Hadoop入门学习(三)——MapReduce 分布式计算框架
MapReduce 提供了两个编程接口:Map 和 ReduceMap接口:提供了“分散”的功能,由服务器分布式对数据对数据进行处理。Reduce接口:提供了“汇总”的功能,将分布式的处理结果汇总统计。用户可以通过Java、Python等编程语言,实现MapReduce功能接口,即可使用MapReduce 框架完成自定义需求程序开发。通常MapReduce是基于YARN运行的。
一、MapReduce 概述
MapReduce 提供了两个编程接口:Map 和 Reduce
Map接口:提供了“分散”的功能,由服务器分布式对数据对数据进行处理。
Reduce接口:提供了“汇总”的功能,将分布式的处理结果汇总统计。
用户可以通过Java、Python等编程语言,实现MapReduce功能接口,即可使用MapReduce 框架完成自定义需求程序开发。
通常MapReduce是基于YARN运行的。
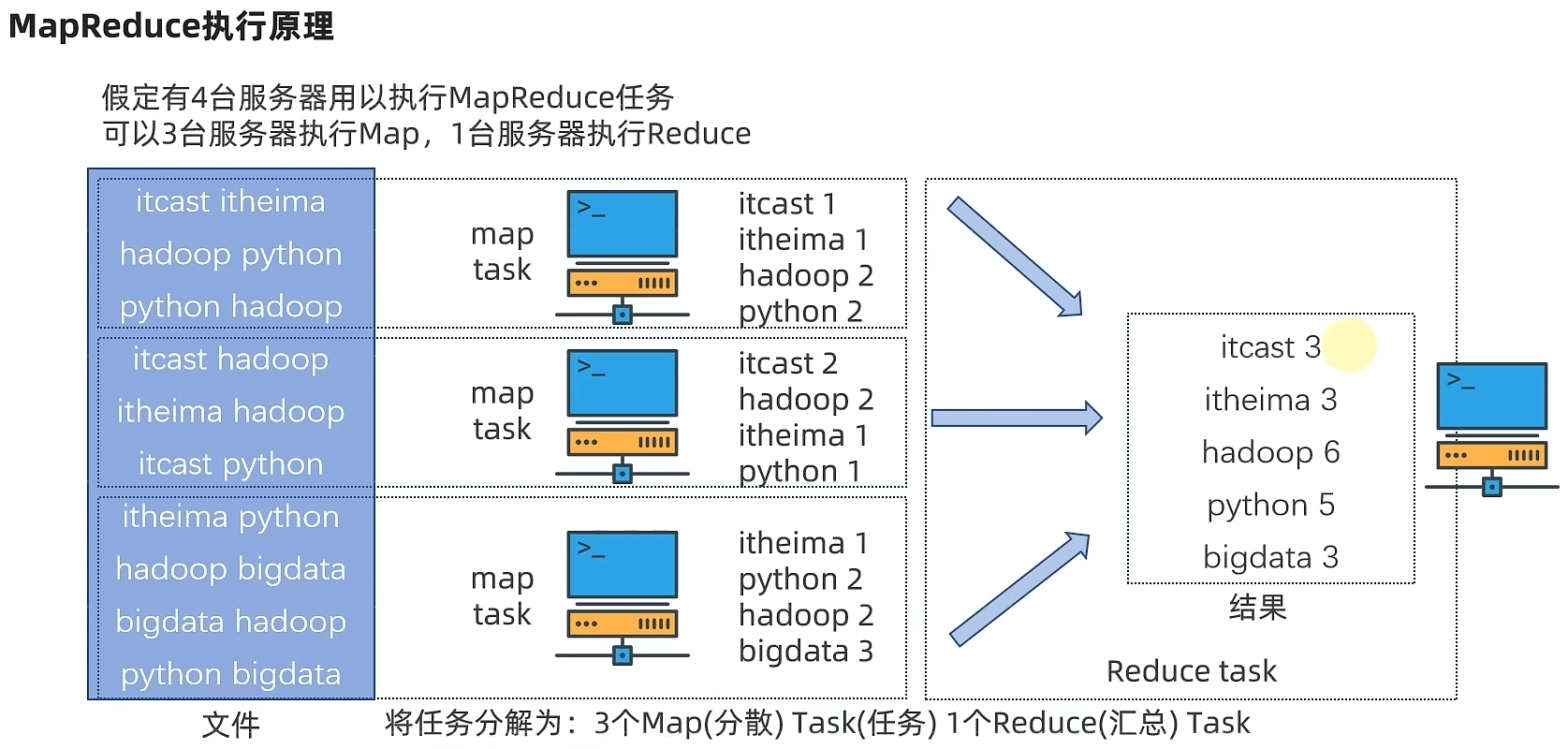
MapReduce的运行机制:将要执行的需求,分解为多个Map Task和Reduce Task,然后将Map Task和 Reduce Task分配到对应的服务器去执行。
MapReduce优点:
1、易于编程。用户只关心,业务逻辑。实现框架的接口。
2、良好扩展性。可以动态增加服务器,解决计算资源不够问题
3、高容错性。任何一台机器挂掉,可以将任务转移到其他节点
4、适合海量数据计算(TB/PB) 几千台服务器共同计算。
MapReduce 缺点:
1、不擅长实时计算。 Mysql
2、不擅长流式计算。Sparkstreaming flink.
3、不擅长DAG有向无环图计算。spark
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
二、MapReduce 框架的运行配置
MapReduce 运行在YARN容器内,无需启动独立进程,只需修改相应的配置文件即可。

MapReduce配置文件修改好后,需要分发到其他服务器节点中
三、提交 MapReduce 测试任务到 Yarn 执行
Hadoop官方内置了一些预置的MapReduce程序代码,我们无需编程,只需要通过命令即可使用。




四、Hadoop常用数据序列化类型

五、MapReduce编程规范(代码示例为wordcount)
用户编写的程序分成三个部分:Mapper、Reducer和 Driver。
5.1 Mapper 阶段
(1)用户自定义的Mapper要继承自己的父类Mapper
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中(重写父类的map方法)
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)(K是偏移量)
假设输入数据为:

则在map方法的(K= “0”,V = “atguigu atguigu”)(K= “17”,V = “ss ss”)...
第二次K= “17”是因为第一行(atguigu atguigu)的长度为16(包含中间空格和最后的回车、换行符)
(5)map()方法(MapTask进程)对每一个<K,V>调用一次

map方法处理后,输出数据(atguigu 1)(atguigu 1)(ss 1)(ss 1)...
经过Shuffle阶段处理后,数据转为如下格式:(atguigu [1,1]),(banzhang [1]),(cls [1,1])...
以上数据作为输入传入Reducer阶段
5.2 Reducer 阶段
(1)用户自定义的Reducer要继承自己的父类Reducer
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer中的业务逻辑写reduce()方法中(重写父类的reduce方法)
(4)ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法

经过reduce方法后,最后的输出数据如下:

5.3 Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象

六、MapReduce序列化


6.1 序列化学习案例
需求介绍:

