【霹雳吧啦】手把手带你入门语义分割3:FCN 网络结构详解 & FCN-32s FCN-16s FCN-8s & Convolutionalization & 损失计算 & 评价指标
目录
前言
这篇文章是我根据 B 站 霹雳吧啦Wz 的《深度学习:语义分割篇章》中的 FCN网络结构详解 所作的学习笔记,涵盖内容如目录所示,希望能为正在学习语义分割的小伙伴们提供一些帮助ヾ(^▽^*))) 因为才刚刚开始接触语义分割,所以在表达上可能比较幼稚,希望王子公主们多多包涵啦!如果存在问题的话,请大家直接指出噢~
- 在做笔记的过程中,我还参考了这篇博客:语义分割|学习记录(3)FCN_fcn-8s-CSDN博客
- 在做笔记的过程中,我还参考了这篇博客:语义分割学习笔记 P3-CSDN博客
一、什么是 FCN 网络模型
相关论文:Fully Convolutional Networks for Semantic Segmentation
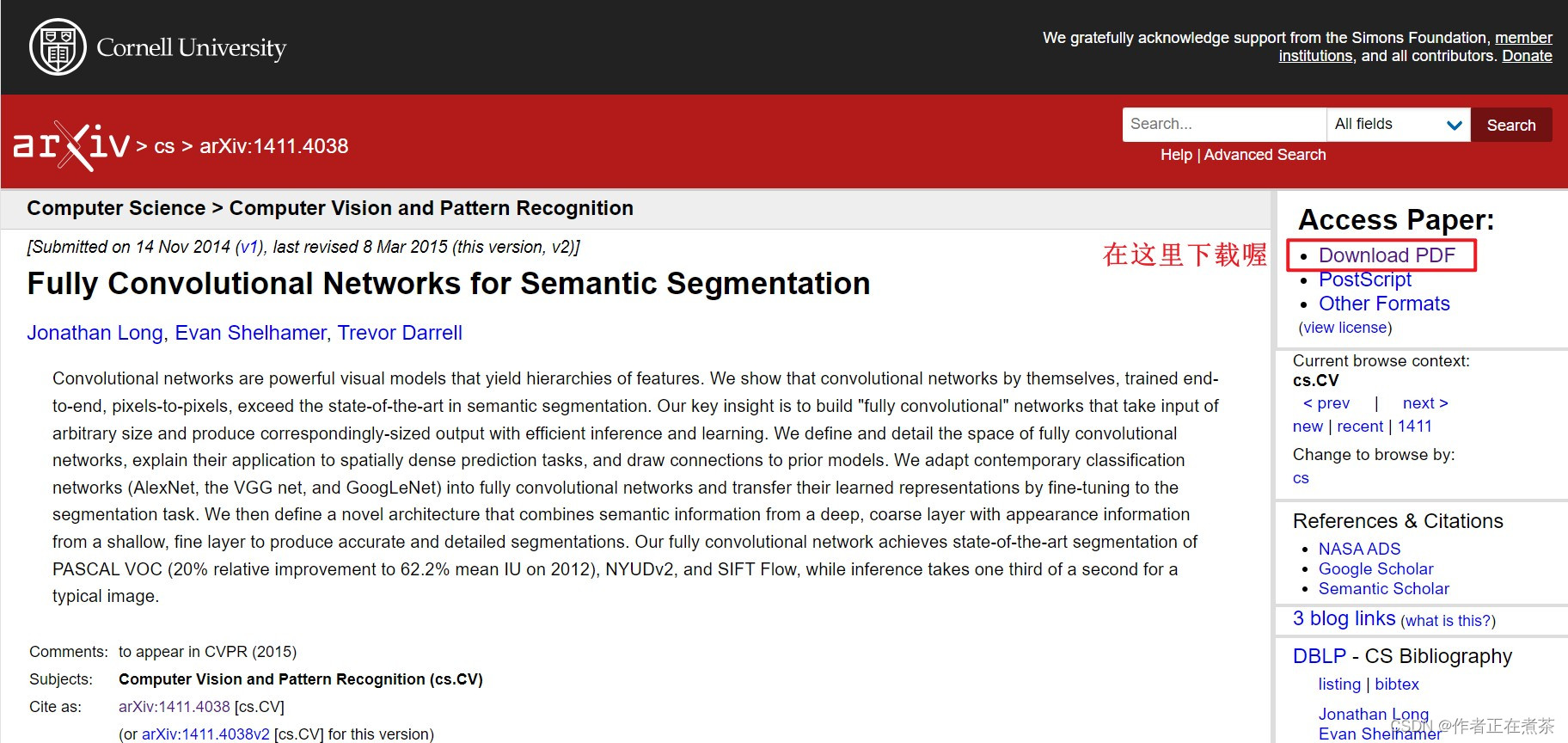
这篇论文中提到,FCN 网络是 首个 端对端的针对像素级预测的 全卷积 网络,这里的 全卷积 是指将分类网络中的全连接层全部替换为卷积层。FCN 网络是语义分割领域中非常经典的网络噢 ヾ(•ω•`)o
