AAAI 2025 | 即插即用,计算量砍掉80%!超轻量SparseViT刷新SOTA,重新定义Transformer图像取证
【摘要】本文提出SparseViT模型,通过稀疏自注意力机制实现非语义特征的自适应学习,用于图像篡改定位任务。核心创新包括:1)设计稀疏自注意力模块,将全局注意力分解为局部子块计算,抑制语义信息而专注篡改痕迹;2)分层多尺度稀疏策略,在不同层级采用递减的稀疏率提取特征;3)轻量级可学习预测头(LFF)实现自适应特征融合。实验表明,该方法在参数效率提升80%的同时达到SOTA性能,打破了传统依赖手工
1. 基本信息

-
标题: Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization through Spare-Coding Transformer
-
论文来源: https://arxiv.org/pdf/2412.14598
2. 核心创新点
-
提出稀疏注意力机制:创新性地利用稀疏自注意力(Sparse Self-Attention)来抑制连续的语义信息,从而迫使模型自适应地学习和提取对图像篡改敏感的非语义特征(如噪声、频率伪影),摆脱了对传统手工特征提取器的依赖。
-
实现卓越的参数效率:通过将ViT中密集的全局自注意力重构为稀疏、离散的形式,模型在大幅减少计算量(FLOPs最多降低80%)和参数的同时,实现了最先进的篡改定位性能。
-
设计可学习的多尺度特征融合头 (LFF) :引入了一个轻量级且高效的预测头LFF (Learnable Feature Fusion)。通过为每个尺度的特征图分配可学习的权重,实现了自适应的特征融合,优于传统的固定融合方式。
-
证明稀疏编码的有效性:首次在图像篡改定位领域证实,语义特征需要密集、连续的交互来构建,而非语义特征因其局部独立性,通过稀疏编码即可建立全局联系并有效检测。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/lN32rMJY6dEzX3RilDuzCQ
https://mp.weixin.qq.com/s/lN32rMJY6dEzX3RilDuzCQ
3. 方法详解
整体结构概述:SparseViT采用编码器-解码器架构。编码器基于Vision Transformer,但其核心的自注意力被替换为稀疏自注意力机制,以分层、不同稀疏率的方式提取多尺度非语义特征。这些特征随后被送入一个名为LFF(可学习特征融合)的轻量级预测头(解码器),进行自适应加权融合,最终生成像素级的篡改预测掩码。
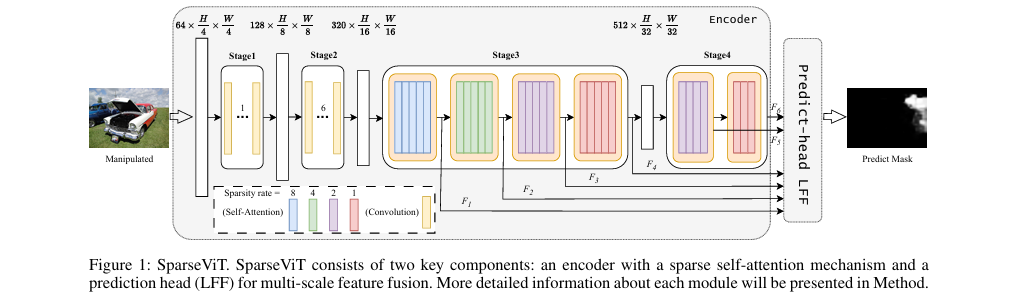
SparseViT整体架构图
步骤分解:
- 稀疏自注意力 (Sparse Self-Attention) :
-
该模块是模型的核心。传统的ViT对整个特征图进行全局自注意力计算,这倾向于学习图像的语义内容。
-
SparseViT引入了“稀疏率 (Sparsity rate)”超参数
S。它将输入的特征图H×W分割成S×S个不重叠的子块。 -
自注意力计算被严格限制在每个独立的子块内部进行,从而打破了全局的上下文联系,抑制了模型对语义信息的学习,迫使其转向关注篡改留下的局部、离散的非语义痕迹。
-
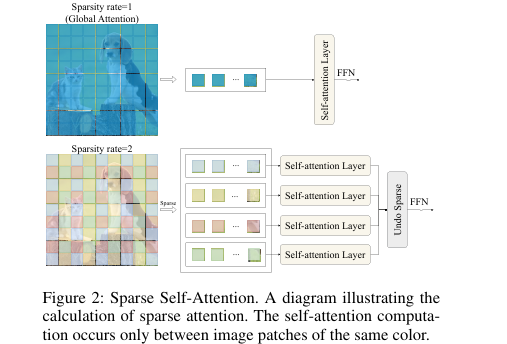
稀疏自注意力计算示意图
-
分层多尺度稀疏策略:
-
模型并非采用固定的稀疏率,而是在编码器的不同阶段(Stage 3和Stage 4)的不同层级应用指数级递减的稀疏率。
-
这一设计使得模型可以在不同层次上以不同的粒度提取非语义特征。稀疏率较小(偏向密集)的层有助于理解宏观结构,而稀疏率较大(更稀疏)的层则专注于捕捉微观的、局部的篡改痕迹。
-
Stage 3和Stage 4中各层的稀疏率计算公式如下:$$S_{3_b{^i}}^S = 2^{\left(3-\frac{i}{5}\right)}, \quad i= 0...19 $$ $$S_{4_b{^i}}^S = 2^{\left(1-\frac{i}{4}\right)}, \quad i= 0...6 $$
-
-
轻量级可学习预测头 (LFF) :
-
LFF (Learnable Feature Fusion)模块负责融合来自编码器不同阶段、不同稀疏率下的多尺度特征图(
F1至F6)。 -
它首先通过线性层和上采样统一所有特征图的通道数和尺寸。
-
关键在于,LFF为每个输入特征图分配一个可学习的缩放参数
γ。在求和融合前,每个特征图都会乘以其对应的γ值。 -
这种机制使得模型可以根据任务需求,在训练中自动学习不同尺度特征的重要性,并动态调整它们的贡献度,从而实现更灵活、更有效的特征融合。
-
LFF的融合过程可以公式化为:$$M_p = \text{Add}(F_i \times \gamma), \quad i=1...6 $$
-
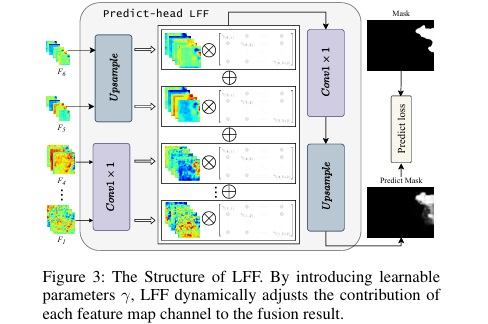
LFF结构图
4. 即插即用模块作用
本报告分析的核心模块是“稀疏自注意力机制 (Sparse Self-Attention)”
适用场景
-
