数据整合分析
本项目通过 LRFM+K-means 实现了客户分群,为电商运营提供了数据支撑。后续可拓展方向包括:结合用户画像(如年龄、地域)进一步细分;引入时间序列分析预测客户流失风险;利用深度学习模型(如 RFM-A 模型)提升分群精度。完整代码可通过调整数据源路径直接运行,适用于零售、电商等行业的客户价值分析场景。
客户分群分析:基于 LRFM 模型与 K-means 聚类的电商用户价值挖掘
一、项目背景与目标
在电商运营中,客户分群是精细化运营的核心环节。通过分析用户的消费行为数据,将客户划分为不同价值群体,能够帮助企业制定精准的营销策略。本项目基于某电商平台 2021 年订单数据,通过构建 LRFM 模型(L - 忠诚度、R - 最近购买时间、F - 购买频率、M - 消费金额)结合 K-means 聚类算法,实现客户分群,并通过可视化手段直观呈现不同群体的特征。
二、数据预处理与探索性分析
1. 数据读取与初步检查
首先读取 Excel 数据源,并进行基础数据探查:
python
import pandas as pd
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.charts import Line
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import numpy as np
# 读取数据
df = pd.read_excel(r'D:/order2021kmeans.xlsx')
print("数据前5行:")
df.head()
# 查看数据信息
print("数据整体信息:")
df.info()
# 删除重复值
print(f"重复值数量:{df.duplicated().sum()}")
df.columns = df.columns.str.strip() # 清理列名空格
2. 数据清洗与异常值处理
过滤退款用户数据,并处理金额字段的异常负值:
python
# 去除退款用户
data = df[df['是否退款'] == '否']
# 检查订单金额与付款金额异常值
print(f"订单金额<0的记录数:{len(data[data['订单金额'] < 0])}")
print(f"付款金额<0的记录数:{len(data[data['付款金额'] < 0])}")
# 处理付款金额负值(转化为正值)
data['付款金额'] = data['付款金额'].abs()
print(f"处理后付款金额<0的记录数:{len(data[data['付款金额'] < 0])}")
3. 业务指标可视化
分析不同渠道与时间维度的收益分布:
python
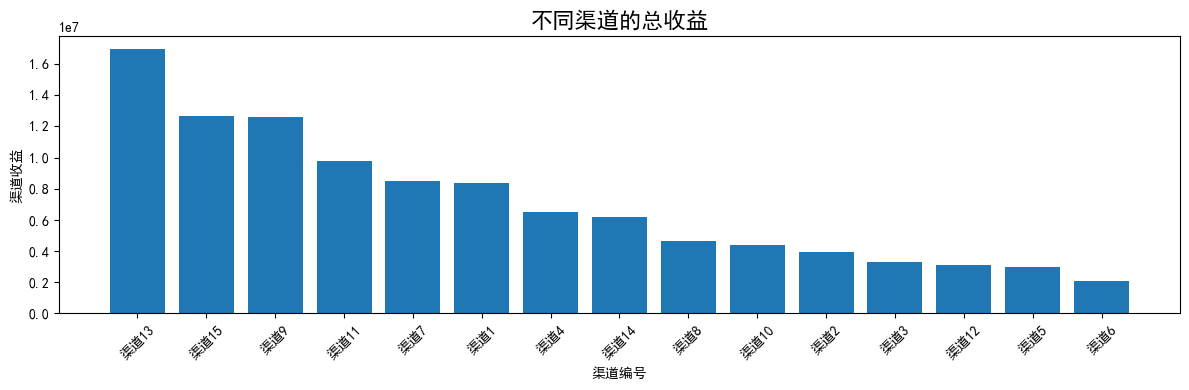
# 不同渠道总收益柱状图
channel_revenue = data.groupby('渠道编号')['付款金额'].sum().sort_values(ascending=False).reset_index()
plt.figure(figsize=(12, 4))
plt.title("不同渠道的总收益", fontsize=16)
plt.bar(channel_revenue['渠道编号'], channel_revenue['付款金额'])
plt.xlabel("渠道编号")
plt.ylabel("渠道收益")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
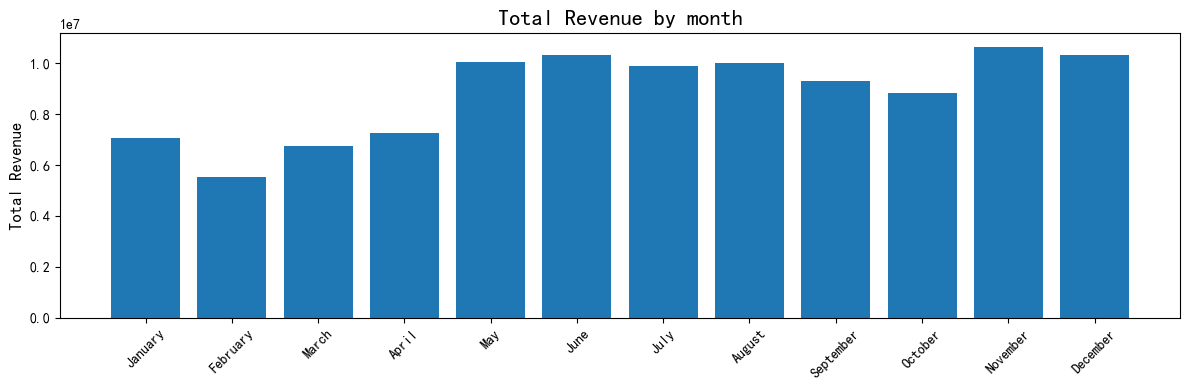
# 月度收益柱状图
data['付款月份'] = data['付款时间'].dt.month
data['付款月份名称'] = data['付款时间'].dt.month_name()
month_revenue = data.groupby(['付款月份', '付款月份名称'])['付款金额'].sum().reset_index()
