【Cangjie】编程语言学习01——基础数据类型_B篇(万字长篇)
注:对于刚刚的一些术语,可以结合术语名和它的涵义去理解,如果理解不了就不要勉强。编程语言的学习是一件抽象而逻辑紧密的事,这样的事只能在不断的实践中逐渐去理解它,将其转化成自己抽象的认知。最忌死记硬背,强行理解,有话说:书读百遍,其意自现。只要在后面多做练习,你就能慢慢形成自己的抽象的认知。同时,对于一些重要的概念,我会在后续的文章中进行不断的强调,帮助理解。而且对于本章的内容,不需要强行理解和记背
注:本教程假定读者是0基础未接触过编程的小白,因此文章的编写会较为啰嗦。如果是有其他编程语言学习经验的,可直接看加粗字体的段落,那些内容基本是比较重要的,对于0基础的读者,一定按照我的建议读此文章,否则很容易刚开始就学不下去了。
(这里的有经验是指有过对某个编程语言有稍微深入的学习,比如认真学习过一本该编程语言的经典书籍,如c++的《C++ Primer》,笔者就花了5个月左右的时间,通读和学习了《C++ Primer》著作的内容)
全文都会带有笔者对仓颉语言的理解,帮助 0基础 的读者更好的理解和学习这门编程语言
一、引言
小明是一个小学生,他的三科成绩为78,92,78
如果我们要用仓颉语言编写一个程序把他的成绩打印出来,我们用打印"hello world"的代码来打印:
main() : Int64 {
println("小明的学习成绩为:78,92,78")
return 0
}运行结果如下(如果你的终端的输出是中文乱码,那么你可以百度一下,关键词为:VScode终端输出中文乱码):

如果我们要打印小明一整个班级的学习成绩,使用这个方法编写代码很明显费劲不讨好,而且一旦要打印另一个班级的成绩,就必须重新编写 n 行的println(.....)的代码,之前的代码就完全不可用了
编程语言给出的解决方法是:先把学生的名字和成绩使用变量存储起来,然后在程序运行时,调用这些变量。代码修改后如下;
main(): Int64 {
let name : String = "小明"
let grade_语文 : Int64 = 78
let grade_数学 : Int64 = 92
let grade_英语 : Int64 = 78
println("${name}的学习成绩为:${grade_语文},${grade_数学},${grade_英语}")
return 0
}运行结果如下:

对于打印一个班级的成绩,我们会在后续给出新的代码,我们先来简析代码
代码中的:name、grade_语文、grade_数学、grade_英语
对于这四个单词,我们称之为【变量(Variable)】,精准一些则称之为【对象(Object)】,'='操作符右边的我们称之为【变量的初始值(Initial Value)】。就是说这四个变量存储了它们等于号操作符右边的初始值。
程序员把它们看做成一个实体,因为它们存储了我们需要的数据
而 println(...) ,我们称之为【函数(Function)】,它能够完成复杂的工作,单一的功能
我们通过在 println 函数的括号内,使用了 【${}】的语法,打印了小明的名字和成绩
这样的代码就是通用的,无论想打印谁的成绩,只需改变 变量的初始值 即可(读者可以尝试打印小花的成绩92,78,89)(以上介绍到的知识点都会在后面的文章中进行解释)
二、变量的定义
注:对于刚刚的一些术语,可以结合术语名和它的涵义去理解,如果理解不了就不要勉强。编程语言的学习是一件抽象而逻辑紧密的事,这样的事只能在不断的实践中逐渐去理解它,将其转化成自己抽象的认知。最忌死记硬背,强行理解,有话说:书读百遍,其意自现。只要在后面多做练习,你就能慢慢形成自己的抽象的认知。同时,对于一些重要的概念,我会在后续的文章中进行不断的强调,帮助理解。而且对于本章的内容,不需要强行理解和记背,以后学得多了,这一章的内容就自然而然理解了,如果重看,或许还会有新的理解。
(一)语法
修饰符 变量名: 变量类型 = 初始值
let name : String = "小明"
a.修饰符:修饰符目前我们只需要学习 可变性修饰符 let 和 var 。
let 修饰不可变变量,var 修饰可变变量
使用let修饰的变量的值,一旦初始化就不可修改,var修饰的变量,初始化之后依然可以修改变量值
比如:
let name : String = "小明"
name = "小花"
上面的写法是错误的,如果你这么写,VScode的编辑器中,会高亮提示报错
var name : String = "小明"
name = "小花"
上面的写法是正确的,name的值已经被修改
读者可以自己在vscode 中对以上两种写法进行尝试b.变量名:程序员给变量命名,再通过名字引用变量
