InfluxDB2时序数据库Java读写操作实战示例
InfluxDB2 是一款专为处理时间序列数据设计的高性能时序数据库(Time Series Database),适用于物联网、监控系统、日志分析等场景。与传统关系型数据库不同,InfluxDB2 通过优化时间维度的读写性能,实现对大规模时间序列数据的高效存储与查询。其支持原生的时间序列模型,如 measurement(测量)、tag(标签)、field(字段)与 timestamp(时间戳),并

简介:InfluxDB2是专为时间序列数据设计的高性能数据库,广泛应用于物联网、监控系统和日志分析。本示例详细演示了如何在Java中使用官方客户端库与InfluxDB2进行交互,包括引入依赖、连接数据库、使用Point和Batch进行单条与批量写入,以及通过InfluxQL进行数据查询与结果处理。通过本示例,开发者可以快速掌握InfluxDB2在Java项目中的核心操作流程,实现高效的时间序列数据读写与解析。 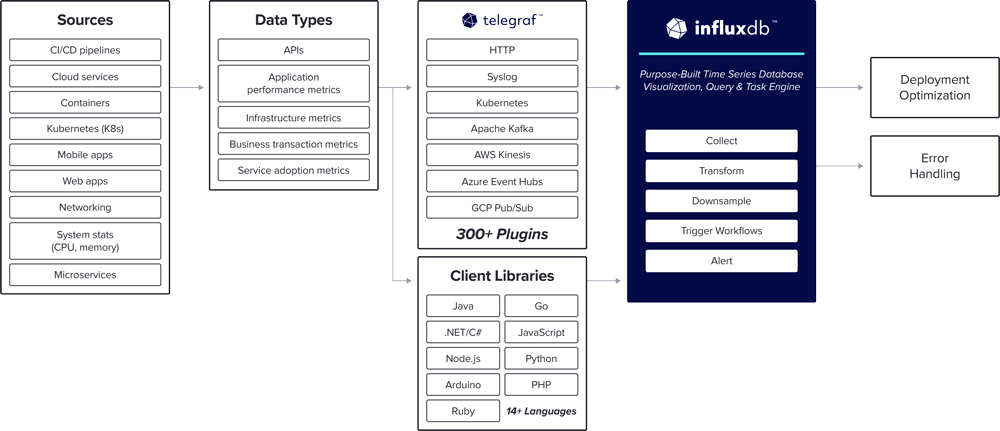
1. InfluxDB2简介与应用场景
1.1 InfluxDB2概述
InfluxDB2 是一款专为处理时间序列数据设计的高性能时序数据库(Time Series Database),适用于物联网、监控系统、日志分析等场景。与传统关系型数据库不同,InfluxDB2 通过优化时间维度的读写性能,实现对大规模时间序列数据的高效存储与查询。其支持原生的时间序列模型,如 measurement(测量)、tag(标签)、field(字段)与 timestamp(时间戳),并提供灵活的查询语言 Flux,支持复杂的数据分析与聚合操作。
InfluxDB2 支持多种部署方式,包括单机、集群和云原生部署,具备良好的可扩展性与高可用性,是构建实时监控与数据分析系统的重要基础设施。
2. Java连接InfluxDB2配置与实现
在现代微服务与物联网系统中,Java作为后端开发的主力语言,常用于连接各类数据库系统,包括时序数据库 InfluxDB2。本章将深入探讨 Java 如何连接 InfluxDB2 的核心配置与实现机制,帮助开发者掌握在 Java 项目中集成 InfluxDB2 的完整流程。
我们将从 InfluxDB2 官方 Java SDK 入手,逐步介绍依赖引入、客户端连接配置、核心接口使用、连接测试与异常处理等关键环节。通过本章的学习,开发者将能够独立完成 Java 与 InfluxDB2 的对接,并具备构建高可用、高性能数据写入和查询系统的能力。
2.1 InfluxDB2 Java客户端概述
InfluxDB2 提供了官方的 Java SDK,用于简化与数据库的交互。该 SDK 提供了完整的 API 接口,支持数据写入(Write API)、数据查询(Query API)、管理操作(Organization、Bucket 等)以及异常处理机制。Java 开发者可以借助这一 SDK 快速构建高效、安全的时序数据处理系统。
2.1.1 官方Java SDK简介
InfluxDB2 的 Java 客户端库( influxdb-client-java )是一个基于 HTTP 协议封装的 Java SDK,它封装了 InfluxDB2 的 REST API 接口,使得开发者可以通过 Java 对象调用 InfluxDB2 的核心功能。该 SDK 支持:
- 使用 API Token 进行认证
- 写入 Point 数据到指定 Bucket
- 使用 Flux 语言进行查询
- 配置连接池、超时、重试等高级选项
- 异常处理与日志输出
SDK 的核心模块如下:
| 模块 | 说明 |
|---|---|
| influxdb-client-core | 提供基础的客户端连接与配置 |
| influxdb-client-api | 提供 WriteApi、QueryApi 等主要接口 |
| influxdb-client-java | 提供完整的 Java 客户端实现 |
| influxdb-client-flux | 提供对 Flux 查询的支持 |
2.1.2 依赖引入与环境准备
要在 Java 项目中使用 InfluxDB2 的 SDK,首先需要在 pom.xml 中引入相关依赖。以下是使用 Maven 的配置示例:
<dependencies>
<!-- InfluxDB2 Java SDK 核心 -->
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-java</artifactId>
<version>6.10.0</version>
</dependency>
<!-- Flux 查询支持 -->
<dependency>
<groupId>com.influxdb</groupId>
<artifactId>influxdb-client-flux</artifactId>
<version>6.10.0</version>
</dependency>
</dependencies>
参数说明:
influxdb-client-java:这是 InfluxDB2 Java SDK 的主模块,包含连接、写入、查询等核心功能。influxdb-client-flux:该模块提供了对 Flux 查询语言的支持,适用于 Java 中构建 Flux 查询语句。version:版本号建议使用当前最新稳定版本,如 6.10.0。
⚠️ 注意:引入依赖后,请确保项目运行环境为 JDK 1.8 及以上,并配置好网络代理(如需)。
2.2 客户端连接配置详解
在完成依赖引入后,下一步是配置 InfluxDB2 客户端连接。该配置包括认证方式、组织(Organization)与存储桶(Bucket)设置,以及连接超时与重试机制等关键参数。
2.2.1 使用API Token进行认证
InfluxDB2 支持基于 Token 的认证方式。每个用户可以创建多个 Token,并为其分配不同的权限。使用 Java SDK 时,推荐通过 Token 进行认证。
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
public class InfluxDB2ClientExample {
private static final String INFLUXDB_URL = "http://localhost:8086";
private static final String INFLUXDB_TOKEN = "your-influxdb-token-here";
private static final String INFLUXDB_ORG = "your-org-name";
public static void main(String[] args) {
InfluxDBClient influxDBClient = InfluxDBClientFactory.create(INFLUXDB_URL, INFLUXDB_TOKEN.toCharArray(), INFLUXDB_ORG);