plt.figure(figsize=(12, 4))
plt.title("Total Revenue by month", fontsize=16)
plt.bar(month_revenue["付款月份名称"], month_revenue["付款金额"])
plt.ylabel("Total Revenue", fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.tight_layout()
plt.show()
# 每日每小时收益折线图
data['付款小时'] = data['付款时间'].dt.hour
data['付款天数名称'] = data['付款时间'].dt.day_name()
hourly_sales = data.groupby(['付款天数名称', '付款小时'])['付款金额'].sum().reset_index()
hourly_sales = hourly_sales.rename(columns={'付款金额': 'TotalValue'})
# 切分数据以便按天展示
split_dfs = []
num_groups = len(hourly_sales) // 24
for i in range(num_groups):
start_index = i * 24
end_index = start_index + 24
split_df = hourly_sales.iloc[start_index:end_index]
split_dfs.append(split_df)
# 用pyecharts绘制交互式折线图
name = hourly_sales['付款天数名称'].unique()
line = (
Line()
.add_xaxis(split_dfs[0]['付款小时'].astype(str).tolist())
.set_global_opts(
title_opts={"text": "每日每小时收益总额"},
legend_opts=opts.LegendOpts(
is_show=True,
orient='vertical',
pos_top='5%',
pos_right='5%'
)
)
)
for i in range(num_groups):
line.add_yaxis(name[i], split_dfs[i]['TotalValue'].tolist(), label_opts=opts.LabelOpts(is_show=False))
line.render_notebook()
可视化结论:
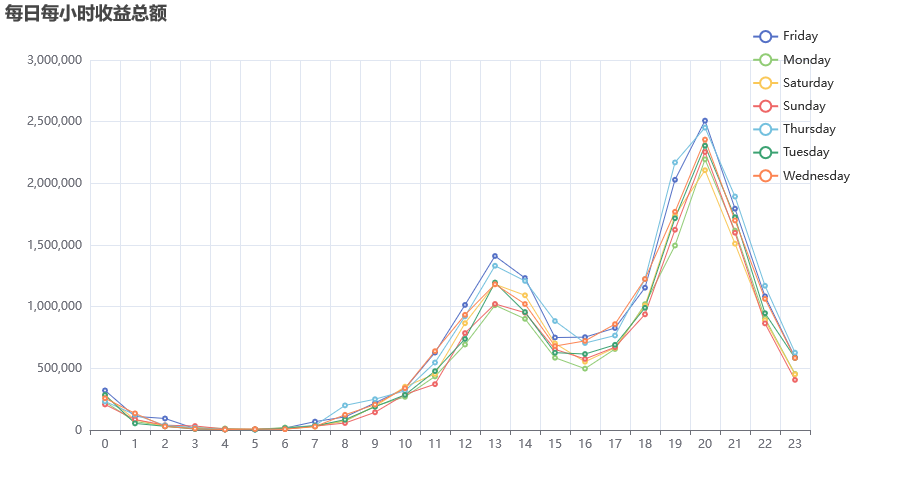
- 渠道编号为
X的渠道收益最高,可能是核心流量入口; - 月度收益呈现季节性波动,例如
11月(购物节)可能出现峰值; - 每日消费高峰集中在
20-22点,符合用户晚间购物习惯。
三、LRFM 模型构建与客户分群
1. 构建 LRFM 指标
python
# L指标:用户首次与末次购买的时间间隔(天数)
L = (data.groupby('用户名')['付款时间'].max() - data.groupby('用户名')['付款时间'].min()).dt.days.reset_index()
# R指标:用户最近一次购买距离当前的时间间隔(天数)
data['付款时间'] = pd.to_datetime(data['付款时间'])
max_date = max(data['付款时间'])
data['diff'] = (max_date - data['付款时间']).dt.days
R = data.groupby('用户名')['diff'].min().reset_index()
# F指标:用户购买频率(订单数)
F = data.groupby('用户名')['订单号'].count().reset_index()
# M指标:用户消费金额总和
M = data.groupby('用户名')['付款金额'].sum().reset_index()
