Redis的key操作以及Value的数据结构
Redis的key操作以及Value的数据结构
Redis初始给了我们16个库,数据都是以键—值对来存储的,其中键的数据结构固定为string,值的数据类型有五种分别为:string、list、set、hash、zset。
-
select 库:切换数据库。
-
flushdb:清空当前库中的所有数据。
1.key操作
-
keys *:查看当前库中所有的key。
-
exists key:判断某个key是否存在。
-
type key:查看key的类型。
-
del key:删除指定的key。
-
expire key 过期时间(s):设置key的过期时间。
-
ttl key:查看key的剩余时间,-1表示永不过期,-2表示已经过期。
-
dbsize:查看当前库中key的数量。
2.Value数据结构
1.string(字符串)
string是最简单常用的数据结构,就是一个简单的动态字符串,不同的类型有不同的编码格式:
1.整数类型,字符串对象的编码格式为int。 2.短字符串长度<=44,字符串对象的编码格式为embstr。 3.长字符串长度>44,字符串对象的编码格式为raw。 最常用的就是计数器,比如文章点赞量、访问量等等。
-
set key value:设置键值,如果key存在会覆盖。
-
get key:获取key对应的value。
-
append key value:在key对应的键值后面追加value。
-
strlen key:获取key对应value的长度。
-
setnx key value:设置键值,只有在key不存在的条件下。
-
incr key:计数器+1。
-
decr key:计数器-1。
-
incrby key 步长:计数器+步长。
-
decrby key 步长:计数器-步长。
2.list (列表)
list是可重复的列表,是按插入的顺序排序的,实现方式有两种分别是ziplist和quicklist(ziplist+链表)。
2.1ziplist实现list
在list中元素数量较少的情况下采用的是压缩链表ziplist存储,ziplist内存占用的是一块连续空间,利用数组实现,可以存字符串和整数,其空间存储的不止有数据,还有ziplist占用字节的总数、元素的总个数和首尾的偏移量。首尾的偏移量用来快速定位到最后一个元素,可用于从后往前遍历。
2.2quicklist实现list
quick是一个双向链表,是基于ziplist实现的,其内部的每一个结点都是ziplist,用于list元素数量大于512时存储。

list主要被用于像展现粉丝列表、关注列表等等。
-
lpush key value1 value2 .....:从左边插入,头插法。
-
lrange key start stop:从左边拿[start stop]下标的数据,当stop=-1时代表获取从start开始到最后一个元素的数据。
-
lpop key:从左边删除值并且返回,值光key亡。
-
rpoplpush key1 key2:从key1右边吐出一个值,并且添加到key2的左边。
-
lindex key index:按照索引的下标获取元素。
-
llen key:获取列表的长度。
-
linsert key before value1 value2:在value1的前面加上value2。
-
lrem key n value:从左边删除n个value值。
-
lset key index newvalue:将列表key下标为index的值替换为newvalue。
3.set(集合)
set是无序不可重复,无序只是表明不保证按插入顺序存储,实现方式有两种分别是inset和hashtable。
3.1inset实现set
inset内部也是一块连续的内存空间,利用数组来实现,用于集合中元素数量较少的情况,而且只能存储整数,intset始终保持数据从小到大有序,为的是节约内存而提高效率,如果有非整数内部的实现就会立刻变为hashtable结构。
3.2hashtable实现set
如果元素数量大于512个,使用hashtable来存储,实现set集合只使用了hashtable中的键,值为null,可以快速查询到需要的数据。
set可用做存储商品的标签,后续用于并、交、差操作。
-
sadd key value1 value2:将多个元素添加到key对应的set集合中。
-
smembers key:取出该集合的所有值。
-
sismember key value:判断集合中是否包含有value值。
-
