yolov8训练数据集报错(内存不足问题)
yolov8训练数据集出现内存大小不足报错现象的处理方案
1.OSError: [WinError 1455] 页面文件太小,无法完成操作
参考文章:OSError: [WinError 1455] 页面文件太小,无法完成操作_页面文件太小,无法完成操作。 (os error 1455)-CSDN博客
此处选择修改参数:
1. 降低batch_size参数(在train.py中修改--batch-size值)
2. 降低workers参数(在train.py中修改--workers值)
3. 添加内存优化参数:
torch.backends.cudnn.benchmark = True # 添加在模型初始化前
torch.cuda.empty_cache() # 每个epoch结束后调用
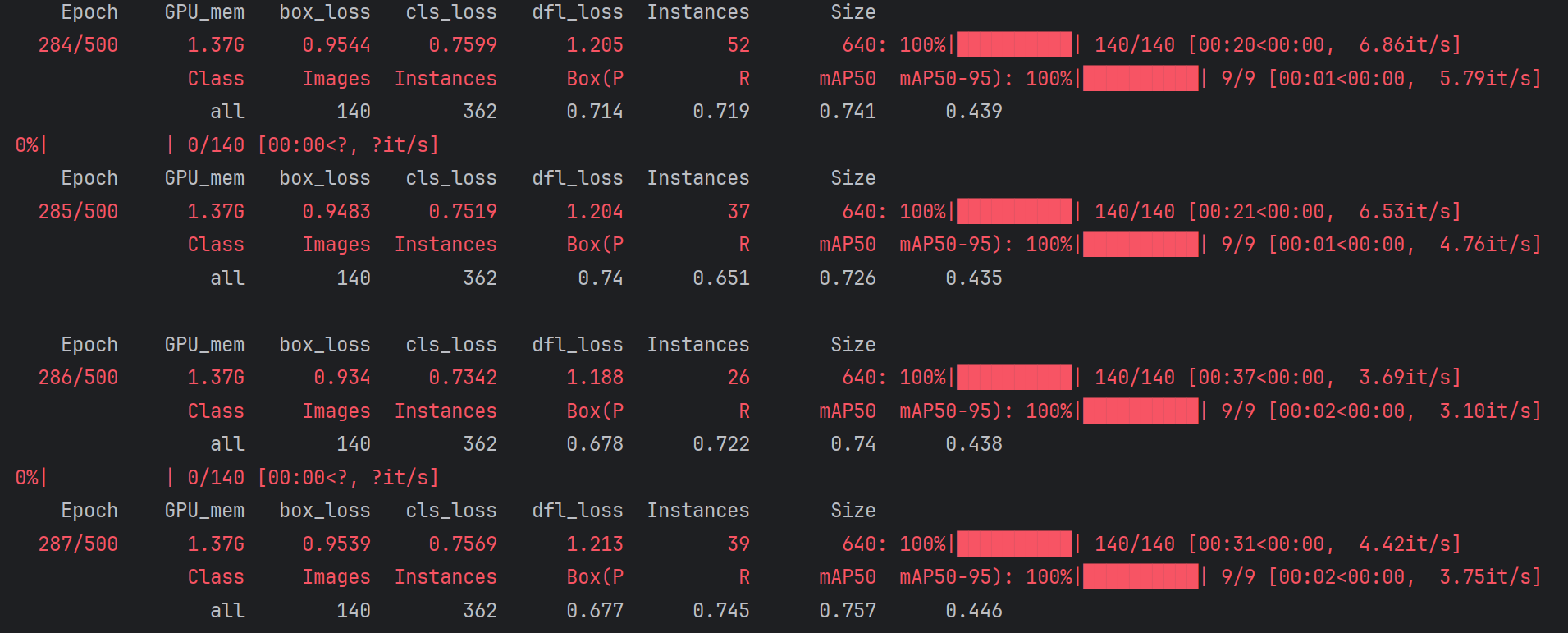
2. RuntimeError: DataLoader worker (pid(s) 16904) exited unexpectedly
错误分析
1. OpenMP 错误
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
这个错误表明程序中存在多个 OpenMP 运行时被链接到同一个进程中,这会导致冲突。OpenMP 是一个并行计算库,用于加速程序运行。当多个库(如 Intel MKL 或其他优化库)同时使用 OpenMP 时,可能会导致冲突。
解决方案:
-
设置环境变量:在运行脚本之前,设置环境变量
KMP_DUPLICATE_LIB_OK=TRUE。这可以允许程序继续执行,但请注意,这可能会导致程序崩溃或产生不正确的结果set KMP_DUPLICATE_LIB_OK=TRUE -
检查依赖项:使用工具(如
conda list或pip list)检查环境中是否有多个库同时使用了 OpenMP。如果有,请尝试重新安装这些库的动态链接版本conda list pip list -
更新环境:更新你的 Python 环境和相关依赖项,确保所有库都是最新版本
conda update --all pip install --upgrade pip pip install --upgrade ultralytics
2. DataLoader 工作进程意外退出
RuntimeError: DataLoader worker (pid(s) 16904) exited unexpectedly
这个错误表明 DataLoader 的工作进程在运行时意外退出。这通常是由于以下原因之一:
-
数据集问题:数据集中的某些文件可能损坏或格式不正确。
-
内存不足:工作进程可能因为内存不足而崩溃。
-
多线程问题:工作进程可能因为多线程问题而崩溃。
解决方案:
-
减少工作线程数:减少
workers参数的值,以减少并发任务数量。例如,将workers设置为 2 或 1results = model.train(data="train.yaml", epochs=500, imgsz=640, batch=8, workers=2) -
检查数据集:确保数据集中的所有图片和标签文件都是完整且格式正确的。可以编写一个简单的脚本来检查数据集的完整性
import os images_dir = "D:\\*****\\train\\images" labels_dir = "D:\\******\\train\\labels" for filename in os.listdir(images_dir): if not filename.endswith(".jpg"): continue image_path = os.path.join(images_dir, filename) label_path = os.path.join(labels_dir, filename.replace(".jpg", ".txt")) if not os.path.exists(label_path): print(f"Missing label for image: {image_path}") -
