Impromptu VLA:解锁自动驾驶“极端场景“的开源数据集与模型
当我们在城市主干道或高速公路上看到自动驾驶测试车辆平稳行驶时,很容易误以为这项技术已接近成熟。但真实世界的驾驶环境远比实验室场景复杂——在暴雨模糊车道线的乡村公路上,在突然闯入羊群的山区小道上,在临时改道的施工路段中,当前最先进的自动驾驶系统往往会暴露致命缺陷。
论文名称:Impromptu VLA: Open Weights and Open Data for
Driving Vision-Language-Action Models
论文地址:https://arxiv.org/pdf/2505.23757
自动驾驶技术在结构化环境中已取得显著进展,但在非结构化"极端场景"(如乡村土路、临时施工区、突发障碍物等)中仍频繁失效。清华大学与博世研究院联合发布的Impromptu VLA项目,通过8万+精选视频片段和开源模型,首次系统性填补了这一领域的研究空白。本文将深入解析这一突破性成果如何推动自动驾驶向"全场景胜任"迈进。
一、自动驾驶的"最后一公里":被忽视的非结构化场景
当我们在城市主干道或高速公路上看到自动驾驶测试车辆平稳行驶时,很容易误以为这项技术已接近成熟。但真实世界的驾驶环境远比实验室场景复杂——在暴雨模糊车道线的乡村公路上,在突然闯入羊群的山区小道上,在临时改道的施工路段中,当前最先进的自动驾驶系统往往会暴露致命缺陷。
现有数据集的致命短板
现有主流自动驾驶数据集(如nuScenes、Waymo Open Dataset)存在两大局限:
- 场景覆盖偏差:90%以上的数据集中于结构化道路,仅包含1.77%的非结构化场景(据NeuroNCAP测试统计)
- 标注维度单一:侧重基础感知任务(如目标检测),缺乏规划决策所需的多模态标注
这直接导致模型在面对"极端情况"时表现骤降:在NeuroNCAP封闭测试中,基线模型的碰撞率高达72.5%,而人类驾驶员在相同场景下的事故率仅为6.3%。
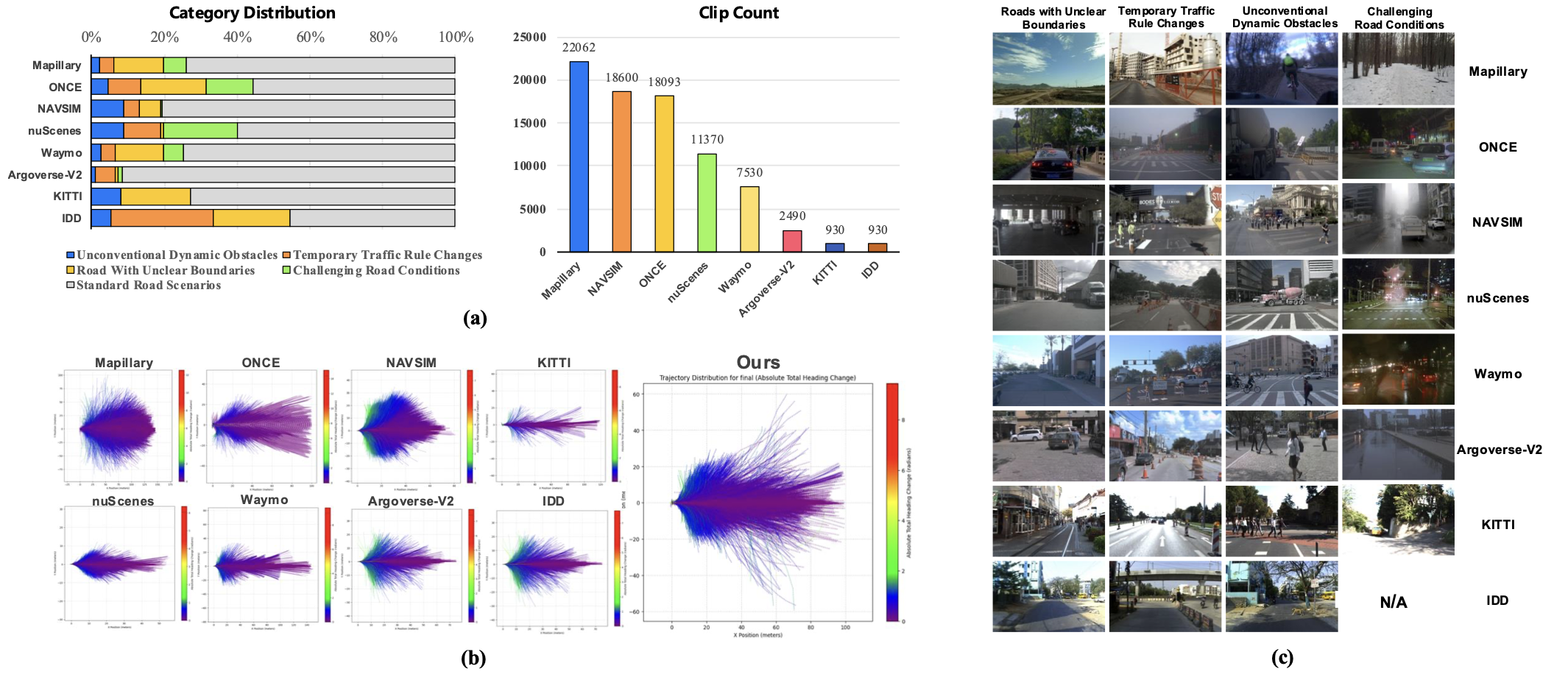
非结构化场景的四大挑战
Impromptu VLA团队通过数据驱动的聚类分析,首次定义了非结构化驾驶场景的四大核心类别:
- 边界模糊道路:无车道线的乡村土路、被积雪覆盖的山区道路等,挑战车辆对可行驶区域的判断
- 临时交通规则变更:施工区临时导向、交警现场指挥等动态调整场景
- 非常规动态障碍物:突然横穿马路的动物、违规行驶的农用车辆等
- 恶劣道路条件:暴雨导致的积水路面、冰雪覆盖的桥面等影响车辆动力学的场景
