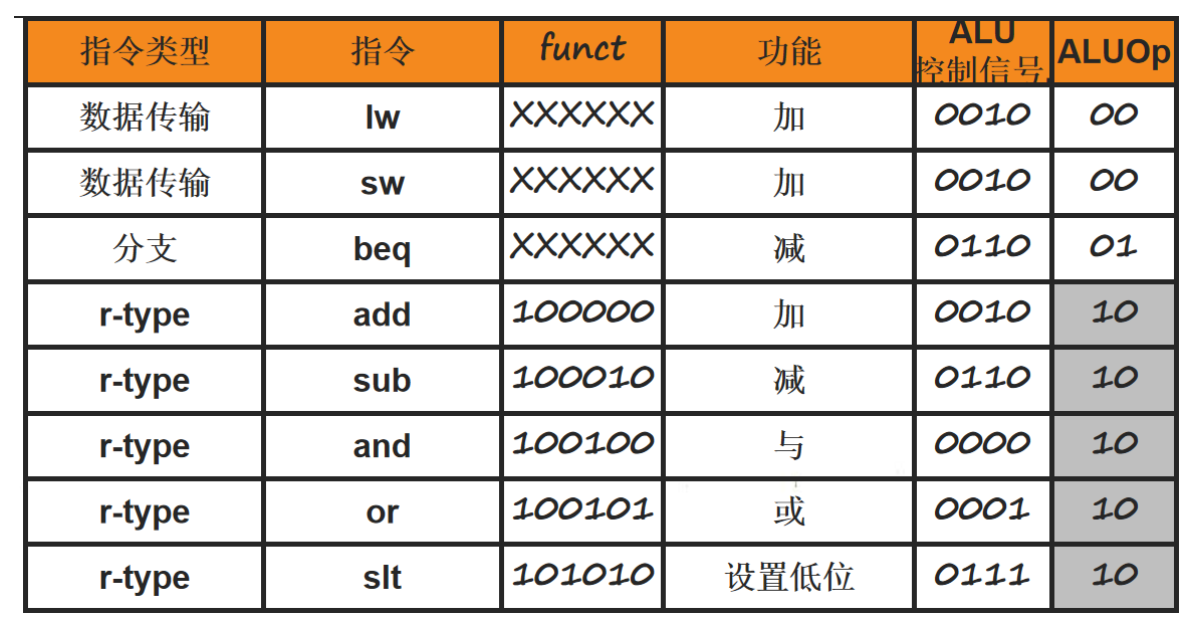
当ALUOp为00时,表示这条指令是访存指令,需要ALU将基址和偏移量相加(0010)
-
当ALUOp为01时,表示这条指令是分支指令beq,需要ALU将两源操作数相减(0110)
-
当ALUOp为10时,表示这是条R型指令,由funct字段进一步指定需要ALU完成的功能。判定为R型指令后,ALU控制单元将6位功能码funct字段映射到加0010、减0110、与0000、或0001、小于则置位0111中的一个。
如下图所示:
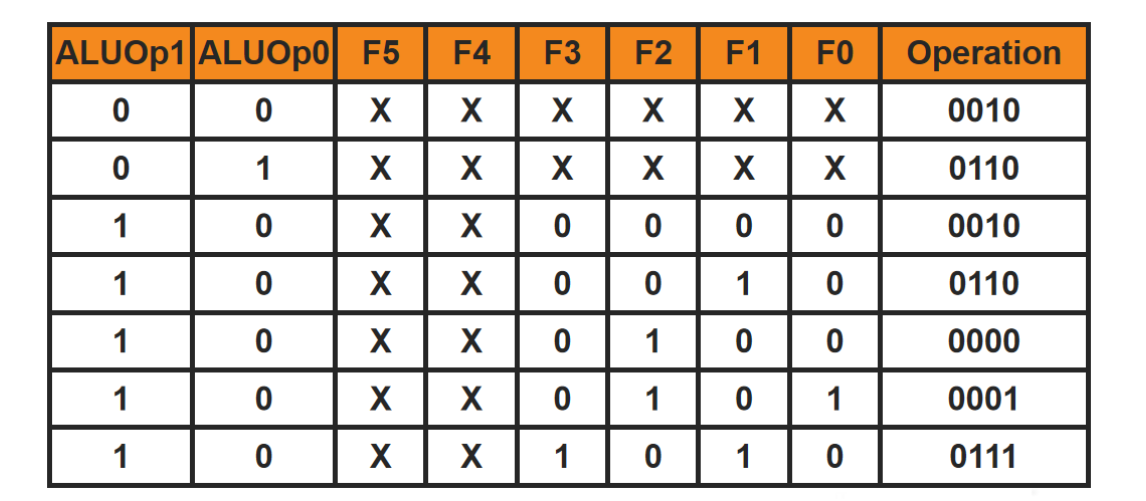
ALU控制线由主控制单元发出的ALUOp、R型指令中的funct字段两级共同决定,这种多级译码方式有利于提高控制器性能。
ALU的使用依赖于:指令类型(op字段)和Funct字段(R型指令)。如下图所示:
对应的函数映射关系如下:
3.2 控制信号
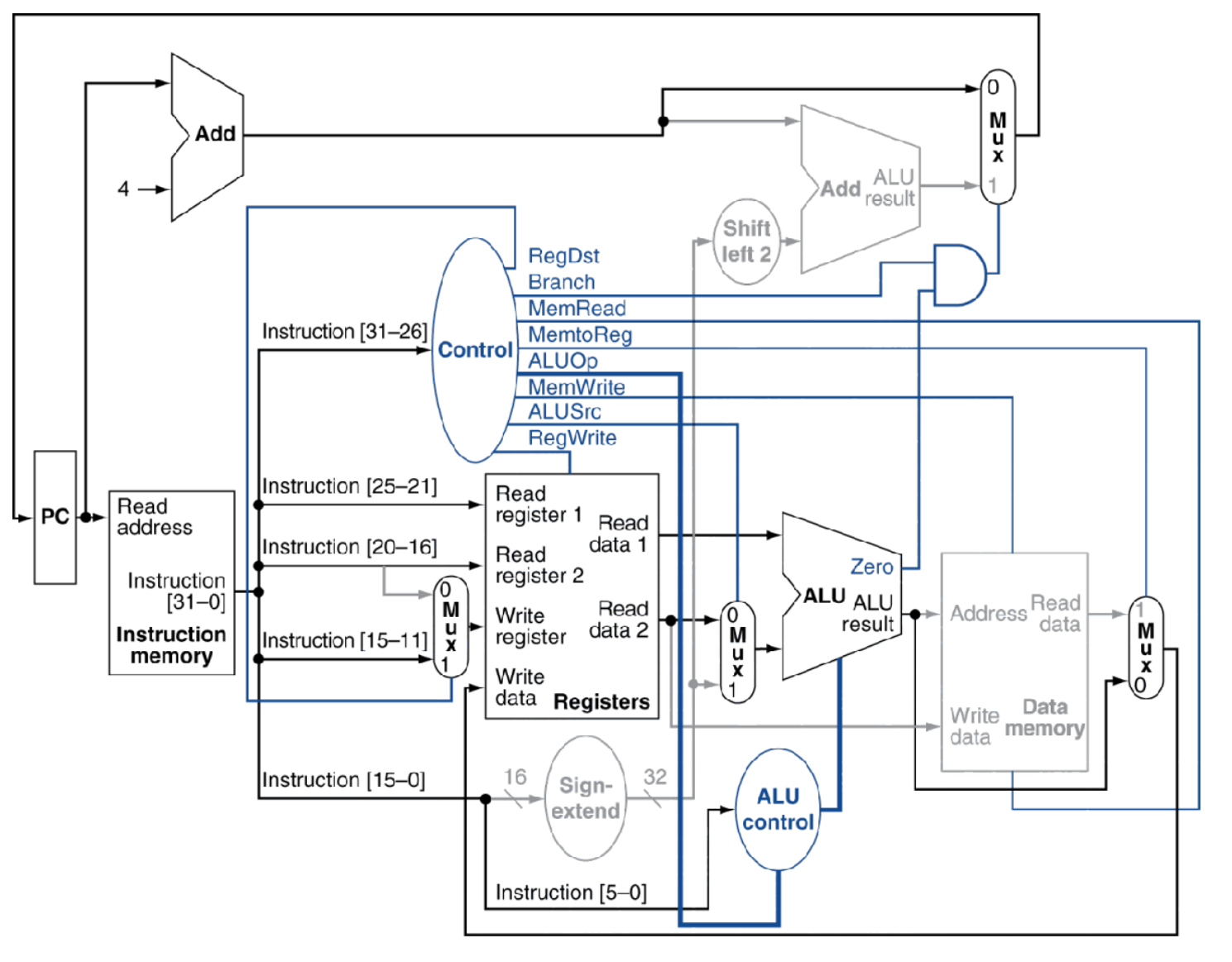
下面是一个带控制的MIPS核心子集数据通路:从图中可以看到控制信号是由32MIPS指令的高6位在ID译码生成的。指令译码就是主控制单元将操作码(不包括功能码)翻译成控制信号,并发送到对应器件的过程,主控制单元共发出8个(共9位)控制信号,由指令Op字段和R型funct字段译码而得。
