【机器学习】模型评估
同时,算出AUC值。(2)欠拟合:欠拟合是机器学习中的一种情况,当模型在训练数据上表现的很差,无法捕捉到数据中的复杂模式,导致模型的泛化能力弱,这通常表现为模型在训练集和验证集上的误差都很高。(3)误差:学习器的实际预测输出与样本的真实输出之间的差异称为“误差”,学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”。将数据集分层采样划分为k个大小相似的互斥子集,每
一、模型评估
1.概念
模型评估是指在机器学习中,对于一个具体方法输出的最终模型,使用一些指标和方法来评估它的泛化能力。这一步通常在模型训练和模型选择之后,正式部署模型之前进行。模型评估不针对模型本身,而是针对问题和数据,因此可以用来评价不同方法的模型的泛化能力,以此决定最终模型的选择。
2.误差
(1)错误率:分类错误的样本数占总样本数的比例,即在m个样本中有a个样本分类错误,则错误率E=a/m。
(2)精度:1-a/m为"精度",即“精度=1-错误率”。
(3)误差:学习器的实际预测输出与样本的真实输出之间的差异称为“误差”,学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”。
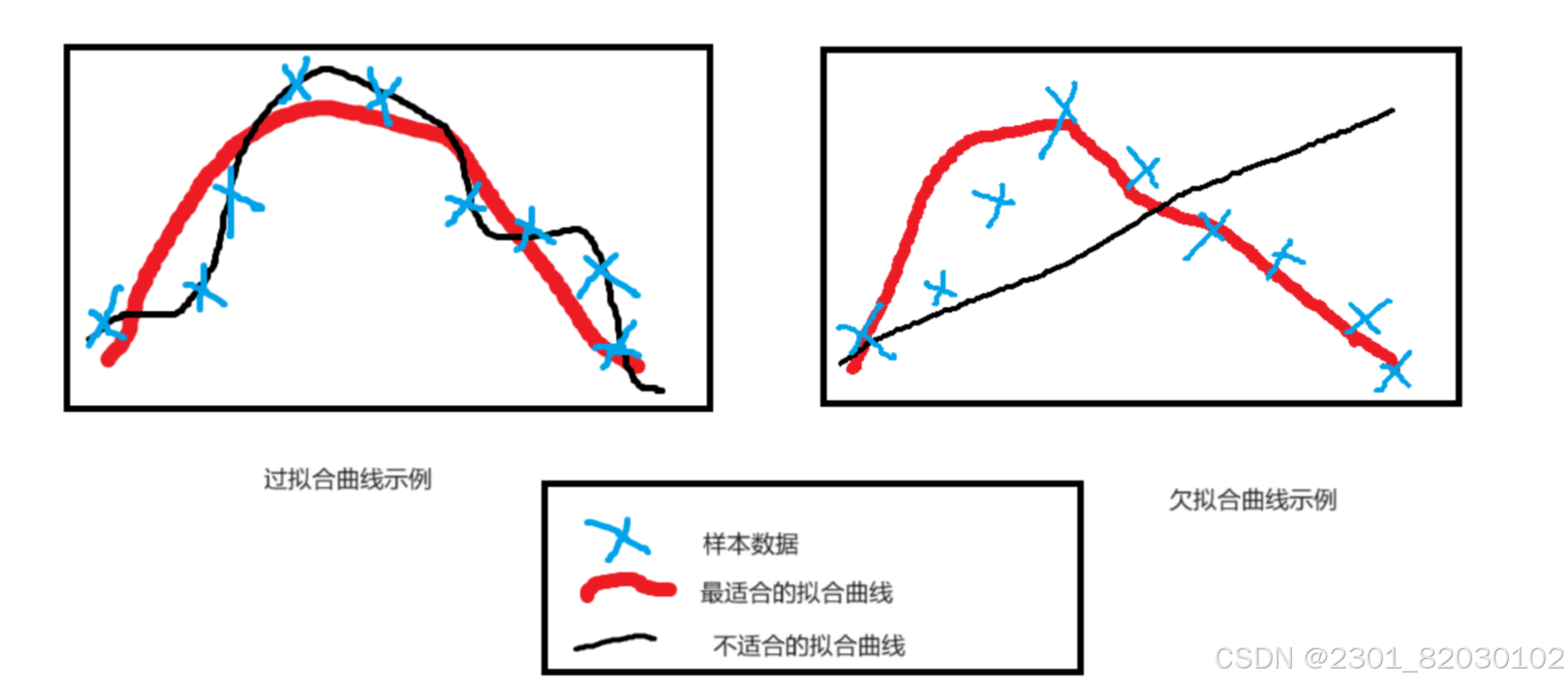
3.过拟合与欠拟合
(1)过拟合:当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降,这种现象在机器学习中称为“过拟合”。