在仓颉中,可以给一些程序元素命名(如变量name,函数println),这些名字有一个专业术语——标识符。
标识符有两种——普通标识符 和 原始标识符(0基础暂时无需理会,应用场景太少了),普通标识符就足够应付绝大多数场景了。两种标识符都有自己的命名规则,本教程只讲普通标识符。
标识符的命名中能存在这几种字符:英文字母、下划线( _ )、数字(0...9)、包括中文等其他文字
有以下注意事项:标识符不能以数字开头、不能使用任何符合、不能与仓颉关键字一致、同一作用域内不可重名
只要符合规则,那么名字我们可以任意组合。下面是标识符的举例,对于后两点注意事项,后面章节说明:
合法:
abc
_abc
a_b_c
a1_b2_c3
仓颉
__こんにちは
非法:
1abc (数字开头)
abc$ (有其他符号 $ )c.变量类型:变量类型指定了变量所持有数据的类型
比如:变量name的String类型,它是字符串类型,用来存储字符数据;变量grade_语文 的 Int64 类型,用来存储整数数据
变量类型是本章节的主要内容,后续会做出更加详细的介绍
d.初始值:初始值就是创建变量时,赋予变量的意义。仓颉要求,任何变量在被引用前,都必须完成初始化,否则会编译错误。如下图:
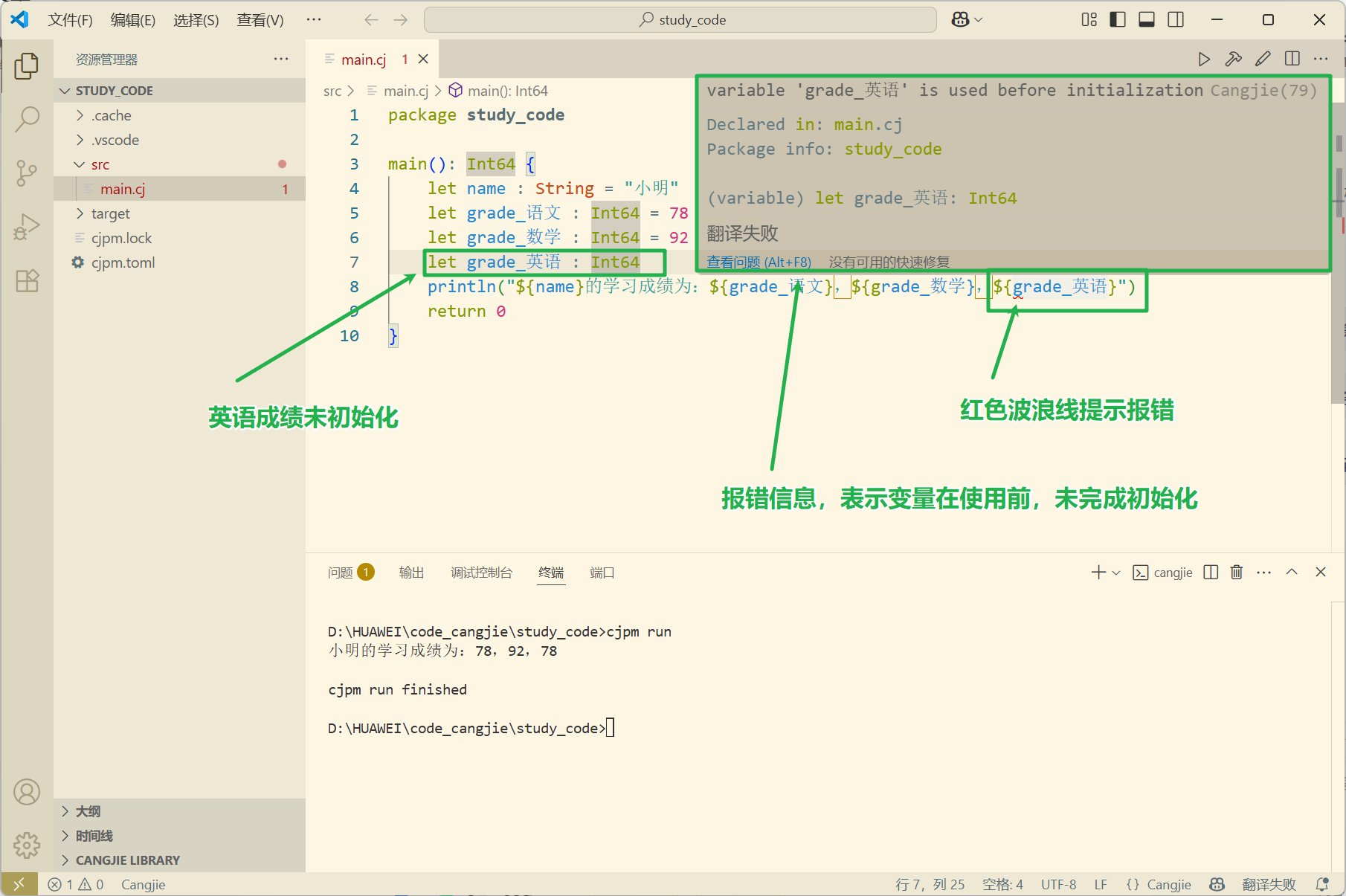
以上是仓颉中,定义一个变量的基础语法。不过这种语法有简略的方式,当变量的初始值有着明确的类型时,如果省略变量类型,仓颉会自动推断变量类型,如下代码:
let name = "小明"
let grade_语文 = 78以上两行代码都是合法且有效的,但是笔者还是建议0基础的读者,还是严格按照使用完整的语法定义变量,这或许有助理解其中一些概念。在有经验之后,再使用这种高级的语法。
笔者建议使用完整语法还有一个重要的原因,仓颉是一个强类型语言,它比普通的强类型语言要更加严格(笔者只系统学过C、C++、Java、Python,C++与Java就是其中严格的强类型语言)。
笔者会在后续举例。
(二)概念
想必在经过上述4点语法解释之后,读者已经对变量有了初步概念——变量就是用来存储数据的容器。(这个概念会有些抽象,要好好理解)
下面是笔者画的 变量生命周期 流程图:
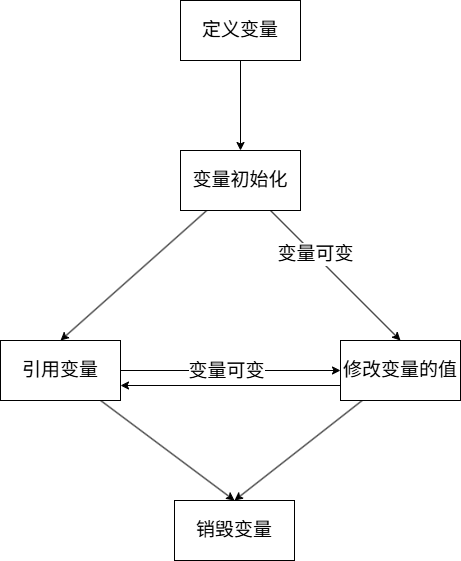
以上流程图只需了解,后续会介绍。
(三)注意事项
1. 任何定义的变量,都必须初始化(暂时先如此理解,后续章节可能会由此引出新的可争论问题)
2. 变量的命名要符合标识符的命名规则(虽然可以使用其他文字,但笔者还是强烈建议使用全英文字母命名)
3. 前期尽量显式指定变量类型
三、基础数据类型
终于到了本章节的主要内容了,接下来的内容重在了解,编写的代码量足够之后,本章节的内容自然而然就会记住,因此不需要费心费力做太多的笔记,值得注意的笔者都已标注出来了。
仓颉的基础数据类型较多,对于0基础而言,着重了解前五种数据类型,后五种数据类型可先略过或简单了解,笔者会在后续章节配合其他知识点引出。
(一)整数类型
整数类型分为有符号(signed)整数类型和无符号(unsigned)整数类型。
| 类型 | 表示范围 |
|---|---|
| Int8 |
−2^7∼2^7−1(−128∼127) |
| Int16 | −2^15∼2^15−1(−32,768∼32,767 |
| Int32 | −2^31∼2^31−1(−2,147,483,648∼2,147,483,647) |
| Int64 | −2^63∼2^63−1(−9,223,372,036,854,775,808∼9,223,372,036,854,775,807) |
| IntNative | platform dependent |
| UInt8 | 0∼2^8−1(0∼255) |
| UInt16 | 0∼2^16−1(0∼65,535) |
| UInt32 | 0∼2^32−1(0∼4,294,967,295) |
| UInt64 | 0∼2^64−1(0∼18,446,744,073,709,551,615) |
| UIntNative | platform dependent |
要理解这些符号的含义,我们需要理解计算机存储数据的编码格式——二进制的补码形式。(笔者在这里就不扩展了,不知道的读者就百度一下吧)
同时呢,又有规定 一个二进制位用计量单位 1bit 表示,1字节(B,Byte)大小表示 8bit,1024(2^10) 字节为 1KB