注意,控制单元只发出Branch信号,而不直接发出PCSrc信号,还要与Zero标志位共同决定。
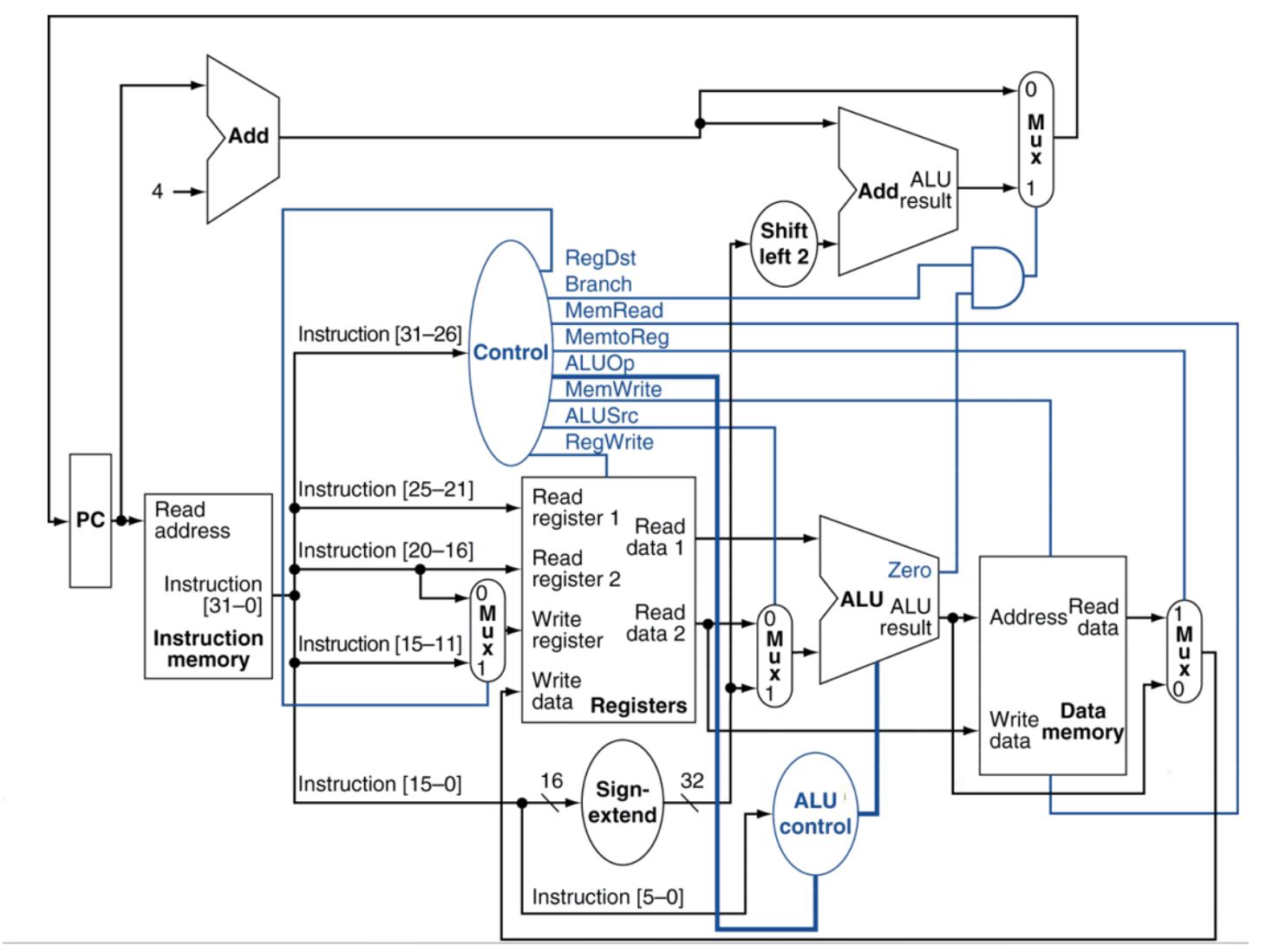
下面分别分析MIPS单周期中各个部件或者功能需要的控制信号。
(1)对于指令寄存器来说,一个程序在运行前将指令写入指令存储器,不需要专门的写使能控制信号来“批准”写入。指令存储器每周期进行一次读操作,是只读且必读的,不需要专门的读使能控制信号来“批准”读出。
(2)对于寄存器堆来说,8条MIPS核心子集指令都会读寄存器,无需读使能控制信号。但是,只有R型指令和lw指令会写回寄存器堆,因此要有寄存器堆写使能控制信号RegWrite,并用启用rd控制信号RegDst决定写回rd还是rt。
(3)对于对ALU部件,除了上述两位ALUOp信号,还需要启用立即数(作为ALU源)控制信号ALUSrc,为1时选取符号扩展后的立即数作为ALU源操作数,为0时选取rt作为ALU源操作数。
(4)对于数据存储器来说,只有lw读数据存储器,只有sw写数据存储器。因此,数据存储器需要读、写控制信号各一个:
-
(数据)存储器读使能控制信号
MemRead -
(数据)存储器写使能控制信号
MemWrite
因为指令存储器不需要读写使能控制信号,不必强调是“数据”存储器。
(5)对于写回操作时,R型指令从ALU写回寄存器,lw从存储器写回寄存器,为了选择写回寄存器的数据来源,需要一个存储器写回控制信号MemtoReg,为1时将存储器数据写回,为0时将ALU运算结果写回。