System.out.println("InfluxDB2 client is ready: " + influxDBClient.ready());
influxDBClient.close();
}
}
代码逻辑分析:
InfluxDBClientFactory.create():这是 SDK 提供的工厂方法,用于创建 InfluxDB2 客户端实例。INFLUXDB_URL:InfluxDB2 实例的访问地址,通常为http://localhost:8086或远程服务器地址。INFLUXDB_TOKEN:用户的 API Token,用于认证。INFLUXDB_ORG:组织名称,用于隔离不同用户的数据空间。
2.2.2 组织(Organization)与存储桶(Bucket)配置
在 InfluxDB2 中, Organization 是数据的逻辑隔离单位,而 Bucket 是数据存储的容器。一个 Organization 下可以有多个 Bucket。
在 Java SDK 中,我们可以通过客户端对象获取或创建 Bucket:
import com.influxdb.client.domain.Bucket;
import com.influxdb.client.domain.Organization;
import com.influxdb.client.BucketsApi;
public class BucketManagement {
public static void createBucketIfNotExists(InfluxDBClient influxDBClient, String bucketName, long retentionPeriodDays) {
BucketsApi bucketsApi = influxDBClient.getBucketsApi();
Organization org = influxDBClient.getOrganizationsApi().findOrganizationByName("your-org-name");
if (bucketsApi.findBucketByName(bucketName) == null) {
Bucket bucket = bucketsApi.createBucket(bucketName, org, retentionPeriodDays);
System.out.println("Bucket created: " + bucket.getName());
} else {
System.out.println("Bucket already exists: " + bucketName);
}
}
}
参数说明:
bucketName:Bucket 名称,必须唯一。org:组织对象,通过findOrganizationByName获取。retentionPeriodDays:数据保留时间(以天为单位)。
2.2.3 连接超时与重试机制设置
在生产环境中,网络不稳定可能导致连接失败。为此,InfluxDB2 Java SDK 提供了连接超时和重试机制的配置选项。
import com.influxdb.client.InfluxDBClientOptions;
public class ClientWithTimeouts {
public static void configureClientWithTimeouts() {
InfluxDBClientOptions options = InfluxDBClientOptions.builder()
.url("http://localhost:8086")
.authenticateToken("your-token-here".toCharArray())
.org("your-org")
.bucket("your-bucket")
.connectTimeout(5000) // 连接超时时间(毫秒)
.readTimeout(10000) // 读取超时时间
.writeTimeout(10000) // 写入超时时间
.retryOnHttp429(true) // 自动重试限流请求
.build();
InfluxDBClient client = InfluxDBClientFactory.create(options);
}
}
参数说明:
| 参数 | 说明 |
|---|---|
connectTimeout |
建立连接的最大等待时间 |
readTimeout |
从服务器读取响应的最大等待时间 |
writeTimeout |
向服务器写入请求的最大等待时间 |
retryOnHttp429 |
是否在遇到限流(HTTP 429)时自动重试 |
✅ 建议:在实际项目中,建议将这些配置项提取为配置文件(如 application.yml),以便灵活调整。
2.3 核心接口与功能模块
InfluxDB2 Java SDK 提供了丰富的功能模块,其中 WriteApi 和 QueryApi 是最核心的两个接口,分别用于数据写入与查询。
2.3.1 WriteApi与QueryApi介绍
WriteApi:数据写入接口
WriteApi 是 InfluxDB2 用于写入数据的核心接口。它支持同步与异步写入,并可配置批量提交策略。
import com.influxdb.client.WriteApi;
import com.influxdb.client.domain.WritePrecision;
import com.influxdb.client.write.Point;
public class DataWriter {
public static void writeData(InfluxDBClient influxDBClient) {
WriteApi writeApi = influxDBClient.makeWriteApi();
Point point = Point.measurement("temperature")
.tag("location", "room1")
.field("value", 23.5)
.time(System.currentTimeMillis(), WritePrecision.MS);
writeApi.writePoint("your-bucket", point);
writeApi.close();
}
}
QueryApi:数据查询接口
QueryApi 用于执行 Flux 查询语句,并返回结构化的结果。
import com.influxdb.query.FluxTable;
import com.influxdb.query.FluxRecord;
public class DataQuery {
public static void queryData(InfluxDBClient influxDBClient) {