首先,通过查看 FCN 网络进行语义分割的效果,可以发现 FCN-8s 的效果与我们人工标注的 Ground truth 非常接近,这说明 FCN 网络在当年进行语义分割的效果非常不错。

接着,作者基于 2011 与 2012 的 PASCAL VOC 测试数据集,将 FCN 网络与当年的主流网络进行对比,发现 FCN 网络的 mean IoU 提升了 20% ,且 推理时间 更短。具体的对比情况可以参考论文提供的这张表:

此外,论文还给出了 FCN-32s 网络模型的正向推理与反向学习过程:通过一系列的 卷积 和 下采样 得到 特征层 ,最后一个特征层的 channel = 21 ,因为使用的是 PASCAL VOC 数据集(20 类别+背景),再经过 上采样 得到和原图大小相同且 channel = 21 的特征图,通过对其每个像素的 21 个值进行 softmax 处理,得到该像素针对每个类别的预测概率,最后取概率最大的类别作为预测类别。
二、Convolutionalization
1、Convolutionalization 引入
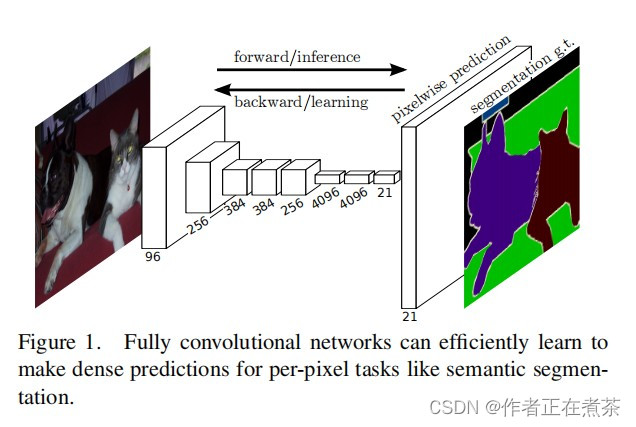
在下面这张图中,4096、4096 和 1000 对应的都是全连接层的输出,输入一张图片,通过分类网络后会得到一个针对 1000 个类别的预测值,将这 1000 个预测值进行 softmax 处理后,可以得到针对每个类别的概率,然后对这些数值进行可视化,例如以柱状图的形式进行可视化展示,我们可以看到预测为 tabby cat 的柱子最高。