scard key:返回该集合的元素个数。
-
srem key value1 value2:删除集合中的某些元素。
-
spop key:随机从该集合吐出一个值,值空key亡。
-
srandmember key n:随机从集合中返回n个值,不会从集合中删除。
-
smove key1 key2 value:将key1集合中的value值转移到key2中。
-
sinter key1 key2:返回两个集合的交集。
-
sunion key1 key2:返回两个集合的并集。
-
sdiff key1 key2:返回两个集合的差集(返回在key1中有的,key2中没有的)。
4.hash(散列)
redis中的散列可以存储多个键值对,底层的实现方式有ziplist和hashtable。
4.1ziplist实现hash
可以使用两个ziplist来实现hash,一个存储键(field),另一个存储值(vlaue),用于键值对中的字符串长度小于64并且元素数量较少的情况。
4.2hashtable实现hash
当键值对的字符串长度大于64或者元素数量大于512时,使用hashtable来实现即可。
hash可用做存储用户购买的商品、购物车,比如用户id为key,然后商品的id为field,购买商品的数量为value。
-
hset key field value:添加field
-
hget key field:获取field对应的value
-
hmset key field1 value1 field2 value2:批量添加
-
hexists key field:判断key中是否存在field
-
hkeys key:查看key中所有的field
-
hvals key:查看key中所有的value
-
hincrby key field n:给field对应的value+n
-
hsetnx key field value:如果不存在field,那么才会添加
5.zset
zset是排好序(默认由小到大)的,并且无重复元素。score分数以及value值,zset是按照分数来排序的,有序集合的实现方式有ziplist和hash(实现映射)+skiplist(跳表查询)两种。
5.1ziplist实现zset
当元素数量小于128并且键值小于64字节时可以使用两个紧挨的ziplist来实现zset,元素大小有序是因为当新增一个元素时,需要扩大内存以及从前到后一个个进行元素比对最终找到合适的插入位置,其中会涉及到元素的移动(类似插入排序),最坏情况下如果扩大内存时,但后面的内存不是空闲的,这就会涉及到整个ziplist的数据重新迁移。
5.2skiplist实现zset
跳表是在一条有序链表的基础上增加了多级索引,其寻址的过程为:从最高层开始开始查找,如果当前位置的next指针为null,那么就下降到下一层,如果next指向的元素小于查找的值,那么就继续向后去遍历查找,如果大于查找的值,那么就调用backward后退指针指向next位置的前一个元素,向前去比较寻找即可。如下图二级索引示例查找27:
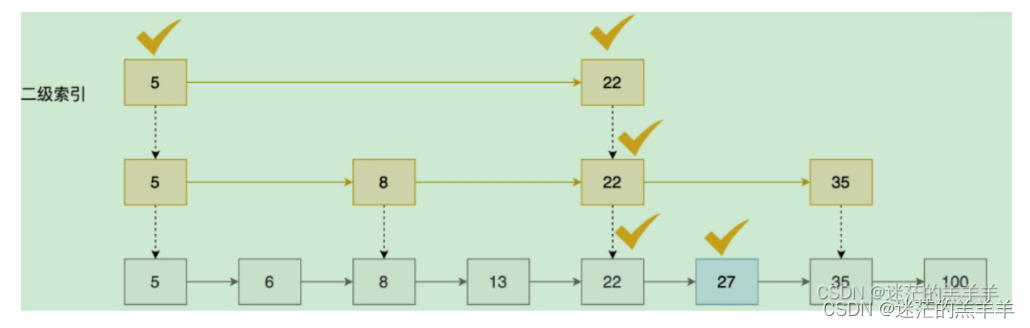
至于为什么不使用平衡二叉树来实现zset的一部分原因是因为其每个节点都需要指向左右子树的2个指针 ,而使用skiplist平均每个元素需要1.3个指针,我们都知道局限redis的会是内存空间大小和网络速度,所以使用skiplist会更加的节省内存空间。
zset最主要的使用场景就是文章访问量排行榜。
-
zadd key score1 value1 score2 value2:批量添加。
-
zrange key start end [withscores]:查找下标范围[start end]的数据,endIndex=-1表示从start开始到最后一个元素的数据。
-
zrangebyscore key minscores maxscores:获取评分范围内的value值。
-
zrevrangebyscore key maxscores minscores [withscores]:将此分数范围内的值按分数从大到小返回。
-
zincrby key n value:将此value的评分+n。
-
zrem key value:删除该key中的value。
-
zcount key minscores maxscores:统计该分数范围内的value个数。
-
zrank key value:返回该值的排名,从0开始。

DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)