【离线数仓项目】——离线大数据系统设计
本文详细介绍了离线大数据系统的设计背景、实时系统与离线系统的对比、离线大数据系统的作用以及技术设计等内容。离线大数据系统适用于数据量大、计算复杂且对实时性要求不高的场景,可满足企业数据分析、AI/机器学习训练等需求,同时减轻实时系统压力。文章还探讨了离线大数据系统的整体架构、各层所需核心技术栈以及准实时大数据技术设计和全栈监控体系设计,为相关项目开发提供了全面的技术参考。
摘要
本文详细介绍了离线大数据系统的设计背景、实时系统与离线系统的对比、离线大数据系统的作用以及技术设计等内容。离线大数据系统适用于数据量大、计算复杂且对实时性要求不高的场景,可满足企业数据分析、AI/机器学习训练等需求,同时减轻实时系统压力。文章还探讨了离线大数据系统的整体架构、各层所需核心技术栈以及准实时大数据技术设计和全栈监控体系设计,为相关项目开发提供了全面的技术参考。
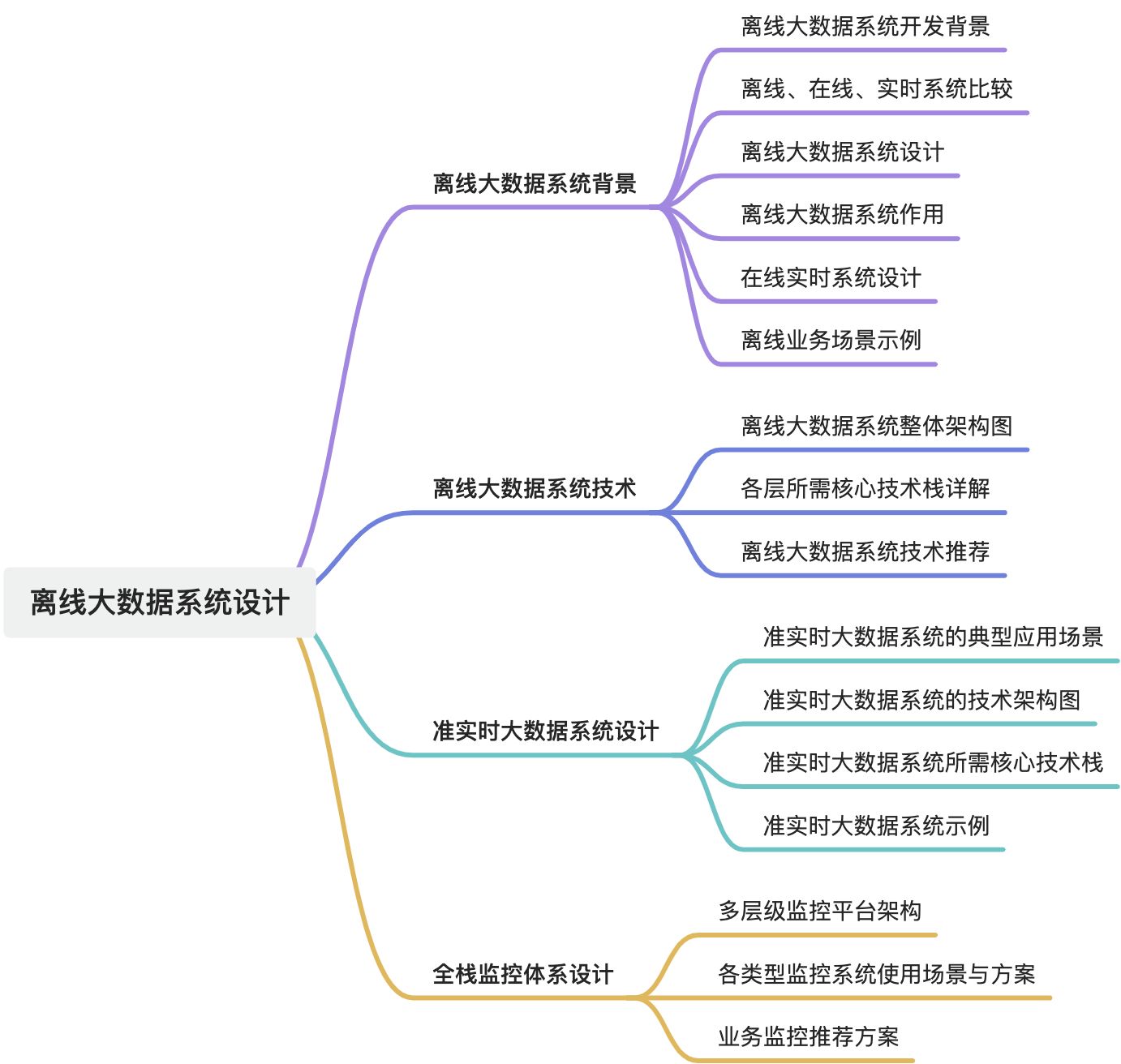
1. 离线大数据系统背景
1.1. 离线大数据系统背景
离线大数据系统的开发背景通常来自企业对大规模数据存储、处理与分析的强烈需求,特别是在对实时性要求不高但数据量巨大、计算复杂度高的场景下。下面从多个角度来详细介绍:
1.1.1. 数据爆炸式增长
- 随着互联网、移动设备、物联网等的发展,企业每天都会产生海量数据(日志、交易、行为、埋点、用户画像等)。
- 传统关系型数据库(如 MySQL、Oracle)难以支撑如此大规模的数据存储与分析。
1.1.2. 业务驱动的数据分析需求
企业希望从数据中获得洞察,做出更智能的业务决策,例如:
- 用户画像分析
- 广告推荐与定向投放
- 产品点击转化分析
- 信贷风险模型训练
- 运营指标统计(如 DAU、GMV、转化率)
这类分析往往需要:
- 扫描大量历史数据
- 执行复杂的聚合、统计、清洗、分组、排序操作
但这类任务不需要实时结果,允许延迟几分钟至数小时,因此非常适合“离线”处理。
1.1.3. AI/机器学习训练的需要
模型训练、特征提取、样本构造等任务,常常需要对长时间跨度的大数据进行批处理。
1.1.4. 降低实时系统压力
离线计算可以预先将数据汇总成宽表、指标表,供实时系统直接引用,避免实时系统计算压力过大。
1.2. 实时系统vs离线系统对比
这是一个数据系统分层设计的核心问题,关键在于:数据量级、实时性需求、业务复杂度、用户规模。总结一句话:当你需要处理海量数据但不要求实时响应时,用离线系统;当你对用户体验、风控、推荐等有实时性要求时,必须用在线系统。下面从实际业务角度出发,帮你梳理:
