【Shap解释Transformer模型】基于pytorch建立transformer模型,对nhanes数据库的下载数据进行二分类,最后用shap解释模型
Shap解释Transformer模型
用Transformer模型对从nhanes数据库中下载的数据进行分类,用了4层encoder和1层全连接层,之后对模型进行评估,计算测试集准确率、召回率、f1分数等指标,绘制ROC曲线,最后用shap解释模型,并绘制自变量重要性汇总图、单变量依赖图等8类图片。
数据说明:
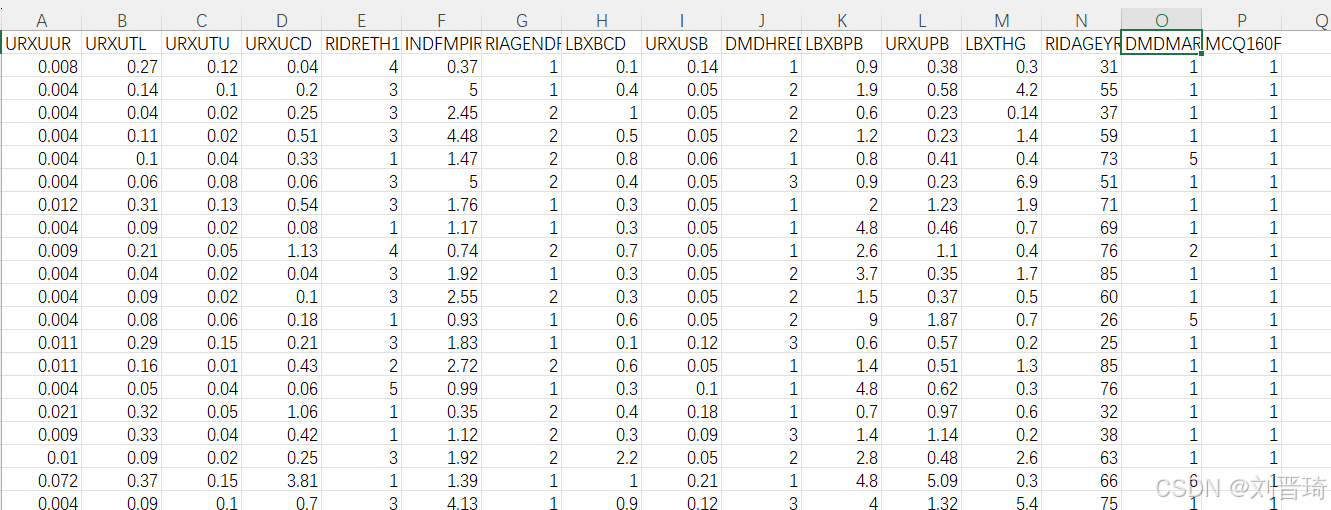
源数据在“mydata.xlsx“文件中,如下所示,A列到O列是自变量(共15个自变量),第一行是变量名称,数据是从nhanes数据库中下载的,不知道含义的可以在网站中搜索(NHANES Variables (clinicalscientists.cn))。P列是结局变量,0或1,二分类。