(1)创建Bean对象实现Writable接口,重写序列化和反序列化方法

(2)编写mapper程序(输出的K是手机号,V是Bean对象,其属性为想要的数据)
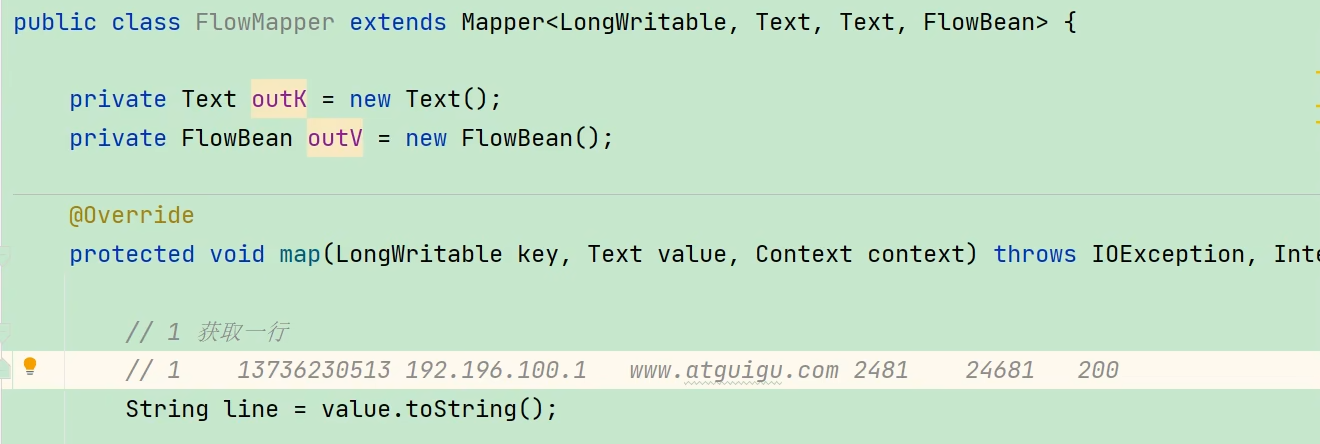
(3)编写reducer程序(输出的K仍是手机号,V是Bean对象,Bean对象写入文件的格式是重写的tostring方法)
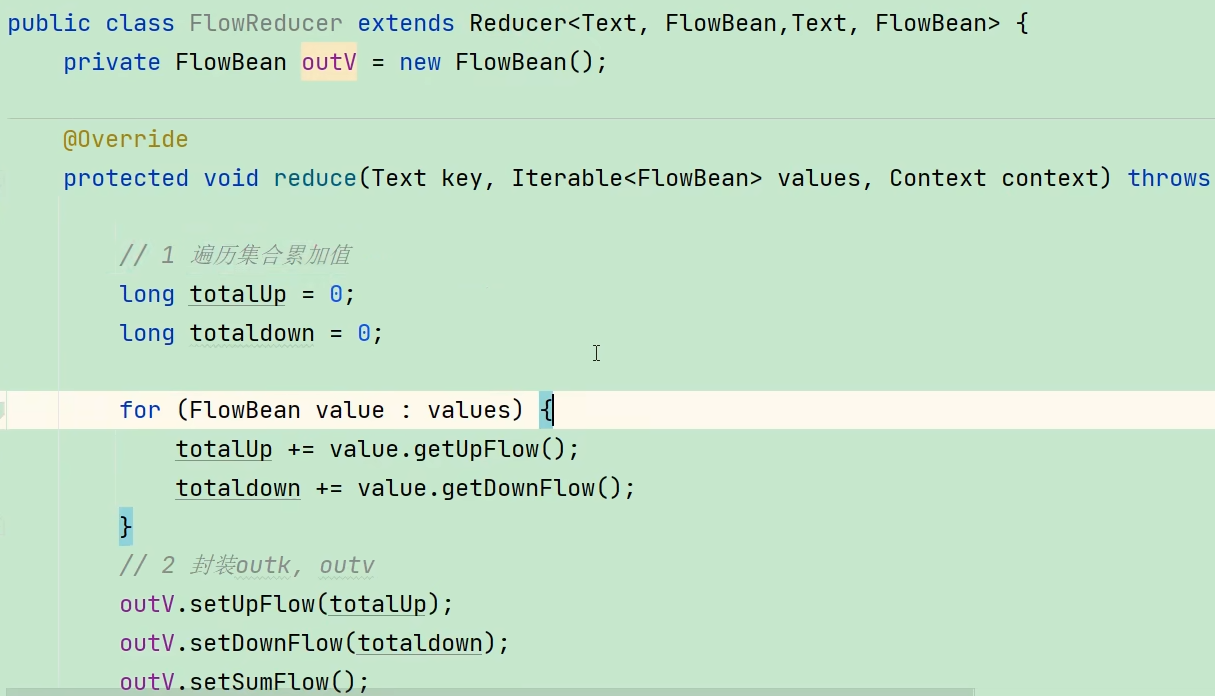
(4)编写Driver程序(固定格式)

