书生·浦语全链条开源开放体系(第二课笔记)
介绍了InternLM预训练模型和基于书生·浦语大语言模型开发的视觉·语言大模型。还有可将大模型部署为智能体的lagent框架。本节课的demo也是围绕智能体和图文创作展开的。首先介绍了什么是大模型——人工智能领域中参数数量巨大、拥有庞大计算能力和参数规模的模型,简单来说就是“大”。第二节课主要介绍了InternLM大模型和一些大模型的趣味Demo。3.模型在各种任务中展现出惊人的性能,也可以说是
·
 第二节课主要介绍了InternLM大模型和一些大模型的趣味Demo
第二节课主要介绍了InternLM大模型和一些大模型的趣味Demo

首先介绍了什么是大模型——人工智能领域中参数数量巨大、拥有庞大计算能力和参数规模的模型,简单来说就是“大”。
那大模型有三个比较共性的特点:
1.利用大量数据进行训练
2.拥有数十亿甚至数千亿个参数
3.模型在各种任务中展现出惊人的性能,也可以说是拥有较强的泛化性

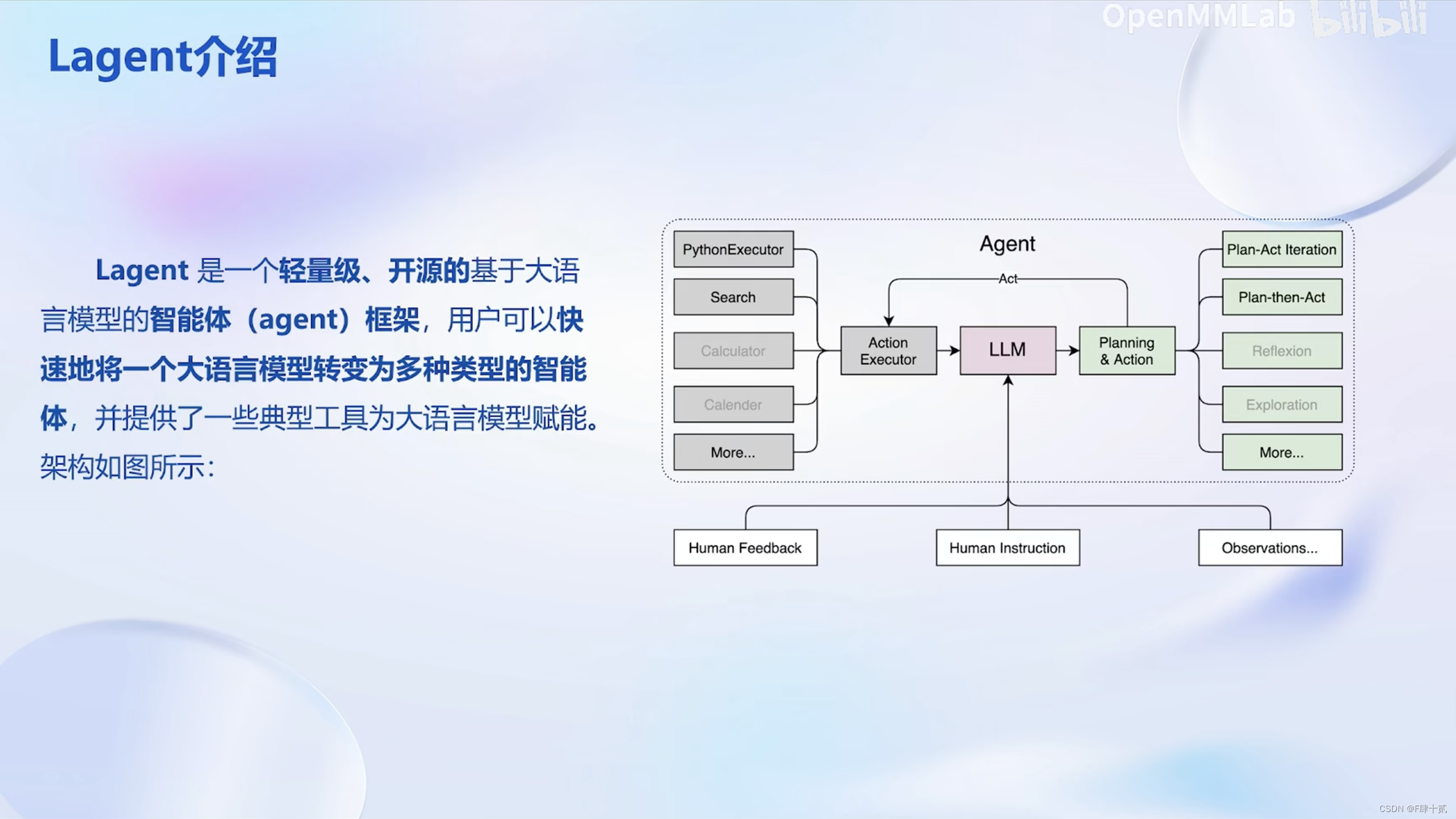
介绍了InternLM预训练模型和基于书生·浦语大语言模型开发的视觉·语言大模型。还有可将大模型部署为智能体的lagent框架。本节课的demo也是围绕智能体和图文创作展开的。
