【HIVE】HiveQL数据查询 1
在Hive中,order by与SQL中定义一致,而增加了SORT BY语句,会在每个reducer中对数据排序,也就是会执行一个局部排序,可以保证每个reducer的输出数据都是有序的(并非全局有序),可以提高后续进行全局排序的效率。两个关键字都可以使用ASC、DESC关键字进行升降排序。选择建议:数据量级大时选择SORT BY,量级小用ORDER BY。
·
一、基础查询
1.SELECT
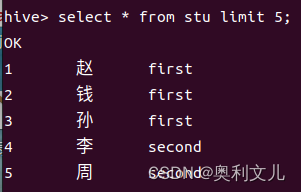
查询前5行:
select * from stu limit 5;
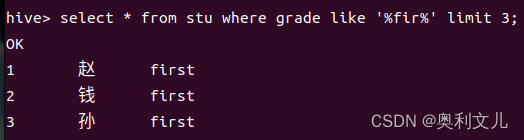
2.WHERE
select * from stu where grade like '%fir%' limit 3;
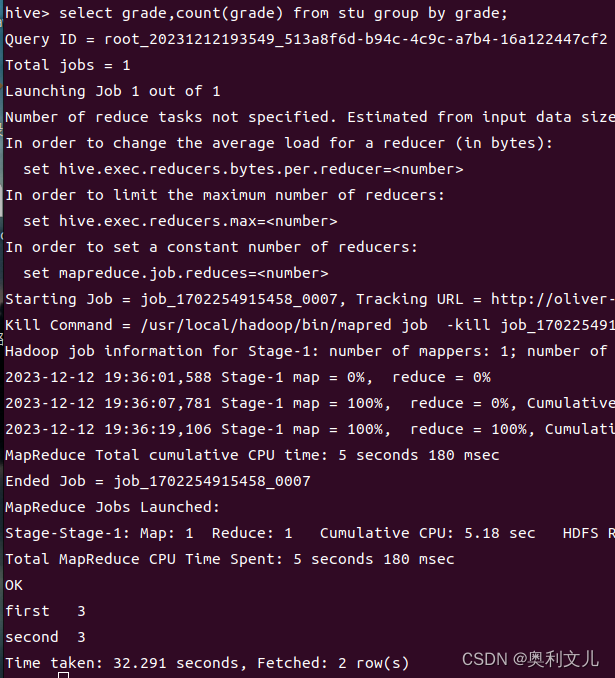
3.GROUP BY
select grade,count(grade) from stu group by grade; #运行时间较慢
4.HAVING
select grade,count(grade) from stu group by id,grade having id<8;

5.ORDER BY、SORT BY
在Hive中,order by与SQL中定义一致,而增加了SORT BY语句,会在每个reducer中对数据排序,也就是会执行一个局部排序,可以保证每个reducer的输出数据都是有序的(并非全局有序),可以提高后续进行全局排序的效率。两个关键字都可以使用ASC、DESC关键字进行升降排序。 选择建议:数据量级大时选择SORT BY,量级小用ORDER BY。
二、连接查询
表一:
create table uuser (user_id bigint,salary bigint,name string,ID_card string,sex string,age bigint,job string,product_id string,product string,channel string,prt_dt date) row format delimited fields terminated by ',';
表二:
create table tuser (user_id bigint,salary bigint,name string,ID_card string,sex string,age bigint,job string,product_id string,product string,channel string,prt_dt date) row format delimited fields terminated by ',' location '/home/oliver/hive/hive-3.1.3/metastore_db/school.db/tuser';
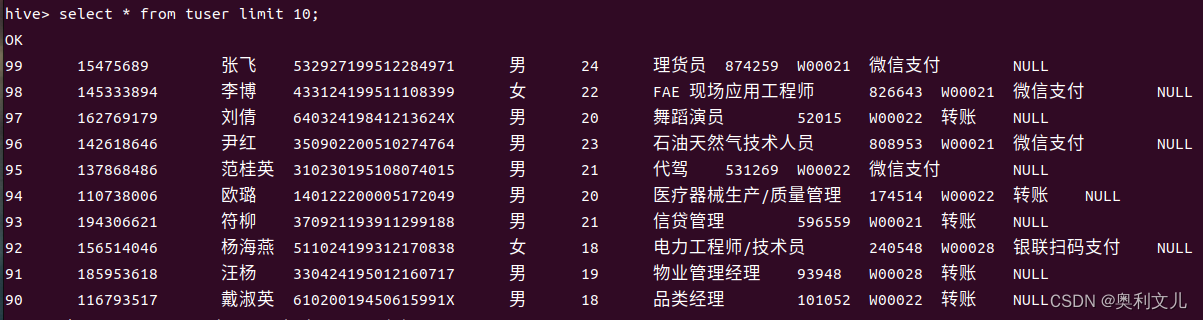
将表一查询到的数据导入表二:
insert overwrite table tuser select * from uuser limit 100;
1.内连接
select a.* from uuser a inner join tuser b on a.user_id=b.user_id where a.salary>5000;
2.自然连接
select uuser.* from uuser natural join tuser where uuser.job like '%经理%';
3.外连接
select a.* from uuser a left outer join tuser b on a.user_id=b.user_id where a.salary>5000;
全外连接:
select a.* from uuser a full outer join tuser b on a.user_id=b.user_id where a.salary>5000;
4.自连接
select * from uuser u ,tuser t where u.user_id=t.user_id

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)