MySQL数据库管理神器Navicat实战工具包(含密钥)
在MySQL数据库管理与开发体系中,第三方图形化工具(如Navicat、phpMyAdmin、DBeaver等)承担着连接交互、结构设计、数据操作与性能监控等关键职能。其中,Navicat凭借其跨平台支持、直观界面和深度集成能力,成为开发者与DBA广泛采用的高效工具。创建报表的第一步是建立数据源连接。可通过以下 SQL 示例获取订单销售趋势数据:-- 获取近30天每日销售额汇总SELECT在报表设

简介:Navicat是一款专为MySQL设计的高效数据库管理与开发工具,提供直观的图形界面和丰富的功能模块,涵盖连接管理、数据库设计、SQL编辑、数据同步与备份恢复等核心操作。本工具包集成Navicat完整功能并包含密钥,支持MySQL及MariaDB等多种版本,适用于新手和专业开发者,显著提升数据库操作效率与安全性,是MySQL用户必备的全流程管理解决方案。 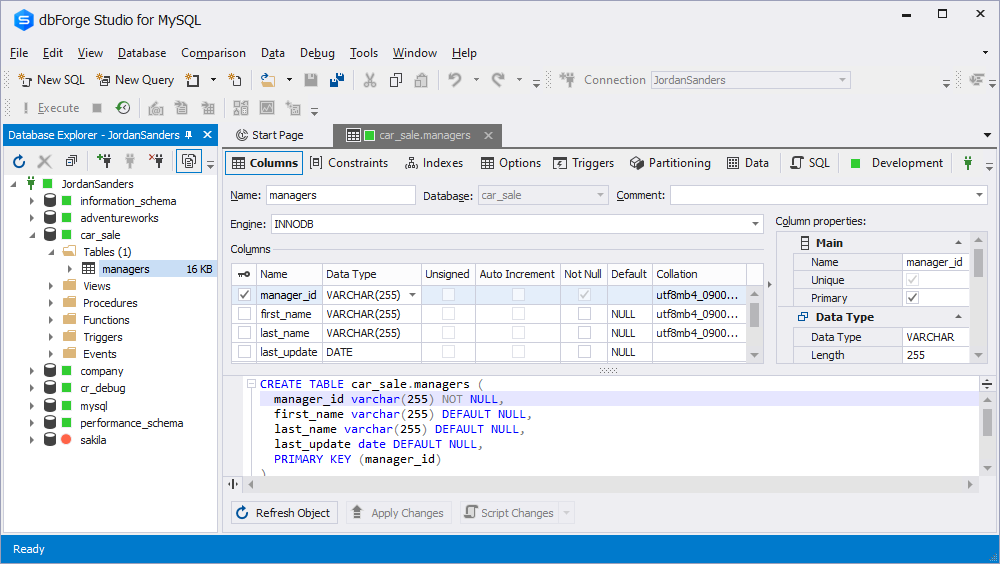
1. MySQL数据工具概述与核心功能解析
1.1 MySQL数据库生态中的工具定位
在MySQL数据库管理与开发体系中,第三方图形化工具(如Navicat、phpMyAdmin、DBeaver等)承担着连接交互、结构设计、数据操作与性能监控等关键职能。其中,Navicat凭借其跨平台支持、直观界面和深度集成能力,成为开发者与DBA广泛采用的高效工具。
1.2 核心功能模块概览
Navicat集成了数据库连接管理、可视化建模、智能SQL编辑、批量数据传输、安全访问控制及自动化运维六大核心模块。通过统一界面整合复杂操作,显著降低人为错误率并提升工作效率。
1.3 工具优势与应用场景匹配
相较于命令行操作,Navicat在多环境切换、异构数据库同步、报表生成等场景中展现出更强的适应性,尤其适用于需要高频交互与团队协作的企业级MySQL应用系统维护与开发。
2. 数据库可视化设计与智能开发实践
在现代数据库开发流程中,传统的命令行操作已难以满足日益复杂的系统设计需求。随着软件工程方法论的演进和开发者对效率、可维护性要求的提升,数据库的可视化设计与智能化开发工具逐渐成为企业级应用架构中的关键支撑环节。Navicat 等主流数据库管理工具通过集成图形化建模、智能SQL编辑、自动结构生成等高级功能,极大地降低了数据库设计门槛,提升了团队协作效率,并为后期运维优化提供了可视化的分析路径。
本章聚焦于如何利用现代化数据库工具实现从概念模型到物理结构的高效转化,深入探讨数据库对象建模的理论基础,并结合 Navicat 平台展开具体操作实践。重点涵盖实体-关系模型构建、表结构约束配置、视图与存储过程的图形化创建、ER图反向工程以及智能SQL编辑器的核心功能机制。通过理论与实操相结合的方式,帮助具备5年以上经验的技术人员重新审视数据库设计流程,挖掘工具链在复杂业务场景下的深层潜力。
2.1 数据库对象建模的理论基础
数据库对象建模是整个数据架构设计的起点,其核心目标是在业务需求与技术实现之间建立清晰、一致且可扩展的数据抽象层。良好的建模不仅决定了系统的性能边界,也直接影响后续开发、测试与维护的成本。尤其在微服务架构普及的当下,跨服务数据一致性、领域驱动设计(DDD)中的聚合根划分等问题,均依赖于前期严谨的建模工作。因此,掌握数据库建模的理论基础,已成为资深数据库工程师和后端架构师不可或缺的能力。
建模过程通常分为三个阶段:概念建模、逻辑建模和物理建模。概念建模关注业务实体及其关系,不涉及具体数据库实现;逻辑建模则将概念模型转化为规范化的关系结构,明确主键、外键、属性类型等要素;物理建模则是针对特定数据库管理系统(如MySQL)进行的最终落地设计,包括索引策略、分区方案、字符集选择等细节。这一递进式流程确保了设计既符合业务语义,又能适应底层存储引擎的特性。
在实际项目中,常见的建模错误包括冗余字段未消除、缺乏必要的唯一约束、过度使用宽表导致查询性能下降等。这些问题往往源于对数据库设计范式的理解不足。因此,深入理解关系型数据库的设计原则,尤其是规范化理论,是避免“技术债”积累的前提。
2.1.1 关系型数据库设计范式简析
数据库设计范式是一组用于指导关系模式优化的标准,旨在减少数据冗余、提高数据一致性并防止更新异常。目前公认的范式共有六种,但实践中主要应用前五种,其中第一范式(1NF)至第三范式(3NF)最为关键。
| 范式级别 | 核心要求 | 典型问题示例 |
|---|---|---|
| 第一范式 (1NF) | 所有属性必须是原子性的,不可再分 | 用户地址字段包含“省,市,区”,无法单独查询市级信息 |
| 第二范式 (2NF) | 满足1NF,且所有非主属性完全依赖于整个候选键 | 复合主键为(订单ID, 商品ID),但“客户姓名”仅依赖于订单ID |
| 第三范式 (3NF) | 满足2NF,且不存在非主属性之间的传递依赖 | “员工表”中“部门编号 → 部门经理”,而“员工”依赖“部门编号”间接依赖“部门经理” |
| 巴科斯-科德范式 (BCNF) | 每个决定因素都必须是超键 | 存在多个候选键时可能出现函数依赖冲突 |
| 第四范式 (4NF) | 消除多值依赖 | 一个教师可以教授多门课程,也可以属于多个研究组,形成独立的多值关系 |
以一个典型的电商订单系统为例,若将订单详情直接嵌套在订单主表中:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
product_list JSON, -- 包含多个商品信息
total_amount DECIMAL(10,2)
);
该设计违反了第一范式,因为 product_list 是非原子字段。正确的做法是将其拆分为两个表:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_name VARCHAR(100),
total_amount DECIMAL(10,2),
created_at DATETIME
);
CREATE TABLE order_items (
item_id INT AUTO_INCREMENT PRIMARY KEY,
order_id INT,
product_name VARCHAR(100),
quantity INT,
unit_price DECIMAL(8,2),
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);
代码逻辑逐行解读:
- 第1–5行:定义
orders表,仅保留与订单整体相关的字段,确保每列均为原子值。 - 第7–13行:创建
order_items表,用于存储订单中的每一个商品条目,实现一对多关系。 - 第12行:设置外键约束,保证每个订单项必须对应一个有效订单,增强数据完整性。
这种分解方式不仅满足1NF,也为后续支持2NF和3NF奠定了基础。例如,若原表中还包含“客户电话”字段,而该字段仅由客户决定,则应进一步提取出 customers 表,避免因客户信息变更而导致大量重复更新。
值得注意的是,在高并发读写场景下,过度规范化可能导致频繁的JOIN操作影响性能。此时可适度采用反规范化策略,如在订单表中冗余客户姓名,但需配合缓存机制或ETL任务保持一致性。这体现了“规范与性能”的权衡艺术,也是高级数据库设计者的决策能力体现。
2.1.2 实体-关系模型(ER模型)构建原理
实体-关系模型(Entity-Relationship Model, ER模型)是由Peter Chen于1976年提出的一种用于描述现实世界数据结构的概念工具。它通过“实体”、“属性”和“关系”三个基本元素,建立起用户可直观理解的数据蓝图,是数据库概念设计阶段的核心表达形式。
在一个典型的ER图中:
- 实体 (矩形表示)代表一类具有相同属性的对象集合,如“学生”、“课程”;
- 属性 (椭圆表示)描述实体的特征,如学生的“学号”、“姓名”;
- 关系 (菱形表示)反映实体间的关联,如“选课”连接“学生”与“课程”。
erDiagram
STUDENT ||--o{ ENROLLMENT : "注册"
COURSE ||--o{ ENROLLMENT : "开设"
STUDENT {
string student_id
string name
date birth_date
}
COURSE {
string course_code
string title
int credits
}
ENROLLMENT {
string enrollment_id
date enroll_date
string grade
}
上述Mermaid流程图展示了一个简单的选课系统ER模型。其中:
- STUDENT 与 ENROLLMENT 构成一对多关系(一个学生可注册多个选课记录);
- COURSE 与 ENROLLMENT 同样为一对多;
- ENROLLMENT 作为关联实体(junction entity),承载了多对多关系的具体实例。
ER模型的优势在于其高度抽象性,使得业务分析师、产品经理和技术人员可以在同一语言体系下沟通数据需求。例如,“一名学生只能注册一次同一门课程”这样的业务规则,可以通过在 ENROLLMENT 表上添加唯一复合索引来实现:
ALTER TABLE enrollment ADD CONSTRAINT uk_student_course
UNIQUE (student_id, course_code);
此约束确保不会出现重复注册,体现了从业务语义到数据库实现的精准映射。
此外,ER模型支持三种基本关系类型:
- 一对一 (1:1):如员工与其工牌;
- 一对多 (1:N):如部门与其下属员工;
- 多对多 (M:N):如学生与课程,需引入中间表解决。
在Navicat中,ER图不仅可以手动绘制,还能基于现有数据库结构自动生成,实现“正向工程”与“反向工程”的双向同步。这对于已有系统的重构、文档生成及团队知识传递具有重要意义。
更进一步地,ER模型还可扩展为增强型ER模型(EER),支持继承、分类(specialization/generalization)和聚集(aggregation)等面向对象特性。例如,在银行系统中,“账户”可细分为“储蓄账户”和“支票账户”,它们共享部分属性但又有各自特有字段。这类复杂结构可通过子类实体建模,并在物理层通过“单一表继承”或“类表继承”等方式实现。
