达摩院EMNLP'25|先学会看,再学会想:新框架突破多模态模型几何视觉瓶颈
作者|陈桂臻 阿里巴巴达摩院实习生
摘要
多模态大语言模型(MLLMs)在几何等视觉密集型推理任务中表现不佳,其核心问题在于模型的视觉感知瓶颈,制约了推理训练的效果。模型如果无法正确感知图像中的基本形状、角度和空间关系,就更无法解决复杂的几何问题。
为此,来自达摩院和新加坡南洋理工大学的研究团队提出了Geo-Perception Question-Answering (GeoPQA)基准来量化模型的视觉感知缺陷,并提出了一个两阶段强化学习框架:先通过组合式问答提升模型对几何图形的视觉感知能力,然后再进行推理训练。和直接推理训练相比,该方法将模型的几何推理能力提升了9.7%。该方法还可应用至图表理解等其他视觉密集型领域,印证了感知基础对多模态推理的关键作用。
-
论文链接:https://aclanthology.org/2025.findings-emnlp.1400/
-
代码仓库:https://github.com/DAMO-NLP-SG/GeoPQA

现存问题及挑战
-
视觉感知瓶颈限制推理能力提升
强化学习(RL)在纯文本大模型的推理训练中成效显著,但直接应用到多模态大模型中却效果有限。
我们发现MLLMs 存在明显的感知瓶颈:即使在基础几何元素的识别(如角度、长度、形状)和空间关系判断(如平行、垂直、相交)等基础视觉任务中,模型仍频繁出现幻觉,导致后续推理失败。这一瓶颈严重制约了RL奖励信号的有效传递,使得推理训练难以发挥应有作用。
-
现有评估体系忽视基础感知能力
当前多数研究侧重于高层次推理能力的评估,而忽视了对模型底层视觉感知能力的衡量。尽管已有部分工作尝试评估几何感知,但其覆盖的视觉场景与问题类型有限,难以全面反映模型在多样化几何结构理解上的缺陷。

GeoPQA基准解读
为了精准量化并提升MLLMs在几何领域的视觉感知能力,我们构建了GeoPQA基准。该基准的核心目标是将视觉感知能力从推理过程中剥离出来,进行独立的评估以及训练。
为了确保图像的多样性和覆盖度,GeoPQA的图像来源包含两部分:
-
真实图像:来自几何数据集Geo170K。
-
合成图像:通过程序化方法生成基础的几何形状(如线段、三角形、圆形)和复合形状,并添加了人类易于理解的几何标注(如直角符号、等边标记)。
我们用Gemini-2.0-Flash-Thinking模型,基于图像描述自动生成感知问题。问题必须仅通过观察图像就能直接回答,无需任何逻辑推理步骤。答案格式限制为“是/否”、数值或简单字符串(如“AB”),以支持自动化评估。问题范围覆盖两大类几何信息:
-
基本几何元素:识别形状、比较长度、识别角度类型等。
-
空间关系:判断几何对象间的相交、平行、垂直、相切等关系。
为确保问题的有效性,我们进行以下质量控制:
-
模型自动过滤:我们使用GPT-4o对生成的问题进行审核,剔除那些图像信息无法支持或答案与描述矛盾的低质量样本。
-
人工抽检:对过滤后的数据进行人工抽样验证,结果显示92%的样本是有效且高质量的。