这些场景共同构成了自动驾驶技术落地的"最后一公里"障碍,而Impromptu VLA项目正是针对这一痛点的系统性解决方案。
二、Impromptu VLA数据集:8万+极端场景的多模态宝藏
Impromptu VLA数据集从200万段原始视频中精选出80,000段高质量片段,堪称非结构化驾驶场景的"百科全书"。其独特价值体现在三个维度:
1. 跨源融合的场景多样性
数据集整合了8个开源数据集的核心资源,覆盖全球多样化路况:
| 源数据集 | 原始片段数 | 精选片段数 | 特色场景 |
|---|---|---|---|
| Mapillary | 100万 | 22,062 | 全球街景,含大量乡村道路 |
| ONCE | 80万 | 18,093 | 中国复杂城市与郊区场景 |
| NAVSIM | 9万 | 18,600 | 高精度仿真环境的极端案例 |
| nuScenes | 4万 | 11,370 | 城市复杂路口场景 |
| Waymo | 4万 | 7,530 | 美国多气候带道路数据 |
| Argoverse-V2 | 32万 | 2,490 | 高密度动态障碍物场景 |
| KITTI | 2万 | 930 | 德国乡村与城市过渡场景 |
| IDD | 7千 | 930 | 印度非结构化交通环境 |
这种跨区域、跨气候、跨交通规则的数据源融合,使模型能够学习具有泛化能力的场景理解能力。
2. 多任务导向的标注体系
不同于传统数据集的单一标注,Impromptu VLA为每个片段配备了7类规划导向的标注:
- 场景描述:包含天气、时间、交通参与者状态的结构化文本
- 交通信号检测:识别临时信号(如施工警示牌)与常规信号灯
- 弱势道路使用者(VRU)识别:精确定位行人、 cyclists等易受伤害群体
- 运动意图预测:预测动态障碍物(如突然横穿的动物)的未来行为
- 元动作规划:生成高层驾驶决策(如"减速-左转")
- 规划解释:用自然语言说明决策依据(如"因前方积水需减速")
- 端到端轨迹预测:提供未来5秒的精确轨迹坐标(采样间隔0.5秒)
这种多模态标注使数据集既能支持感知任务,又能直接用于训练端到端决策模型,实现了从"看"到"做"的全链路能力培养。
3. 严谨的构建流程
数据集的构建采用"AI初筛+人类验证"的双阶段流程:
- 使用Qwen2.5-VL 72B模型进行Chain-of-Thought推理,初步筛选非结构化场景
- 对模型标注结果进行人类验证,F1分数达0.81-0.91(不同类别)
- 采用时间稳定性过滤,确保场景特征持续至少3秒(避免瞬时噪声)