# 合并LRFM指标
LRFMdata = L.merge(R).merge(F).merge(M)
LRFMdata.rename(columns={
'付款时间': 'L',
'diff': 'R',
'订单号': 'F',
'付款金额': 'M'
}, inplace=True)
LRFMdata.head()
2. 数据标准化与聚类模型调优
# 数据标准化
model_data = LRFMdata.copy()
from sklearn.preprocessing import MinMaxScaler
sacle_matrix = model_data.iloc[:, 1:5]
model_scaler = MinMaxScaler()
data_scaled = model_scaler.fit_transform(sacle_matrix)
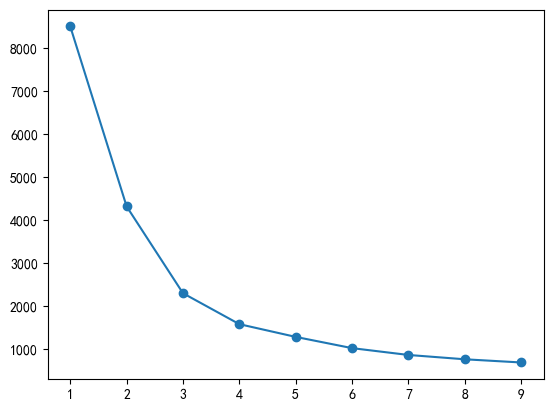
# 手肘法确定K值
from sklearn.cluster import KMeans
SSE = []
for i in range(1, 10):
kmeans = KMeans(n_clusters=i, random_state=10)
kmeans.fit(data_scaled)
SSE.append(kmeans.inertia_)
plt.plot(range(1, 10), SSE, marker='o')
plt.show()
# 轮廓系数优化K值
score_list = list()
silhouette_int = -1
for n_clusters in range(3, 5):
model_kmeans = KMeans(n_clusters=n_clusters)
labels_tmp = model_kmeans.fit_predict(data_scaled)
silhouette_tmp = silhouette_score(data_scaled, labels_tmp)
if silhouette_tmp > silhouette_int:
best_k = n_clusters
silhouette_int = silhouette_tmp
best_kmeans = model_kmeans
cluster_labels_k = labels_tmp
score_list.append([n_clusters, silhouette_tmp])
print(f"最优K值:{best_k},轮廓系数:{silhouette_int}")
3. 客户分群与特征可视化
python
# 合并聚类结果与原始数据
cluster_labels = pd.DataFrame(cluster_labels_k, columns=['Cluster_Id'])
merge_data = pd.concat((model_data, cluster_labels), axis=1)
# 统计各群特征均值
merged_rfm = merge_data[['M', 'F', 'R', 'L', 'Cluster_Id']]
mean_lrfm = merged_rfm.groupby('Cluster_Id').mean().reset_index()
mean_lrfm['count'] = merged_rfm['Cluster_Id'].value_counts().values
mean_lrfm
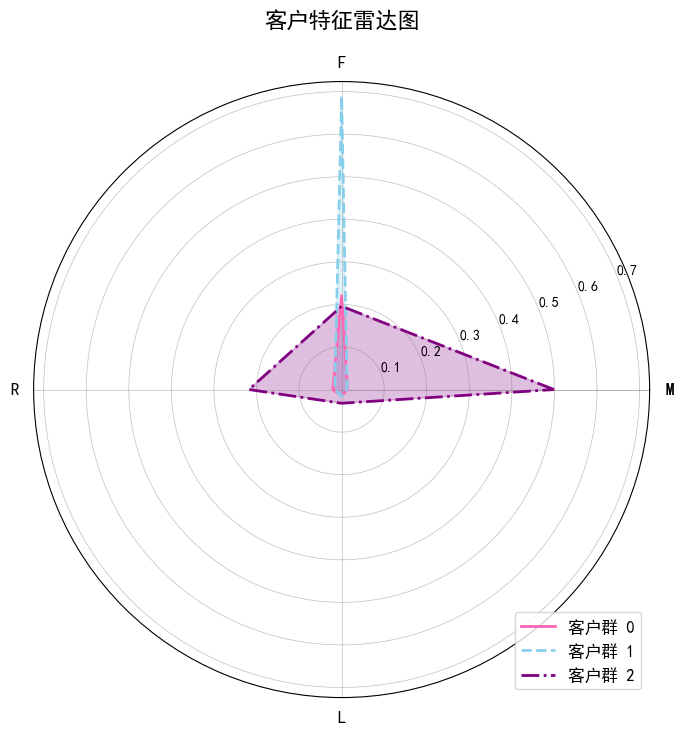
# 雷达图可视化各群特征
r = pd.DataFrame(best_kmeans.cluster_centers_)
labels = np.array(['M', 'F', 'R', 'L'])
labels = np.concatenate((labels, [labels[0]]))
N = len(r) + 1