(5)对于分支指令,首先,仅当遇到beq指令才可能分支。其次,分支条件为真即ALU运算rs-rt=0时才分支。这是分支跳转的两个条件。
使用一个与门(AND gate)进行与运算。当两个输入均为1时,才输出1。当分支控制信号Branch和ALU零标志Zero同时为真,才将PC源控制信号PCSrc置为1,选择将分支目标地址写回PC,完成分支。只要其中一个条件为假(当然包括两个都为假),选择PC+4写回PC,取消分支。
对应控制信号含义,这个值在这里意义不大,具体要结合图中数据通路。
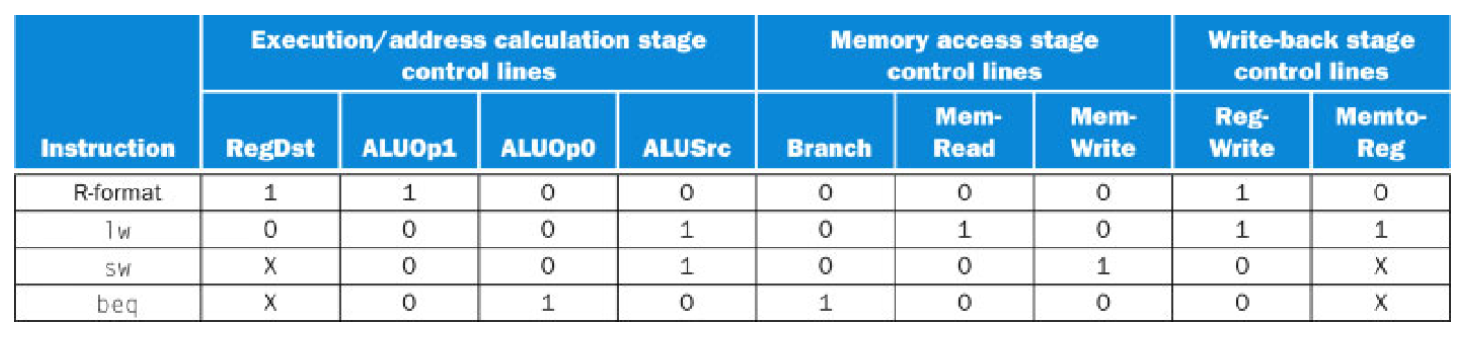
| 控制信号名称 | 含义 | 无效时的含义(0) | 有效时的含义(1) |
|---|---|---|---|
| RegDst | 选择目的寄存器 | 写寄存器的目标寄存器号来自rt字段(位20:16) | 写寄存器的目标寄存器号来自rd字段(位15:11) |
| RegWrite | 寄存器写信号 | 无 | 寄存器堆写使能有效 |
| ALUSrc | ALU 源操作数选择 | 第二个 ALU 操作数来自寄存器堆的第二个输出(读数据2) | 第二个ALU操作数为指令低16位的符号扩展 |
| PCSrc | PC 源选择 | PC由PC+4取代 | PC由分支目标地址取代 |
