掌上高考——全国高考数据爬虫与数据可视化分析(大学生期末课设)
该项目通过爬虫requests,bs4等获取所需数据,存储为csv文件,再由MySQL存入数据库进行管理,由flask服务器与web前端fetch异步,同步交互,使用Echarts图表进行可视化分析。
·
一、作品介绍
- 该项目通过爬虫requests,bs4等获取所需数据,存储为csv文件,再由MySQL存入数据库进行管理,由flask服务器与web前端fetch异步,同步交互,使用Echarts图表进行可视化分析。
- 该项目涉及使用原生JS,MySQL,python,HTML等代码语言,实现前后端分离。
-
代码最后展示,需要源文件打包可私信或评论区留言,因发送压缩文件,建议私信lx方式,看到消息就会回复的。
-
爬虫需安全合法,不可恶意攻击服务器。
二、作品展示
- index首页: 导航作用,快速访问对应图表
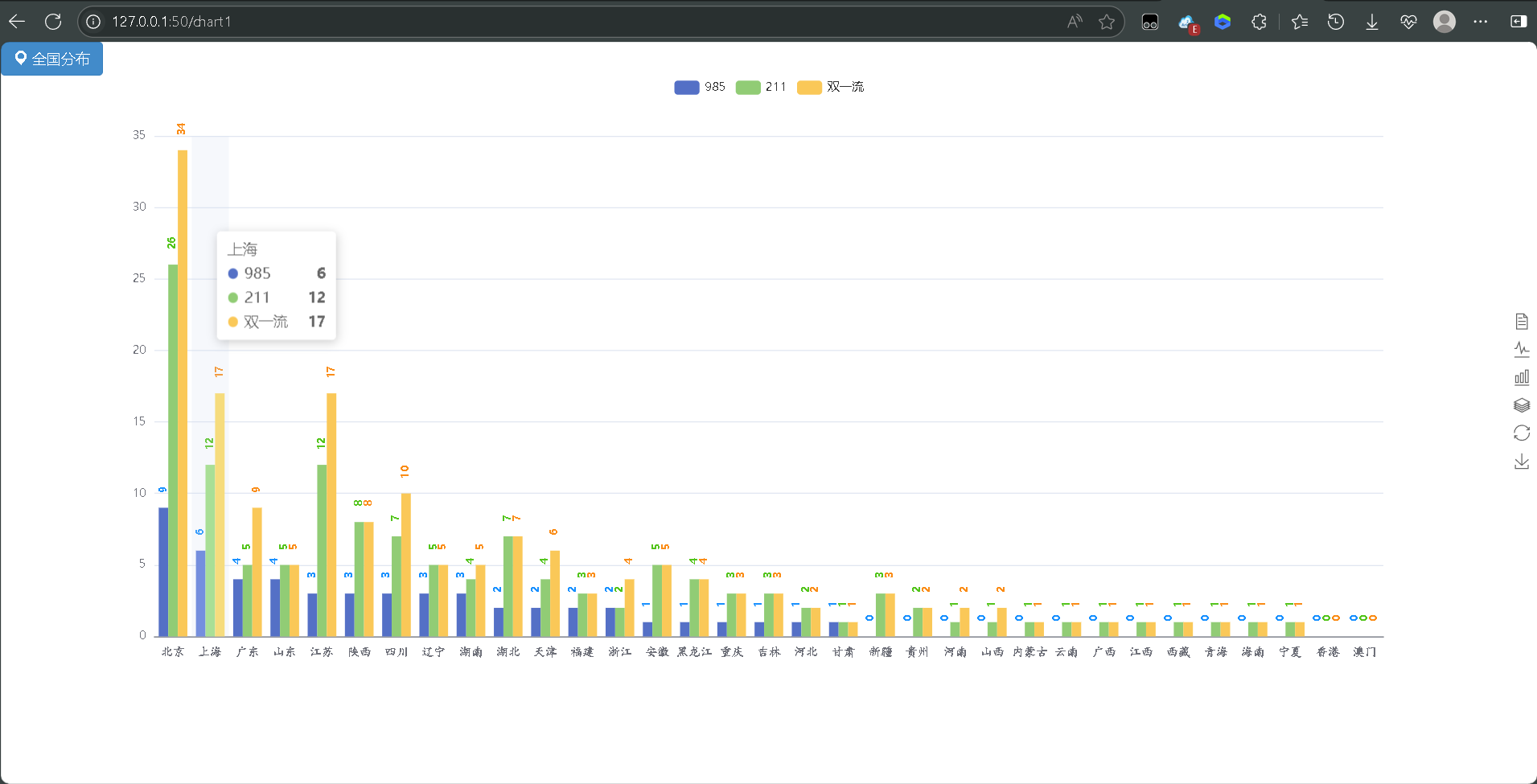
- 分布柱状图:各省市985/211/双一流高校数量对比
- 高校分布地图:全国重点高校地理分布可视化

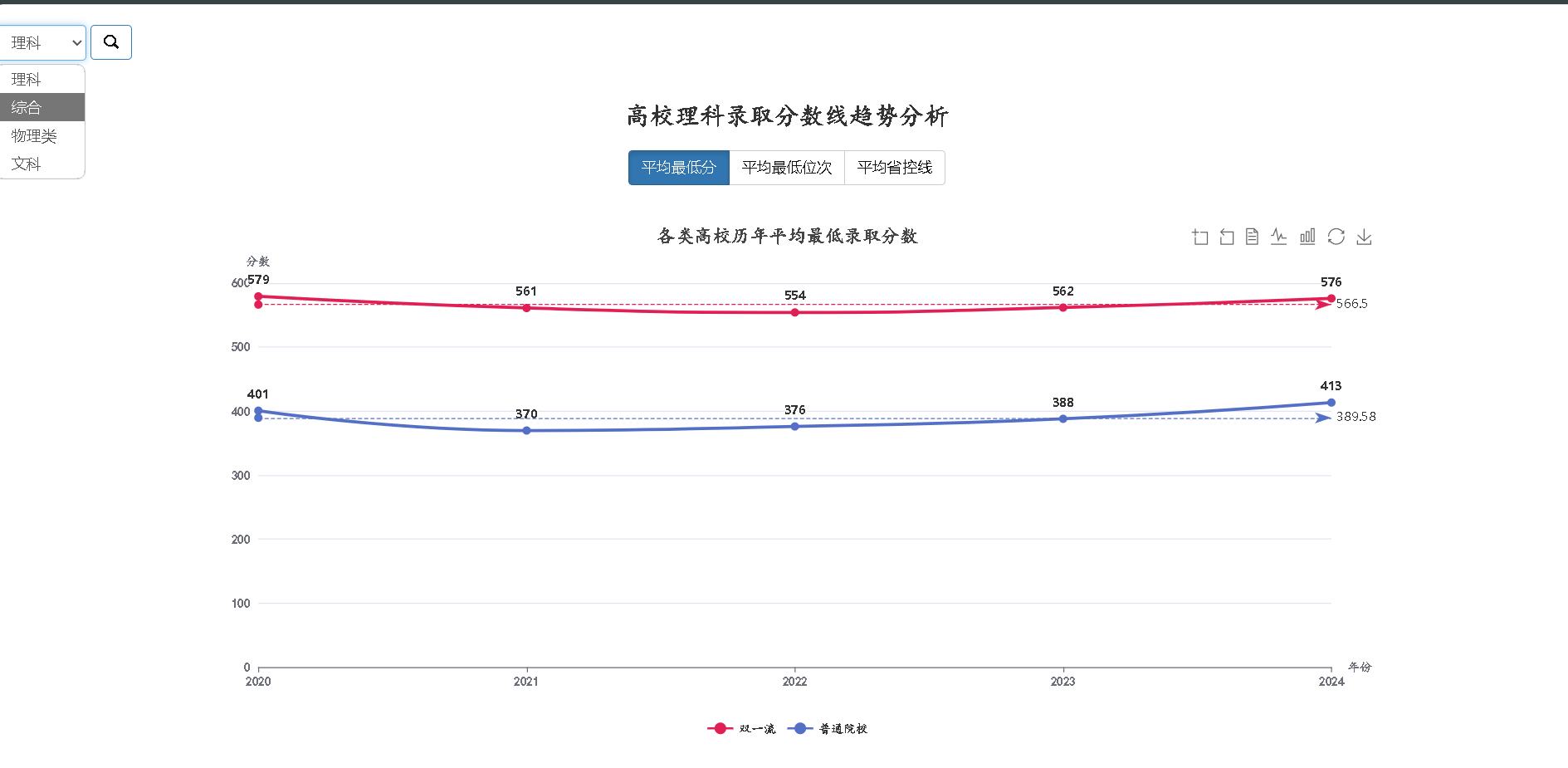
- 分数线地图:历年录取分数线/位次趋势分析(下拉框可自选分类)
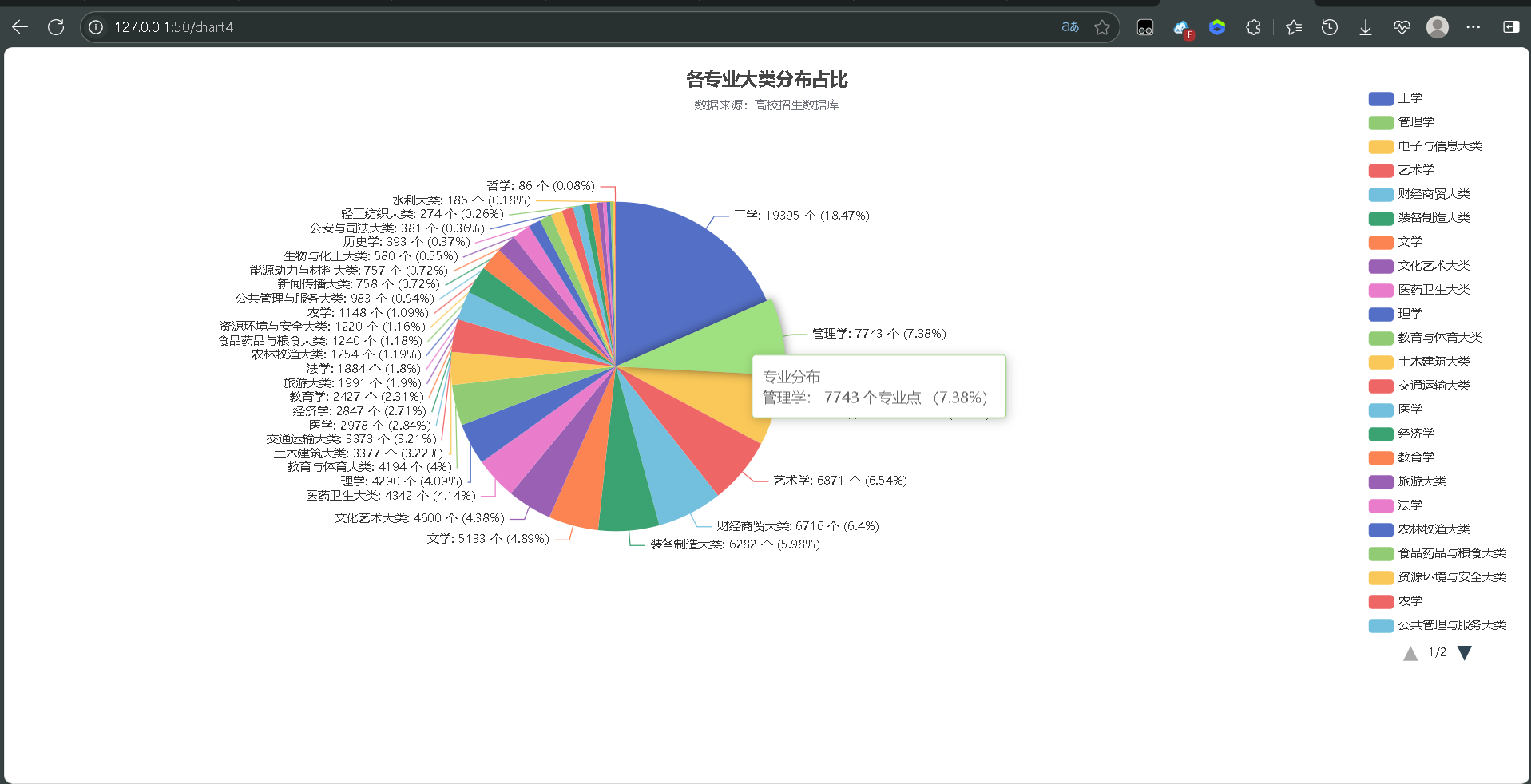
- 专业大类占比图表:各高校专业大类分布占比
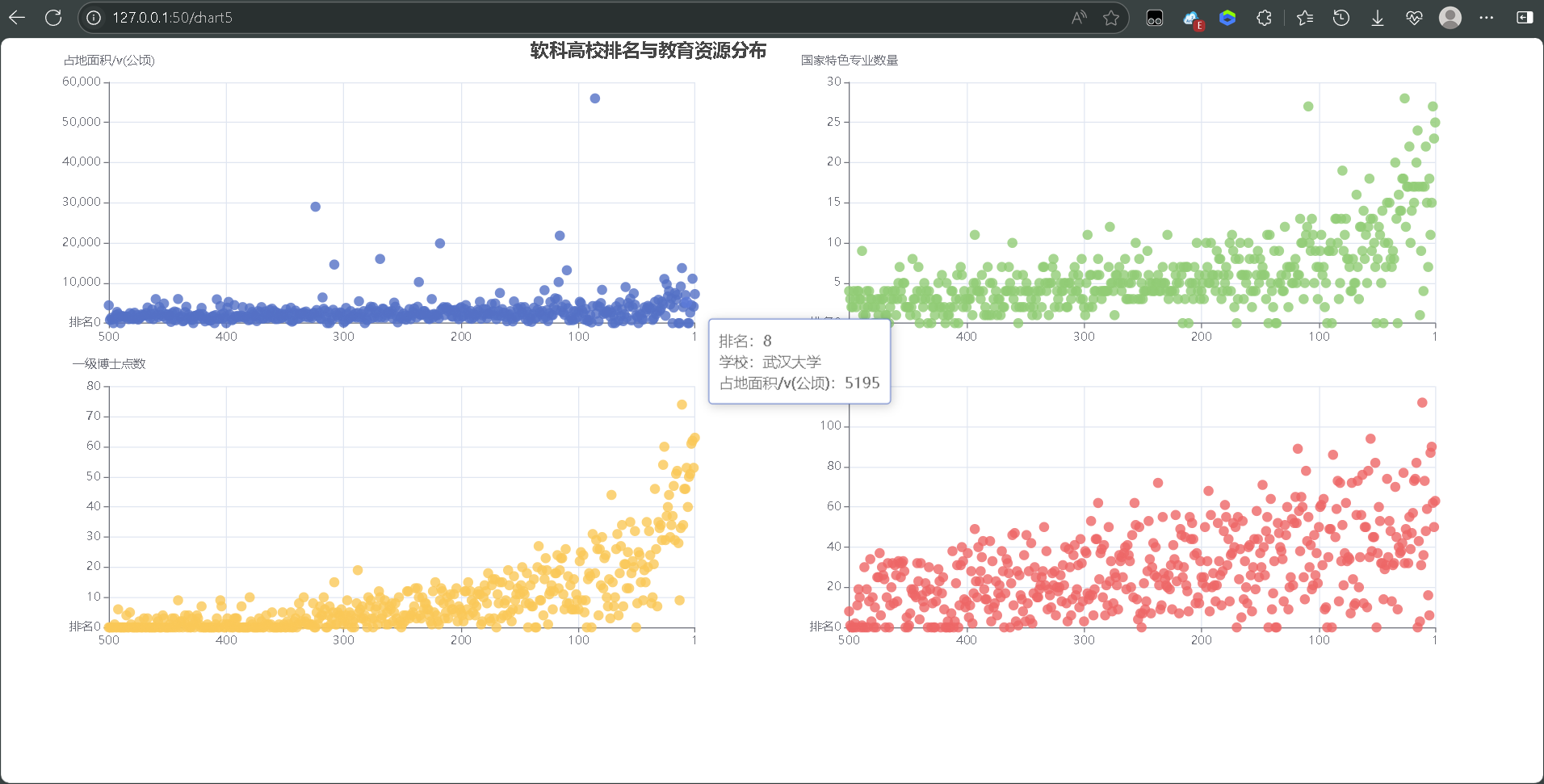
- 教育资源图表:软科排名与博士/硕士点等资源分布
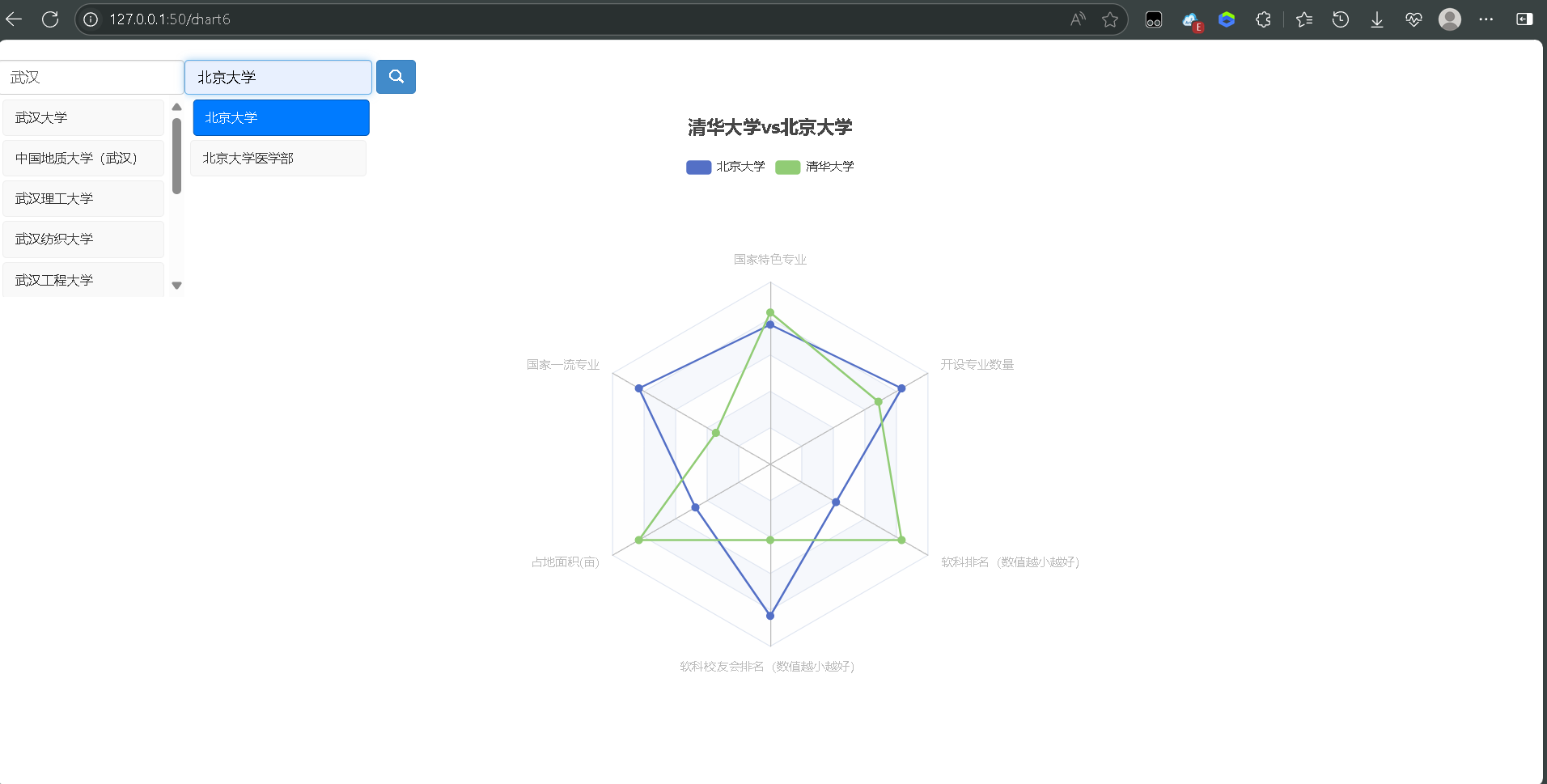
- 高校对比雷达图:多维度对比清华/北大等高校资源(搜索框自选学校)
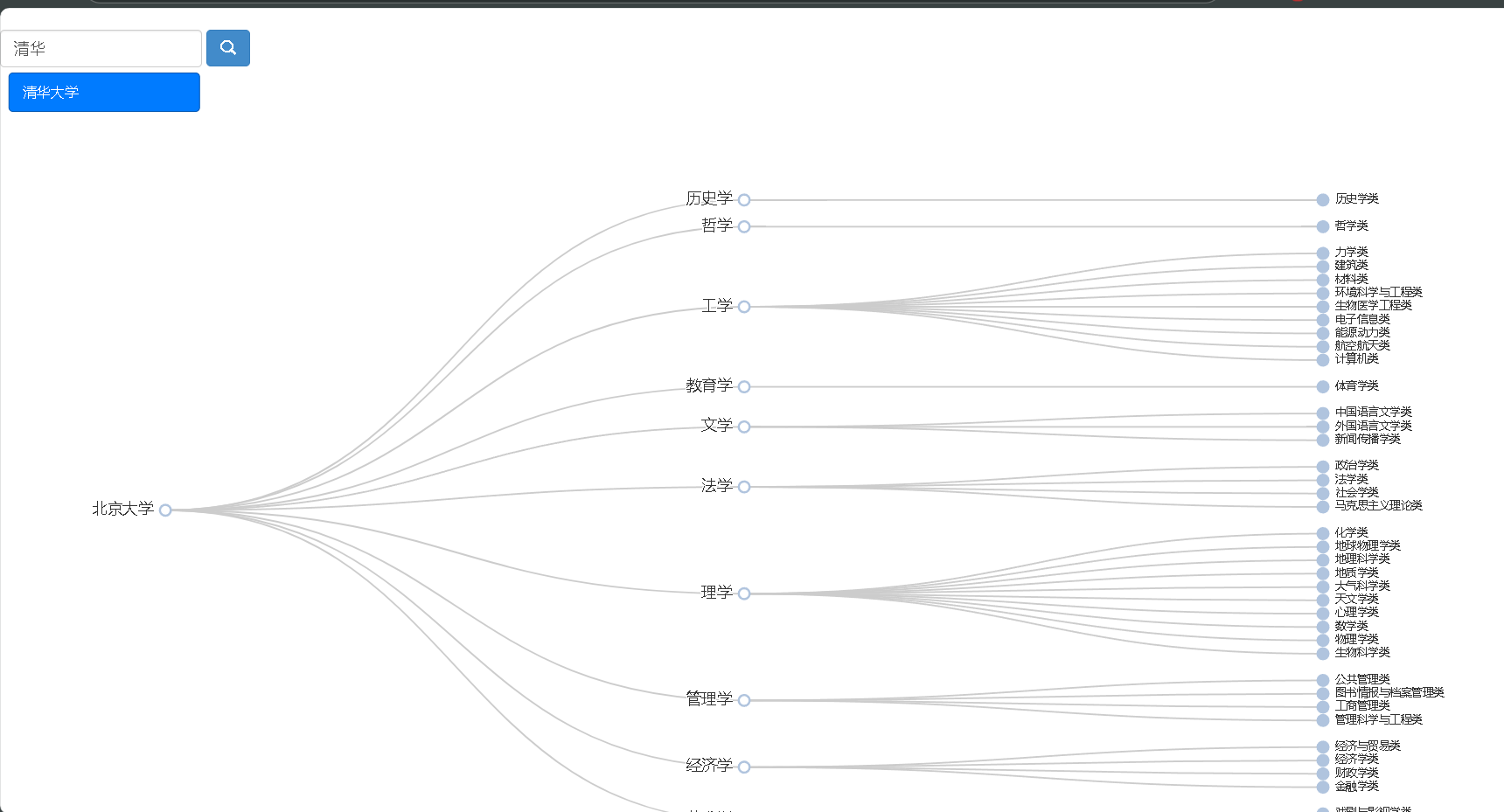
- 专业分布树图:高校专业大类-子类-专业结构树(搜索框自选学校)
三、代码部分
SQL建表
CREATE TABLE IF NOT EXISTS `prov_score` (
`school_id` INT NOT NULL DEFAULT -1 COMMENT '学校ID ',
`name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校名称 ',
