目标检测算法——YOLOv1
一、YOLOv1概述
在YOLOv1提出之前,R-CNN系列算法在目标检测领域中独占鳌头。R-CNN系列检测精度高,但是由于其网络结构是双阶段(two-stage)的特点,使得它的检测速度不能满足实时性,饱受诟病。为了打破这一僵局,涉及一种速度更快的目标检测器是大势所趋。
2016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once(也就是我们常说的YOLO的全称),并将该成果发表在了CVPR2016上,从而引起了广泛地关注。
YOLOv1 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box 的位置和 bounding box 所属的类别。简单来说,只看一次就知道图中物体的类别和位置。
二、 预备知识补充
Bounding Boxes(边界框)
在计算机视觉、图像处理等领域,bounding boxes(边界框) 是一种用于定位和标记图像或视频中目标对象的矩形框。它通过坐标信息来定义目标在画面中的位置和范围,是目标检测、目标跟踪等任务的基础工具。
边界框的评估指标
为衡量边界框预测的准确性(如模型预测框与人工标注的真实框的匹配程度),常用交并比(IoU, Intersection over Union):
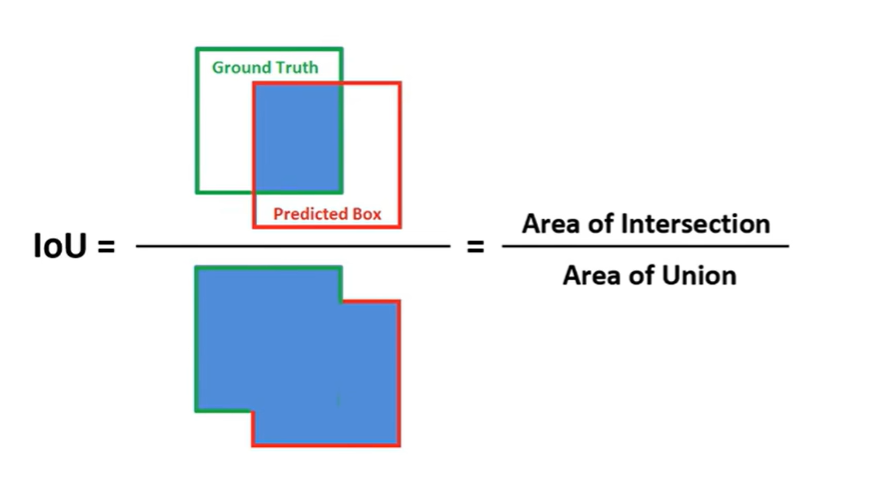
- 计算公式:
IoU = (预测框与真实框的交集面积) / (预测框与真实框的并集面积) - 取值范围:0~1,越接近 1 表示预测越准确。
- 实际应用中,通常设定 IoU 阈值(如 0.5),超过阈值则认为检测有效。
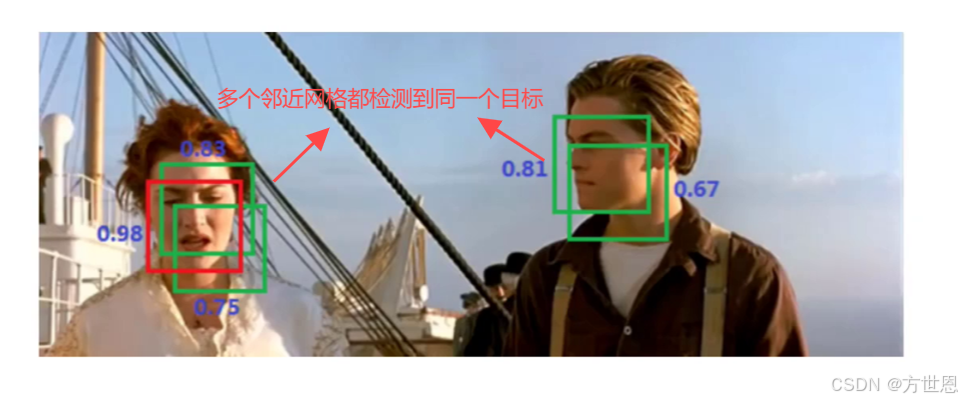
NMS非极大值抑制
NMS的主要目的是解决目标检测过程中出现的重复检测问题。在目标检测任务中,算法可能会预测出多个重叠或相似的边界框(bounding boxes),这些边界框可能指向同一个目标。NMS通过筛选局部极大值,找到最优的边界框,并抑制其他冗余的边界框。
