基于机器学习的乳腺癌预测模型实现
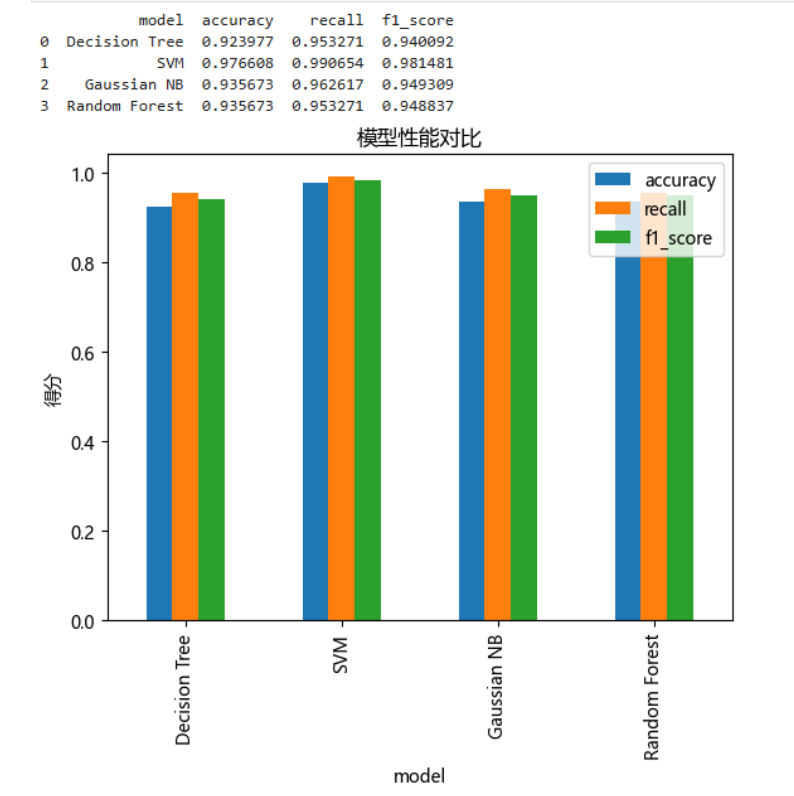
答: SVM 最佳:在本实验中,SVM 凭借最高的准确率(0.977)、召回率(0.991)和 F1 分数(0.981)领先于其他模型。原因在于乳腺癌数据集的特征空间对良恶性样本而言近似线性可分,SVM 的线性/核方法能够有效划分这两类样本,同时其最大化间隔的策略也增强了对噪声与少数异常点的鲁棒性。朴素贝叶斯快捷:高斯朴素贝叶斯取得了 0.936 的准确率(F1=0.949),训练速度最快、内存占
一、实验目的:
1. 理解决策树、朴素贝叶斯、SVM和随机森林等机器学习算法的基本原理及工作流程;
2. 掌握使用 Python 中相关库(如 scikit-learn)调用上述算法的方法;
3. 实现使用决策树、朴素贝叶斯、SVM和随机森林算法对乳腺癌数据集进行预测;
4. 对各个模型的超参数调整;
5. 对比不同算法在乳腺癌预测任务中的性能差异,分析各算法的优缺点。
二、实验内容(包含实验过程、截图和代码解释):
1. (1)使用 Python 中的 scikit-learn中datasets 库导入乳腺癌数据集。
(2)查看数据集的基本信息,包括数据的形状、特征名称、数据类型等。
(3)对数据集进行预处理:
①处理缺失值:检查数据集中是否存在缺失值,若存在,采用适当的方法(如填充均值、中位数或众数等)进行处理。
②数据标准化/归一化:对于某些算法(如 KNN、SVM 等),需要对数据进行标准化或归一化处理,以消除不同特征量纲和取值范围差异对模型的影响。
③划分训练集和测试集:将数据集划分为训练集和测试集。
- 模型构建与训练
- 决策树模型
- 使用 scikit-learn 中的 DecisionTreeClassifier 构建决策树模型。
