DepthVLA:利用深度-觉察空间推理增强视觉-语言-动作模型
25年10月来自清华和星海图的论文“DepthVLA: Enhancing Vision-Language-Action Models with Depth-Aware Spatial Reasoning”。
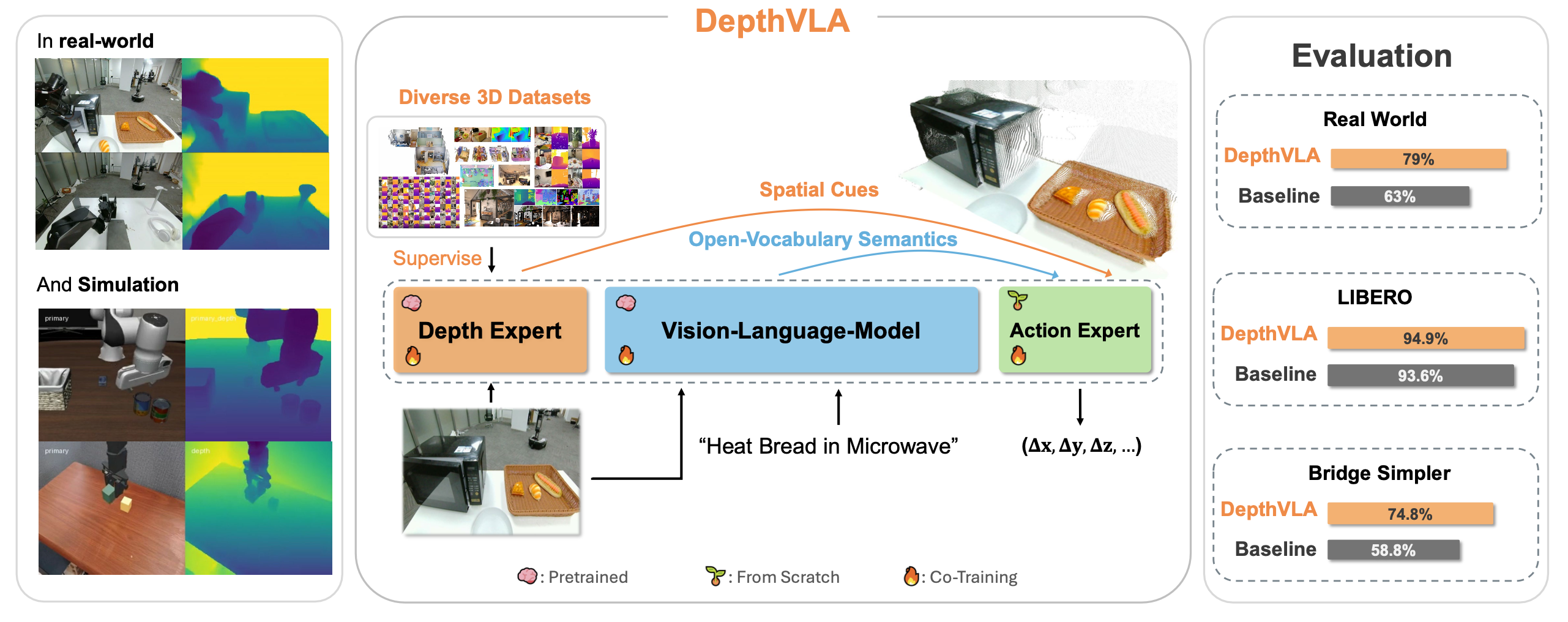
视觉-语言-动作(VLA)模型近年来展现出令人瞩目的泛化能力和语言引导操作能力。然而,由于视觉-语言模型(VLM)固有的空间推理能力有限,VLA在需要精确空间推理的任务上性能下降。现有的VLA依赖于大量的动作数据预训练来将VLM映射到三维空间,这降低了训练效率,并且仍然不足以实现精确的空间理解。本文提出一种名为DepthVLA的简单而有效的VLA架构,它通过预训练的深度预测模块显式地融入空间觉察能力。DepthVLA采用混合Transformer设计,将VLM、深度Transformer和动作专家模型整合在一起,并采用完全共享的注意机制,从而形成一个具有增强空间推理能力的端到端模型。在真实环境和模拟环境中进行的大量评估表明,DepthVLA 的性能优于现有最佳方法,
如图所示,DepthVLA 是一种简单而有效的 VLA 架构,它通过预训练的深度预测专家显式地融入空间觉察。该模块在多种 3D 数据集 [21]–[24] 上进行训练,能够提供强大的几何理解能力。受 π0 [3] 的启发,DepthVLA 采用混合transformer (MoT) [25] 设计,通过完全共享的注意机制将深度专家与 VLM 和流匹配动作专家集成,从而形成端到端的 VLA 模型。直观地说,VLM 提供语言理解和开放词汇语义感知,深度专家提供细粒度的几何线索,而动作专家则根据来自两种模态的表征生成动作。MoT 设计还支持对每个组件进行单独预训练,从而可以在除具身动作数据集之外的更多样化的数据集上进行训练。尽管增加了深度专家,但 DepthVLA 只会略微增加推理延迟,使其适用于实时部署。
问题描述与模型概述