| MemRead | 存储器读信号 | 无 | 数据存储器读使能有效 |
| MemWrite | 存储器写信号 | 无 | 数据存储器写使能有效 |
| MemtoReg | 标识写入寄存器的数据来源 | 写入寄存器的数据来自ALU | 写入寄存器的数据来自数据存储器 |
只要选择目的寄存器和标识写入寄存器的数据来源对应sw和beq指令为x。
四、指令数据通路
一条指令执行的过程:
- 从存储器中取指令
- 分析指令
- 执行指令
- 写结果,形成下一条指令的地址
在单周期处理器中,指令的执行包括五个主要阶段: 取指(Instruction Fetch),译码(Instruction Decode),执行(Execute),访问数据存储器(Memory Access),写回(Write Back)。 具体指令在某个阶段完成的任务与前面MIPS指令单周期五阶段是一样的。
3.1 R型指令(add)
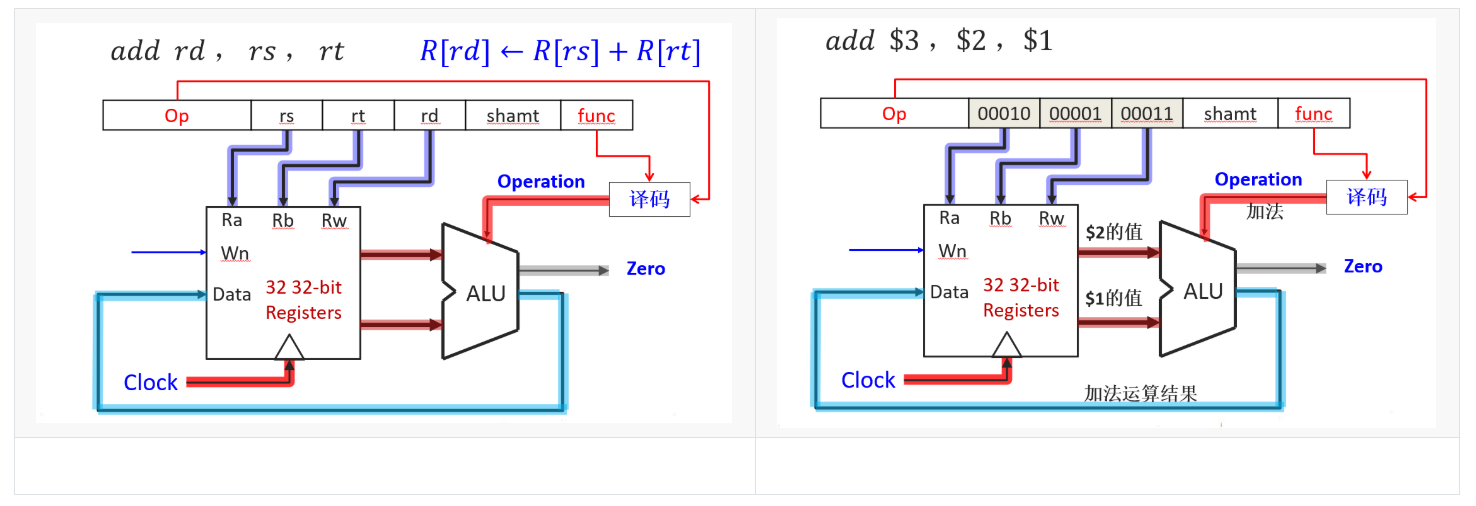
整个数据路径如下:
(1)PC中存放地址,访问指令寄存器得到32位MIPS指令字。
(2)将32MIPS指令字进行解析,高6位[31-26]生成8个控制信号,依次5位分别得到rs,rt,rd的值,并将其放入寄存器堆中。如下图所示。
(3)寄存器组通过读信号,将存放在Ra和Rb寄存器中的值取出,放入ALU中进行运算,将结果返回到寄存器堆的Rw中。
