python|机器学习的调参方式
1.各参数与交叉验证:(预备知识点)
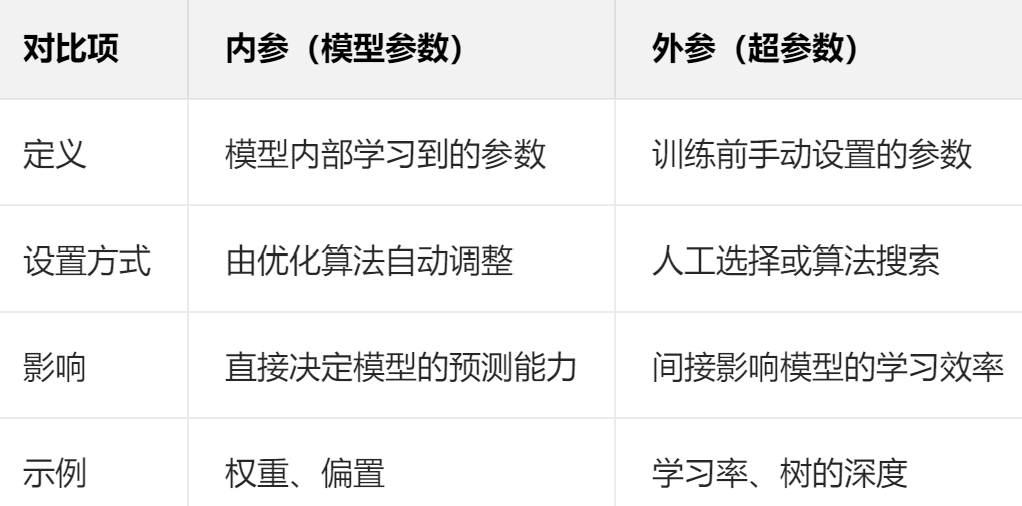
(1)内参和外参:
模型 = 算法 + 实例化设置的外参(超参数)+训练得到的内参
- 内参:
内参是模型在训练过程中自动学习到的参数,无需人工干预。如线性回归中的权重(w)和偏置(b):y = wx + b;神经网络中的神经元连接权重和偏置
- 外参:
外参是在模型训练前需要手动设置的参数,控制着模型的学习方式和复杂度。如学习率,决策树的最大深度。
(2)交叉验证:
交叉验证是一种评估模型泛化能力的统计方法,核心思想是将原始数据集分成多个子集,轮流作为训练集和验证集。
作用:
- 解决数据划分的随机性问题:传统的训练集 / 测试集划分方式可能会因为数据划分的随机性导致评估结果不稳定。
- 充分利用数据:在数据量有限的情况下,交叉验证可以更有效地利用所有数据进行模型评估。
- 防止过拟合:通过多次验证,更准确地评估模型在未知数据上的表现。
交叉验证方法:K 折交叉验证
将数据集分成 K 个子集,依次选择其中 1 个子集作为验证集,其余 K-1 个子集作为训练集。重复 K 次,最终得到 K 个模型性能评分,取平均值作为最终评估结果。
注:做交叉验证时一般要单独留出来测试集,K折交叉验证流程:先划分训练集和测试集,测试集单独存放,在整个模型训练和调参过程中绝对不能使用。对训练集做 K 折交叉验证:将训练集分成 K 个子集(比如 K=5),每次用 1 个子集当验证集,剩下的当训练集,重复 K 次,得到 K 个验证分数,取平均作为当前超参数的性能指标。通过这种方式比较不同超参数的验证分数,选择分数最高的超参数组合。用最优超参数重新训练模型:用全部训练集(不再拆分)重新训练一个模型(使用步骤 2 选好的超参数)。用测试集做最终评估:用这个最终模型在测试集上预测,得到的分数就是模型的最终泛化能力评估。
注:交叉验证与验证集 / 测试集的关系
- 不使用交叉验证时:
- 需要手动划分训练集、验证集和测试集。
- 训练集用于模型训练,验证集用于调整超参数,测试集用于最终评估。
- 使用交叉验证时:
- 可以省去专门的验证集,直接通过交叉验证在训练集上评估不同超参数组合的性能。
- 测试集仍需保留,用于最终的模型评估,确保评估结果的客观性。
2.调参前的准备工作:
(1)数据预处理
(2)划分训练集,验证集和测试集
划分为3块:(train+val+test)
# 划分训练集、验证集和测试集
# 这个函数只能划分一次,所以需要调用两次才能划分出训练集、验证集和测试集。
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:1:1划分训练集、验证集和测试集
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42)
# 80%训练集,20%临时集
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42) # 50%验证集,50%测试集划分为2块:(train+test)
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
注:很多调参函数自带交叉验证,甚至是必选的参数,因此大多数时候需要交叉验证,不需要划分验证集了。
(2)基准模型评估:
使用简单模型或默认参数的模型对数据进行训练和评估,得到一个基础性能指标(如准确率、误差值等)的过程。这个 “基准” 是后续所有模型优化的参考标准。
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里不需要验证集,不需要调参
import time
# time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))3.调参方法:
(1)网格搜索:(以随机森林为例)
通过穷举所有可能的参数组合来寻找最优模型配置的调参方法。它的核心思想简单直接:在预先定义好的参数空间中,尝试每一种参数组合,并通过交叉验证评估每种组合的性能,最终选择表现最优的参数。
工作原理:
- 定义参数网格:用户指定每个超参数的候选值,形成一个 “网格”。
- 穷举所有组合:系统地遍历参数网格中的每一种组合。
- 交叉验证评估:对每种组合,使用交叉验证(如 K 折)在训练集上评估模型性能。
- 选择最优参数:根据预设的评估指标(如准确率、F1 分数)选择最佳参数组合。
优缺点:
优:
- 全面性:确保探索了所有指定的参数组合。
- 简单易用:实现标准化,大多数机器学习库(如 scikit-learn)提供内置支持。
- 可复现性:结果完全取决于参数网格的定义,不受随机因素影响。
缺:
- 计算成本高:参数空间较大时(如每个参数有 10 个候选值,5 个参数就有 10⁵=10 万种组合),计算量呈指数级增长。
- 可能浪费资源:并非所有参数组合都值得尝试(如某些组合明显不合理)。
- 局部最优风险:若参数网格定义不当,可能错过全局最优解。
# 网格搜索优化随机森林
from sklearn.model_selection import GridSearchCV
# 定义要搜索的参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建网格搜索对象
grid_search = GridSearchCV(
estimator=RandomForestClassifier(random_state=42), # 随机森林分类器
param_grid=param_grid, # 参数网格
cv=5, # 5折交叉验证
n_jobs=-1, # 使用所有可用的CPU核心进行并行计算
scoring='accuracy' # 使用准确率作为评分标准
)
start_time = time.time()