(2)欠拟合:欠拟合是机器学习中的一种情况,当模型在训练数据上表现的很差,无法捕捉到数据中的复杂模式,导致模型的泛化能力弱,这通常表现为模型在训练集和验证集上的误差都很高。欠拟合与过拟合相对,这是指对训练样本的一般性质尚未学好。
(3)解决方法:
过拟合:优化目标加正则项、early stop、减少训练样本
欠拟合:决策树(拓展分支)、增加训练轮数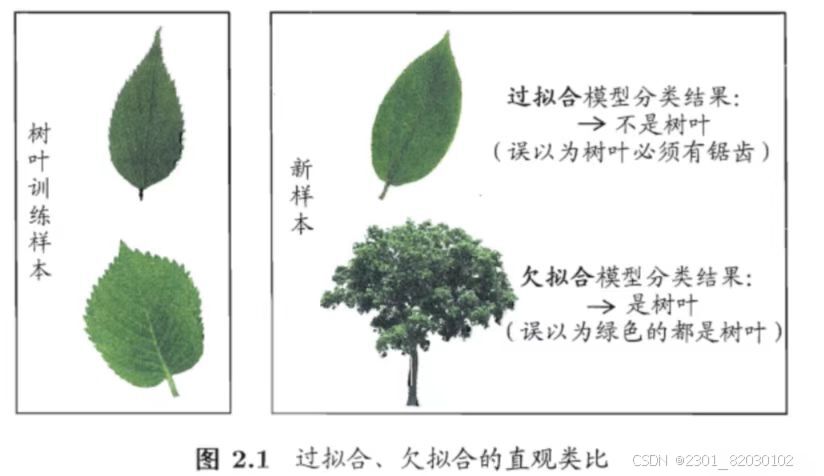
二、评估方法
1.留出法
"留出法"直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=∅。在S上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计。
训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。即便在给定训练/测试集的样本比例后,仍存在多种划分方式对初始数据D进行分割。不同的划分将导致不同的训练/测试集,相应的,模型评估的结果也会有所差别。因此单独使用留出法得到的估计结果往往不够稳定可靠,在使用留出法时,一般要采用若干随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
2.交叉验证法
将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试集最终返回k个测试结果的均值,k最常用的取值是10。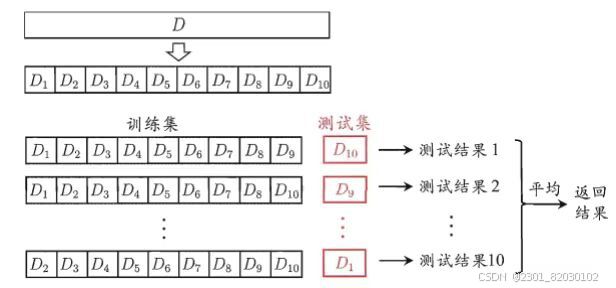