综上所述,掌握ER模型不仅是数据库建模的基础技能,更是连接业务逻辑与技术实现的桥梁。对于资深开发者而言,能够快速识别业务中的核心实体与关键关系,是设计高内聚、低耦合数据架构的前提条件。
2.2 Navicat中的可视化建模操作
Navicat 作为一款功能强大的数据库管理工具,提供了完整的可视化建模环境,使开发者无需编写DDL语句即可完成数据库结构的设计与调整。其图形界面支持拖拽式表创建、字段约束配置、视图与存储过程的可视化编辑,并能自动生成ER图,极大提升了数据库设计效率。尤其在敏捷开发和DevOps流程中,这种“所见即所得”的操作模式显著缩短了原型验证周期。
更重要的是,Navicat 支持多种数据库平台(MySQL、PostgreSQL、Oracle、SQL Server等),允许开发者在统一界面下进行跨数据库建模与迁移,特别适用于异构系统整合项目。以下将详细解析其在表结构设计、高级数据库对象创建及ER图管理方面的核心功能。
2.2.1 表结构设计与字段约束配置
在Navicat中创建新表可通过右键点击数据库→“新建表”进入可视化设计器。界面左侧为字段列表,右侧为字段属性面板,支持设置名称、数据类型、长度、是否允许NULL、默认值、自增、字符集、排序规则等。
常见字段类型及其适用场景如下表所示:
| 数据类型 | 说明 | 推荐使用场景 |
|---|---|---|
INT / BIGINT |
整数类型 | 主键、数量统计 |
VARCHAR(n) |
可变长字符串 | 用户名、标题、短文本 |
TEXT / LONGTEXT |
长文本 | 文章内容、日志 |
DECIMAL(M,D) |
精确小数 | 金额、利率 |
DATETIME / TIMESTAMP |
时间戳 | 创建时间、事件记录 |
ENUM |
枚举类型 | 状态字段(如’active’,’inactive’) |
字段约束是保障数据质量的关键手段。Navicat 提供以下几种主要约束类型的图形化配置入口:
- 主键(Primary Key) :唯一标识每一行,自动创建唯一索引;
- 外键(Foreign Key) :建立表间引用关系,支持级联更新/删除;
- 唯一键(Unique) :防止重复值插入;
- 检查约束(Check Constraint) :限制字段取值范围(MySQL 8.0+支持);
- 非空约束(Not Null) :强制字段必须有值。
例如,设计一个用户权限管理系统中的角色表:
CREATE TABLE roles (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL UNIQUE COMMENT '角色名称',
description TEXT,
status ENUM('active', 'inactive') DEFAULT 'active',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
参数说明与逻辑分析:
- id 使用 BIGINT 是为了支持大规模系统下的主键增长;
- name 设置为 NOT NULL 和 UNIQUE ,防止重名角色;
- status 使用 ENUM 类型限制合法状态值,避免脏数据;
- created_at 与 updated_at 自动维护时间戳,减少应用层负担。
在Navicat界面中,这些约束均可通过勾选选项框或下拉菜单完成配置,无需记忆SQL语法。同时,工具会实时校验输入合法性,如尝试为 VARCHAR(10) 输入超过10字符的内容时会提示警告。
此外,Navicat 还支持“设计模式”与“SQL模式”切换,方便开发者查看当前设计对应的DDL语句,便于版本控制与团队协作。
2.2.2 视图、触发器与存储过程的图形化创建
除了基本表结构,Navicat 还提供对高级数据库对象的可视化支持。
视图(View)
视图是一种虚拟表,常用于简化复杂查询、隐藏敏感字段或实现权限隔离。在Navicat中,可通过“新建视图”向导选择基础表并构造SELECT语句。
例如,创建一个只显示活跃用户的视图:
CREATE VIEW active_users AS
SELECT u.id, u.username, u.email, r.name AS role_name
FROM users u
JOIN user_roles ur ON u.id = ur.user_id
JOIN roles r ON ur.role_id = r.id
WHERE u.status = 'active';
该视图屏蔽了密码字段,仅暴露必要信息,适合前端接口调用。
触发器(Trigger)
触发器用于在INSERT、UPDATE或DELETE操作前后自动执行特定逻辑。Navicat提供事件类型、触发时机(BEFORE/AFTER)、执行语句的图形化设置。
示例:当订单状态变为“已发货”时,自动记录日志:
DELIMITER $$
CREATE TRIGGER after_order_shipped
AFTER UPDATE ON orders
FOR EACH ROW
BEGIN
IF OLD.status != 'shipped' AND NEW.status = 'shipped' THEN
INSERT INTO order_logs(order_id, action, timestamp)
VALUES(NEW.id, 'shipped', NOW());
END IF;
END$$
DELIMITER ;
逻辑解析:
- 使用 DELIMITER 修改语句结束符,避免内部 ; 提前终止定义;
- OLD 和 NEW 分别表示修改前后的行数据;
- 条件判断防止重复写入日志。
存储过程(Stored Procedure)
存储过程封装复杂业务逻辑,可在数据库层执行批量操作。Navicat支持参数输入、返回结果集等配置。
DELIMITER $$
CREATE PROCEDURE GetTopCustomers(IN limit_count INT)
READS SQL DATA
BEGIN
SELECT c.name, SUM(o.amount) AS total_spent
FROM customers c
JOIN orders o ON c.id = o.customer_id
GROUP BY c.id
ORDER BY total_spent DESC
LIMIT limit_count;
END$$
DELIMITER ;
此过程接受一个输入参数 limit_count ,返回消费额最高的客户列表,可用于报表生成。
2.2.3 ER图自动生成与反向工程应用
Navicat 最具价值的功能之一是ER图的自动生成与同步管理。通过“模型”→“逆向数据库到模型”,可将现有数据库结构转换为可视化ER图,支持缩放、布局调整、颜色标记等功能。
更进一步,Navicat 支持“正向工程”——即将ER图导出为SQL脚本,用于在目标数据库中创建结构。这对于新项目初始化、测试环境搭建极为便利。
此外,ER图还可用于差异对比。通过加载两个不同版本的模型,Navicat 能自动识别新增表、字段变更、约束修改等内容,并生成迁移脚本,极大降低人工出错风险。
graph TD
A[源数据库] -->|反向工程| B(ER模型)
B --> C{修改设计}
C --> D[生成SQL]
D --> E[目标数据库]
E -->|验证| F[结构一致性]
该流程图展示了基于ER模型的数据库演化路径,体现了从物理结构到逻辑模型再回到物理实现的闭环管理思想。
对于大型系统而言,定期生成并归档ER图,是保障数据资产可追溯、可审计的重要措施。
3. 数据操作与高效导入导出策略
在现代数据库应用开发和运维过程中,数据的增删改查(CRUD)操作是日常工作的核心环节,而批量数据的导入导出则是系统迁移、报表生成、数据分析等任务中不可或缺的技术支撑。随着企业数据量呈指数级增长,如何在保证数据一致性的同时实现高效的数据流转,已成为数据库工具必须解决的关键问题。Navicat 作为一款集可视化管理、智能开发与数据集成于一体的数据库客户端工具,在数据操作与导入导出方面提供了强大且灵活的功能体系。本章节将深入探讨基于 Navicat 的数据操作机制与高效导入导出策略,涵盖从基础 CRUD 操作到复杂异构数据迁移的全流程实践。
3.1 数据增删改查的操作逻辑与事务控制
数据库中最基本的操作即为“增(Insert)、删(Delete)、改(Update)、查(Select)”,统称为 CRUD 操作。这些操作不仅是应用程序访问数据的核心手段,也是数据库管理员进行数据维护的重要途径。在 Navicat 中,CRUD 操作不仅可以通过图形化界面完成,还可以通过 SQL 编辑器执行脚本,实现更精细的控制。更重要的是,所有修改类操作都应在事务控制下进行,以确保数据的一致性和可回滚性。
3.1.1 CRUD操作在Navicat中的实现路径
Navicat 提供了多种方式来执行 CRUD 操作,用户可以根据使用习惯选择最适合的方式。
图形化操作模式
对于非技术人员或希望快速查看和编辑数据的用户,Navicat 的“数据表”视图提供了直观的表格展示。双击打开任意数据表后,可以直接在网格中新增行、修改字段值或删除记录。例如,在 users 表中添加一条新用户记录:
| id | name | created_at | |
|---|---|---|---|
| 1 | 张三 | zhangsan@demo.com | 2025-04-05 10:00:00 |
只需在最后一行输入对应信息并保存,Navicat 将自动生成相应的 INSERT 语句提交至数据库。同样地,选中某行点击“删除”按钮即可触发 DELETE FROM users WHERE id = 1; 。
这种方式虽然便捷,但在处理大量数据或需要条件筛选时效率较低。此时应结合 SQL 查询窗口进行操作。
SQL 脚本执行模式
Navicat 内置的 SQL 编辑器支持完整的 SQL 语法编写。以下是一个典型的多步骤 CRUD 流程示例:
-- 开启事务
START TRANSACTION;
-- 插入新用户
INSERT INTO users (name, email, created_at)
VALUES ('李四', 'lisi@demo.com', NOW());
-- 更新指定用户邮箱
UPDATE users
SET email = 'zhangsan_new@demo.com'
WHERE name = '张三';
-- 删除已注销用户
DELETE FROM users
WHERE status = 'inactive' AND last_login < DATE_SUB(NOW(), INTERVAL 1 YEAR);
-- 查询验证结果
SELECT * FROM users WHERE name IN ('张三', '李四');
-- 若无误则提交,否则回滚
COMMIT;
-- ROLLBACK;
代码逻辑逐行分析:
- 第1行:
START TRANSACTION;显式开启一个事务,确保后续操作具备原子性。 - 第4–6行:使用
INSERT向users表插入一条包含姓名、邮箱和当前时间的新记录。 - 第9–11行:
UPDATE语句根据name字段匹配目标记录,并更新其邮箱地址。 - 第14–16行:
DELETE删除一年内未登录且状态为“非活跃”的用户,避免误删正常账户。 - 第19–20行:
SELECT用于验证前几步操作的结果是否符合预期。 - 最后两行:根据验证结果决定
COMMIT提交更改或ROLLBACK回滚,防止错误持久化。
该流程体现了良好的数据操作规范: 先预览、再执行、最后确认 。Navicat 支持在 SQL 编辑器中分步运行语句,并实时显示影响行数和查询结果,极大提升了操作安全性。
此外,Navicat 还提供“自动提交”开关设置。当关闭自动提交时,所有 DML 操作均处于事务中,直到手动提交;开启后每条语句独立生效,适用于只读查询场景。
| 模式类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 图形化编辑 | 单条数据修改、调试 | 直观易用,无需写 SQL | 不适合批量操作,缺乏灵活性 |
| SQL 脚本执行 | 批量处理、复杂逻辑、自动化 | 精确控制,支持事务与变量 | 需掌握 SQL 语法 |
| 自动提交模式 | 只读查询、测试环境 | 即时生效,响应快 | 容易造成意外数据变更 |
| 手动事务模式 | 生产环境关键数据操作 | 可回滚,保障数据一致性 | 操作流程较长,需人工干预 |
建议实践 :在生产环境中始终关闭自动提交,所有数据变更操作封装在
START TRANSACTION ... COMMIT/ROLLBACK块中,并在执行前备份相关表。
3.1.2 多表联合查询与结果集处理技巧
在实际业务中,单一表的数据往往无法满足需求,通常需要通过 JOIN 关联多个表获取完整信息。Navicat 提供了强大的查询构建器(Query Builder),也支持直接编写复杂 SQL 实现高性能检索。
考虑如下两个表结构:
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10,2),
order_date DATETIME
);
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(50),
city VARCHAR(30)
);
要统计每个城市的订单总额,可以使用以下 SQL:
SELECT
c.city AS 城市,
COUNT(o.order_id) AS 订单数量,
SUM(o.amount) AS 总金额
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.user_id
GROUP BY c.city
HAVING SUM(o.amount) > 1000
ORDER BY 总金额 DESC;
代码逻辑逐行解读:
- 第2–4行:选择输出字段,包括城市名称、订单计数和金额汇总。
- 第5行:主表为
customers,使用LEFT JOIN确保即使没有订单的城市也能显示(订单数为 NULL)。 - 第6行:连接条件设定
customer_id与user_id对应。 - 第7行:按城市分组聚合数据。
- 第8行:
HAVING过滤掉总金额小于等于 1000 的城市,注意此处不能用WHERE,因为WHERE在分组前过滤,而聚合函数只能在HAVING中使用。 - 第9行:按总金额降序排列,便于优先查看高价值地区。
Navicat 的查询结果窗口支持导出为 Excel、CSV 或 PDF,并可对列进行排序、筛选和高亮异常值。此外,右键点击结果行还可快速跳转至关联表的原始数据,极大提升排查效率。
flowchart TD
A[开始查询] --> B{是否涉及多表?}
B -->|是| C[构建JOIN关系]
B -->|否| D[单表SELECT]
C --> E[确定连接类型: INNER/LEFT/RIGHT]
E --> F[添加WHERE过滤条件]
F --> G[使用GROUP BY聚合]
G --> H[应用HAVING筛选组]
H --> I[ORDER BY排序]
I --> J[执行并返回结果集]
J --> K[结果可视化展示]
K --> L[可选: 导出或进一步分析]
上述流程图清晰展示了多表联合查询的标准处理流程。Navicat 的 Query Builder 正是按照这一逻辑引导用户逐步构建 SQL,降低出错概率。
同时,针对大数据量查询,建议启用“限制结果集”功能(如 LIMIT 1000),避免一次性加载过多数据导致内存溢出或界面卡顿。可通过分页查询配合 OFFSET 和 LIMIT 实现渐进式浏览:
-- 分页查询第2页,每页20条
SELECT * FROM orders ORDER BY order_date DESC LIMIT 20 OFFSET 20;
此技术常用于后台管理系统中的列表展示模块,Navicat 支持将此类参数化查询保存为“查询模板”,供团队成员复用,提升协作效率。
3.2 批量数据导入导出的技术原理
在企业级应用中,经常面临将外部数据(如 Excel 报表、CSV 日志、JSON 接口响应)批量导入数据库,或将数据库内容导出用于分析或共享的需求。Navicat 提供了高度自动化的“导入向导”和“导出向导”,支持多种格式转换与映射配置,显著降低了数据流转的技术门槛。
3.2.1 支持的数据格式及其转换机制(CSV、Excel、JSON等)
Navicat 支持以下主流数据格式的双向转换:
| 格式类型 | 导入支持 | 导出支持 | 特点说明 |
|---|---|---|---|
| CSV | ✅ | ✅ | 轻量通用,适合日志、ETL 场景 |
| Excel | ✅ (.xls/.xlsx) | ✅ | 兼容 Office,支持多 sheet |
| JSON | ✅ | ✅ | 层次结构友好,适合 API 数据 |
| XML | ✅ | ✅ | 标准化标签,常用于配置文件 |
| SQL | ✅ | ✅ | 导出为 INSERT 语句,便于重建 |
| TXT | ✅ | ✅ | 自定义分隔符,灵活性高 |
以从 CSV 文件导入用户数据为例,假设源文件 users_import.csv 内容如下:
name,email,age,registered_date
王五,wangwu@example.com,28,2024-03-15
赵六,zhaoliu@test.org,34,2024-04-01
在 Navicat 中启动“导入向导”:
1. 选择目标表 users
2. 指定文件路径并选择格式为 CSV
3. 设置字段分隔符为逗号( , ),文本限定符为双引号( " )
4. 映射 CSV 列到数据库字段
5. 配置编码(如 UTF-8)、日期格式( YYYY-MM-DD )
6. 选择导入模式:追加、替换或删除后插入
7. 预览并执行
Navicat 在后台会生成类似以下的临时处理逻辑:
# (伪代码示意)Navicat 内部解析流程
import csv
from datetime import datetime
with open('users_import.csv', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
# 类型转换
age_int = int(row['age'])
date_obj = datetime.strptime(row['registered_date'], '%Y-%m-%d')
# 构造 SQL
sql = """
INSERT INTO users (name, email, age, created_at)
VALUES (%s, %s, %d, %s)
""" % (row['name'], row['email'], age_int, date_obj)
execute(sql) # 执行插入
尽管用户无需编写代码,但理解底层转换机制有助于排查问题。例如,若 CSV 中含有中文字符而编码设为 GBK,则可能导致乱码;若日期格式不匹配,则可能抛出转换异常。
对于 JSON 文件,Navicat 支持扁平化嵌套结构。例如:
[
{
"user": {
"id": 101,
"profile": {
"name": "孙七",
"contact": {"email": "sunqi@demo.com"}
}
},
"signup_date": "2025-01-10"
}
]
可通过 XPath 式路径提取字段:
- $.user.id → 映射到 user_id
- $.user.profile.name → 映射到 name
- $.user.profile.contact.email → 映射到 email
这种能力使得 Navicat 成为对接 RESTful API 数据的理想中间工具。
3.2.2 字段映射与编码兼容性问题解决方案
字段映射是导入导出过程中的关键环节,尤其在源数据与目标表结构不一致时尤为重要。
字段映射策略
Navicat 提供三种映射模式:
| 映射方式 | 说明 |