而 Int8 中的 '8' 就是表示 8bit,即一个字节,因此它能表示的范围为 -2^7 ~ 2^7-1,至于为什么不是 -2^7+1 ~ 2^7-1 ,这也是因为2的补码格式规定的,不知道可百度。
所以 Int8 占用1字节内存;Int16占用2字节内存;Int32占用4字节内存,由此类推。
这也引出一个问题,整数类型在初始化和赋值时,接受的值不能超过其能表示的范围,否则报错:
// 会引起编译器报错的代码 这能体现一点 仓颉语言的强类型性质
// 在这一点就比其它语言更严格,也更安全
let t : Int8 = 128仓颉推荐使用Int64,并且仓颉中整数类型字面量在没有类型上下文的情况下默认推断为 Int64 类型,可以避免不必要的类型转换。
而关于 IntNative 与 UIntNative 两个类型,据笔者推测,应该事关计算机可表示的字长。总之这两个类型应该是程序所在计算机处理效率最高的整数类型。
有一件非常重要的事,这些 【整数类型之间,互相无法直接转换】。这是与 C++、Java等语言的一大区别。
let x : UInt8 = 127
let y : Int8 = x // 报错
let z : Int32 = x // 报错1、整数类型字面量
类型字面量通俗解释 就是字符裸值,比如前面代码中,为两种类型初始化时,等号右边的裸值就是类型字面量。
整数类型字面量有 4 种进制表示形式:二进制(使用 0b 或 0B 前缀)、八进制(使用 0o 或 0O 前缀)、十进制(没有前缀)、十六进制(使用 0x 或 0X 前缀)。
在各进制表示中,可以使用下划线 _ 充当分隔符的作用(嵌入式包喜欢),方便识别数值的位数,如 0b0001_1000。
let x : UInt8 = 0b0000_0001
let y = 0o777
let z : Int32 = 0x0000_0001| 后缀 | 类型 | 后缀 | 类型 |
|---|---|---|---|
| i8 | Int8 | u8 | UInt8 |
| i16 | Int16 | u16 | UInt16 |
| i32 | Int32 | u32 | UInt32 |
| i64 | Int64 | u64 | UInt64 |
// x 被 仓颉推导为 Int64 类型,因为128也被推导为 Int64字面量
let x = 128
// y 是 Int32 类型
let y = 128i32
// z 是UInt8类型, 0~255
let z = 128u8在代码中的 "// x 被 仓颉推导为 Int64 类型,因为128也被推导为 Int64字面量" 这样的解释文字我们称之为注释,仓颉的注释语法是 "//" 以两个斜杠开头,后面的任何字符都是注释,不会影响到代码。
2、类型别名
类型别名相当于类型的小名,别名的数量没有限制。
| 类型别名 | 功能 |
|---|---|
| Byte | Byte 类型是内置类型 UInt8 的别名。 |
| Int | Int 类型是内置类型 Int64 的别名。 |
| UInt | UInt 类型是内置类型 UInt64 的别名。 |
3、字符字节字面量
仓颉编程语言支持字符字节字面量,以方便使用 ASCII 码表示 UInt8 类型的值。字符字节字面量由字符 b、一对标识首尾的单引号、以及一个 ASCII 字符组成。
关于 ASCII 码 可以百度一下,很容易能找到一个 ASCII码 表格。
var a = b'x' // a is 120 with type UInt8
var b = b'\n' // b is 10 with type UInt8
var c = b'\u{78}' // c is 120 with type UInt8
(二)浮点类型
浮点类型包括 Float16、 Float32 和 Float64,分别用于表示编码长度为 16-bit、 32-bit 和 64-bit 的浮点数(带小数部分的数字,如 3.14159、8.24 和 0.1 等)的类型。Float16、 Float32 和 Float64 分别对应 IEEE 754 中的半精度格式(即 binary16)、单精度格式(即 binary32)和双精度格式(即 binary64)。
Float64 的精度约为小数点后 15 位,Float32 的精度约为小数点后 6 位,Float16 的精度约为小数点后 3 位。
无要求情况下,首选 Float64 的浮点类型(因为它能表示更大的整数范围和更小的计算误差)。
1、浮点类型字面量
浮点类型字面量有两种进制表示形式:十进制、十六进制。
0基础了解十进制就行了(事实上一般情况下,十进制的浮点表示形式就已经够用了)。
- 在十进制表示中,一个浮点字面量至少要包含一个整数部分或一个小数部分,没有小数部分时必须包含指数部分(以