核心任务: 图像篡改定位 (Image Manipulation Localization, IML),包括拼接、复制-粘贴、移除等多种篡改手法的检测。
-
相关领域: 数字取证、媒体内容安全、信息真实性验证。
-
潜在应用: 可扩展到其他需要关注低级、非语义伪影的视觉任务,如AI生成内容检测 (AIGC Detection)、图像隐写分析、相机源识别等。
主要作用
-
模拟/替代能力: 有效替代了传统篡改检测流程中需要手工设计的特征提取器(如SRM, BayarConv, DCT, Noiseprint等),实现了非语义特征的自适应、端到端学习。
-
降低计算/内存: 通过将全局注意力稀疏化,大幅降低了模型的计算复杂度(FLOPs)和参数量,使其比同类SOTA模型更轻量、更高效。
-
增强泛化性/鲁棒性: 通过抑制对易过拟合的语义信息的依赖,模型更专注于学习通用的、与内容无关的篡改痕迹,从而在未见过的、复杂的篡改场景下展现出更强的泛化能力和鲁棒性(如抵抗JPEG压缩、高斯模糊和噪声攻击)。
-
提升定位精度: 专注于非语义特征使得模型能够避免语义相关的假阳性(例如,不会因为图像中某个物体本身看起来不协调而误报),从而更精确地定位篡改边界。
总结
稀疏自注意力机制是一个高效、轻量级的“去语义化”模块,它通过打破全局上下文,迫使模型从学习“图像里有什么”转变为关注“图像处理得对不对”,从而在图像篡改定位任务中实现了高精度、强泛化和低成本的统一。
➔➔➔➔点击查看原文,获取本文及其他精选即插即用模块集合![]() https://mp.weixin.qq.com/s/lN32rMJY6dEzX3RilDuzCQ
https://mp.weixin.qq.com/s/lN32rMJY6dEzX3RilDuzCQ
5. 即插即用模块
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from timm.models.layers import trunc_normal_, DropPath, to_2tuple
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CMlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
def forward(self, x):
# print(x.shape)
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def block(x,block_size):
B,H,W,C = x.shape
pad_h = (block_size - H % block_size) % block_size
pad_w = (block_size - W % block_size) % block_size
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
Hp, Wp = H + pad_h, W + pad_w
x = x.reshape(B,Hp//block_size,block_size,Wp//block_size,block_size, C)
x = x.permute(0,1,3,2,4,5).contiguous()
return x, H, Hp, C
def unblock(x, Ho):
B,H,W,win_H,win_W,C = x.shape
x = x.permute(0,1,3,2,4,5).contiguous().reshape(B,H*win_H,W*win_W, C)
Wp = Hp = H*win_H
Wo = Ho
if Hp > Ho or Wp > Wo:
x = x[:, :Ho, :Wo, :].contiguous()
return x
def alter_sparse(x, sparse_size=8):
x = x.permute(0, 2, 3, 1)
assert x.shape[1]%sparse_size == 0 & x.shape[2]%sparse_size == 0, 'image size should be divisible by block_size'
grid_size = x.shape[1]//sparse_size
out, H, Hp, C = block(x, grid_size)
out = out.permute(0, 3, 4, 1, 2, 5).contiguous()
out = out.reshape(-1, sparse_size, sparse_size, C)
out = out.permute(0, 3, 1, 2)
return out, H, Hp, C
def alter_unsparse(x, H, Hp, C, sparse_size=8):
x = x.permute(0, 2, 3, 1)
x = x.reshape(-1, Hp//sparse_size, Hp//sparse_size, sparse_size, sparse_size, C)