三、性能度量
1.回归性能指标
在预测任务中,给定样例集D={(x1,y1),(x2,y2),…,(xm,ym)},其中yi是示例xi的真实标记。要评估学习器f的性能,就要把学习器预测结果f(x)与真实标记y进行比较。
回归任务最常用的性能度量是均方误差:
更一般的,对于数据分布D和概率密度函数p(.),均方误差可描述为: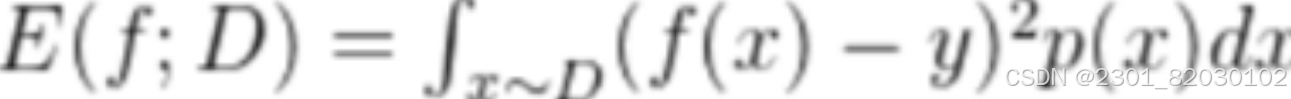
2.分类性能指标
(1)混淆矩阵
混淆矩阵也被称为误差矩阵或可能性表格,是机器学习领域中一种常见的可视化工具,特别是在监督学习中。它的主要作用是用来评价算法或分类器的结果分析表。混淆矩阵是一个n行n列的矩阵,其中每一列代表预测值,每一行代表实际值。
在二分类问题中,混淆矩阵的四个主要元素通常被标记为:
TP:真正例,实际是正例,识别为正例。
FN:真反例,实际是正例,却识别成了负例。
FP:假正例,实际是负例,却识别成了正例。
TN:真反例,实际是负例,识别为负例。
分类结果混淆矩阵如下:
查准率P、查全率R:
查准率和查全率是一对矛盾的变量。
一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
通常只有在一些简单任务中,才可能使查准率和查全率都很高。
平衡点(BEP):是综合考查准率、查全率的性能度量,它是“查准率=查全率”时的取值。
P-R图: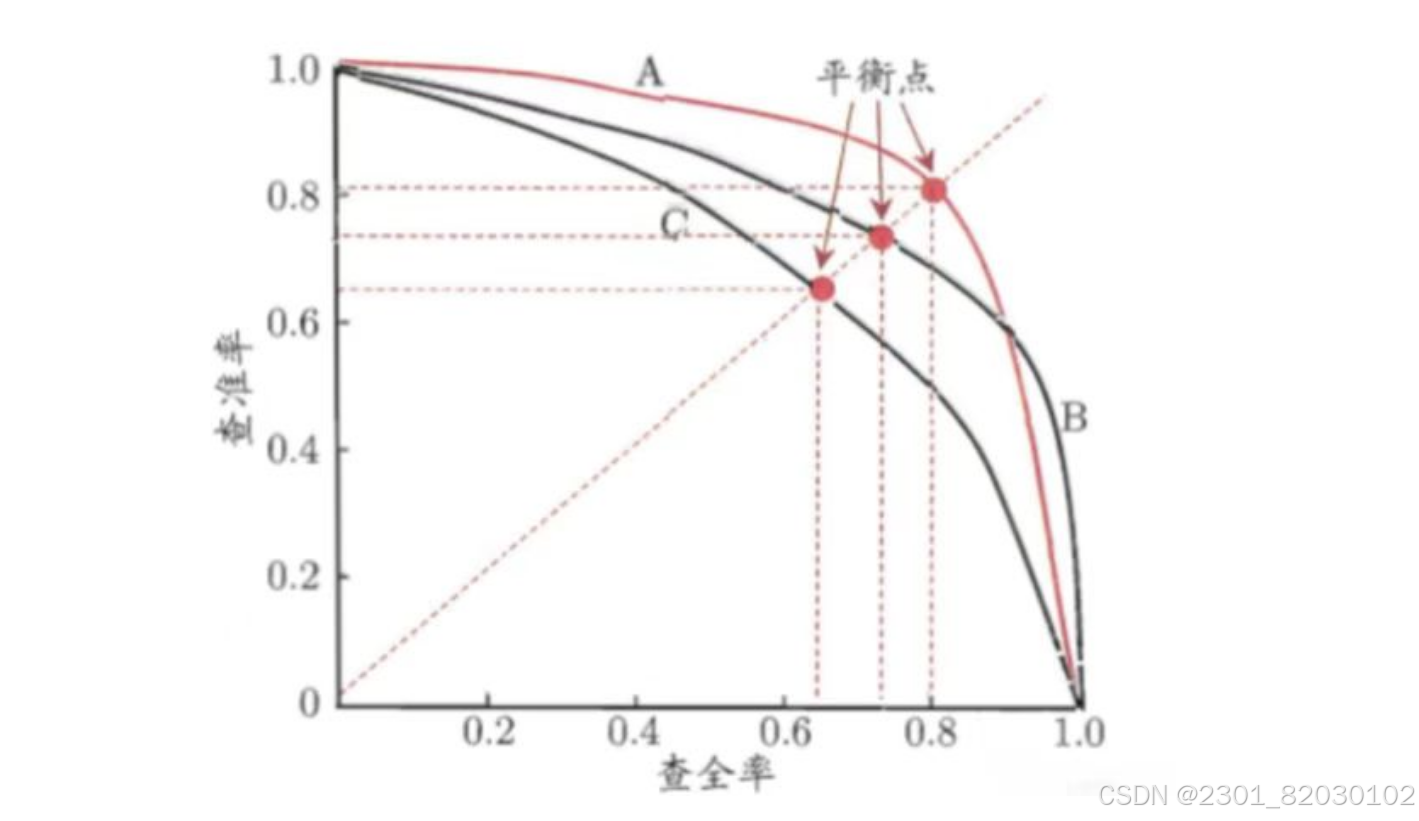
(2)F1分数
