YOLOV8跑自己的数据集(语义分割)
个人记录。为了记忆用的。里面包含了跑通一个yolov8模型的需要更改的代码、连接服务器的用法、遇到的bug、数据集的制作以及数据集格式的转换提示:以下是本篇文章正文内容,下面案例可供参考。
·
前言
个人记录。为了记忆用的。
里面包含了跑通一个yolov8模型的需要更改的代码、连接服务器的用法、遇到的bug、数据集的制作以及数据集格式的转换
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据集的制作
- 用的软件:labelme
- labelme生成的是json文件,不符合yolo所用的数据集格式(.txt)
- 利用代码进行格式转换,并将数据集分为测试(test)、验证(val)、训练(train)
- 注意:分割的和检测所用的.txt并不是一样的,也就是转换的代码也不同。
(分割)json格式转换txt格式代码
- 运行时候更改defalut后面的json文件地址和保存生成txt文件地址。以及class中的类别
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
path = os.path.join(json_dir, json_path)
with open(path, 'r') as load_f:
json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# 保存 txt 的路径
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
# 确保目标目录存在
os.makedirs(os.path.dirname(txt_path), exist_ok=True)
try:
with open(txt_path, 'w') as txt_file:
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.write(label_str)
except Exception as e:
print(f"Error writing to {txt_path}: {e}")
