【深度学习】【入门】池化层
池化层是深度学习中重要的下采样操作,主要分为最大池化和平均池化两种类型。最大池化选取窗口内最大值,适合边缘检测;平均池化计算窗口平均值,能平滑噪声保留整体特征。池化层的作用包括:降低特征图尺寸以减少计算量、增强模型对平移和旋转的鲁棒性、防止过拟合。此外还有随机池化和全局池化等特殊方法。代码示例展示了PyTorch中MaxPool2d的实现,通过设置kernel_size、stride等参数控制池化
1.池化层的概念
它像一个智能筛选器,对卷积层输出的特征图进行巧妙处理,让模型在学习过程中能够聚集焦点,忽略冗余
池化层是一种基于滑动窗口的下采样操作,通过在特征图的局部区域内执行某种聚合操作,来减少特征图的尺寸,同时保留关键信息。它能够按照一定规则,比如取局部区域内的最大值(最大池化)或者平均值(平均池化),将图像中那些过于琐碎的细节信息适当忽略,提取出最具代表性的特征 ,把大尺寸的图像转化为较小尺寸但关键信息得以保留的特征图,大大降低后续处理的计算量和存储需求。
2.池化层的作用
1.降维和减少计算量
在深度学习模型的构建中,计算资源的有效利用是一个关键问题。随着网络层数的增加,如果特征图的尺寸保持不变,后续层需要处理的数据量将呈指数级增长,这不仅会消耗大量的计算时间,还可能导致内存不足的问题。池化层通过下采样操作,能够显著减少特征图的尺寸,从而降低计算复杂度
2.提高鲁棒性
在现实世界中,我们所处理的数据往往存在各种变化,比如图像中的物体可能会发生平移、旋转或尺度变化。对于深度学习模型来说,能否在这些变化情况下依然准确地识别出目标,是衡量其性能的重要指标。池化层的出现,为模型带来了对这些变化的鲁棒性,使模型能够更加稳定地工作
3.防止过拟合
过拟合是深度学习中常见的问题,当模型在训练数据上表现得过于完美,但在测试数据或新数据上却表现不佳时,就出现了过拟合现象。这是因为模型学习到了训练数据中的一些特殊细节和噪声,而没有真正掌握数据的内在规律,导致泛化能力下降。池化层作为一种有效的正则化手段,可以通过减少模型参数数量和降低模型复杂度来防止过拟合的发生
3.池化层的类型
1.最大池化
最大池化(Max Pooling)是最为常见的池化方式之一,其原理直观且易于理解。在进行最大池化操作时,我们会设定一个固定大小的池化窗口,比如常见的3*3或2*2窗口 。这个窗口就像一个探测器,在特征图上以一定的步长滑动,每次滑动到一个位置,就对窗口内的所有元素进行比较,选取其中的最大值作为该窗口池化后的输出结果
在实际应用中,最大池化在图像边缘检测任务中表现出色。图像边缘是图像中物体形状和结构的重要特征,边缘像素的强度值通常与周围像素有明显差异。当我们使用最大池化时,由于它会选择窗口内的最大值,所以能够很好地保留这些边缘像素的信息,从而突出图像的边缘特征。在识别手写数字时,数字的笔画边缘是区分不同数字的关键特征,最大池化可以有效地提取这些边缘,帮助模型更准确地识别数字
2.平均池化
平均池化(Average Pooling)与最大池化有所不同,它的核心原理是计算池化窗口内所有元素的平均值,并将这个平均值作为该窗口池化后的输出值
平均池化在保留数据整体特征和去除噪声方面具有独特的作用。在图像中,噪声通常表现为像素值的随机波动,这些波动可能会干扰模型对图像主要特征的学习。平均池化通过计算平均值,可以在一定程度上平滑这些噪声,使特征图更加稳定和可靠。对于一些需要关注图像整体特征的任务,如场景分类,平均池化能够更好地保留图像中各个区域的平均信息,帮助模型判断图像所属的场景类别。在判断一张图像是属于城市街道场景还是自然风光场景时,平均池化后的特征图能够综合反映图像中各个区域的平均颜色、纹理等信息,为模型的分类决策提供有力支持
3.其它池化方法
随机池化(Stochastic Pooling)是一种基于概率的池化方法。在随机池化中,每个元素被选中作为输出的概率与其值成正比。也就是说,值较大的元素被选中的概率相对较高,但并不是像最大池化那样绝对地选择最大值。这种方式在一定程度上增加了模型的随机性和泛化能力,因为它不会像最大池化那样总是依赖于局部区域的最大值,而是在一定范围内随机选择,使得模型对于不同的输入数据具有更好的适应性
全局池化(Global Pooling)则是一种特殊的池化方式,它与一般池化方法的区别在于池化窗口的大小。全局池化的池化窗口大小与整个特征图相同,即对整个特征图进行一次池化操作。全局平均池化(Global Average Pooling, GAP)是全局池化的一种常见形式,它将整个特征图的所有元素求平均值作为输出。这种方法在一些场景中具有重要应用,比如在图像分类任务中,使用全局平均池化可以直接将特征图转化为一个固定长度的特征向量,避免了全连接层带来的大量参数,从而减少模型的过拟合风险,同时也能加快模型的训练速度
4.最大池化讲解(常用)
1.参数