七、MapReduce 框架原理
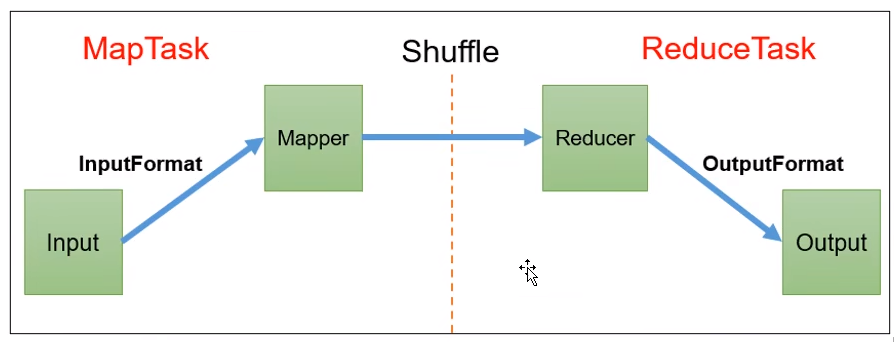
7.1 MapReduce 工作流程
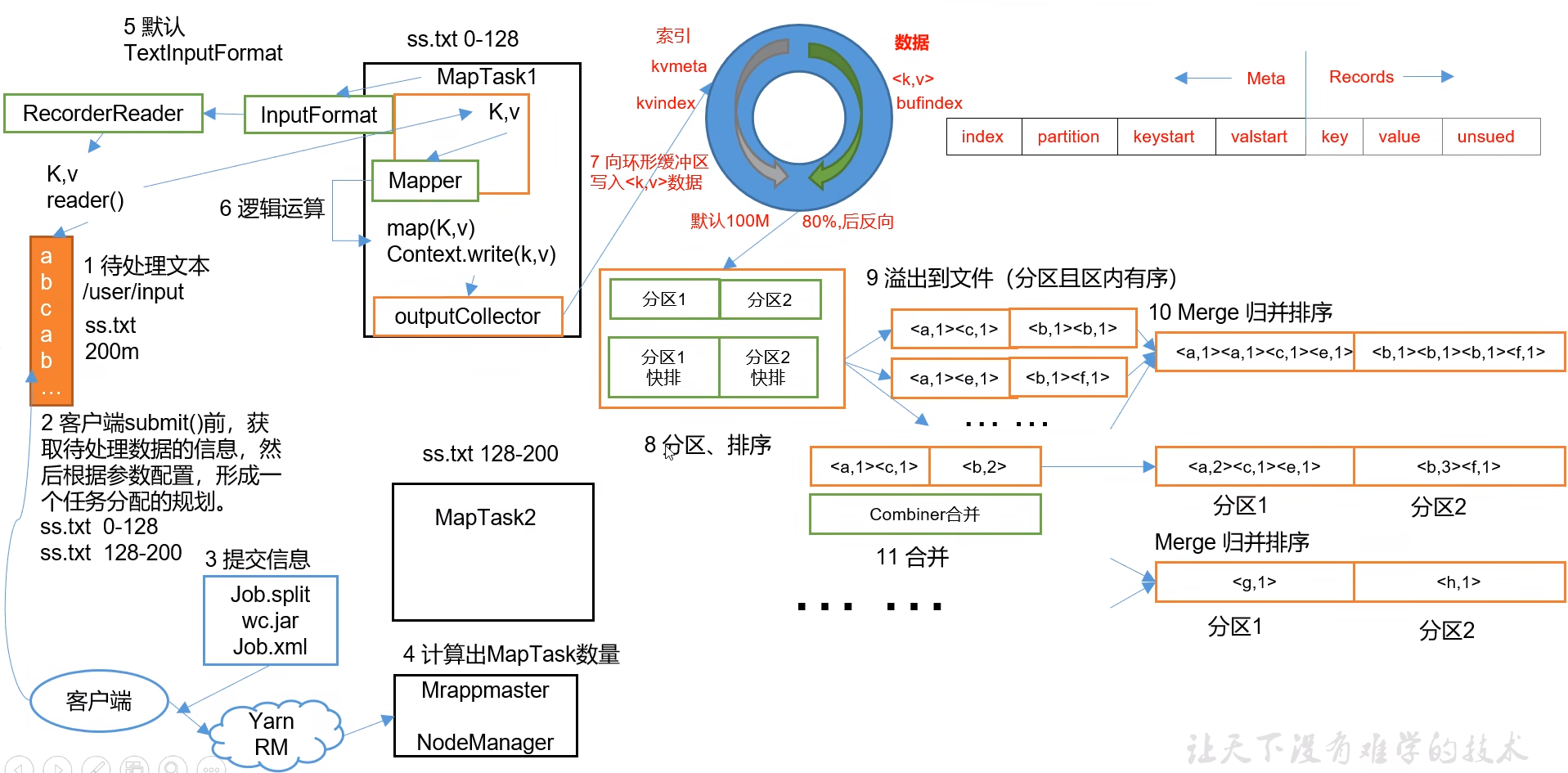
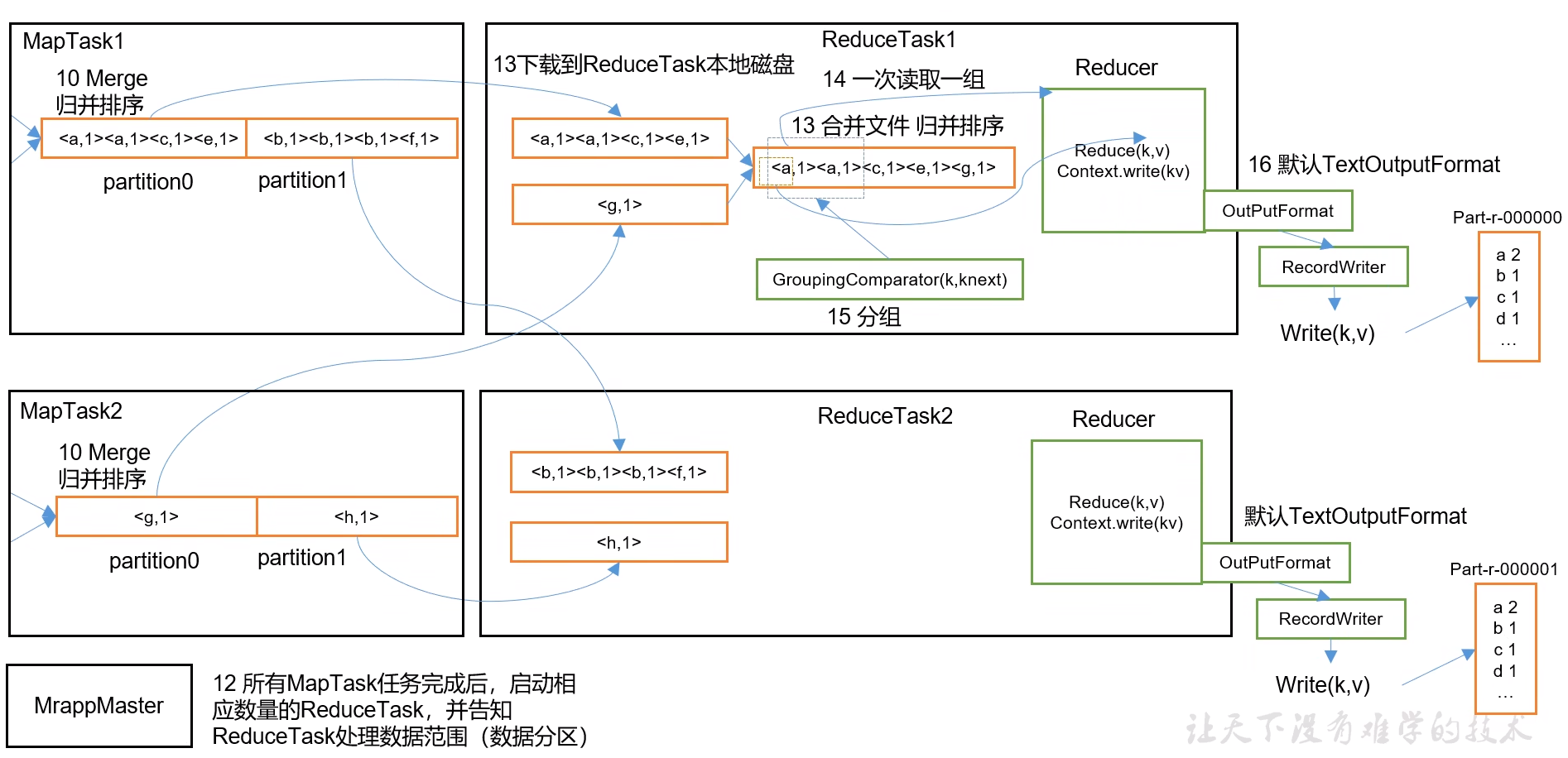
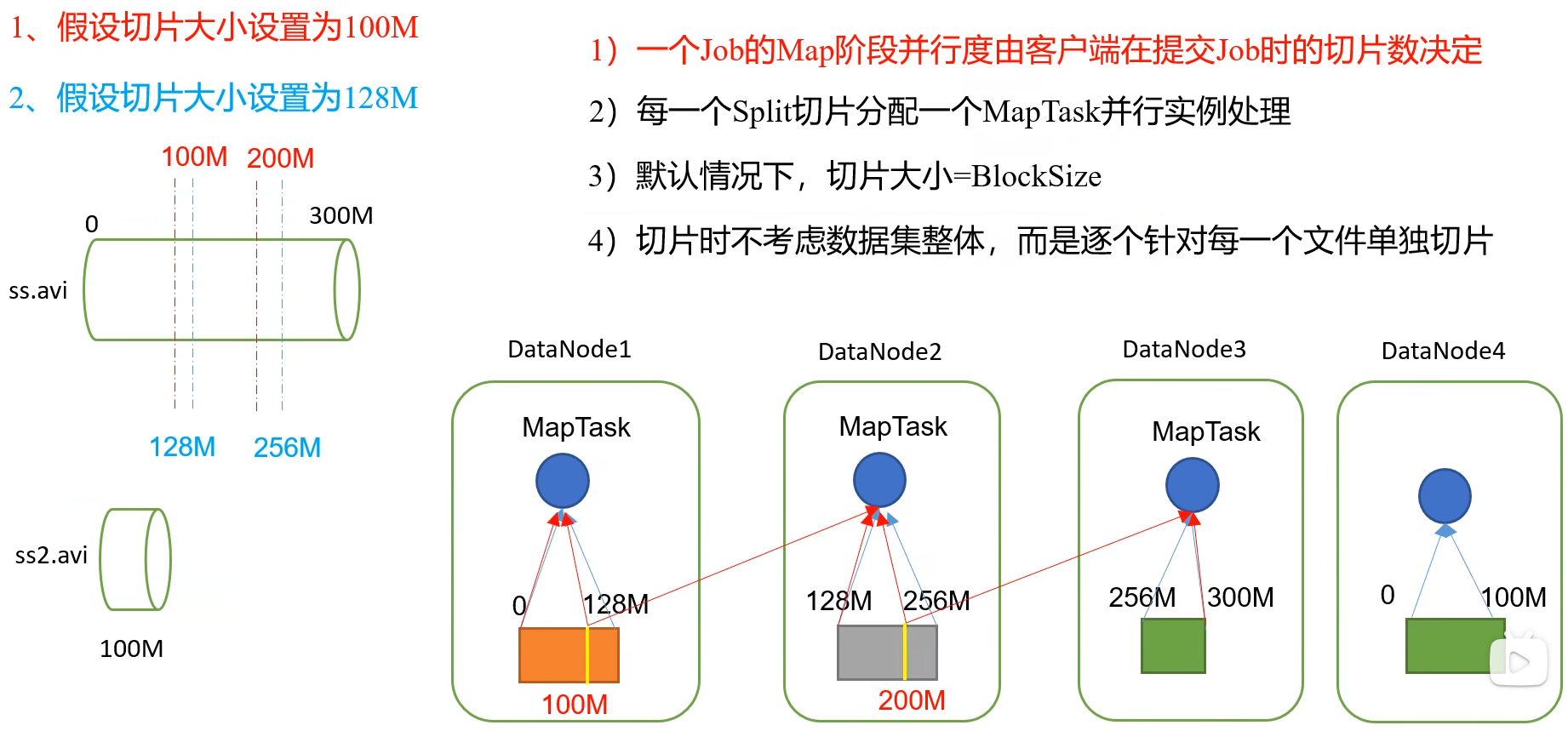
7.2 切片机制
数据块:Block是 HDFS物理上把数据分成一块一块。数据块是 HDFS 存储数据单位