三、模型结构及关键问题
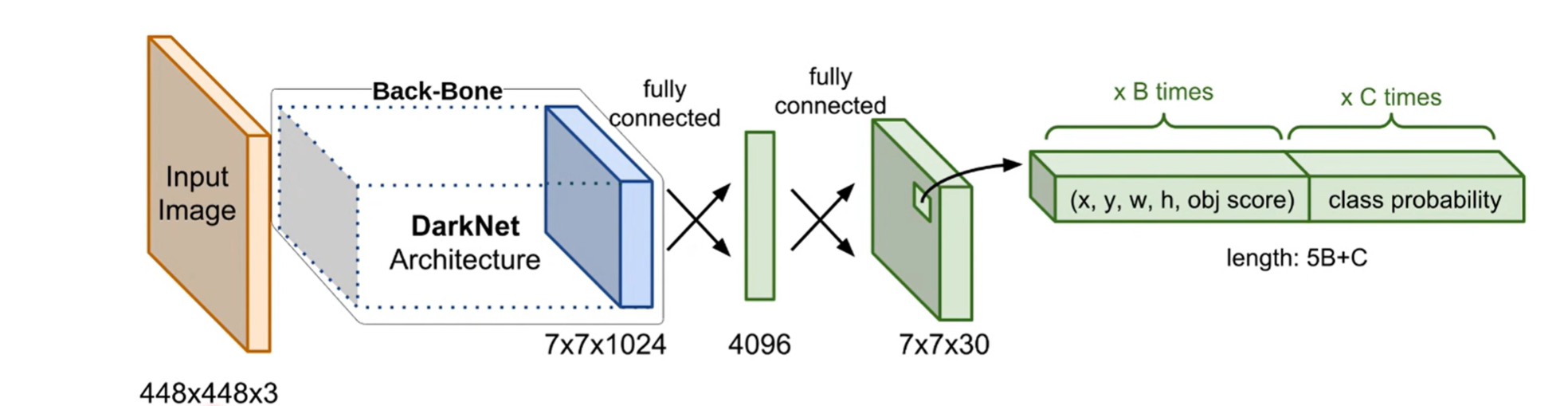
- 那理解YOLO这个算法,最重要的就是理解这个7*7*30的tensor。这里面的一个难点就是很多人,他会把这个tensor在训练阶段和推理阶段的用法混为一谈,所以导致大家不能够真实地理解YOLO这个算法的工作原理。因此我们在学习YOLO的时候,最重要的就是理解这个7*7*30的tensor在训练阶段和推理阶段分别起着什么样的作用。
- 首先是在训练阶段,我们要理解的核心问题是这个7*7*30的tensor作为网络的输出,此时这个输出的目的是通过和输入图像的标签建立联系,也就是通过损失函数计算损失,来优化网络的权重,从而使得预测能够更加接近真实的标签。
- 而在推理阶段,我们要关注的重点是这个7*7*30的tensor是如何表示输出的边界框和类别的。因为在推理阶段,我们希望网络的输出就是一个一个效果很好的边界框,同时这个边界框带有框内物体的类别信息。
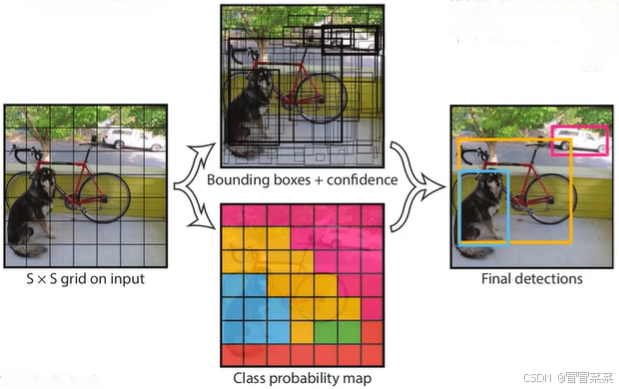
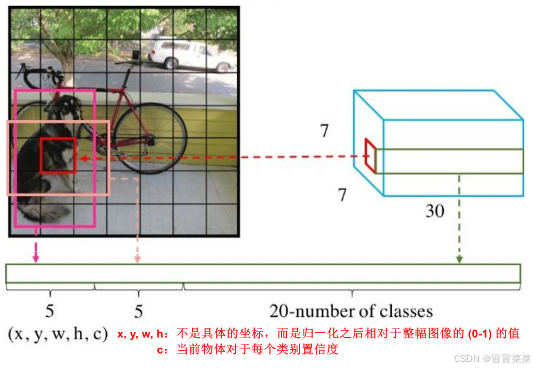
- 将一幅图像分成 SxS 个网格(grid cell),YOLOv1这个算法是7,也就是我们会分成7乘7的网格。如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object。一个格子只能预测一个物体,会生成两个预测框。
- 每个网格有固定的 B 个 bounding box是因为在训练的时候会在线地计算每个 predictor 预测的 bounding box 和 ground truth 的 IOU,计算出来的 IOU 大的那个 predictor,就会负责预测这个物体,另外一个则不预测。这么做有什么好处?我的理解是,这样做的话,实际上有两个 predictor 来一起进行预测,然后网络会在线选择预测得好的那个 predictor(也就是 IOU 大)来进行预测。