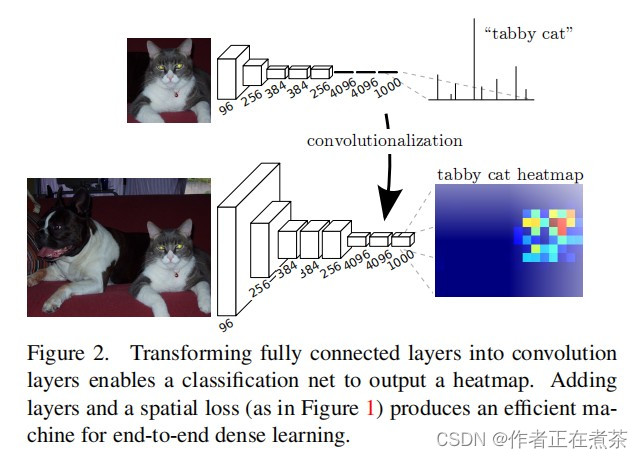
全连接层要求输入结点的个数固定,即 输入图片的像素固定 ,若改变则报错,因此训练分类网络时要固定输入图片的大小。但如果我们将 全连接层改为卷积层 ,那么训练分类网络时对输入图片的大小就无限制了。因此我们对全连接层进行了 Convolutionalization 处理。
【补充】如果输入图片的大小大于 224 x 224 ,那么最终得到的特征层的高和宽将大于 1 ,这时对应每个 channel 的数据就是 2 维数据,我们可以将其可视化成一张图片的形式,也就是上图中的 tabby cat heatmap 。
2、回忆 VGG16 网络模型
在 VGG16 网络模型中,通常使用 D 配置,输入图片经过这个网络模型后,从 224 x 224 x 3 至 7 x 7 x 512 ,下采样 32 倍,在经过三个全连接层,前两个全连接层对应的是 4096 个结点,第三个全连接层对应的是 1000 个结点。
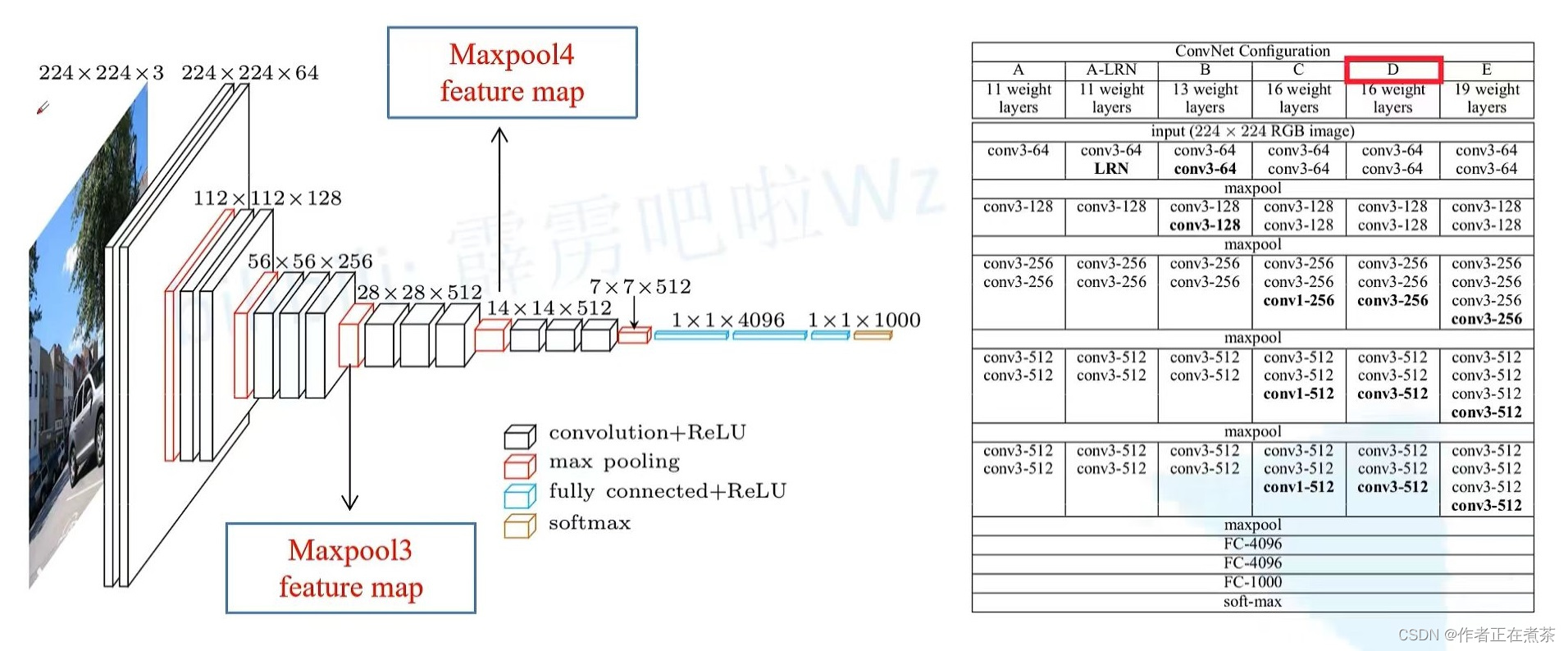
【注意】大家最好记住 Maxpool3 的下采样率为 8 ,Maxpool4 的下采样率为 16 哟!