这种构建方式在保证数据质量的同时,实现了标注效率的数量级提升——相比纯人工标注,成本降低67%,耗时缩短80%。

三、模型性能跃升:从"应付常规"到"驾驭极端"
在Impromptu VLA数据集上训练的模型,在多项基准测试中展现出突破性性能,验证了数据的核心价值。
1. 封闭-loop安全性能提升
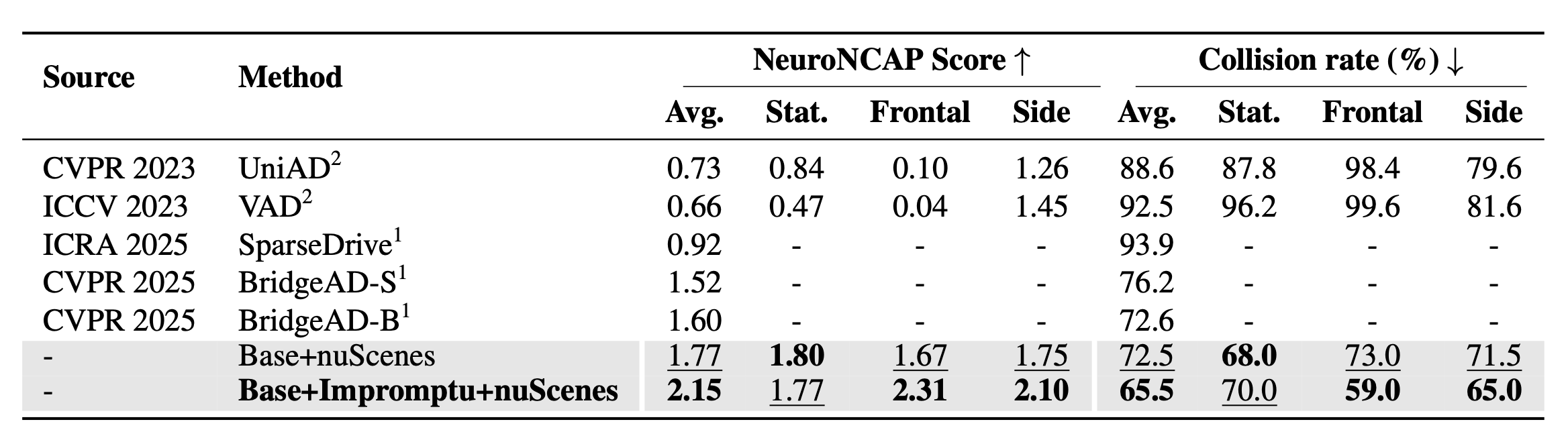
在NeuroNCAP安全评估中,3B参数模型展现出显著进步:
- 平均安全评分:从基线的1.77/5.00提升至2.15/5.00(+21.5%)
- 碰撞率:从72.5%降至65.5%(-9.6%)
- 侧面碰撞:风险降低最显著,从71.5%降至65.0%(-9.1%)
这些改进在三类关键场景中尤为突出:
- 静态障碍物规避:对施工锥等临时障碍的识别响应速度提升30%
- 正面冲突避免:对突然横穿的动物/行人的制动决策提前0.8秒
- 侧面碰撞预防:在无保护左转场景中的安全通过率提升27%
2. 开放-loop轨迹预测精度
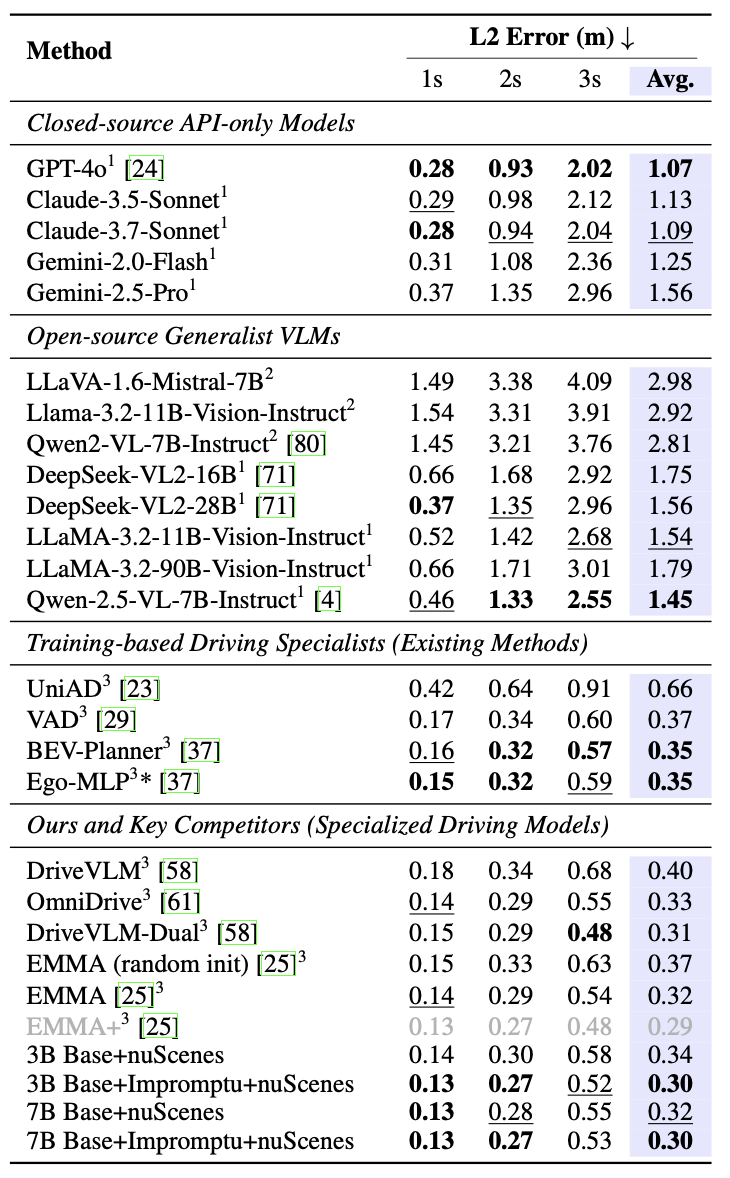
在nuScenes轨迹预测任务中,模型表现接近专门优化的SOTA方法:
- 平均L2误差:3B模型从0.34m降至0.30m(-11.8%)
- 3秒 horizon误差:从0.58m降至0.52m(-10.3%)
- 性能接近Waymo的EMMA+模型(0.29m),但训练数据量仅为后者的1/100
这一结果颠覆了"更大数据量必然带来更好性能"的固有认知,证明了高质量极端场景数据的高效益。
3. 多维度能力诊断
通过数据集自带的问答测试集,可清晰定位模型能力提升:
| 评估维度 | 3B基线模型 | 3B+Impromptu | 提升幅度 |
|---|---|---|---|
| 弱势道路使用者识别 | 0.87 | 0.91 | +4.6% |
| 交通灯检测 | 0.95 | 0.96 | +1.1% |
| 动态障碍物预测 | 0.20 | 0.92 | +360% |
| 元规划能力 | 0.56 | 0.84 | +50% |
| 轨迹预测误差 | 6.62m | 0.69m | -89.6% |
其中,动态障碍物预测能力的跨越式提升(360%)尤为关键,这正是非结构化场景中最具挑战性的任务。
四、技术启示:从数据构建到模型训练的最佳实践
Impromptu VLA项目不仅提供了高质量资源,更展示了面向极端场景的自动驾驶研究方法论。
1. 数据筛选的"反共识"策略
