具身领域的Scaling Law (GEN-0 / Embodied Foundation Models That Scale with Physical Interaction)
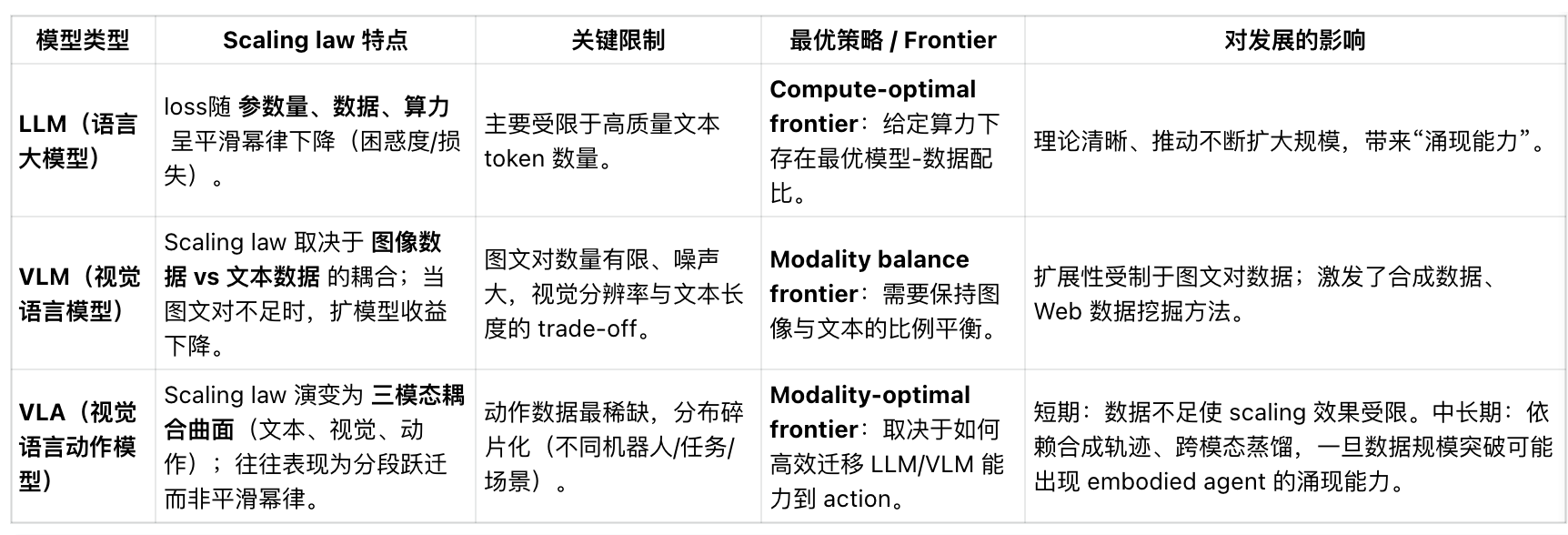
本文探讨了不同AI领域的缩放定律(Scaling Laws),揭示了模型性能与计算资源、规模及数据量之间的量化关系。在LLM领域,幂律关系确立了"规模即能力"的认知;VLM研究则发现早期融合架构在低计算预算下更优,MoE模型性能显著提升;RFM领域验证了机器人任务中缩放定律的有效性,同时指出数据多样性的重要性;LBM研究显示其在多任务场景下的数据效率优势。实践案例(如小鹏、GO
参考:GNE-0
Scaling Laws(缩放定律)核心是描述 AI 模型性能与计算资源、模型规模、训练数据量等关键变量之间的量化关系,多数遵循幂律函数,不同领域因任务特性和技术范式差异,在具体规律、适用范围及实践启示上存在显著区别。
一、LLM(大型语言模型)的 Scaling Laws
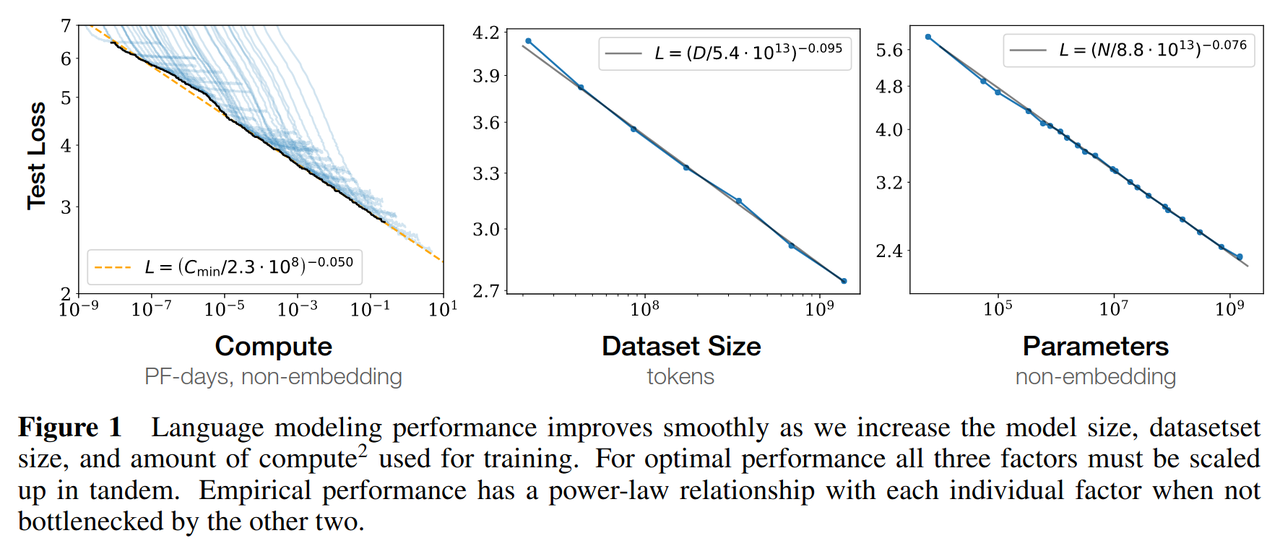
LLM 的缩放定律是该领域早期探索的核心规律之一,奠定了大模型 “规模即能力” 的基础认知。
- 核心研究:以 Kaplan, Jared 等人 2020 年发表的《Scaling laws for neural language models》(arXiv:2001.08361)为标志性成果,首次系统量化了 LLM 性能与关键资源的关系。贾里德•卡普兰(Jared Kaplan)目前是Anthropic首席科学家,同时也是前OpenAI员工。
- 核心规律:遵循幂律关系,模型性能(如语言生成质量、任务准确率)随计算资源增加、模型参数规模扩大、训练数据量增多而持续提升,且在一定范围内(如参数从百亿到万亿级),性能提升具有可预测性。
- 关键价值:为后续 GPT、PaLM 等超大规模 LLM 的研发提供了理论指导,明确了 “增大规模” 是提升 LLM 能力的有效路径。
二、VLM(视觉语言模型)的 Scaling Laws
VLM 融合视觉与语言模态,其缩放定律需兼顾跨模态数据与模型结构的特殊性,目前研究聚焦于多模态协同缩放的规律。