3、Convolutionalization 过程
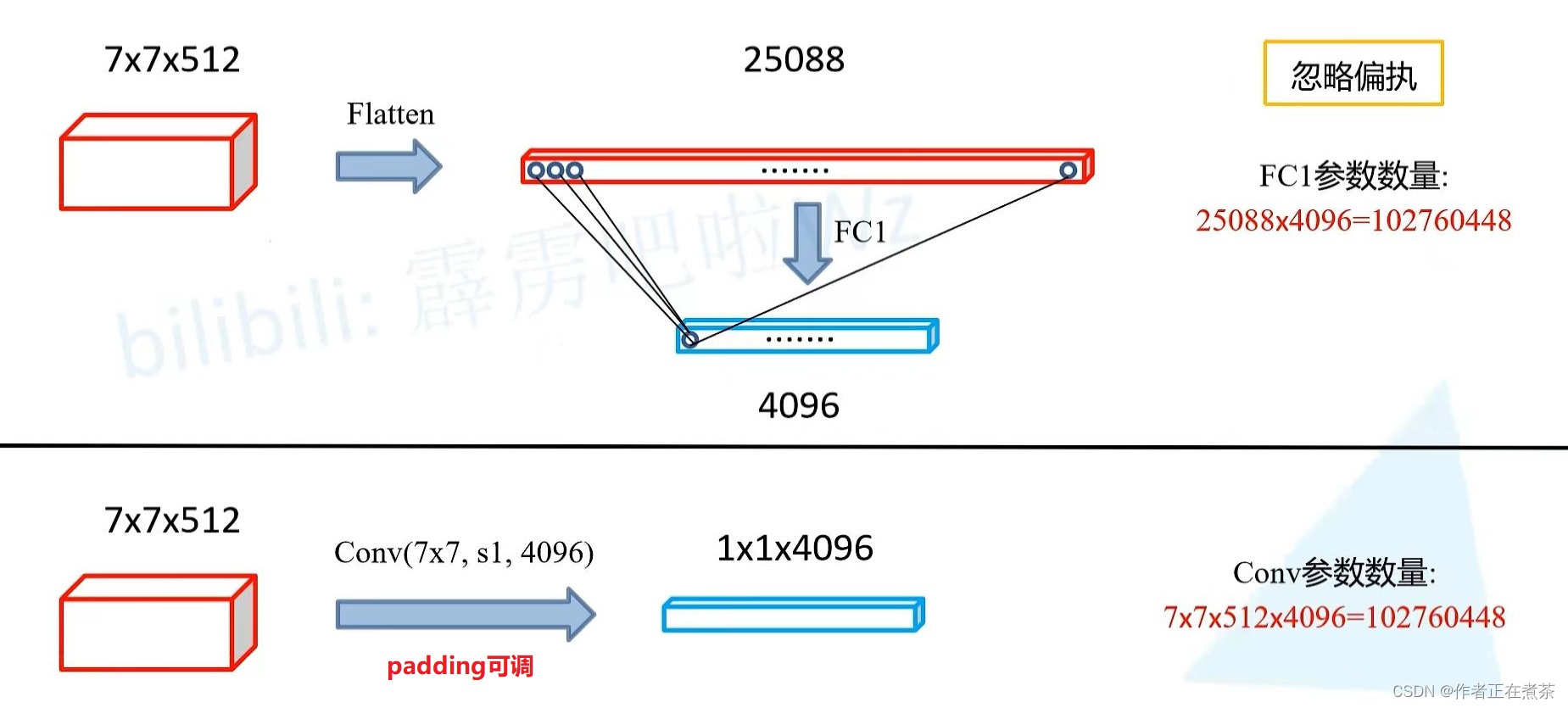
通过分析计算可知,这两个过程完全等效,这也就是 Convolutionalization 的过程,将第一个全连接层转化为卷积层的过程:
- 全连接层:对 7 x 7 x 512 的特征层进行展平和全连接操作后,FC1 参数数量为 7 x 7 x 512 x 4096 = 102760448
- 卷积层:对 7 x 7 x 512 的特征层进行 conv ( 7 x 7 , s1, 4096 ) 卷积操作后,Conv 参数数量为 7 x 7 x 512 x 4096 = 102760448
三、详细介绍 FCN 网络模型
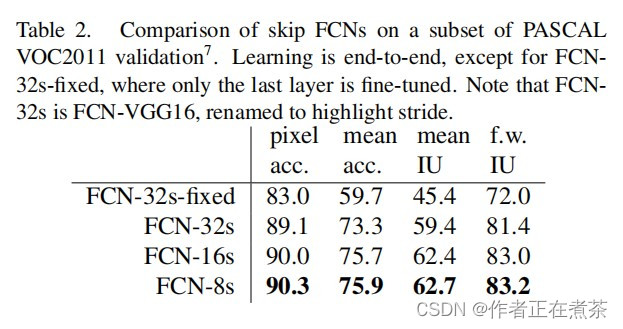
这篇论文还给出了 FCN-32s-fixed、FCN-32s、FCN-16s 和 FCN-8s 等模型的性能指标对比列表,具体如下:
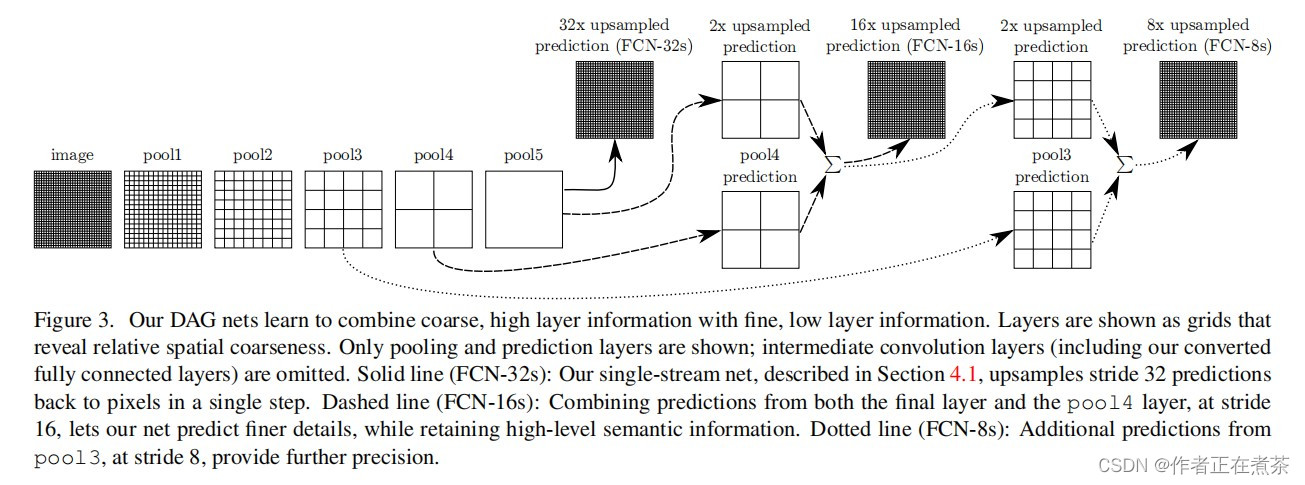
先来简单讲讲 FCN-32s、FCN-16s 和 FCN-8s 是什么样的:
- FCN-32s 将预测结果上采样了 32 倍,还原回原图大小
