Milvus向量数据库入门指南
Milvus是一个开源的向量数据库,专为AI应用和向量相似度搜索而设计,以加速非结构化数据的检索。自2019年创建以来,Milvus专注于存储、索引和管理由深度神经网络和其他机器学习模型生成的海量嵌入向量。其能够处理万亿级别的向量索引任务。Milvus的核心优势在于其高效的索引机制,它支持多种索引类型,包括FLAT、IVF_FLAT、IVF_SQ8、IVF_PQ和HNSW等。这些索引类型适用于不同
一、Milvus简介
Milvus是一个开源的向量数据库,专为AI应用和向量相似度搜索而设计,以加速非结构化数据的检索。自2019年创建以来,Milvus专注于存储、索引和管理由深度神经网络和其他机器学习模型生成的海量嵌入向量。其能够处理万亿级别的向量索引任务。
Milvus的核心优势在于其高效的索引机制,它支持多种索引类型,包括FLAT、IVF_FLAT、IVF_SQ8、IVF_PQ和HNSW等。这些索引类型适用于不同的应用场景,如图像识别、自然语言处理、推荐系统等。Milvus还提供了灵活的API接口,方便开发者集成和使用。
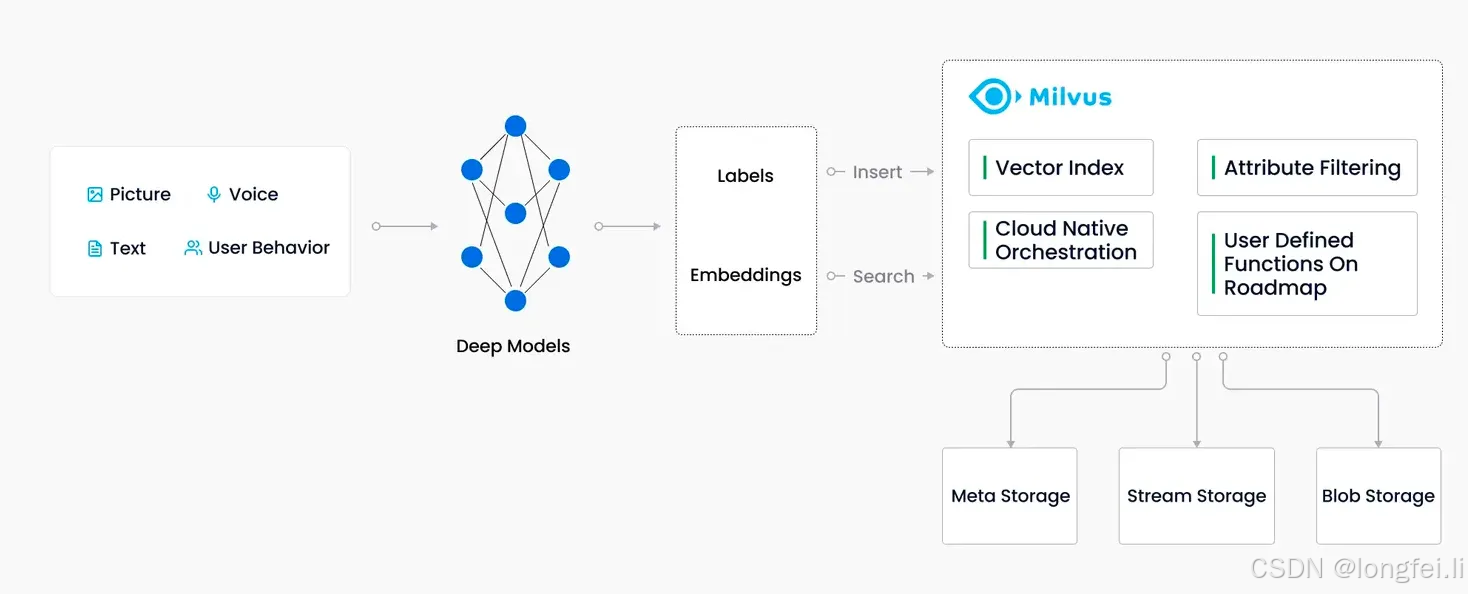
二、Milvus关键概念
非结构化数据
非结构化数据指的是那些没有固定格式和结构的数据,比如图像、视频、音频等数据都是非结构化数据。这类数据不遵循任何预定义的模型,且无法用二维的数据结构来定义其数据内容。但这种数据占据了世界数据的80%,为了挖掘和分析此类数据可以通过各种人工智能或机器学习模型将其转化为向量数据后进行处理。
嵌入向量
嵌入向量又被称为embedding vector,在大模型应用开发领域经常提到embedding,指的就是将非结构化数据(如音视频、ppt文档、图片等)转成向量化表示。
向量化表示可以理解为是非结构化数据的特征抽象表达,在数学的表达式中,向量是一个由浮点数或二进制数组成的n纬数组。
相似度搜索
相似度搜索是指将目标对象与向量数据库中的数据进行比对,找到与其最相似的结果;向量的相似度检索是通过embedding算法将非结构化数据转成vector,并使用最近邻搜索(ANN)算法计算出与其距离最相近的向量。同理,召回的原数据也是最相似的。
三、Milvus优势
简单易用:Milvus向量数据库可以让用户在几分钟内轻松搭建大型向量相似性搜索服务,提供多种语言的SDK,操作简单直观。
快速高效:Milvus有效节省硬件资源,并提供多样的索引算法。Milvus性能出色,向量召回速率极高。
高可用性:Milvus向量数据库受上千家企业信赖,适用于多种用例场景。Milvus系统组件相互独立、隔离,能充分确保系统弹性和可靠性。
高可扩展性:Milvus的分布式架构和高吞吐量特性使其非常适合处理大规模向量数据。
云原生:Milvus是一款云原生的向量数据库,采用存储与计算分离的架构设计,支持灵活扩展。
丰富功能:Milvus支持多种数据类型,提供数据过滤、多种数据一致性等级、Time Travel等丰富的功能。
存储计算分离:Milvus采用共享存储架构,存储计算完全分离,计算节点支持横向扩展,各个层次相互独立,独立扩展和容灾。
硬件感知优化:Milvus针对多种硬件架构和平台优化了其性能,包括AVX512、SIMD、GPU和NVMe SSD。
高级搜索算法:Milvus支持多种内存和磁盘索引/搜索算法,包括IVF、HNSW、DiskANN等,所有这些算法都经过了深度优化。
四、Milvus支持的索引类型
FLAT
● 特点:FLAT索引适用于需要100%召回率且数据规模相对较小(百万级)的向量相似性搜索应用。它不对向量进行压缩,因此是唯一能保证搜索结果完全准确的索引。
● 适用场景:适合数据集较小且对搜索精度要求极高的情况
IVF_FLAT
● 特点:IVF_FLAT是一种基于量化的索引,将向量数据划分为多个聚类单元,通过调节nprobe在召回率与查询速度之间找到平衡。
● 适用场景:适合需要较高召回率和快速查询的场景。
IVF_SQ8
● 特点:IVF_SQ8也是一种基于量化的索引,标量量化(SQ)将每个浮点数(4字节)压缩为1字节,减少内存占用。
● 适用场景:适合内存资源有限,允许轻微的召回率下降的场景。
IVF_PQ
● 特点:IVF_PQ结合IVF和PQ(乘积量化),进一步压缩数据存储需求,适用于追求高查询速度、低准确性的场景。
● 适用场景:适合内存资源有限,允许较大召回率下降,适合极高速查询的场景。
HNSW
● 特点:HNSW使用多层结构的导航小世界图(NSW)进行搜索,适用于追求高查询效率的场景。
● 适用场景:适合高精度和快速查询,适合内存资源充足的场景。
ANNOY
● 特点:ANNOY是基于树的索引,适用于追求高召回率的场景,特别是在低维向量空间中。
● 适用场景:适合追求高召回率的场景,尤其是在低维向量空间中。
SCANN(Beta版)
● 特点:SCANN索引利用SIMD提升计算效率,适用于高精度、高查询速率的场景,适合内存资源较为充足的场景。
● 适用场景:适合高精度,高查询速率的场景,适合内存资源较为充足的场景。
DISKANN