e或E为前缀,底数为 10)。 - 在十六进制表示中,一个浮点字面量除了至少要包含一个整数部分或小数部分(以
0x或0X为前缀),同时必须包含指数部分(以p或P为前缀,底数为 2)。
在使用十进制浮点数字面量时,可以通过加入后缀来明确浮点数字面量的类型,后缀与类型的对应为:
| 后缀 | 类型 |
|---|---|
| f16 | Float16 |
| f32 | Float32 |
| f64 | Float64 |
在无后缀情况下,浮点数字面量被自动推导为 Float64 浮点类型。
(三)布尔类型
布尔类型使用 Bool 表示,用来表示逻辑中的真和假。
1、布尔类型字面量
布尔类型只有两个字面量:true 和 false。
let a: Bool = true
let b: Bool = false
注意:在仓颉中,不以 非0值 和 0值 表示逻辑真假。所以下面的代码都是错的:
let a: Bool = 1 // 错误,类型不匹配
let b: Bool = 0 // 错误,类型不匹配(四)字符类型
字符类型使用 Rune 表示,可以表示 Unicode 字符集中的所有字符。
1、字符类型字面量
一个 Rune 字面量由字符 r 开头,后跟一个由一对单引号或双引号包含的字符。
- 单个字符
let a: Rune = r'a' let b: Rune = r"你" - 转义字符
转义字符由 反斜杠开始,后接一个字符或两位十六进制数字let newLine : Rune = r'\n' // 换行符 let tab : Rune = r'\t' // 制表符 let slash : Rune = r'\\' // 打印反斜杠 \关于转义字符可以用 print 函数打印,看看效果,如:
main() { let slash: Rune = r'\\' let newLine: Rune = r'\n' let tab: Rune = r'\t' let char_border = r'\'' // 转义单引号 print(char_border) print(newLine) print(char_border) // 通过查看两个单引号的打印位置,得知换行符的执行效果 }关于更多的转义字符,可以查看 ASCII码 表格。
-
通用字符
通用字符以\u开头,后面加上定义在一对花括号中的 1~8 个十六进制数,即可表示对应的 Unicode 值代表的字符。let he: Rune = r'\u{4f60}' // 你 let llo: Rune = r'\u{597d}' // 好
(五) 字符串类型
字符串类型使用 String 表示,用于表达文本数据,由一串 Unicode 字符组合而成。
如果0基础的读者不明白 Unicode 字符是什么,也可以自己百度,笔者不在这里赘述。
1、字符串字面量
- 单行字符串字面量的内容定义在一对单引号或一对双引号之内,引号中的内容可以是任意数量的任意字符。(除了用于定义字符串字面量的非转义的引号 和 单独出现的
\之外的)
let name : String = '小明'
let name2 : String = "\"小明\""
let s1 : String = "'" \\ 错误 引号需要转义
let s2 : String = "\" \\ 错误 单个反斜杠表示转义符号,后面应该接其它转义字符- 多行字符串字面量开头结尾需各存在三个双引号(
""")或三个单引号(''')。字面量的内容从开头的三个引号换行后的第一行开始,到遇到的第一个非转义的三个引号为止,之间的内容可以是任意数量的(除单独出现的\之外的)任意字符。let s1: String = """ """// 必须是 三个引号换行后的第一行 let s2 : String = ''' Hello, Cangjie Lang''' let s3 : String = ''' """ '''// 这样的多行字符串字面量可以通过编译并正常运行 let s4 : String = ''' \ '''// 错误,无转义字符 - 多行原始字符串字面量以一个或多个井号(
#)和一个单引号(')或双引号(")开头,后跟任意数量的合法字符,直到出现与字符串开头相同的引号和与字符串开头相同数量的井号为止。转义规则不适用于多行原始字符串字面量,字面量中的内容会维持原样。let s1: String = #""# let s2 = ##'\n'## // 原样打印 两个字符,而不是打印换行符 let s3 = ###" Hello, Cangjie Lang"###
2、“字符串字节字面量 ”