- 核心参考:相关研究(如 Shukor M 等人 2025 年论文《Scaling laws for native multimodal models》,arXiv:2504.07951)围绕 “视觉 - 语言协同缩放” 展开。Mustafa Shukor是苹果公司的技术人员,同时也是Smolvla的作者。
- 核心公式:
论文的核心公式是用于描述原生多模态模型(NMMs)性能与模型参数 N N N 训练token数量 D D D之间幂律关系的损失函数公式,该公式是推导NMMs缩放定律的基础,贯穿全文对早期融合、晚期融合及稀疏MoEs模型的性能分析,具体形式如下:
L = E + A N α + B D β L=E+\frac{A}{N^{\alpha}}+\frac{B}{D^{\beta}} L=E+NαA+DβB
其中, L L L 表示模型的验证损失(平均覆盖interleaved图像-文本、图像caption、纯文本数据的交叉熵损失),是衡量模型性能的核心指标; E E E代表数据集上理论可达到的最低损失(下限值); N N N为模型参数数量(对MoEs模型特指活跃参数), α \alpha α是参数缩放指数,反映参数增加对降低损失的贡献程度 α \alpha α 越大,参数提升性能的效率越高); D D D 为训练token的总数量, β \beta β是token缩放指数,体现训练数据量增加对性能优化的影响 β \beta β越大,更多token带来的损失下降越显著); A A A和 B B B为常数项,由模型架构与数据集特性决定。 - 核心发现:
- 该论文通过对457个不同架构原生多模态模型(NMMs)的缩放定律研究发现,早期融合与晚期融合架构在相同计算预算下性能相当,但早期融合模型在低计算预算时表现更优、训练效率更高(内存占用少、训练速度快)且所需参数更少,不存在晚期融合架构的固有优势。
- 原生多模态模型遵循与纯文本LLM相似的缩放定律,参数(N)与训练token(D)需大致等比例缩放(平均α≈0.301、β≈0.335,L∝C^-0.049),且不同训练数据混合(图像-文本、interleaved数据、纯文本)虽会导致缩放系数略有差异,但整体趋势一致。
- 引入混合专家模型(MoEs)的稀疏早期融合NMMs在相同推理成本下性能显著优于密集模型,专家在早期和最后层表现出更强的模态特异性,中期层更倾向跨模态共享,且模态无关路由策略优于模态感知路由。