源代码使用说明:
代码文件是“transformer做卒中分类.py“,建议用pycharm打开,运行结束后可以看到所有的图片和变量。建模流程说明如下:
第一步 导入python第三方库
首先保证你安装了下图中的库,如果运行报错,可以查看各个库的版本是否太低,大于等于我用的版本就可以

Python版本:3.10.0
Pycharm版本:2024.1
Shap库版本:0.46.0
Torch版本:2.4.1
Pandas版本:2.2.3
Sickit-learn版本:1.5.2
Matplotlib版本:1.9.2
Numpy版本:2.0.2
第二步 定义运行参数
必须要自行修改的变量是path,替换成自己电脑中的文件路径即可,其余变量可自行修改。
如果要进行多分类的预测,还需要修改num_classes参数,

第三步 提取数据集以及定义transformer模型
具体可以看代码中的注释
因为是二分类,所以只用到了Transformer的Encoder模块,使用了4层encoder和1层全连接网络的结果,没有用embedding,因为自变量本身就有15个维度,而且全是数值,相当于自带embedding
第四步 评估模型
计算模型在测试集上的准确率、召回率、精准率等等指标,并且绘制ROC曲线

第五步 shap解释
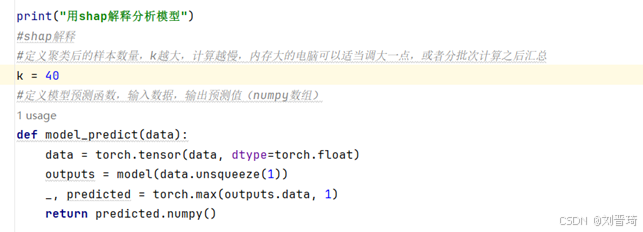
使用shap库中kernel解释器解释transformer模型,kernel可以解释任意机器学习模型,缺点是精确度差一点,以及计算速度慢,由于测试集数据量较大(包括7665个样本),为了提高计算速度,首先对测试集进行聚类,参