|
对比维度 |
实时系统(在线) |
离线系统 |
|
时效性 |
毫秒~秒级响应 |
分钟~小时级处理 |
|
使用场景 |
风控、推荐、监控 |
报表、建模、统计 |
|
数据特征 |
实时流、事件驱动 |
全量、批处理 |
|
用户感知 |
高(直接影响体验) |
低(运营后台) |
|
技术栈 |
Kafka、Flink、Redis |
Hive、Spark、Hudi |
|
成本 |
高(实时计算 + 高并发) |
相对低(定时批处理) |
|
架构复杂度 |
更高 |
中等偏高 |
1.2.1. 实时/准实时/离线系统
|
属性 |
实时系统 |
准实时系统 |
离线系统 |
|
处理延迟 |
毫秒 ~ 秒 |
秒 ~ 分钟(1~15 分钟) |
小时 ~ 天 |
|
常用技术 |
Flink、Kafka、Redis |
Flink、Spark Streaming、ClickHouse |
Spark、Hive、Hudi |
|
使用场景 |
推荐、风控、竞价秒杀 |
看板、特征流、同步更新 |
报表、建模、统计 |
|
架构复杂度 |
高 |
中高 |
中等 |
|
成本 |
高 |
中 |
相对低 |
1.2.2. 🎯 离线vs在线数据处理系统选择
✅ 建议使用离线系统,如果:
- 每日数据 ≥ 10GB,日志多、计算重
- 不要求实时响应
- 有模型训练、报表支持需求
- 有大量批量计算、复杂关联
✅ 建议使用在线系统,如果:
- 需要实时风控 / 推荐 / 异常告警
- 希望用户操作能立即反馈
- 企业已进入精细化运营阶段
- 已具备稳定离线架构,需提升用户体验
1.3. 离线大数据系统设计
1.3.1. ✅ 离线大数据系统适合场景
|
适用场景 |
特点说明 |
|
海量数据处理 |
日数据量 ≥ 10 GB,月级 TB 数据量,比如用户行为日志、交易日志 |
|
低实时性要求 |
对分析结果允许延迟 5 分钟~24 小时,例如次日运营报表、月度结算 |
|
批量模型训练 |
离线生成训练数据集、样本宽表、历史画像等 |
|
复杂数据汇总与清洗 |
需要大量 JOIN、聚合、窗口分析,如用户月活跃度、留存计算 |
|
周期性任务调度 |
比如每天凌晨跑前一天的 GMV、DAU、风控评分分布等 |
1.3.2. 📦离线系统应用系统级别
|
系统规模 |
日活 / 用户数 |