(4)当写的时钟信号到来时,把结果写入Rw中,返回到寄存器rd。
完整带控制信号的R指令,灰色部分都是没有使用的部件。
3.2 I型指令(lw/store)
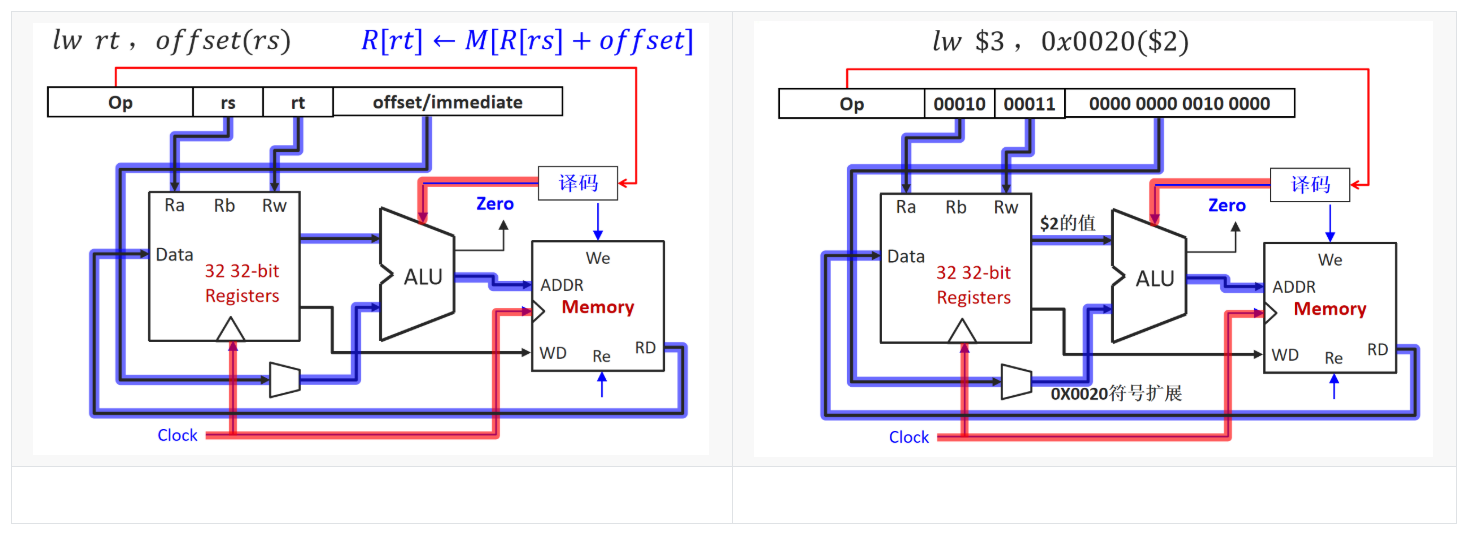
整个数据路径如下:
(1)PC中存放地址,访问指令寄存器得到32位MIPS指令字。
(2)将32MIPS指令字进行解析,高6位[31-26]生成8个控制信号,并读取得到rs,rt,立即数的值。并将16位立即数进行符号扩展变为32位,为下一步目标地址的计算做准备,如下图所示。
(3)取出Ra的值和扩展为32位的立即数,将它们在ALU中进行运算,得到地址。
(4)通过地址在数据存储器DM中取出相应的值,在写时钟脉冲到来时写入寄存器W中。
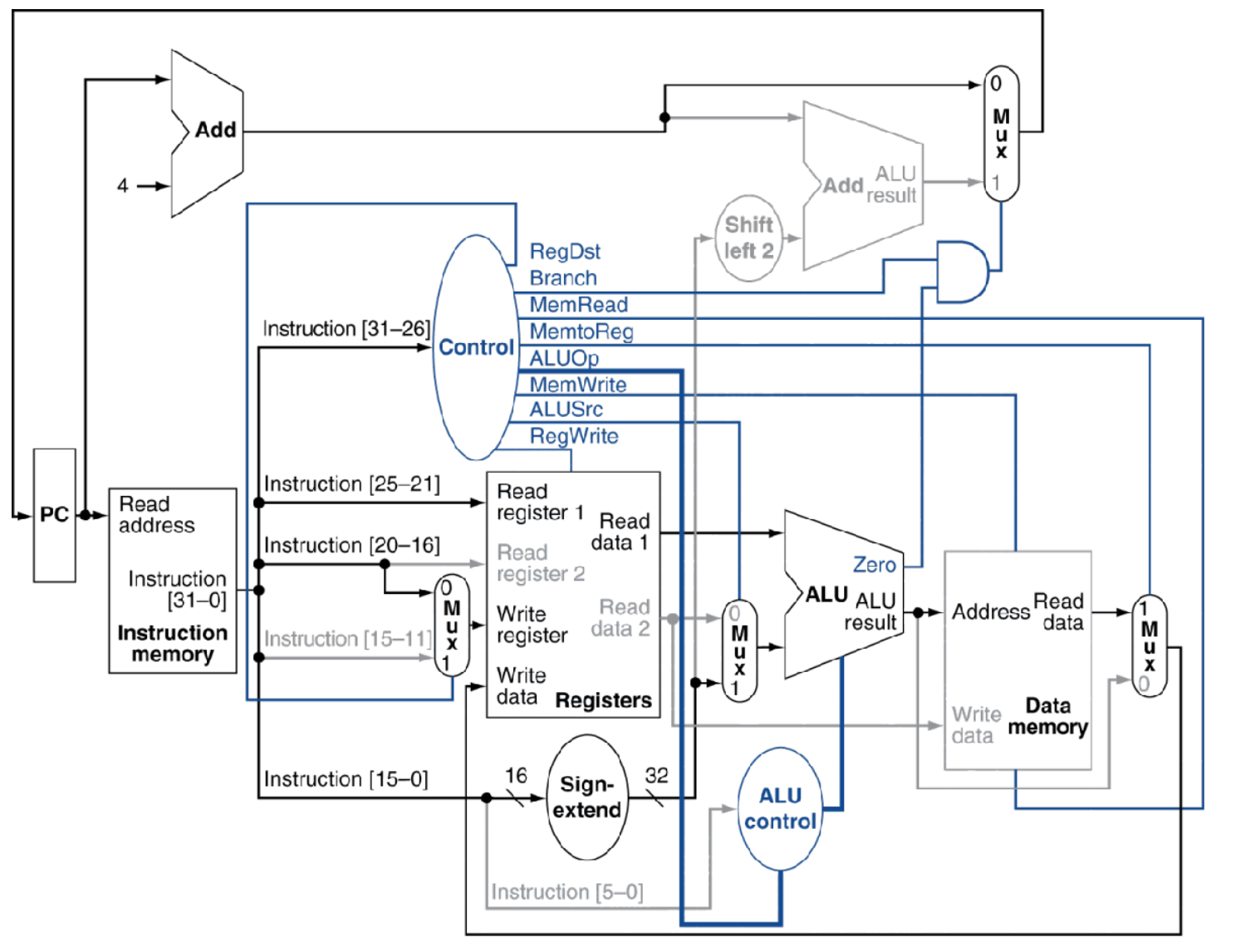
sw指令和前lw指令相同。将值(rt)写入到数据存储器中指定的地址,操作完成。
3.3 分支指令(beq)
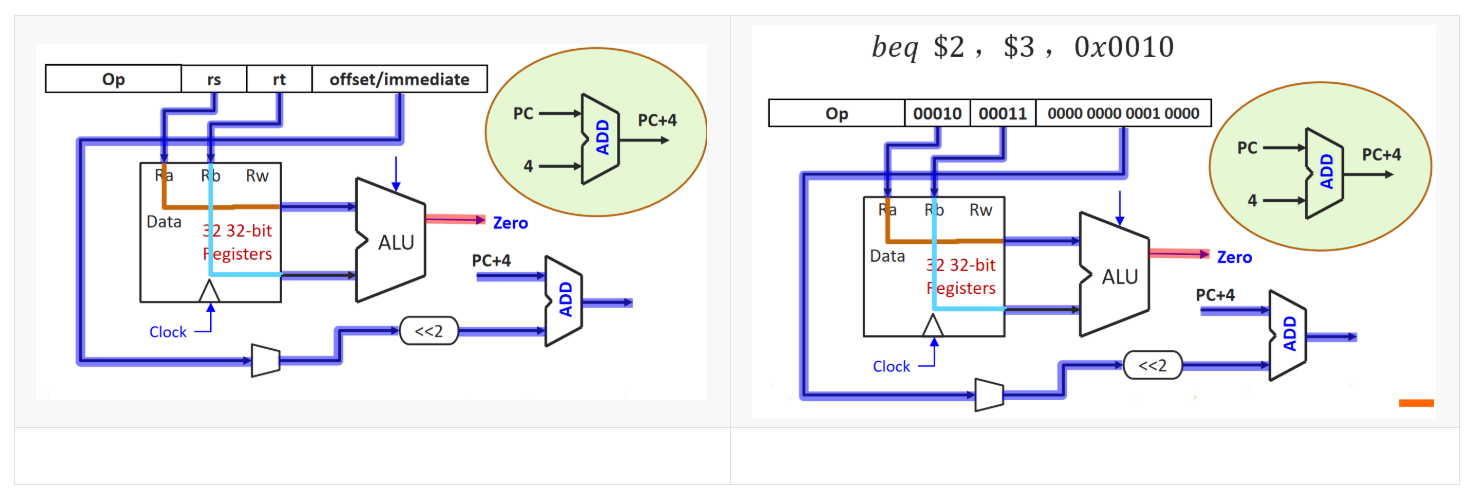
整个数据路径如下:
(1)PC中存放地址,访问指令寄存器得到32位MIPS指令字。
(2)将32MIPS指令字进行解析,高6位[31-26]生成8个控制信号,读取两个比较数rs和rt以及立即数相对偏移地址。如下图所示。