三、RFM(机器人基础模型)的 Scaling Laws
RFM 面向具身智能(机器人操作、环境交互),其缩放定律需结合物理世界任务特性,规律更复杂且与 “失败率” 直接挂钩,是目前具身 AI 领域的研究重点。
- 核心定义与幂律模型
RFM 的缩放定律描述模型性能(以 “成功率 SR” 衡量,失败率 FR=100-SR)与计算资源、模型规模、训练数据量的量化关系,核心遵循幂律函数:
Y = X β + γ Y = X^\beta + \gamma Y=Xβ+γ
- 变量含义:
- X:表示计算资源(如训练算力)、模型规模(如参数数量)、训练数据量(如演示样本数);
- Y:表示模型失败率(FR,百分比);
- 关键系数β:决定缩放行为,研究中 90% 的场景满足−1<β<0(β为负表示X增大时Y减小,即失败率降低、性能提升)。
- 具体缩放规律
![[图片]](https://i-blog.csdnimg.cn/direct/a8a3d69e795142f085c517acff16781e.png)
- 关键研究与延伸发现
- Sartor S 等人 2024 年研究(《Neural Scaling Laws in Robotics》,arXiv:2405.14005):
- 首次通过 198 篇论文的元分析证实:缩放定律同时适用于 RFM 和 “用于机器人任务的 LLM”,且二者幂律系数接近,优于纯 LLM 的缩放效率;
- 任务复杂度影响缩放效率:熟悉任务(如重复抓取已知物体)的β绝对值更大(缩放效率更高),陌生任务(如复杂环境组装)的β绝对值更小;
- 指出局限:具身 AI 缺乏标准化基准,且规模增大到一定程度后会出现 “边际收益递减”,但同时会涌现新能力(如跨任务迁移)。
- Lin F 等人 2024 年研究(《Data scaling laws in imitation learning for robotic manipulation》,arXiv:2410.18647):聚焦 “机器人操作任务的模仿学习”,补充数据缩放的细节规律:
- 数据多样性>演示数量:增加环境多样性(如不同光照、背景)和物体多样性(如不同形状、材质),比单纯增加单环境 / 单物体的演示数量更有效;一旦单环境 / 单物体的演示数达 50 次(阈值),额外演示对性能提升微乎其微;