InternLM模型介绍

lagent框架介绍
浦语·灵笔图文创作理解demof

接下来就是一些流程的演示。
第二节课作业
基础作业:
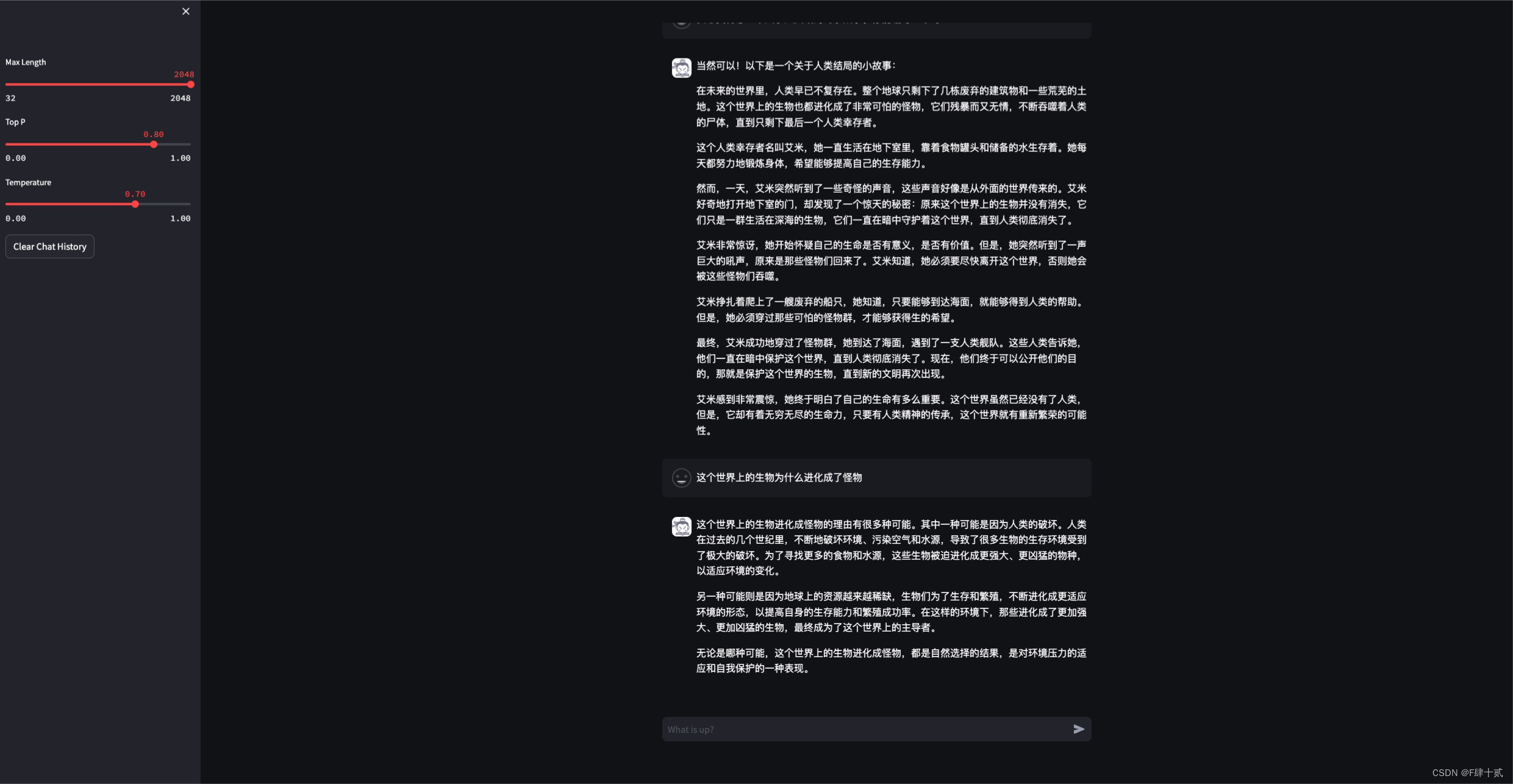
- 使用 InternLM-Chat-7B 模型生成 300 字的小故事(需截图)。
- 熟悉 hugging face 下载功能,使用
huggingface_hubpython 包,下载InternLM-20B的 config.json 文件到本地(需截图下载过程)。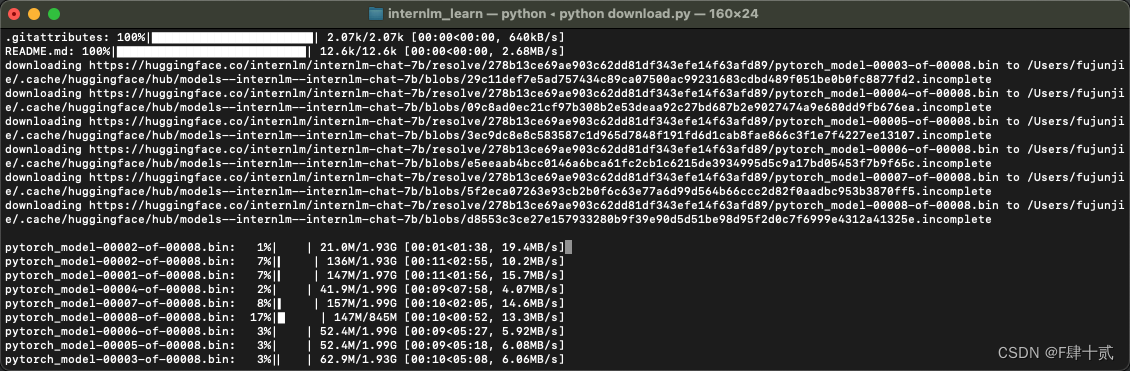