- 每个网格要预测 B 个bounding box(B一般取2),每个 bounding box 除了要回归自身的位置之外,还要附带预测一个 confidence 值。每个 bounding box 共 5 个参数 ( x , y , w , h , c ) 。
- 使用 ( x , y )表示 bounding box 中心相对于方格左上角的偏移量,范围为 [0,1](x,y是物体的中心点相对于网络的坐标)。
- 使用 ( w , h ) 表示 bounding box 的宽和高,该值是相对于图像宽高的比,范围为 [0,1](w和h是物体的边界框的宽度和高度)。


- confidence 代表了所预测的 box 中含有 object 的置信度(有则为 1,没有则为 0)和这个 box 预测的有多准两重信息,其值是这样计算的:
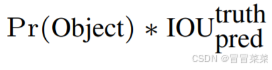
- 该表达式含义:如果有 object 的中心落在一个 grid cell(网格) 里,则第一项取 1,否则取 0。 第二项是预测的预测框(predict box)与真实标签框(ground truth)之间的交并比(IOU)值(详情请看预备知识补充)。
四、算法流程
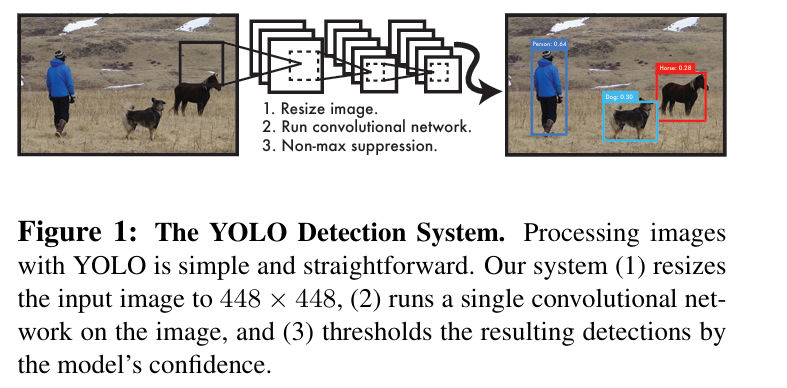
整个 YOLO 检测系统如下图所示:
- 假设网络实现的预测类别数为 C 个。论文中使用 PASCAL VOC 数据集,C=20,即实现 20 类别物品的目标检测。
- 输入图像首先被 resize 到指定尺寸。论文中将输入图像统一调整到 448 × 448 ,即网络输入:448 × 448 × 3 。
- 对图像进行划分,共划分 S × S个方格。论文中 S=7, 即共划分 7 × 7 = 49 个方格,每个方格包含 64 × 64个像素点。
- 针对每个方格:生成 C 个类别目标的概率分数(表示该方格是否存在该目标的概率),用 p 表示;生成 B 个检测框,每个检测框共 5 个参数,即 ( x , y , w , h , c )。