F1的大小反映模型的稳定性,F1越大,模型越稳定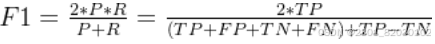
F1的更一般形式: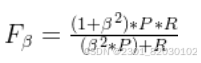
β=1,标准的F1
β>1,偏重查全率
β<1,偏重查准率
(3)ROC与AUC
ROC与P-R曲线相似,根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标作图,就得到了“ROC曲线”。ROC曲线的纵轴是TPR(真正例率),横轴是FPR假正例率),两者分别定义为: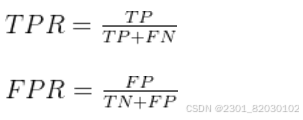
ROC曲线的面积就是AUC(如果曲线交叉,AUC越大的学习器性能越好)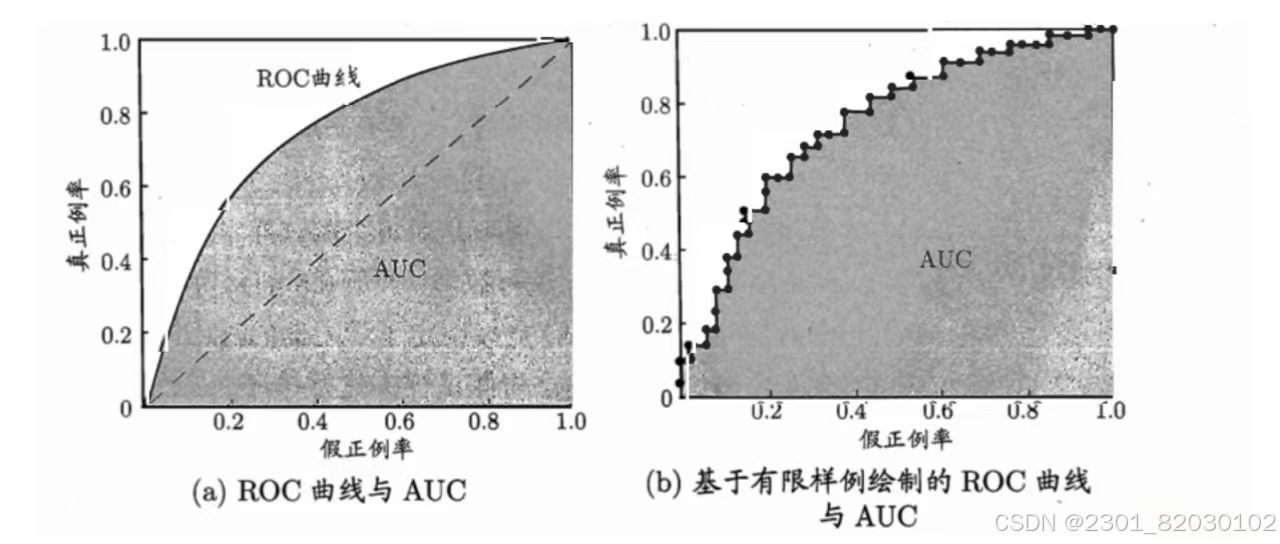
四、实验
1.代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, precision_recall_curve, roc_curve, auc
from sklearn.metrics import roc_auc_score
import seaborn as sns
# 生成1000个样本的数据集(随机)
np.random.seed(0)
X = np.random.rand(1000, 10)#矩阵 1000行10列
y = (X[:, 0] + X[:, 1] > 1).astype(int)