● 特点:DISKANN是一种磁盘上的索引,适用于大规模数据集,可以在磁盘上高效地进行近似最近邻搜索。
● 适用场景:适合大规模数据集,需要在磁盘上进行高效搜索的场景。
五、Milvus的安装
5.1 使用Docker Compose安装
$ wget https://github.com/milvus-io/milvus/releases/download/v2.4.17/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo docker-compose up -d
5.2 验证安装
使用以下命令查看服务状态:
sudo docker-compose ps
安装完成后如果想使用可视化面板来查看数据,可在docker-compose.yml文件中添加Attu的容器,重新启动docker-compose即可。
具体可参考github:https://github.com/zilliztech/attu/releases
六、Milvus的使用
6.1 创建Milvus客户端
在Python中创建Milvus客户端:
from pymilvus import MilvusClient
client = MilvusClient("http://192.168.0.123:8000")
6.2 创建集合
在Milvus中创建一个集合(Collection)来存储向量及其元数据:
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768, # 向量的维度
)
6.3 创建索引
可通过FieldSchema来创建集合的相关属性,并添加索引:
# 定义表结构字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True, description="id"),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=512, is_primary=False, description="内容"),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024, description="向量值"),
]
schema = CollectionSchema(fields)
# 如果collection不存在则创建一个新collection
if client.has_collection(vector_db.collection_name):
client.drop_collection(vector_db.collection_name)
client.create_collection(
vector_db.collection_name,
schema=schema,
dimension=768
)
# 初始化索引参数
index_params = client.prepare_index_params()
index_params.add_index(
field_name="embedding",
index_type="HNSW",
metric_type="COSINE",
index_name="vector_index",
M=16,
efConstruction=32
)
client.create_index(vector_db.collection_name, index_params=index_params)
6.4 插入数据
将数据插入到集合中:
data = [
{"id": i, "embedding": [random.random() for _ in range(768)], "text": "sample text"}
for i in range(10)
]
res = client.insert(collection_name="demo_collection", data=data)
client.load_collection("demo_collection")
插入完数据后需要调用load_collection()才能在页面加载出来数据。
6.5 向量搜索
在Milvus上进行向量相似性搜索:
query_vector = [random.random() for _ in range(768)]
res = client.search(
collection_name="demo_collection",
data=[query_vector], # 查询向量
limit=2, # 返回结果的数量
output_fields=["text"], # 返回列数据
)
七、总结
Milvus作为一个强大的向量数据库,为处理非结构化数据提供了高效的解决方案。通过本文的介绍,大家可以了解Milvus的基本概念、功能和使用方法,为进一步深入学习和应用打下基础。
随着AI技术的不断发展,Milvus将在智能问答系统、信息检索系统和自然语言生成等领域发挥越来越重要的作用。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)