遵循标准的端到端 VLA 设置,其中策略 π_θ 根据当前观测值 o_t(来自一个或多个摄像头)、语言指令 l 和本体感觉状态 s_t 预测长度为 k 的动作块 A_t = a_t:t+k:A_t = π_θ (o_t, l, s_t)。
DepthVLA 采用混合transformer(MoT)架构,集成三个专家:视觉语言模型(VLM)、深度模块和流匹配动作专家,如图所示。该设计扩展 π0 [3](使用双专家 MoT,即 VLM + 动作专家),通过添加一个独立的深度专家来提供显式的空间信息。
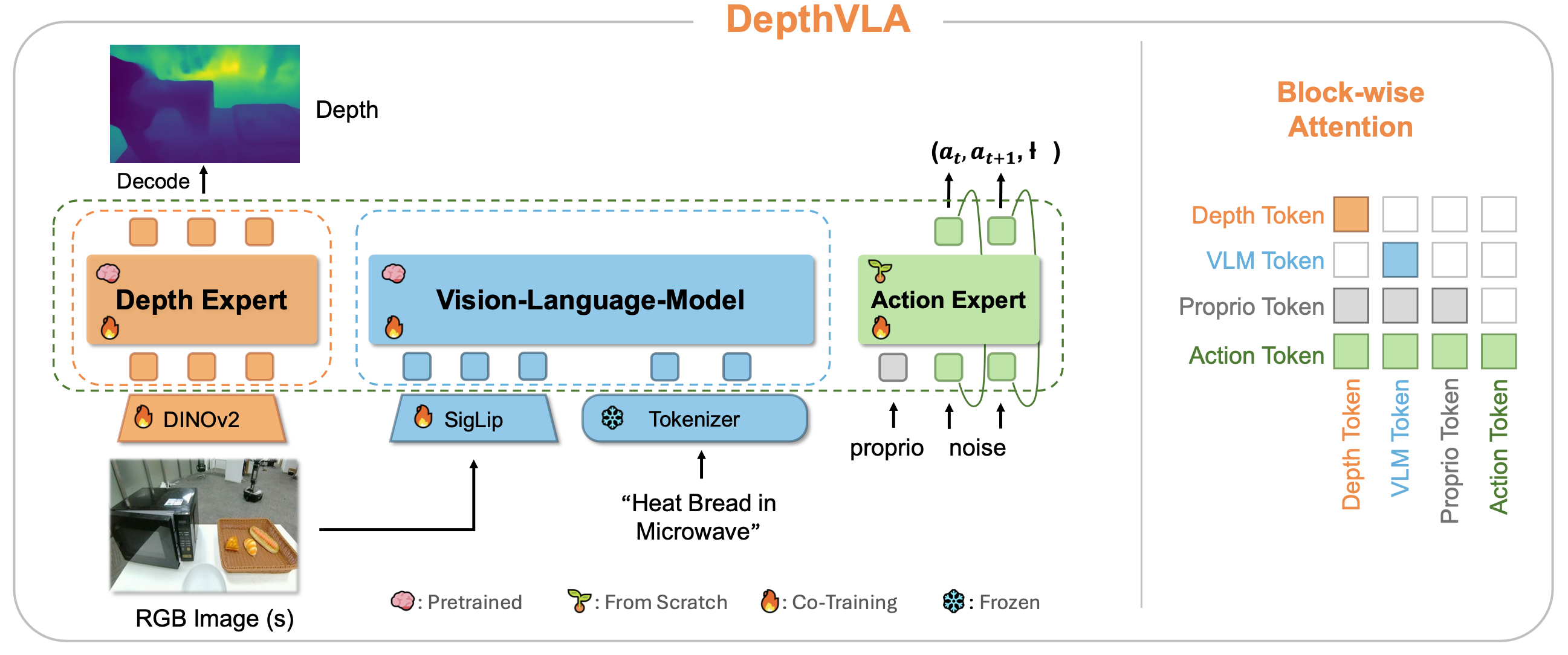
具体而言,VLM 专家对 o_t 和 l 进行编码以捕获语义和语言特征,而深度专家处理 o_t 以推断几何信息。然后,动作专家基于语义专家和几何专家提供的组合特征生成连续动作。这三位专家共享相同的注意层,但各自拥有不同的权重和特征维度。
为了保留 VLM 和深度模块的预训练能力,应用分块掩码:VLM 和深度专家的 tokens 只关注自身,而动作 tokens 可以关注所有流,如图右侧所示。这种设计使得 DepthVLA 能够利用预训练知识,同时融合语义和空间线索,从而实现精确的动作生成。
深度专家
深度专家作为专门的空间推理器,提供几何线索来指导动作专家。为了与 VLA 无缝集成,它采用了与 VLM 相同的 Transformer 主干网络,但权重和维度各不相同。
将深度专家设计为编码器-解码器架构。编码器基于 DINOv2 [43],能够捕捉细粒度的几何特征。从 Depth Anything V2 [19] 的预训练检查点进行初始化,以继承来自大规模 3D 基础模型的强大空间先验。解码器镜像了 VLM 的 Transformer 结构,并通过线性头输出深度预测结果。与仅提供最终深度图的方法 [15]、[17] 不同,深度专家能够在所有中间层执行空间推理,从而为动作预测提供更丰富的几何线索。动作专家关注这些中间特征,利用丰富的几何表示,而不是低维的深度输出。这提高了精细的空间理解能力,对于精确抓取和避障等任务至关重要。