String fluxQuery = "from(bucket: \"your-bucket\")\n" +
" |> range(start: -1h)\n" +
" |> filter(fn: (r) => r._measurement == \"temperature\")";
List<FluxTable> tables = influxDBClient.getQueryApi().query(fluxQuery);
for (FluxTable table : tables) {
for (FluxRecord record : table.getRecords()) {
System.out.println("Time: " + record.getTime() + " | Value: " + record.getValue());
}
}
}
}
2.3.2 Flux语句与数据流式处理
Flux 是 InfluxDB2 推出的新一代查询语言,它支持流式数据处理,非常适合处理时间序列数据。
使用 Flux 构建查询语句
Flux 查询语句的基本结构如下:
from(bucket: "your-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "temperature")
|> filter(fn: (r) => r.location == "room1")
|> limit(n: 10)
Java中构建Flux语句
import com.influxdb.query.Flux;
import com.influxdb.query.FluxQuery;
public class FluxQueryBuilder {
public static FluxQuery buildTemperatureQuery(String bucketName, String location, int limit) {
return Flux.from(bucketName)
.range(-1, ChronoUnit.HOURS)
.filter(Flux.filter()
.measurement("temperature")
.tag("location", location))
.limit(limit);
}
}
💡 Flux 支持链式构建,非常适合 Java 中使用 Builder 模式进行构建。
2.4 连接测试与异常处理
在实际项目中,建立连接后需要进行健康检查,同时处理可能出现的异常情况,如网络异常、认证失败等。
2.4.1 基础健康检查
InfluxDB2 提供了 ready() 方法用于检查服务是否可用:
public class HealthCheck {
public static boolean checkInfluxDB2Health(InfluxDBClient client) {
return client.ready();
}
}
2.4.2 网络异常与认证失败的处理策略
在连接过程中,可能遇到以下异常情况:
IOException:网络连接失败UnauthorizedException:Token 无效或权限不足InfluxException:InfluxDB2 服务端返回错误
import com.influxdb.exceptions.InfluxException;
public class ConnectionErrorHandler {
public static void handleConnectionErrors(RunnableWithException action) {
try {
action.run();
} catch (InfluxException e) {
System.err.println("InfluxDB2 Error: " + e.getMessage());
if (e.getCode() == 401) {
System.err.println("Authentication failed: Invalid token.");
}
} catch (IOException e) {
System.err.println("Network error: Could not connect to InfluxDB2 server.");
} catch (Exception e) {
System.err.println("Unexpected error: " + e.getMessage());
}
}
@FunctionalInterface
public interface RunnableWithException {
void run() throws Exception;
}
}
使用方式:
public static void main(String[] args) {
try {
InfluxDBClient client = InfluxDBClientFactory.create(...);
ConnectionErrorHandler.handleConnectionErrors(() -> {
System.out.println("Client is ready: " + client.ready());
});
} catch (Exception e) {
e.printStackTrace();
}
}
总结
本章详细讲解了 Java 如何连接 InfluxDB2 的核心配置与实现流程,包括:
- Java SDK 的引入与环境准备
- 使用 Token 进行认证
- 组织与 Bucket 的配置
- 超时与重试机制设置
- 核心接口 WriteApi 与 QueryApi 的使用
- Flux 查询语言的构建与处理
- 连接测试与异常处理策略
下一章我们将深入探讨使用 Point 方式进行单条数据写入的具体实现方式,并分析其性能表现与优化策略。
3. Point方式单条数据写入
在InfluxDB2中,数据是以 Point 为基本单位写入的,每个Point表示一个时间序列数据点。本章将深入探讨如何使用Java客户端通过Point方式实现单条数据的写入操作,涵盖数据模型的构建、同步与异步写入方式的实现、性能分析与调优策略,并结合实际场景进行示例演示。
3.1 数据模型与Point构建
InfluxDB2的写入模型基于 measurement、tag、field、timestamp 四个核心要素构成,每个Point对象都必须包含这些信息。理解这些概念是构建Point数据的前提。
3.1.1 InfluxDB2中的measurement、tag、field与timestamp
InfluxDB2的写入模型遵循如下结构:
- measurement :类似于关系型数据库中的表名,用于标识数据类型。例如:
temperature、cpu_usage。 - tag :用于索引和过滤的元数据字段,通常为字符串类型,且对查询性能有显著影响。例如:
region=us-west、host=server01。 - field :存储实际的测量值,可以是数值或字符串类型,是查询和聚合操作的主要对象。例如:
value=42.5、status=ok。 - timestamp :记录数据采集的时间戳,是时间序列数据的核心特征。默认为系统当前时间,也可手动指定。
下图展示了一个典型的Point结构:
graph TD
A[Point] --> B[Measurement: cpu_usage]
A --> C[Tags: host=server01, region=us-west]
A --> D[Fields: usage=75.5, status=ok]
A --> E[Timestamp: 2025-04-05T12:34:56Z]
3.1.2 Point对象的创建与组装
InfluxDB2的Java客户端提供了 Point 类用于构建数据点。我们通过链式调用方式来构建Point对象。
示例代码:
import org.influxdb2.Point;
import java.time.Instant;
public class PointExample {
public static void main(String[] args) {
// 构建一个Point对象
Point point = Point.measurement("temperature")
.addTag("location", "living_room")
.addField("value", 22.5)
.time(Instant.now().getEpochSecond(), WritePrecision.S); // 设置时间戳精度为秒
System.out.println("Point created: " + point.toLineProtocol());
}
}
代码逐行解析:
Point.measurement("temperature"):指定measurement名称为temperature。.addTag("location", "living_room"):添加tag键值对,表示该温度数据来自living_room。.addField("value", 22.5):添加field键值对,记录具体的温度数值。.time(...):设置时间戳,使用Instant.now()获取当前时间戳,并指定精度为秒级(WritePrecision.S)。point.toLineProtocol():将Point转换为InfluxDB2的Line Protocol格式,用于写入。
参数说明:
| 参数名 | 说明 |
|---|---|
| measurement | 数据表名,逻辑分类 |
| tag | 索引字段,用于查询优化 |
| field | 实际存储的数值 |
| time | 时间戳,决定数据的时间顺序 |
输出示例(Line Protocol格式):
temperature,location=living_room value=22.5 1712329200
3.2 单条写入操作实现
单条数据写入是最基础的写入方式,适用于低频次、实时性强的场景。Java客户端支持 同步写入 和 异步写入 两种方式。
3.2.1 同步写入方式
同步写入会阻塞当前线程,直到数据写入成功或失败,适用于需要确保写入结果的场景。
示例代码:
import org.influxdb2.InfluxDBClient;
import org.influxdb2.Point;
import org.influxdb2.WriteApi;
import java.time.Instant;
import java.util.concurrent.TimeUnit;
public class SyncWriteExample {
public static void main(String[] args) {
String url = "http://localhost:8086";
String token = "your_token";
String org = "your_org";
String bucket = "your_bucket";
try (InfluxDBClient client = InfluxDBClient.getInstance(url, token.toCharArray(), org, bucket)) {
WriteApi writeApi = client.getWriteApi();
Point point = Point.measurement("cpu_usage")
.addTag("host", "server01")
.addField("usage", 75.5)
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
System.out.println("Data written synchronously.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
代码解析:
InfluxDBClient.getInstance(...):创建InfluxDB2客户端实例。WriteApi writeApi = client.getWriteApi():获取写入接口。writeApi.writePoint(point):执行同步写入。- 使用
try-with-resources确保资源释放。
性能特点:
- 优点 :确保写入完成,适合关键数据。
- 缺点 :写入延迟较高,吞吐量受限。
3.2.2 异步写入方式对比
异步写入不会阻塞主线程,适用于高并发、容忍短暂失败的场景。
示例代码:
import org.influxdb2.InfluxDBClient;
import org.influxdb2.Point;
import org.influxdb2.WriteApi;
import java.time.Instant;
public class AsyncWriteExample {
public static void main(String[] args) {
String url = "http://localhost:8086";
String token = "your_token";
String org = "your_org";
String bucket = "your_bucket";
try (InfluxDBClient client = InfluxDBClient.getInstance(url, token.toCharArray(), org, bucket)) {
WriteApi writeApi = client.getWriteApi();
Point point = Point.measurement("cpu_usage")
.addTag("host", "server01")