x = x.permute(0, 3, 4, 1, 2, 5).contiguous()
out = unblock(x, H)
out = out.permute(0, 3, 1, 2)
return out
class CBlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.attn = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x + self.drop_path(self.conv2(self.attn(self.conv1(self.norm1(x)))))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Sparse_Self_Attention(nn.Module):
def __init__(self, dim, num_heads, sparse_size=0, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
global layer_scale
self.ls = layer_scale
self.sparse_size = sparse_size
if self.ls:
global init_value
print(f"Use layer_scale: {layer_scale}, init_values: {init_value}")
self.gamma_1 = nn.Parameter(init_value * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_value * torch.ones((dim)),requires_grad=True)
def forward(self, x):
x_befor = x.flatten(2).transpose(1, 2)
B, N, H, W = x.shape
if self.ls:
x, Ho, Hp, C = alter_sparse(x, self.sparse_size)
Bf, Nf, Hf, Wf = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.attn(self.norm1(x))
x = x.transpose(1, 2).reshape(Bf, Nf, Hf, Wf)
x = alter_unsparse(x, Ho, Hp, C, self.sparse_size)
x = x.flatten(2).transpose(1, 2)
x = x_befor + self.drop_path(self.gamma_1 * x)
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x), H, W))
else:
x, Ho, Hp, C = alter_sparse(x, self.sparse_size)
Bf, Nf, Hf, Wf = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.attn(self.norm1(x))
x = x.transpose(1, 2).reshape(Bf, Nf, Hf, Wf)
x = alter_unsparse(x, Ho, Hp, C, self.sparse_size)
x = x.flatten(2).transpose(1, 2)
x = x_befor + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
x = x.transpose(1, 2).reshape(B, N, H, W)
return x
# 设置全局变量
layer_scale = True
init_value = 1e-6
if __name__ == '__main__':
# 定义输入张量大小(批量大小、通道数、高度、宽度)
B, C, H, W = 1, 64, 256, 256 # 可以根据需要调整形状
input_tensor = torch.randn(B, C, H, W) # 随机生成输入张量
# 初始化 SABlock
dim = C # 输入和输出通道数
num_heads = 4 # 注意力头的数量
sparse_size = 4 # 稀疏处理块大小
mlp_ratio = 4.0 # MLP 隐藏层的放大比例
qkv_bias = True # 是否使用 QKV 偏置
drop = 0.1 # dropout 概率
attn_drop = 0.1 # 注意力 dropout 概率
drop_path = 0.1 # DropPath 概率
# 创建 Sparse_Self_Attention 实例
sablock = Sparse_Self_Attention(
dim=dim,
num_heads=num_heads,
sparse_size=sparse_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)