注意:字符串字节字面量 是笔者杜撰的名字,而不是仓颉官方给出的术语。
- 如果字符串字面量只有一个字符,且是一个表示 ASCII 字符中的一个,那么这个字符串字面量可以被强制转换为 Byte (内置类型
UInt8的别名)类型 - 如果字符串字面量是一个单字符的字符串字面量,那么可以被强制转换为 Rune 类型
// 以下四行代码军合法,并且字符串字面量被强制转换为等号左边变量的类型
var b : Byte = "0" // 内置类型 UInt8 的别名
var r : Rune = "0"
b = "1"
r = "你"值得注意的是,不管框住字符串的是 两个单引号('') 还是 两个双引号(""),不管它们里面有几个字符,它们都是字符串字面量, 字符字面量是由前缀 'r' 的,字符字节字面量的前缀是 'b',各位读者注意区分。这些细节必须要抠。
let a : Byte = b'0' // 字符字节字面量 ASCII 字符
let b : Rune = r'0' // 字符字面量 任意 Unicode 字符
let c : String = '0' // 字符串字面量3、插值字符串
记不记得在本章节的引言部分的代码中,使用 println 函数时就是用了 插值字符串 的语法。
插值字符串是一种包含一个或多个插值表达式的字符串字面量,通过将表达式插入到字符串中,可以有效避免字符串拼接的问题。
需要注意的是,这个语法 不适用于多行原始字符串字面量。
还有,关于表达式是仓颉语言中的一个极其重要的概念,理解好了这个概念,在学习其他语法时将如虎添翼,甚至可能会因为理解好了这个概念就轻易的吃透其他语法。不过这个概念笔者不打算在这里打开,笔者计划在后续的操作符章节中展开,并在往后不断强调。
语法:插值表达式必须用花括号 {} 包起来,并在 {} 之前加上 $ 前缀。
// 插值字符串是 ${name} 的结果 "小明" , name 是插值表达式
println("${name}的学习成绩为:${grade_语文},${grade_数学},${grade_英语}")也就是说,引用一个变量的语法就是一个 表达式。
下面五个基础类型 0基础 的读者,先了解类型的数据形式,就是主要了解它们的字面量格式,记得抽象理解,因为其中有的类型是抽象复杂类型,字符串类型是我们遇到的第一个抽象复杂类型(抽象复杂类型这个术语也是笔者编的,为了方便理解)。
(六)元组类型
元组(Tuple)可以将多个类型组合在一起,成为一个新的类型。
元组类型使用 (T1, T2, ..., TN) 表示,其中 T1 到 TN 可以是任意类型,类型间使用逗号(,)连接。
元组至少是二元的(元素的元)。
// 定义了一个元组类型的变量 可存放两个Int32,一个Int64 元素 未初始化
let tuple : (Int32, Int32, Int64) 注意:
- 元组的长度是固定的,即一旦定义了一个元组类型的实例,它的长度不能再被更改。
- 元组类型是不可变类型,即一旦定义了一个元组类型的实例,它的内容不能再被更新。
// 元组类型不受 可变性修饰符 影响
var tuple : (Bool, Bool) = (true, false)
tuple[0] = false // Error, 'tuple element' can not be assigned
1、元组类型字面量
元组类型的字面量使用 (e1, e2, ..., eN) 表示,其中 e1 到 eN 是表达式,多个表达式之间使用逗号分隔。
// 下面两行代码是完全合法的 即使 let 是不可变修饰符,仓颉要求变量至少要在变量被引用前完成初始化,否则编译报错
let t : (Int32, Int32)// 声明变量
t = (128, 127) // 初始化 变量(不过目前笔者还不明白,c变量是在第一行代码获取资源并创建变量,还是在第二行代码中获取资源完成创建。不过笔者推断应该是 第一行就创建出变量)
目前笔者建议声明时初始化,即两行代码合并到一起。
元组支持通过 t[index] 的方式访问某个具体位置的元素,其中 t 是一个元组,index 是下标,并且 index 只能是从 0 开始且小于元组元素个数的整数类型字面量,否则,编译报错。
let t : (Int32, Int32) = (128, 127)
println("t 元组的第一个元素 ${t[0]}\nt 元组的第二个元素 ${t[1]}")
// 其中用到了 转义字符 '\n'换行符, 插值字符串 ${} 其中 t[0]和t[1]都是插值表达式2、元组字面量的初始化
关于这一点 0基础 只看用法,先不看解释,等经验超过 2千 行代码时,再回来看解释,否则理解不了。贪多嚼不烂!