# 划分数据集为训练集(80%)和测试集(20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征标准化,标准化用于将特征数据转换为具有零均值和单位方差的形式
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)#对训练集进行标准化处理
X_test = scaler.transform(X_test)#对测试集进行标准化处理
# 初始化KNN分类器并选择K值
k = 5
knn_classifier = KNeighborsClassifier(n_neighbors=k)
# 训练KNN分类器
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 模型的概率预测
y_scores = knn.predict_proba(X_test)[:, 1]
# 初始化存储P-R曲线上的点
precision_points = []
recall_points = []
# 初始化空列表来存储ROC曲线上的点
TPR_points = []
FPR_points = []
# 遍历不同的阈值
thresholds = np.linspace(0, 1, 10)#生成一个包含10个元素的等差数列,范围从0到1
for threshold in thresholds:
y_pred = (y_scores >= threshold).astype(int)
TP = np.sum((y_pred == 1) & (y_test == 1))
FP = np.sum((y_pred == 1) & (y_test == 0))
TN = np.sum((y_pred == 0) & (y_test == 0))
FN = np.sum((y_pred == 0) & (y_test == 1))
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
TPR_points.append(TPR)
FPR_points.append(FPR)
precision = TP / (TP + FP) if TP + FP > 0 else 1.0
recall = TP / (TP + FN) if TP + FN > 0 else 1.0
precision_points.append(precision)
recall_points.append(recall)
print("TP(真正例个数):",TP)
print("FP(假正例个数):",FP)
print("TN(真反例个数):",TN)
print("FN(假反例个数):",FN)
print("R(查全率):",recall_points)
print("P(查准率):",precision_points)
print("FPR(假正例率):",FPR_points)
print("TPR(真正例率):",TPR_points)
#计算AUC值
AUC = roc_auc_score(y_test, y_pred)
print("AUC = ",AUC)