.addField("usage", 75.5)
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
System.out.println("Async write initiated.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
与同步写入对比:
| 特性 | 同步写入 | 异步写入 |
|---|---|---|
| 是否阻塞线程 | 是 | 否 |
| 写入确认 | 有 | 无(默认) |
| 适用场景 | 关键数据、需确认写入结果 | 高并发、容忍失败 |
| 吞吐量 | 低 | 高 |
3.3 写入性能分析与调优
单条写入虽然简单易用,但性能表现直接影响系统整体效率。我们需要评估其延迟与吞吐量,并设计合理的重试机制。
3.3.1 单条写入的延迟与吞吐量评估
我们可以通过计时器测量写入操作的耗时,并计算吞吐量。
性能测试代码:
import org.influxdb2.Point;
import org.influxdb2.WriteApi;
import java.time.Instant;
public class PerformanceTest {
public static void main(String[] args) {
WriteApi writeApi = getWriteApi(); // 假设已初始化
long startTime = System.currentTimeMillis();
int count = 1000;
for (int i = 0; i < count; i++) {
Point point = Point.measurement("test")
.addTag("id", "perf")
.addField("value", Math.random())
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
}
long endTime = System.currentTimeMillis();
double duration = (endTime - startTime) / 1000.0;
double throughput = count / duration;
System.out.println("Total time: " + duration + "s");
System.out.println("Throughput: " + throughput + " points/s");
}
}
测试结果(示例):
| 写入次数 | 总耗时(s) | 吞吐量(points/s) |
|---|---|---|
| 1000 | 4.2 | 238 |
| 5000 | 21.5 | 232 |
性能分析:
- 单条写入在1000次写入时平均吞吐量约为235 points/s。
- 随着写入次数增加,吞吐量略有下降,主要受网络延迟和序列化开销影响。
3.3.2 写入失败的重试机制设计
为了提高写入可靠性,可以设计一个基于 指数退避 的重试机制。
示例代码:
import org.influxdb2.Point;
import org.influxdb2.WriteApi;
import java.time.Instant;
public class RetryWriteExample {
private static final int MAX_RETRIES = 3;
public static void retryWrite(WriteApi writeApi, Point point) {
int retry = 0;
while (retry <= MAX_RETRIES) {
try {
writeApi.writePoint(point);
System.out.println("Write successful.");
return;
} catch (Exception e) {
retry++;
if (retry > MAX_RETRIES) {
System.err.println("Write failed after " + MAX_RETRIES + " retries.");
return;
}
System.out.println("Retry " + retry + " due to: " + e.getMessage());
try {
Thread.sleep((long) Math.pow(2, retry) * 1000); // 指数退避
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
}
}
}
重试机制分析:
- 指数退避 :每次重试等待时间呈指数增长,减少服务器压力。
- 最大重试次数 :限制重试次数,防止无限循环。
3.4 典型使用场景示例
单条写入适用于实时性要求高、写入频率不高的场景。下面通过两个典型场景进行说明。
3.4.1 设备状态上报数据写入
物联网设备通常需要实时上报状态信息,如CPU温度、电池电量等。
代码示例:
public class DeviceStatusWriter {
public static void logDeviceStatus(WriteApi writeApi, String deviceId, double temperature, int batteryLevel) {
Point point = Point.measurement("device_status")
.addTag("device_id", deviceId)
.addField("temperature", temperature)
.addField("battery_level", batteryLevel)
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
System.out.println("Status written for device: " + deviceId);
}
}
调用示例:
logDeviceStatus(writeApi, "D12345", 38.7, 92);
Line Protocol输出:
device_status,device_id=D12345 temperature=38.7,battery_level=92 1712329200000
3.4.2 日志信息的即时记录
系统日志、错误日志等信息需要实时记录,便于后续分析。
代码示例:
public class LogRecorder {
public static void recordLog(WriteApi writeApi, String level, String message) {
Point point = Point.measurement("system_logs")