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是 MapReduce 程序计算输入数据的单位,一个切片会对应启动一个MapTask
Job提交流程源码详解:
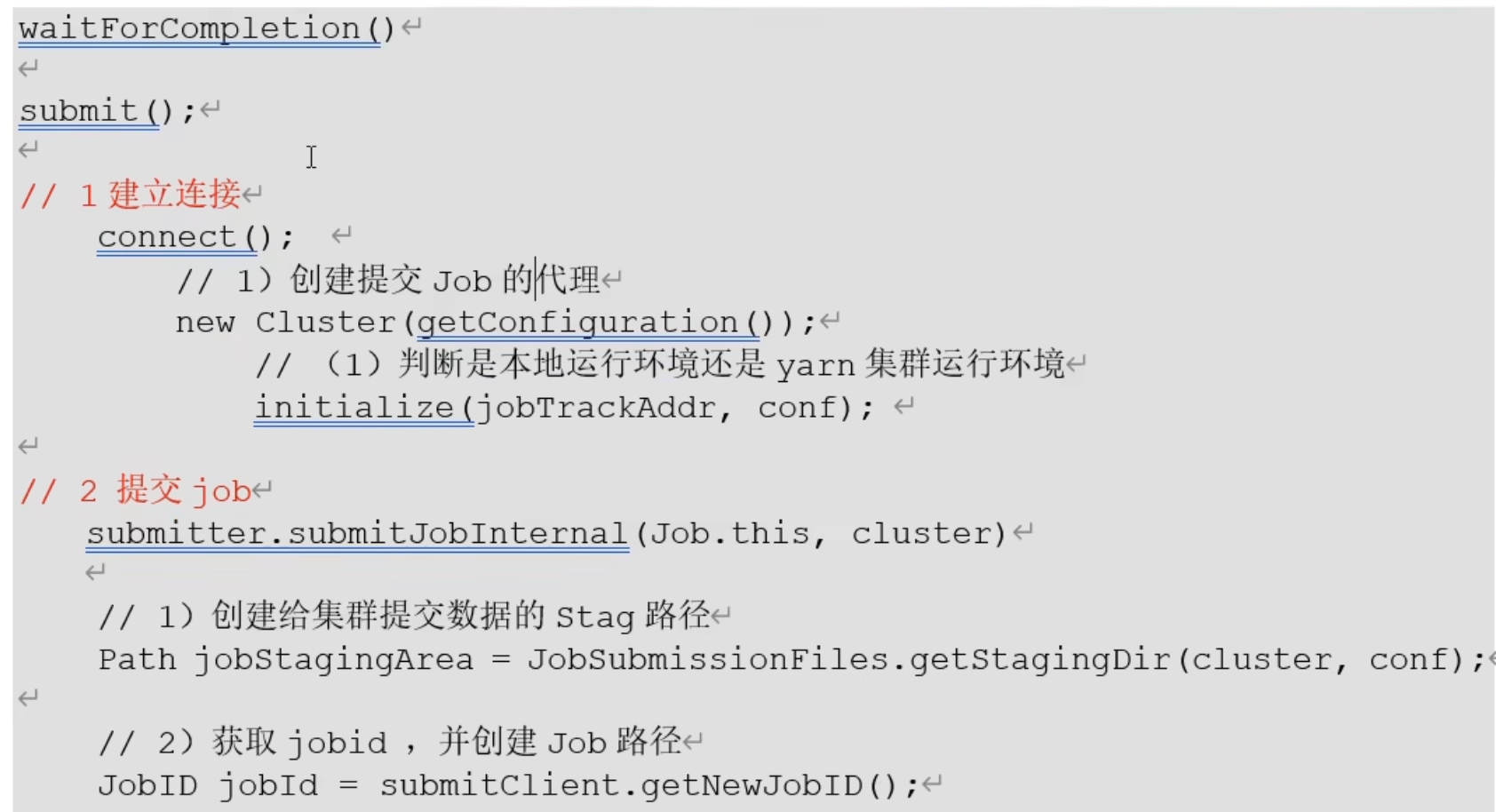
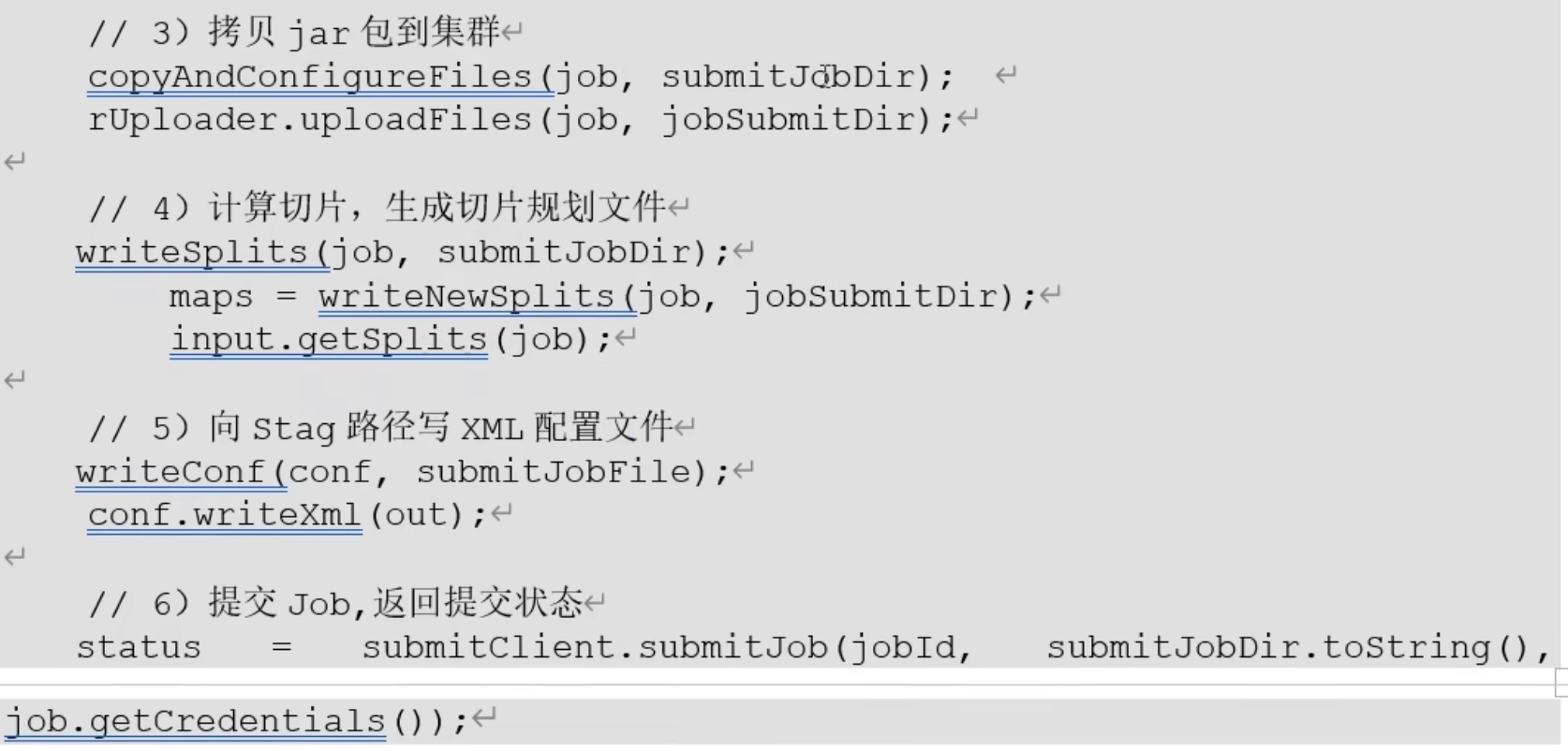
· 步骤2)创建一个临时路径
步骤 6)提交Job后 status的值由 DEFINE 转变为RUNNING
FileInputFormat(MapReduce默认数据输入)切片源码解析:



7.3 InputFormat 数据输入


KeyValueTextInputFormat 是从第一个分隔符(如" \t ")切割,将一行切割成两部分,前一部分是K,后一部分是V。KV都是Text类型。
NlineInputFormat 是一次读取多行进行处理。
CombineTextInputFormat 切片机制:


可通过添加如下代码,改变数据输入切片规则:

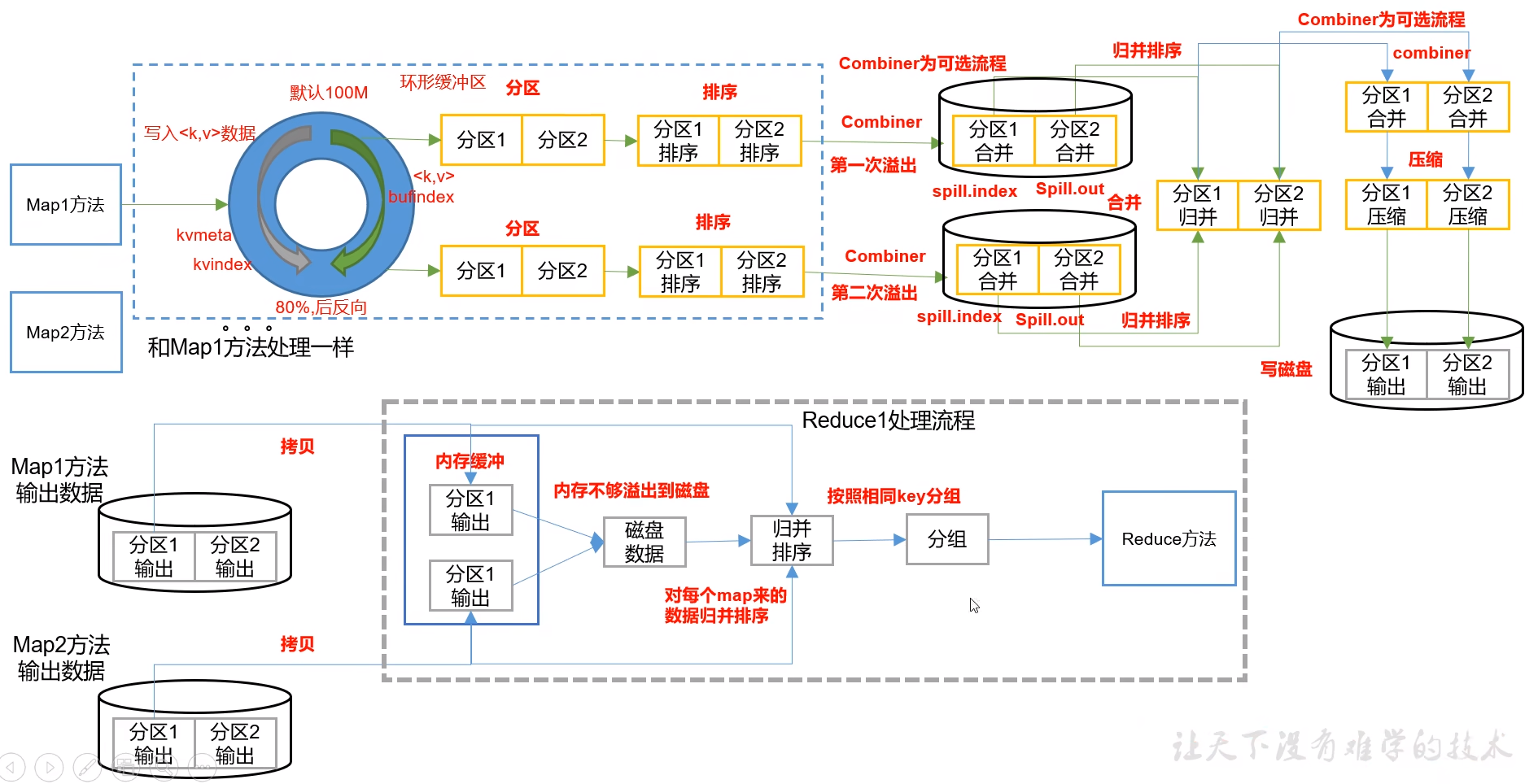
7.4 Shuffle 机制
7.4.1 分区 Partition

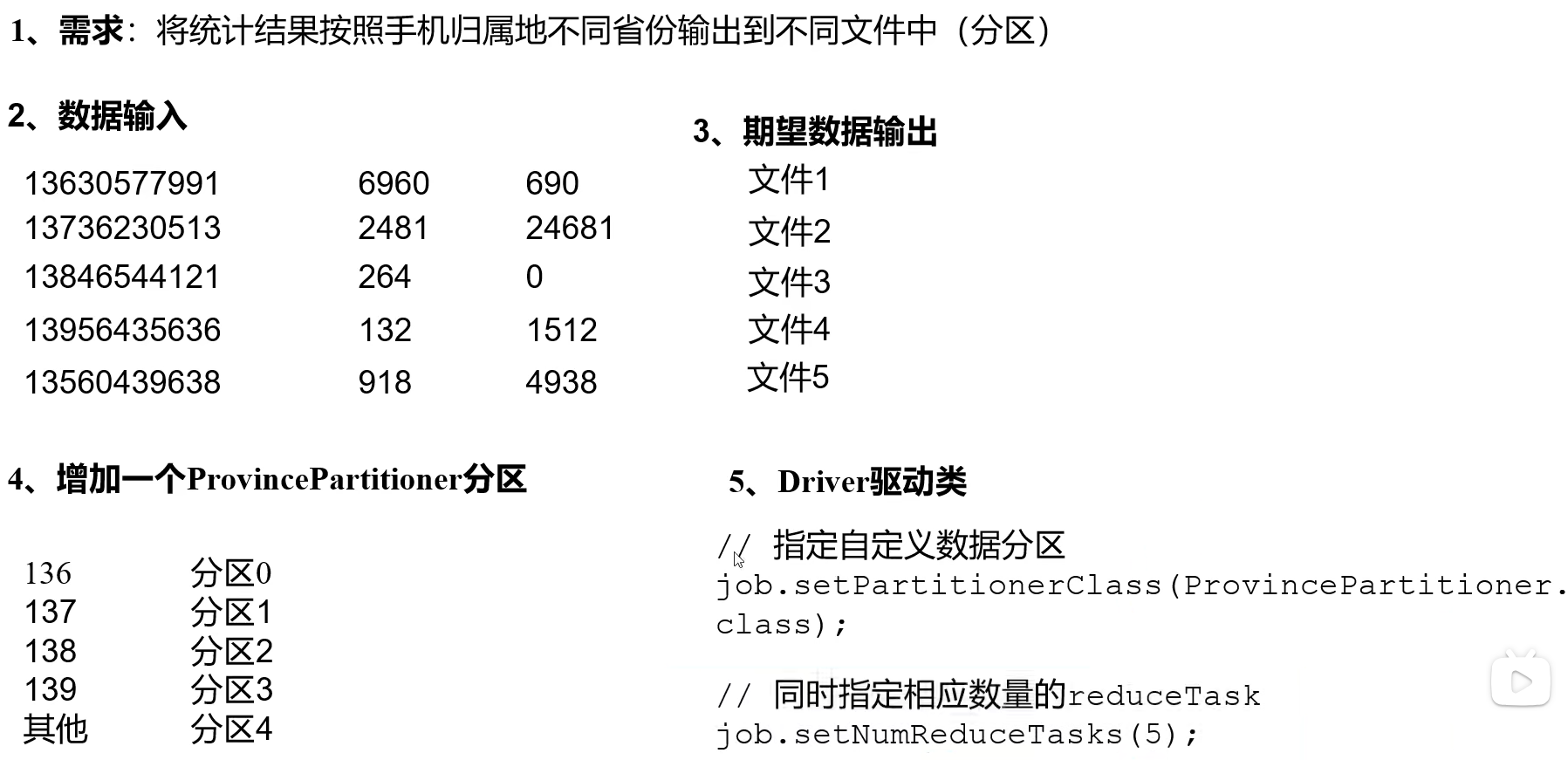
自定义Partitioner 步骤:

自定义Partitioner 学习案例:

7.4.2 排序 WritableComparable
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盎上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行次归并排序。
(1)部分排序
MapReduce根据输入记录的键数据集排序。保证输出的每个文件内部有序。
(2)全排序
最终输出结果只有一个文件且文件内部有序。实现方式是只设置一个ReduceTask。但该方法在处理大型文件时效率极低,因为一台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
(3)辅助排序:(GroupingComparator)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
(4)二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序
自定义排序 WritableComparable :
bean 对象做为key 传输,需要实现 WritableComparable接口重写 compareTo 方法,就可以实现排序。
自定义排序学习案例:

7.4.3 合并 Combiner
(1)Combiner是MR程序中Mapper和Reducer之外的一种组件。
(2)Combiner组件的父类就是Rducer。
(3)Combiner和Reducer的区别在于运行的位置
Combiner是在每一个 MapTask 所在的节点运行;
Reducer是接收全局所有 Mapper 的输出结果;
(4)Combiner的意义就是对每-个MapTask的输出进行局部汇总以减小网络传输量。
(5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且Combiner的输出KV应该跟Reducer的输入KV类型要对应起来。
自定义 Combiner 实现步骤:
1)自定义一个 Combiner 类继承 Reducer,重写 Reduce 方法
2)在WordcountDriver 驱动类中指定 Combiner
job.setCombinerClass (WordCountCombiner.class);
也可以不编写Combiner 类,直接使用Reducer类指定为Combiner:
job.setCombinerClass (WordCountReducer.class);
如果没有 Reducer 阶段,则也没有 Shuffle 阶段
7.5 OutputFormat 数据输出
OutputFormat是 MapReduce 输出的基类,所有实现MapReduce输出都实现了 Outputormat接口。常见的OutputFormat实现类有以下几种:
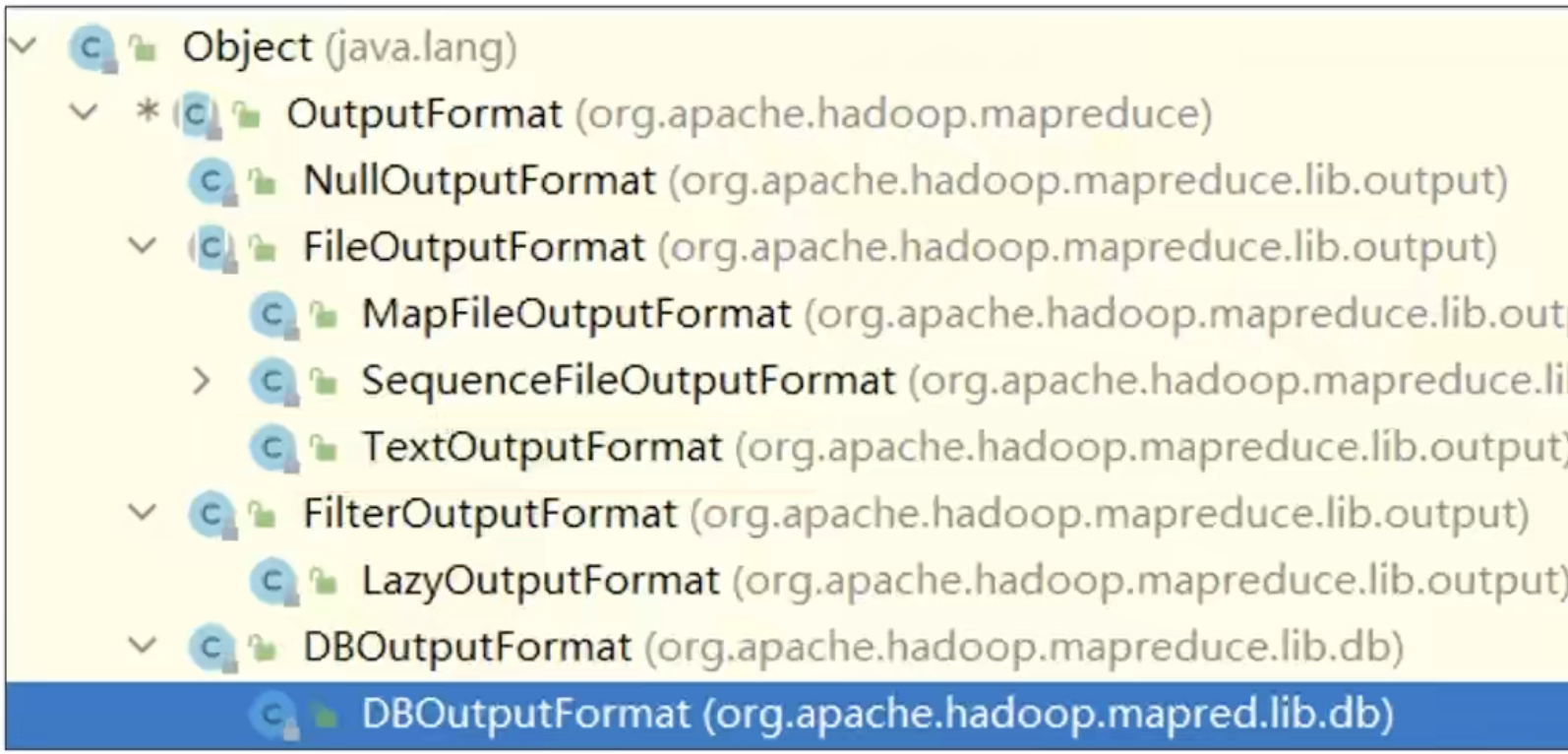
默认输出格式是 TextOutputFormat。
自定义 OutputFormat 步骤:
(1)自定义一个类继承 FileOutputFormat
(2)改写RecordWriter,具体改写输出数据的方法write()。
自定义 OutputFormat 学习案例:

自定义 OutputFormat 类:
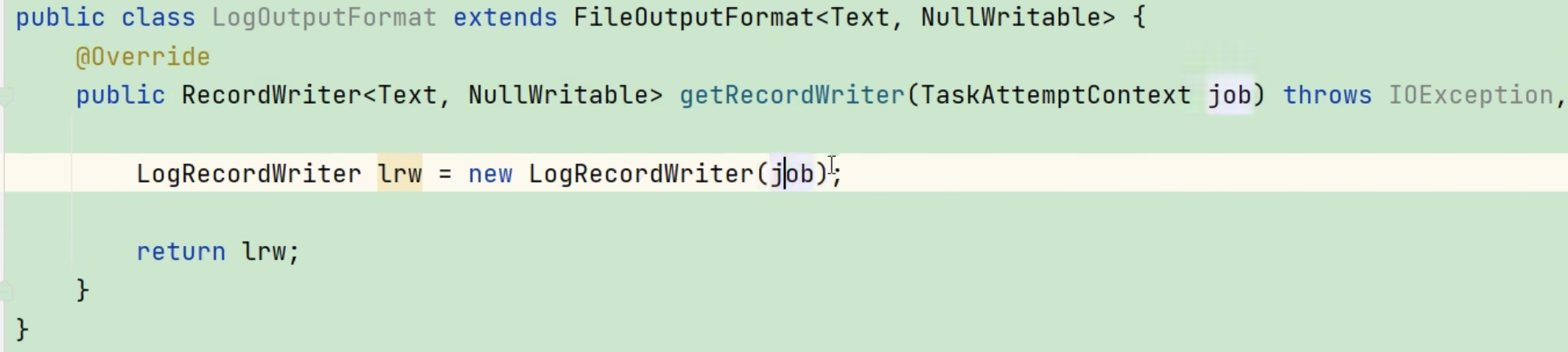
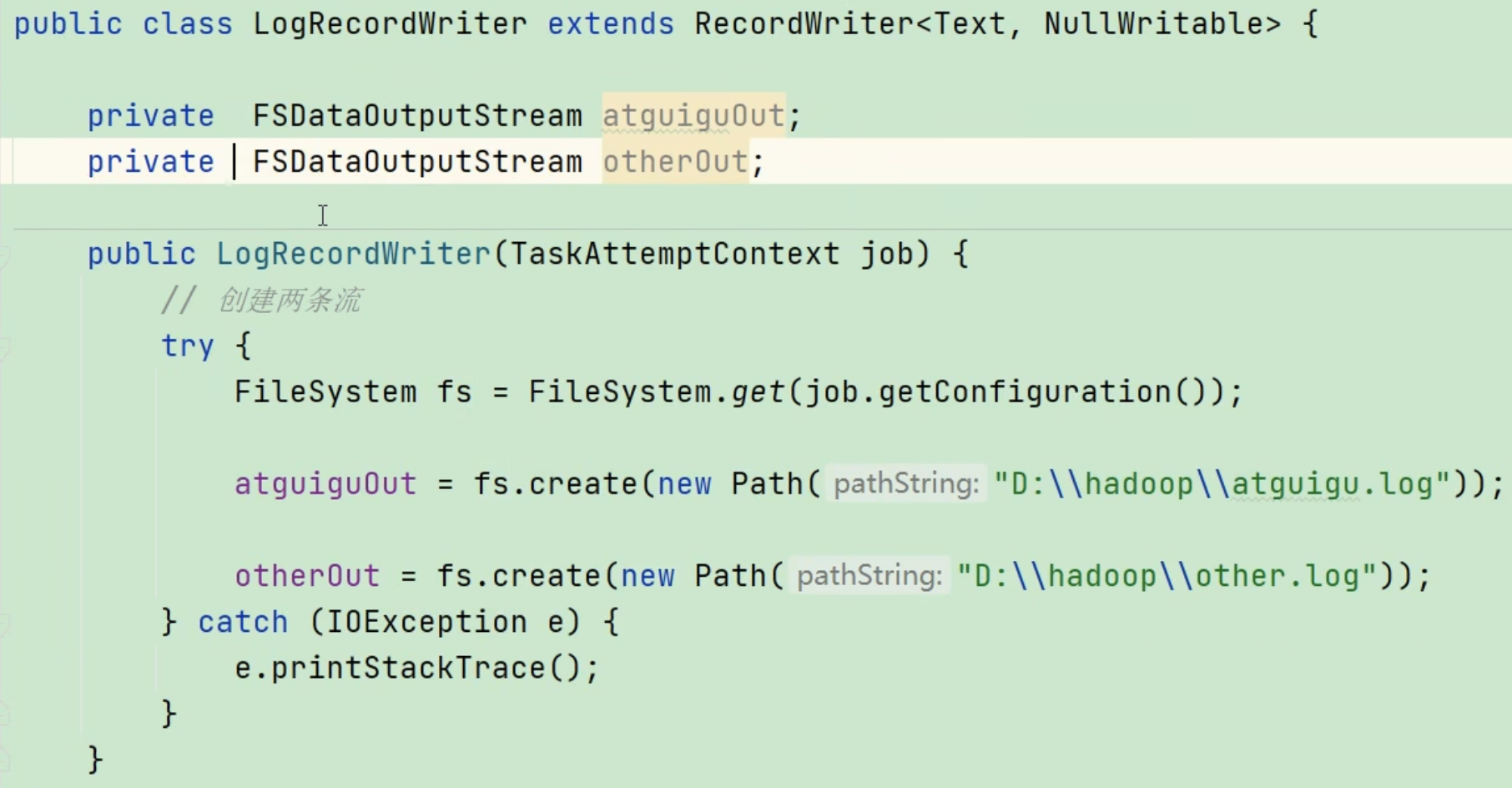
创建两个文件的输出流:
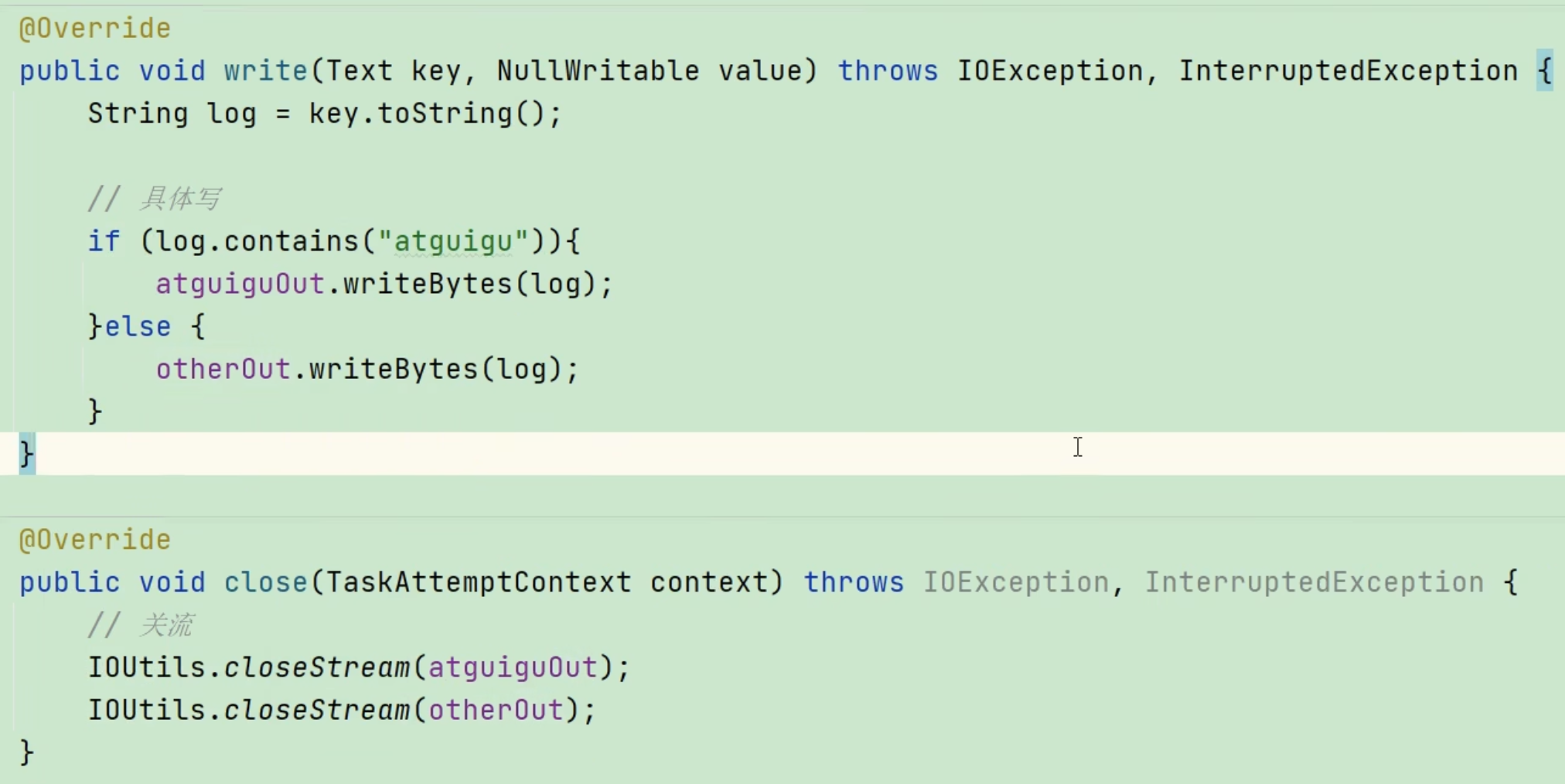
在继承 RecordWriter 类中的write()方法内编写条件判断:
在Driver类中定义:

7.6 Reduce Task 并行度决定机制
MapTask 并行度由切片个数决定,切片个数由输入文件和切片规则决定。
ReduceTask 数量的决定是可以直接手动设置:
/默认值是 1,手动设置为4
job.setNumReduceTasks(4);
ReduceTask 数量设置注意事项:
(1)ReduceTask-0,表示没有Reduce阶段,输出文件个数和Map个数一致。
(2)ReduceTask默认值就是1,所以输出文件个数为一个。
(3)如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜。
(4)ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
(5)具体多少个ReduceTask,需要根据集群性能而定
(6)如果分区数不是1,但是ReduceTask为1,不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于肯定不执行。
7.7 Join 多种应用
读取多个文件(相当于mysql多多张表),将其合并后输出
7.7.1 Reduce Join
Map 端的主要工作:为来自不同表或文件的key/vale 对打标签,以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为 value,最后进行输出。
Reduce 端的主要工作:在 Reduce 端以连接字段作为 key 的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在 Map 阶段已经打标志)分开,最后进行合并就可以了。
Reduce Join 学习案例:
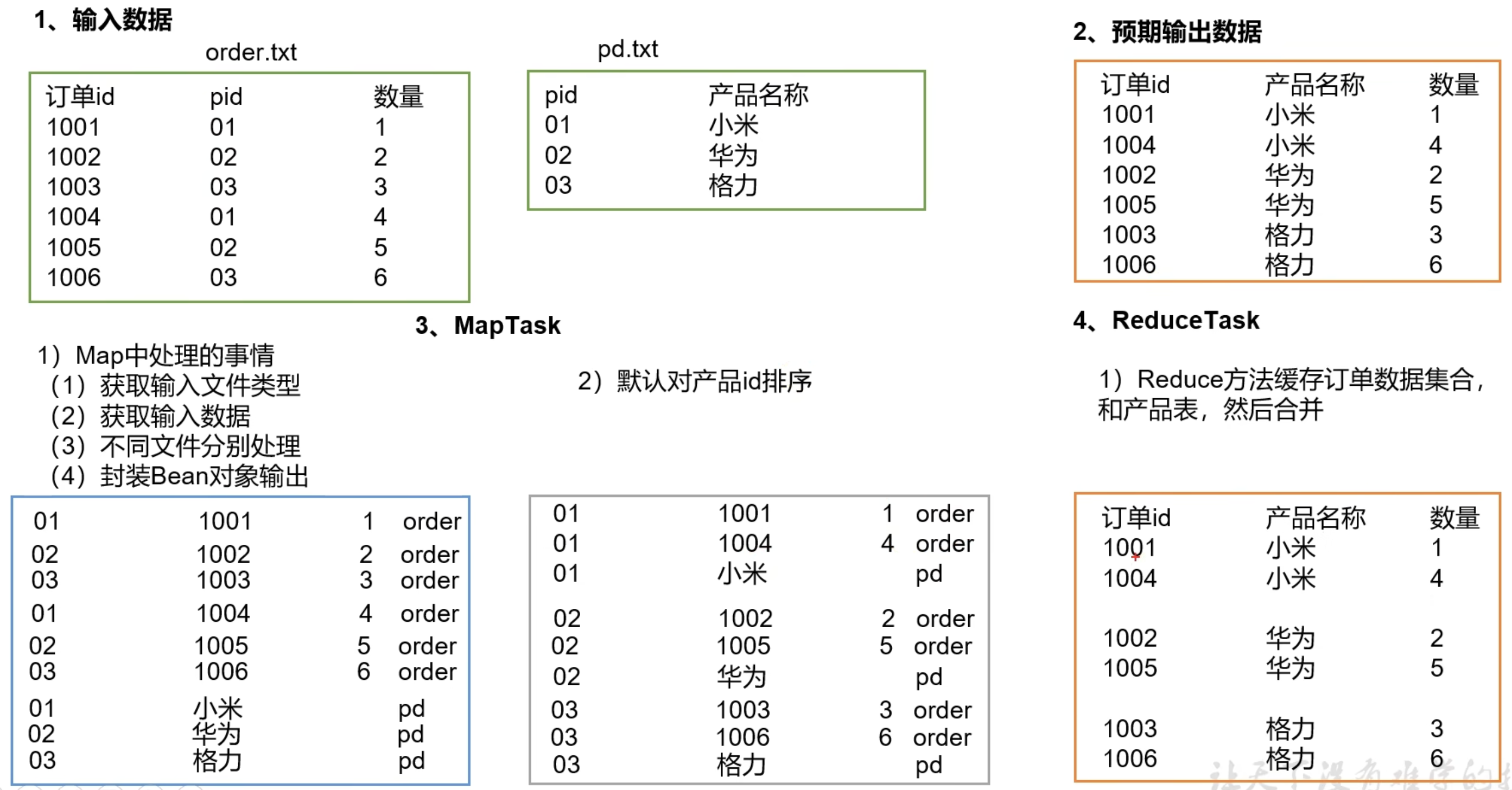
(1)创建商品和订单合并后的 TableBean 对象类(实现Writable接口的序列化后、反序列化方法和toString()方法)
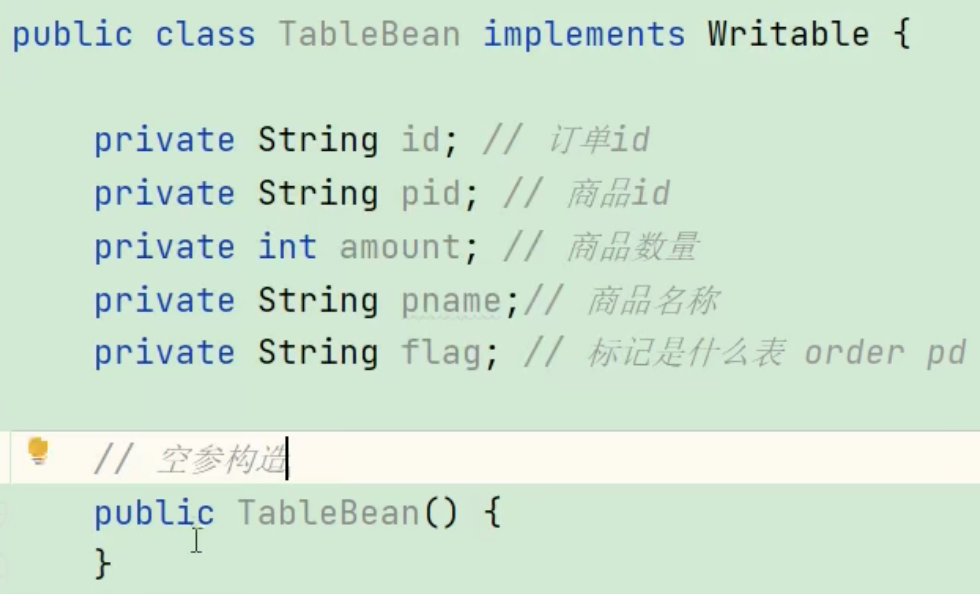
(2)编写 Mapper 类代码(在setup()初始化方法中,通过获取切片信息,可以得到读取文件的路径及名字)