- 每个方格输出向量如下图所示。因此针对每个方格,共有参数量为(C+B×5) 个。本论文中,即 ( 20 + 2 × 5 ) = 30个。

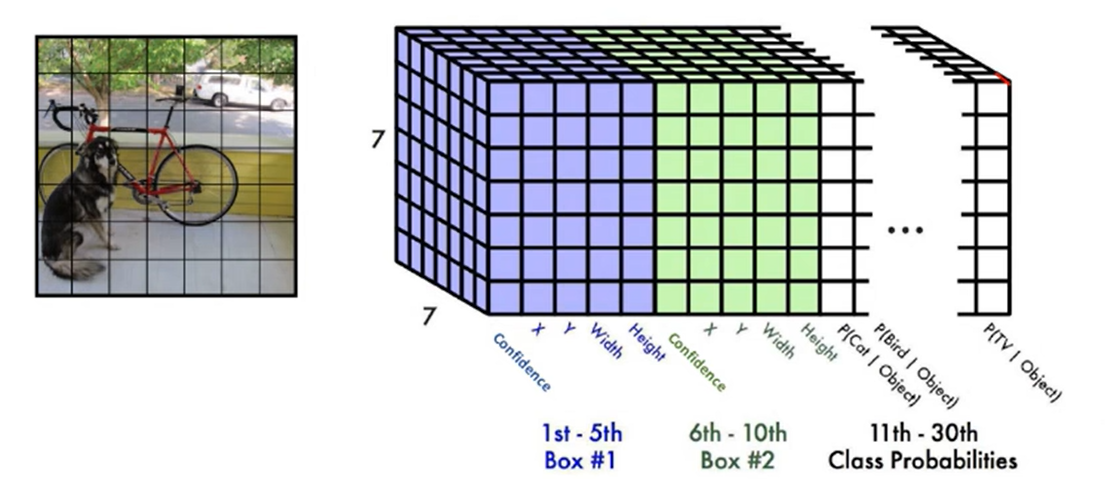
- 针对一张图片,最终输出向量:S × S × ( C + B × 5 )。本论文中即 7 × 7 × 30 = 1470。
- 对输出向量进行后处理,得到最终预测结果。

- 输入图像:448×448 的图像经卷积神经网络(CNN)处理,得到 7×7×30 的输出。
- 训练阶段:
- 每个grid cell(网格)生成两个bounding boxes(边界框),一共98 个bounding boxes(边界框)(7×7×2 )。
- 真实标签中心落在一个grid cell(网格)内,且该网格单元就负责拟合边界框。意思就是此网格通过前向传播生成的两个边界框中,我们选择与真实值IoU(交并比)最大的那个边界框,然后通过计算预测的边界框和真实值之间的损失,通过反向传播来修正网络的参数。
- 如果一个网格单元不包含目标中心,则将其视为背景,仅对置信度损失产生影响 。

- 推理阶段:
- 预测 98 个边界框(7×7×2 )。
- 应用非极大值抑制(NMS),基于交并比(IoU)阈值去除冗余边界框。
- 应用 NMS 后,依据最高类别得分选择最终边界框 。
五、损失函数
1. 损失即计算网络输出值(或预测值)与标签值差异的程度。举例说明,如上图的包含狗狗的方格,对应的标签值与预测值形式如下:

2. YOLOv1 中损失函数共包含三项,即:(1) 坐标预测损失、(2) 置信度预测损失、(3) 类别预测损失。三个损失函数都使用了均方误差。计算公式如下所示:
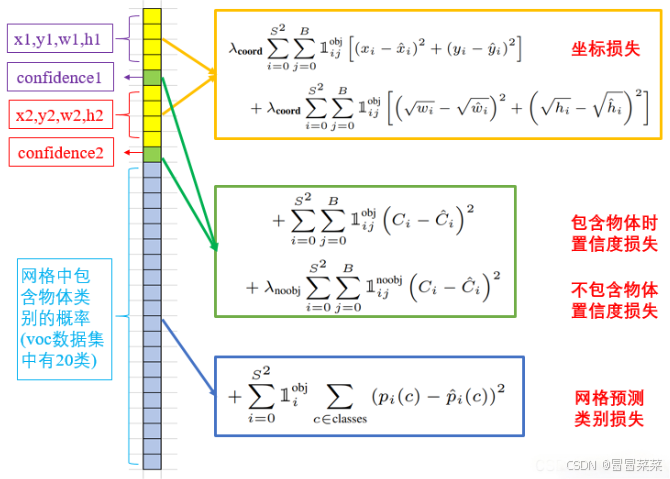