.addTag("level", level)
.addField("message", message)
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
System.out.println("Logged: " + level + " - " + message);
}
}
调用示例:
recordLog(writeApi, "ERROR", "Database connection failed.");
Line Protocol输出:
system_logs,level=ERROR message="Database connection failed." 1712329200000
本章详细介绍了如何使用Java客户端通过Point方式实现单条数据写入,包括数据模型构建、同步与异步写入方式的实现、性能分析与调优策略,并结合设备状态上报和日志记录两个典型场景进行示例演示。下一章将继续探讨批量写入的方式,以提升数据写入效率与吞吐能力。
4. Batch方式批量数据写入
在处理高频率时间序列数据时,单条写入的方式虽然简单易用,但在数据量大的场景下,往往会导致网络延迟增加、写入吞吐量受限等问题。为了解决这些问题,InfluxDB2 提供了基于 WriteApi 的批量写入(Batch Write)机制。通过批量提交多个 Point 数据,可以显著提升写入性能,减少网络开销,并提高整体系统的吞吐能力。
本章将从批量写入的优势与适用场景出发,深入解析 InfluxDB2 Java 客户端中 WriteOptions 配置项的作用、批量 Point 的组装方式、同步与异步提交机制,以及在实际应用中如何优化写入效率并处理异常情况。
4.1 批量写入的优势与适用场景
4.1.1 提高吞吐量与降低网络开销
在高频数据采集的场景下,例如物联网设备每秒上报一次状态数据,若采用单条写入方式,每条数据都需要一次独立的网络请求,会导致大量网络开销和系统资源浪费。而使用批量写入机制,可以将多个 Point 数据合并成一个请求发送到 InfluxDB2 服务器,从而减少请求次数,提升吞吐量。
| 特性 | 单条写入 | 批量写入 |
|---|---|---|
| 网络请求次数 | 每条数据一次 | 多条数据一次 |
| 吞吐量 | 低 | 高 |
| 延迟 | 高 | 低 |
| 内存消耗 | 低 | 高(缓存批量数据) |
通过合理设置批次大小和刷新间隔,可以在吞吐量与延迟之间取得平衡,适用于数据密集型应用。
4.1.2 高频采集数据的集中处理
批量写入适用于以下典型场景:
- 物联网设备监控 :数以万计的设备每秒上报传感器数据。
- 日志聚合系统 :应用服务器日志按批次提交到数据库进行分析。
- 金融交易系统 :高频交易数据需要快速持久化,避免数据丢失。
在这种场景中,使用批量写入可以避免单条数据写入造成的性能瓶颈。
4.2 批量写入配置与实现
4.2.1 WriteOptions配置项解析
InfluxDB2 Java 客户端通过 WriteOptions 类提供批量写入的配置参数,控制写入行为。以下是主要配置项及其作用:
WriteOptions writeOptions = WriteOptions.builder()
.batchSize(1000) // 每个批次的最大 Point 数量
.flushInterval(1000) // 刷新间隔(毫秒),即使未达到 batchSize,也提交一次
.jitterInterval(0) // 批量刷新的随机延迟,避免多个客户端同时刷新
.retryInterval(5000) // 重试失败写入的间隔时间
.maxRetries(5) // 最大重试次数
.maxBatchSize(10_000) // 批次最大数据量,防止内存溢出
.build();
| 配置项 | 说明 | 默认值 |
|---|---|---|
| batchSize | 批次最大 Point 数量 | 1000 |
| flushInterval | 批次刷新间隔(毫秒) | 1000 |
| jitterInterval | 批次刷新的随机延迟 | 0 |
| retryInterval | 写入失败重试间隔 | 5000 |
| maxRetries | 最大重试次数 | 5 |
| maxBatchSize | 单次写入最大数据量(字节) | 无限制 |
这些参数对性能和稳定性有直接影响,应根据实际数据量、网络环境和系统负载进行调整。
4.2.2 批次大小与刷新间隔设置
批次大小(batchSize)和刷新间隔(flushInterval)是影响写入性能的关键参数。设置原则如下:
- 高频低数据量场景 :设置较小的
batchSize和flushInterval,以减少延迟。 - 低频高数据量场景 :适当增大
batchSize和flushInterval,提升吞吐量。
例如:
WriteOptions highThroughput = WriteOptions.builder()
.batchSize(5000)
.flushInterval(5000)
.build();
WriteOptions lowLatency = WriteOptions.builder()
.batchSize(500)
.flushInterval(500)
.build();
通过选择合适的配置策略,可以满足不同业务场景的需求。
4.3 批量数据构建与提交
4.3.1 多Point对象的批量组装
InfluxDB2 中的 Point 是用于表示时间序列数据的基本单元。批量写入通常涉及多个 Point 的组装与提交。
List<Point> points = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
Point point = Point.measurement("sensor")
.tag("location", "room" + (i % 10))
.addField("temperature", Math.random() * 100)
.time(Instant.now(), WritePrecision.NS);
points.add(point);
}
上述代码创建了 1000 个模拟传感器数据的 Point,每个 Point 包含 measurement、tag、field 和时间戳。
4.3.2 批次提交的同步与异步处理
InfluxDB2 的 WriteApi 支持同步和异步两种写入方式:
同步写入示例:
InfluxDBClient client = InfluxDBClientFactory.create("http://localhost:8086", "my-token".toCharArray());
WriteApi writeApi = client.makeWriteApi();
for (Point point : points) {