- FCN-16s 将预测结果上采样了 16 倍,还原回原图大小
- FCN-8s 将预测结果上采样了 8 倍,还原回原图大小
1、FCN-32s
在原论文中,作者在 backbone 的第一个卷积层中将 padding 设置为 100 ,这是为了让 FCN 网络能够适应不同大小的图片。
参考上文的 VGG 模型可知,输入图片的高宽小于 192 时,最后一个特征层的高宽小于 7 ,此时若将 padding 设置为 0 会报错。
【注意】我们通常不对高宽小于 32 的图片进行语义分割,所以只需将 padding 设置为 3 即可,这样就可以训练任意高宽大于 32 的图片啦!没有必要将 padding 设置为 100 ,这样不仅会增大网络的计算量,还会导致在上采样后要做一定的裁剪。
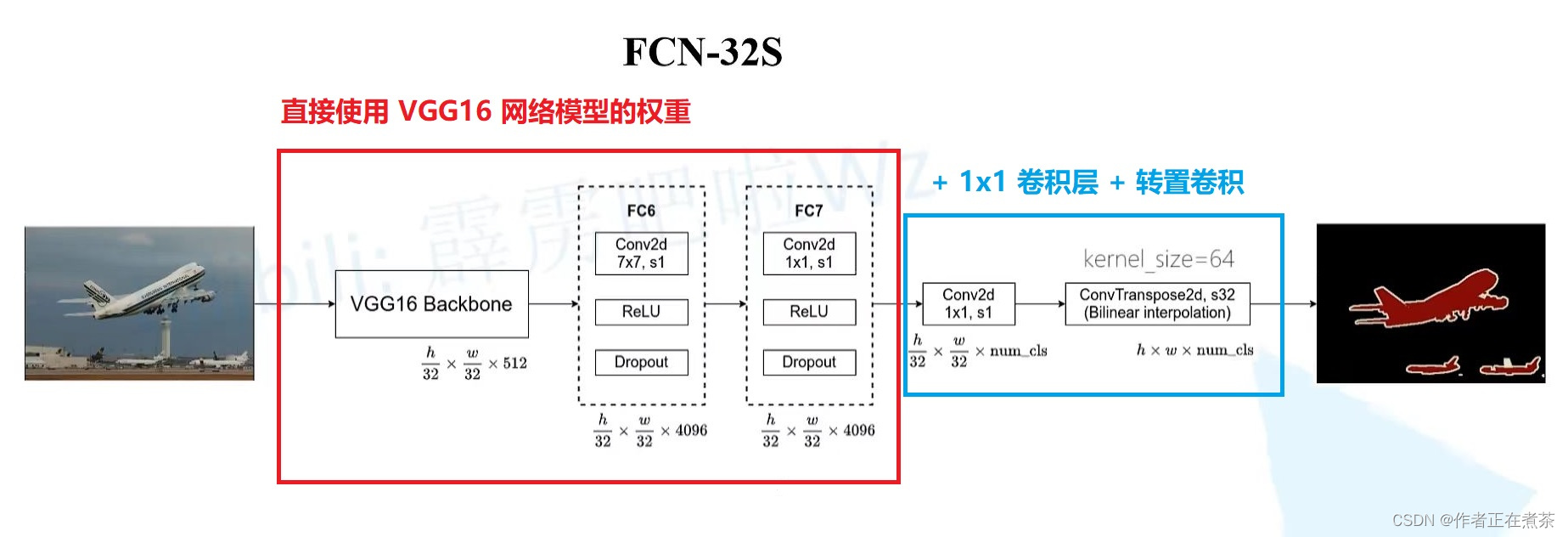
【重点】结合视频教程的截图,微臣尽可能用比较清晰的语言来介绍 FCN-32s 网络模型:
- 输入特征图经过 VGG16 Backbone 后的输出为 h / 32 * w / 32 * 512