- 使用的是差方和误差。需要注意的是,w和h在进行误差计算的时候取得是它们的平方根,原因是对不同大小的bounding box预测中,大框和小框的 bounding box 和 ground truth 都是差了一点,但对于实际预测来讲,大框(大目标)差的这一点也许没啥事儿,而小框(小目标)差的这一点可能就会导致bounding box的方框和目标差了很远。而如果还是使用第一项那样直接算平方和误差,就相当于把大框和小框一视同仁了,这样显然不合理。而如果使用开根号处理,就会一定程度上改善这一问题 。
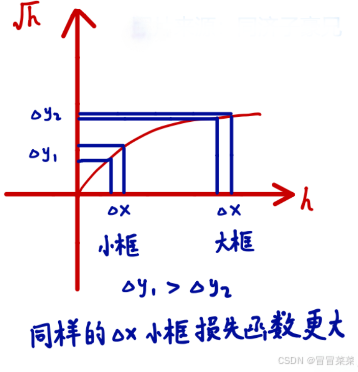
(此图取至冒冒菜菜,看完后举播有种醍醐灌顶的感觉)
- 定位误差比分类误差更大,所以增加对定位误差的惩罚,使
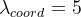 。
。 - 在每个图像中,许多网格单元不包含任何目标值。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使
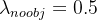 。
。
六、总结
YOLOv1 开创性地将目标检测重构为单阶段回归问题(7×7 网格 + 30 维张量输出),以 45 FPS 的实时速度颠覆传统两阶段检测(速度快),其全局推理显著降低背景误检;然而,网格空间约束(每格仅 2 框 1 类别)导致小物体漏检率高(不太适用于小物体),直接回归机制与低分辨率特征(7×7)造成定位偏差,且末端全连接层(超 4000 万参数)严重限制泛化性——这些缺陷为后续 YOLO 系列的进化指明方向,奠定了实时检测的基石。
b站上我觉得这个视频对7×7 网格 + 30 维张量输出的作用讲的较为清楚,大家可以去看看。
【全网最清楚的YOLO V1原理讲解,打牢YOLO目标检测算法基础!】https://www.bilibili.com/video/BV1gKwAeWEo4?p=6&vd_source=e114821e9fc8f0ea2830325b9b282d22

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)