|---|---|
| 自动映射 | 按列名或位置自动匹配,适合结构一致的情况 |
| 手动映射 | 用户拖拽源列到目标字段,支持表达式转换 |
| 忽略未映射字段 | 允许部分字段不参与传输,提高容错性 |
示例:现有 CSV 包含 full_name 和 birth_year ,但目标表只有 first_name 和 age 。此时可通过手动映射 + 表达式实现转换:
-- 表达式示例(Navicat 支持内置函数)
SUBSTRING_INDEX(full_name, ' ', 1) -- 提取姓氏作为 first_name
YEAR(CURDATE()) - birth_year -- 计算年龄
编码兼容性处理
常见编码问题及解决方案如下表所示:
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 中文显示为问号或乱码 | 源文件编码非 UTF-8 | 在导入向导中明确指定编码(如 UTF-8、GBK) |
| 特殊符号(é, ü)异常 | 字符集不支持 | 确认数据库表字符集为 utf8mb4_unicode_ci |
| 导出 Excel 出现编码错误 | Excel 默认 ANSI 打开 | 导出时选择 .xlsx 格式或添加 BOM 头 |
| 数字被识别为字符串 | CSV 缺少类型提示 | 使用“预览并修正数据类型”功能 |
特别提醒:MySQL 的 utf8 实际仅支持 3 字节字符,无法存储 emoji(如 😊),应使用 utf8mb4 字符集。Navicat 在新建连接时建议勾选“使用 utf8mb4”选项。
graph LR
A[原始数据文件] --> B{判断编码格式}
B -->|UTF-8| C[直接读取]
B -->|GBK/GB2312| D[转码为 UTF-8]
B -->|未知| E[尝试自动检测]
C --> F[解析字段结构]
D --> F
E --> F
F --> G[映射到目标表字段]
G --> H{是否存在类型冲突?}
H -->|是| I[提示用户修正或强制转换]
H -->|否| J[执行批量插入]
J --> K[记录成功/失败行数]
K --> L[生成日志报告]
该流程图揭示了 Navicat 在处理编码与映射时的内部决策路径。了解此机制有助于提前准备数据,减少失败率。
3.3 数据迁移流程中的实践要点
跨数据库迁移是系统升级、云迁移或架构重构中的高频操作。Navicat 提供“数据传输”功能,支持同构(MySQL→MySQL)与异构(MySQL→PostgreSQL)迁移。
3.3.1 迁移任务配置与进度监控
创建迁移任务步骤如下:
1. 选择源连接与目标连接
2. 选择迁移对象:数据库、表、视图等
3. 配置选项:是否复制结构、是否包含数据、索引处理方式
4. 映射 schema 名称(如源为 db_prod → 目标为 db_test )
5. 启动任务并实时监控进度条与日志
Navicat 会在后台生成一系列 DDL 与 DML 操作,例如:
-- 创建表结构
CREATE TABLE target_db.users LIKE source_db.users;
-- 插入数据(分批提交以减少锁表时间)
INSERT INTO target_db.users SELECT * FROM source_db.users LIMIT 1000 OFFSET 0;
INSERT INTO target_db.users SELECT * FROM source_db.users LIMIT 1000 OFFSET 1000;
-- ...
迁移过程中可通过“暂停/恢复”功能控制节奏,避免影响线上服务性能。
3.3.2 异构数据库间的数据传输稳定性保障
不同数据库的 SQL 方言、数据类型存在差异,例如:
| MySQL 类型 | PostgreSQL 类型 | 转换注意事项 |
|---|---|---|
DATETIME |
TIMESTAMP |
格式兼容 |
TINYINT(1) |
BOOLEAN |
自动映射真假 |
AUTO_INCREMENT |
SERIAL |
需重设序列 |
TEXT |
TEXT |
直接对应 |
Navicat 内置类型映射引擎,可在迁移前预览转换方案,并允许用户手动调整。此外,建议启用“错误容忍模式”,跳过个别失败行而非中断整个任务。
为提升稳定性,推荐采用以下最佳实践:
- 分批次迁移大表(按主键区间分割)
- 关闭目标库外键约束临时加速插入
- 迁移完成后校验行数与 checksum
- 使用“结构同步”功能修复潜在差异
综上所述,Navicat 在数据操作与导入导出方面提供了从简单到复杂的全栈支持,既能满足初学者的易用性需求,又能为资深开发者提供精确控制能力。合理运用其功能,可大幅提升数据管理效率与可靠性。
4. 数据库安全管理与访问控制机制
在现代企业级数据库系统中,安全已成为不可忽视的核心要素。随着数据泄露事件频发、网络攻击手段不断升级,数据库作为核心资产的存储载体,其安全性直接关系到企业的运营稳定性和用户隐私保护。MySQL 作为广泛应用的关系型数据库管理系统,在默认配置下可能面临诸多安全隐患,如明文传输、弱密码策略、权限滥用等。因此,构建一套完整的数据库安全管理与访问控制机制,是保障数据完整性和机密性的关键所在。
本章聚焦于 Navicat 环境下的数据库安全实践 ,深入剖析从通信加密到身份认证,再到细粒度权限分配的全链路安全防护体系。首先探讨 SSL/TLS 加密通信的基本原理及其在 MySQL 中的技术实现基础;随后详细展示如何在 Navicat 客户端中配置 SSL 安全连接,并提供常见问题的诊断方法;最后系统解析 MySQL 内置的权限模型结构,并结合 Navicat 图形化工具演示用户角色创建、权限授予与回收的操作流程,帮助开发者和 DBA 构建符合最小权限原则的安全访问架构。
整个章节内容遵循“理论—部署—验证—优化”的递进逻辑,不仅涵盖协议层级的技术细节,还融合了实际操作中的最佳实践建议,确保读者能够在真实生产环境中有效落地安全策略。通过引入代码示例、参数说明表、Mermaid 流程图等多种表达形式,提升内容可读性与技术深度,满足具备五年以上经验的技术人员对高阶安全控制的理解需求。
4.1 SSL安全连接的理论支撑与部署前提
在分布式应用架构中,数据库通常部署于独立服务器或云实例上,客户端通过网络远程连接进行数据交互。这一过程中,若未启用加密机制,所有 SQL 查询语句、认证凭据(如用户名和密码)以及返回结果都将以明文形式在网络中传输,极易被中间人(Man-in-the-Middle, MITM)截获或篡改。为应对此类风险,SSL(Secure Sockets Layer)及其继任者 TLS(Transport Layer Security)成为保障数据库通信安全的标准解决方案。
4.1.1 加密通信原理与TLS/SSL协议作用
SSL/TLS 协议位于传输层(TCP)之上、应用层之下,旨在为两个通信实体之间建立一条安全通道。其核心功能包括:
- 数据加密 :使用对称加密算法(如 AES)对传输内容进行加密,防止窃听。
- 身份验证 :通过数字证书验证服务器(有时也包括客户端)的身份,防止伪装攻击。
- 数据完整性校验 :利用消息认证码(MAC)确保数据在传输过程中未被篡改。
当 MySQL 客户端与服务器建立连接时,若启用 SSL,则会触发一个称为“SSL 握手”的过程。该过程大致分为以下几个阶段:
sequenceDiagram
participant Client
participant Server
Client->>Server: 发起连接请求(Client Hello)
Server->>Client: 返回证书 + 支持的加密套件(Server Hello)
Client->>Server: 验证证书有效性,生成预主密钥并用公钥加密发送
Server->>Client: 解密预主密钥,双方基于它生成会话密钥
Client->>Server: 切换至加密通信模式
Server->>Client: 确认加密通道建立成功
上述流程展示了典型的 TLS 1.2 握手过程。其中,“证书”由受信任的 CA(Certificate Authority)签发,包含服务器的域名、公钥及有效期等信息。客户端需验证该证书是否合法、是否过期、是否匹配目标主机名,否则将拒绝连接。
在 MySQL 中,SSL 的启用依赖于 OpenSSL 或 yaSSL 库的支持。自 MySQL 5.7 起,默认编译版本已内置 SSL 功能。可通过以下命令检查当前服务器是否支持 SSL:
SHOW VARIABLES LIKE '%ssl%';
执行结果示例如下:
| Variable_name | Value |
|---|---|
| have_openssl | YES |
| have_ssl | YES |
| ssl_ca | /etc/mysql/certs/ca.pem |
| ssl_cert | /etc/mysql/certs/server-cert.pem |
| ssl_key | /etc/mysql/certs/server-key.pem |
参数说明:
- have_openssl 和 have_ssl :表示服务器是否具备 SSL 支持;
- ssl_ca :权威机构(CA)证书路径,用于验证客户端或服务器证书;
- ssl_cert :服务器自身的数字证书文件;
- ssl_key :服务器私钥文件,必须严格保密;
- 若这些值为空或为 DISABLED ,则表明尚未配置 SSL。
为了强制要求某些用户只能通过 SSL 连接,MySQL 提供了 REQUIRE SSL 子句。例如:
CREATE USER 'secure_user'@'%'
IDENTIFIED BY 'StrongPass!2024'
REQUIRE SSL;
此语句创建了一个仅允许通过 SSL 连接的用户。任何尝试非加密连接的行为都将被拒绝,并记录错误日志。
此外,还可以进一步限制用户使用 X.509 证书进行双向认证:
CREATE USER 'cert_user'@'%'
IDENTIFIED BY 'Pass123!'