- 设置模型的参数(如最大深度、最小样本分裂等),并训练模型。
- 对训练后的模型进行评估,计算模型在测试集上的准确率、召回率、F1 分数等指标,对超参数优化。
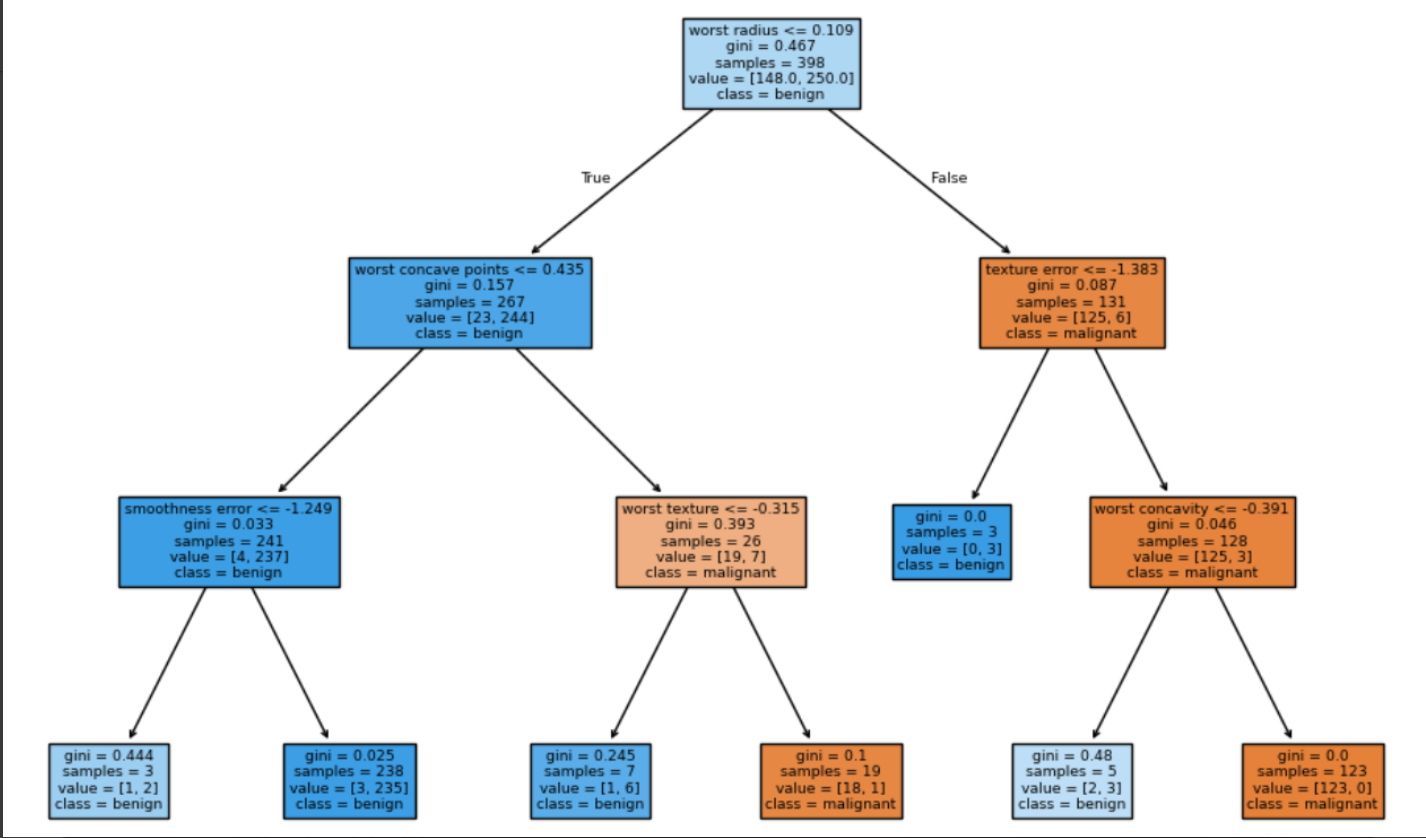
- 绘制决策树的可视化图,分析模型的决策过程。
- SVM 模型
- 使用 scikit-learn 中的 SVC 构建 SVM 模型。
- 设置模型的参数(如核函数类型、惩罚参数 C 等),并训练模型。
- 对训练后的模型进行评估,计算模型在测试集上的准确率、召回率、F1 分数等指标,对超参数优化。
- 朴素贝叶斯模型
- 使用 scikit-learn 中的 GaussianNB(高斯朴素贝叶斯)或其他适合的朴素贝叶斯分类器构建模型。
- 训练模型,并对训练后的模型进行评估,计算模型在测试集上的准确率、召回率、F1 分数等指标,对超参数优化。
- 随机森林模型
- 使用 scikit-learn 中的 RandomForestClassifier 构建随机森林模型。
- 设置模型的参数(如树的数量、最大深度等),并训练模型。
- 对训练后的模型进行评估,计算模型在测试集上的准确率、召回率、F1 分数等指标,超参数优化。
3. 模型性能比较与分析
(1)将上述四种模型在测试集上的准确率、召回率、F1 分数等指标进行汇总比较,分析各模型在乳腺癌预测任务中的性能差异。
(2)分析各模型的优缺点,结合实验结果,讨论在乳腺癌预测任务中选择何种模型更为合适。
三、过程解释
数据加载与基本信息查看:
过程说明:使用 scikit-learn 内置的乳腺癌数据集,加载特征矩阵 X 与目标向量 y。
代码:
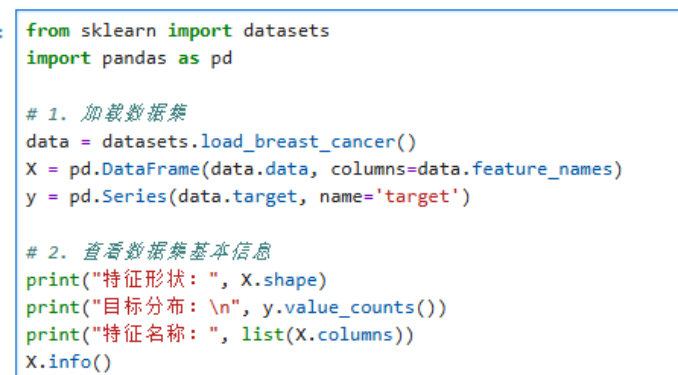
代码解释:
load_breast_cancer 返回一个带有 data、target 和 feature_names 属性的 Bunch 对象。