在赋值表达式中,可使用元组字面量对表达式的右值进行解构,这要求赋值表达式等号左边必须是一个元组字面量,这个元组字面量里面的元素必须都是左值或者一个元组字面量,等号右边的表达式也必须是 tuple 类型,右边 tuple 每个元素的类型必须是对应位置左值类型的子类型。
(左值的意思是可暂时理解为变量,右值可暂时理解为字面量。它们的区别是左值能保存值,并在下文继续引用,右值则是临时存在的,无法在下文引用)
利用这个性质能做到一次 初始化 或 赋值 多个变量,如下:
var a: Int64
var b: String
var c: Float64
((a, b), c) = ((2, "def"), 3.0)
// ((a, b), c) 组成了一个临时的元组字面量 可以把这个元组字面量赋值给一个元组
// 此时可以把 ((a, b), c) 的结果 ((2, "def"), 3.0) 理解为一个右值,因为在下文中无法再引用这个临时的元组字面量了
// 元组 ((a, b), c) 有两个元素:(a, b) 与 c
// (a, b) 又组成一个元组字面量, c 是一个左值
// (a, b) 元组字面量 有两个元素,且两个都是左值以上表达式的求值顺序上先计算等号右边表达式的值,再对左值部分从左往右逐个赋值。
当元组字面量中出现 _ 时,表示忽略等号右侧 tuple 对应位置处的求值结果(意味着这个位置处的类型检查总是可以通过的)。
var a: Int64
var b: String
((a, b), _) = ((2, "def"), 3.0) // value of a is 2, value of b is "def", 3.0 is ignored
3、元组类型的类型参数
可以为元组类型标记显式的类型参数名,但不影响对其中元素的访问方式。
let c: (name: String, grade : Int64) = ("banana", 5)
// 同样适用的场景
func getFruitPrice (): (name: String, price: Int64) {
return ("banana", 10)
}
无法通过类型参数名去访问或引用其中的元素(目前笔者未发现类型参数名的作用,似乎只能用作提醒,有点鸡肋)。
对于一个元组类型,只允许统一写类型参数名,或者统一不写类型参数名,不允许交替存在。
(七)数组类型
我们可以使用 Array 类型来构造单一元素类型,有序序列的数据(这里说的“有序”,指的是插入顺序)。
仓颉使用 Array<T> 来表示 Array 类型。T 表示 Array 的元素类型,T 可以是任意类型。
元素类型不相同的 Array 是不相同的类型,所以它们之间不可以互相赋值。
var a : Array<Int64> // Int64类型的有序序列
var b : Array<String> // String类型的有序序列
1、Array类型的初始化
- Array数组类型字面量
使用方括号将逗号分隔的值列表括起来 就是Array字面量
let a: Array<String> = [] // Created an empty Array whose element type is String
let b = [1, 2, 3, 3, 2, 1] // Created a Array whose element type is Int64, containing elements 1, 2, 3, 3, 2, 1
- 构造函数初始化(0基础直接了解用法,不需要理会解释)
使用构造函数的方式构造一个指定元素类型的 Array。
需要注意的是,当通过 item 指定的初始值初始化 Array 时,该构造函数不会拷贝 item,如果 item 是一个引用类型,构造后数组的每一个元素都将指向相同的引用。
关于“拷贝”、“引用类型”、“值类型”等概念,将在后续章节展开。
let a = Array<Int64>() // Created an empty Array whose element type is Int64
let b = Array<Int64>(a) // Use another Array to initialize b
let c = Array<Int64>(3, item: 0) // Created an Array whose element type is Int64, length is 3 and all elements are initialized as 0
let d = Array<Int64>(3, {i => i + 1}) // Created an Array whose element type is Int64, length is 3 and all elements are initialized by the initialization function
2、访问 Array 成员
Array 元素的访问同样使用 array[index] 的方式访问。即使用下标,非空 Array 的下标同样从 0 开始,到 数组的长度-1。
下标的类型必须是 Int64。
let arr = [7, 8, 9]
print(arr[0])
print(arr[1])
print(arr[2])当我们需要知道某个 Array 包含的元素个数时,可以使用 size 属性获得对应信息。
println(arr.size)如果我们想获取某一段 Array 的元素,可以在下标中传入 Range 类型的值,就可以一次性取得 Range 对应范围的一段 Array。
let arr1 = [0, 1, 2, 3, 4, 5, 6]
let arr2 = arr1[0..5] // arr2 contains the elements 0, 1, 2, 3, 4