数k是聚类后的样本数量,k越大,shap值计算速度越慢,但是相应的画出的图会更好看,请各位根据自己的电脑情况进行取舍,这里取40。
如果电脑性能不足,但是又想要大样本的shap值,k值可以取大一点,但是计算shap值的时候分块计算,如每次计算40个,计算完成后在将结果合并。
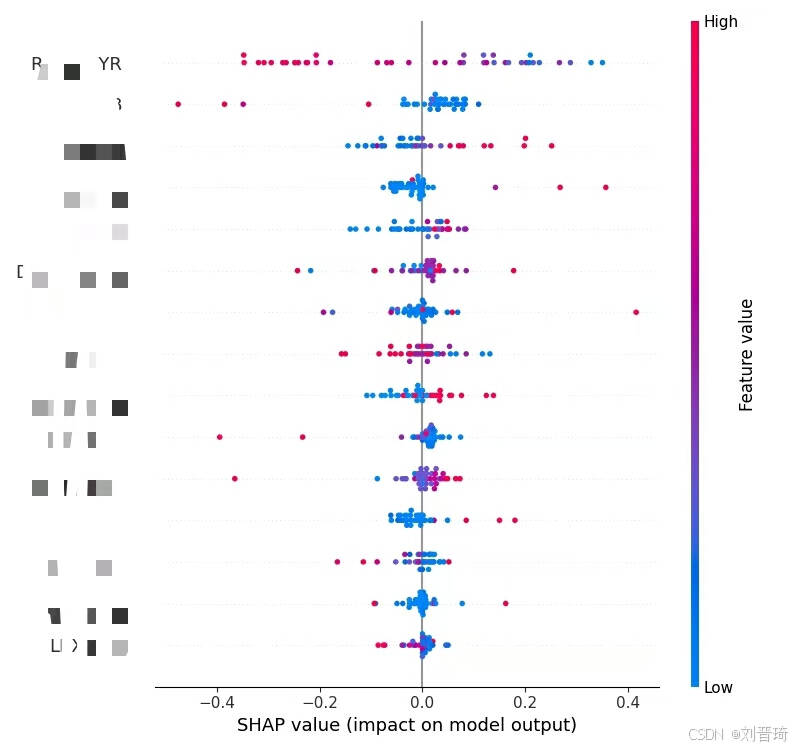
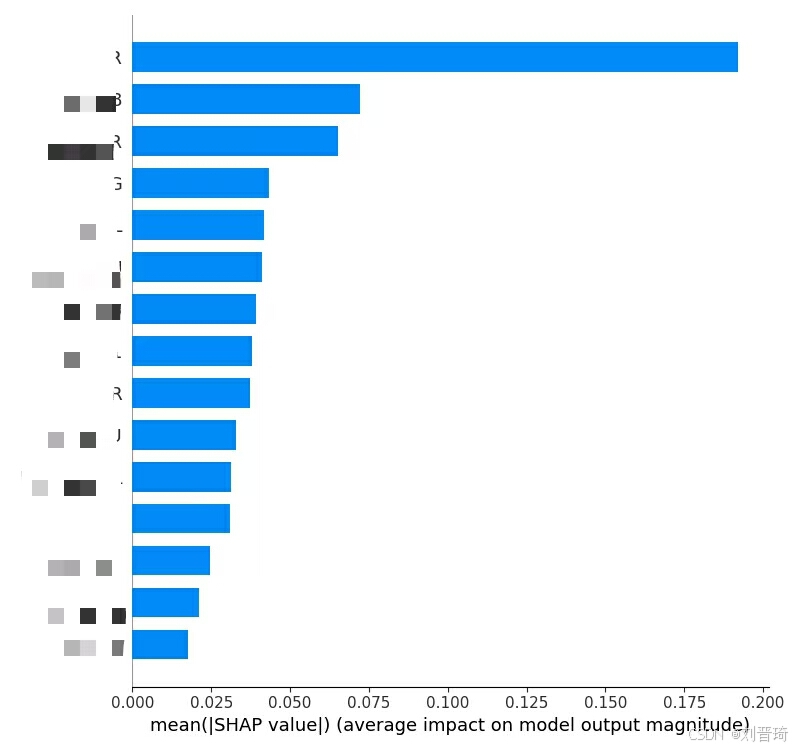
接下来是绘制各种图,共9张,包括测试集ROC曲线、自变量重要性汇总图、自变量重要性柱状图、单个变量的依赖图、单个变量的力图、单个样本的决策图、多个样本的决策图、热图、单个样本的解释图。部分结果如下所示。
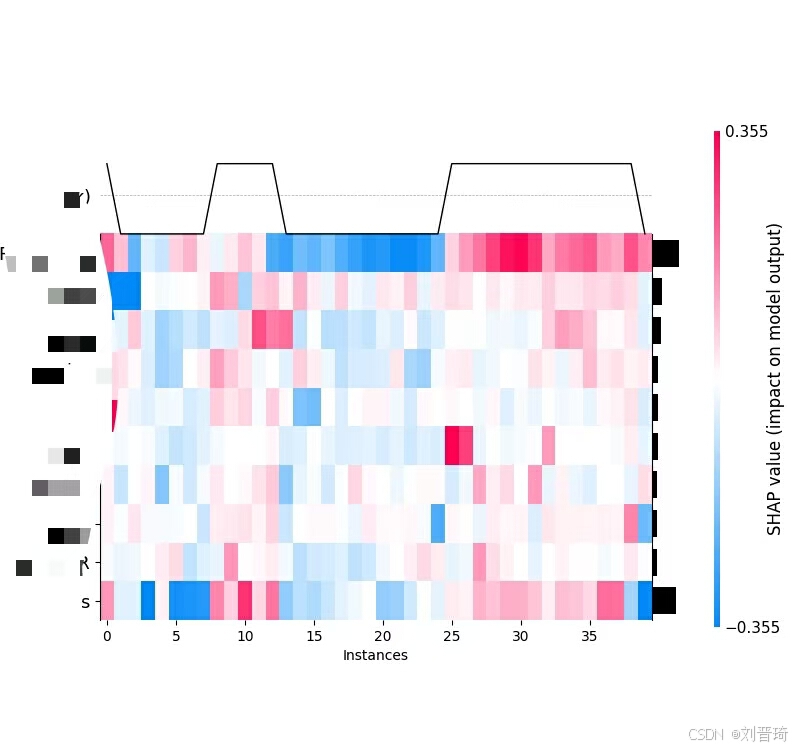
