Python 高级:人工智能(线性回归、岭回归、逻辑回归)
1. 机器学习算法怎么从数据中学习规律
线性回归:,
和
称之为可训练参数;
算法学习:找到最优的可训练参数;
构造损失函数:。函数值越小,模型的预测值与真实值越接近,求
最小的时候
和
的值。
2. 线性回归api
from sklearn.linear_model import LinearRegression
# 获取数据
x = [[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]]
y = [84.2, 80.6, 80.1, 90, 83.2, 87.6, 79.4, 93.4]
# 机器学习
estimator = LinearRegression()
estimator.fit(x,y)
# 获取回归系数
estimator.coef_
# 获取偏置
estimator.intercept_3. 波士顿房价预测
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import SGDRegressor
# 正规方程优化
# 1、获取数据
data = load_boston()
# 2、数据基本处理 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=10)
# 3、特征工程 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、机器学习 正规方程
# 4.1 创建模型 实例化估计器
estimator = LinearRegression()
# 4.2 训练模型
estimator.fit(x_train, y_train)
# 5、模型评估 MSE 均方误差 预测值和真实值
# 5.1 获取预测值
y_predict = estimator.predict(x_test)
# 5.2 计算MSE
mean_squared_error(y_pred=y_predict, y_true=y_test)
# 梯度下降优化
# 1、获取数据
data = load_boston()
# 2、数据基本处理 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=10)
# 3、特征工程 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、机器学习 正规方程
# 4.1 创建模型 实例化估计器
estimator = SGDRegressor(max_iter=10000, tol=0.000001)
# 4.2 训练模型
estimator.fit(x_train, y_train)
# 5、模型评估 MSE 均方误差 预测值和真实值
# 5.1 获取预测值
y_predict = estimator.predict(x_test)
# 5.2 计算MSE
mean_squared_error(y_pred=y_predict, y_true=y_test)4. 正则化
Ridge岭回归代价函数:
Lasso岭回归代价函数:
L2正则化:
使得其中一些w的值都很小,都接近于0,削弱某个特征的影响,Ridge回归。
L1正则化:
使得其中一些w的值直接为0,删除这个特征的影响,LASSO回归。
目标函数:
目标函数=损失函数+正则项
Ridge岭回归代码实现:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import Ridge
# 1、获取数据
data = load_boston()
# 2、数据基本处理 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=10)
# 3、特征工程 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、机器学习 正规方程
# 4.1 创建模型 实例化估计器
estimator = Ridge(alpha=1.0)
# 4.2 训练模型
estimator.fit(x_train, y_train)
# 5、模型评估 MSE 均方误差 预测值和真实值
# 5.1 获取预测值
y_predict = estimator.predict(x_test)
# 5.2 计算MSE
mean_squared_error(y_pred=y_predict, y_true=y_test)5. 模型的保存和加载
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import SGDRegressor
from sklearn.linear_model import Ridge
from sklearn.externals import joblib
# 1、获取数据
data = load_boston()
# 2、数据基本处理 划分数据集
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=10)
# 3、特征工程 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、机器学习 正规方程
# 4.1 创建模型 实例化估计器
# estimator = Ridge(alpha=1.0)
# 4.2 训练模型
# estimator.fit(x_train, y_train)
# 保存模型
# joblib.dump(estimator, './1217.pkl')
# 加载模型
estimator=joblib.load('./1217.pkl')
# 5、模型评估 MSE 均方误差 预测值和真实值
# 5.1 获取预测值
y_predict = estimator.predict(x_test)
# 5.2 计算MSE
mean_squared_error(y_pred=y_predict, y_true=y_test)6. 逻辑回归
线性回归输入:
sigmoid激活函数:
线性回归的结果输入到sigmoid函数当中,输出结果为[0, 1]区间中的一个概率值,默认为0.5为阈值
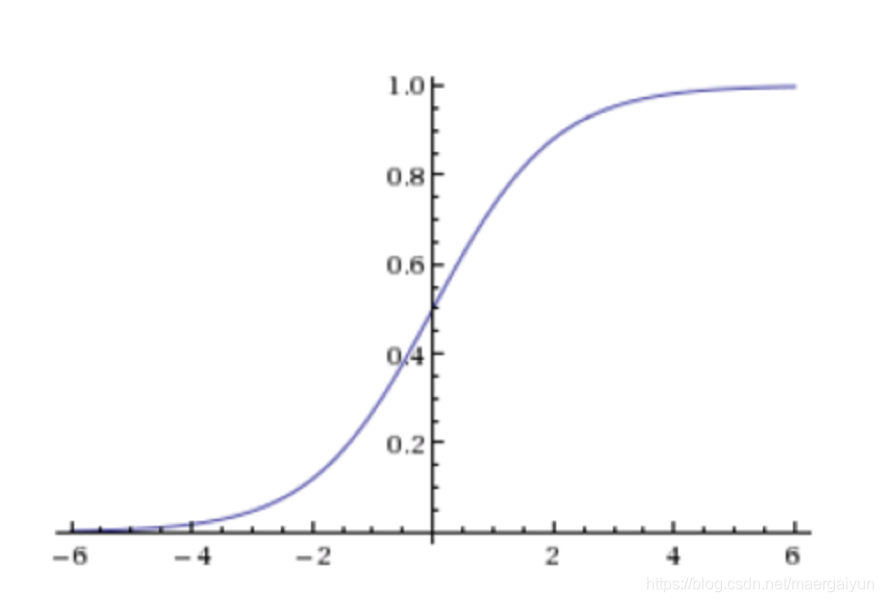
对数似然损失:
7. 癌症分类预测
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 1.获取数据 在线下载
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names=names)
# 2.数据基本处理
# 缺失值处理('?'标记)
data = data.replace(to_replace='?', value=np.NaN)
data = data.dropna()
# 划分数据集
x = data.iloc[:, 1:10] # 特征值
y = data['Class']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 3.特征工程 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习 逻辑回归建模
# 4.1 建立模型
estimator = LogisticRegression()
# 4.2 训练模型
estimator.fit(x_train, y_train)
# 5.模型评估
estimator.score(x_test, y_test)
# 分类评估报告
# 获取预测值
y_predict = estimator.predict(x_test)
# 获取分类评估报告
res = classification_report(y_true=y_test, y_pred=y_predict, labels=[2,4], target_names=['良性', '恶性'])
print(res)
8. ROC曲线与AUC指标
TPR:
TPR = TP / (TP + FN),所有真实类别为1的样本中,预测类别为1的比例
FPR:
FPR = FP / (FP + TN),所有真实类别为0的样本中,预测类别为1的比例
ROC曲线:
ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5。
AUC指标:
AUC的概率意义是随机取一对正负样本,正样本得分大于负样本的概率;
AUC的最小值为0.5,最大值为1,取值越高越好;
AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器;
0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)