(3)寄存器组通过读信号,将存放在Ra和Rb寄存器中的值取出,放入ALU中进行比较,即减法运算,根据结果是否为0,判断两数是否相等。与此同时,加法器得到符号扩展并左移两位的PC相对地址,将其与PC+4相加得到分支目标地址。
(4)beq分支指令在MEM周期将PC+4/分支目标地址写回PC,决定分支是否发生。
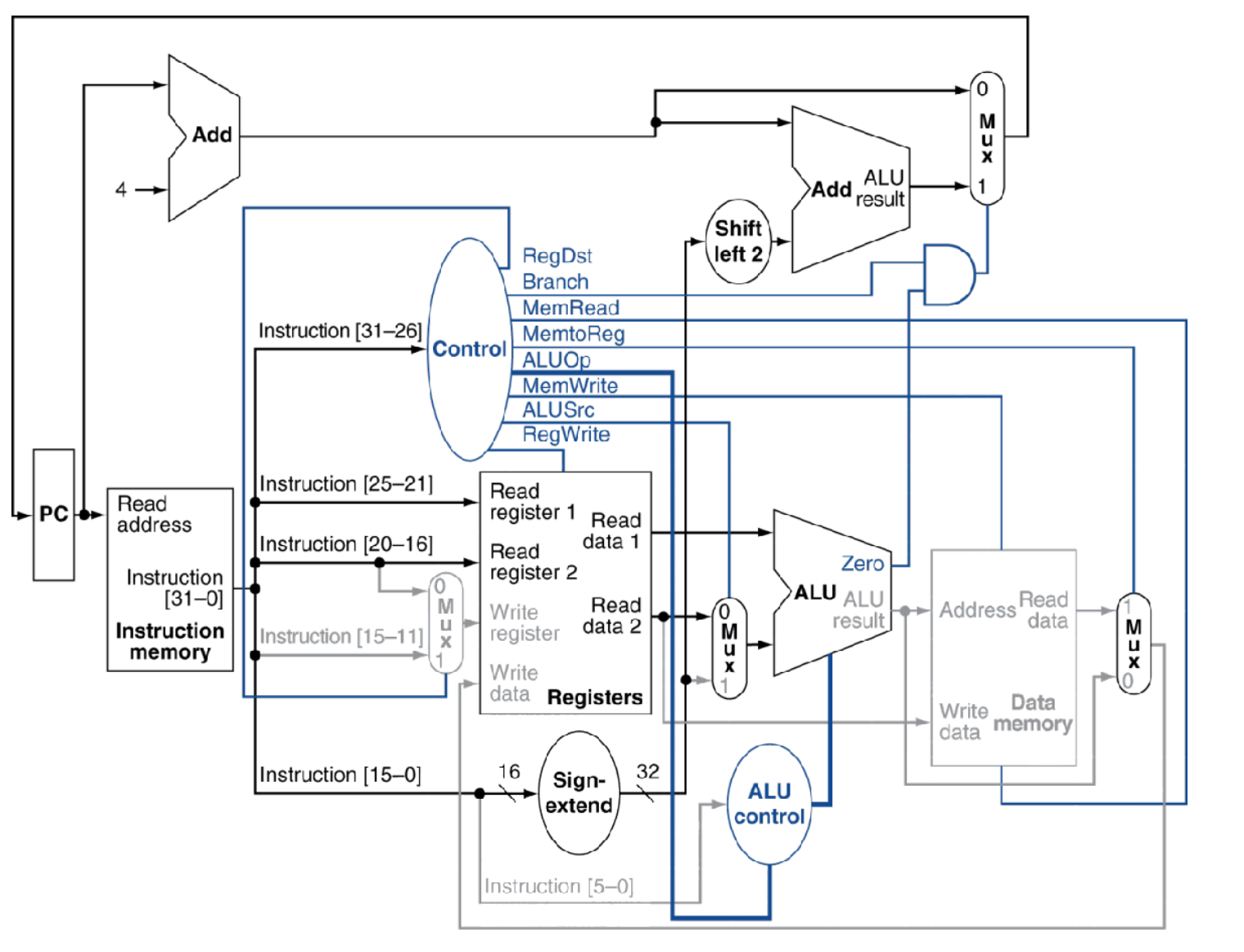
3.4 J指令
在上面的基础上加上无条件跳转指令的相关控制,就形成下面的数据通路。
J跳转指令低 26 位表示跳转到的地址,先左移两位然后加到(PC+4)的高四位偏移量。即目的地址:(PC+4)高4位 + (26<< 2) = 32位。跳转指令主要有控制信号Jump控制,为1直接跳转。
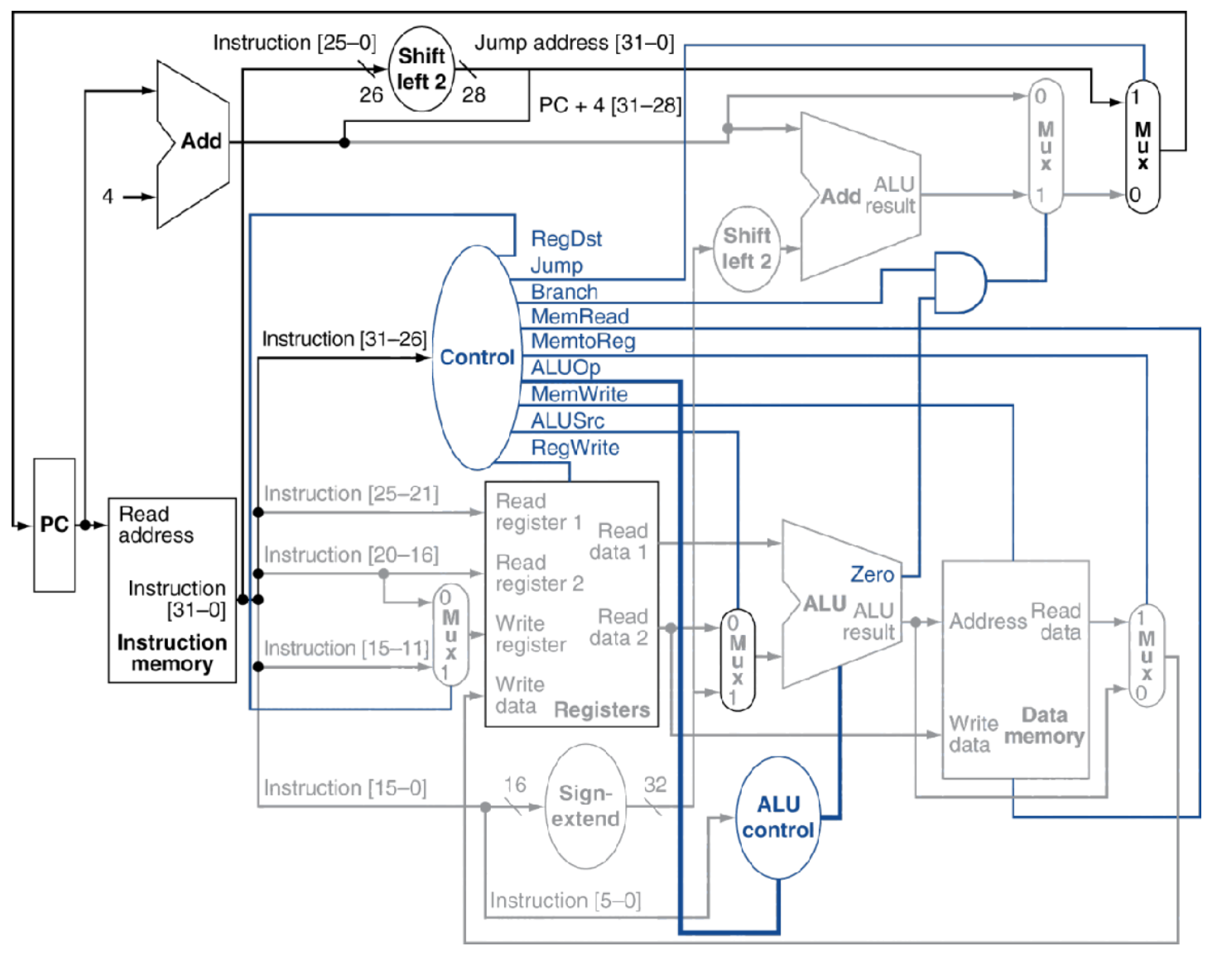
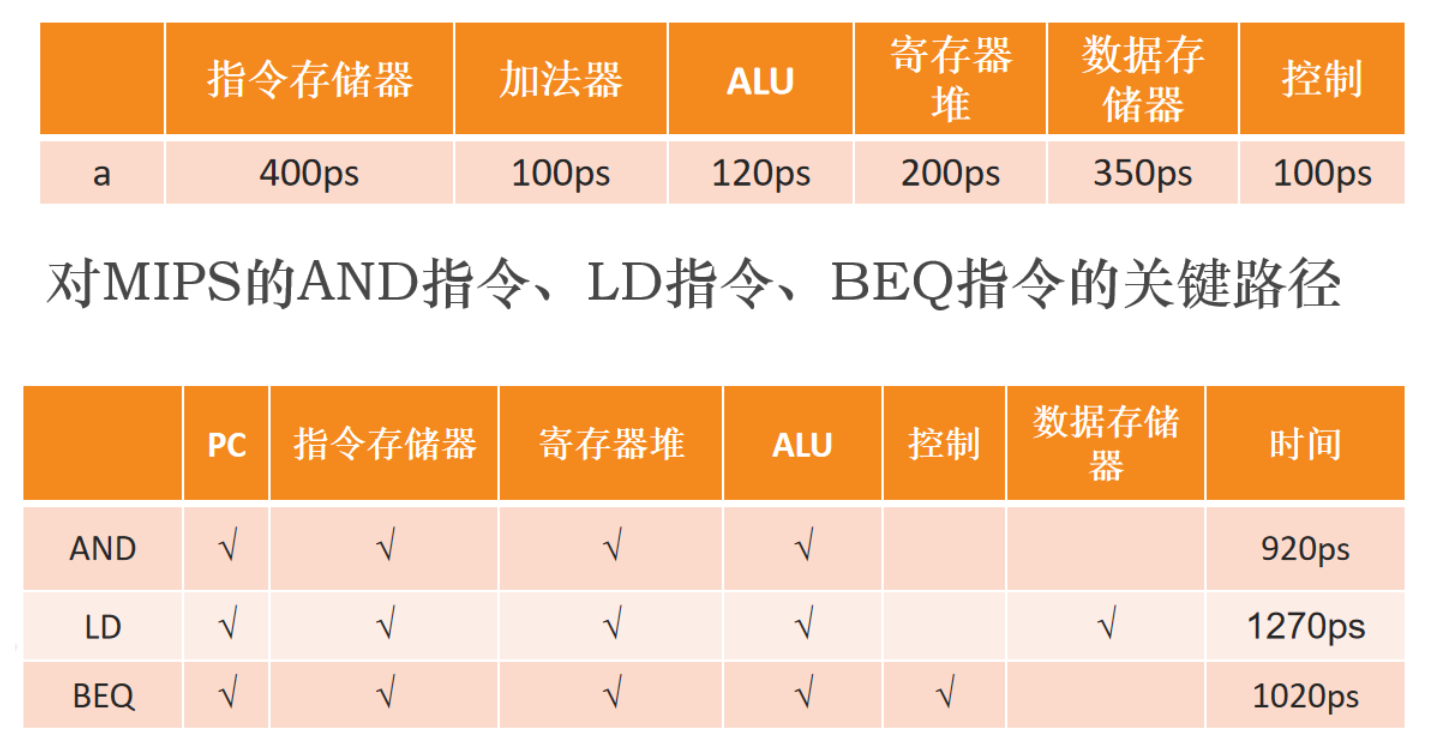
3.5 关键路径
最长的延迟决定了时钟周期的长度,从上面知道load指令5个阶段都在执行任务,因此时钟周期的长度取决于load指令完成时间。
关键路径:load指令
Instruction memory -> register file -> ALU -> data memory -> register file
如果还要包括浮点或更复杂指令的指令集,单周期无法胜任, 可通过流水线技术改进性能。