在集成到 VLA 之前,用单目深度预测任务在各种 3D 数据集上对深度专家进行预训练,以获得鲁棒的空间推理能力。其采用尺度不变的对数损失 [44]L_si(dˆ, d),其中d 是真实深度度量,dˆ 是预测的深度图,λ 控制尺度项的平衡(默认设置为 0.5)。这种简单的损失足以学习鲁棒的空间推理和距离估计。
DepthVLA 策略训练
用具身动作数据训练 DepthVLA,并以模仿学习为目标,最大化动作的对数似然。为了更好地建模连续且多样化的动作轨迹,采用流匹配损失L_flow(θ)。其中 Aτ_t 是插值噪声动作 Aτ_t = τA_t + (1 − τ)ε,其中 τ ∈ [0,1]。v_θ (·) 是模型预测的流,u(·) 是从动作轨迹导出的目标流。
为了保持深度专家的空间推理能力,在 VLA 训练过程中保留深度预测损失。因此,最终损失为:L = L_si + L_flow。这种方法使得 DepthVLA 能够以端到端的方式联合优化空间推理和动作生成。
实现细节
模型架构。所有模型均使用 PyTorch 实现。采用 Paligemma-3B [29] 作为 VLM 主干网络,这是因为其具有较强的泛化能力,并沿用之前 VLA 相关工作 [3]、[9]、[26] 的做法。深度专家采用 DINOv2-L 作为编码器,其初始化基于 Depth Anything V2 [19] 数据集。解码器的大小与动作专家相匹配,两个模块均包含约 3 亿个参数。作为最接近的基线模型,严格按照 JAX 官方实现重新实现 π0。重实现的 π0 与 DepthVLA 的唯一区别在于添加深度专家,从而可以公平地比较显式空间推理的影响。
训练细节。深度专家在大规模 3D 数据集上进行预训练,包括 WildRGB-D [22]、Scannet [23]、Scannet++ [24] 和 HyperSim [21]。预训练运行 5 万步,采用余弦学习率调度,批大小为 1024,初始学习率为 5 × 10⁻⁵。对于 VLA 训练,对大规模数据集(例如 Galaxea Open-World [26]、BridgeData V2 [31])使用 1024 的批大小,对小规模数据集(例如 LIBERO [27]、真实世界基准任务)使用 64 的批大小。所有模型均不使用任何历史信息进行动作生成。所有模型均在 32 个 NVIDIA H100 GPU 上进行训练,使用 AdamW 优化器 [46],学习率为 2.5 × 10⁻⁵,权重衰减为 10⁻⁴。
