空间计量模型_截面数据空间计量模型——空间杜宾误差模型
3.6 空间杜宾误差模型3.6.1 模型及估计(一)空间杜宾误差模型及假设空间杜宾误差模型(SDEM)表达式为:(二)空间杜宾误差模型的估计本文采取极大似然估计法。极大似然估计是建立在极大似然原理的基础上的一个统计方法,直观想法是:一个随机试验如有若干个可能的结果A,B,C,…。若在一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。求极大似然函数估计值的一般步...
3.6 空间杜宾误差模型
3.6.1 模型及估计
(一)空间杜宾误差模型及假设
空间杜宾误差模型(SDEM)表达式为:


(二)空间杜宾误差模型的估计
本文采取极大似然估计法。极大似然估计是建立在极大似然原理的基础上的一个统计方法,直观想法是:一个随机试验如有若干个可能的结果A,B,C,…。若在一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。求极大似然函数估计值的一般步骤:
-
写出似然函数;
-
对似然函数去对数,并整理;
-
求导数;
-
解似然方程。
极大似然估计是参数估计的方法之一,说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察期结果,利用结果退出参数的大概值。极大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,这样当然不会再去选择其他小概率的样本,所以就把这个参数作为估计的真实值。
本文模型为空间杜宾误差模型:
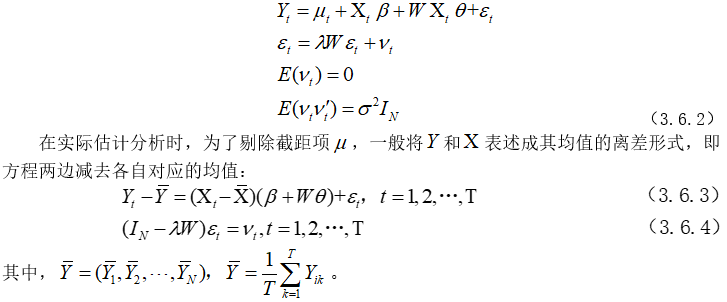


3.6.2 实例及操作
针对R&D项目数量的空间杜宾误差模型构造如下:

stata软件并不能直接找到SDEM模型的命令,这时就要观察SDEM模型的表达,可以发现,在SDM 模型用操作的时候,空间滞后变量(WXt)是自动生成的。但假若我们将其看成普通变量,则该模型就变成空间误差模型(SEM),而SEM则可以直接通过stata命令完成。根据上式(3.6.11)构建的模型,打开是数据集“li3.6”具体的在Command窗口中的命令为:
spregsem lninno lnrdk lnrdl wlnrdk wlnrdl , wmfile (D:\stata16\shuju\chap03\li3.6W.dta)
将利用经典回归模型和SDEM模型所估计的结果,进行整理如下:
表3.6.1 2016年我国省际R&D项目数量影响因素的实证分析结果
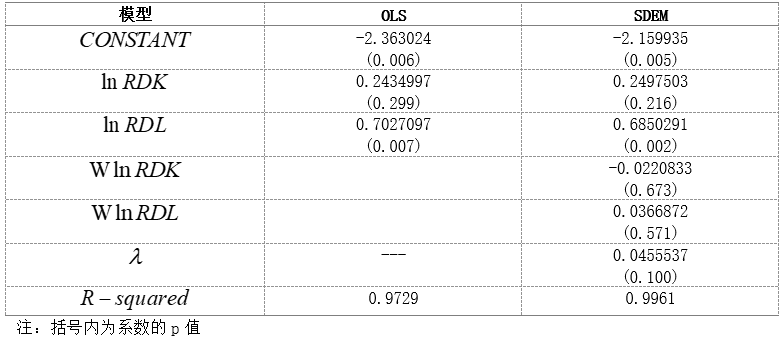
由表3.6.1可见:首先,SDEM模型的拟合优度高于OLS模型,且在SDEM模型中各系数相比OLS模型均变得更加显著,故SDEM模型为相对较优的估计。其次,在SDEM模型的估计结果中,R&D的空间误差自相关系数为0. 0455537,其P值为0.1,结果较为显著,说明各个地区之间的工业企业研究与试验发展存在正的空间相关性,说明了邻近省份的R&D项目数量具有明显的区域集聚特点。然而,两个空间滞后解释变量的系数均不显著,说明各省R&D项目数量的空间效应有限,可以考虑在模型中剔除这两个变量。
讲员:叶阿忠
编辑:梁文明
往期回顾:
截面数据空间计量模型-空间杜宾模型
截面数据空间计量模型-空间误差模型
截面数据空间计量模型-空间滞后模型

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)