- 高效数据收集策略:4 个数据收集者仅需 1 个下午,为 2 个任务收集 “多环境 + 单物体 + 50 次演示 / 环境 - 物体对” 的数据,即可让策略在新环境中达 90% 成功率;
- 模型组件影响:视觉编码器(如 DINOv2 预训练的 ViT-Large)的预训练 + 全参数微调对性能增益显著,而扩散模型参数规模增大无明显性能提升(当前架构已满足任务需求)。
- Belkhale S K 2025 年博士论文(《Towards Generalist Robots: Action Reasoning and Scaling Data》):强调 “数据多样性对通用机器人效能的关键作用”,例如 RFM 处理熟悉数据时β=−0.37(效率高),处理陌生数据时β=−0.23(效率低),进一步验证数据多样化的必要性。
四、LBM(大型行为模型)的 Scaling Laws 相关发现
LBM 面向机器人多任务灵巧操作,其研究重点是 “数据效率” 与 “泛化能力” 的缩放关系,核心补充了 RFM 在多任务场景的规律。 - 核心研究:Barreiros J 等人 2025 年论文《A careful examination of large behavior models for multitask dexterous manipulation》(arXiv:2507.05331)。
- 关键结论:
- 数据效率优势场景:LBM 在 “未见复杂任务” 和 “分布偏移场景” 中数据效率显著优于单任务模型:
- 未见模拟任务:仅需单任务模型 30% 的数据微调,即可达单任务模型全量数据的性能;
- 真实世界任务(如 “设置早餐托盘”):仅用 15% 任务特定数据微调,性能超越单任务模型全量数据训练结果。
- 未微调 LBM 的局限:未微调的 LBM 无法持续优于单任务模型,原因是 “语言编码器规模小(语言 - 视觉 - 动作对齐精度低)” 和 “预训练数据归一化错误”,启示未来需强化跨模态对齐和数据预处理。
- 实验设计保障:通过 “盲测试 + 随机化”“大样本量(真实世界 50 次 / 任务、模拟 200 次 / 任务)”“贝叶斯分析 + 显著性检验”“控制变量(固定架构仅变数据 / 预训练量)” 确保结果可靠性。