(3)编写 Reduce 类代码(代码思路:遍历同一K的V集合,将订单表数据存入订单集合中,将商品数据单独存储,再循环遍历订单集合,给其商品属性赋值,然后输出)因为V集合不是一个迭代器,所以要创建一个临时对象存储Bean对象。


(4)编写Driver 类(按固定格式即可)
缺点:这种方式中,合并的操作是在 Reduce 阶段完成,Reduce 端的处理压力太大,Map节点的运算负载则很低,资源利用率不高,且在Reduce 阶段极易产生数据倾斜。
解决方案:Map 端实现数据合并。
7.7.2 Map Join
Map Join 适用于一张表十分小、一张表很大的场景。(将小表缓存在内存当中)
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在 Driver 驱动类中加载缓存。

上述学习案例的 Map Join 思路:

八、Hadoop 的数据压缩
压缩的优点:减少磁盘IO、减少磁盘存储空间
压缩的缺点:增加CPU开销
因此,运算密集型的 Job,少用压缩;IO 密集型的 Job,多用压缩
8.1 MapReduce支持的压缩编码
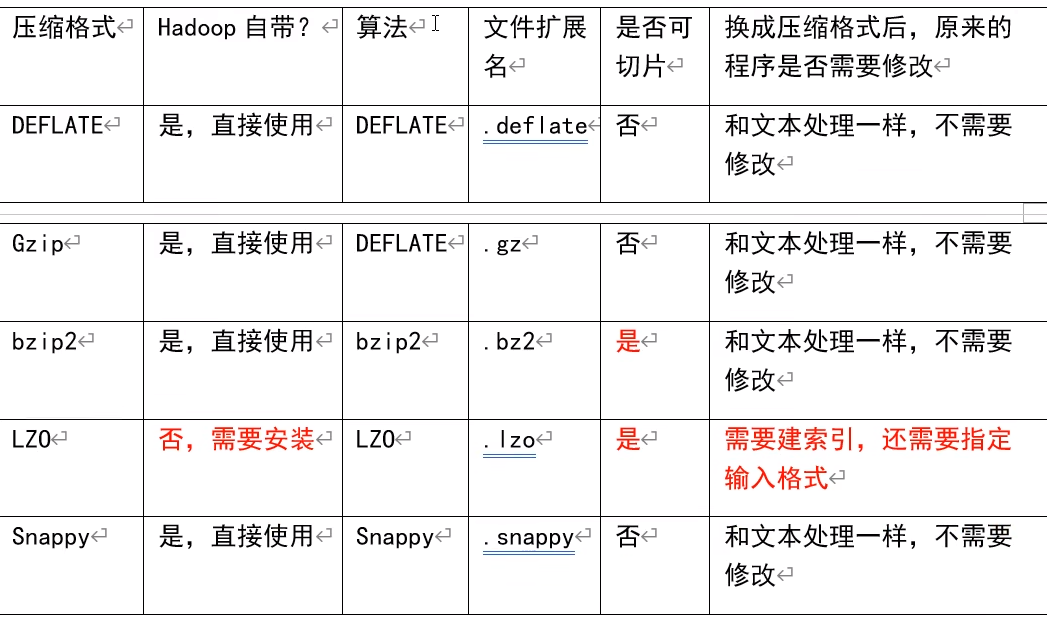
压缩性能比较:
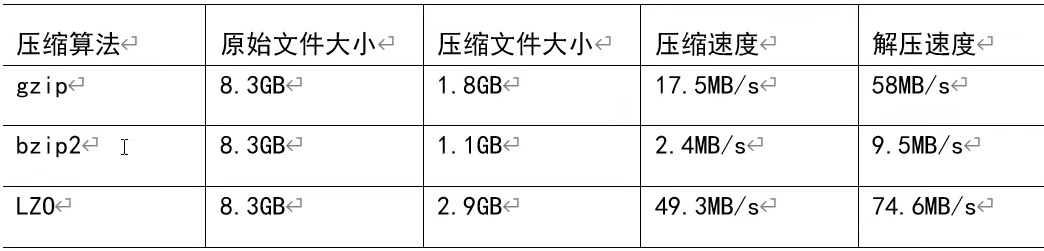
压缩方式的选择:

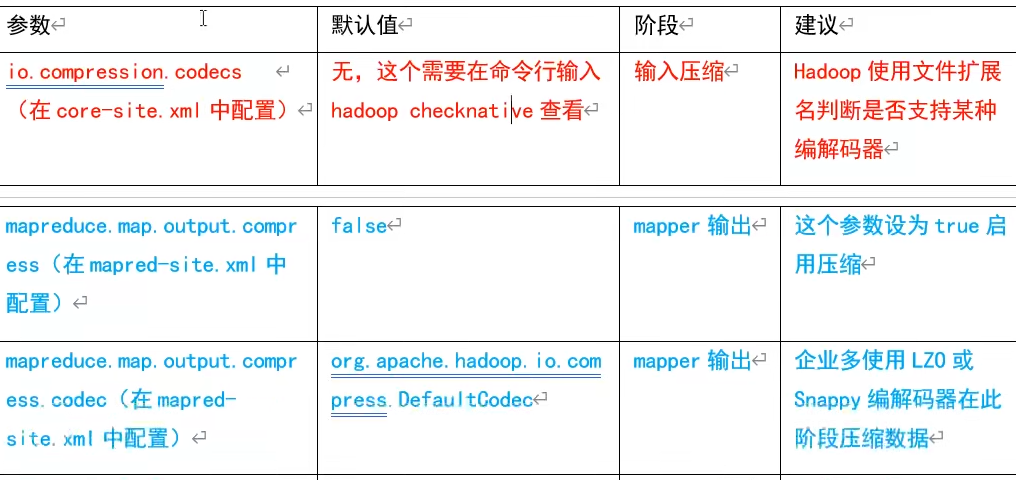
8.2 配置压缩参数

在Hadoop中开启压缩,可以配置以下参数:

8.3 压缩实操案例
8.3.1 Map 输出端采用压缩
即使 MapReduce 的输入输出文件都是未压缩的文件,仍然可以对 Map 任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到 Redce 节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可。
在Driver类中添加如下属性:
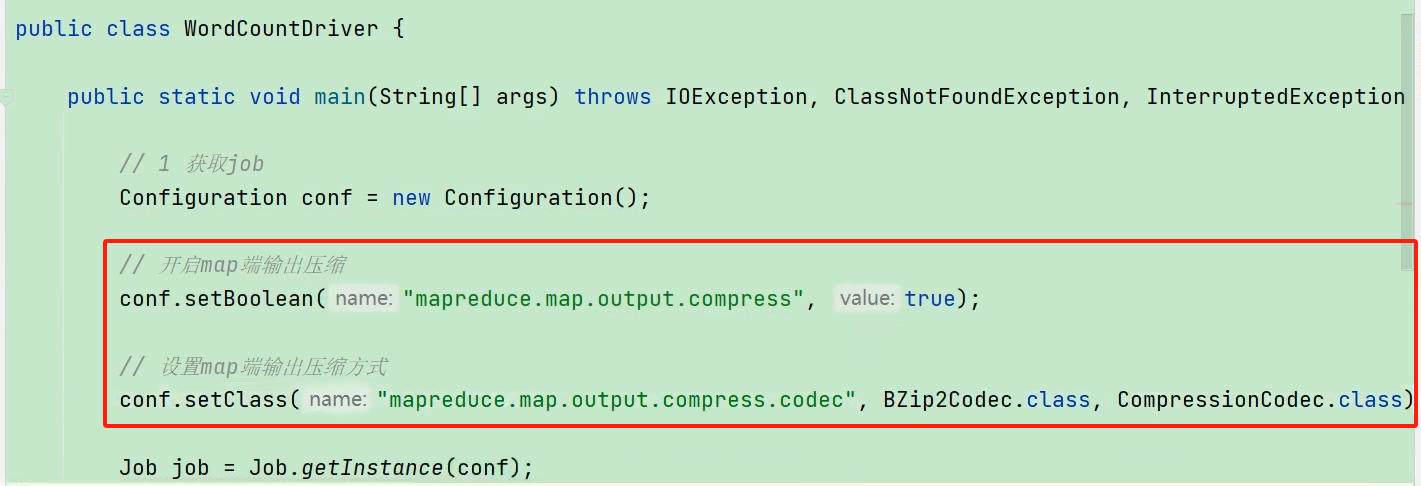
8.3.2 Reduce 输出端采用压缩
在Driver类中添加如下属性:


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)