REQUIRE SUBJECT '/CN=client.example.com';
这表示该用户必须提供特定主题名称的客户端证书才能登录。
综上所述,SSL 不仅解决了通信过程中的数据暴露问题,还能通过证书机制增强身份可信度,是构建安全数据库连接的第一道防线。
4.1.2 服务器证书与客户端验证流程
要实现完整的 SSL 安全连接,除了服务器端配置外,客户端也必须正确处理证书验证流程。特别是在使用 Navicat 这类图形化工具时,理解证书信任链的形成机制至关重要。
证书类型与信任链
在 PKI(Public Key Infrastructure)体系中,证书分为三类:
1. 根证书(Root CA Certificate) :由权威 CA 自签名,预置于操作系统或浏览器的信任库中;
2. 中间证书(Intermediate CA Certificate) :由根 CA 签发,用于签发终端实体证书;
3. 服务器/客户端证书(End-entity Certificate) :用于标识具体服务或设备。
当客户端收到服务器证书后,会沿着证书链向上追溯,直到找到一个本地信任的根证书。如果链条断裂或签名无效,则验证失败。
自签名证书的应用场景
在开发或测试环境中,往往不具备申请公共 CA 证书的条件。此时可使用 OpenSSL 工具生成自签名证书。以下是生成步骤示例:
# 生成私钥
openssl genrsa -out ca-key.pem 2048
# 生成自签名 CA 证书
openssl req -new -x509 -nodes -days 3650 \
-key ca-key.pem \
-out ca.pem \
-subj "/CN=MyTestCA"
# 生成服务器私钥和证书请求
openssl req -newkey rsa:2048 -nodes -keyout server-key.pem \
-out server-req.pem \
-subj "/CN=localhost"
# 使用 CA 签发服务器证书
openssl x509 -req -in server-req.pem \
-days 365 \
-CA ca.pem -CAkey ca-key.pem -set_serial 01 \
-out server-cert.pem
完成上述操作后,需将 ca.pem 、 server-cert.pem 和 server-key.pem 部署至 MySQL 服务器配置目录,并在 my.cnf 中指定路径:
[mysqld]
ssl-ca=/etc/mysql/certs/ca.pem
ssl-cert=/etc/mysql/certs/server-cert.pem
ssl-key=/etc/mysql/certs/server-key.pem
重启 MySQL 服务后即可启用 SSL。
客户端验证模式选择
Navicat 在配置 SSL 连接时提供了多种验证级别选项,对应不同的安全强度:
| 验证模式 | 描述 |
|---|---|
| 不使用 SSL | 明文传输,不推荐用于生产环境 |
| 使用 SSL,不验证证书 | 建立加密连接,但不校验证书合法性,存在中间人攻击风险 |
| 使用 SSL,验证 CA 证书 | 客户端需导入 CA 证书,验证服务器证书是否由该 CA 签发 |
| 使用 SSL,验证完整证书链 | 最高安全等级,要求服务器证书、中间证书、根证书均有效且完整 |
推荐在生产环境中采用“验证 CA 证书”或更高级别模式,以杜绝伪造服务器接入的风险。
证书更新与吊销管理
证书具有有效期,过期后会导致连接中断。应建立定期巡检机制,监控证书剩余有效时间。同时,一旦私钥泄露或员工离职,应及时吊销相关证书并重新签发。
MySQL 支持 CRL(Certificate Revocation List),但配置较为复杂。更常见的做法是在应用层控制用户权限,配合自动化的证书轮换脚本实现安全治理。
通过以上机制,可以构建一个基于 SSL/TLS 的端到端加密通信体系,从根本上防范数据在传输过程中的泄露与篡改风险,为后续的访问控制打下坚实基础。
4.2 Navicat中SSL连接的配置实践
Navicat 作为主流的数据库管理工具之一,提供了直观的界面来配置和管理 SSL 安全连接。正确配置 SSL 不仅能提升数据传输的安全性,还能满足企业合规审计的要求。本节将详细介绍如何在 Navicat 中完成 SSL 参数设置,并提供连接测试与故障排查的方法论。
4.2.1 安全连接参数设置与测试方法
在 Navicat 中新建或编辑一个 MySQL 连接时,点击“高级”选项卡即可进入 SSL 配置区域。主要参数如下所示:
| 参数项 | 说明 |
|---|---|
| 使用SSL | 勾选后启用 SSL 加密 |
| CA 文件 | 指定 CA 根证书文件( .pem 或 .crt 格式),用于验证服务器证书 |
| 客户端证书文件 | 双向认证时需提供的客户端证书 |
| 客户端密钥文件 | 对应客户端证书的私钥文件 |
| 密码(如有) | 若私钥文件受密码保护,需在此输入解密密码 |
假设我们已拥有以下证书文件:
- ca.pem :CA 根证书
- client-cert.pem :客户端证书
- client-key.pem :客户端私钥
配置步骤如下:
- 打开 Navicat 主界面,右键“连接” → “MySQL” → 输入连接名称、主机地址、端口、用户名和密码;
- 切换至“高级”标签页;
- 勾选“使用SSL”;
- 点击“CA 文件”右侧的浏览按钮,选择
ca.pem; - 如需双向认证,继续填写“客户端证书文件”和“客户端密钥文件”路径;
- 点击“测试连接”,观察反馈结果。
若配置正确,Navicat 将显示“连接成功”,并在状态栏提示“SSL: 已启用”。
为进一步确认连接确实走的是加密通道,可在 MySQL 服务器端执行以下查询:
SELECT
id,
user,
host,
ssl_type,
ssl_cipher
FROM information_schema.processlist
WHERE user = 'your_username';
预期输出:
| id | user | host | ssl_type | ssl_cipher |
|---|---|---|---|---|
| 123 | secure_user | 192.168.1.100 | ECDHE-RSA-AES128-GCM-SHA256 | TLS_AES_128_GCM_SHA256 |
若 ssl_type 非空,说明当前会话已启用 SSL 加密。
强制 SSL 连接的用户策略
为确保特定用户始终通过加密方式访问,应在 MySQL 中设置强制 SSL 要求:
ALTER USER 'report_user'@'%' REQUIRE SSL;
FLUSH PRIVILEGES;
此后,任何未启用 SSL 的连接尝试都将失败,并抛出类似错误:
ERROR 1045 (28000): Access denied for user 'report_user'@'192.168.1.100' (using password: YES)
此机制可有效阻止低安全级别的接入行为。
4.2.2 常见连接失败问题排查指南
尽管配置看似简单,但在实际操作中常因证书格式、路径权限或版本兼容性问题导致连接失败。以下是典型错误及其解决方案:
错误1:证书验证失败(”Unknown certificate authority”)
原因分析 :客户端未识别 CA 证书,可能是未导入或证书链不完整。
解决方法 :
- 确保使用的 CA 证书是服务器证书的真实签发者;
- 若使用中间 CA,需将中间证书合并至 CA 文件中:
cat intermediate-ca.pem >> ca.pem
- 在 Navicat 中重新选择更新后的
ca.pem文件。
错误2:私钥格式不匹配(”Key does not match the certificate”)
原因分析 :客户端证书与私钥不匹配,或私钥已被修改。
验证命令 :
# 提取证书公钥模数
openssl x509 -noout -modulus -in client-cert.pem | openssl md5
# 提取私钥模数
openssl rsa -noout -modulus -in client-key.pem | openssl md5
若两次输出的 MD5 值不同,则说明密钥对不匹配,需重新生成。
错误3:SSL 协议版本不兼容
现象 :连接超时或立即断开。
排查思路 :
- 检查 MySQL 服务器支持的 TLS 版本:
SHOW GLOBAL VARIABLES LIKE 'tls_version';
输出示例: TLSv1,TLSv1.1,TLSv1.2
- Navicat 默认支持 TLS 1.0+,若服务器禁用了旧版本(如仅允许 TLS 1.3),而 Navicat 版本较老,则无法握手成功。
解决方案 :
- 升级 Navicat 至最新版本(≥16.x)以支持 TLS 1.3;
- 或临时放宽服务器 TLS 版本限制(不推荐用于生产环境):
[mysqld]
tls_version = TLSv1.2,TLSv1.3
错误4:文件路径权限不足
现象 :提示“无法读取证书文件”
原因 :Navicat 运行账户无权访问指定路径下的证书文件。
解决方案 :
- Windows:确保证书文件未被加密或占用;
- macOS/Linux:检查文件权限:
chmod 644 *.pem
chown $USER:$USER *.pem
避免将私钥设为全局可读。
通过以上系统化的配置与排错流程,可显著提高 SSL 连接的成功率与稳定性,为企业级数据库访问提供可靠的安全保障。
4.3 用户权限管理与访问控制策略
数据库安全不仅体现在通信加密层面,更深层次的安全控制来自于对用户行为的精细化权限管理。MySQL 提供了一套完善的权限体系,结合 Navicat 的图形化操作界面,能够高效地实施基于角色的访问控制(RBAC),实现最小权限原则(Principle of Least Privilege)。
4.3.1 MySQL权限体系结构解析
MySQL 的权限系统采用多层级、多维度的授权模型,主要包括以下几个组成部分:
-
权限范围层级 :
- 全局级(*.*):适用于所有数据库;
- 数据库级(db_name.*):针对某一数据库的所有对象;
- 表级(db_name.table_name):仅限某张表;
- 列级(db_name.table_name(column)):细化到字段;
- 存储程序级(FUNCTION/PROCEDURE):针对函数或存储过程。 -
权限类型分类 :
- 管理权限 :如SUPER,RELOAD,SHUTDOWN;
- 数据库操作权限 :如SELECT,INSERT,UPDATE,DELETE;
- 结构变更权限 :如ALTER,CREATE,DROP,INDEX;
- 复制相关权限 :如REPLICATION SLAVE,REPLICATION CLIENT。
权限存储于 mysql 系统数据库中的多个表中,主要包括:
| 权限表 | 用途说明 |
|---|---|
user |
全局权限 + 用户认证信息 |
db |
数据库级别权限 |
tables_priv |
表级权限 |
columns_priv |
列级权限 |
procs_priv |
存储过程与函数权限 |
当用户发起请求时,MySQL 按照“全局 → 数据库 → 表 → 列”的顺序逐层匹配权限,取最具体的规则生效。
权限继承与 GRANT OPTION
使用 GRANT OPTION 可赋予用户转授权限的能力:
GRANT SELECT ON sales.* TO 'analyst'@'%' WITH GRANT OPTION;
这意味着 analyst 用户可将 SELECT 权限授予他人,但不能超越自身权限范围。
动态权限与角色支持(MySQL 8.0+)
自 MySQL 8.0 起引入了“角色”(Role)概念,简化了批量权限管理:
-- 创建角色
CREATE ROLE 'read_only', 'data_editor';
-- 授予权限给角色
GRANT SELECT ON *.* TO 'read_only';
GRANT SELECT, INSERT, UPDATE ON corp.* TO 'data_editor';
-- 将角色分配给用户
GRANT 'read_only' TO 'guest'@'%';
SET DEFAULT ROLE 'read_only' TO 'guest'@'%';
这种方式极大提升了权限管理的灵活性与可维护性。
4.3.2 在Navicat中分配角色与细粒度权限操作
Navicat 提供了可视化的权限管理界面,极大降低了 SQL 授权语句的学习门槛。
步骤1:打开用户管理窗口
- 连接至目标 MySQL 实例;
- 右键连接名 → “用户” → 打开“用户中心”;
- 选择“用户”标签页,列出所有账户。
步骤2:创建新用户并分配权限
- 点击“新建用户”;
- 输入登录名、主机(如
%表示任意主机)、密码; - 切换至“服务器权限”选项卡,勾选所需权限:
- 建议取消FILE,SHUTDOWN,SUPER等高危权限; - 切换至“数据库权限”选项卡,选择具体数据库并配置 CRUD 权限;
- 点击“保存”。
Navicat 自动生成相应的 GRANT 语句并执行,无需手动编写。
示例:为报表用户配置只读权限
-- Navicat 自动生成的语句
GRANT SELECT ON `sales`.* TO 'report_user'@'%';
GRANT USAGE ON *.* TO 'report_user'@'%'
REQUIRE NONE
WITH MAX_QUERIES_PER_HOUR 0
MAX_CONNECTIONS_PER_HOUR 10
MAX_UPDATES_PER_HOUR 0
MAX_USER_CONNECTIONS 5;
该配置限制了每小时最多 10 次连接,禁止更新操作,增强了资源管控能力。
使用角色简化管理(MySQL 8.0+)
在 Navicat 中也可管理角色:
- 在“用户中心”切换至“角色”标签;
- 点击“新建角色”,命名如
app_reader; - 分配
SELECT权限至相关数据库; - 返回“用户”标签,将角色授予指定用户;
- 设置默认角色。
此方式特别适用于微服务架构中统一权限模板的部署。
通过结合底层权限机制与图形化工具的优势,组织可以建立起既安全又高效的数据库访问治理体系,真正实现“谁可以访问什么”的精准控制。
5. 数据库运维自动化与性能优化方案
在现代企业级应用架构中,数据库作为核心数据存储与访问的枢纽,其稳定性、可用性与响应效率直接决定了系统的整体服务质量。随着业务规模扩大和数据量激增,传统人工干预式的数据库管理方式已难以满足高并发、低延迟、持续可用等关键诉求。因此,构建一套完整的数据库运维自动化体系,并结合科学的性能调优策略,成为保障系统长期健康运行的关键路径。
Navicat 作为一款功能强大的数据库开发与管理工具,在数据库自动化运维与性能监控方面提供了丰富的集成能力。本章将深入探讨如何借助 Navicat 及其底层数据库引擎(以 MySQL 为例)实现定时备份恢复、实时性能监控、查询优化建议生成以及多数据库间的结构与数据同步机制。通过理论解析与实操演示相结合的方式,帮助开发者与 DBA 构建高效、稳定、可追溯的数据库运维闭环。
5.1 定时备份与一键恢复的机制设计
数据库备份是防止数据丢失的第一道防线,而恢复则是灾难发生后重建业务的核心手段。一个高效的备份与恢复机制不仅需要保证数据完整性,还需具备自动化调度、日志追踪和快速还原的能力。Navicat 提供了图形化任务计划功能,支持用户配置周期性备份任务并执行一键式恢复操作,极大提升了数据库维护的便捷性与可靠性。
5.1.1 备份策略选择:完全备份 vs 差异备份
在制定备份策略时,首先要明确不同备份类型的特点及其适用场景。常见的备份方式包括 完全备份 (Full Backup)、 差异备份 (Differential Backup)和 增量备份 (Incremental Backup)。这三种模式各有优劣,需根据实际业务需求进行权衡。
| 备份类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 完全备份 | 每次备份都复制整个数据库的所有数据 | 恢复速度快,只需一个文件 | 占用空间大,备份时间长 |
| 差异备份 | 仅备份自上次完全备份以来发生变化的数据 | 节省空间,恢复比增量快 | 随时间推移体积增大,仍依赖完整备份 |
| 增量备份 | 仅备份上一次任意类型备份之后更改的数据 | 最节省空间和时间 | 恢复过程复杂,需按顺序应用多个备份文件 |
对于中小型系统或对恢复速度要求较高的环境,推荐采用“ 每周一次完全备份 + 每日一次差异备份 ”的组合策略;而对于大型系统且网络带宽受限的情况,则可考虑使用增量备份,但必须配套完善的日志管理和恢复测试流程。
Navicat 支持通过“自动运行任务”模块创建备份作业。以下是一个典型的备份脚本示例,使用 mysqldump 命令行工具配合 Windows 计划任务或 Linux Cron 实现:
#!/bin/bash
# 定义变量
BACKUP_DIR="/data/backup/mysql"
DATE=$(date +%Y%m%d_%H%M%S)
DB_NAME="sales_db"
USER="backup_user"
PASSWORD="secure_password"
# 执行完全备份
mysqldump -u$USER -p$PASSWORD --single-transaction --routines --triggers $DB_NAME > $BACKUP_DIR/${DB_NAME}_full_$DATE.sql
# 压缩备份文件
gzip $BACKUP_DIR/${DB_NAME}_full_$DATE.sql
echo "Backup completed: ${DB_NAME}_full_$DATE.sql.gz" >> /var/log/backup.log
代码逻辑逐行解读:
- 第2–5行:定义备份目录、时间戳、数据库名及认证信息,便于后续引用。
- 第8行:调用
mysqldump工具导出指定数据库; --single-transaction确保一致性(适用于 InnoDB),避免锁表;--routines和--triggers包含存储过程和触发器定义;- 第11行:使用
gzip压缩.sql文件,显著减少磁盘占用; - 第13行:记录日志,用于审计和故障排查。
该脚本可被封装为 .sh 文件并在操作系统层面设置定时任务。例如,在 Linux 中可通过编辑 crontab 实现每日凌晨2点执行:
0 2 * * * /usr/local/bin/mysql_backup.sh
此外,Navicat 自身也提供可视化任务调度器,允许用户无需编写脚本即可配置备份任务。其内部原理即为调用上述命令并封装成 GUI 流程,降低了技术门槛。
为了进一步提升安全性,建议启用加密传输与存储机制。例如,可以结合 GPG 加密备份文件:
gpg --cipher-algo AES256 -c ${DB_NAME}_full_$DATE.sql.gz
此命令会提示输入密码,生成 .gpg 加密文件,确保即使备份介质泄露也不会导致敏感数据暴露。
5.1.2 计划任务调度与日志审计跟踪
自动化备份的成功落地离不开可靠的调度机制与完整的日志审计体系。Navicat 的“批处理作业”功能允许用户创建包含多个操作的任务流,如“备份 → 压缩 → 上传至远程服务器 → 发送邮件通知”。
下面是一个基于 Navicat 高级功能构建的自动化任务流程图(使用 Mermaid 表示):
graph TD
A[开始] --> B{是否到达预定时间?}
B -- 是 --> C[执行 mysqldump 备份]
C --> D[压缩 SQL 文件为 .gz]
D --> E[通过 SFTP 上传至异地服务器]
E --> F[发送成功邮件通知管理员]
F --> G[记录日志到 backup_log 表]
G --> H[结束]
B -- 否 --> I[等待下一周期]
I --> B
该流程体现了典型的事件驱动型任务调度模型,强调了 条件判断、链式执行、异常反馈与状态持久化 四大要素。
