pandas读取表头_Pandas数据处理与分析二
读写excel文件1、读取Excel数据pandas中通过read_excel()函数读取以 'xls' 或 ’xlsx’ 后缀的excel文件,使用方法和各参数详解如下:pandas.read_excel(io,sheet_name=0,header=0,index_col=None,names=None,dtype=None)举个例子:pan...

 读写excel文件 1、读取Excel数据 pandas中通过read_excel()函数读取以 'xls' 或 ’xlsx’ 后缀的excel文件,使用方法和各参数详解如下:
读写excel文件 1、读取Excel数据 pandas中通过read_excel()函数读取以 'xls' 或 ’xlsx’ 后缀的excel文件,使用方法和各参数详解如下:
pandas.read_excel(io, sheet_name=0, header=0, index_col=None, names=None,dtype=None)

-
指定第一行数据为列名(也是默认情况)
df = pd.read_excel('pandas_data.xlsx',sheet_name='Sheet2', names=['班级','班主任','学生人数'])print(df) 班级 班主任 学生人数0 1 小红 401 2 小王 432 3 小明 453 4 小张 474 5 小李 505 6 小刘 436 7 小周 427 8 小陈 41-
指定班级列(第一列)为索引列
df = pd.read_excel('pandas_data.xlsx',sheet_name=1, names=['班级','班主任','学生人数'], index_col=0)print(df)输出:
班级 班主任 学生人数 1 小红 402 小王 433 小明 454 小张 475 小李 506 小刘 437 小周 428 小陈 41DataFrame.to_excel(excel_writer=None, sheet_name=None, na_rep='',float_format=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)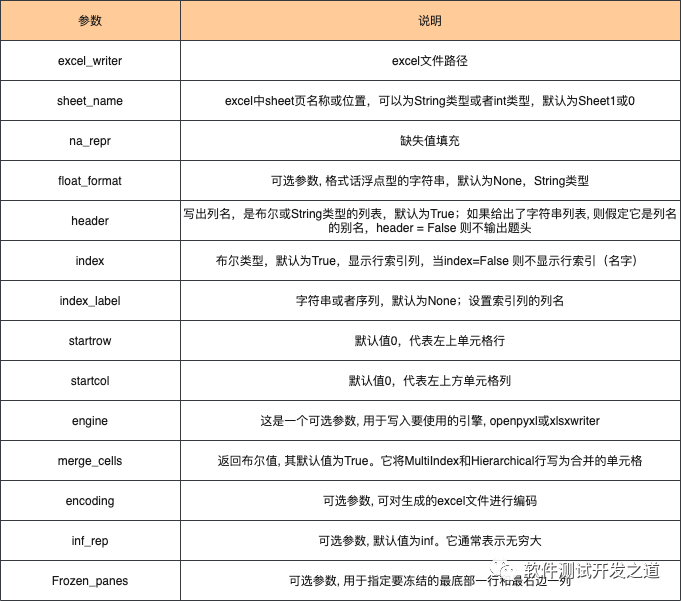
-
将自定义的数据写入指定的sheet页,显示索引
info = pd.DataFrame({ 'id': [1, 2, 3, 4, 5, 6], 'course': ['英语', '数学', '化学', '物理', '政治', '地理'], 'avg_score': [80, 90, 85, 91, 99,79], 'teacher': ['小红', '小王', '小明', '小张', '小李', '小刘']})info.to_excel('pandas_data.xlsx',sheet_name='成绩')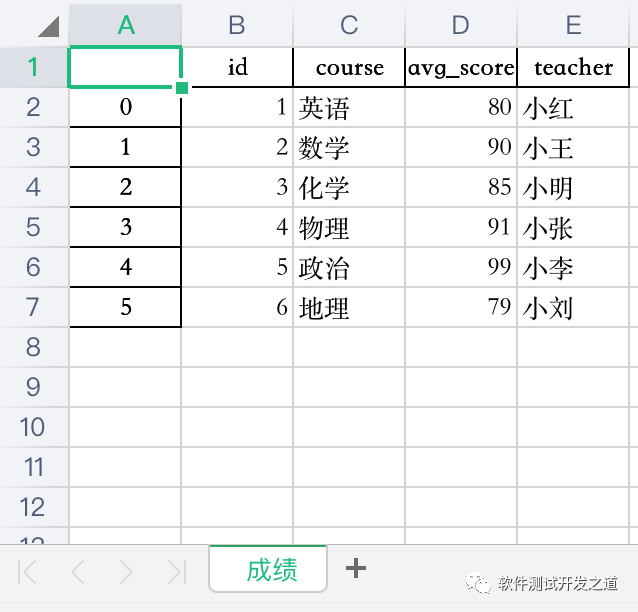
-
将自定义数据写入指定的sheet页,显示索引列为id列