`local_province_name` VARCHAR(40) NOT NULL DEFAULT '' COMMENT '省份名称 ',
`local_batch_name` VARCHAR(40) NOT NULL DEFAULT '' COMMENT '批次名称 ',
`local_type_name` VARCHAR(40) NOT NULL DEFAULT '' COMMENT '科类名称 ',
`major_score` INT NOT NULL DEFAULT -1 COMMENT '专业分数 ',
`max` INT NOT NULL DEFAULT -1 COMMENT '最高分',
`min` INT NOT NULL DEFAULT -1 COMMENT '最低分',
`min_section` INT NOT NULL DEFAULT -1 COMMENT '最低分位次',
`average` INT NOT NULL DEFAULT -1 COMMENT '平均分',
`avg_section` INT NOT NULL DEFAULT -1 COMMENT '平均分位次',
`dual_class_name` VARCHAR(40) DEFAULT '' COMMENT '双一流类型',
`num` INT NOT NULL DEFAULT -1 COMMENT '录取人数',
`sg_info` VARCHAR(40) DEFAULT '' COMMENT '生源信息',
`sg_name` VARCHAR(40) DEFAULT '' COMMENT '生源名称',
`proscore` INT NOT NULL DEFAULT -1 COMMENT '省控线',
`year` INT NOT NULL DEFAULT -1 COMMENT '年份'
);
CREATE TABLE IF NOT EXISTS `rank_all` (
`type_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '排名类型',
`name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校名称',
`school_id` INT NOT NULL DEFAULT -1 COMMENT '学校ID',