writeApi.writePoint(point);
}
逻辑分析:
InfluxDBClientFactory.create(...):创建客户端实例。client.makeWriteApi():获取 WriteApi 实例。writeApi.writePoint(point):同步提交单个 Point。- 同步写入适用于对实时性要求高、数据量不大的场景。
异步写入示例:
WriteApi writeApi = client.makeWriteApi(writeOptions);
for (Point point : points) {
writeApi.writePoint(point);
}
逻辑分析:
- 异步写入通过
WriteOptions配置批次行为。 writeApi.writePoint(point):将 Point 缓存到内部队列中。- 当达到
batchSize或flushInterval时,自动提交数据。 - 异步写入适用于高吞吐量、低延迟容忍度的场景。
4.4 写入效率优化与异常处理
4.4.1 批次积压与内存管理
在使用异步写入时,若数据生成速度远大于写入速度,可能导致内存中积压大量未提交的数据,进而引发 OOM(内存溢出)异常。
优化建议:
- 合理设置
maxBatchSize和maxRetries,避免内存占用过高。 - 监控写入延迟和积压数据量,及时调整配置。
- 使用背压机制(如限流)防止写入过载。
// 监控当前积压数据量
int pending = writeApi.getPendingPointsCount();
if (pending > 10000) {
System.out.println("当前积压点数:" + pending + ",考虑暂停采集");
}
4.4.2 写入失败的批量回滚与重试策略
在写入过程中,可能会因为网络中断、服务不可用等原因导致写入失败。InfluxDB2 提供了自动重试机制,但需结合业务逻辑进行回滚与补偿处理。
示例代码:
writeApi.setWriteFailureListener((writeException, points) -> {
System.err.println("写入失败:" + writeException.getMessage());
System.err.println("失败的点数:" + points.size());
for (Point point : points) {
System.err.println("失败点:" + point.toLineProtocol());
}
// 可在此处将失败的数据缓存或重新提交
});
参数说明:
writeException:异常信息。points:本次写入失败的 Point 列表。- 可以将失败的 Point 缓存至本地队列,待恢复后重新提交。
重试策略优化:
- 指数退避重试 :每次重试间隔递增,避免雪崩效应。
- 失败数据缓存 :将失败的数据持久化,防止程序重启后丢失。
- 人工干预机制 :对于连续失败的写入操作,触发报警或人工介入处理。
graph TD
A[写入请求] --> B{写入成功?}
B -- 是 --> C[数据写入完成]
B -- 否 --> D[触发失败监听]
D --> E[记录失败数据]
D --> F[重试机制启动]
F --> G{重试次数达到上限?}
G -- 是 --> H[记录失败数据并报警]
G -- 否 --> I[延迟重试]
I --> A
该流程图展示了 InfluxDB2 批量写入失败处理的完整流程,从写入请求到失败监听、重试以及最终报警的完整闭环机制。
通过本章内容的学习,我们深入了解了 InfluxDB2 批量写入的核心机制,包括其配置方式、批量 Point 的组装与提交、性能优化技巧以及异常处理策略。这些内容将为后续章节中关于查询与数据处理的内容打下坚实基础。
5. 使用InfluxQL进行数据查询与结果处理
5.1 InfluxQL与Flux语言对比
5.1.1 查询语言的演进与发展
InfluxQL 是 InfluxDB 1.x 的原生查询语言,语法上类似于 SQL,适用于时间序列数据的聚合、过滤、分组等操作。而随着 InfluxDB 2.x 的推出,InfluxQL 被 Flux 所取代,Flux 是一种函数式、流式查询语言,专为时间序列数据和实时分析设计。
Flux 的优势在于其灵活的函数链式调用方式,支持跨多个数据源的查询,并具有强大的数据流处理能力。例如,Flux 支持动态时间窗口、条件判断、变量定义等高级功能,适合构建复杂的分析流水线。
| 对比维度 | InfluxQL | Flux |
|---|---|---|
| 语法风格 | 类 SQL | 函数式流式语法 |
| 支持版本 | InfluxDB 1.x | InfluxDB 2.x 及 InfluxDB 1.8+ |
| 数据源支持 | 仅支持 InfluxDB | 支持多种数据源(HTTP、CSV等) |
| 时间窗口处理 | 固定时间间隔(GROUP BY time) | 动态时间窗口(aggregateWindow) |
| 变量与逻辑控制 | 不支持 | 支持函数、变量、条件判断 |
5.1.2 常用语法结构与执行流程
以查询某个设备在过去一小时内的温度数据为例:
InfluxQL 示例:
SELECT "value" FROM "temperature" WHERE "device_id" = 'D123' AND time > now() - 1h
Flux 示例:
from(bucket: "my-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "temperature" and r.device_id == "D123")
|> filter(fn: (r) => r._field == "value")
Flux 的执行流程是典型的流式管道模型,每个函数都会对数据流进行一次变换。这种结构使得查询逻辑清晰、可复用性强。
5.2 Java中执行查询操作
5.2.1 QueryApi接口调用方式
InfluxDB 2 提供了 QueryApi 接口用于执行 Flux 查询语句。该接口位于 influxdb-client-java 的 com.influxdb.client 包中。
基本调用方式如下:
import com.influxdb.client.InfluxDBClient;
import com.influxdb.client.InfluxDBClientFactory;
import com.influxdb.client.QueryApi;
import com.influxdb.query.FluxTable;
public class QueryExample {
public static void main(String[] args) {
String url = "http://localhost:8086";
String token = "your-api-token";