是否需要离线系统 |
|
小型系统 |
< 10 万用户 |
通常不需要,可用 MySQL + 脚本处理 |
|
成长型系统 |
10 万~100 万用户 |
✅ 推荐使用离线系统(如 Spark + Hive + Airflow) |
|
中大型系统 |
> 100 万用户、数据 > 10 TB |
✅ 强烈推荐搭建完整离线数仓体系 |
1.4. 离线大数据系统作用
|
功能 |
说明 |
|
数据清洗 |
把原始日志、埋点等原始数据进行格式转换、过滤、脱敏等 |
|
数据整合 |
连接不同数据源(如用户信息、交易数据、设备数据),形成统一数据视图 |
|
指标统计 |
生成 PV/UV、DAU、留存率、GMV 等核心业务指标 |
|
宽表生成 |
面向业务和模型训练的数据表(如用户画像宽表、特征工程表) |
|
任务调度 |
控制任务按日/小时运行(例如每天凌晨 1 点跑前一天的全量日志分析) |
|
数据仓库 |
搭建数据湖、数据中台,统一数据资产管理与对接(Hive、Hudi、Iceberg) |
|
报表支撑 |
支持经营分析、管理报表等 BI 系统使用 |
|
模型训练支撑 |
为机器学习、风控模型等提供原始样本或特征数据集 |
1.5. 在线实时系统设计
1.5.1. ✅ 在线数据处理系统(实时系统)适合场景
|
适用场景 |
特点说明 |
|
对时效性极高 |
需要分钟级、秒级响应,例如实时监控、实时风控、实时推荐 |
|
用户操作实时反馈 |
比如点击商品后立即推荐、广告曝光后立即出价决策 |
|
实时指标看板 |
实时 DAU、活跃设备数、订单秒级监控等 |
|
流式处理场景 |
IoT、日志采集、用户行为埋点数据流等 |
|
风控事件决策 |
放款审批、反欺诈、支付限额等需实时判断 |
1.5.2. 🧩 应用系统级别:
|
系统规模 |
应用特征 |
是否需要实时系统 |
|
小型系统 |
非核心场景 |
❌ 通常不需要,实时性不敏感 |
|
中型系统 |
需秒级响应,如风控系统 |
✅ 需搭建实时流处理架构 |
|
大型系统 |
涉及推荐、实时定价、监控报警 |
✅ 必备,支撑业务闭环与精细运营 |
1.6. 离线业务场(DAU100万在业内)背景
“每天日活跃用户(DAU)100万”是一个非常关键的运营指标,在互联网行业中已经属于中大型 App 的等级,是一个重要的里程碑。DAU(Daily Active Users) 指的是每天至少打开一次应用的独立用户数量。