将 data.data 转为 DataFrame 便于后续操作。
value_counts() 查看良/恶性样本分布。
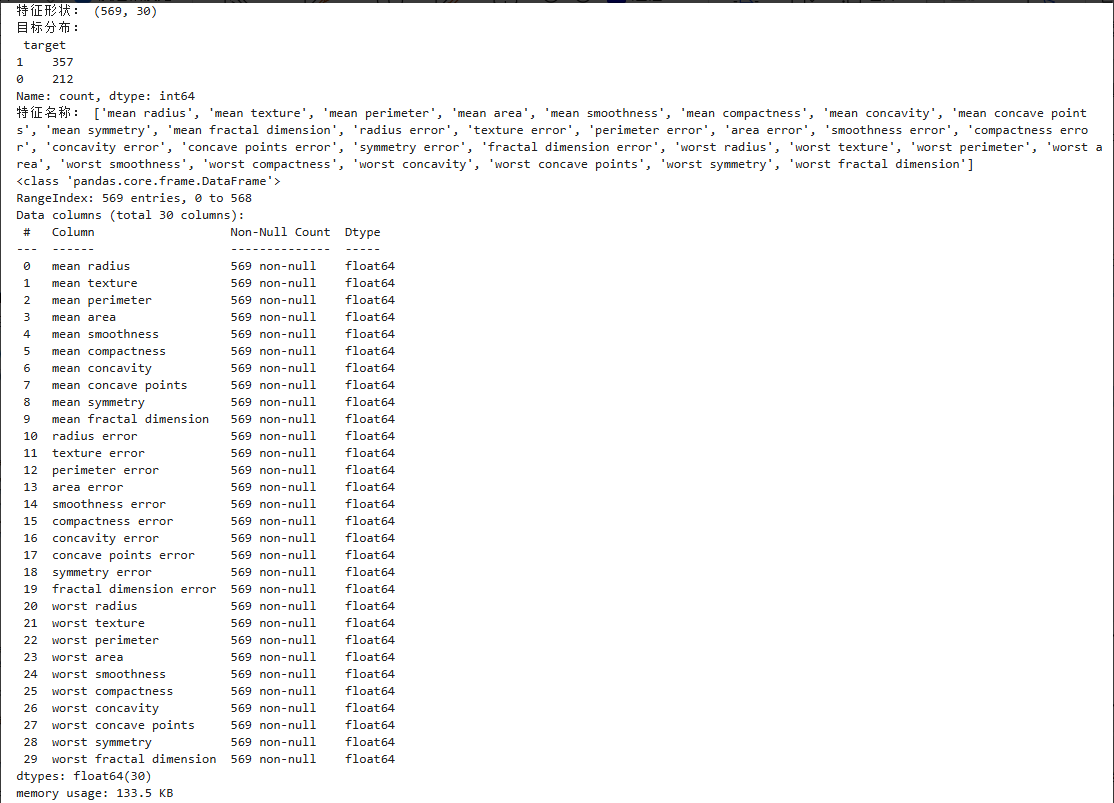
数据预处理
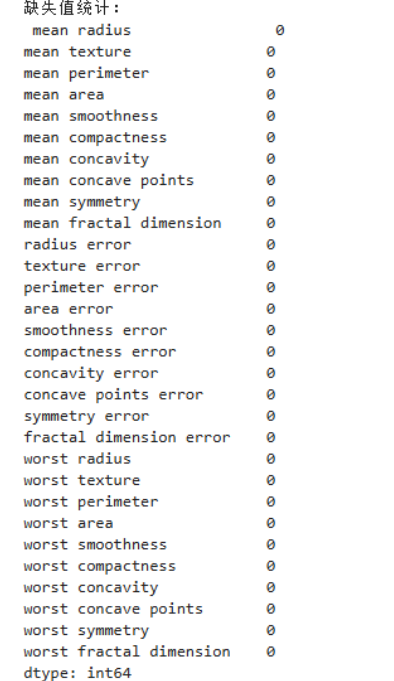
过程说明:
检查缺失值;
对特征进行标准化;
划分训练集与测试集。
代码:

代码解释:
isnull().sum() 可统计每列缺失值数量,此数据无缺失。
StandardScaler 将特征转为均值 0、方差 1,有利于收敛与模型性能。
Stratify=y 保证标签比例在训练/测试集保持一致。
决策树模型
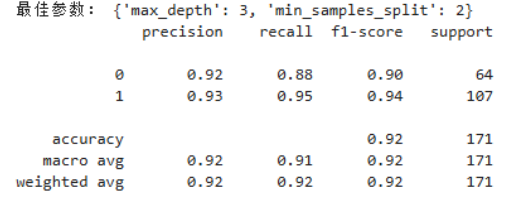
过程说明:使用 DecisionTreeClassifier,通过网格搜索调整 max_depth 与 min_samples_split。
代码:
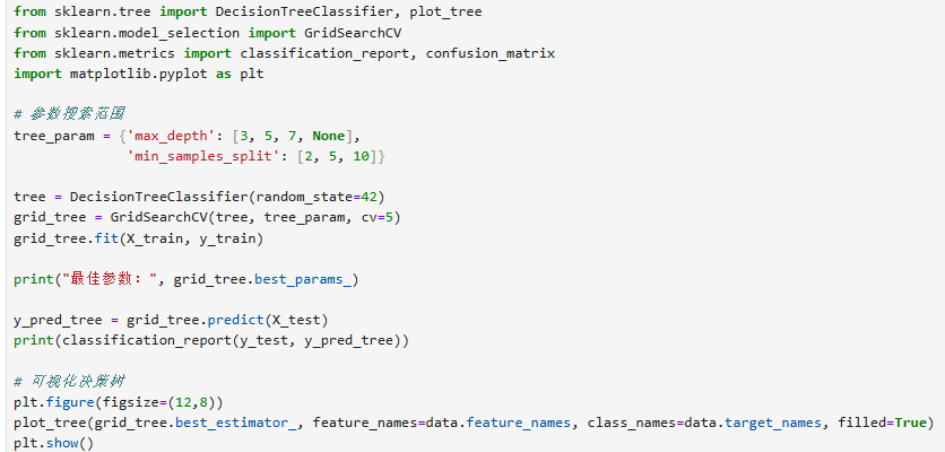
代码解释:
GridSearchCV 在 5 折交叉验证基础上寻找最优参数。
classification_report 包含精确率、召回率、F1 分数与支持度。
支持向量机 (SVM)
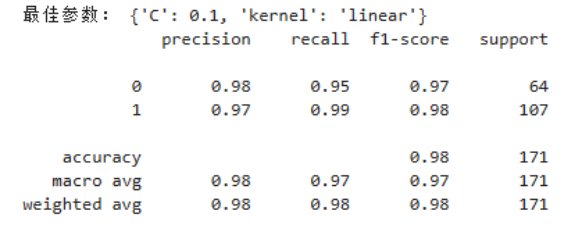
过程说明:使用 SVC,调整核函数 kernel 与惩罚参数 C。
代码:

代码解释:
linear 核适合线性可分数据;rbf 核可映射到高维空间。
朴素贝叶斯
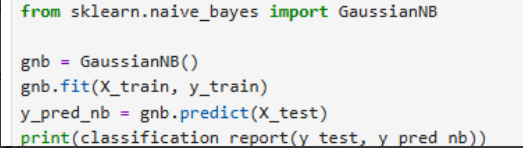
过程说明:使用 GaussianNB,无需参数搜索。
代码:
代码解释:
高斯朴素贝叶斯假设特征遵循高斯分布。