五、具身领域 Scaling Laws 的实践案例
-
小鹏的参数规模验证:在具身智能实践中,相同数据在 10 亿、30 亿、70 亿、720 亿参数模型上,均呈现 “参数越大,模型能力越强” 的明显缩放效果,验证了 RFM 缩放定律在工程实践中的有效性。
![[图片]](https://i-blog.csdnimg.cn/direct/26f995ad8bcd45389e3346b1072aa7a6.png)
-
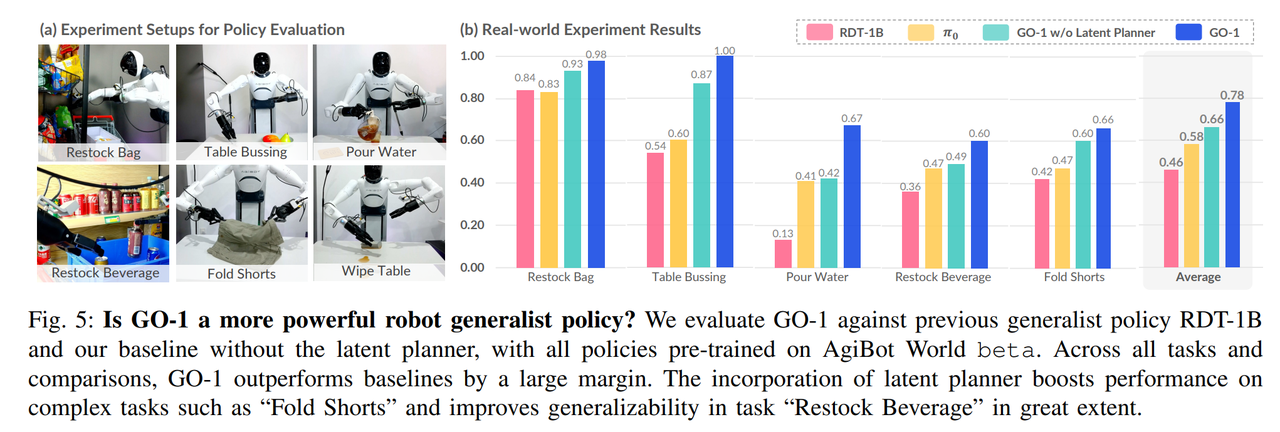
智元 2025 年开源的 GO-1(基于 ViLLA 架构的具身智能模型),为研究者提供了验证缩放定律的开源工具,推动具身领域缩放规律的落地探索。 https://opendrivelab.com/OpenGO1/
-
银河通用提出的GroceryVLA模型,GroceryVLA具备五大核心能力,包括无需路径规划的稳定作业、跨品类统一抓取策略、泛化至新环境的能力、动态判断最优抓取目标以及实时闭环策略调整能力。
baijiahao.baidu.com 【2025 外滩大会】具身智能:从泛化到行动,重塑产业未来_哔哩哔哩_bilibili 1小时25分
-
Gemini Robotics-ER 1.5 ,Google推进了Gemini Robotics,它构建了一个“智能体”系统架构,由一个“指挥官”(Gemini Robotics-ER 1.5)和一个“行动者”(Gemini Robotics 1.5)组成。

VLA模型统计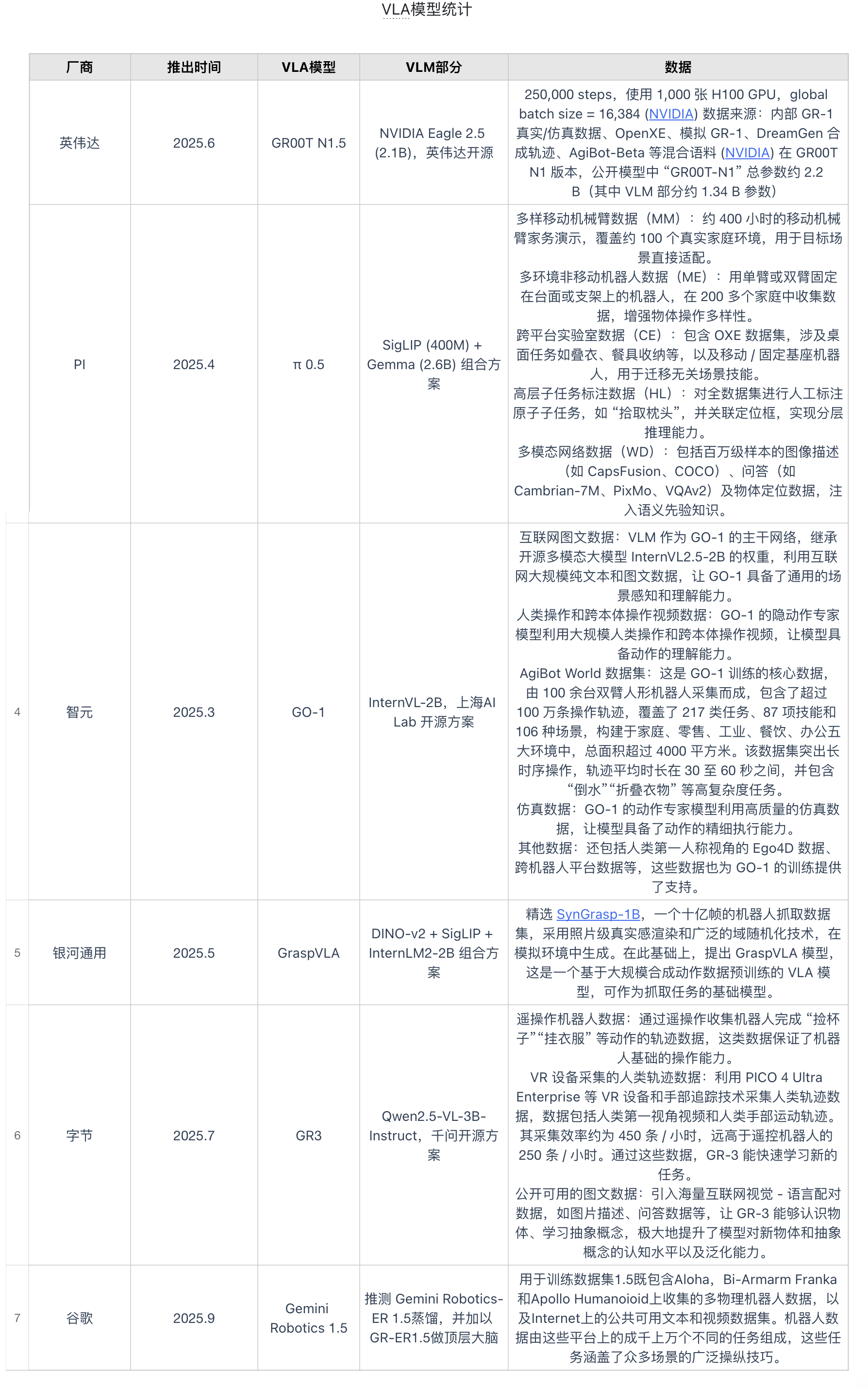
六、核心局限
- 任务复杂度限制:当前缩放定律仅在 “简单机器人任务”(如抓取、放置)中验证有效,对于 “复杂长程任务”(如多步骤组装、动态环境交互),性能与资源的关系尚无可靠结论;
- 边际收益递减:所有资源(计算、数据、模型)缩放均存在 “边际收益递减”,规模增大到一定程度后,性能提升成本急剧增加;
- 标准化缺失:具身领域缺乏统一的任务基准(如环境设置、性能指标),导致不同研究的缩放定律难以直接对比。
七、GEN-0:可随物理交互扩展的具身基础模型