- DAU 100 万 = 每天有 100 万不重复的用户使用 App
- 表示这个 App 在市场上已经具有了相当的活跃度和用户基础,能在主流用户层中占据稳定一席之地
1.6.1. DAU100万在业内处于什么水平?
|
DAU 范围 |
App 级别 |
举例 |
特点 |
|
10 万以下 |
小型 App |
利基类工具、校园 App |
用户较少,偏小众 |
|
10~50 万 |
成长期 App |
地区新闻、垂直社区 |
有一定用户粘性 |
|
50~100 万 |
中大型 App |
区域性社交、电商、实用工具 |
商业化初步成熟 |
|
100~500 万 |
大型 App |
知名垂直类产品,如:丁香医生、小红书早期阶段、得到 |
具备品牌影响力和市场竞争力 |
|
500 万以上 |
超大型 App |
抖音、微信、淘宝、知乎等 |
全国级别,进入全民平台 |
🟩 所以,DAU 100 万的 App 处于“头部垂直领域”或“区域性主流平台”水平。
1.6.2. DAU 100 万的 App 可能是哪些类型?
✅ 社交类(中腰部)
- 举例:陌陌、Soul、探探 等早期阶段
- 用户粘性强,DAU 与留存率直接挂钩
✅ 垂直电商类
- 举例:某品牌私域电商 App、区域零售 App(比如美宜佳 App)
- DAU 100 万说明有稳定消费用户群
✅ 工具类 / 教育类
- 举例:某记账 App、学习 App、网盘类(早期的夸克、幕布等)
- 用户使用频率高,但可能偏“轻量”。
✅ 内容/资讯类
- 举例:得到、知乎早期、澎湃新闻
- 内容驱动、粘性高、商业化潜力大。
✅ 金融类
- 比如:某消费金融、理财类 App(如陆金所、360借条早期)
- DAU 100 万说明有大规模信贷、理财或借贷需求。
2. 离线大数据技术设计
建设一个完整的离线大数据系统,需要一整套从数据采集 → 存储 → 计算 → 调度 → 数据建模 → 可视化 → 数据治理的技术组件体系。一个成熟的离线大数据系统,不只是“跑 Spark 任务”,而是包含从数据采集、存储、清洗、建模、调度、可视化、治理在内的完整数据闭环系统。下面我会从实际架构角度,系统地给你列出每一层所需的关键技术栈和它们的作用。
2.1. 🧱 离线大数据系统整体架构图
数据源(日志、数据库等)
↓
[数据采集层] — Flume / Sqoop / DataX / CDC / Kafka
↓
[数据存储层] — HDFS / Hive / Hudi / Iceberg / Delta Lake
↓
[数据计算层] — Spark / Hive / MR(已过时)/ Presto / Trino
↓
[调度与管理层] — Airflow / Azkaban / DolphinScheduler
↓
[数据建模层] — ODS → DWD → DWS → ADS(数仓分层建模)
↓
[数据可视化层] — Superset / FineBI / Tableau / QuickBI / Metabase
↓
[数据治理层] — DataHub / Atlas / Data Quality / Bloodline2.2. 🧩 各层所需核心技术栈详解
2.2.1. 📥 数据采集层
|
技术 |
用途 |
场景 |
|
Flume |
日志收集 |
收集 Web / App 的行为日志 |
|
Kafka |
消息中间件 |
解耦采集与处理,离线+实时 |
|
Sqoop |
DB → HDFS 导入 |
把关系型数据导入 Hive/HDFS |
|
DataX |
通用 ETL 工具 |
多源同步(MySQL、Oracle、MongoDB 等) |
|
Canal / Debezium |
CDC 同步 |
MySQL binlog 变更同步 |
2.2.2. 💾 数据存储层
|
技术 |
用途 |
特点 |
|
HDFS |
分布式文件系统 |
Hadoop 基础存储层,PB 级存储 |
|
Hive |
数据仓库 |
基于 HDFS,支持 SQL 查询(HiveQL) |
|
Hudi / Iceberg / Delta Lake |
数据湖 |
支持更新、插入、版本控制等高级特性 |