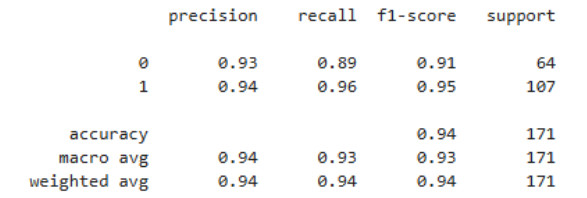
随机森林
过程说明:使用 RandomForestClassifier,调整 n_estimators 和 max_depth。
代码:
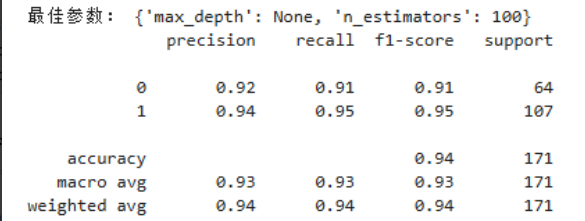
代码解释:
随机森林通过多数投票结合多棵树减少过拟合。
模型性能比较与分析
过程说明:汇总各模型的准确率、召回率和 F1 分数,绘制对比柱状图。
代码:
代码解释:
plot(kind='bar') 绘制柱状图,直观对比。
模型优缺点对比及推荐
根据本次乳腺癌数据集实验结果与模型特性:
推荐模型:SVM
在测试集上取得最高的准确率(0.977)、召回率(0.991)和 F1 分数(0.981),最适合对良恶性样本进行精确分类。
对该数据集线性或近线性可分特性表现优异,但应注意调参和计算开销。
备用模型:随机森林
性能次于 SVM,但也达到 0.936 的准确率,具有更强的抗噪能力和容错性,且无需复杂核技巧。
不推荐模型:单棵决策树与朴素贝叶斯
单棵决策树易过拟合且性能受限,朴素贝叶斯假设不完全满足,导致少量性能差距。
综合考虑性能、可解释性与计算成本,SVM 是乳腺癌预测任务中的首选模型,随机森林可作为兼顾稳定性的备选方案。
四、思考:
1. 在本次实验中,不同机器学习算法在乳腺癌预测任务中的性能表现有何差异?分析造成这种差异的可能原因;
答: SVM 最佳:在本实验中,SVM 凭借最高的准确率(0.977)、召回率(0.991)和 F1 分数(0.981)领先于其他模型。原因在于乳腺癌数据集的特征空间对良恶性样本而言近似线性可分,SVM 的线性/核方法能够有效划分这两类样本,同时其最大化间隔的策略也增强了对噪声与少数异常点的鲁棒性。