if __name__ == "__main__":
"""
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs"
"""
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default='',
help='json path dir')
parser.add_argument('--save-dir', type=str, default='',
help='txt save dir')
parser.add_argument('--classes', type=str, default=' ', help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)(分割)将数据集进行划分
同样自己运行时更改地址和类别。
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集80%,验证集10%,测试集10%,按需修改
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default='',
help='image path dir')
parser.add_argument('--txt-dir', type=str, default='',
help='txt path dir')
parser.add_argument('--save-dir', default='', type=str,
help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)二、需要更改的代码
1.yaml文件
复制一个yaml文件,将内容更改为如下所示:
- train、val、test的地址进行修改
- nc是类别,有几个类别就写几,这里我加上了背景是两类
- names是类别名称,要和json文件中的,进行标注时候的类别进行对应,background这个我不知道不加会不会报错,是背景。
## coco8-seg.yaml 示例
train: # 训练图像路径
val: # 验证图像路径
test: # 测试图像路径(可选)
nc: 2 # 类别数
names: ['di','background'] # 类别名称列表2.train 文件
如果下载的代码中没有train文件,可以自己建一个python文件
- 其中fengedi.yaml是我的yaml文件,需要更改为自己。
- 这个分割的,如果是检测的,在model这里要将.yaml和.pt文件更改成相应的,可以在下图找到.pt这个是预训练权重文件,在这个网址https://docs.ultralytics.com/zh/models/yolov8中可以进行下载,下载后放在项目根目录中。
from ultralytics import YOLO
import torch
import wandb
# Load a model
model = YOLO("yolov8n-seg.yaml") # build a new model from scratch
model.load('yolov8n-seg.pt')
# Use the model
if __name__ == '__main__':
torch.cuda.device_count()
model.train(data="fengedi.yaml", epochs=500) # train the model
metrics = model.val() # evaluate model performance on the validation set
wandb.init(allow_none=True) # Allow running without logging in

3、val验证代码,没有的话自己建一个。路径自己更改。
from ultralytics import YOLO
import torch
import torch.nn as nn
# Load a model
# model = YOLO('yolov8.pt') # load an official model
model = YOLO('路径')