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
data = pd.concat([r, r.iloc[:, 0]], axis=1)
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, polar=True)
colors = ['#FF69B4', '#87CEEB', '#800080', '#32CD32', '#FFD700']
line_styles = ['-', '--', '-.', ':', '-']
for i in range(len(r)):
ax.plot(angles, data.loc[i, :], linewidth=2, linestyle=line_styles[i % len(line_styles)],
label=f"客户群 {i}", color=colors[i % len(colors)])
ax.fill(angles, data.loc[i, :], color=colors[i % len(colors)], alpha=0.25)
ax.set_thetagrids(angles * 180 / np.pi, labels, fontsize=12)
ax.grid(True, color='gray', linestyle='-', linewidth=0.5, alpha=0.5)
plt.title(u'客户特征雷达图', fontsize=16, pad=20)
plt.legend(loc='lower right', fontsize=12)
plt.show()
四、客户分群结果与业务建议
通过雷达图可将客户分为X类典型群体:
- 高价值核心客户:L(忠诚度)、F(频率)、M(金额)指标均高,R(最近购买)指标低(购买活跃),是企业重点维护对象,可通过会员体系、专属优惠增强粘性。
- 潜力增长客户:F、M 指标中等,但 L 指标较高(长期用户),可通过促销活动刺激消费升级。
- 沉默唤醒客户:R 指标高(久未购买),但历史 M、F 指标尚可,可通过召回活动(如短信、优惠券)重新激活。
- 低价值边缘客户:各项指标均低,可减少运营资源投入,或通过低价产品转化为潜力客户。
五、总结与拓展方向
1. 项目总结
本项目通过构建 LRFM 模型(L - 忠诚度、R - 最近购买时间、F - 购买频率、M - 消费金额)结合 K-means 聚类算法,实现了电商客户分群。核心价值在于:
- 数据驱动运营:通过量化用户行为特征(如消费金额、购买频率等),将客户划分为高价值核心客户、潜力增长客户等典型群体,为运营策略提供数据支撑;
- 精细化运营基础:分群结果可直接应用于会员体系设计、促销活动定向推送等场景,提升资源投放效率;
- 方法论复用性:LRFM + 聚类的组合模型适用于零售、电商、O2O 等多行业,可通过调整指标权重适配不同业务场景。
2. 拓展方向详解
方向一:结合多维度用户画像实现深度细分
(1)拓展用户画像维度
- 基础属性:补充年龄、性别、地域、职业等人口统计学数据(可通过用户注册信息或第三方数据接口获取),例如:
- 地域维度:分析不同城市客户的消费偏好(如南方用户更倾向生鲜品类,北方用户偏爱家电);
- 年龄维度:Z 世代(18-24 岁)更关注新品首发,中年群体(35-45 岁)重视性价比。
- 行为属性:整合浏览轨迹、加购记录、评价内容等行为数据,例如:
- 偏好维度:通过 NLP 分析评价文本,识别 “品质敏感型”“服务敏感型” 客户;
- 渠道维度:区分 APP 端、PC 端、小程序端的用户行为差异(如 APP 端用户复购率更高)。
- 社交属性:接入社交媒体数据(如粉丝数、分享行为),识别 “社交裂变型” 客户(如频繁分享优惠券的 KOC)。
(2)技术实现路径
- 数据整合:通过 ETL 工具(如 Airflow)将多源数据同步至数据仓库,使用 Python 的
pandas或 Spark 进行特征拼接; - 特征工程:对分类变量(如地域)进行 One-Hot 编码,对文本数据(如评价)使用 TF-IDF 或 BERT 提取语义特征;