`sort` INT NOT NULL DEFAULT -1 COMMENT '排序原位次',
`province_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '省份名称',
`rank` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '最终排名'
);
CREATE TABLE IF NOT EXISTS `error_log` (
`type_spider` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '爬虫类型',
`school_id` INT NOT NULL DEFAULT -1 COMMENT '学校ID',
`name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校名称',
`page` INT NOT NULL DEFAULT -1 COMMENT '页码 (page)',
`content` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '错误内容'
);
CREATE TABLE IF NOT EXISTS `specials` (
`school_id` INT NOT NULL DEFAULT -1 COMMENT '学校ID',
`school_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校名称',
`special_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '专业名称',
`type_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '专业类型',
`limit_year` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学制',
`level2_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '专业大类',
`level3_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '专业子类',
`nation_feature` INT NOT NULL DEFAULT -1 COMMENT '国家特色专业',
`nation_first_class` INT NOT NULL DEFAULT -1 COMMENT '国家一流专业',
`province_feature` INT NOT NULL DEFAULT -1 COMMENT '省级特色专业'
);
CREATE TABLE IF NOT EXISTS `university_info` (
`school_id` INT NOT NULL DEFAULT -1 COMMENT '学校ID',
`name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校名称',
`province_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '省份',
`city_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '城市',
`level_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '层次(本科/专科)',
`type_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '学校类型(理工、综合等)',
`school_nature_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '公办/民办',
`f985` INT NOT NULL DEFAULT -1 COMMENT '是否985',
`f211` INT NOT NULL DEFAULT -1 COMMENT '是否211',
`dual_class_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '双一流类型',
`num_doctor` INT NOT NULL DEFAULT -1 COMMENT '一级博士点数量',
`num_doctor2` INT NOT NULL DEFAULT -1 COMMENT '二级博士点数量',