info = pd.DataFrame({ 'id': [1, 2, 3, 4, 5, 6], 'course': ['英语', '数学', '化学', '物理', '政治', '地理'], 'avg_score': [80, 90, 85, 91, 99,79], 'teacher': ['小红', '小王', '小明', '小张', '小李', '小刘']})info.to_excel('pandas_data.xlsx',sheet_name='成绩',index_label='id')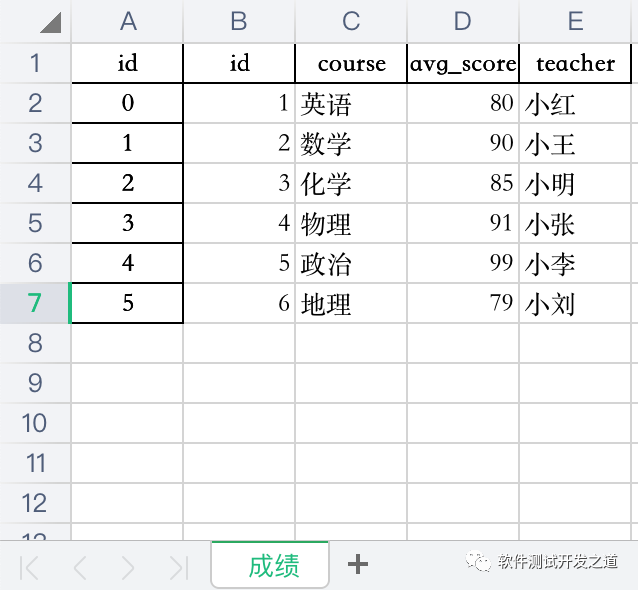
-
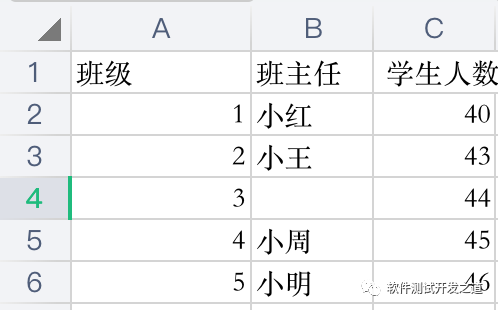
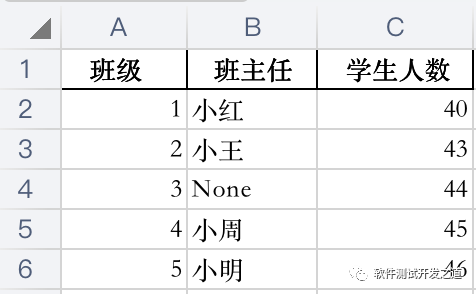
读取excel中的数据,写入指定文档的sheet页中,缺失值以"None"填充,不显示索引
info=pd.read_excel('demo.xlsx')info.to_excel('demo_1.xlsx',sheet_name='班级信息',na_rep='None',index=False)demo.xlsx数据 demo_1.xlsx数据:
1、读取csv文件数据
文件:
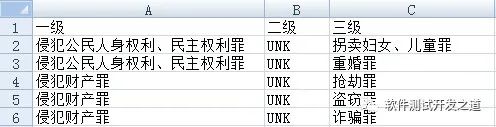
csv_data = pd.read_csv('./1111.csv',sep=',')print(csv_data) 一级,二级,三级0 侵犯公民人身权利、民主权利罪,UNK,拐卖妇女、儿童罪1 侵犯公民人身权利、民主权利罪,UNK,重婚罪2 侵犯财产罪,UNK,抢劫罪3 侵犯财产罪,UNK,盗窃罪4 侵犯财产罪,UNK,诈骗罪2、skiprows跳过显示某些行
-
skiprows为整数(表头算下标1)
csv_data = pd.read_csv('./1111.csv',sep=',',skiprows=1) # 不显示第一行print(csv_data) 侵犯公民人身权利、民主权利罪,UNK,拐卖妇女、儿童罪0 侵犯公民人身权利、民主权利罪,UNK,重婚罪1 侵犯财产罪,UNK,抢劫罪2 侵犯财产罪,UNK,盗窃罪3 侵犯财产罪,UNK,诈骗罪-
skiprows为列表(表头算下标0)
csv_data = pd.read_csv('./1111.csv',sep=',',skiprows=[1,2]) # 不显示第1、2行数据print(csv_data) 一级,二级,三级0 侵犯财产罪,UNK,抢劫罪1 侵犯财产罪,UNK,盗窃罪2 侵犯财产罪,UNK,诈骗罪-
skiprows为lambda表达式(不算默认的表头行)
# 显示偶数行csv_data = pd.read_csv('./1111.csv',sep=',',skiprows=lambda x:x%2 == 0)print(csv_data) 侵犯公民人身权利、民主权利罪,UNK,拐卖妇女、儿童罪0 侵犯财产罪,UNK,抢劫罪1 侵犯财产罪,UNK,诈骗罪3、skiprows与header的关系
先跳过skiprows行,再根据剩下的行确定表头行