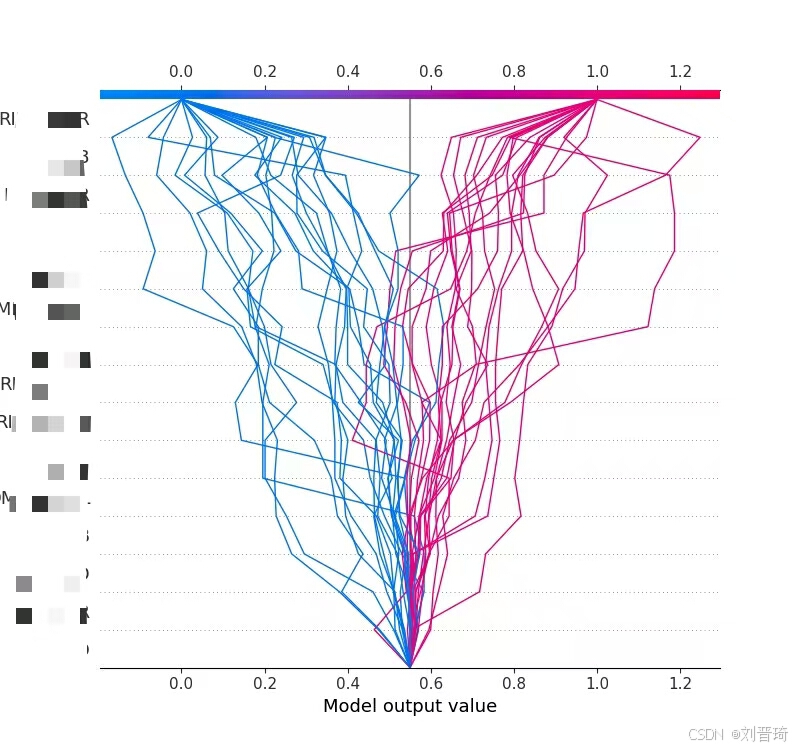
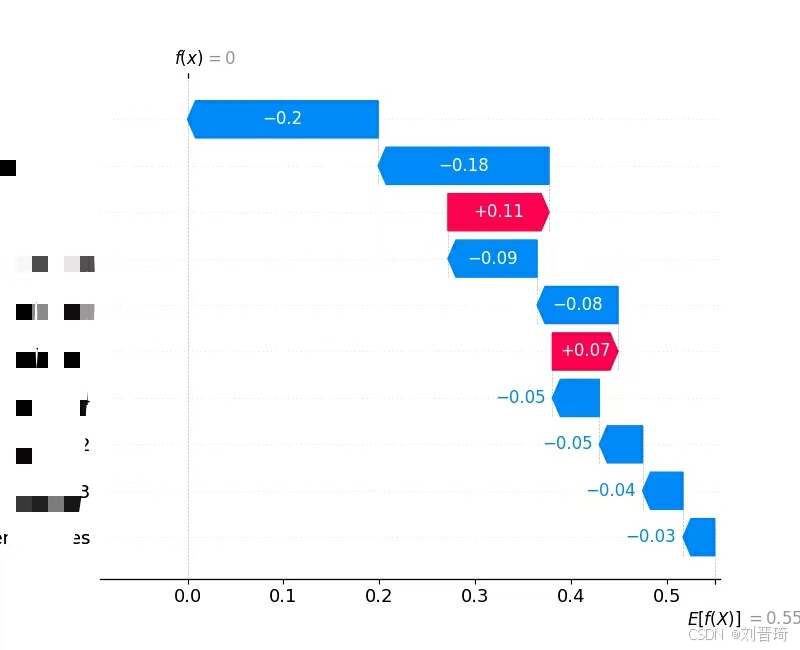
Pycharm中运行结果如下所示。
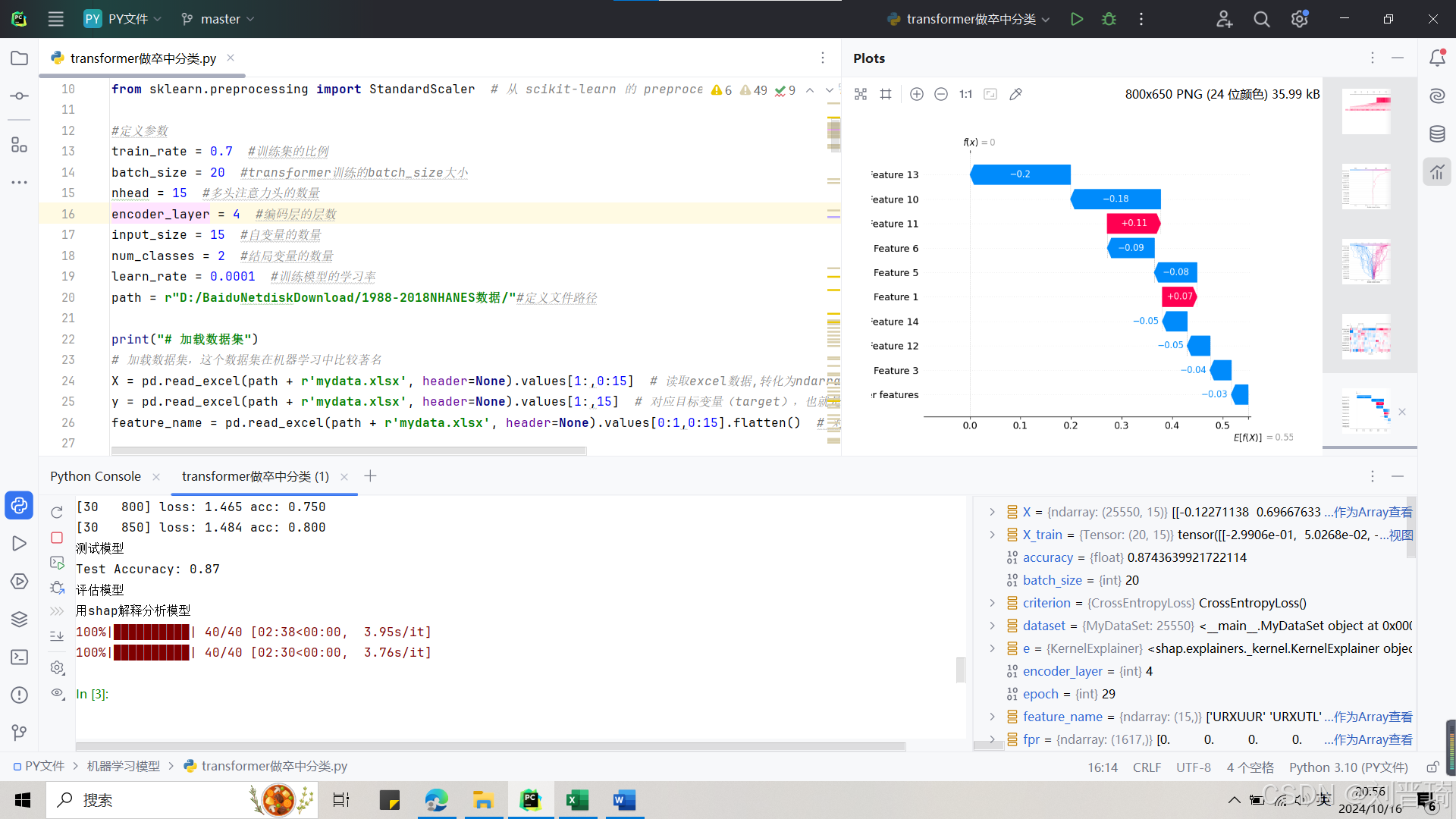
右上角是用shap解释transformer绘制的各种图片,
右下角是代码运行产生的各种变量,
左下角是交互命令行,运行结束之后可以继续输入命令,
代码纯手写,shap解释部分替大家踩了很多坑,终于整理出了可用的模板,谢谢理解~
【闲鱼链接】:https://m.tb.cn/h.gEYCNMJ?tk=JS183Ofa5F8
包括数据集、源代码、运行结果图
如链接失效,闲鱼或小红书搜索卷卷餐厅就可以看到啦

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)