推理细节。与基线 π0 相比,DepthVLA 引入 6 亿个额外参数(3 亿个来自 DINOv2 编码器,3 亿个来自深度专家解码器)。在配备 BF16 混合精度的 NVIDIA 4090 GPU 上运行推理。DepthVLA 需要 8.0 GB 的显存(π0 为 6.7 GB),每步推理延迟为 210 毫秒(π0 为 190 毫秒)。由于动作预测是以 1 秒为单位的(在 15 Hz 的平台上为 16 步),因此额外的延迟在实践中可以忽略不计。
仿真基准测试
BridgeV2 和 Simpler。BridgeData V2 [31] 是一个大规模的真实世界机器人操作数据集,包含使用 WidowX 机器人在 24 个环境中收集的超过 6 万条轨迹。它提供多样化的任务和环境变化,使其成为训练通用策略的坚实基础。为了获得深度监督,用 Depth Anything V2 [19] 和 UniDepth V2 [33] 生成伪标签。
Simpler WidowX [28] 是一个仿真环境,旨在高度模拟 BridgeData V2,为策略评估提供一个可复现的平台。它包含四个任务套件,在环境、物体配置和相机姿态方面均有差异,有效地弥合真实环境和仿真环境之间的差距。在 BridgeData V2 上训练 DepthVLA 2 万步(约 12 个 epoch),并在 Simpler WidowX 上进行零样本评估。报告每个任务套件的最终成功率,该成功率在不同的随机种子下进行 120 次试验后得出。
LIBERO。LIBERO [27] 是一个基于 Franka Panda 机械臂的模拟操作基准测试,其演示包括前视和腕视摄像头图像以及自然语言指令。它包含四个任务套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long,每个套件包含 10 个任务的 500 个演示。