`num_master` INT NOT NULL DEFAULT -1 COMMENT '一级硕士点数量 ',
`num_master2` INT NOT NULL DEFAULT -1 COMMENT '二级硕士点数量 ',
`num_subject` INT NOT NULL DEFAULT -1 COMMENT '重点学科数量',
`gbh_num` INT NOT NULL DEFAULT -1 COMMENT '国家科研平台 ',
`create_date` INT NOT NULL DEFAULT -1 COMMENT '建校年份',
`belong` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '主管部门',
`old_name` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '曾用名',
`email` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '邮箱',
`phone` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '招生电话',
`site` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '招生网 ',
`school_site` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '官网',
`num_library` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '图书馆藏书量',
`area` INT NOT NULL DEFAULT -1 COMMENT '占地面积',
`address` VARCHAR(255) NOT NULL DEFAULT '' COMMENT '地址'
);爬取排名
import requests, json, csv, os,time
# 排名
school_id = ''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
'Referer': 'https://www.gaokao.cn/',
'Cookie': '__client_id=cf18e5784735de38665ebd085374d9d4cc3f3953; _uid=1051776; C3VK=0e0e22'
}
param ={
"a":"www.gaokao.cn"
}
lst_head = ['type_name','name','school_id','sort','province_name','rank']
is_exist_head = True
error_writer_head = ['type_spider','school_id','name','page','content']
error_write_head = True
log_file = os.path.join(r'spider\gaokao_spider\data', 'error_log.csv')
os.makedirs(os.path.dirname(log_file), exist_ok=True)
error_writer = csv.writer(open(log_file, 'a', newline='', encoding='utf-8'))
if os.path.exists(log_file):
with open(log_file, 'r', encoding='utf-8') as file:
first_row = next(csv.reader(file), None)
if first_row == error_writer_head:
error_write_head = False
rank_lst = ['https://static-data.gaokao.cn/www/2.0/schoolrank/ruanke_zongbang.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/xyh_rank.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/us_rank.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/qs_world.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/tws_china.