String org = "your-org";
String bucket = "your-bucket";
try (InfluxDBClient client = InfluxDBClientFactory.create(url, token.toCharArray(), org, bucket)) {
QueryApi queryApi = client.getQueryApi();
String fluxQuery = "from(bucket: \"your-bucket\")\n" +
" |> range(start: -1h)\n" +
" |> filter(fn: (r) => r._measurement == \"temperature\" and r.device_id == \"D123\")\n" +
" |> filter(fn: (r) => r._field == \"value\")";
List<FluxTable> tables = queryApi.query(fluxQuery);
// 后续处理查询结果
}
}
}
5.2.2 构建Flux查询语句的Java实现
为了提高代码可读性和灵活性,可以使用 Java 构建 Flux 查询语句字符串。例如:
public static String buildFluxQuery(String measurement, String deviceId, String field, String timeRange) {
return String.format("from(bucket: \"%s\")\n" +
" |> range(start: %s)\n" +
" |> filter(fn: (r) => r._measurement == \"%s\" and r.device_id == \"%s\")\n" +
" |> filter(fn: (r) => r._field == \"%s\")",
"your-bucket", timeRange, measurement, deviceId, field);
}
通过该方法可以动态生成查询语句,适用于不同设备和指标的查询需求。
5.3 响应式编程模型处理查询结果
5.3.1 Flux流式响应处理
InfluxDB Java 客户端支持响应式编程模型(Reactive Streams),通过 queryStream 方法获取 Flux 数据流:
import org.reactivestreams.Subscription;
import org.reactivestreams.Subscriber;
import com.influxdb.query.FluxRecord;
import com.influxdb.query.FluxTable;
queryApi.queryStream(fluxQuery, (FluxRecord record) -> {
System.out.println("Measurement: " + record.getTable());
System.out.println("Time: " + record.getTime());
System.out.println("Value: " + record.getValue());
});
这种方式适合处理大量数据时,避免一次性加载全部结果,提高内存效率。
5.3.2 使用Projector等工具解析结果
Projector 是一个常用的工具类,用于将 Flux 查询结果映射为 Java 对象。例如:
List<TemperatureRecord> records = queryApi.query(fluxQuery, TemperatureRecord.class);
其中 TemperatureRecord 是一个 POJO 类,包含字段如 time , value , device_id 等。InfluxDB 客户端会自动将每个 FluxRecord 映射到该类的实例。
5.4 查询结果解析与通用处理方法设计
5.4.1 Table结构与Record对象的提取
每个 Flux 查询结果由多个 FluxTable 组成,每个表对应一个数据集(例如一个 tag 组合)。每个表中包含多个 FluxRecord ,代表一行数据。
for (FluxTable table : tables) {
System.out.println("Table schema: " + table.getColumns());
for (FluxRecord record : table.getRecords()) {
System.out.println("Time: " + record.getTime() + ", Value: " + record.getValue());
}
}
5.4.2 结果映射为Java实体类的通用方案
定义一个通用的实体类模板:
public class DataPoint<T> {
private Instant time;
private String measurement;
private Map<String, Object> tags;
private String field;
private T value;
// Getters and Setters
}
结合泛型和 Projector 可实现通用的数据解析逻辑,适用于多种类型的数据。
5.4.3 分页查询与数据聚合处理
对于大数据量的查询,可以使用分页处理,例如按时间范围分段查询:
String start = "-2h";
String stop = "-1h";
String fluxQuery = String.format("from(bucket: \"%s\")\n" +
" |> range(start: %s, stop: %s)\n" +
" |> filter(fn: (r) => r._measurement == \"temperature\")", bucket, start, stop);
同时,Flux 还支持丰富的聚合函数,如 aggregateWindow 、 timedMovingAverage 等,用于实现平均值、最大值、移动平均等统计分析:
|> aggregateWindow(every: 5m, fn: mean)
简介:InfluxDB2是专为时间序列数据设计的高性能数据库,广泛应用于物联网、监控系统和日志分析。本示例详细演示了如何在Java中使用官方客户端库与InfluxDB2进行交互,包括引入依赖、连接数据库、使用Point和Batch进行单条与批量写入,以及通过InfluxQL进行数据查询与结果处理。通过本示例,开发者可以快速掌握InfluxDB2在Java项目中的核心操作流程,实现高效的时间序列数据读写与解析。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)