Generalist AI团队于2025年11月4日发布博客,介绍了全新具身基础模型GEN-0,该模型突破传统机器人基础模型局限,以高保真原始物理交互为核心进行多模态训练,在模型性能、数据规模、架构设计等多方面实现创新,标志着具身基础模型进入“能力随真实世界物理交互数据的scaling law”的新阶段。可以说是具身领域的GPT时刻!报告没有公布更加详细的版本,还是等开源吧,才能得出更加可靠的结论。
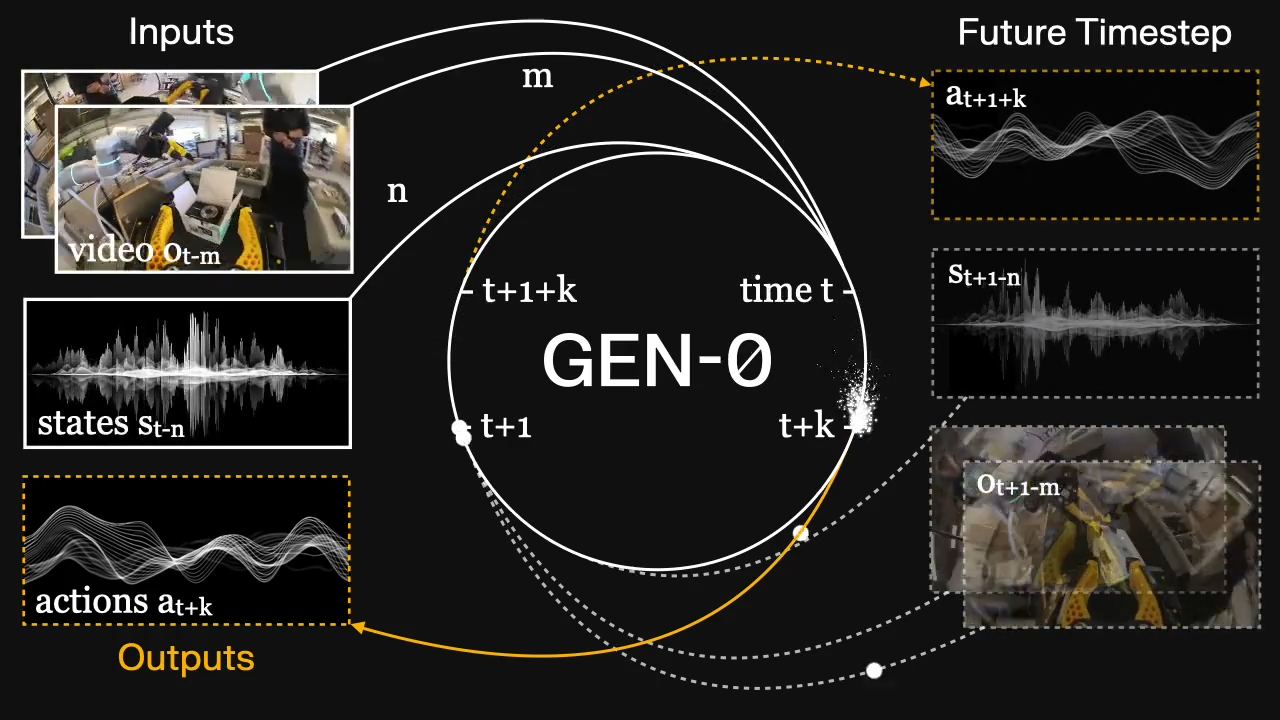
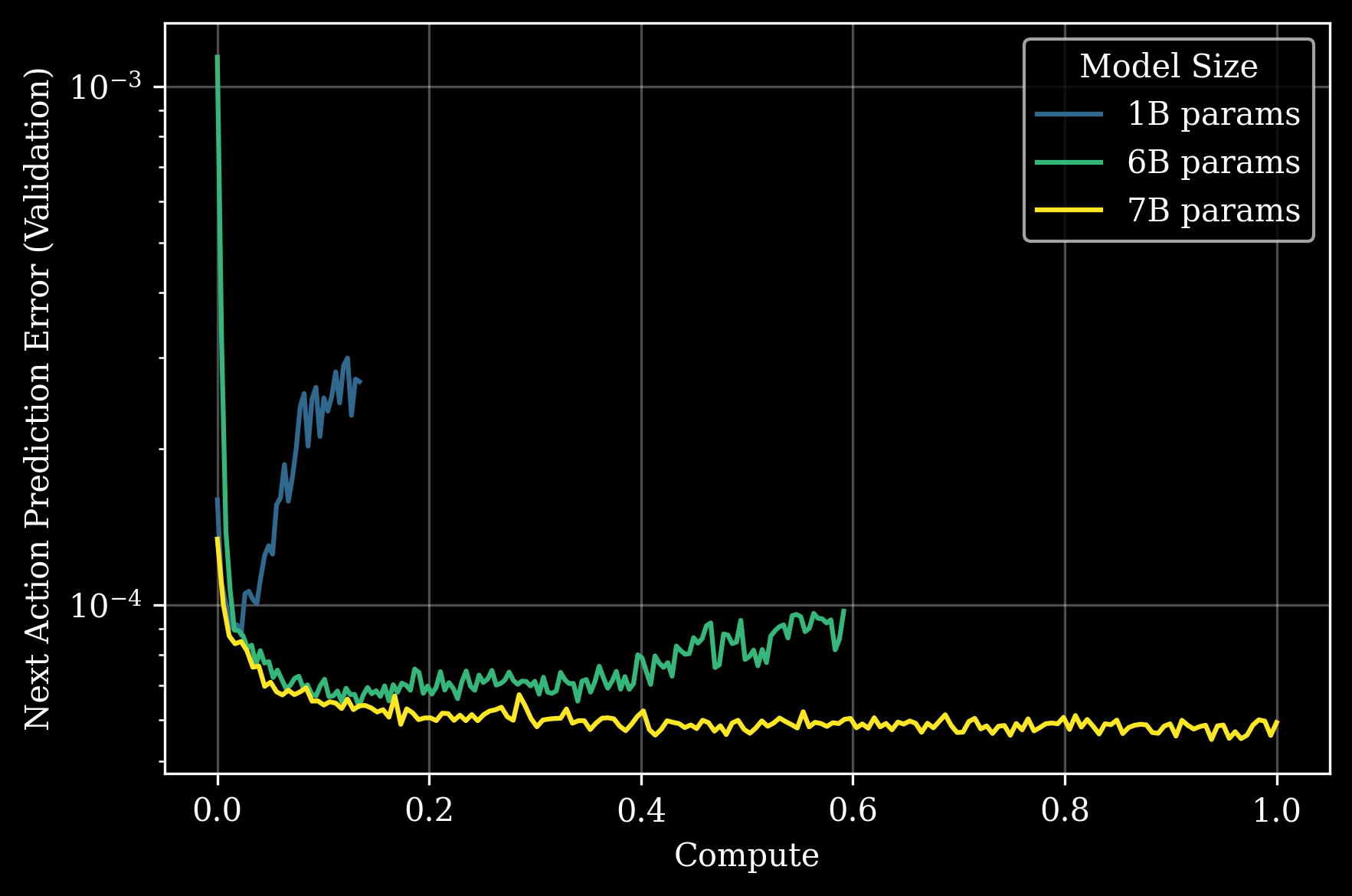
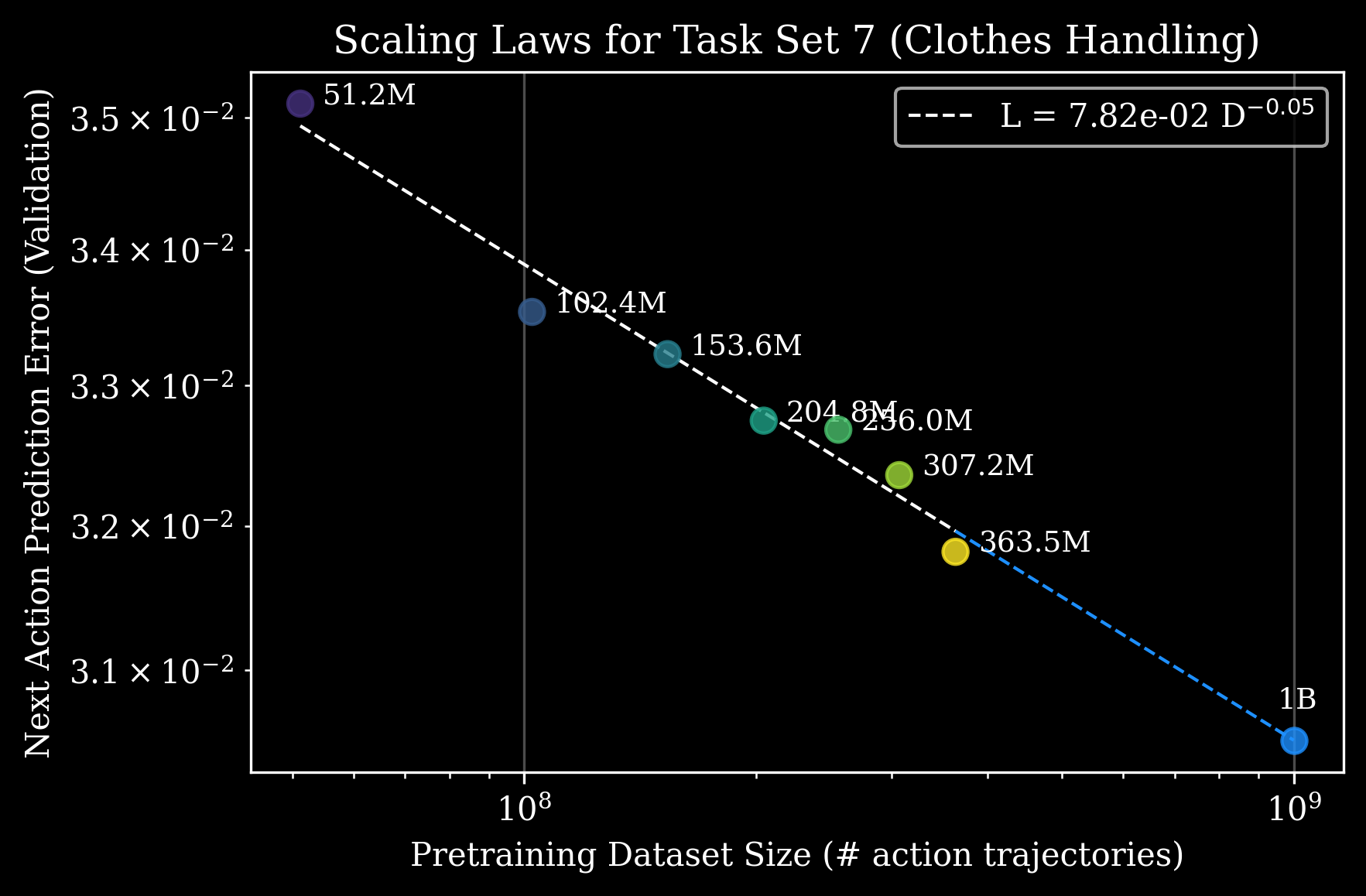
一、模型核心突破与核心特性
GEN-0的核心价值在于打破机器人领域“依赖视觉-语言预训练、缺乏物理交互维度扩展规律”的现状,其关键特性围绕“物理交互适配”与“可扩展性”展开:
1. 超越智能阈值(Surpassing the Intelligence Threshold)
- 模型规模与能力的“相变”现象:在机器人高数据训练场景中,模型能力随规模增长呈现显著分界——10亿参数以下的小模型(如1B)会出现“骨化”(ossification),即模型权重无法持续吸收复杂传感运动数据;6B模型开始显现多任务能力;7B及以上模型(已扩展至10B+)能高效内化大规模机器人预训练数据,下游任务仅需数千步训练即可快速适配。
- 行业意义:这是机器人领域首次观测到“骨化”现象,印证了莫拉维克悖论(Moravec’s Paradox)——人类看似轻松的感知与灵巧操作,需远超抽象推理的计算复杂度,物理世界智能(物理常识)的激活门槛远高于传统模型。
2. 机器人领域的扩展定律(Scaling Laws for Robotics)
GEN-0首次在机器人领域验证了“数据/计算与性能的可预测关系”,核心表现为两点:
- 预训练阶段的扩展规律:模型规模、预训练计算量与下游零样本任务性能呈稳定正相关(如图1),7B+模型在“下一个动作验证预测误差”上持续优于小模型。
- 预训练对微调的长期增益:预训练数据量与下游训练后性能呈幂律关系(如图3),且适用于服装、制造、物流、汽车、电子等多行业任务(如乐高搭建、快餐打包、衣物处理)。例如,在“衣物处理”任务中,可通过公式L(D) = (Dc/D)αD 预测:给定10亿条动作轨迹,能精准估算模型达到特定误差所需的预训练数据量,为行业任务资源分配提供依据。