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/tws_world.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_yuy.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_zf.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_ty.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_mz_rank.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/ruanke_mb_rank_zongbang.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/ruanke_gz_zongbang_rank.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/ruanke_mb_gz_rank.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_zw.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_yy.json',
'https://static-data.gaokao.cn/www/2.0/schoolrank/rk_cj.json']
rank_name_lst = ['软科综合','软科校友会','us世界','qs世界','泰晤士大陆',
'泰晤士世界','软科语言类','软科政法类','软科体育类','软科民族类','软科民办本科',
'软科公办高职','软科民办高职','软科中外合作','软科软科医药类','软科财经类']
output_file = os.path.join(r'spider\gaokao_spider\data', 'rank_all.csv')
os.makedirs(os.path.dirname(output_file), exist_ok=True)
writer = csv.writer(open(output_file, 'a', newline='', encoding='utf-8'))
if os.path.exists(output_file):
with open(output_file, 'r', encoding='utf-8') as file:
first_row = next(csv.reader(file), None)
if first_row == lst_head:
is_exist_head = False
if is_exist_head:
writer.writerow(lst_head)
if error_write_head:
error_writer.writerow(error_writer_head)
for i in range(len(rank_lst)):
url = rank_lst[i]
try:
resp = requests.get(url,params=param, headers=headers)
data = json.loads(resp.text)['data']
for item in data:
lst = []
lst.append(rank_name_lst[i])
lst.append(item['name'])
lst.append(item['school_id'])
lst.append(item['sort'])
lst.append(item['province_name'])
lst.append(item['rank'])
writer.writerow(lst)
print(f"[+] {rank_name_lst[i]} 排名完成")
time.sleep(1)
except:
print(f"[!] 出错:{rank_name_lst[i]}{url}")
message = ['get_rank',None,None,None,f'{rank_name_lst[i]}{url}']
error_writer.writerow(message)
time.sleep(1)
四、项目结构
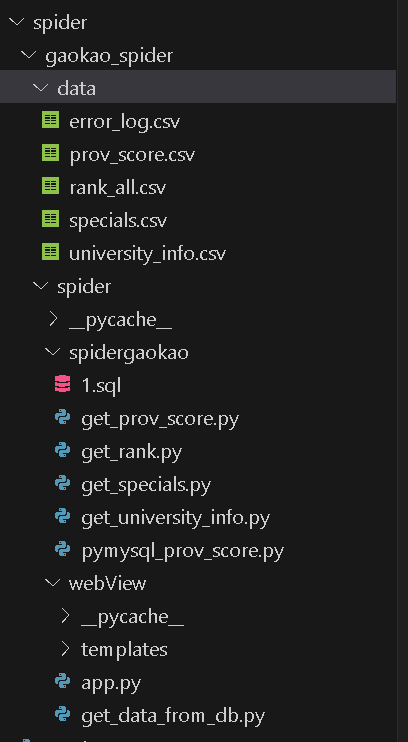
- 注意:需要项目源码打包文件可私信或评论区留言,因发送压缩文件,可私信lx方式,看到消息就会回复。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)