csv_data = pd.read_csv('./1111.csv',sep=',',skiprows=1,header=1)print(csv_data) 侵犯公民人身权利、民主权利罪,UNK,重婚罪0 侵犯财产罪,UNK,抢劫罪1 侵犯财产罪,UNK,盗窃罪2 侵犯财产罪,UNK,诈骗罪3、无效值处理na_values
csv_data = pd.read_csv('./1111.csv',sep=',',na_values=['侵犯财产罪,UNK,诈骗罪'])print(csv_data) 一级,二级,三级0 侵犯公民人身权利、民主权利罪,UNK,拐卖妇女、儿童罪1 侵犯公民人身权利、民主权利罪,UNK,重婚罪2 侵犯财产罪,UNK,抢劫罪3 侵犯财产罪,UNK,盗窃罪4 NaN4、读取前n行数据nrows
csv_data = pd.read_csv('./1111.csv',sep=',',nrows=2)print(csv_data) 一级,二级,三级0 侵犯公民人身权利、民主权利罪,UNK,拐卖妇女、儿童罪1 侵犯公民人身权利、民主权利罪,UNK,重婚罪5、分块读取数据chunksize
csv_data = pd.read_csv('./1111.csv',sep=',',chunksize=2) # 将返回一个TextFileReader 对象迭代器for v in csv_data: print(v)6、写数据到csv文件
csv_data = pd.read_csv('./Book1.csv',sep=',',engine='python', encoding='gbk')print(csv_data)csv_data['其他']='暂无分类'print(csv_data)csv_data.to_csv('./2222.csv', sep=',', index=False,na_rep= 'NA',columns=['其他','日期','天气','地点'],encoding='gbk')注意:读取含有中文的csv文件时,需要加上 engine=‘python’和encoding信息,一般是utf-8或者gbk,都可以试一试
日期 天气 地点0 20200912 晴 南京1 20200812 多云 上海2 20200908 雨 深圳3 20200512 阴 山西4 20200602 多云 山东5 20200415 多云 南通6 20200504 晴 苏州 日期 天气 地点 其他0 20200912 晴 南京 暂无分类1 20200812 多云 上海 暂无分类2 20200908 雨 深圳 暂无分类3 20200512 阴 山西 暂无分类4 20200602 多云 山东 暂无分类5 20200415 多云 南通 暂无分类6 20200504 晴 苏州 暂无分类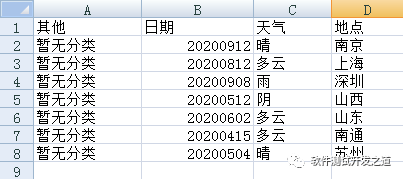

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)