# 绘制P-R曲线
plt.plot(recall_points, precision_points, marker='.')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('P-R Curve')
plt.grid(True)
#plt.show()
# 绘制 ROC 曲线
plt.figure()
plt.plot(FPR_points, TPR_points, color='darkorange', lw=2)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.title('ROC Curve')
plt.show()
2.结果

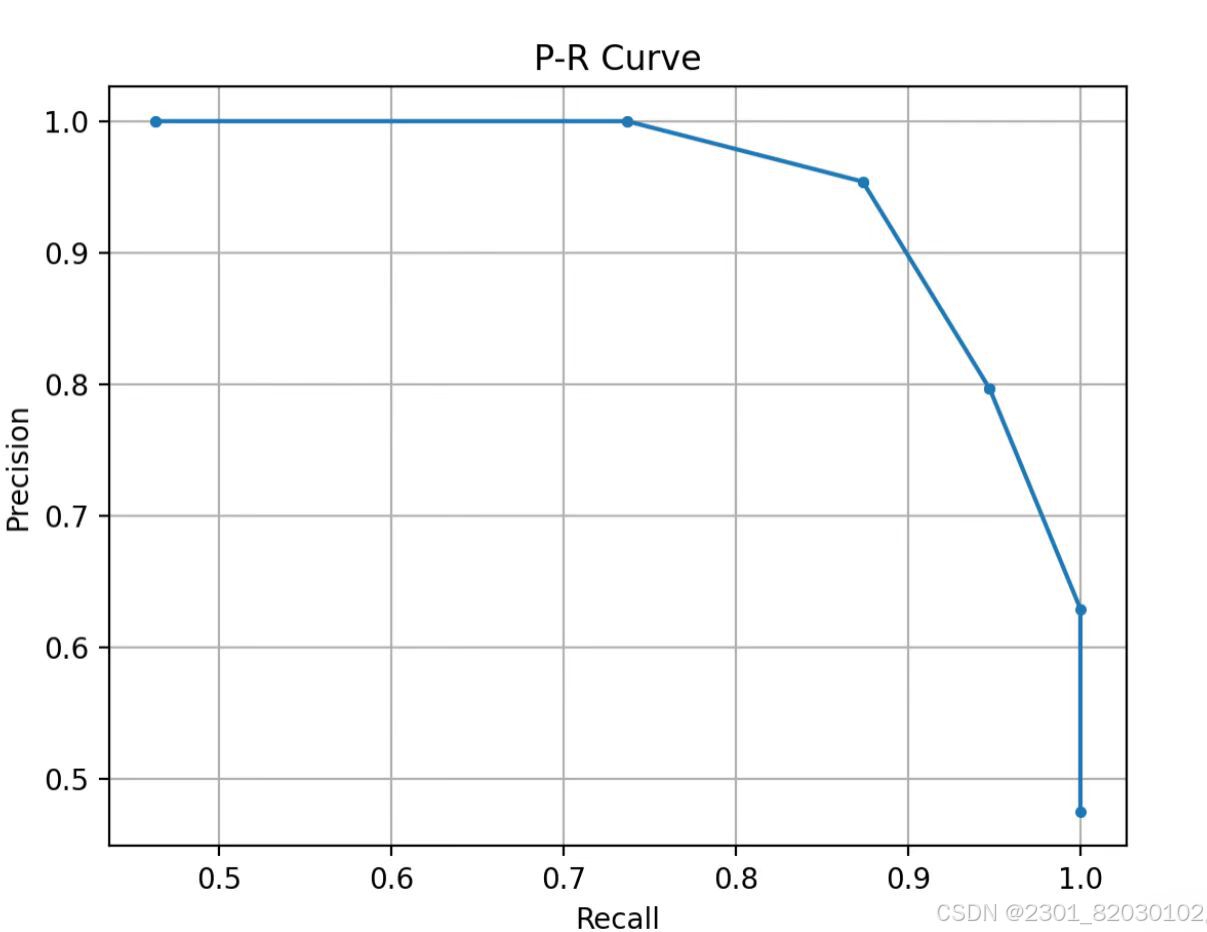
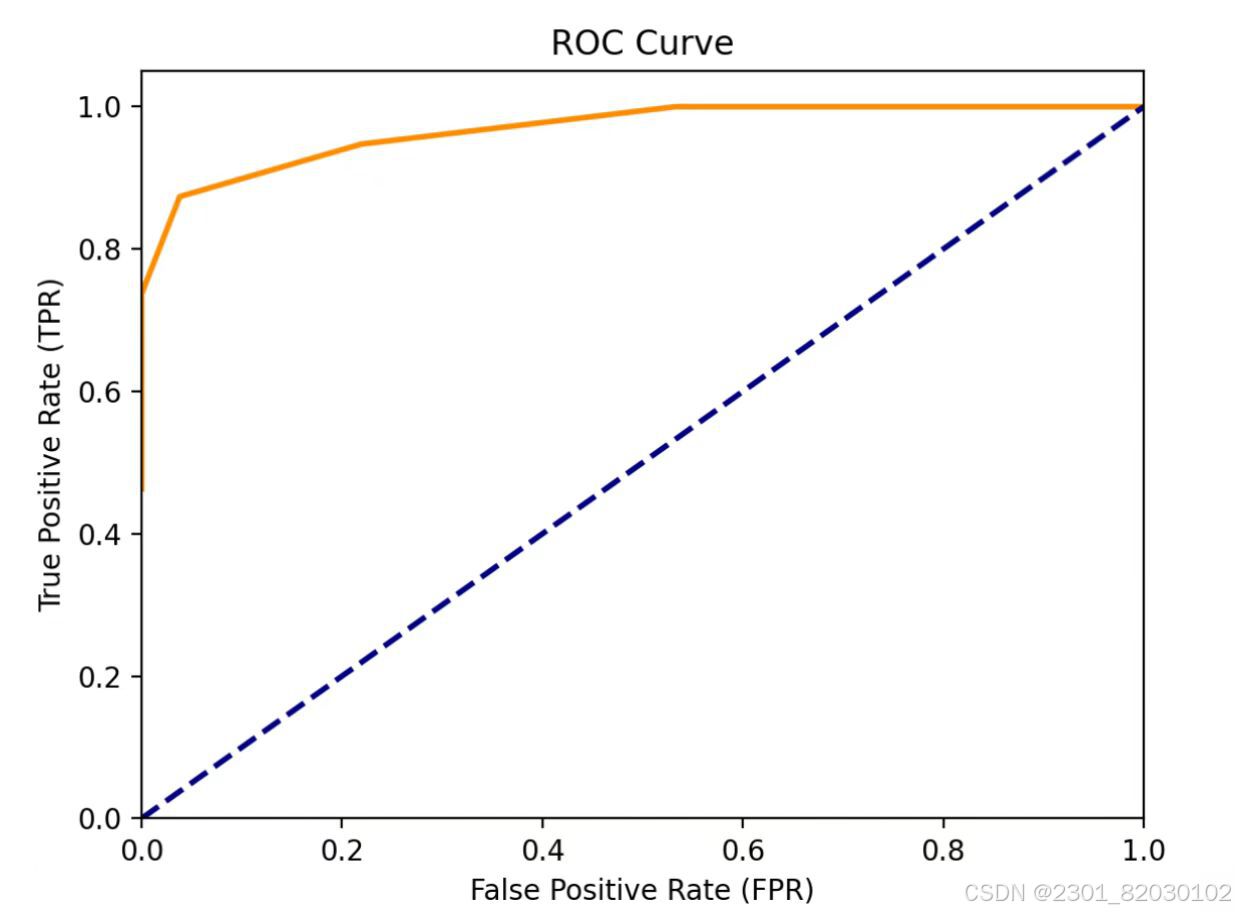
3.实验小结
本实验利用numpy生成含1000个样本、10个特征的随机数据集,并依据前两个特征之和是否大于1构建二分类标签。通过遍历不同阈值,算出TP、FP、TN、FN等关键指标,进而得到精确率、召回率、TPR和FPR。同时,算出AUC值。最后,基于计算结果绘制P-R曲线与ROC曲线,前者直观展现模型在不同阈值下精确率与召回率的权衡关系,后者通过与随机猜测对角线对比,进一步评估模型性能。实验结果证明该KNN模型在当前数据集上具备良好的分类性能 。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)