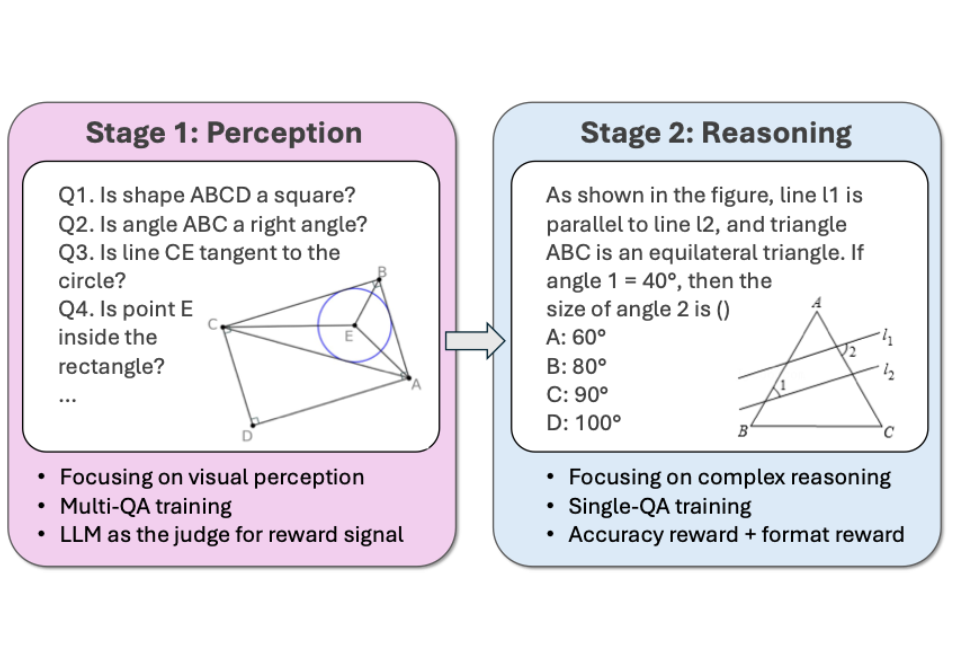
感知-推理两阶段强化学习框架
-
第一阶段:感知训练
该阶段专注于提升模型对几何图形的精准感知和理解能力。通过在GeoPQA训练集上进行训练,模型将学会识别基本的几何元素(如形状、角度、长度)和它们之间的关系(如平行、垂直、相交),为后续的复杂推理打下视觉基础。
我们将多个感知问题(例如最多7个)与对应的一个图像组合成一个训练样本。模型需要一次性生成所有问题的答案,并且仅在全部答对时才能获得奖励,这使模型必须全面、细致地观察图像中的每一个细节,而不是依赖统计偏向来猜测单个问题。
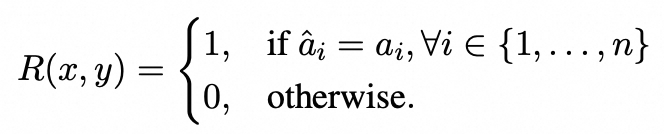
-
第二阶段:推理训练
在模型具备必要的视觉感知能力后,我们再训练其逻辑推理和解题。我们使用Geo170K的问答集作为训练数据,采用标准的分组相对策略优化(GRPO) 方法进行强化学习训练。
由于第一阶段已经减少了感知错误的问题,模型在此阶段获得的奖励信号能够更准确、更直接地反映其推理逻辑的正确性,而不会被底层的感知噪音所干扰,这使得RL训练能够高效地提升模型的几何推理能力。

演示结果
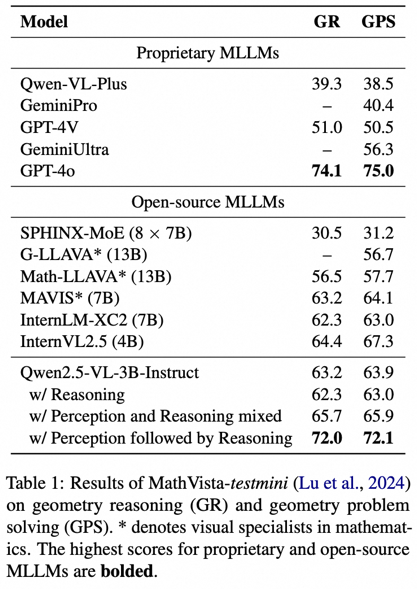
与直接进行推理训练相比,采用先感知后推理的两阶段训练框架,在MathVista几何推理任务上准确率提升了9.7%,在几何解题任务上提升了 9.1%。直接进行推理训练的效果甚至略低于原始基线模型。这证实了如果不对底层的视觉感知瓶颈进行提升,直接进行推理训练是低效的。
实验结果也进一步揭示了我们感知数据的关键作用:无论是将感知与推理数据混合训练,还是采用顺序的两阶段策略,其性能均显著优于纯粹的推理训练。这证明,引入感知数据本身是提升推理性能的关键。然而,先感知后推理的序列化方法,所带来的性能增益要明显高于简单的数据混合,凸显了专门的感知训练阶段的重要性。
另外,我们仅使用3B参数的模型,就超过了多个参数量更大的开源专家模型(如13B的G-LLaVA和7B的MAVIS),其性能与GPT-4o的差距也缩小至约2%。在7B模型上也同样有效。


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 0
0 0
0- 0



 已为社区贡献124条内容
已为社区贡献124条内容

所有评论(0)