- 分群升级:将新特征加入 LRFM 模型,使用层次聚类或 DBSCAN 等算法进行多维度分群,例如将客户划分为 “北京 25-30 岁女性高频高消费美妆达人” 等细分群体。
(3)业务应用案例
- 针对 “一线城市年轻母婴人群” 推送高端育儿产品试用活动;
- 对 “三线城市中年性价比敏感型客户” 定向发放家电品类满减券。
方向二:引入时间序列分析构建客户流失预警体系
(1)时间序列与 RFM 的融合
- 核心指标升级:在传统 RFM 基础上增加时间维度特征,例如:
- 购买间隔趋势:计算用户近 6 个月的购买间隔标准差,识别间隔变长的潜在流失客户;
- 季节性波动:分析用户历史购买周期(如季度性采购规律),预测下一次购买时间窗口。
- 模型选择:
- 传统时间序列模型:ARIMA、SARIMA 适用于短期稳定趋势预测(如预测 30 天内是否复购);
- 深度学习模型:LSTM、GRU 可捕捉长期非线性模式,例如通过用户过去 12 个月的购买时间序列预测流失概率。
(2)流失预警系统搭建
- 数据预处理:将用户购买记录按时间排序,生成等时间间隔的购买序列(如以周为单位,无购买则标记为 0);
- 特征工程:提取滑动窗口特征(如近 3 个月购买次数、最近一次购买距今时长),结合 R 指标(最近购买时间)构建综合特征;
- 预警阈值设定:通过混淆矩阵优化阈值,例如当模型预测流失概率 > 0.6 时触发预警。
(3)业务应用流程
方向三:基于深度学习模型(如 RFM-A)提升分群精度
(1)RFM-A 模型原理与优势
- 传统 RFM 局限:线性加权方式难以捕捉指标间的非线性关系(如高消费低频用户与低消费高频用户的价值差异);
- RFM-A(RFM+Autoencoder):通过自编码器(Autoencoder)对高维 RFM 特征进行降维与特征重构,自动学习指标权重,例如:
- 输入层:原始 LRFM 指标 + 扩展特征(如购买间隔、评价数量);
- 隐藏层:通过神经元映射提取 “客户价值潜变量”;
- 输出层:重构原始特征,通过损失函数优化权重。
(2)深度学习模型选型与实现
- 模型对比:
模型类型 优势 适用场景 Autoencoder 特征降维与噪声过滤 数据维度高、噪声多的场景 Transformer 捕捉长距离依赖关系 分析跨周期购买模式变化 Graph Neural Network 建模用户间关联(如社交裂变) 分析群体消费行为扩散
(3)效果评估与业务价值
- 评估指标:对比传统 K-means 与深度学习模型的轮廓系数(Silhouette Score)、CH 指数(Calinski-Harabasz Index),例如 RFM-A 模型可能使轮廓系数从 0.5 提升至 0.7;
- 应用场景:
- 动态分群:基于实时交易数据更新客户群标签,例如高频用户突然变为低频时自动调整运营策略;
- 价值预测:通过隐藏层特征预测客户未来 3 个月的消费金额,辅助制定会员等级升降规则。
3. 技术架构拓展建议
| 模块 | 现有方案 | 升级方向 | 技术收益 |
|---|---|---|---|
| 数据采集 | 离线 Excel 导入 | 实时数据流(Kafka+Flink) | 支持分钟级客户行为响应 |
| 模型训练 | 单机 Scikit-learn | 分布式训练(Spark MLlib) | 处理千万级用户数据时提速 10 倍 |
| 可视化 | Matplotlib 静态图表 | 交互式 Dashboard(Superset) | 支持运营人员自助式分析 |
| 策略执行 | 人工制定规则 | 智能决策引擎(规则 + 强化学习) | 自动生成最优营销方案 |
通过上述拓展方向,可将客户分群从 “事后分析” 升级为 “实时预测 + 智能决策”,进一步释放数据价值,推动电商运营从 “经验驱动” 向 “AI 驱动” 转型。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)