1.kernel_size
池化窗口大小,可为整数或包含两个整数的元组
2.stride
窗口滑动步长,默认与kernel_size相同,类型是整数或包含两个整数的元组
3.padding
隐式填充,填充负无穷,用于在输入两侧补充,类型为整数或包含两个整数的元组
4.dilation
控制窗口内元素间隔的参数,类型是整数或含两个整数的元组
5.return_indices
布尔值,为True时会返回最大索引
6.ceil_mode
布尔值,为True时ceil(向上取整),默认False(floor)(向下取整),用于调整输出尺寸计算方式
2.代码:
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.nn import Conv2d, MaxPool2d
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor(), download=False)
dataloader = DataLoader(dataset=dataset, batch_size=64)
class Module(nn.Module):
def __init__(self):
super(Module,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, stride=3, padding=0, dilation=1, return_indices=False, ceil_mode=True)
def forward(self,x):
x=self.maxpool1(x)
return x
module = Module()
writer = SummaryWriter('../logs')
step = 0
for data in dataloader:
imgs,targets = data
output = module(imgs)
print(imgs.shape)
print(output.shape)
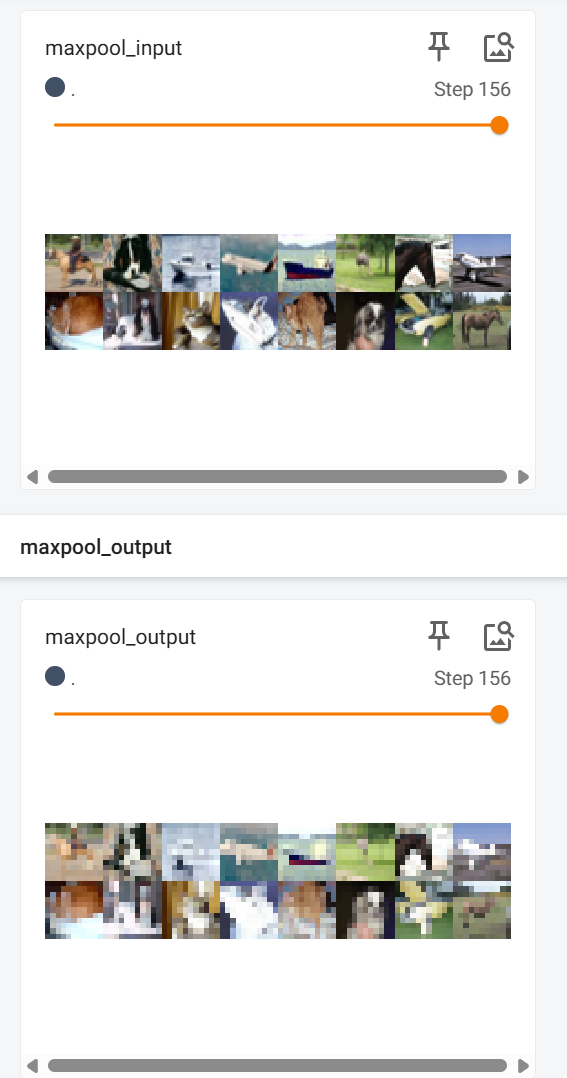
writer.add_images('maxpool_input', imgs, step)
writer.add_images('maxpool_output', output, step)
step = step + 1
writer.close()3.结果:


DAMO开发者矩阵,由阿里巴巴达摩院和中国互联网协会联合发起,致力于探讨最前沿的技术趋势与应用成果,搭建高质量的交流与分享平台,推动技术创新与产业应用链接,围绕“人工智能与新型计算”构建开放共享的开发者生态。
更多推荐

 37
37 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)