- 经过 FC6 对应的卷积层后高宽不变 :H_out = ( H_in + 2 * padding - kernel_size ) / stride + 1 = ( H_in + 6 - 7 ) / 1 + 1 = H_in
- 经过 FC7 对应的卷积层后高宽不变 :H_out = ( H_in + 2 * padding - kernel_size ) / stride + 1 = ( H_in + 0 - 1 ) / 1 + 1 = H_in
- 经过 1 x 1 的卷积层,卷积核个数 channel = 包含背景在内的分类类别个数 num_class
- 经过转置卷积(在我的上篇文章中有具体讲解)上采样 32 倍,恢复到原图的大小,针对每个像素都有 num_class 个参数
- 经过 softmax 处理后就能够得到针对每个像素的预测类别
【注意】在第五步中,原论文作者是通过双线性差值的方法来初始化转置卷积的参数的,大家如果有兴趣的话,可以参考这篇博文:
 https://blog.csdn.net/qq_37541097/article/details/112564822
https://blog.csdn.net/qq_37541097/article/details/112564822【补充】在第五步中,源代码中转置卷积的学习参数被冻结住了,这意味着它就是一个简单的双线性插值,因此这里甚至可以不使用转置卷积,而直接使用深度学习框架中提供的双线性插值方法。将其冻结是因为原论文作者通过实验发现是否冻结对结果的影响不大,但是冻结之后就无需训练其对应的权重,从而可以加速网络的训练过程。而之所以这里转置卷积的使用效果不佳,是因为上采样率过大。
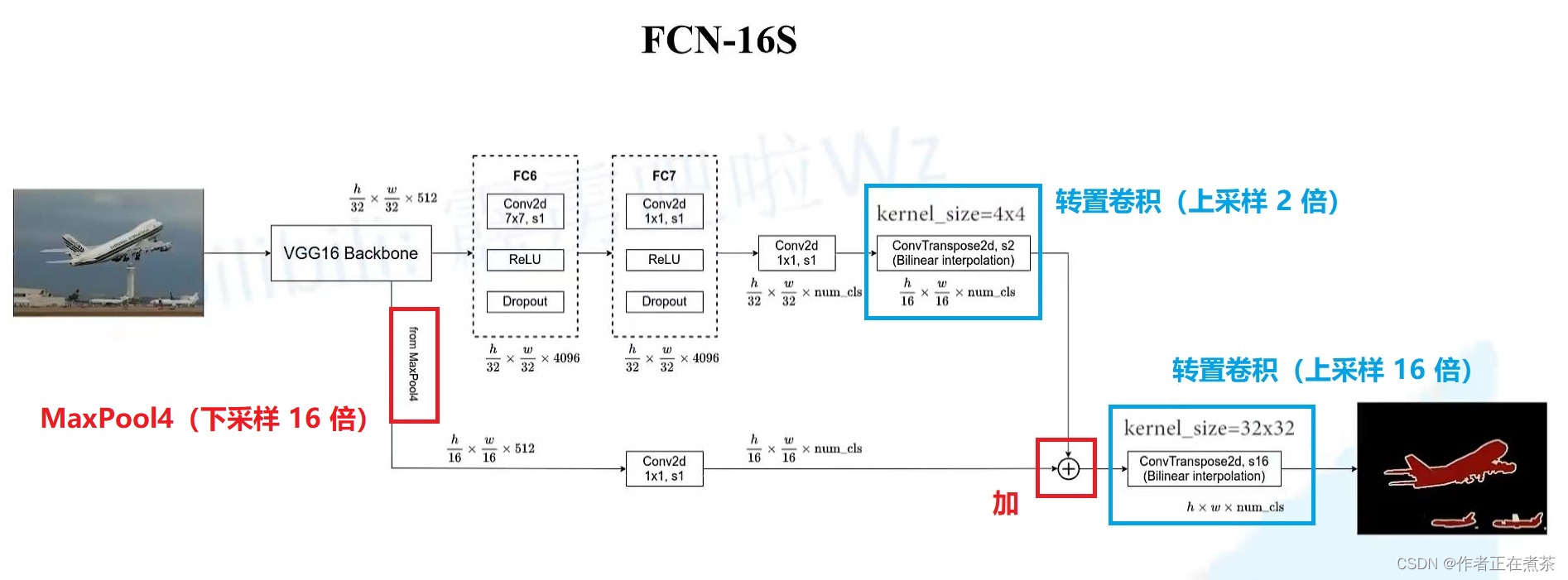
2、FCN-16s
谈谈 FCN-16s 和 FCN-32s 的区别:
- FCN-16s 使用的第一个转置卷积上采样 2 倍,第二个转置卷积上采样 16 倍
- FCN-16s 额外使用了来自 MaxPool4 下采样了 16 倍的输入特征图
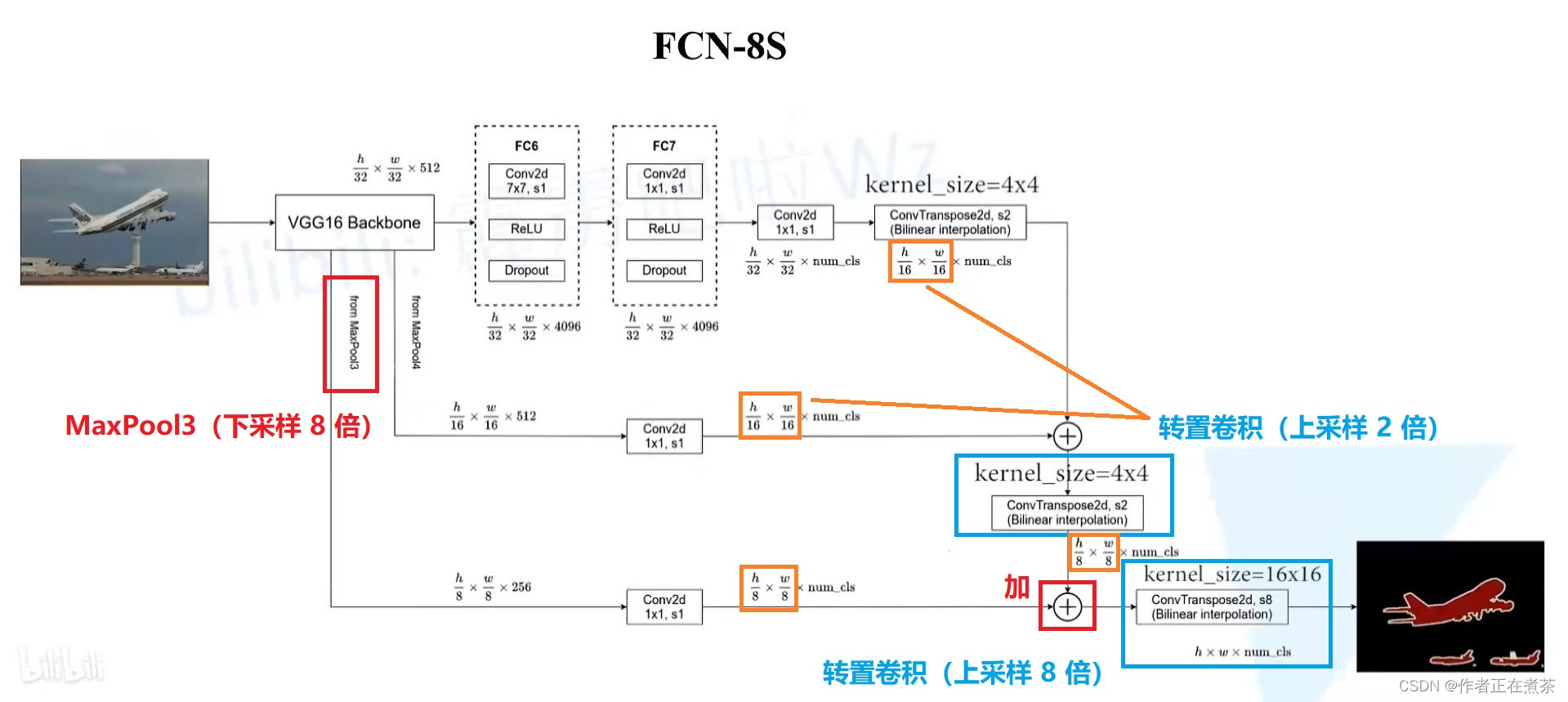
3、FCN-8s
谈谈 FCN-8s 和 FCN-16s 的区别:
- FCN-16s 使用的第一个转置卷积上采样 2 倍,第二个转置卷积上采样 2 倍,第三个转置卷积上采样 8 倍,
- FCN-16s 额外使用了来自 MaxPool3 下采样了 8 倍的输入特征图
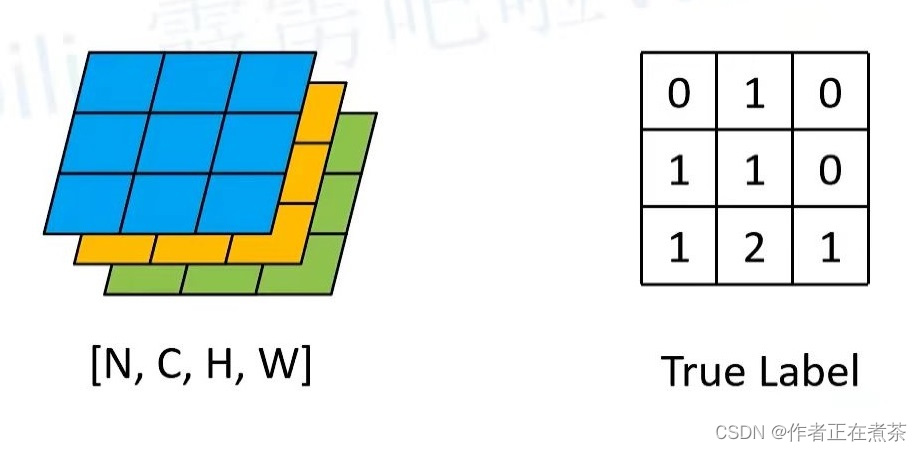
四、损失计算 Cross Empty Loss
针对每个像素( pixel )计算 Cross Entropy Loss,然后将所有 Cross Entropy Loss 相加求平均得到网络的最终损失。
五、语义分割评价指标
常见的语义分割评价指标主要包括 Pixel Accuracy ( Global Accuracy )、mean Accuracy、mean IoU 等:
- Pixel Accuracy = 类别预测正确的像素个数总和 ÷ 图片的总像素个数
- mean Accuracy = 对每个类别的 Accuracy 求平均值
- mean IoU = 对每个类别的 IoU 求平均值
关于语义分割评价指标,微臣在本系列的第一篇文章中已经作了详细的讲解,王子公主们请移驾我的这篇博文:
最后说些话
致亲爱的王子公主们:微臣在这篇文章中已经尽可能用比较清晰的语言来陈述啦!但感觉还有极大的进步空间~之后会继续努力的!最后祝大家身体健康,生活顺利!

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 35
35 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)