在数据库端建立专门的日志表用于记录每次备份的状态,有助于后期分析与合规审查。建表示例如下:
CREATE TABLE backup_log (
id INT AUTO_INCREMENT PRIMARY KEY,
db_name VARCHAR(64) NOT NULL,
backup_type ENUM('full', 'differential', 'incremental') DEFAULT 'full',
start_time DATETIME NOT NULL,
end_time DATETIME,
file_path VARCHAR(255),
file_size BIGINT, -- 字节单位
status ENUM('success', 'failed', 'running') DEFAULT 'running',
error_message TEXT,
operator VARCHAR(50)
);
每当备份任务启动时插入一条初始记录,完成后更新结束时间和状态字段。例如:
INSERT INTO backup_log (db_name, backup_type, start_time, operator)
VALUES ('sales_db', 'full', NOW(), 'navicat_scheduler');
任务完成后再执行更新:
UPDATE backup_log
SET end_time = NOW(),
file_path = '/data/backup/sales_db_full_20250405.sql.gz',
file_size = 1073741824,
status = 'success'
WHERE db_name = 'sales_db' AND status = 'running';
这种细粒度的日志记录机制,使得任何一次备份都可以被精确回溯,尤其适合金融、医疗等强监管行业。
此外,为防止备份文件无限增长造成磁盘溢出,应引入 自动清理策略 。可通过如下 SQL 查询识别过期备份并删除:
-- 查找超过7天的已完成备份记录
SELECT id, file_path FROM backup_log
WHERE start_time < DATE_SUB(NOW(), INTERVAL 7 DAY)
AND status = 'success';
然后在脚本中遍历结果并执行 rm 删除操作:
find /data/backup/mysql -name "*.sql.gz" -mtime +7 -delete
综上所述,合理的备份策略不仅是技术实现问题,更是运维制度建设的一部分。结合 Navicat 的图形化调度与自定义脚本扩展能力,能够构建出既灵活又稳健的数据保护体系。
5.2 性能监视工具的应用实践
数据库性能直接影响用户体验与系统吞吐能力。面对复杂的查询负载、慢SQL频发、连接堆积等问题,仅靠经验判断已无法应对。Navicat 内置的性能监视器提供了直观的实时监控界面,帮助用户快速定位瓶颈所在,并给出优化建议。
5.2.1 实时会话监控与慢查询识别
数据库性能下降往往源于某些长时间运行的查询或资源争抢。Navicat 的“服务器监控”面板可实时展示当前活动会话、CPU 使用率、内存占用、I/O 状态等关键指标。
更重要的是,它能连接到 MySQL 的 information_schema.PROCESSLIST 表,列出所有正在执行的线程:
SELECT
ID,
USER,
HOST,
DB,
COMMAND,
TIME,
STATE,
INFO
FROM information_schema.PROCESSLIST
WHERE COMMAND != 'Sleep'
ORDER BY TIME DESC;
参数说明:
ID: 连接标识符,可用于KILL终止特定会话;USER/HOST: 客户端来源,辅助安全审计;COMMAND: 当前操作类型(Query、Connect 等);TIME: 已执行秒数,超过阈值(如 60s)视为潜在慢查询;INFO: 正在执行的 SQL 语句,是诊断的关键依据。
当发现某个查询执行时间过长时,可进一步启用 MySQL 的慢查询日志(Slow Query Log)进行深度分析。需在 my.cnf 配置文件中开启:
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2
log_queries_not_using_indexes = 1
long_query_time=2表示执行时间超过2秒的查询将被记录;log_queries_not_using_indexes=1记录未使用索引的查询,即使执行很快;
随后可通过 mysqldumpslow 工具分析日志:
mysqldumpslow -s c -t 10 /var/log/mysql/slow.log
该命令按出现次数排序,输出最频繁的前10条慢查询,便于优先优化。
Navicat 还可在“查询分析器”中直接显示执行计划(EXPLAIN),辅助判断是否存在全表扫描、临时表或文件排序等问题。例如:
EXPLAIN SELECT u.name, o.total
FROM users u JOIN orders o ON u.id = o.user_id
WHERE u.created_at > '2024-01-01';
返回结果中的关键列解释如下:
| 列名 | 含义说明 |
|---|---|
type |
访问类型, ALL 表示全表扫描,应尽量避免 |
key |
实际使用的索引名称 |
rows |
预估扫描行数,越大性能越差 |
Extra |
额外信息,如 Using filesort 或 Using temporary 表示存在性能隐患 |
若发现 type=ALL 且 rows 数量巨大,说明缺少有效索引。此时应考虑添加复合索引:
ALTER TABLE users ADD INDEX idx_created_at (created_at);
并通过 ANALYZE TABLE users; 更新统计信息以确保优化器做出正确决策。
5.2.2 查询优化建议生成与索引推荐
高级版本的 Navicat 支持“查询优化”功能,能够基于执行计划自动提出改进建议。其内部算法通常结合规则匹配与成本估算模型,模拟 MySQL 优化器行为。
假设原始 SQL 存在性能问题:
SELECT * FROM products WHERE category = 'electronics' AND price > 500 ORDER BY created_at DESC LIMIT 100;
执行 EXPLAIN 后发现:
- type=ALL
- Extra=Using where; Using filesort
这表明进行了全表扫描并使用了文件排序,性能极差。
Navicat 可能提出的优化建议包括:
“建议在
(category, price, created_at)上创建复合索引以覆盖查询条件与排序字段。”
据此创建索引:
CREATE INDEX idx_cat_price_date ON products(category, price, created_at);
再次执行 EXPLAIN ,预期结果为:
- type=index
- key=idx_cat_price_date
- Extra=Using index condition; Backward index scan
此时查询已从全表扫描降级为索引扫描,且利用索引完成倒序读取,无需额外排序。
为进一步验证效果,可使用 SHOW STATUS 对比优化前后资源消耗:
FLUSH STATUS;
-- 执行目标查询
SELECT ...;
SHOW SESSION STATUS LIKE 'Handler_read%';
重点关注 Handler_read_next 和 Handler_read_rnd_next :
- 值越小越好;
- Handler_read_rnd_next 高表示随机读取严重,通常是未走索引的表现。
通过此类精细化监控与迭代优化,可逐步消除系统性能瓶颈,实现查询响应时间从秒级降至毫秒级的跨越。
5.3 多数据库同步与差异对比技术
在分布式架构或多数据中心部署中,保持多个数据库实例之间的数据一致性是一项挑战。Navicat 提供“数据/结构同步”功能,支持跨同构或异构数据库间的双向同步与差异比对。
5.3.1 结构同步与数据比对算法原理
结构同步的核心在于 元数据提取与变更检测 。Navicat 通过 JDBC 或原生驱动连接源库与目标库,分别获取表结构信息(字段名、类型、约束、索引等),然后进行逐项比对。
其比对流程可用以下 Mermaid 图表示:
graph LR
S[源数据库] -->|读取元数据| C[结构比较引擎]
T[目标数据库] -->|读取元数据| C
C --> D[生成差异报告]
D --> E{是否存在差异?}
E -- 是 --> F[生成同步脚本 ALTER/CREATE/DROP]
E -- 否 --> G[同步完成]
F --> H[用户确认执行]
H --> I[应用变更到目标库]
具体而言,结构比对涉及以下几个维度:
| 比对项 | 是否支持 | 说明 |
|---|---|---|
| 表名 | ✅ | 忽略大小写或前缀差异 |
| 字段数量 | ✅ | 检测新增或删除字段 |
| 字段类型 | ✅ | 如 VARCHAR(50) vs VARCHAR(100) |
| 默认值 | ✅ | 影响数据一致性 |
| 主键/唯一约束 | ✅ | 结构一致性关键 |
| 索引定义 | ✅ | 包括组合索引顺序 |
| 触发器与视图 | ✅ | 高级对象同步 |
数据比对则更为复杂,通常采用 哈希校验法 或 分块对比法 来提升效率。对于大表,Navicat 会按主键区间分批加载数据,并计算每批次的 MD5 或 CRC32 校验和,仅对不一致的区块进行详细行级比对。
例如,两张表 orders_src 与 orders_dst 的数据比对逻辑片段如下:
-- 分段计算哈希值(伪代码)
SELECT
FLOOR(id / 1000) AS chunk,
COUNT(*) AS cnt,