|
Parquet / ORC |
列式存储格式 |
提升查询效率,压缩好 |
2.2.3. ⚙️ 数据计算层(离线批处理)
|
技术 |
说明 |
|
Apache Spark |
内存计算引擎,替代 MapReduce,主流离线批处理框架 |
|
Hive |
基于 SQL 的批处理,适合简单数据加工 |
|
Presto / Trino |
分布式查询引擎,适合即席分析 |
|
MR(MapReduce) |
已过时,低效,不推荐新项目使用 |
2.2.4. 🕰️ 调度与任务管理层
|
技术 |
用途 |
|
Apache Airflow |
DAG 调度系统,Python 配置灵活 |
|
Azkaban |
简单易用的批处理任务调度系统 |
|
DolphinScheduler |
支持工作流、依赖管理、任务重试等 |
|
Oozie |
Hadoop 原生调度器(老旧) |
2.2.5. 🧱 数据建模与数仓设计
- 数据仓库分层建模方法(Kimball 模型):
-
- ODS(原始层):存原始数据
- DWD(明细层):清洗后标准化字段、维度打平
- DWS(汇总层):业务主题汇总表
- ADS(应用层):供报表、接口直接使用
工具支持:使用 Spark SQL / Hive / DBT 来处理建模逻辑。
2.2.6. 📊 数据可视化层
|
工具 |
用途 |
|
Apache Superset |
开源数据可视化平台,支持多种数据源 |
|
Metabase |
简单易用,适合快速搭建 |
|
FineBI / QuickBI |
国产商业 BI 平台,适合业务人员 |
|
Tableau / PowerBI |
企业级数据分析平台 |
2.2.7. 🧹 数据治理与元数据管理
|
工具 |
用途 |
|
Apache Atlas |
数据血缘、元数据管理 |
|
DataHub(LinkedIn 开源) |
支持 Schema、血缘、数据发现 |
|
Great Expectations / Data Quality |
数据质量检测工具 |
|
Amundsen |
数据目录、数据可见性系统 |
2.3. 📦 推荐通用技术组合(当前主流)
|
模块 |
技术选型(推荐) |
|
采集 |
Kafka + Flume + DataX |
|
存储 |
Hive + HDFS + Hudi |
|
计算 |
Spark SQL + Presto |
|
调度 |
Airflow / DolphinScheduler |
|
建模 |
ODS → DWD → DWS → ADS,SQL 实现 |
|
可视化 |
Superset / Metabase |
|
元数据治理 |
DataHub / Atlas |
3. 准实时大数据技术设计
准实时大数据系统,是介于 实时系统(毫秒/秒级响应) 与 离线系统(小时级/天级处理) 之间的一类系统,通常具有如下特征:数据延迟在 1 分钟~15 分钟左右,强调数据新鲜度,但又不强求极致低延迟。准实时系统是“秒级无强需求 + 数据必须新”的理想方案,用于平衡时效性与计算资源成本,广泛应用于运营看板、轻量风控、实时分析等场景。
3.1. ✅ 准实时大数据系统的典型应用场景
|
应用场景 |
说明 |
|
实时运营看板 |
展示分钟级更新的 DAU、GMV、访问 PV、转化率等 |
|
弱实时推荐系统 |
用户行为 5~10 分钟内反馈至推荐系统做内容调整 |
|
数据同步与缓存刷新 |
数据库更新后几分钟内同步至下游(如 ES、Redis) |
|
异常检测 & 预警 |
检测趋势、波动(非强实时告警) |
|
模型特征流更新 |
实时构造用户行为特征,但模型仍按周期离线跑 |
3.2. ✅ 准实时大数据系统的技术架构图
数据源(业务系统、日志、数据库)
↓
Kafka / Pulsar
↓
实时计算引擎(Flink / Spark Streaming)
↓
数据输出至多目标:ClickHouse / ES / Redis / MySQL / Hudi
↓
运营看板 / 数据接口 / 中台服务 / 离线同步系统3.3. 🧩 准实时大数据系统所需核心技术栈