# source 后是测试集的路径 name参数后面路径是把预测的结果放到哪里
results=model.predict(source='路径',save=True,
show=False,name="参数路径")三、连接服务器的方法
准备
- 下载xshell(运行代码用)、Xftp(像服务器传送文件)
- 下载网址:家庭/学校免费 - NetSarang Website
- 需要知道服务器的用户名、主机、密码、端口号
XFTP连接传文件
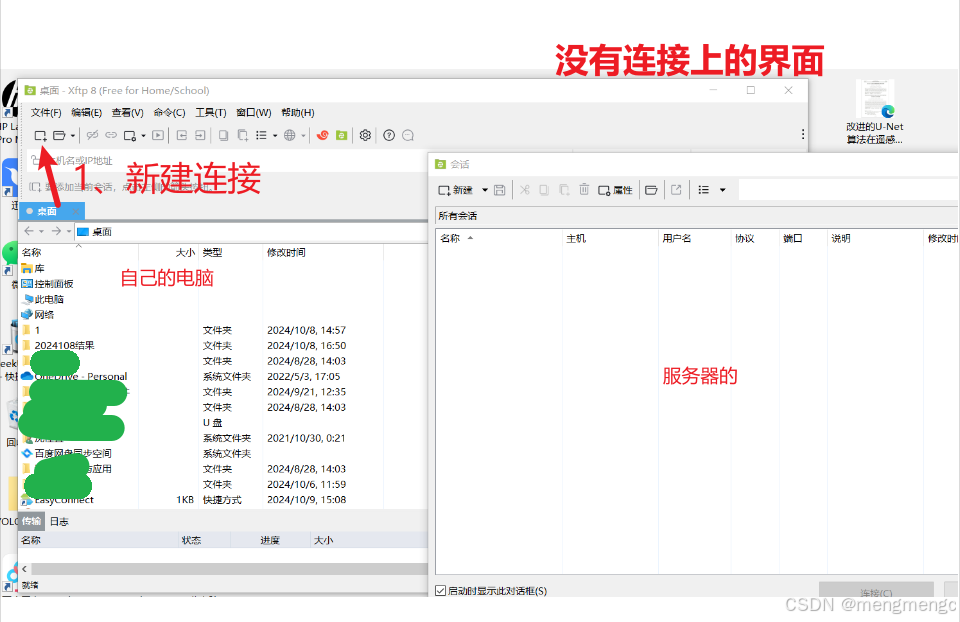
1、新建连接
2、输入主机号和端口号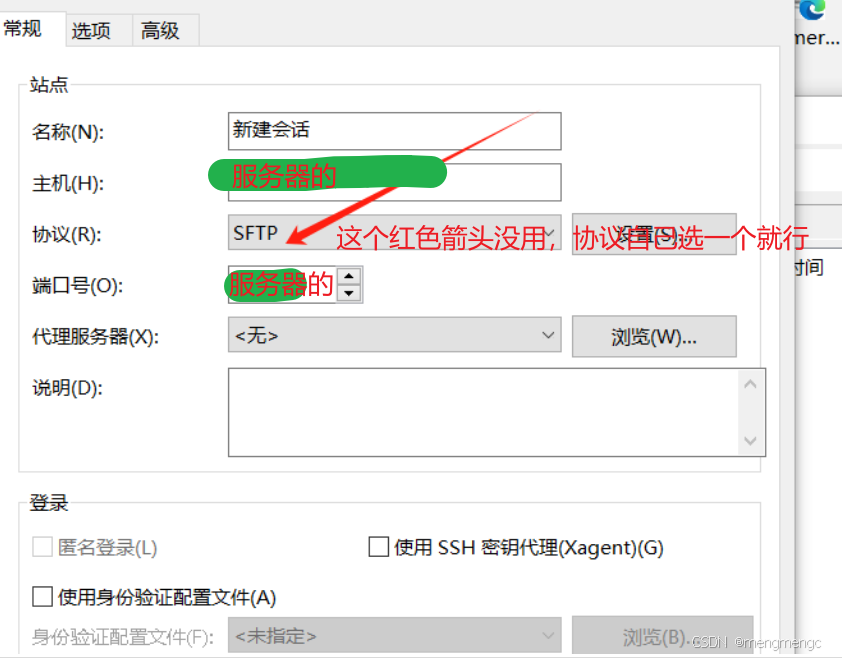
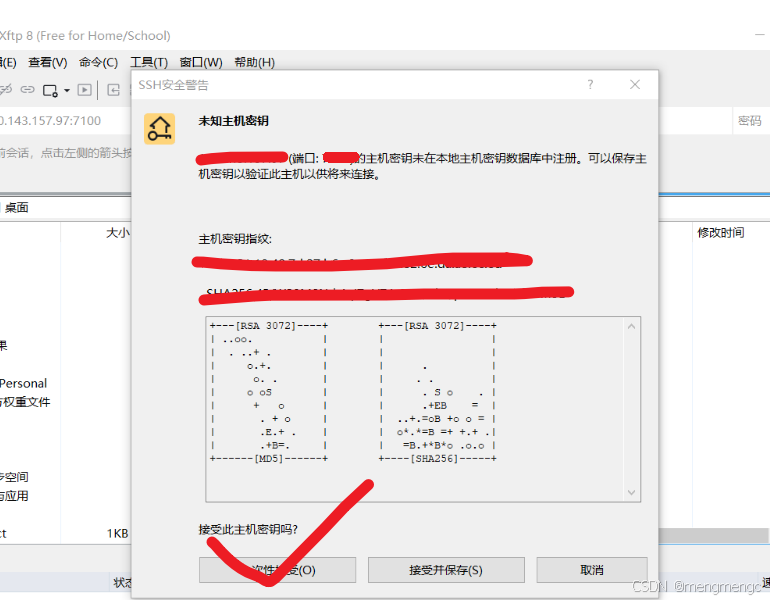
这里点一次性接受
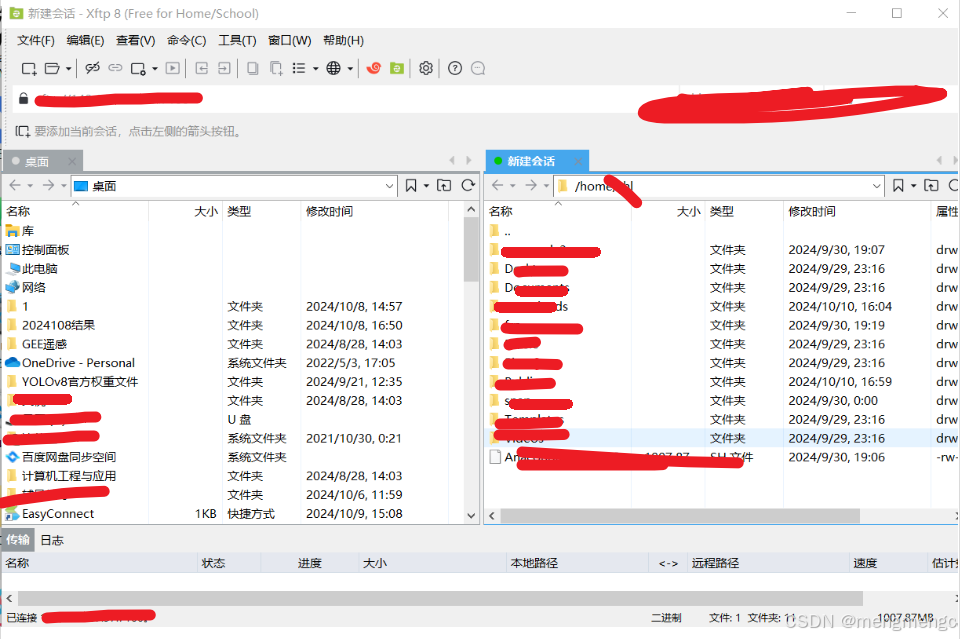
3、连接上的界面,然后将自己的代码传过去就可以了
Xshell运行代码
1、连接,输入主机号、端口号
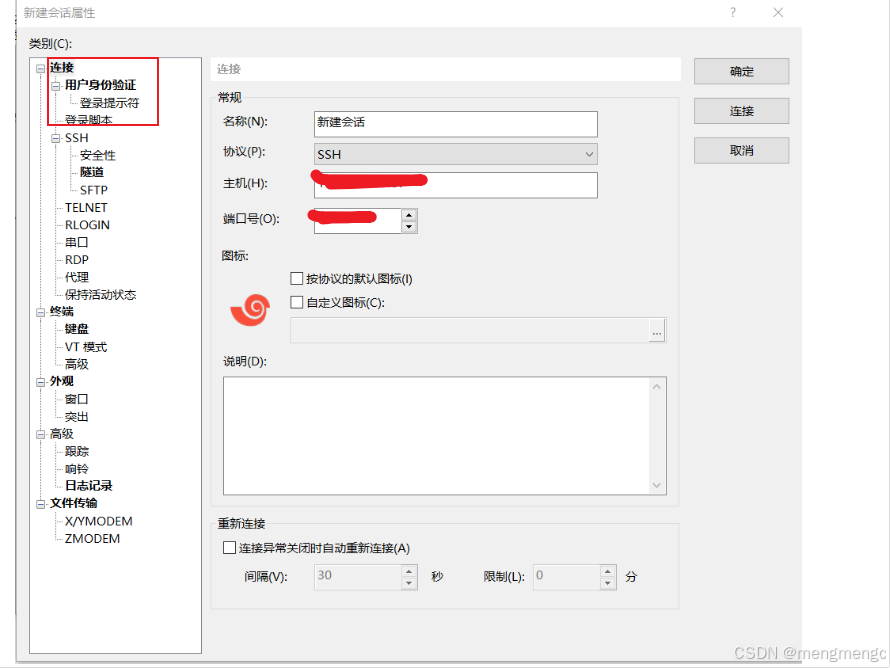
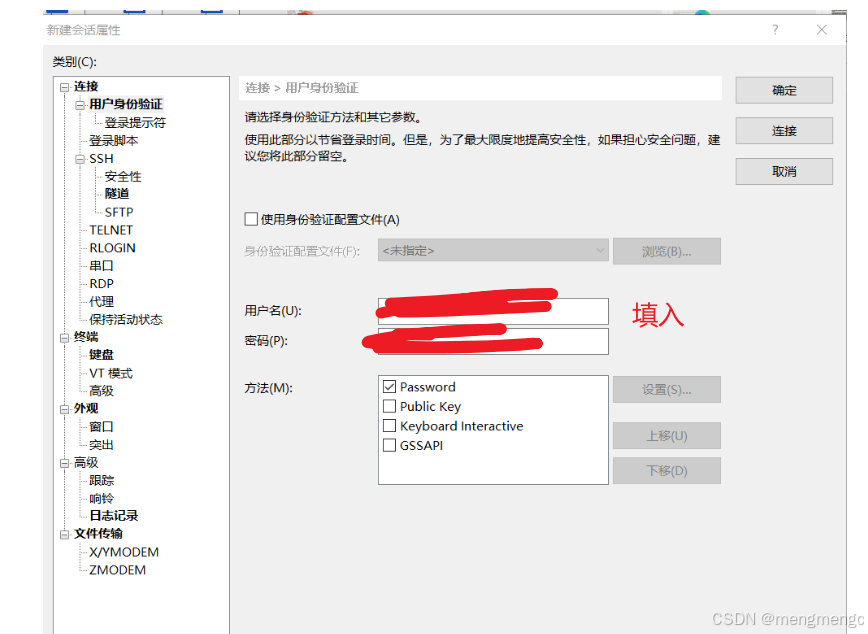
2、连接上界面
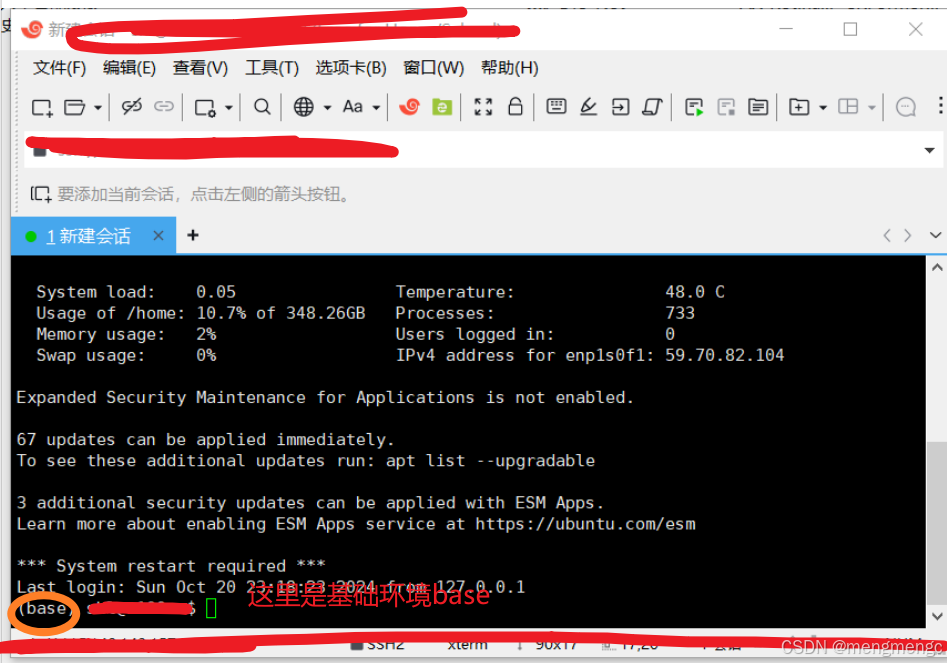
切换环境:source activate 环境名
切换路径:cd 路径
运行代码:python train.py
这里的路径是传输代码到服务器上的,服务器的上代码路径。例如:

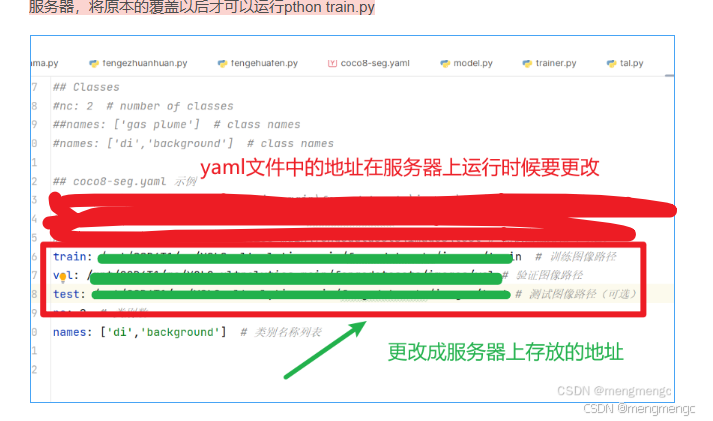
注意:在服务器运行时候,需要更改yaml中文件的地址(改成服务器上存放的地址),再上传过去服务器,将原本的覆盖以后才可以运行pthon train.py
四、遇到的问题
wandb.errors.UsageError: api_key not configured (no-tty). call wandb.login(key=[your_api

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)