· 随机森林稳健:随机森林以 0.936 的准确率位列第二,它通过集成多棵决策树并投票减少了单树过拟合带来的方差,因而在数据中存在较多变量交互或噪声时仍能保持较好性能。不过其计算开销和模型体积都大于单棵树。
朴素贝叶斯快捷:高斯朴素贝叶斯取得了 0.936 的准确率(F1=0.949),训练速度最快、内存占用最小,但其“特征条件独立”假设在实际特征高度相关时难以满足,因而略逊于 SVM/随机森林。
单棵决策树:虽然直观可解释、可视化友好,但在本实验中表现最差(准确率≈0.924),原因是单树容易对训练集过拟合,且对噪声和极端值敏感。
2.当数据集规模增大或特征数量增多时,预测上述各算法的性能变化趋势,并解释原因。
答:
决策树/随机森林
优点:可并行构建多树,水平扩展效果好;随机森林在大样本量下方差收敛更快,且可通过设置 max_depth、n_estimators 控制复杂度。
缺点:随着特征数量和样本量增加,单棵树的训练时间和内存需求呈指数或多项式增长;特征维度过高时每棵树所需搜索的切分点爆炸式增多,整体计算成本显著上升。
SVM
优点:在高维空间依旧保持线性可分或可借助核方法映射后线性可分的特性;维度增加并不显著影响划分效果。
缺点:经典 SVM 的训练复杂度与样本数、特征数都呈二次甚至三次增长,大规模数据集下训练时间和内存瓶颈明显,需要借助核近似、分布式算法或随机特征映射等技术。
朴素贝叶斯
优点:对高维稀疏数据(如文本分类)极为友好,训练与预测均为线性复杂度,且能增量更新;特征维度增大时模型训练速度下降不明显。
缺点:假设条件独立,特征之间高度相关或分布非高斯时性能受限;数据量增大对其概率估计影响有限,但假设偏差仍是瓶颈。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 60
60 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)