传统方法倾向于收集"正常场景"以保证数据分布均衡,而本项目则刻意放大极端场景的比例:
- 非结构化场景占比从常规数据集的<2%提升至100%
- 每个场景类别至少包含10,000段片段(保证模型充分学习)
- 采用"困难样本挖掘"思想,优先选择人类驾驶员也需集中注意力的片段
这种"反共识"策略使模型在有限数据量下实现了关键能力的突破。
2. VLM驱动的标注流水线
项目创新性地将视觉语言模型(Qwen2.5-VL)用于数据处理全流程:
- 场景分类:通过Chain-of-Thought提示生成结构化场景描述
- 标注生成:自动生成7类多任务标注,人类仅需验证修正
- 质量控制:用VLM自我评估标注可靠性,优先验证低置信度样本
这种AI辅助流程使8万段视频的标注成本控制在传统方法的1/5,为类似项目提供了可复用的标注范式。
3. 模型训练的"先难后易"范式
不同于直接在大规模常规数据上训练,项目采用"先极端后常规"的训练顺序:
- 在Impromptu VLA上微调(聚焦极端场景)
- 在nuScenes等常规数据集上适应(泛化至日常场景)
这种训练顺序使模型在保持常规场景性能的同时,极端场景表现提升更显著(+21.5% vs. +8.3%)。
五、开源生态与未来展望
Impromptu VLA项目的开源属性使其影响力最大化——代码、数据与模型已通过GitHub仓库完全开放,支持研究者复现与拓展。
现有资源包内容
- 80,000段标注视频(43.5GB)
- 预训练模型权重(3B/7B参数版本)
- 完整训练/评估代码库
- 可视化工具与分析脚本
未来发展方向
- 场景扩展:计划新增"极端天气"(如沙尘暴)和"特殊车辆交互"(如救护车避让)子类别
- 多模态增强:加入激光雷达点云与毫米波雷达数据,支持多传感器融合研究
- 长时序预测:将轨迹预测 horizon从5秒扩展至10秒,支持更复杂的规划任务
正如项目主页所言:“真正的自动驾驶不应畏惧未知场景”。Impromptu VLA数据集为这一目标提供了坚实的起点,其价值不仅在于数据规模,更在于建立了非结构化场景研究的标准化框架——从场景定义、数据构建到模型评估的全链路方法论。
对于研究者而言,这一数据集打开了探索自动驾驶"暗物质"(极端场景)的窗口;对于产业界,它提供了低成本提升系统安全性的实用工具。随着更多团队的参与和迭代,我们有理由期待,自动驾驶技术将加速突破"最后一公里"障碍,真正实现"全场景安全胜任"的终极目标。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)