不同单元有不同的延迟时间,对一条指令而言,关键路径上各单元的延迟时间决定了该指令的最小延迟。假设各单元的延迟时间如下表所示:
五、中断机制
中断:在运行过程中,如果发生某种随机事态,CPU暂停执行现行程序,转去执行为某个随机事态服务的中断处理程序,处理完毕后再自动恢复原程序的执行。
中断的实质与特点:
- 程序切换(实质)
- 方法:保存断点,保护现场;恢复现场,返回断点。
时间:一条指令结束时切换。保证程序的完整性。
- 随机性(特点)
- 随机发生的事态(按键、故障)
- 有意调用,随机请求与处理的事态(调用打印机)
- 随机插入的事态(软中断指令插入程序任何位置)
中断与转子的区别:
子程序的执行由程序员事先安排,而中断服务程序的执行则是由随机中断事件触发。
子程序的执行受主程序或上层程序控制,而中断服务程序一般与被中断的现行程序无关。
一般不存在同时调用多个子程序情况,但可能发生多个外设同时向CPU发出中断服务请求情况
中断与异常的区别:
- 中断是系统停止当前正在运行的程序而转向其他服务,可能是因为优先级高的请求服务了,或者是因为人为安排中断。中断是属于正常现象。 而异常是由于软件错误而引起的。
- 中断是CPU所具备的功能(硬件)。异常是软件运行过程中的一种开发过程中没有考虑到的程序错误。
中断响应条件:
- 有未被屏蔽中断请求到达;
- CPU处于开中断模式;
- 中断源优先级比当前程序的优先级更高;