当 Range 字面量在下标语法中使用时,我们可以省略 start 或 end。
当省略 start 时,Range 会从 0 开始;当省略 end 时,Range 的 end 会延续到最后一位。
let arr1 = [0, 1, 2, 3, 4, 5, 6]
let arr2 = arr1[..3] // arr2 contains elements 0, 1, 2
let arr3 = arr1[2..] // arr3 contains elements 2, 3, 4, 5, 6
3、修改 Array
Array 是一种长度不变的 Collection 类型,因此 Array 没有提供添加和删除元素的成员函数。
但是 Array 允许我们对其中的元素进行修改,同样使用下标语法。
可变性修饰符不修饰 Array 的元素。因此下面的代码都是合法的:
// 不可变修饰符
let arr1 : Array<Int64> = [0, 1, 2, 3, 4, 5]
arr1[0] = 3 // 代码合法
var arr2 : Array<Int64> = [0, 1, 2, 3, 4, 5]
arr2[0] = 3Array 是引用类型,因此 Array 在作为表达式使用时不会拷贝副本,同一个 Array 实例的所有引用都会共享同样的数据。
因此对 Array 元素的修改会影响到该实例的所有引用。
let arr1 = [0, 1, 2]
let arr2 = arr1
arr2[0] = 3
for (it in arr1){
print("${it}\t")
}
print("\n")4、VArray
VArray 可以先完全略过,后期可能还会有大的调整,使用 Array 就够了。
仓颉编程语言引入了值类型数组 VArray<T, $N> ,其中 T 表示该值类型数组的元素类型,$N 是一个固定的语法,通过 $ 加上一个 Int64 类型的数值字面量表示这个值类型数组的长度。
需要注意的是,VArray<T, $N> 不能省略 <T, $N>,且使用类型别名时,不允许拆分 VArray 关键字与其泛型参数。
类型别名 与 泛型参数 的概念在后续章节介绍。
let varr1 : VArray<Int64, $3> // Ok
let varr2 : VArray // Error注意:
由于运行时后端限制,当前 VArray<T, $N> 的元素类型 T 或 T 的成员不能包含引用类型、枚举类型、Lambda 表达式(CFunc 除外)以及未实例化的泛型类型。
VArray 有两个构造函数,一个 size 属性 和 []操作符(用于下标访问元素)
// VArray<T, $N>(initElement: (Int64) -> T)
let b = VArray<Int64, $5>({ i => i}) // [0, 1, 2, 3, 4]
// VArray<T, $N>(item!: T)
let c = VArray<Int64, $5>(item: 0) // [0, 0, 0, 0, 0]
println(c.size)
println(c[0])(八)区间类型 Range
告读者:这个类型真的只需要了解字面量即可,后续会用到字面量。
区间类型用于表示拥有固定步长的序列,区间类型是一个泛型,使用 Range<T> 表示。
T 表示元素类型,要求此类型必须支持关系操作符,并且可以和 Int64 类型的值做加法运算。
每个区间类型的实例都会包含 start、end 和 step 三个值。其中,start 和 end 分别表示序列的起始值和终止值,step 表示序列中前后两个元素之间的差值(即步长);start 和 end 的类型是 T,step 类型是 Int64,并且它的值不能等于 0。
// Range<T>(start: T, end: T, step: Int64, hasStart: Bool, hasEnd: Bool, isClosed: Bool)
let r1 = Range<Int64>(0, 10, 1, true, true, true) // r1 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
let r2 = Range<Int64>(0, 10, 1, true, true, false) // r2 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r3 = Range<Int64>(10, 0, -2, true, true, false) // r3 contains 10, 8, 6, 4, 2
1、区间类型字面量
区间字面量有两种形式:“左闭右开”区间和“左闭右闭”区间。
- “左闭右开”区间的格式是
start..end : step,它表示一个从start开始,以step为步长,到end(不包含end)为止的区间; - “左闭右闭”区间的格式是
start..=end : step,它表示一个从start开始,以step为步长,到end(包含end)为止的区间。
let n = 10
let r1 = 0..10 : 1 // r1 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r2 = 0..=n : 1 // r2 contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
let r3 = n..0 : -2 // r3 contains 10, 8, 6, 4, 2
let r4 = 10..=0 : -2 // r4 contains 10, 8, 6, 4, 2, 0
step 可缺省(即省略的意思),缺省时编译器默认 step 为 1 。同时注意,区间也有可能是空的(即不包含任何元素的空序列),举例如下:
let r5 = 0..10 // the step of r5 is 1, and it contains 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
let r6 = 0..10 : 0 // Error, step cannot be 0
let r7 = 10..0 : 1 // r7 to r10 are empty ranges
let r8 = 0..10 : -1
let r9 = 10..=0 : 1
let r10 = 0..=10 : -1
注意,只要 step 的符号 和 end与start 的 差值 的符号不一致,就是空区间。
比如: r7 中的 end - start = 0 - 10 = -10 符号为 '-' (即负号),step 为 1 符号为 '+'(即正号),因此 r7 是空区间。
注意:有基础的读者可能会认为区间类型的原理,是像在一个数组里存储了这样 n 个的值,这样理解是不对的。毕竟区间类型有 start、end、step三个变量,只要指出想要第几个数,通过等差数列的公式就能计算出来了。因此在抽象理解 区间类型 时,不要建立了错误的理解。
(九)Unit 类型
对于那些只关心副作用而不关心值的表达式,它们的类型是 Unit。
Unit 类型只有一个值,也是它的字面量:()。除了赋值、判等和判不等外,Unit 类型不支持其他操作。
0 基础 只要知道 Unit类型的字面量 为 () 即可,下面的概念以后会强调。
关于副作用这个抽象的概念,可以尝试从下面的例子来理解:
等号操作符 '=' 的 主要作用是 对两边的表达式求值,而它的副作用则是 将等号操作符右边表达式的值,赋值到左边的表达式(必须是左值)。
后续可能还会强调,理解不了也没关系,经验上来了就会懂了,慢慢领悟吧。
(十)Nothing 类型
Nothing 是一种特殊的类型,它不包含任何值,并且 Nothing 类型是所有类型的子类型。
0 基础看到这就行了。
break、continue、return 和 throw 表达式的类型是 Nothing,程序执行到这些表达式时,它们之后的代码将不会被执行。其中 break、continue 只能在循环体中使用,return 只能在函数体中使用。
包围着的循环体“无法穿越”函数边界。
while (true) {
func f() {
break // Error, break must be used directly inside a loop
}
let g = { =>
continue // Error, continue must be used directly inside a loop
}
}
注意:
目前编译器还不允许在使用类型的地方显式地使用 Nothing 类型。
到这里仓颉的十个基础数据类型就讲完了,其中包含内置类型 5个,内置类型就是指 是编程语言本身预先定义好的数据类型,无需额外导入或声明即可直接使用,它们是构成程序数据结构的基础。你也可以把 内置类型理解为 英文的 26个字母。内置类型表格如下:
内置类型
| 内置类型名 | 功能 |
|---|---|
| Int8 | 表示 8 位有符号整型,表示范围为 [-2^7, 2^7 - 1]。 |
| Int16 | 表示 16 位有符号整型,表示范围为 [-2^{15}, 2^{15} - 1]。 |
| Int32 | 表示 32 位有符号整型,表示范围为 [-2^{31}, 2^{31} - 1]。 |
| Int64 | 表示 64 位有符号整型,表示范围为 [-2^{63}, 2^{63} - 1]。 |
| IntNative | 表示平台相关的有符号整型,其长度与当前系统的位宽一致。 |
| UInt8 | 表示 8 位无符号整型,表示范围为 [0 ~ 2^8 - 1]。 |
| UInt16 | 表示 16 位无符号整型,表示范围为 [0 ~ 2^{16} - 1]。 |
| UInt32 | 表示 32 位无符号整型,表示范围为 [0 ~ 2^{32} - 1]。 |
| UInt64 | 表示 64 位无符号整型,表示范围为 [0 ~ 2^{64} - 1]。 |
| UIntNative | 表示平台相关的无符号整型,其长度与当前系统的位宽一致。 |
| Float16 | 表示 16 位浮点数,符合 IEEE 754 中的半精度格式(binary16)。 |
| Float32 | 表示 32 位浮点数,符合 IEEE 754 中的单精度格式(binary32)。 |
| Float64 | 表示 64 位浮点数,符合 IEEE 754 中的双精度格式(binary64)。 |
| Bool | 表示布尔类型,有 true 和 false 两种取值。 |
| Rune | 表示 unicode 字符集中的字符。 |
| Unit | 表示仓颉语言中只关心副作用而不关心值的表达式的类型。 |
| CPointer<T> | 表示 T 类型实例的指针,在与 C 语言互操作的场景下使用,对应 C 语言的 T*。 |
| CString | 表示 C 风格字符串,在与 C 语言互操作的场景下使用。 |
总结
本章节的内容主要是 基础数据类型。
对于 0基础的读者来说,主要先理解以下几部分内容:
- 变量的定义
- 常用的内置类型 与 整数类型的 Int64、浮点数类型的 Float64,
若有足够的精力 字符串类型 与 数组类型 也可做一些练习
本章节的内容很多,也很枯燥,记不下来没关系,以后的练习多了就自然而然记住了,而且以后也肯定会需要重读本篇文章的。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)