进阶作业(可选做)
- 完成浦语·灵笔的图文理解及创作部署(需截图)
- 多模态对话
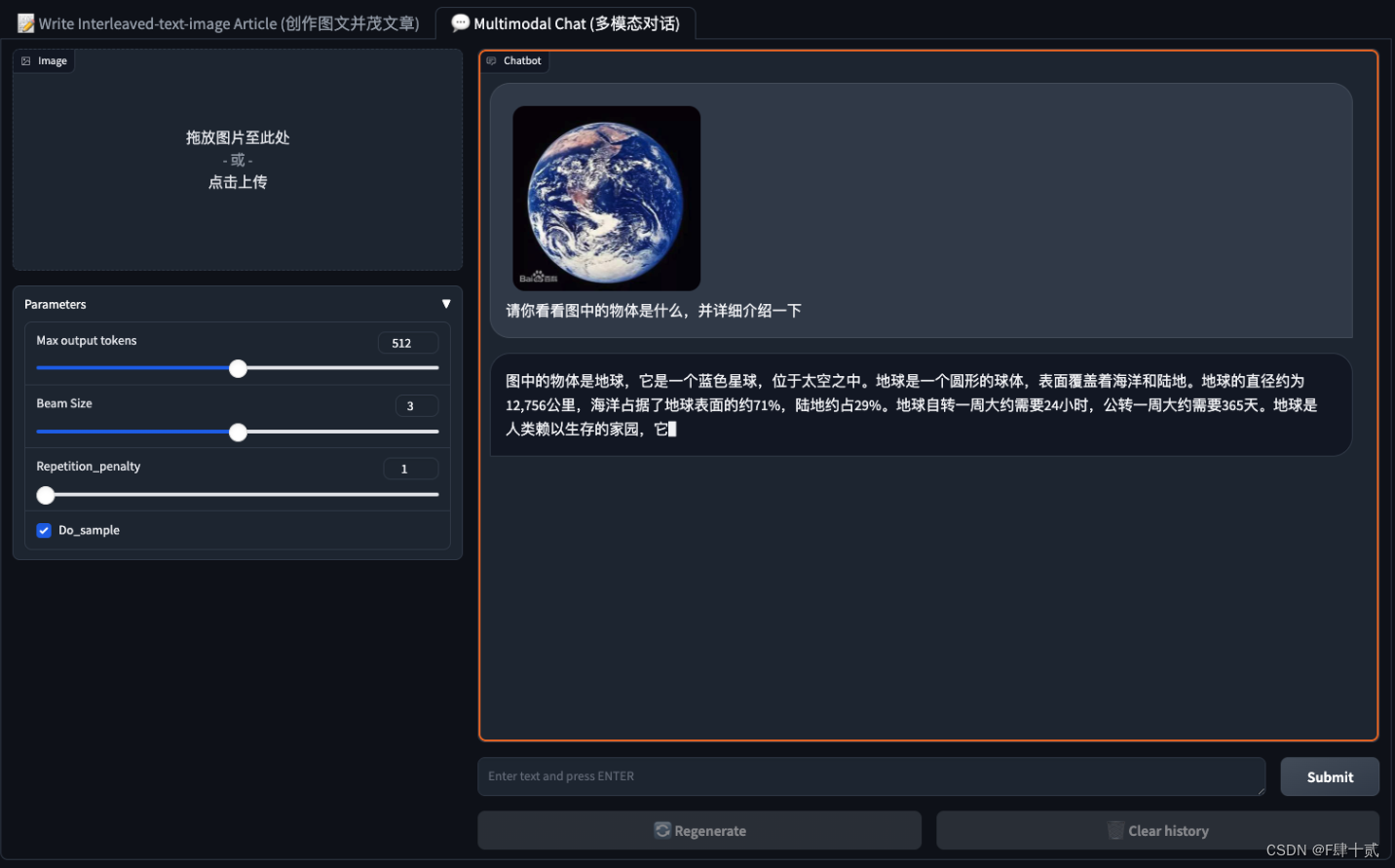
- 图文创作(不知道是否是网络原因一直没有输出结果)
- 多模态对话
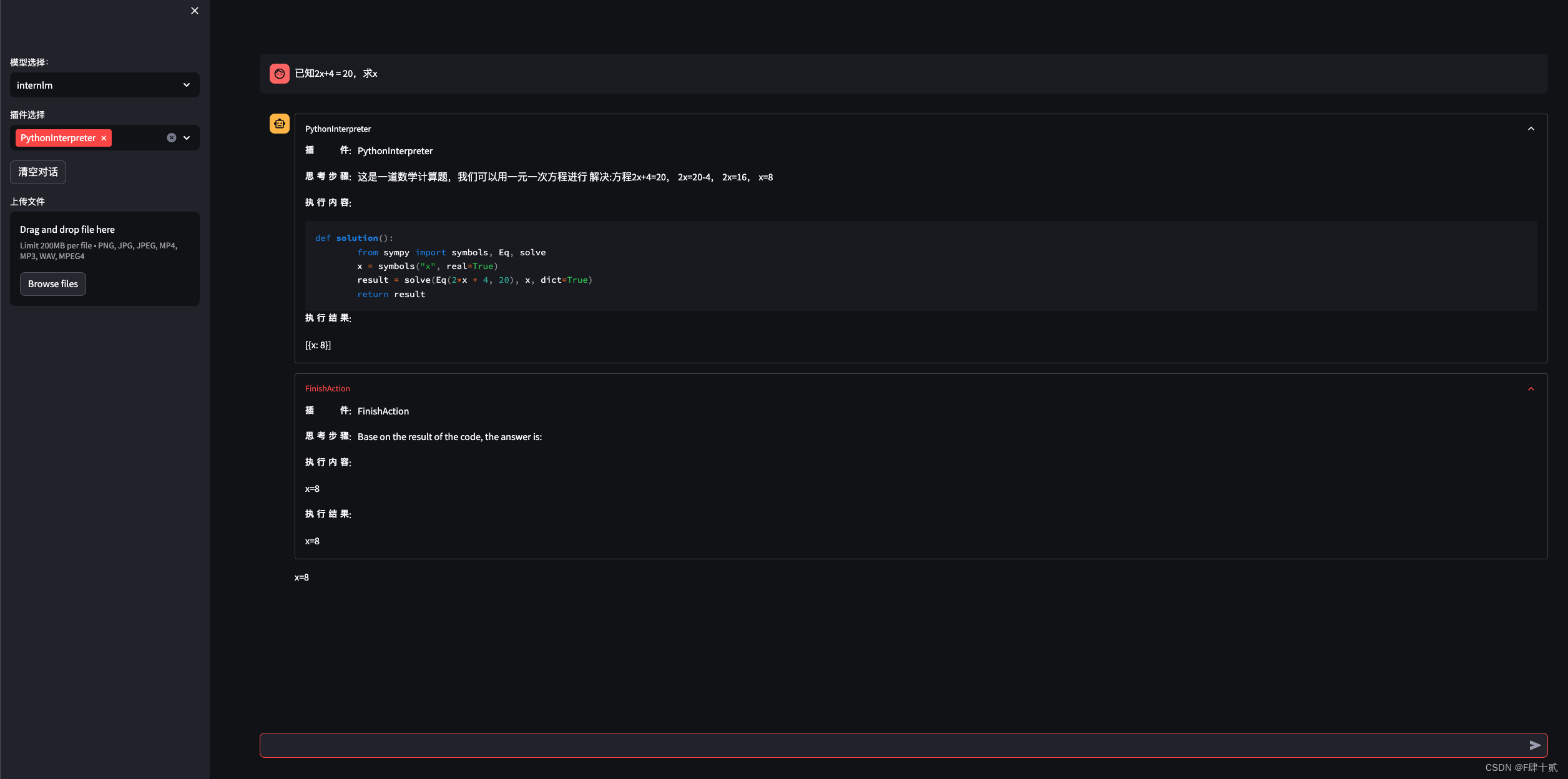
- 完成 Lagent 工具调用 Demo 创作部署(需截图)

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)