与以往工作 [1]、[3]、[15]、[17] 通常为每个套件训练一个模型不同,用单个 DepthVLA 模型在所有四个套件上联合训练 3 万步(约 8 个 epoch)。这创建一个更具挑战性的环境,要求模型在不同任务类型中具有更强的泛化能力。报告每个任务套件的成功率,总共进行 2000 次试验,涵盖 40 个任务,并使用了不同的随机种子。
真实世界基准测试
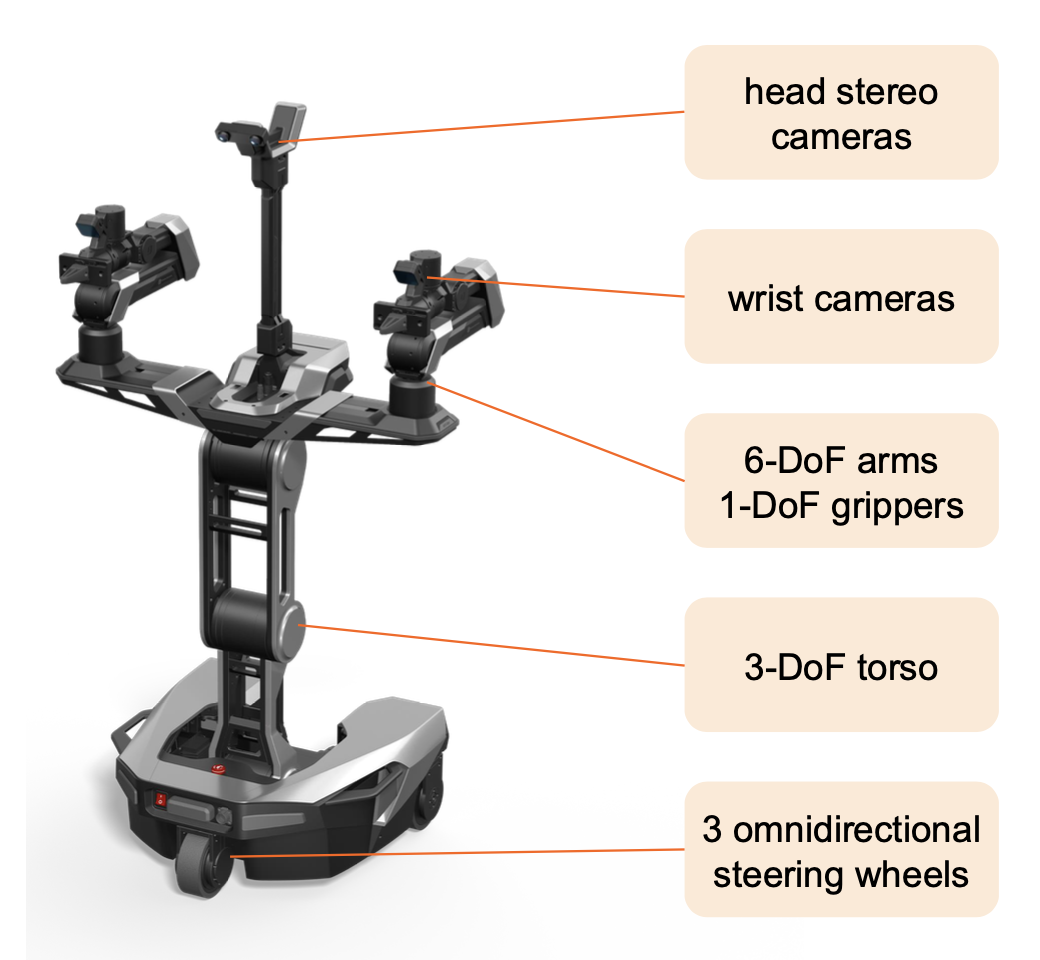
在商用双臂移动平台 Galaxea R1 Lite 上评估 DepthVLA。该系统由两个 6 自由度机械臂、两个腕戴式摄像头和一个头部摄像头组成,如图所示。为了评估大规模动作预训练对 DepthVLA 的益处,用 Galaxea 开放世界数据集 [26] 对 DepthVLA 进行预训练。该数据集包含 150 个任务类别和 50 个真实世界场景的 10 万条轨迹。深度标签使用 VGGT [20] 和 UniDepth V2 [33] 生成。DepthVLA 和重实现的 π0 均进行 8 万步(约 4 个 epoch)的预训练。
为了评估空间感知、精细抓取和避障能力,设计三个基准任务:桌面整理:机器人整理杂乱的桌面,将笔放入笔筒、挂起耳机并将书本放到支架上。此任务衡量小物体抓取和精确位置估计的能力。
微波炉操作:机器人打开微波炉门,将食物放在盘子上,将盘子放入微波炉,然后关上门。此任务测试每一步的避障能力。积木堆叠:机器人垂直堆叠积木,测试精确的抓取和放置能力。
对于每个基准任务,收集 100 条轨迹,并对预训练模型进行 4000 步的微调。性能评估采用进度分数,任务中每个成功的子步骤计 1 分,每个任务的分数取 20 次运行的平均值。此外,还进行仅包含 20 条微调轨迹的少样本实验,以评估 DepthVLA 的少样本迁移能力。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 31
31 0
0- 0



 已为社区贡献355条内容
已为社区贡献355条内容

所有评论(0)