3.3.1. 🔌 数据采集层
|
技术 |
用途 |
|
Kafka |
高吞吐、低延迟的消息队列,核心传输通道 |
|
Pulsar |
更现代化的分布式消息系统,支持多租户与分区 |
|
Flink CDC / Canal / Debezium |
数据库变更监听(MySQL/PostgreSQL binlog) |
|
Flume |
用于采集日志数据(如 Nginx、App 日志) |
3.3.2. ⚙️ 实时计算引擎
|
技术 |
特点 |
|
Apache Flink |
✅ 强一致、高吞吐、状态管理完善,准实时主力引擎 |
|
Spark Structured Streaming |
✅ 更适合批流一体、微批模型,适用于分钟级准实时 |
|
Kafka Streams |
轻量级处理,适合小规模准实时场景 |
|
Storm(过时) |
不推荐新项目使用 |
3.3.3. 💾 数据存储层(结果输出)
|
技术 |
场景说明 |
|
ClickHouse |
分析型数据库,适合准实时 OLAP 报表查询 |
|
Redis |
秒级缓存结果,供 API 接口调用 |
|
Elasticsearch |
日志查询、全文检索、实时报表展示 |
|
Hudi / Iceberg |
实时数据写入,供离线系统读取 |
|
MySQL / TiDB |
实时数据回写场景,如更新统计表、接口用表 |
3.3.4. 📅 调度协调 & 统一管理
|
技术 |
作用 |
|
Airflow + Flink Runner |
统一管理实时与离线任务 |
|
Dinky / Flink Gateway |
Flink 任务发布与管理平台 |
|
StreamPark |
管理 Spark / Flink 流任务的 Web 控制台 |
3.3.5. 📊 可视化展示
|
技术 |
说明 |
|
Apache Superset |
开源可视化工具,适合连接 ClickHouse/ES |
|
Grafana |
实时指标展示和预警 |
|
Quick BI / FineBI |
国产商业化平台,支持多种实时数据源接入 |
3.4. ✅ 典型准实时架构示例
3.4.1. 🎯 举例:电商运营看板系统(更新频率:每 5 分钟)
|
模块 |
技术 |
|
数据采集 |
Kafka + Flume(埋点日志) |
|
数据同步 |
Flink SQL(分钟级窗口聚合) |
|
数据存储 |
ClickHouse(结果落盘) |
|
数据展示 |
Superset + Grafana(看板) |
3.4.2. 🎯 举例:准实时风控评分系统
|
模块 |
技术 |
|
数据源 |
Kafka + Flink CDC |
|
特征计算 |
Flink + Redis 状态管理 |
|
数据落地 |
Hudi + MySQL |
|
接口调用 |
风控服务从 Redis + Hudi 查询 |
4. 全栈监控体系设计
监控系统在实际架构中会同时结合实时系统、准实时大数据系统和离线系统,形成一整套覆盖“秒级告警 + 分钟级趋势 + 小时级分析”的全栈监控体系。
|
系统类型 |
作用 |
推荐技术 |
|
实时系统 |
秒级监控、故障快速发现 |
Prometheus、Flink、Redis |
|
准实时系统 |
分钟级运营趋势、弱实时指标 |
Flink、ClickHouse、Grafana |
|
离线系统 |
历史追踪、趋势分析、报表 |
Spark、Hive、Hudi、BI 工具 |
4.1. 🧩 监控系统所使用的三类数据处理体系
|
系统类型 |
监控目标 |
代表技术 |
延迟 |
|
实时系统 |
秒级指标、告警、接口异常、QPS、RT |
Prometheus、Grafana、Kafka、Flink、Redis |
毫秒~秒级 |
|
准实时系统 |
分钟级统计、运营可视化、慢查询趋势、服务稳定性评分 |
Flink、Spark Streaming、ClickHouse、Superset |
1~5 分钟 |
|
离线大数据系统 |
日级日志分析、趋势对比、根因分析、月报 |
Hive、Spark、Hudi、Presto、Airflow |
小时~天 |