BIT_XOR(CAST(CONV(SUBSTRING(MD5(CONCAT_WS('|', id, amount, status)), 1, 16), 16, 10) AS UNSIGNED)) AS hash_value
FROM orders_src
GROUP BY chunk;
同样的查询在目标表执行,对比各 chunk 的 hash_value ,仅当不一致时才深入比较具体行内容。
5.3.2 自动化同步任务配置与冲突解决机制
Navicat 允许将同步任务保存为“自动化任务”,并设定执行频率(如每天凌晨同步生产库到报表库)。
同步过程中可能遇到的典型冲突包括:
- 主键冲突 :目标库已存在相同主键记录;
- 外键约束失败 :引用的父记录尚未同步;
- 字段截断 :目标字段长度小于源数据;
- 字符集不兼容 :UTF8MB4 vs LATIN1 导致乱码;
针对这些问题,Navicat 提供多种处理策略:
| 冲突类型 | 解决选项 |
|---|---|
| 主键重复 | 跳过、覆盖、重命名 |
| 外键缺失 | 延迟处理、先同步父表 |
| 数据类型不符 | 强制转换、报错中断 |
| 字符编码差异 | 自动转码、提示警告 |
在实际操作中,建议遵循“ 先结构后数据、先主表后明细、先测试后上线 ”的原则,最大限度降低风险。
同时,启用“事务包装”选项可确保同步过程的原子性——要么全部成功,要么全部回滚,避免中间状态污染目标库。
综上,数据库运维自动化并非单一工具的堆砌,而是集备份、监控、优化、同步于一体的综合性工程。通过合理运用 Navicat 的各项功能,并辅以脚本定制与流程设计,可显著提升数据库管理水平,为企业数字化转型提供坚实支撑。
6. 跨平台协同与高级功能集成应用
6.1 云端配置同步的架构设计理念
随着分布式开发团队和多终端办公模式的普及,数据库管理工具的跨设备协同能力成为提升工作效率的关键因素。Navicat Premium 提供了基于云服务的配置同步机制,支持用户在不同操作系统(Windows、macOS、Linux)和设备之间无缝切换,实现连接信息、查询脚本、ER 图设计、任务计划等关键配置的统一管理。
该机制的核心是 Navicat Cloud 服务平台,其采用 RESTful API 架构进行数据交互,并通过 HTTPS 加密通道保障传输安全。用户登录后,本地客户端会定期将配置变更推送到云端,同时拉取其他设备的更新内容,形成双向同步闭环。
同步数据类型与频率策略
| 数据类型 | 是否支持同步 | 同步触发方式 | 加密方式 |
|---|---|---|---|
| 数据库连接配置 | ✅ | 实时保存后自动同步 | AES-256 |
| SQL 查询片段 | ✅ | 手动保存至“云片段” | AES-256 |
| ER 模型设计文件 | ✅ | 修改后30秒内同步 | AES-256 |
| 报表模板 | ✅ | 导出并上传至云端 | AES-256 |
| 计划任务 | ❌ | 仅限本地存储 | - |
| 用户偏好设置 | ✅ | 启动时同步一次 | TLS 传输加密 |
| 触发器/存储过程代码 | ✅ | 作为对象脚本同步 | AES-256 |
| 查询执行历史 | ⚠️(可选) | 需手动开启历史记录同步 | AES-256 |
| 数据模型版本快照 | ✅ | 自动创建每日快照 | AES-256 |
| 自定义字段映射模板 | ✅ | 编辑后立即同步 | AES-256 |
| 图表分析布局 | ✅ | 布局更改后延迟同步 | AES-256 |
| 权限角色配置 | ❌ | 依赖目标数据库本身权限体系 | - |
同步频率由后台服务调度控制,默认每5分钟检测一次变更。对于敏感操作(如删除连接),系统会保留7天回收站记录,防止误删导致的数据丢失。
sequenceDiagram
participant LocalClient as 本地Navicat客户端
participant NavicatCloud as Navicat Cloud服务
participant RemoteDevice as 其他设备客户端
LocalClient->>NavicatCloud: 提交配置变更(POST /sync)
NavicatCloud-->>LocalClient: 返回同步成功状态码200
NavicatCloud->>RemoteDevice: 推送增量更新通知(WebSocket)
RemoteDevice->>NavicatCloud: 请求最新配置(GET /config/latest)
NavicatCloud-->>RemoteDevice: 返回加密配置包
RemoteDevice->>RemoteDevice: 解密并应用新配置
此架构确保了高可用性和最终一致性,即使在网络不稳定环境下也能通过本地缓存继续工作,待网络恢复后自动补传差量数据。
6.2 报表生成与图表化分析功能深度使用
Navicat 内置的报表工具不仅支持静态数据导出,更具备动态绑定、参数化查询和可视化渲染能力,适用于财务统计、运营分析、日志监控等多种业务场景。
6.2.1 自定义报表模板设计与数据绑定
创建报表的第一步是建立数据源连接。可通过以下 SQL 示例获取订单销售趋势数据:
-- 获取近30天每日销售额汇总
SELECT
DATE(order_date) AS sale_day,
COUNT(*) AS order_count,
SUM(total_amount) AS daily_revenue,
AVG(total_amount) AS avg_order_value
FROM sales_orders
WHERE order_date >= CURDATE() - INTERVAL 30 DAY
GROUP BY DATE(order_date)
ORDER BY sale_day DESC;
在报表设计器中,可将上述查询结果集绑定到表格组件,并添加计算字段如“环比增长率”。参数化输入框允许用户选择时间范围,提升交互灵活性。
<!-- 报表示例结构片段 -->
<ReportTemplate name="MonthlySalesReport">
<DataSource queryId="q_sales_trend"/>
<Parameter name="start_date" type="date" defaultValue="TODAY-30"/>
<Parameter name="end_date" type="date" defaultValue="TODAY"/>
<Element type="table" dataSource="result_set">
<Column field="sale_day" label="日期" format="yyyy-MM-dd"/>
<Column field="order_count" label="订单数" align="right"/>
<Column field="daily_revenue" label="收入(元)" format="#,##0.00" align="right"/>
<Column expression="[daily_revenue]/LAG([daily_revenue]) - 1" label="环比"/>
</Element>
</ReportTemplate>
支持导出为 PDF、HTML、Excel 等格式,且保留样式与分页设置。
6.3 Navicat安装部署与授权激活全流程
6.3.1 不同操作系统下的安装注意事项
Windows 平台
- 要求 .NET Framework 4.8 或更高版本
- 安装程序自动注册 ODBC 驱动(若启用)
- 防火墙提示需允许
navicat.exe网络访问以启用云同步
macOS 平台
- 从官方下载
.dmg映像文件,拖拽至 Applications 文件夹 - 首次运行需在「系统设置 → 隐私与安全性」中授权“仍要打开”
- Apple Silicon 芯片机型兼容原生 ARM64 版本,性能提升约 40%
Linux 平台
支持 Ubuntu/Debian( .deb )、CentOS/RHEL( .rpm )及通用 .tar.gz 包:
# Debian系安装示例
sudo dpkg -i navicat-premium-linux.deb
sudo apt-get install -f # 自动修复依赖
# 启动命令
/opt/navicat/start_navicat.sh
图形界面依赖 libgtk-3-0 , libxss1 等库,无头服务器需额外配置 Xvfb 进行远程访问。
6.3.2 密钥获取、激活流程及合法使用规范
激活流程如下:
- 注册账户 :访问 Navicat官网 创建账号
- 购买许可证 :选择 Navicat Premium 永久许可或年订阅
- 获取序列号 :支付完成后邮件发送激活码(形如
NAVP-PREM-XXXX-XXXX-XXXX) - 离线激活 (适用于内网环境):
- 在无法联网的机器上生成硬件指纹(Hardware Fingerprint)
- 登录官网输入指纹获取激活响应文件
- 导入响应文件完成验证
每个许可证支持最多3台设备同时激活,超出需先释放旧设备。企业批量部署可通过 Volume License Manager 统一管理授权状态。
graph TD
A[下载安装包] --> B{操作系统?}
B -->|Windows| C[运行Setup.exe]
B -->|macOS| D[挂载DMG并复制到Applications]
B -->|Linux| E[使用dpkg/rpm安装或解压运行]
C --> F[启动Navicat]
D --> F
E --> F
F --> G[输入序列号]
G --> H[联网激活或离线激活]
H --> I[进入主界面开始使用]
简介:Navicat是一款专为MySQL设计的高效数据库管理与开发工具,提供直观的图形界面和丰富的功能模块,涵盖连接管理、数据库设计、SQL编辑、数据同步与备份恢复等核心操作。本工具包集成Navicat完整功能并包含密钥,支持MySQL及MariaDB等多种版本,适用于新手和专业开发者,显著提升数据库操作效率与安全性,是MySQL用户必备的全流程管理解决方案。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)