3. 谐波推理(Harmonic Reasoning)
针对物理系统“实时交互无法暂停思考”的核心痛点(区别于语言模型可延迟响应),GEN-0设计了全新训练范式:通过异步、连续时间的“感知-动作令牌流”构建协同交互,无需依赖System1-System2架构或推理时引导,即可支持超大规模模型在真实物理场景中同步“思考与行动”。例如,在“组装相机套件”任务中,模型无需拆分“放清洁布、折纸盒、取相机、封箱”等子任务,通过单条谐波推理流即可完成长周期灵巧操作。
4. 跨具身性(Cross-Embodiment)与数据突破
- 多机器人适配:架构原生支持不同自由度(DoF)的机器人,已在6DoF、7DoF、16+DoF半人形机器人上验证有效性。
- 数据规模与增长能力:打破机器人领域“数据匮乏”瓶颈——预训练数据基于自研机器人数据集,包含27万小时真实世界多样化操作数据(覆盖家庭、仓库、工作场所),且以每周1万小时的速度加速增长,规模远超2025年已知的所有机器人数据集(如图4)。
二、支撑体系:数据生态与基础设施
GEN-0的性能依赖于“全链路数据能力”,从数据构建到基础设施形成闭环:
1. 操作宇宙图谱(Mapping the Universe of Manipulation)
团队正构建全球最大、最多样的真实世界操作数据集,覆盖人类可完成的所有操作任务(如削土豆、拧螺栓),场景涵盖家庭、面包店、自助洗衣店、工厂等。配套开发了内部搜索工具(如图5),通过t-SNE映射语言标签嵌入,输入文本描述即可定位数据集近邻区域,随机采样相关操作视频,实现数据高效检索。
2. 互联网级机器人数据基础设施(Infrastructure for Internet-Scale Robot Data)
为支撑超大规模数据处理,团队打造了定制化技术体系:
- 硬件与网络:部署全球硬件网络(数千台数据采集设备/机器人),铺设专用互联网线路保障多站点上行带宽,签订多云合约。
- 数据处理能力:自研数据加载器、上传机器,支持10K级核心持续多模态数据处理,压缩数十PB数据,训练效率达“每天吸收6.85年真实世界操作经验”,媲美前沿视频基础模型。
三、预训练科学(Science of Pretraining)
GEN-0通过大规模消融实验,揭示了“数据质量与多样性优于数量”的核心结论,为机器人预训练提供科学指导:
1. 数据混合的影响
不同来源、类型的预训练数据(如特定任务数据、通用操作数据)会显著改变模型特性。例如,Partner B的“Class 2 Skills”数据(技能类数据)训练出的模型,在“灵巧操作”任务上预测误差(0.00301995)和反向KL散度(0.00182561)均为最低,下游监督微调(SFT)效果最优;而部分高预测误差、低反向KL的模型,因分布多模态特性,更适配强化学习微调。
2. 性能评估维度
采用“预测误差(MSE)+反向KL散度”双指标评估:
- MSE:衡量预测动作与真实动作的偏差(MSEval = ||a⋆−â||²₂);
- 反向KL散度:通过蒙特卡洛估计(混合高斯分布)衡量模型的“模式寻求行为”,更贴合物理操作的稳定性需求。
四、引用与成果价值
GEN-0的发布标志着机器人基础模型从“依赖文本/图像/仿真数据”转向“真实物理交互驱动”,其核心价值在于:
- 为机器人领域提供首个“数据-计算-性能”可预测的扩展框架,降低行业落地的资源试错成本;
- 通过谐波推理、跨具身性等设计,解决真实物理场景的实时交互难题,推动机器人从“单一任务”向“通用操作”升级;
- 开放的数据集生态与预训练科学,为全球机器人研究提供可复用的技术范式。
若需引用该成果,可参考:
- 文本引用:Generalist AI Team, “GEN-0: Embodied Foundation Models That Scale with Physical Interaction”, Generalist AI Blog, Nov 2025.
- BibTeX引用:
@article{generalist2025gen0,
author = {Generalist AI Team},
title = {GEN-0: Embodied Foundation Models That Scale with Physical Interaction},
journal = {Generalist AI Blog},
year = {2025},
note = {https://generalistai.com/blog/preview-uqlxvb-bb.html},
}

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)