单周期处理机是在一条指令执行的过程中检测异常事件,当异常事件发生时处理机在该指令结束时转向异常事件处理程序,处理完毕后再返回到用户程序。
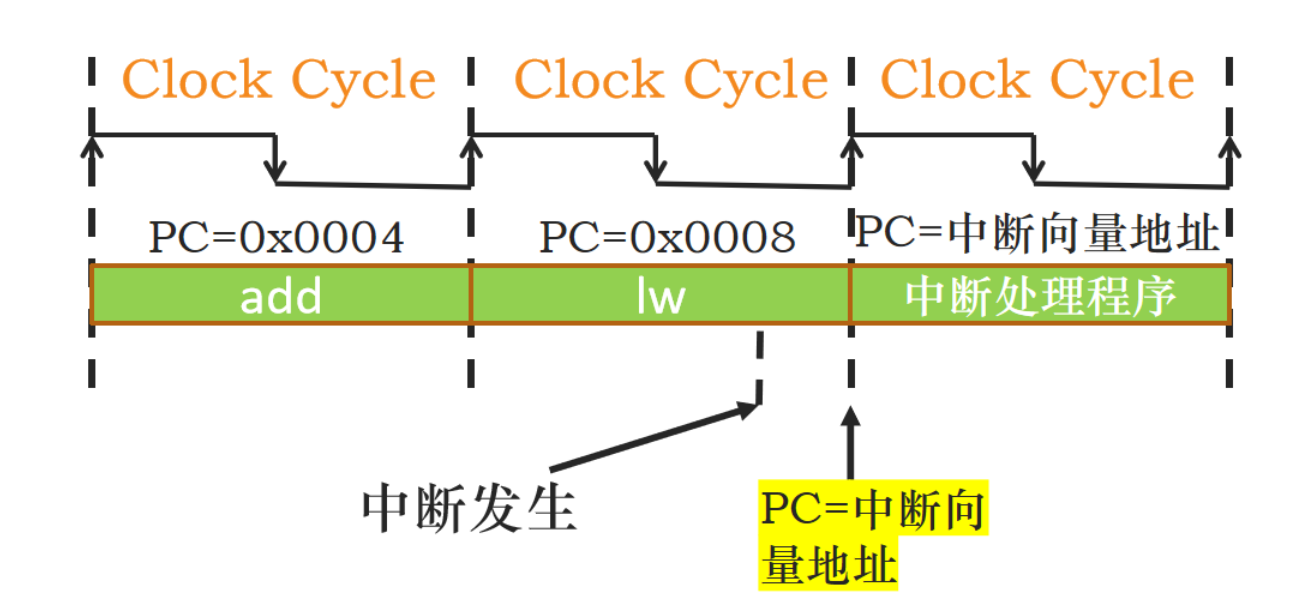
多个外设同时向CPU发出中断服务请求情况
中断与异常的区别:
- 中断是系统停止当前正在运行的程序而转向其他服务,可能是因为优先级高的请求服务了,或者是因为人为安排中断。中断是属于正常现象。 而异常是由于软件错误而引起的。
- 中断是CPU所具备的功能(硬件)。异常是软件运行过程中的一种开发过程中没有考虑到的程序错误。
中断响应条件:
- 有未被屏蔽中断请求到达;
- CPU处于开中断模式;
- 中断源优先级比当前程序的优先级更高;
单周期处理机是在一条指令执行的过程中检测异常事件,当异常事件发生时处理机在该指令结束时转向异常事件处理程序,处理完毕后再返回到用户程序。
[外链图片转存中…(img-tinA32SQ-1756548642342)]
当发生异常时,处理机保存当前处理机状态,如当前PC值(比如当前是lw指令执行中发生中断,则保留的地址应该是sub指令的地址,下一条指令的地址),处理机状态寄存器的内容等等。由硬件向PC写入异常事件处理程序的入口地址,以实现程序的转移。
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)