# 在训练集上进行网格搜索
grid_search.fit(X_train, y_train)
# 在训练集上训练,模型实例化和训练的方法都被封装在这个网格搜索对象里了
end_time = time.time()
print(f"网格搜索耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", grid_search.best_params_) #best_params_属性返回最佳参数组合
# 使用最佳参数的模型进行预测
best_model = grid_search.best_estimator_ # 获取最佳模型
best_pred = best_model.predict(X_test) # 在测试集上进行预测
print("\n网格搜索优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("网格搜索优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))(2)贝叶斯优化:
贝叶斯优化是一种基于概率模型的参数搜索方法,它通过历史评估结果来预测哪些参数组合可能表现更好,从而避免像网格搜索那样盲目尝试所有组合。
特点:
-
高效利用计算资源:对于复杂模型(如神经网络)或大数据集,网格搜索的计算成本不可接受,而贝叶斯优化能用更少的迭代找到接近最优的参数。
-
自动探索与利用平衡:早期尝试不同区域(探索),后期聚焦于已知优解附近(利用),避免盲目搜索。
-
连续参数空间支持:可以直接处理连续参数(如学习率),无需离散化。
# 贝叶斯优化随机森林
from bayes_opt import BayesianOptimization
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
# 假设 X_train, y_train, X_test, y_test 已经定义好
# 定义目标函数,这里使用交叉验证来评估模型性能
def rf_eval(n_estimators, max_depth, min_samples_split, min_samples_leaf):
n_estimators = int(n_estimators)
max_depth = int(max_depth)
min_samples_split = int(min_samples_split)
min_samples_leaf = int(min_samples_leaf)
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
random_state=42
)
scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
return np.mean(scores)
# 定义要搜索的参数空间
pbounds_rf = {
'n_estimators': (50, 200),
'max_depth': (10, 30),
'min_samples_split': (2, 10),
'min_samples_leaf': (1, 4)
}
# 创建贝叶斯优化对象,设置 verbose=2 显示详细迭代信息
optimizer_rf = BayesianOptimization(
f=rf_eval, # 目标函数
pbounds=pbounds_rf, # 参数空间
random_state=42, # 随机种子
verbose=2 # 显示详细迭代信息
)
start_time = time.time()
# 开始贝叶斯优化
optimizer_rf.maximize(
init_points=5, # 初始随机采样点数
n_iter=32 # 迭代次数
)
end_time = time.time()
print(f"贝叶斯优化耗时: {end_time - start_time:.4f} 秒")
print("最佳参数: ", optimizer_rf.max['params'])
# 使用最佳参数的模型进行预测
best_params = optimizer_rf.max['params']
best_model = RandomForestClassifier(
n_estimators=int(best_params['n_estimators']),
max_depth=int(best_params['max_depth']),
min_samples_split=int(best_params['min_samples_split']),
min_samples_leaf=int(best_params['min_samples_leaf']),
random_state=42
)
best_model.fit(X_train, y_train)
best_pred = best_model.predict(X_test)
print("\n贝叶斯优化后的随机森林 在测试集上的分类报告:")
print(classification_report(y_test, best_pred))
print("贝叶斯优化后的随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, best_pred))注:网格搜索通常需要(如示例中的rf_eval),用于在每次迭代中评估参数性能并反馈给概率模型)。
(3)随机搜索:
需要定义参数的分布,而不是固定的列表。它不会尝试所有组合,而是在指定次数内随机采样。通常,用相对较少的迭代次数(如 50-100)就能找到相当好的参数。对于给定的计算预算,随机搜索通常比网格搜索更有效,尤其是在高维参数空间中。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)