4.2. 🧰 一个典型的“多层级监控平台架构”
┌───────────────┐
│ 业务系统/中间件│
└──────┬────────┘
↓
┌────────────┬────────────┬─────────────┐
│ 实时系统 │ 准实时系统 │ 离线系统 │
│ Prometheus │ Flink │ Spark /Hive │
│ Grafana │ ClickHouse │ HDFS / Hudi │
│ Redis │ Superset │ Airflow │
└────────────┴────────────┴─────────────┘
↓ ↓ ↓
秒级告警 分钟级分析 天级回溯
自动化恢复 运营大屏 SLA月报4.3. 🧭 各类型监控系统使用场景与方案
4.3.1. ✅ 实时监控系统(核心:秒级预警、系统稳定性保障)
4.3.1.1. 📌 应用场景:
- CPU、内存、磁盘、网络等资源告警
- QPS、RT、接口 5xx 异常告警
- Kafka 堆积预警、线程池繁忙、GC 时间过长
- 秒级报警推送(钉钉、微信、短信)
4.3.1.2. 📦 技术方案:
|
模块 |
技术选型 |
|
数据采集 |
Node Exporter、JMX Exporter、Agent 上报 |
|
监控数据库 |
Prometheus / VictoriaMetrics(拉模式) |
|
分布式中间件 |
Kafka(Push 模式采集 + 广播) |
|
实时流处理 |
Flink(自定义规则处理)、Redis(状态缓存) |
|
展示告警 |
Grafana + Alertmanager |
4.3.2. ✅ 准实时系统(核心:分钟级可视化与趋势分析)
4.3.2.1. 📌 应用场景:
- API 接口耗时、请求量趋势图
- 错误码聚类、服务波动热力图
- 各系统 TPS、延迟分布
- 运营实时看板、分钟级 SLA 指标
4.3.2.2. 📦 技术方案:
|
模块 |
技术选型 |
|
数据采集 |
Kafka + Logstash / Filebeat / Flume |
|
流式计算 |
Flink SQL / Spark Streaming(窗口计算) |
|
数据存储 |
ClickHouse(高性能列式库) |
|
数据展示 |
Superset、Grafana(连接 ClickHouse) |
4.3.3. ✅ 离线大数据监控系统(核心:历史回溯、模型分析)
4.3.3.1. 📌 应用场景:
- 日志聚合分析:如全链路日志分析(慢查询追踪)
- 历史趋势回溯(如:上月故障点总结)
- SLA 报表、服务可用性趋势线
- 根因分析(系统级链路、调用耗时异常分析)
4.3.3.2. 📦 技术方案:
|
模块 |
技术选型 |
|
数据落地 |
Kafka → HDFS(或 Hudi / Iceberg) |
|
数据仓库 |
Hive(ODS → DWD → ADS) |
|
离线计算 |
Spark SQL / Presto |
|
调度系统 |
Airflow / DolphinScheduler |
|
可视化 |
FineBI / Superset / QuickBI |
4.4. 🧠业务监控(应用层监控)的推荐方案
业务监控比系统监控更复杂,涵盖“用户行为 + API 成功率 + 下单转化 + SLA 等”。
4.4.1. 📌 推荐组件组合:
|
监控维度 |
技术方案 |
|
接口成功率、RT |
Prometheus + Grafana |
|
业务指标(订单量、转化率) |
Flink → ClickHouse + Superset |
|
日志链路分析(错误聚合) |
Kafka + ELK(Elasticsearch + Logstash + Kibana) |
|
业务行为监控(按钮点击、漏斗) |
自定义埋点 SDK + Kafka + Flink + ClickHouse |
|
SLA 统计、合规报表 |
Hive + Spark + 离线报表调度 |
博文参考

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)