重磅更新!sciclhls包发布clhls数据虚弱指数提取功能,效率提升看得见
CLHLS是中国老年健康影响因素跟踪调查数据,由北京大学主持,覆盖1998-2018年全国23个省市,包含11.3万人次调查数据,重点关注高龄老人健康。数据可用于计算虚弱指数(由40个变量组成),支持纵向分析和轨迹分析。通过R语言的clhls.frailtyindex函数可快速提取虚弱指数,并支持多年度数据分析和全变量导出。该数据与CHARLS数据库有相通性,适合双库交叉验证研究。研究团队还开发了
什么是clhls数据?
Clhls是北京大学“中国老年健康影响因素跟踪调查(简称‘中国老年健康调查’;英文名称为Chinese Longitudinal Healthy Longevity Survey (CLHLS))”及交叉学科研究由国家自然科学基金委主任基金应急项目、重大项目、重点项目及国际合作项目。1998-2018年在全国23个省/市/自治区随机抽取大约一半县市进行八次跟踪调查,累计入户访问11.3万人次,其中最需照料的80岁及以上高龄老人占总样本67.4%,其余为较低龄老人和中年对照组;包括:2.01万人次百岁老人,2.68万人次90-99岁老人,2.93万人次80-89岁老人,2.01万人次65-79岁老人,1.12万人次35-64岁中年人;同时访问2.89万位65+岁已死亡被访老人的直接家庭成员,收集了老人死亡前健康状况、生活质量与医疗和照料需求成本等详细数据。

虚弱指数是个连续指标,由40个变量组成,在clhls数据上大约能提取37-39个,一个有8波,大概变量约400个,一个个得校对提取,鬼知道我写了多久,反正是写得想吐了。虚弱指数有啥用,可以用来做纵向分析和轨迹分析
懂的都懂

目前使用函数Charls和clhls的虚弱指数都可以秒提取,Charls和clhls这两个数据都是北京大学弄的,数据有一定相通性,可以对两个数据相同得指标来做双库分析,就是一个建模,一个验证。OK,废话不多说,下面我来简单演示一下,以1998年得数据为例子
library(haven)
library(foreign)
library(tidyverse)
library(sciclhls)
setwd("E:/公众号文章2025年/中国老年健康影响因素跟踪调查(CLHLS)-追踪数据(1998-2018")
data <- read.spss("clhls_1998_2018_longitudinal_dataset_released_version1.sav",
use.value.labels=F, to.data.frame=T)
使用clhls.frailtyindex函数提取clhls数据得虚弱指数,这个函数使用非常简单,前面放入数据,后面指定年份就行。支持1998年到2018年8个波的所有年份。
clhls.frailtyindex(data=data,year = "data1998")
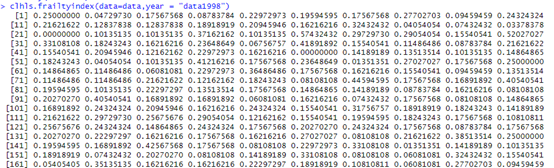
这样数据就提取出来了,非常简单,如果有些人需要全部变量数据做热图或者什么交叉滞后分析的,可以选择
out<-clhls.frailtyindex(data=data,year = "data1998",alldata = T)
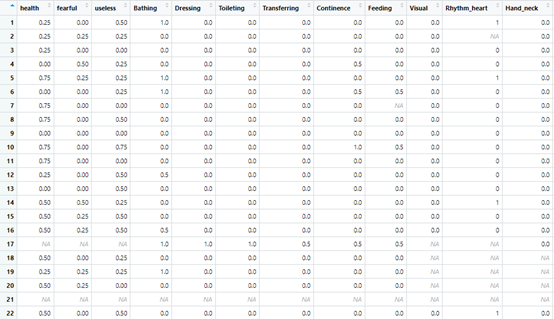
这样每个指标得情况都出来了,最后一个指标就是虚弱指数。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 7
7 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)