增加内存:如果可能,增加系统的物理内存或虚拟内存(页面文件)。
-
调试 DataLoader:在 DataLoader 中启用调试模式,以获取更多关于错误的信息
from torch.utils.data import DataLoader DataLoader(..., num_workers=0, pin_memory=False)
总结
通过上述步骤,你应该能够解决 OpenMP 错误和 DataLoader 工作进程意外退出的问题。如果问题仍然存在,建议在干净的环境中重新安装所有依赖项,并确保环境配置正确。
注:此处我是因为内存大小不够,报错终端,于是选择从中断的地方继续运行,相关代码如下:
# 五、训练意外终止之后继续训练(断点训练)
# 如果你的训练意外终止,想从终止的地方继续开始训练,你可以修改train.py文件或者直接创建新的文件,这里演示直接创建新的文件resume.py,内容如下:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/detect/train14/weights/last.pt') # 这里用你训练终止前保存的最近的一次模型,这个你应该很容易找到
# 继续训练
results = model.train(resume=True)
(比较省事的方法就是直接改内存大小,但是个人感觉不是很保险,就修改了代码每次训练的数据量并更新代码在内存告罄的时候接上继续训练了,看个人想法)
3、全部训练完成后再次运行代码:
得到报错:
AssertionError: runs\detect\train14\weights\last.pt training to 500 epochs is finished, nothing to resume.
Start a new training without resuming, i.e. 'yolo train model=runs\detect\train14\weights\last.pt'
1. 已完成训练的权重文件
AssertionError: runs\detect\train14\weights\last.pt training to 500 epochs is finished, nothing to resume.
Start a new training without resuming, i.e. 'yolo train model=runs\detect\train14\weights\last.pt'这个错误表明你尝试从一个已完成训练的模型权重文件(last.pt)恢复训练,但该文件已经完成了训练计划(即已达 500 个 epoch)。因此,程序无法继续恢复训练,因为没有更多的 epoch 可以继续训练。
解决方法
1. 开始新的训练
如果你需要继续基于上次训练的结果进行新的训练,可以使用以下方法:
-
方法一:直接使用
last.pt文件作为预训练模型,但不使用resume参数results = model.train(data="train.yaml", epochs=500, imgsz=640, batch=8, workers=4, pretrained="runs/detect/train14/weights/last.pt")这样,程序会将
last.pt作为预训练模型,从头开始新的训练计划。 -
方法二:如果需要继续从上次训练的中断点开始,但训练计划尚未完成,确保
last.pt文件确实包含未完成的训练状态。
2. 检查训练配置
仔细检查你的训练脚本和配置文件,确保训练目标和方式正确无误:
-
如果你确实希望恢复训练,确保
resume参数正确引用了未完成的权重文件。 -
如果你想要开始新的训练,确保不使用
resume参数,而是直接指定预训练模型。
总结
这个错误的核心在于你的 last.pt 文件已经完成了训练计划,程序无法从已完成的训练状态继续恢复。根据你的需求,选择合适的方法来继续训练或开始新的训练计划即可。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)